故障类型增量场景下基于终身学习的轴承故障诊断方法
2022-09-16陈博戬沈长青石娟娟朱忠奎冯毅雄
陈博戬,沈长青,石娟娟,朱忠奎,冯毅雄
(1.苏州大学 轨道交通学院,江苏 苏州 215131;2.浙江大学 流体动力与机电系统国家重点实验室,杭州 310027)
故障诊断已经成为现代工业系统中不可缺少的技术[1]。近年来,基于深度学习的故障诊断方法得到了空前的发展[2-4]。基于深度学习的轴承等关键机械部件故障诊断方法往往要求各故障类型的足量数据且训练集与测试集同分布;然而,在实际应用场景中,轴承存在不同的故障模式和故障程度,即对于诊断模型而言,虽然已经学习了某些故障模式和程度的诊断知识,但仍要面临新诊断需求下存在故障类型增量,需要进一步提升模型泛化能力的问题。受限于深度神经网络自身的特点,深度故障诊断模型在学习新数据时会遗忘已学习的旧知识,即现有模型直接学习新的故障类型将导致对旧故障类型的诊断性能不佳,这种现象被称为灾难性遗忘[5];而收集所有已知故障类型的数据来重新训练模型的成本过高甚至难以实现:因此,引入终身学习来克服深度学习模型的灾难性遗忘,持续、增量地积累和迁移诊断知识,从而建立一个泛化能力更强的诊断模型。
在计算机视觉领域,已有的一些对克服灾难性遗忘的研究被称为终身学习、持续学习或增量学习[6]。文献[7]提出了增量分类器和表征学习(Incremental Classifier and Representation Learning,iCaRL),首先提出了基于典例的终身学习方法并将其与知识蒸馏[8]相结合。文献[9]将终身学习的一些方法用于小样本学习,但忽略了终身学习需解决的关键问题,即灾难性遗忘。然而,基于终身学习的故障诊断方法的研究还很少。迁移学习和元学习是与终身学习有紧密联系的学习范式[10],在故障诊断领域是热点话题:文献[11]提出了一种用于电机轴承和齿轮箱故障诊断的迁移方法,文献[12]提出了一种基于度量的元学习模型,以实现小样本的故障诊断。迁移学习、元学习和终身学习都试图通过在任务之间迁移知识来帮助目标任务学习,但迁移学习和元学习仅关注目标任务的性能,而终身学习则要求模型在所有已学习任务上都有良好的表现。基于终身学习的故障诊断方法可以不断学习新的故障类型,减少训练成本并且不断积累、丰富知识,从而提高诊断模型的可靠性和泛化能力。因此,研究基于终身学习范式的故障类型增量的故障诊断具有十分重要的意义。
本文提出了一种新的基于终身学习的轴承故障诊断方法(Lifelong Learning Based Bearing Fault Diagnosis Method,LLBFDM),用于具有故障类型增量的轴承故障诊断。LLBFDM基于一种高效、流行的终身学习方法iCaRL,为克服iCaRL存在的灾难性遗忘并解决知识保留(稳定性)和知识学习(可塑性)困境[13],本文提出了双分支自适应聚合残余网络(Dual-branch Adaptive Aggregation Residual Networks,DAARN),通过自适应聚合权重加权聚合DAARN中稳定分支和动态分支平衡模型的稳定性与可塑性,使用双级优化程序优化聚合权重和模型参数,并通过一个具有故障类型增量的轴承诊断案例验证本方法的有效性。
1 理论背景
1.1 终身学习
终身学习是通过模仿人类学习而开发的一种高效的学习模型,以实现在一系列连续的任务中持续地学习。终身学习模型可以像人类一样提取并保留在一系列训练任务中逐步出现的有效信息,并利用这些信息帮助学习新的任务。如图1所示,终身学习有2个主要问题:灾难性遗忘和稳定性-可塑性困境。

