基于语料库的《故乡》三个日译本的计量考察
2022-09-17陈昌柏
◎胥 芮 陈昌柏
(山东科技大学外国语学院 山东 青岛 266000)
《故乡》是鲁迅先生1921年发表在《新青年》杂志上的一部短篇小说。不仅在国内影响巨大,也受到了日韩广大译者和读者的关注。日译版《故乡》最早于1927年10月被日本《大调和》杂志刊行,目前可知《故乡》日语译本数量多达14本。值得一提的是,竹内好的《故乡》更是被收录在初中国语教科书中,成为众多译本的范本。本文将井上红梅、佐藤春夫、竹内好三位译者的《故乡》译本,建立观察语料库,对译本进行计量分析,同时选取了同时期的太宰治《姥捨》和宫本百合子《広場》作为参照语料,考察译文翻译共性。
一、文献回顾
(一)基于语料库的译者风格对比研究
区别于传统译本对比,以Mona Bake(2000)为代表的西方学者开始尝试用语料库语言学与翻译理论相结合的方法对译本进行比较,突出译者风格。国内基于语料库的英译本译者风格对比研究取得了丰硕成果。(黄立波、朱志瑜2012;李德凤、贺文照、侯林平2018)黄立波、朱志瑜(2012)指出了Mona Bake在译者风格研究方法论上的不足。对比葛浩文和戴乃迭的翻译作品发现仅从标准类符形符比与平均句长和报道动词say的形态频率分布方面难以考察二者的翻译风格,并指出翻译风格的考察可以从以源语为规范的源语型译者风格和以目标语为规范的目的语译者风格两方面进行。李德凤、贺文照、侯林平(2018)采用同源多译类比语料库将蓝诗玲英译的鲁迅小说与王际真、杨宪益、及莱尔的译本进行对法,考察其译者风格。发现蓝译本用词丰富且典雅;相对于原文删节现象明显;报道动词said后连接词that隐化现象明显。在此基础上继续分析了蓝译朱文的《我爱美元》译本,证明了上述结论。
近年来,基于语料库的译者风格对比研究作为一种新的研究范式慢慢渗透到日语译本研究之中。程(2013)利用中日对比语料库比较了《雪国》三个译本,并指出与其他两位男性译者相比高慧琴女性译者在平均句长、性别词汇、歧视词汇等方面呈现出微弱的女性主义意识。王(2020)以村上知行和驹田信二《水浒传》译本为研究对象从词汇、句法、语篇三方面定量分析结合例句验证分析译者风格差异。发现驹田译本阅读难度较大但尽可能地保持了原作风格,村上译本句子较简短容易理解,但是有省略现象,不能很好地传达原文。总体来说,与英语学界相比国内日语界对基于语料库的译者风格对比研究关注度仍有欠缺。
(二)《故乡》相关的翻译研究
《故乡》的日译版众多,传统的译本对比研究主要侧重于从翻译策略角度对《故乡》译本进行对比分析。马越(2013)在硕士论文中对14个《故乡》日译本的译者“隐形”与“显形”以及“归化”与“异化”的翻译策略进行了考察。刘转弟(2021)基于翻译目的论,从译者和出版方两个方面探讨竹内好与藤井省三《故乡》译本的翻译目的,在此基础上运用文本分析法对比两译本的翻译策略并对译本的交际效果进行了考察。远藤茜(2018)对竹内好、井上红梅、丸山升的三个译本进行对比,发现三位译者对原文“紫色的圆脸”“茫然”等词持有不同理解,并指出教材中收录的竹内好译本存在误译,在授课实践中,教师要根据原文意思选择正确的翻译进行讲解。先行研究关于《故乡》的日译本对照研究多着眼于翻译策略,重点关注两种语言间的转换问题。本文通过自建小型语料库对《故乡》的三个日译版译作进行定量分析, 通过数据考察译者的翻译风格并分析译本的翻译质量。
