开放环境下自适应聚类优化包络的相机来源取证
2022-09-17侯嘉尧
王 波,王 悦,王 伟,侯嘉尧
(1.大连理工大学信息与通信工程学院,辽宁大连 116024;2.中国科学院自动化所智能感知与计算研究中心,北京 100190)
1 引言
由于数字图像处理技术的进步以及各类数字图像处理软件的普及,人们可以方便、快捷地将数字图像通过图像处理软件进行修改,并利用网络社交平台随心所欲地传播,从而给整个社会带来深远的影响.当不法分子将其修改过的图像在网络上进行传播时,所造成后果往往不堪设想.因此,图像来源取证技术得到了越来越多的学者关注.数字图像的相机来源取证是计算机视觉领域最具挑战性和现实意义的研究问题之一[1].
在传统的封闭环境中,相机来源鉴别往往被认为是一个确定类别数的多分类问题[2~8].但是如果待鉴别图像由训练集外的(未知的)相机拍摄,传统封闭环境下的分类方法会把该图像错误地归类到已知的来源相机之一.因此,考虑到未知来源相机的存在,开放环境下的相机来源鉴别被认为是一个类别数不确定的多分类问题.随着市面上的相机品牌和种类的日新月异,取证分析人员很难实时掌握市面上的所有品牌型号的相机信息[9].相对于传统的封闭环境,开放环境下的数字图像来源鉴别允许待测试图像为已知数据集合之外的未知类,通过引入“未知类”来大大减少分类器的误分类问题.本文针对开放环境下的相机来源鉴别问题,提出一种基于特征空间包络优化的来源取证方法.本文贡献主要体现在以下3个方面.
(1)实现了一种开放环境图像来源鉴别方法,该算法在已知来源相机识别准确率以及时间复杂度上占据明显优势.
(2)针对单类别异常点检测问题,提出了一种基于手肘法聚类的特征空间包络优化方法.
(3)构建了一个开放环境下的多分类方法,在数据集增添新类别时只需要单独训练该类别,相对已有方法在数据更新方面具有更强的扩展性.
2 相关工作
2.1 基于相机模型的数字图像来源鉴别
本文所研究的内容属于图像被动取证技术[10]中的一种,它不需要事先对图像进行任何处理,而是直接利用图像本身的信息进行鉴别,因而具有更加广阔的应用场景.如图1 所示,在溯源设备角度数字图像取证技术可以分为3 个层次[11]:(1)基于设备类型;(2)基于设备型号;(3)基于设备个体.本文面向开放环境下数字图像来源设备型号的鉴别问题开展工作.
2.2 开放环境下的相机来源鉴别
图1 中方框表示传统封闭环境下的数字图像来源鉴别,此时的待检测图像往往被认为是来自训练数据集的设备,即已知类设备.开放环境下的相机来源鉴别是指在检测过程中允许待检测图像来自数据集之外的设备,也就是引入了“未知类”的概念,从而减少了新型相机被分类器误认成来自已知相机模型的错误分类情况.
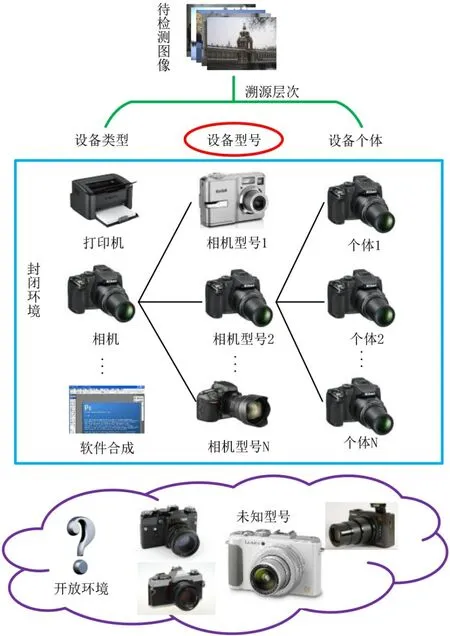
图1 数字图像取证层次划分与开放环境描述
在相机来源取证中引入开放环境问题最早可以追溯到2009 年,王波等人[11]将一类和多类支持向量机相结合,解决了图像来源取证方法对于多类样本准确性较差,以及无法对未知模型的图像进行溯源的问题.2012 年,Costa 等人[12,13]提出了一种决策边界雕刻的方法.该方法首先将已知模型的图像作为正类样本,将其他已知模型的图像作为负样本;然后,通过调整决策边界来最小化假阳性匹配,训练二值支持向量机来区分正样本和负样本.由于缺乏关于未知模型的信息,决策边界在实际情况下可能无法很好地将正类样本与未知类样本识别出来.2015 年,Huang 等人[14]提出了一种基于K 近邻的未知相机来源检测方法.他们首先使用K 近邻算法从测试集中识别出一部分的未知源图像,并将它们从测试集中分离出来;然后将这部分图像作为未知源图像的初始训练样本,与训练集一起用来训练一个N+1 类的支持向量机(Support Vector Machine,SVM)[15];接着,继续使用这个SVM 从测试集中把剩余的未知源图像分离出来,加入到训练样本中,不断重复这个训练与分离的过程,最终取得了不错的鉴别效果.但是由于K 近邻算法的特点,当样本不平衡时已知模型的预测精度较低,计算复杂度和空间复杂度也相对较高.近年来,单类别学习可解决在连续学习领域中的灾难性遗忘问题[16],但由于训练过程处于传统封闭环境,因此无法解决未知类的问题.
随着深度学习的发展,Bondi等人[17]于2017年首次将卷积神经网络引入相机模型来源鉴别中.接着,2018年,Bayer和Stamm[18]提出了一种基于最大置信度的阈值算法来识别未知相机模型.他们首先使用一个卷积神经网络来提取相机模型识别特征,然后将学习到的深度特征映射到置信度分数上,以表明这两个图像块是由相同或不同的相机模型捕获的,如果置信度低于阈值,则将查询图像识别为未知.2018年,Mayer等人[19]提出一种图像碎片对比系统.该方法首先使用一个基于卷积神经网络的特征提取器去为图像提取特征,接下来学习了一种相似性度量方法,将这些特征对映射到与每个已知相机模型相关的分数上,最后以该分数作为判断两幅图像是否属于同一源相机模型的标准.然而,该方法只能确定两个输入图像之间的关系.此外,由于深度学习方法的特点,该方法在训练过程中需要数量较大的训练集且时间消耗很大.由于每增加一个种类的相机都需要将其他已有相机联合起来重新训练一个新的分类器,因此该方法在模型扩展方面有一定的局限性.在此基础上,Mayer等人[20]于2020年设计了一个视频相机模型验证系统,包括深度特征提取器、相似度网络和视频级融合系统.该方法可以对两个查询视频是否被同一摄像机模型捕获进行分类.