图1 终身学习中的主要问题
终身学习的过程主要包括两方面:知识迁移和知识积累。在终身学习中,学习一项新的任务相当于是对模型进行微调,这也是迁移学习中常用来迁移知识的方法。然而,单纯的微调无法积累知识,模型将失去完成先前已学习任务的能力。这种在先前已学习任务上性能突然断崖式的下降被称为灾难性遗忘。
终身学习的另一个主要问题是稳定性-可塑性困境。终身学习模型应该在克服灾难性遗忘的基础上,维持稳定性和可塑性之间的平衡,以实现对新任务敏感的同时,对旧任务的表现不产生破坏性的干扰;然而,终身学习模型很难在保持可塑性的同时实现良好的稳定性。稳定性-可塑性困境是对终身学习发展的一个新挑战。
已经提出的关于终身学习的方法可以分为三类:正则化方法、知识重放和参数隔离。这些方法通常可以组合使用以获得令人满意的性能。
1.2 问题定义

1.3 所提方法背景
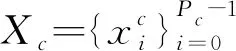
(1)
式中:Pc为类c的样本数量;F为特征提取。
假设要选取t个典例,对于d=1,…,t,典例e为
(2)
ε=(e1,e2,…,et)。
(3)
在第n个阶段,典例ε0:n-1={ε0,ε1,…,εn-1}和训练数据Dn共同训练模型Θn-1得到Θn,接着筛选典例εn。
知识蒸馏通过约束参数的更新方向以克服灾难性遗忘[15],在第n阶段,分类损失为常用的交叉熵分类损失函数,可表示为
(4)


(5)

综上,总的损失函数为
(6)
2 基于终身学习的轴承故障诊断方法
2.1 LLBFDM的终身学习过程
LLBFDM的终身学习过程分为初始阶段和n个增量阶段。LLBFDM由3个主要部分组成:数据预处理模块、特征提取器F和分类器G。在数据预处理模块中,故障的振动信号通过快速傅里叶变换(Fast Fourier Transform,FFT)转换成频域信号,然后将一维频域信号转换为二维信号。这个模块在所有阶段都是相同的,而其他2个部分在初始阶段和增量阶段是不同的。


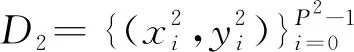

2.2 兼具稳定性和可塑性的特征提取器DAARN
DAARN基于ResNet[16]结构,ResNet广泛用于图像识别领域,由残差块组成。本方法遵循iCaRL的设置,采用ResNet-32作为LLBFDM的骨干网络。ResNet-32的结构见表1。

表1 ResNet-32的结构
在初始阶段,特征提取器F0的结构是标准的ResNet-32。由于故障类型的递增,在初始阶段得到的模型不能可靠地诊断新故障,因此在增量学习阶段采用DAARN,以获得更可靠的诊断模型。
在终身学习中,学习一个新任务相当于对前一个任务学习得到的模型进行微调。微调一般有2种: 1)对所有网络参数进行微调,称为参数级微调;2)冻结部分网络,对其余网络参数进行微调,称为部分微调。如图2a所示,以三通道卷积神经网络为例,Q为神经元数量,参数级微调更新了模型的所有参数。受文献[17]的启发,本文引入一种新的微调方式,称为神经元级微调,如图2b所示。神经元级微调冻结了模型Θ0的所有参数,并为每个神经元增加了一个新的权重参数。神经元级微调可以减少模型可学习参数的数量,从而避免过度拟合,并通过冻结初始模型的参数防止灾难性遗忘。

图2 DAARN的结构

xk=(Wk⊙βk)xk-1,
(7)
式中:⊙为哈达玛积。
如图2c所示,DAARN由2个不同的ResNet-32分支组成:一个动态分支和一个稳定分支。每个分支由3层相同类型的残差块组成,即3个动态块(橙色)或3个稳定块(蓝色)。动态块的训练为参数级微调,稳定块的训练为神经元级微调。在完成初始阶段训练后,特征提取器F0被用来初始化动态分支,并在稳定分支中冻结。
用α和β分别表示动态分支和稳定分支的可学习参数。α可以动态适应新任务,β则是软固定的,以尽可能地保留先前学习任务的知识。引入自适应聚合权重ω以平衡模型的可塑性和稳定性,ωα和ωβ分别代表动态块和稳定块的自适应聚合权重。输入的故障数据x[0]通过3个残差块层获得特征h。在第n个残差层的动态块和稳定块的特征提取可表示为
(8)
式中:W0为从初始阶段得到并冻结的神经元权重;f为单个残差块的特征提取。
第n个残差块层提取的特征可以表示为
(9)
2.3 双级优化程序

