基于迁移学习的装备领域词向量训练方法研究
2022-09-16祖月芳凌海风
祖月芳,凌海风
(1.陆军工程大学野战工程学院,南京 210004;2.解放军96761 部队,河南 三门峡 472100)
0 引言
分布式语义表示方法之所以受到青睐,是源于2013 年Tomas Mikolov 等推出了一款用于获取word vector 的工具包Word2vec,它是在深度学习的基础上获取的一种词向量的分布式表达。腾讯AI Lab 开源了包含800 多万中文词汇的公开词向量,其在覆盖率、新鲜度及准确性上大幅提高,在自然语言处理领域带来了显著的效能提升。虽然腾讯词向量广受大众追捧,但在装备领域其对一些专业术语涵盖不是很全面,这导致在运用腾讯词向量表示一些特定专业领域的文本时受限。基于这样的情况,本文结合腾讯词向量的优势,基于迁移学习的思想以腾讯词向量作为初始向量进行了训练,获得了装备领域的词向量。
1 基于Gensim 实现装备领域词向量的增量训练
1.1 词向量训练的方法
随着自然语言处理技术的发展,可以进行词向量训练的模型有很多种,比如目前使用较多的Word2vec 模型和Bert 模型。本文在进行装备领域词向量训练时选择了Word2vec 模型,舍弃了现在更火的Bert 模型;原因是在训练词向量是Bert 模型的基本单位是字,而Word2vec 模型的基本单位是词语,结合装备领域相关专业术语的特点,使用以词为基本单位的Word2vec 模型更符合本文的需求。其中,gensim 包提供了Word2vec 的python 接口。
Word2vec 主要有CBOW 模型(Continuous Bagof-Words Model) 和Skip-gram 模 型(Continuous Skip-gram Model)两个词嵌入模型。两个模型都包含3 层:输入层、投影层和输出层。如图1 所示,CBOW 模型是在已知当前词ω的上下文ω,ω,ω,ω的前提下预测当前词ω,训练完成后,每个词都会作为中心词把周围词的词向量进行调整来获得所有词的词向量。
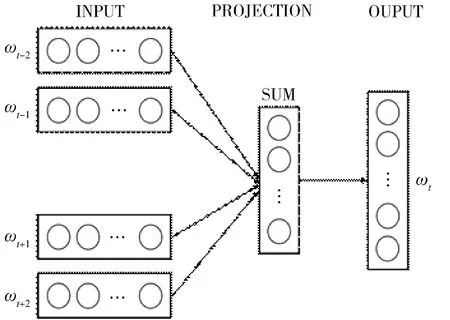
图1 CBOW 模型
Skip-gram 模型与之相反,它是在已知当前词ω的前提下,预测其上下文ω,ω,ω,ω,所有文本遍历完毕后,也就得到了文本所有词的词向量,如图2 所示。