3 开放环境聚类包络优化算法
本文算法的主要思想是根据不同相机模型拍摄图像的高维特征,通过聚类手段将原始的同一类型相机数据依照特征空间分布的不同进行划分,以实现模型包络细化.具体来说:首先通过手肘法[21]得到每一类相机数据的聚类个数,并以该聚类数为参照进行K均值(kmeans)聚类[22];然后将得到的相机模型子类数据分别进行支持向量数据描述(Support Vector Data Description,SVDD)[23,24]以刻画其子包络,并根据所属相机模型类别将子包络合成一个更具细节特征的特征包络[25];最后通过判决法则将来自未知相机模型的图像排除,并对判断为已知来源的图像分类溯源,实现开放环境下的相机来源鉴别.本文算法的整体流程如图2所示.
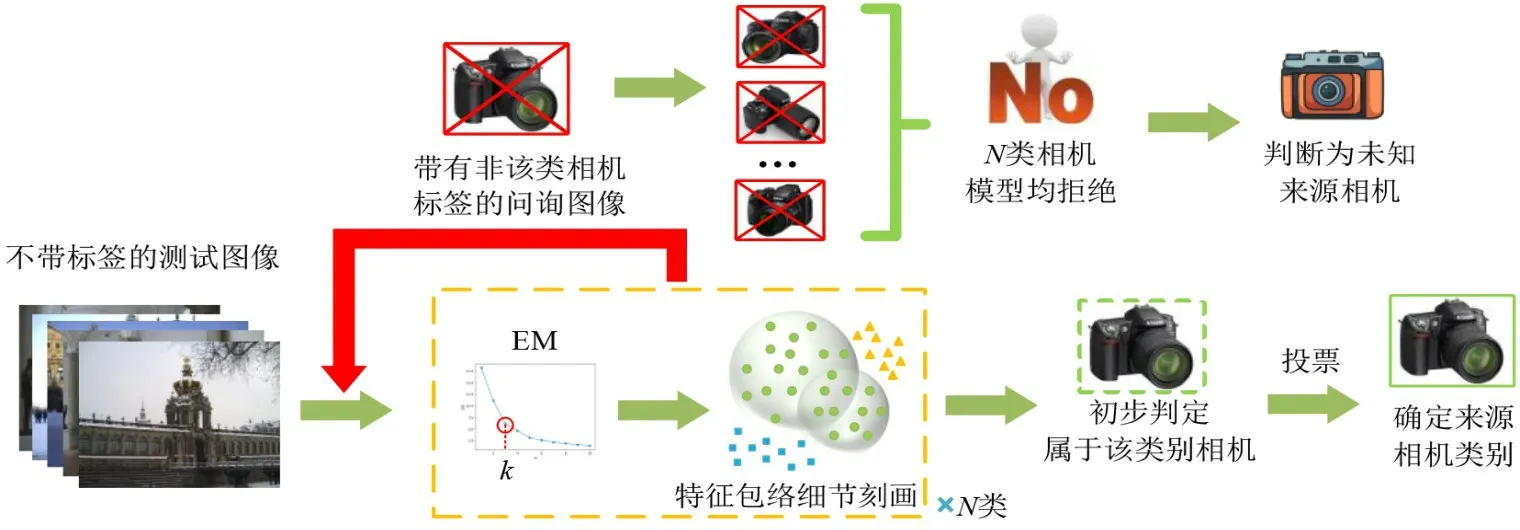
图2 算法整体流程图
3.1 手肘法确定聚类个数
k-means 是聚类划分类中的最广为人知的一种方法.其算法的优点是易于实现,且其复杂度适合数据量较大的情况.考虑其简单且运行效率快的优点,本文采用k-means 聚类算法将每一类原始类别相机模型分别聚类成k个子类.现有的k-means 聚类方法并没有给出聚类个数,人为预先设定其聚类数往往难以得到最优.因此,本文应用手肘法(Elbow Method,EM)模型来为k-means算法确定最佳聚类数.EM核心指标是误差平方和(Sum of the Squared Errors,SSE)[26],其表达式是

其中,k表示该类相机模型的数据根据特征空间分布所确定的内部聚类总数;i表示其中的某个子数据集的编号;Ci表示属于该类训练相机模型的第i类子数据集;SSE 代表所有样本的聚类误差,用于刻画聚类效果的好坏.
由于k与簇间聚合程度之间是正相关的,当k的数量小于真实的聚类数时,SSE 的下降幅度会很大,而当k接近真实聚类数时,增加k所带来的聚合回报会骤减,因此SSE 会随着k的增大而逐渐趋于稳定.此时,SSE 与k之间会形成一个类似手肘形状的关系图,而这个手肘的关节处对应的k值就是数据拥有的真实聚类数.
3.2 特征包络细节刻画
本文首先提取训练集图像的CFA(Color Filter Array)特征[27~29],然后针对每一类相机模型进行包络刻画.SVDD 作为一种新型的单类分类器,通过刻画正类样本的边界最小容积超曲面在异常检测领域得到了广泛的应用.然而,特征空间中的样本分布通常是复杂的而且是不可预测的,而SVDD 在这些情况下往往不能很好地描述边界样本.
如图3 所示,假设在高维特征空间中分布着3 类相机模型样本,绿色圆形表示已知来源相机模型样本(正类样本),使用面来描述正类样本分布时往往会造成误分类:如红色边界圆所示,如果保证尽可能多的覆盖正类样本,则超球体的半径需要变大,这势必会造成其他未知类别样本被错误的判断成已知类别样本(红色边缘三角形、红色边缘正方形);如紫色边界圆所示,如果保证超球体类内纯度,则其半径会随之减小,这势必会导致部分正类样本被错误地分类成未知来源的负类样本(紫色边缘小圆形).
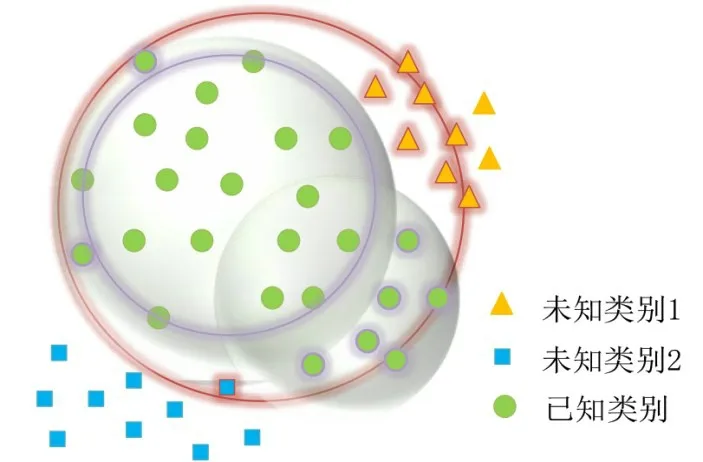
图3 特征空间包络优化示意图
因此,本算法提出预先根据不同类别的特征分布对每一类正类样本进行数据再划分,利用EM 法确定聚类个数,然后通过k-means 聚类方法将正类样本划分成多个子类数据集合,之后分别对子类边界数据构建超曲面,形成k个子包络.由于属于同一相机模型的子包络内部数据具有相同的真实标签,因此可以将多个子包络融合构成一个新的超曲面包络.此时,该包络相比之前的方法涵盖了更多该类别的细节特征,从而可以在保证正类样本的召回率情况下,更好地拒绝未知样本,如图3中浅绿色球体所示,当k等于2时构建的两个超曲面体相比之前一个超曲面对边界的细节特征刻画得更加具体,大大减少了错误分类的情况.