(10)
(10)式的上半部分是上层问题,下半部分是下层问题。在下层问题中,模型参数Θn由所有可用数据ε0:n-1∪Dn进行更新,即
[Θn]←[Θn]-γ1∇[Θn]Ln(Θn,ωn;ε0:n-1∪Dn),
(11)
式中:γ1为下层问题的学习率。
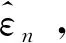
(12)
式中:γ2为上层问题的学习率。
3 试验结果及其分析
3.1 数据集描述
轮对轴承故障数据采集试验平台如图3所示,试验台大轮直径为280 mm,小轮直径为200 mm,V带传动中小带轮基准直径为95 mm,大带轮基准直径为200 mm,传动比约为2.105。采用编码器对转速信号进行测量,转轴每转一圈编码器可以发出600个脉冲。三轴加速度传感器中的x,y,z方向分别是转轴竖直方向、水平方向和轴向。用NI系统控制变频器控制电动机转速,电流传感器测量变频器电流。

图3 自制轮对轴承故障数据采集试验平台
试验轴承型号为NJ208E(外圈双挡边,内圈单挡边圆柱滚子轴承),设置直径分别为0.2,0.3,0.4 mm的故障,每种尺寸包含内圈故障、外圈故障、滚子故障、内圈+滚子故障、外圈+滚子故障、内圈+外圈故障、内圈+外圈+滚子故障7种故障位置,分别用I,O,B,IB,OB,IO,IOB表示,共21种不同的故障类型。试验转速为400 r/min,采样频率为32 768 Hz,在2.4 kN载荷下使用测得的加速度信号构建故障类型增量数据集。模型的每个诊断任务包含7种相同故障尺寸的故障类型,如I0.2,B0.2,O0.2,IB0.2,OB0.2,IO0.2,IOB0.2,作为初始诊断任务;而I0.3,B0.3,O0.3,IB0.3,OB0.3,IO0.3,IOB0.3作为第1个增量诊断任务。每种故障类型由100个训练样本,100个测试样本。总计3个任务,每次学习1个任务。
3.2 对比方法
目前,基于终身学习的诊断方法的研究十分稀少,通过比较相关的非终身学习方法、最流行的终身学习方法和消融试验验证LLBFDM的有效性及优越性,所有方法均使用ResNet-32作为骨干网络,详细情况见表2:R1是用新故障类型的数据与所有已知故障类型的数据一起训练模型,通常用于多任务学习,训练成本最高但结果也最理想,是终身学习表现的上界;R2是对整个深度神经网络进行微调,以说明灾难性遗忘;R3冻结了初始阶段训练得到的特征提取器,仅对分类器进行微调;M1是LLBFDM的基础,iCaRL并没有使用全连接层作为分类器,而是使用了最近邻分类器;M2引入了一系列的方法,如余弦归一化分类器(Learning Unified Classifier Incrementally via Rebalancing,LUCIR),以克服灾难性遗忘[18];A1,A2用于验证双分支结构的必要性和重要性;A3用于验证自适应聚合权重的有效性。

表2 对比方法
3.3 试验实施细节
LLBFMD的超参数见表3:每个学习阶段的学习率γ1初始化为0.1,学习率衰减因子设置为0.1,在第80和120个迭代时分别降低到0.01和0.001;学习率γ2也通过学习率衰减因子随迭代次数下降;自适应聚合权重ωα和ωβ被约束为ωα+ωβ=1;在使用含有温度参数K的知识蒸馏损失函数的方法中,K被设置为2。在M1和M2中,未描述的参数被设置为默认值,超参数的设置在所有试验中均相同。

表3 LLBFMD超参数设置
每个训练样本有1 024个采样点,经过数据预处理模块后被重塑为3×32×32。每个故障类型的典例数固定为10个,典例总数随着诊断任务的增加而增加。每个方法都进行5次重复试验,并给出平均准确率和标准差。
3.4 结果分析
本试验旨在验证LLBFDM的有效性,为比较每种方法在克服灾难性遗忘和解决稳定性-可塑性困境方面的能力,在完成每个阶段的训练后,分别给出T0和所有已学习任务的诊断精度,结果见表4和表5。