图2 Skip-gram 模型
可以看出,CBOW 模型预测行为的次数跟整个文本的词数几乎是相等的,复杂度大概是O(V);而Skip-gram 进行预测的次数是要多余CBOW 的,因为每个词作为中心词时,都要使用周围词预测一次。这样相当于比CBOW 方法多进行了K 词(假设K 为窗口大小),因此,时间的复杂度为O(KV)。但是在Skip-gram 中每个词都要受到周围词的影响,每个词作为中心词时都要进行K 次预测、调整,因此,对于装备领域文本数据量不大、相关专业词汇出现次数较少的情况,本文选择使用Skip-gram模型进行词向量的训练。
1.2 基于腾讯词向量实现装备领域的词向量增量训练
词向量模型的增量式训练方法,通过对新增文本中出现的新词进行初始化更新,和基于历史词表的采样对词向量模型进行动态更新,完成向量模型对新增文本text 进行增量式学习。这种方法能够避免对历史数据进行重复性学习,大幅减少计算复杂度,保持了较高的学习率。由于各个领域都有一些专业术语,要保证一次或几次训练的词向量能涵盖所有的领域几乎是不可能的。不同领域的语料库中的数据是动态变化的,为了避免在海量数据情况下的重复学习,对装备领域的词向量进行增量训练是十分必要的。
本文训练词向量的目的主要是应用于装备故障诊断领域。如图3 所示,通过利用对外公开的《解放军报》、军事类百科全书、机械领域词典以及装备领域故障数据库等海量的数据文件,以装备和与军事领域相关数据作为数据集,基于迁移学习的思想采用预训练好的16 G 腾讯词向量作为初始向量,使用Word2vec 词嵌入模型在词向量数据集上进行装备领域词向量的增量训练。
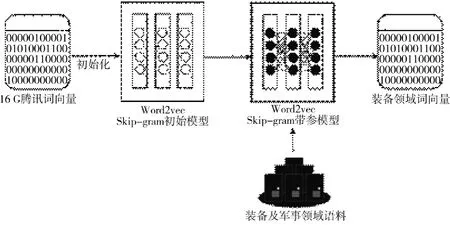
图3 word2vec 模型的增量训练过程
2 实验数据
2.1 数据集介绍
本文使用的数据集包括开源的数据集以及装备和军事领域相关的语料数据。其中,开源数据集是由腾讯AI 实验室公开的包含800 多万中文词汇的一个大规模、高质量的中文词向量数据集;装备及军事领域相关的语料库是由收集整理的66.6 M军事类百科全书、393 M 中国大百科全书、在网页爬取的从2016 年1 月至2021 年5 月1 日的435 M《解放军报》的新闻数据,以及在装备管理信息系统、装备履历书、装备维修手册以及大项任务中出现的55 936 条故障数据组成的。