3.3 正类样本的模型训练
假设在训练集TR中有N类相机,每一类相机用不同的标签η表示,每类相机模型的数据集合用Γ(η)表示,即Γ(η)⊂TR,∀η∈(1,2,…,N).
对于每一类相机模型数据集合Γ(η),利用上文方法将其分为K个子集,用γ(ηk)表示.其中,ηk表示来自同一个真实相机模型η,但是属于不同子数据集k的样本标签.也就是说,γ(ηk) ⊂Γ(η),∀k∈(1,2,…,K).

其中,a是超曲面的中心,R是半径,ξi表示松弛因子,C代表用于平衡超曲面体积和误差分数的惩罚参数.通过引入拉格朗日乘子[23,24],原始问题可以转化成式(3)的对偶问题:

其中,αi是拉格朗日系数,是核函数(特征空间的内积).
通过对偶问题的求解,可以得到所有样本的拉格朗日系数.在所有的训练样本中满足0≤αi≤C的拉格朗日系数称为支持向量.假设训练数据集中由支持向量组成的样本集为V,利用核函数映射到输入空间的边界不再局限于球面分布,超曲面的中心和半径表示如式(4)和式(5)所示:

其中,xv∈V.正训练样本的数据描述可以通过超曲面的中心和半径得到.
根据上述公式对相机模型数据进行聚类细化形成子超曲面包络,再将子超曲面根据真实标签进行融合形成该类别相机模型的判决超曲面包络.由于捕捉到了相机模型内部的特征分布情况,因此即使训练集只有一个已知的相机模型(恶劣情况),本文算法也能有效地拒绝未知样本.与其他现有方法相比,本算法在未知来源相机模型上更具可扩展性.也就是说,一旦数据集需要添加一些新的相机模型,只需要对每一个新的相机模型进行训练,而不需要对数据集中所有已知的相机模型进行再训练.
3.4 未知来源相机检测及已知来源相机溯源
对于测试集TE,假设测试集中的图像用xtest表示.假设通过上文所述得到的超曲面判决模型为,同上文定义,ηk代表判决模型的真实标签.对每一个超曲面来说,测试样本xtest到超曲面中心的距离为
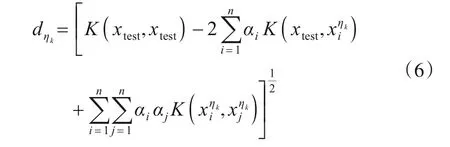

由此得到以下判决准则:
(1)对于所有超曲面,如果测试样本计算出的所有均满足>1,则认为此测试样本来自测试集之外的某个未知来源相机模型;
(2)如果测试样本计算出的任何一个满足≤1,则该样本被初步认为是来自数据集中某已知来源相机模型.接下来,需要进行投票以确定其真实标签.
算法1为已知来源相机标签分配准则:
(1)如果测试样本只被一个超曲面Mηk所接受,即只存在一个满足≤1,则判断该测试样本为具有真实标签η的相机模型所拍摄;
(2)如果测试样本被多个不同的超曲面接受,但是超曲面由同一真实标签下不同子类数据集构成,即η相同、k不同.那么,可以判断该测试样本为具有真实标签η的相机模型所拍摄;
(3)如果测试样本被多个不同的超曲面接受,且超曲面来自不同真实标签,即有多个不同的η标签.那么,系统将对具有不同真实标签超曲面的数量排序,选择接受该测试样本数量最多的超曲面的真实标签作为该测试样本的标签.如果存在数量并列第一的情况,则计算所在的超曲面位置,并将其真实标签赋予该测试样本.
综上所述,通过应用判决准则可以将测试集中的未知来源相机拍摄的样本排除,并对已知来源相机拍摄的样本分类溯源.

4 实验与结果分析
为了在开放环境下对本文算法进行评估,本节进行了大量实验,详细的实验设置和实验结果如下所述.
4.1 实验设置
本文选择图像来源鉴别中经典的数据集——Dresden数据集[30].除此之外,本文还选择了SOCRatES数据集[31]来说明本文算法在开放环境下手机图像的溯源也有一定的适用性.Dresden 数据集中的图像是由不同相机在室内、室外不同环境下获取的,提供了来自27个不同模型的74个相机的近17 000张图像.SOCRatES数据集由大约9 700 张图片和1 000 个视频组成,这些图像和视频是用15 个不同品牌、60 个不同型号的103 款不同的智能手机拍摄的.
为了消除同一相机模型中不同个体的影响,同一相机模型的训练和测试集中的样本来自不同的个体.本文实验在尽可能地满足相机品牌多样性的条件下,从Dresden和SOCRatES数据集中分别随机选择10个不同相机模型,相机型号的详细信息见表1和表2.