二、语料选取与加工
20世纪30年代以来,日本文坛掀起一股翻译、评论鲁迅文学作品的高潮。
井上红梅、竹内好、佐藤春夫在这一时期翻译了大量的鲁迅文学作品,成为鲁迅作品日译的代表。本文选取这三位译者的《故乡》译本,清洗语料后通过“Comainu-0.72”软件对译文进行长单位解析后分词制作单词表,建立小型观察语料库。运用语料库检索软件Wordsmith Tools(6.0)对词表进行处理考察译本词汇、句法和语篇的翻译特征。
三、计量参数的选定
本文参考英译本译者风格研究方法论(黄立波、朱志瑜2012;李德凤、贺文照、侯林平2018)和安本美典(1994)、村上证胜(1994)等日本学者在文体计量研究方面积累的大量经验,结合语料库翻译学和计量文体学的研究方法,最终确定了本文拟考察的各计量参数(平均句长、标准型符类符比、词汇密度、品词使用率、MVR值等),在数据分析的基础上对三个译本进行定性分析。
四、词汇特征
(一)词汇丰富度
Loviosa(1998)指出类符型符比(TTR)可以作为衡量作者词汇量与文本词汇丰富度的指标,类符型符比越高,词汇量越大,词汇丰富度越高。但是,随着型符数量的不断增加,类符数量没有等量增加的情况下TTR值往往无法正确反映两个文本的词汇丰富差异。因此我们引入标准符型符比(STTR)这一指标。标准符型符比(STTR)即文本中每一千字的类符(type)与型符(token)的比例,不受文本总字数的干扰,使测量结果更加客观。本文选取标准符型符比(STTR)作为衡量译本词汇丰富程度的指标,通过语料库检索工具wordsmith(6.0)对三个译本进行检测,结果如下表所示。
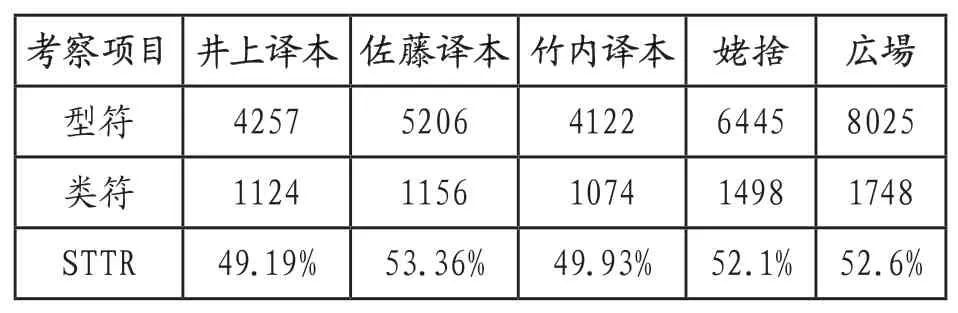
表1 :词汇特征指标对比
数据分析结果显示,井上译本和竹内译本STTR值明显低于参照语料,佐藤译本STTR值在五个文本中最高,说明佐藤译本在词汇选用上重复率低,用词丰富。此外值得注意的是,佐藤译本在型符数量上高出其他两个译本近1000余词。观察译文可以看出佐藤译本在文化负载词的翻译上区别于其他两位译者,采用了直译的翻译策略,且为了缩小目的语读者与源语之间的文化差异在括号内增加了一些细致说明和解释,这在一定程度上方便读者理解,同时也增加了译文的词汇量。
(二)品词使用率与词汇密度
日本学者在进行文体计量分析时,常使用品词使用率这一指标。通过“Comainu-0.72”形态素解析器对各文本进行品词分类。其中值得注意的是代名词使用率的差异,我们对其使用数量和使用率进行统计,绘制成下列表格。
观察表3可知翻译文本的代名词使用率均高于参照语料。我们又对原文《故乡》代名词使用数量进行统计发现原文中人称代词使用数量为301次,这说明翻译文本人称代词较高使用率受其汉语原文本影响。且相较于汉语原文三译本均呈现出人称代词隐化的翻译共性。其中人称代词使用率最低的为竹内译本。我们可以推测三译本将原文中的人称代词更多的转化到语境之中,进行了隐化处理,使得译本中人称代词的使用频率大幅度下降。

表3 :平均句长对比
(三)名词比率与MVR值
桦岛忠夫、寿岳章子(1965)提出用MVR值和名词比率的比值来考察文体特征,并指出描写性文章名词占比小,概括性性文章名词比率大。同时MVR值越大,文章倾向于状况描写;越小则倾向于动作描写。通过表2品词使用率分别计算出五个文本的名词比率与MVR值,制作了图1,其中横轴表示名词比率,纵轴表示MVR值。