2.2 数据预处理
由于腾讯词向量是在下载后不联网的情况下使用,所以装备领域词向量的训练不存在涉密问题。在开始进行词向量训练之前,需要先对收集的数据进行预处理工作。首先,收集语料数据。语料库主要有两部分来源,一是利用正则匹配的方法从《解放军报》和军事类百科全书等网页爬取最新语料的内容并除去两端的<contect>标签;二是收集整理在装备管理信息系统、装备履历书、装备维修手册以及大项任务中存在的故障数据。其次,对语料数据进行清洗。主要分为两步:一是要对一些多余的空行、符号以及无关紧要的字词进行处理;另外还要对文章中包含的如日期、长串数字以及一些英文名称等进行泛化处理。通过将语料库中连续的数字和英文字母替换成<NUM>和<ENG>来减少文本的噪声,提高训练速度。二是分词。中文和英文的语言特点不同,英文句子中的单词之间是通过空格来分开的,不同于英文的是,中文句子中没有词的界限,而word2vec 的工作本身是以词语为基础的,这就需要先对中文语料做分词处理工作。本文采用了开源的jieba 中文分词工具,它是基于Unigram 和隐马尔可夫(HMM)的分词模型,具有分词准确率高、模型简单易用的特点,还可以依据相关领域的特征,通过jieba 分词载入用户自定义字典,使得用户自定义的词典中含有的词语不被分开,从而可以获得装备或军事领域所需的分词效果。
3 实验及结果分析
3.1 参数设置
使用Word2Vec 中的Skip-gram 方法对装备领域词向量进行训练,需要对词向量维度(size),窗口大小(window),min-count 等几个可能影响训练速度和质量的参数进行设置。其中,词向量维度]是Word2Vec 将单词映射到的N 维空间的维数,N就是说用N 个特征来表示这个词向量。设定较大的值需要更多的训练数据,但可以产生更准确的模型。合理的值在10~1 000 之间,默认值是100。min-count 表示最低词频训练阈值,这个一般根据语料库的大小进行设置,通常设置min-count=5。窗口大小是指词向量训练时上下文扫描的窗口大小,一般为防止增加噪音信息不宜设置过长,窗口是5 就是考虑前5 个词和后5 个词。本节根据语料特点以及在词向量训练中实验运行的内存、运算耗时等情况,将min-count 和window 的值均设定为5,词向量的维度经过实验对比设定为200 更能满足要求。