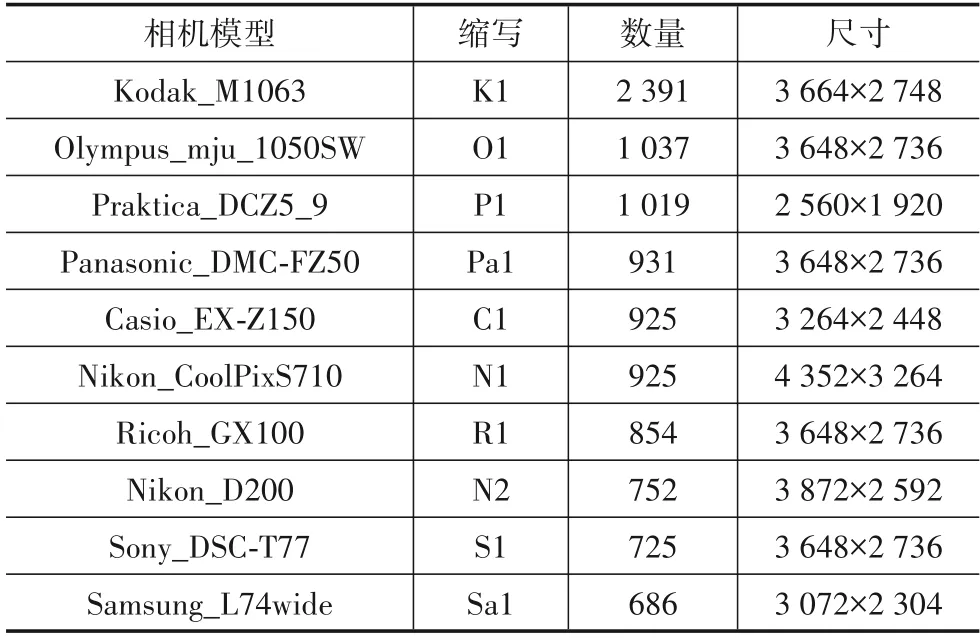
表1 Dresden数据集中选择的相机模型信息

表2 SOCRatES数据集中选择的相机模型信息
由于Dresden和SOCRatES 图像数据集中的不同相机模型拍摄图像尺寸不同,因此本文对所有图像进行预处理,在每幅图像中心截取256×256大小的子图作为实验数据.
本文所采用的对比方法如下:
(1)联合OC-SVM和MC-SVM 的数字图像来源取证方法(Combined Classification Framework,CCF)[11];
(2)未知模型的相机来源鉴别算法(Source Camera Identification with Unknown models,SCIU)[14];
(3)相似度比较法识别未知来源相机算法(Mayer et al.Similarity,MS)[18,19].
为了说明本文算法在数据聚类预处理上的有效性,本文还设置了两个自对比实验:
(1)数据聚类预处理后的CCF 算法(CCF_Adaptive Clustering,CCF_AC):每类相机模型先通过手肘法确定聚类个数,再运用k-means 聚类算法将每一类原始类别相机模型分别聚类成k个子类,接下来使用联合OCSVM和MC-SVM 的图像来源取证方法(Combined Classification Framework,CCF)[11]得到判决模型;
(2)本文所提算法去除数据聚类处理后的自对比算法(Self-Contrast,SC):不使用数据聚类预处理对相机模型再划分,直接根据每一类相机模型特征进行超曲面包络构建得到判决模型.
4.2 评估指标
为了说明本文算法的有效性,本文使用以下评价指标[14].
(1)已知来源相机模型识别精度(Known ACCuracy,KACC),用于评估算法对召回已知的来源图像的能力,定义为

(2)未知来源相机模型识别精度(Unknown ACCuracy,UACC),用于评估算法对排除未知来源图像的能力,定义为

(3)整体相机模型识别精度(Overall ACCuracy,OACC),用于评估算法整体的识别准确率,定义为

4.3 与使用SVM为代表的已有方法对比
为了评估本文算法与其他使用SVM 为代表的已有方法之间的性能,特设计了如下实验.首先将如表1所示的Dresden 数据集中的10 类相机模型按照7∶3 分成训练集和测试集,然后将10 类相机模型的测试集图像整理在一起作为本实验的测试集.接下来,分别选择每一类相机模型剩下来的图像作为训练集样本,10 类相机模型图像共同构成的测试集来做测试.此实验设置最大程度模拟了现实生活中已知来源的训练样本少且未知来源的图像样本多的恶劣情况,通过对不同方法下的KACC,UACC和OACC 三个指标的分析,可以真实、客观地评价出本文算法的表现情况.
本文利用手肘法对Dresden 以及SOCRatES 数据集中每一类相机模型的训练样本进行预处理,确定出每类训练样本的聚类子类个数,如表3所示.
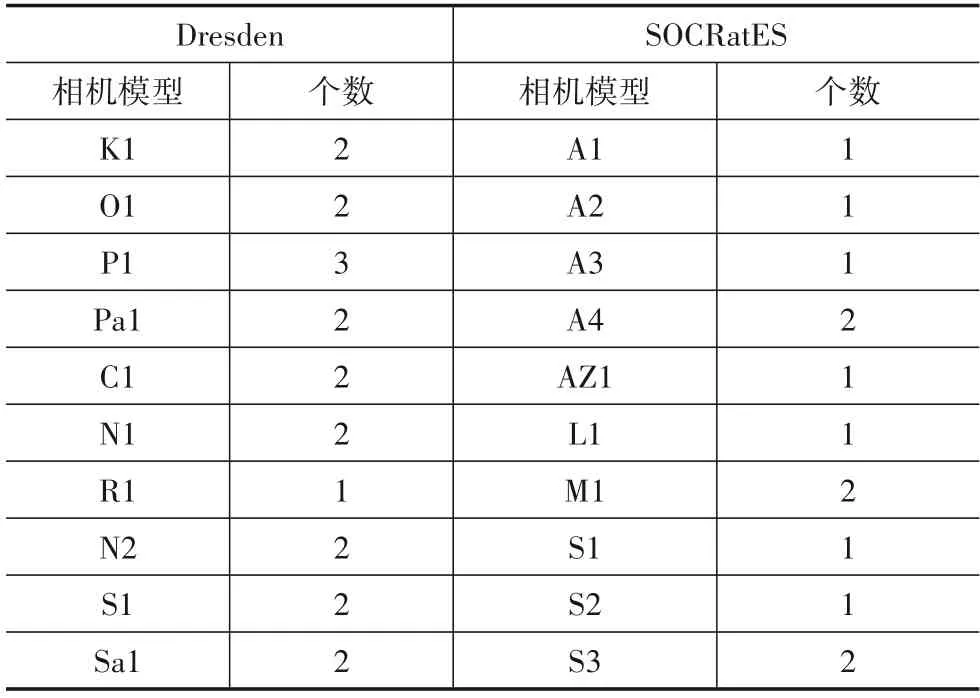
表3 Dresden与SOCRatES中聚类子类个数 单位:个
表4、表5和表6 所示,分别为5 种方法在Dresden数据集下的已知来源相机模型精度(KACC)、未知来源相机模型精度(UACC)以及整体相机模型精度(OACC).由于相机模型R1 在数据预处理上得到的聚类子类个数为1,说明在高维特征空间该相机模型的分布没有呈现明显的簇类划分,因此SC 算法与本文算法在此相机模型的3个评价指标上得到了相同的数值.