表4 各方法在任务T0上的诊断精度

表5 各方法在所有已学习任务上的诊断精度
各方法在任务T0上的平均诊断精度及标准差可以反映出其克服灾难性遗忘的能力,由表4可知:R1的训练结果最理想;R2体现了神经网络在完成新任务的训练而不采取任何行动后会发生的灾难性遗忘现象;R3表明即使冻结了特征提取器,诊断模型在完成新任务学习后仍会有一定程度的知识遗忘;随着学习阶段的增加,M1和M2在T0的诊断精度不断下降,但与R2相比仍有较高的诊断精度,表明知识蒸馏与典例可以防止模型的灾难性遗忘;与M1,M2和A1,A2,A3相比,LLBFDM对T0的诊断在每个阶段都取得了最高的精度,也是最接近R1的结果,克服灾难性遗忘的能力令人满意,保持了诊断模型的可靠性。
各方法在所有已学习任务上的平均诊断精度及标准差可以反映出其解决稳定性-可塑性困境的能力,由表5可知:R1是诊断性能的上限;R2由于灾难性遗忘而性能较差,其完成第1个增量阶段后在所有学习任务T0:1上的混淆矩阵如图4所示,对整个网络进行参数级微调将导致对旧任务T0的灾难性遗忘,说明深度神经网络缺乏有效保留旧任务记忆的能力;R3的结果说明初始阶段得到的特征提取器不适用于新任务的故障特征提取; M1和M2在第1阶段和第2阶段的准确率持续下降,无法维持可靠的诊断精度,这是由于未考虑稳定性-可塑性困境,不能维持可塑性和稳定性的良好平衡以保持可靠的诊断精度;A1,A2分别用于验证稳定分支和动态分支的性能,由于稳定分支的可学习参数比动态分支少,A1的诊断精度在2个增量阶段的表现都比A2差;在A3中将2个聚合权重固定为0.5,由于缺乏聚合权重的更新来平衡模型的可塑性和稳定性,也无法维持可靠的诊断性能;在新任务的训练中,动态分支承担着绝大部分学习新知识的责任,而稳定分支则保留了任务T0的知识并慢慢学习新的故障类型,采用聚合权重平衡这2个分支并使用双层优化程序更新聚合权重和模型参数,使LLBFDM在每个阶段都有令人满意的表现,结果表明LLBFDM能够克服灾难性遗忘并解决稳定性-可塑性的困境,诊断精度是除R1外最高的,且标准差也低于除R1以外的所有方法,说明LLBFDM的鲁棒性更强。
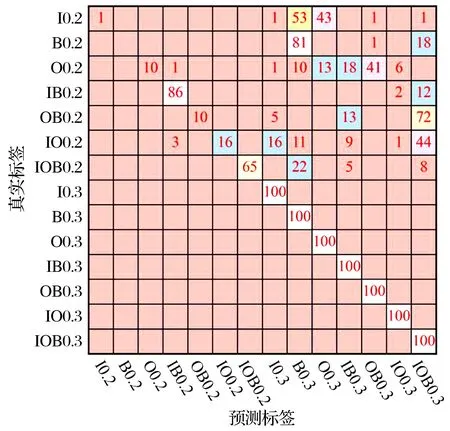
图4 增量阶段1中R2在所有已学习任务的混淆矩阵
4 结束语
在终身学习范式下,本文提出了LLBFDM用于具有故障类型增量的轴承故障诊断。作为LLBFDM的核心,DAARN克服了灾难性遗忘,通过使用稳定分支和动态分支并结合自适应聚合权重对其进行平衡,解决了终身学习中的稳定性-可塑性困境。在具有故障类型增量的轴承数据集上进行测试,LLBFDM的有效性得到了验证。试验结果显示,与其他终身学习方法和消融试验相比,LLBFDM具有更好的诊断精度和更强的鲁棒性。
LLBFDM考虑了稳定性-可塑性困境,并使用了典例等方法克服灾难性遗忘,但在进行新任务的训练时忽视了旧故障类型与新故障类型之间样本数量的不平衡问题,会造成分类器的权重偏向于新类,从而加剧灾难性遗忘。在后续工作中,将对具有修正类偏置能力的分类器进行研究,并进一步探索小样本故障类型增量下终身学习诊断模型的建立。