3.2 评价指标
当前词向量的评价方式往往可以分为两大类,包括定量评价和定性评价。定量评价是通过一些实际任务的指标来评价;定性评价是通过一些可视化的方法进行直观上的评估。本节训练的装备领域词向量将结合定量分析和定性分析两种方法进行评价。
词向量的定量评价常用到的两种方法是类比评价和相似度评价。类比评价是一种较为经典的词向量评价方法,是假设已知一对词语a 和b 的关系,同时给定另一个词语c,通过类比的方法推理出另一个相关的词语d,例如经典的类比任务King-Queen=Man-Wan。这种方法的缺点是需要有比较成熟的相关数据集,装备领域的类比数据还不够完善,所以该方法并不适用于本文。相似度评价是基于已经训练好的词向量,通过计算给定两两单词的相似度来作比较,来判断它的效果怎样。其中,判断词语相似度最常用的方法包括欧氏距离和余弦相似度。向量的夹角余弦值可以体现两个向量在方向上的差异,余弦相似度就是把一个向量空间中两个夹角的余弦值作为衡量两个个体之间差异的大小。
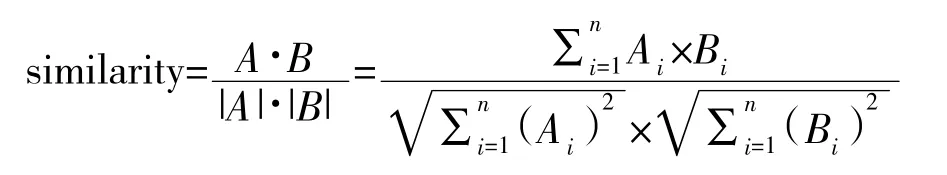
本节主要采用余弦相似度评价和空间可视化相结合的方法,对装备领域的词向量进行评估。
3.3 结果分析
依据现有的实验条件和语料库数据情况,主要从自主训练和基于腾讯词向量训练词向量两个方面进行了实验。自主训练词向量不同于基于迁移学习的训练,两种训练方法的本质区别在于是否受语料数据的规模的影响,有没有稳定的模型参数做支撑。词向量训练效果的评价主要从3 个方面进行分析:1)自主训练词向量实验效果分析;2)自主训练与基于腾讯词向量训练结果对比分析;3)可视化分析。
3.3.1 自主训练词向量实验效果分析
在自主训练词向量过程中,为了获得较理想的词汇语义表征效果,通过自主训练的方法分别得到了50 维、100 维、150 维、200 维和300 维词向量的训练模型,并运用余弦相似度计算输出了与中心词最相似的前10 个词语,得到结果如表1 所示,这里仅展示以“电台”为中心词输出的结果。