如表4 所示,本文算法以及SC 算法在KACC 上远高出其他几种方法.其中,本文算法以95.2%取得最高的平均准确率,SC算法以91.5%达到第二高.接下来分别是CCF_AC 算法(53.3%)以及CCF 算法(46.5%),SCIU 算法的KACC 效果最差,只有42.9%.本文所提算法在特征空间的包络描述上具有更多的细节特征,因此可以在训练集中只有一种类型相机图像的恶劣情况下,仍然达到召回已知来源相机模型样本的作用,这是其他对比算法很难达到的.因为在面对错综复杂的测试样本时,分类器往往为了拒绝未知样本而造成已知样本的误判,而本文算法通过包络优化解决了这一问题,而两组自对比实验可以看出,本文算法相比SC算法在KACC 上提升了3.7%,CCF_AC 算法相比CCF 算法在KACC上提升了6.8%.
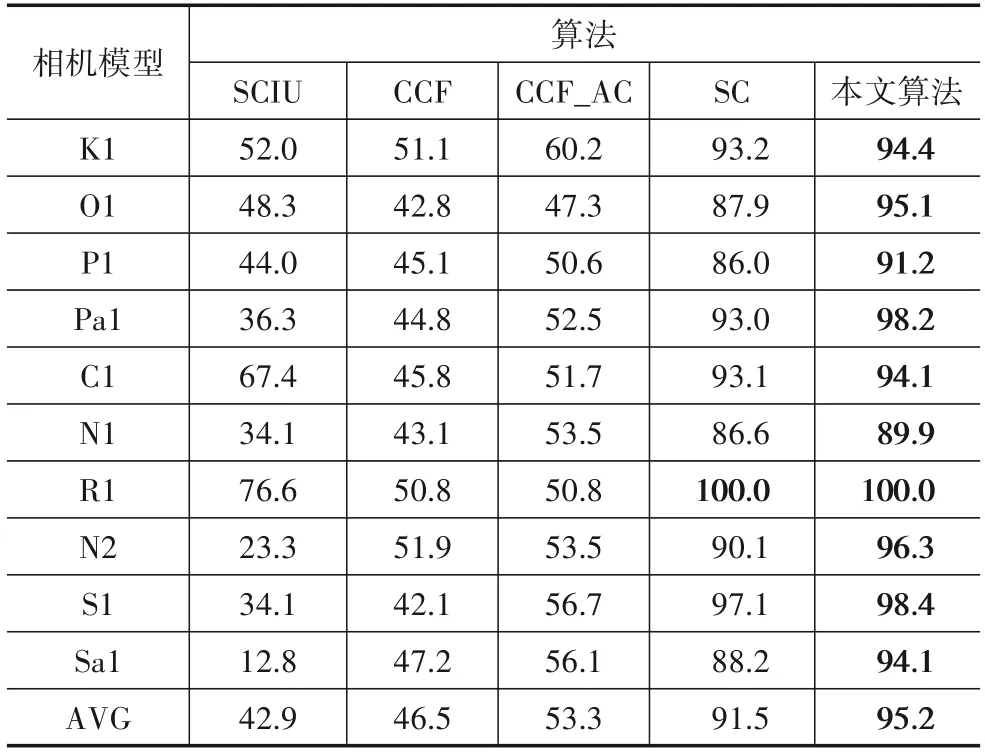
表4 Dresden已知来源相机模型识别精度 单位:%
如表5 所示,在UACC 中除了SCIU 算法的平均准确率只有84.8%之外,其他4种方法均表现优异.其中,CCF_AC 算法以97.1%获得最高的平均未知来源相机识别准确率,本文算法也达到了96.1%的准确率,接下来是CCF 算法(95.8%)和SC 算法(95.3%).虽然在未知来源相机模型平均准确率上CCF_AC 算法表现最为突出,却付出了KACC过低(53.3%)的代价.
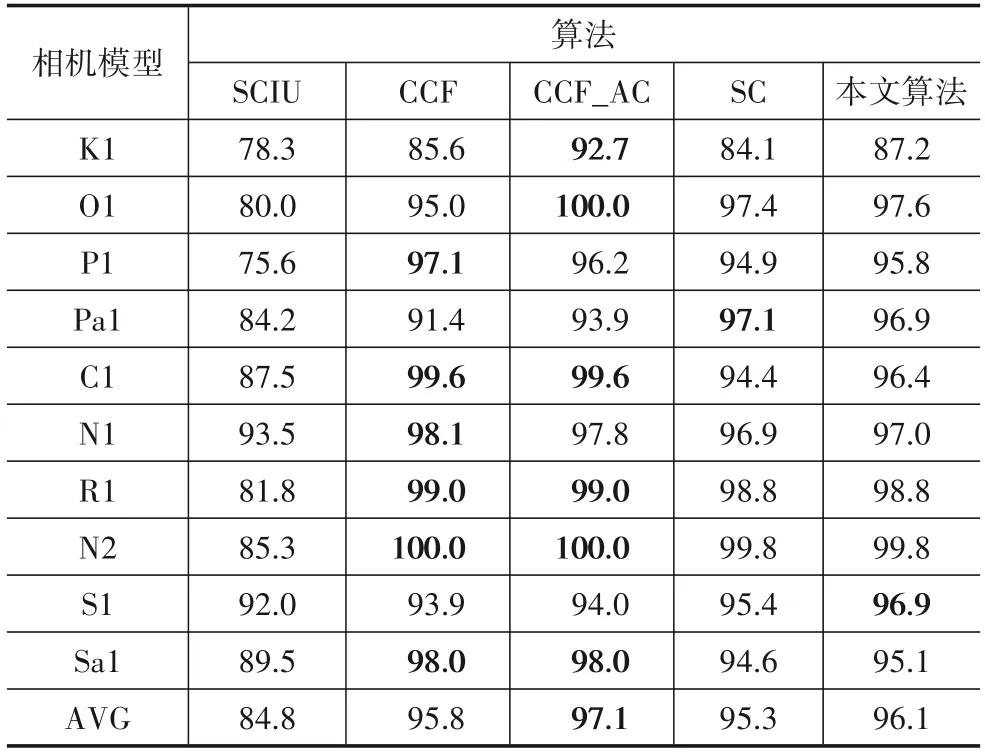
表5 Dresden未知来源相机模型识别精度 单位:%
表6 展示了5 种算法在Dresden 数据集上的整体相机模型识别精度,总体来看本文算法表现最佳.由于对于特征空间包络细节的刻画,本文算法可以使得分类模型在拒绝未知来源相机模型的同时,增加已知来源相机模型的识别准确度,从而使得OACC 取得更好的效果.5 种算法的相机模型识别能力按照递减顺序排列如下:本文算法、SC 算法、CCF_AC 算法、CCF 算法以及SCIU 算法,其平均整体相机模型识别精度分别为96.1%,95.1%,92.8%,91.0%以及80.9%.