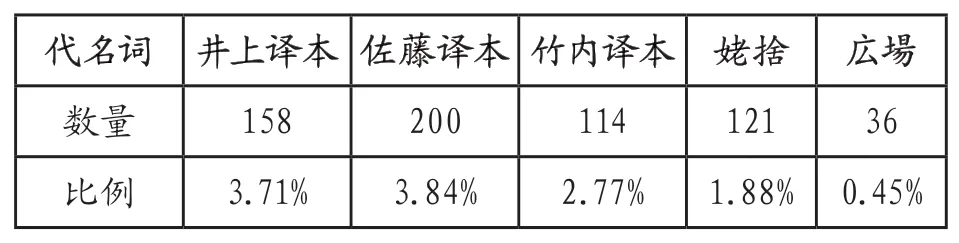
表2 :代名词使用率对比
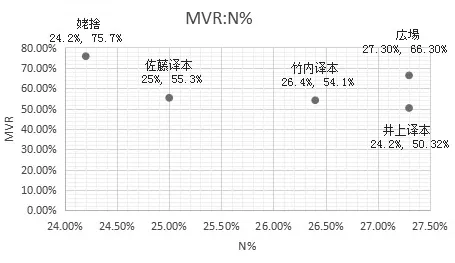
图1 :文本名词比率与MVR值分布
由图1可知,参照语料与翻译译本在名词使用率上差距不大,但在MVR值上二者相差甚远。相比于参照语料,三部译本MVR值更低,这说明翻译小说在翻译过程中会对原文进行简化,省略掉一些修饰成分。
五、句法层面特征
平均句长是指文本中平均每句含有的词数,即文本形符数和句子个数之间的比值。文本的平均句长是反映译本难易程度的总要指标。句子越长,文本阅读难度会随之增大。要对源自同一文本的各译本进行对比,对各类句式的使用和平均句长的考察尤为重要。本文通过软件wordsmith(6.0)的词表功能,得到三译本的平均词长,并将文本中的句号、问号、感叹号作为句子的切分记号,对文本中各句式的使用以及总句数进行考察,得到下表。
统计结果表明,三部翻译文本的平均句长位于两部参照语料之间,且都低于《故乡》原文。黄立波(2018)指出译文相对于原文的词数或者句子数被作为显化的一个重要指标。三译本无论是总词数还是总句数都要超过原文,这符合翻译文本趋向显化得特征。观察三部译本,竹内译文平均句长最短,将原文长句拆分成方便读者理解的短句,句子数量增多,句式更为灵活,但一定程度上没有忠实于原文使译文中鲁迅的思考分节化。相比之下,佐藤译本更加忠实于原文句式,多用长句,一定程度上会增加译本阅读难度。
六、语篇特征
Halliday (1976)指出语篇必须具备一惯性,衔接是一个语义概念。文本可以通过语法手段(照应、省略等)和词汇手段(重述、搭配等)进行衔接。本文将从接续词和指示词的使用情况来考察三个译本的语篇特征。
正保勇(1981)指出,指示词是考察句子或文本连贯性的重要指标,日语指示词是考察文脉语义连贯度的重要形式。因此笔者对文本中使用频率较高的指示代词进行了统计。
根据表4数据可以看出,在接续词和指示词使用量上佐藤译本均为最高值,而井上译本均为最低值。我们可以推断佐藤译本语言更具备连贯性,语篇衔接度较高;而井上译本文本衔接度低,会给读者带来一定的阅读障碍。

表4 :三译本指示代词使用统计表
七、小结
本研究基于语料库的翻译研究方法,在词汇、句法、语篇层面对鲁迅《故乡》的三个日译本进行了计量分析,得出以下主要发现:
词汇层面:
佐藤译本相比较与竹内和井上译本选词更加丰富;竹内译将人称代词进行了隐化处理,转化到语境之中降低了使用率;且三译本MVR值均低于参照语料呈现出修饰词简化的翻译共性。
句法层面:
竹内译本对源语中的长句进行了简化处理,分割成小短句,平均句长明显低于其他译本,将长句拆分成短句一定程度上降低了阅读难度。佐藤译本更倾向于忠实的还原
原文句式,句式结构复杂阅读难度增加。篇章层面:
佐藤译本不论是接续词还是指示词在三个译本中使用率均为最高值,语篇衔接做得更好。而相比之下井上译本在接续词、指示代词的使用频率低,接续词种类单调,译文前后连贯性低会给读者带来一定的阅读障碍。
注释:
①据富士池优美介绍“长单位”设立的着眼点在于句法功能,是一种以辨明文本的语言特征为目的的语言单位。
②MVR值即修饰词(形容词、形容动词、副词、连体词)与动词的比值。