通过对表1 分析,横向比较可知,采用50 维来表达装备领域的词语含义效果不明显,即使像“3”“不能”以及“不”等这样与“电台”关联度不明显的词语相似度竟然超过了“A 型”“保险丝”之类的词语,且相似度在80%以上。产生这种现象的原因是50 维的词向量模型的空间维度较低,很难在低维的向量空间中综合表达并区分涵盖语料丰富的信息内容,因此,运用50 维的词向量模型不能满足装备领域词语的表达需求。纵向比较可得,从100 维到300 维的词向量模型表示同一词语的相似度在逐渐下降,造成这样结果的原因是随着向量空间的增大,每个词语在每一维上的表达更加精确,相似度值的区分也更加明显,而且当向量维度增加到200维以上时,出现了“发射机”“接收机”等与“电台”关联度更高的词语;但同时也发现运用200 维的词向量模型已经达到了一定的对装备领域词语表达效果,用300 维的空间表示比较浪费、存在信息冗余,也大大增加了后续计算的工作量。综合分析比较,将向量维度设定为200 维对装备领域词语的语义信息有一定的表征效果,但自主训练的词语关联度还不够凸显。
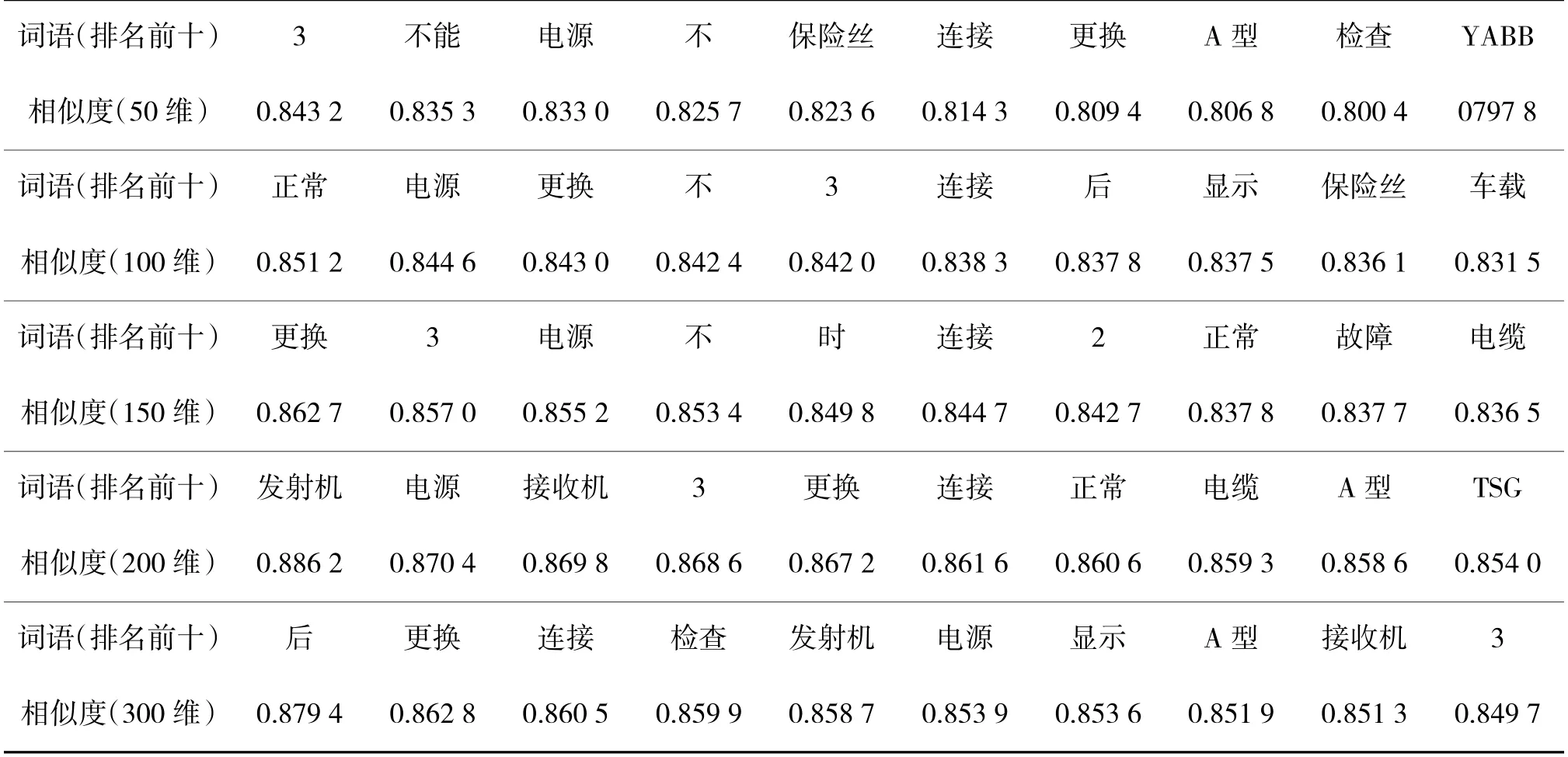
表1 自主训练词向量相似度对比分析
3.3.2 自主训练与基于腾讯词向量训练结果对比分析
由于腾讯词向量对装备领域的一些类似“断壳”之类的专有名词涵盖不全面,所以不直接使用腾讯词向量对装备故障文本进行表示。针对腾讯词向量模型参数稳定、覆盖词语领域广泛成熟的优势以及装备领域语料不足够大的特点,将词向量维度设置为200 维,基于gensim 包运用腾讯词向量模型对装备领域的词向量进行了增量训练,得到了装备领域的词向量模型。这里以“电台”为中心词,随机抽取与“电台”一词关联度高的以及关联度不高的部分词语,运用基于腾讯词向量训练生成的词向量模型和自主训练生成的200 维的词向量模型,分析比较同一类词语之间余弦相似度差异,其结果如下页表2 所示。

表2 自主训练与基于腾讯词向量训练的词向量相似度对比