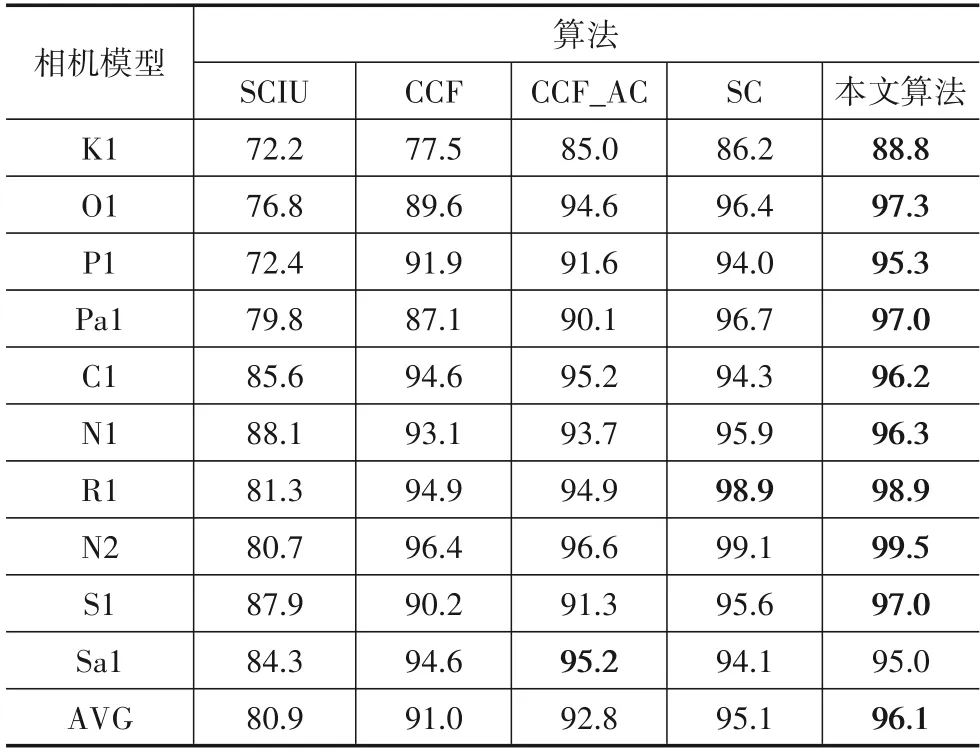
表6 Dresden整体相机模型识别精度 单位:%
表7、表8和表9 分别展示了5 种算法在SOCRatES数据集上的KACC,UACC 以及OACC 的情况.其中,本文算法、SC 算法以及CCF_AC 算法、CCF 算法之间重合的点较Dresden 数据集上的情况明显增多.这是由于SOCRatES 数据集的训练样本数量相对较少,从而导致本文算法由于其自适应的特点选择聚类子类个数为1,因此两组自对比实验由于聚类子类个数的相同导致实验结果的一致.由此可见,在数据集中训练样本数量差别较大时,本文算法由于自适应性而更为灵活.
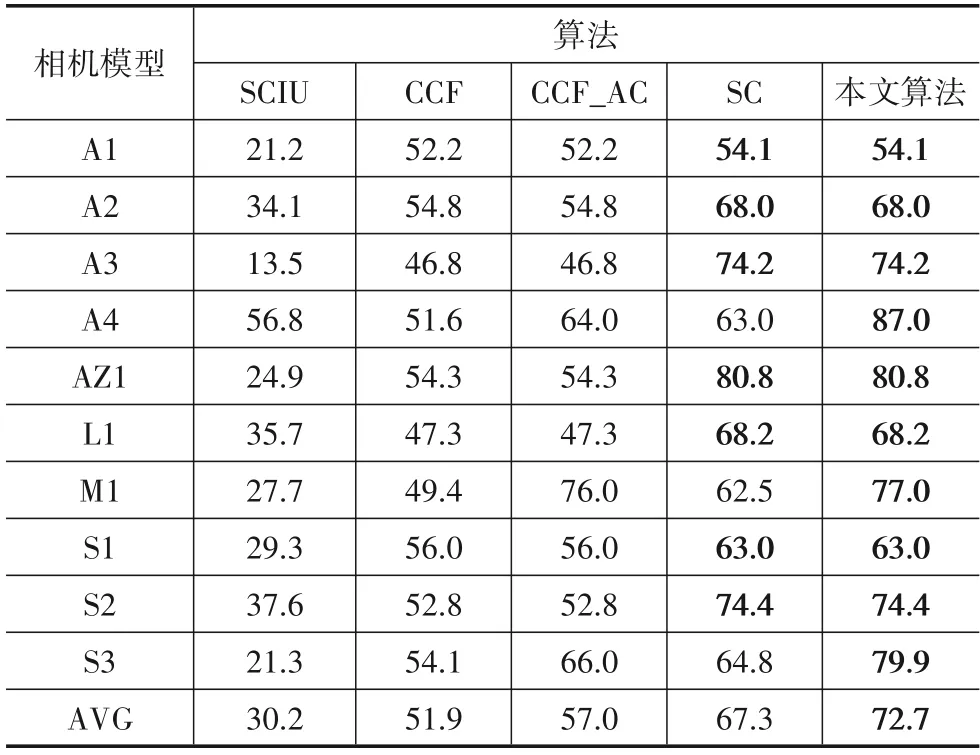
表7 SOCRatES已知来源相机模型识别精度 单位:%

表8 SOCRatES未知来源相机模型识别精度 单位:%
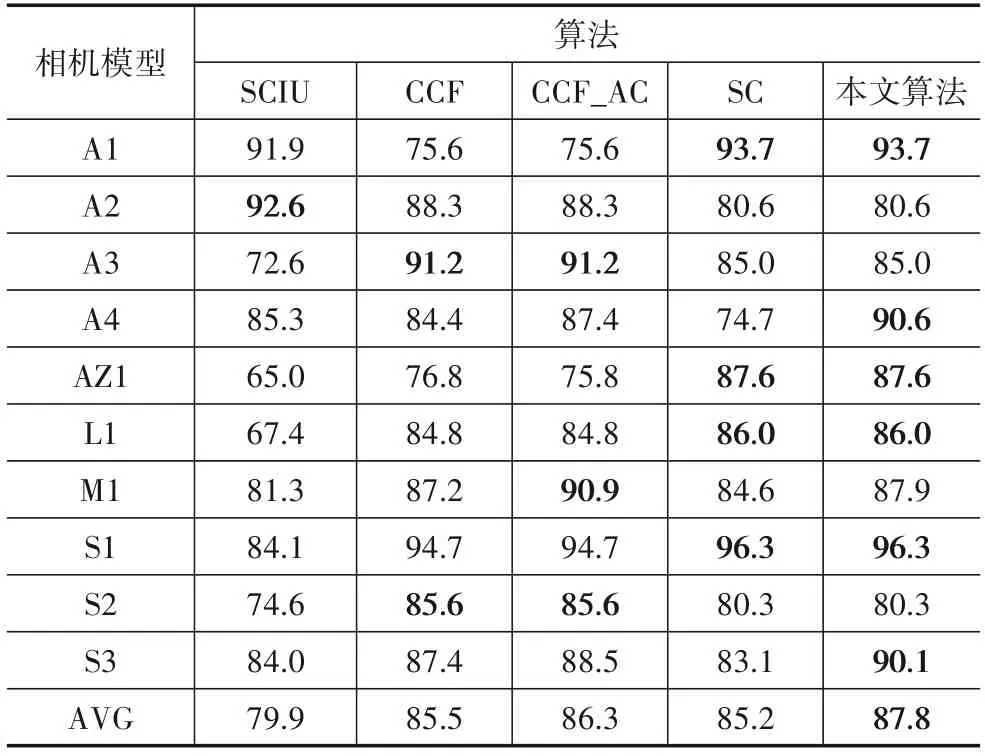
表9 SOCRatES整体相机模型识别精度 单位:%
通过与表4、表5和表6 的逐一对比发现,5 种算法在SOCRatES数据集上的识别准确度均有所下降.分析可能有以下两个原因:(1)由于SOCRatES 数据集的训练样本数量相比Dresden 数据集有所下降,训练样本的减小对分类器的造成的负面影响导致KACC,UACC 以及OACC均有所降低;(2)由于SOCRatES数据集为手机图像样本数据集,其图像特征相比相机拍摄的图像是否含有其他特质还需进一步挖掘.
综上所述,本文算法在Dresden 数据集以及SOCRatES 数据集上的表现均优于其他几种对比方法.在Dresden 数据集上的KACC 高达95.2%,相比SCIU 算法和CCF算法分别提升了49.3%,48.7%,与此同时平均UACC 与OACC 也能超过95%.在SOCRatES 数据集 上的KACC 为72.7%,相比SCIU 算法和CCF 算法分别提升了42.5%,20.8%,与此同时平均UACC 与OACC 均超过其他已有对比方法,达到89.5%,87.8%.
4.4 与深度学习方法对比
本节主要展示本文算法与MS 算法的对比实验以及结果分析.MS 算法首先使用一个基于卷积神经网络的特征提取器为图像提取特征,接下来学习了一种相似性度量方法,将这些特征对映射到与每个已知相机模型相关的分数上,最后以该分数作为判断两幅图像是否属于同一源相机模型的标准.由于该方法只能确定两个输入图像之间的关系,为了体现实验的公平性特此设置两组实验:
(1)已知与已知(Known vs.Known):测试输入的两组图像均来自已知来源的相机模型;
(2)已知与未知(Known vs.Unknown):测试输入的两组图像一组来自已知来源的相机模型,另一组来自未知来源的相机模型.
在Dresden 数据集上选择K1,O1,P1,Pa1和C1 作为已知来源相机模型,N1,R1,N2,S1和Sa1作为未知来源相机模型;在SOCRatES数据集上选择A1,A2,A3,A4和AZ1 作为已知来源相机模型,L1,M1,S1,S2和S3 作为未知来源相机模型.随机抽取每一类相机模型中的30%图像作为测试集(包含5 类已知来源相机模型和5类未知来源相机模型).
如图4和图5 所示,绿色底纹表示已知来源相机模型缩写,蓝色底纹表示未知来源相机模型缩写,图中的数据为MS 算法和本文算法的整体分类准确率,浅色底纹表示MS 算法,深色底纹表示本文算法,较高者用黑色加粗字体表示.其中,图4 为Dresden 数据集下的整体分类准确率对比.在“已知对已知”的实验上,本文算法的平均准确率高出MS算法5.1%,在“已知对未知”实验上本文算法的平均准确率高达96.1%,而MS 算法只有86.7%.在图5 所示的SOCRatES 数据集上也有类似的情况发生,在“已知对已知”的实验上,本文算法的平均准确率高出MS 算法7.3%,在“已知对未知”实验上,本文算法的平均准确率高出MS方法2.1%.
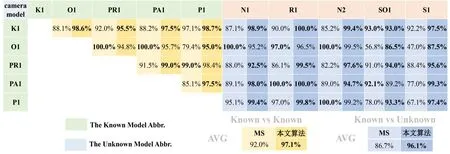
图4 Dresden相机模型识别整体准确率对比
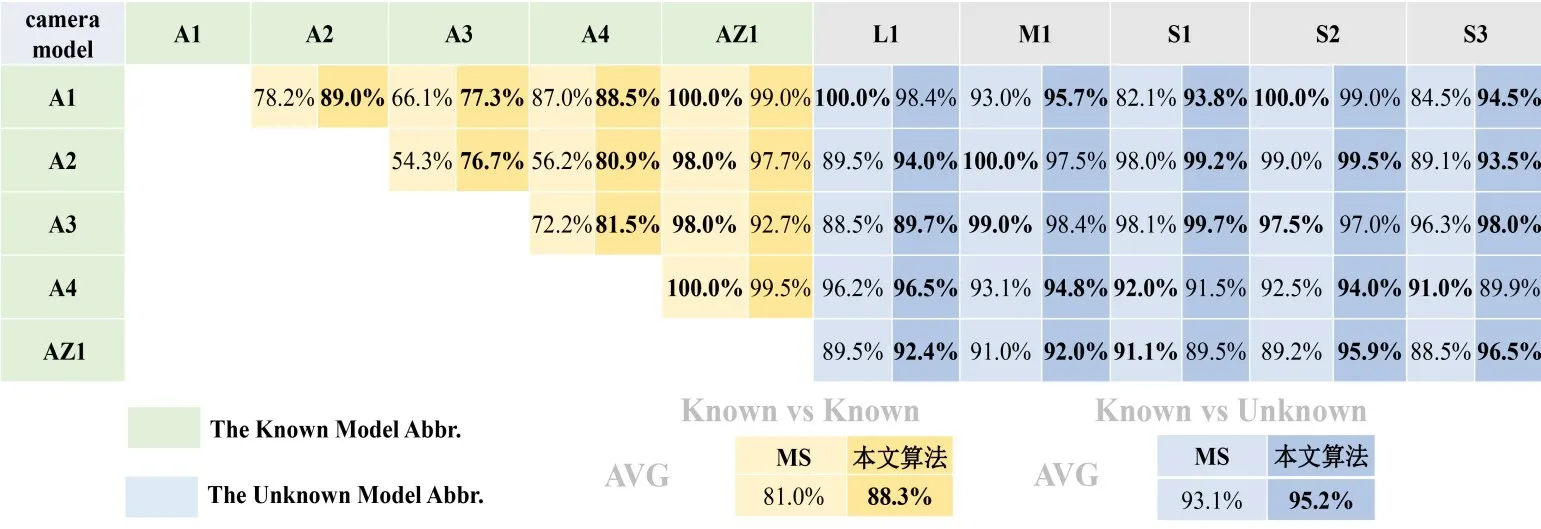
图5 SOCRatES相机模型识别整体准确率对比
图6所示为Dresden数据集中相机模型识别整体准确率分布.虽然在35 组实验中MS 算法有6 组达到了100.0%的识别准确率,而本文算法只有2 组.但是,准确率在90.0%~99.9%区间内的实验中本文算法有30组,而MS 算法只有12 组.且本文算法中最低的实验准确率为86.5%,而MS 算法有7 次实验的识别准确率均低于85.0%,其中MS 算法识别准确率最低的一组实验中只达到了47.0%.可见,本文算法的鲁棒性更强.相似地,如图7 所示为SOCRatES 数据集中相机模型识别整体准确率分布.在35 组实验中,本文算法有26 组的识别整体准确率达到90.0%~99.9%区间,相比MS 算法具有更强的鲁棒性.

图6 Dresden相机模型识别整体准确率分布

图7 SOCRatES相机模型识别整体准确率分布
除此之外,本文算法在数据集更新时只需要单独训练新加入的新型相机模型的数据,而无需联合所有数据库中的相机模型数据重新训练,因此具有弹性的模型扩展能力.
4.5 时间复杂度对比
表10和表11 分别展示了本文算法与其他对比算法在Dresden 以及SOCRatES 数据集上的时间消耗对比(由于MS 算法属于深度学习算法,而深度学习算法需要较长的训练时间,因此其时间复杂度远高于以SVM为代表的传统方法,为了体现公平性只讨论了使用预训练特征的情况下本文算法与其他4 种使用以SVM 为代表的对比算法的时间复杂度情况).所有实验的运行环境为AMD Ryzen 7-3750H 2.3 GHz 处理器,8 GB 内存,64位Windows10操作系统.
如表10和表11 所示,本文算法在Dresden和SOCRatES数据集上平均时间复杂度分别为8.3 s和8.8 s,而SCIU 算法的时间消耗分别达到了14 725.4 s和8 866.4 s.其原因为SCIU 算法内部使用了K 近邻算法,K近邻算法由于需要对每一个待分类的样本计算它到全体已知样本的距离,才能求得它的K 个最近邻点,因此计算量较大,从而消耗的时间较多.除此之外,本文算法在相机模型K1,O1和P1上相较于自对比试验SC算法所消耗时间更少,而其他相机型号下则SC算法所消耗时间更少.这是因为相机模型K1,O1和P1 所含训练样本较多,而数据聚类处理后对于每个子数据集来说构建超曲面包络所消耗的时间成本更低,而随着训练样本数量的减小,这种优势则逐渐消失,此时由于数据聚类所耗费的时间成本则不容忽视.而在表11中,由于所有相机模型的训练样本相同,则没有出现表10中的情况.综上所述,相比其他方法,本文算法在时间成本上的优势明显.

表10 Dresden时间复杂度对比 单位:s
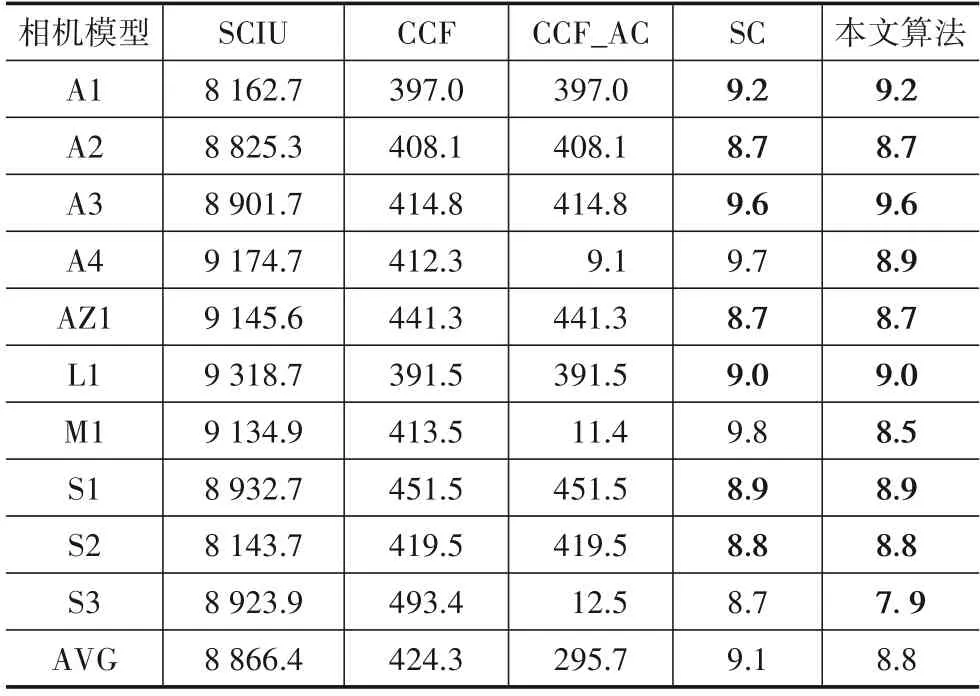
表11 SOCRatES时间复杂度对比 单位:s
5 结束语
开放环境下的数字图像来源检测是数字图像取证领域极具挑战性和现实意义的问题之一,本文提出了一种开放环境下聚类包络优化的相机来源取证方法以解决开放环境下的相机模型来源检测问题.首先通过手肘法得到每一类相机数据的聚类个数,并以该聚类数为参照进行k-means 聚类;然后将得到的相机模型子类数据分别进行支持向量数据描述以刻画其子包络,并根据所属相机模型类别将子包络合成一个更具细节特征的特征包络;最后通过判决法则将来自未知相机模型的图像排除,并对判断为已知来源的图像分类溯源,实现开放环境下的相机来源鉴别.
为了说明本算法的有效性,本文在数字图像来源鉴别领域著名的Dresden 数据集以及SOCRatES 数据集上进行了大量实验,并计算了KACC,UACC和OACC 三个技术指标.通过分析大量实验结果可以看出,相比现有的开放环境下相机模型来源鉴别方法,本文提出的算法在多个指标上均具有优越性,尤其在已知来源相机召回率以及时间成本上占据显著优势.其次,本文提出的基于手肘法聚类的特征空间包络优化方法或为单类别异常点检测提供一种新的技术手段.除此之外,本文提出的算法在数据集增添新类别时只需要单独训练该类别,相对已有方法在数据更新方面具有更强的扩展性.
由于缺少未知来源相机模型数量及性质的信息,本文算法将未知来源相机模型拍摄的图像识别出后,不能将未知来源的相机模型进行分类,这或将成为未来工作的研究方向.