通过对比分析发现,自主训练的词向量模型受语料库量的限制,在计算与“电台”一词相关和不相关的词语时区分度不高,且出现了与“电台”一词关联度不高的“底盘”“发动机”等词的相似度远超过了与“电台”关联度较密切的“调频电台”“调频”等词语的现象。与之形成鲜明的对比的是,在计算与“电台”关联较高的一类词如“调频电台”“天线”“接收机”“发射机”“调频”时,运用基于腾讯词向量训练得到的词向量模型其计算结果都在0.5 以上,且词语之间彼此的区分度明显;在计算与“电台”关联不太高的“发动机”“底盘”“电源”“电缆”“连接”等词时,其相似度都在0.3 左右浮动,且词语之间与电台的关联度也能较好地区分出来。所以,采用基于腾讯词向量模型训练装备领域词向量更符合人们的主观判断。
3.3.3 可视化分析
运用基于腾讯词向量模型训练和自主训练两种方法分别生成了528 969 和297 130 个200 维的词向量,由于词向量文件比较大,全部可视化就什么都看不见了,所以将两种训练方法得到的词向量模型随机抽取部分进行可视化展示,效果如图4 所示。
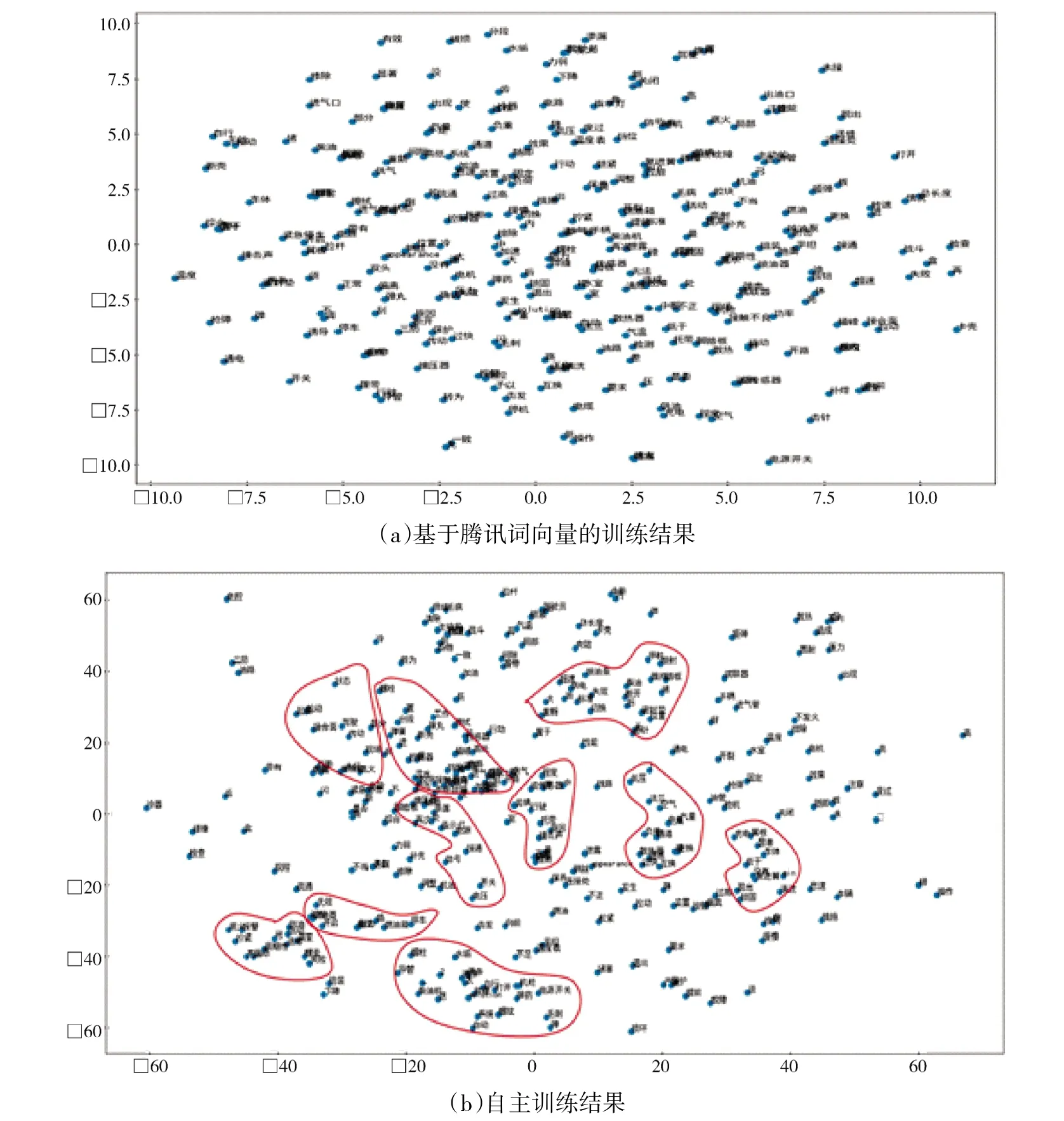
图4 两种训练方法得到词向量的二维投影
通过向量可视化结果可知,图4(a)基于腾讯词向量训练得到的装备领域词向量存在关联关系的大部分词语有明显的聚类特征,语义相似或存在明显关联关系的词会有相近的分布,只有少量词语由于语料数据规模导致关联关系不明显;而图4(b)自主训练的词向向量呈现分布均匀,词向量之间的语义关联关系不明显,没有明显的聚类特征。产生这样的训练效果,一方面是由于语料库的数据量不够大,仅自主训练没有达到较好的效果,另一方面是腾讯词向量模型本身参数已经较稳定,训练的效果更有说服力。显然,基于腾讯词向量训练的装备领域词向量涵盖词语全面、同一类词语之间存在一定的关联关系,更符合装备领域词向量训练应达到的效果。
在表3 中,对3 种词向量模型采用余弦相似度分别计算并找出了与给定中心词距离最相近的5个词。从计算结果发现,在数据集相同的情况下不同的训练方法产生了不同的训练结果。在腾讯词向量模型中,中心词和邻近词之间只是在词性语义方面相近,中心词与邻近词不存在“偏好”。运用同一语料数据,进行自主训练和基于腾讯词向量训练后发现,自主训练的中心词和邻近词存在一定关联关系但词性语义有所区别;而基于腾讯词向量训练的中心词不仅词性语义相近且对装备领域的词语有一定的“偏好”。通过这一现象表明,运用装备领域的语料基于腾讯词向量模型训练得到的装备领域的词向量,具备一定的特殊性和针对性。
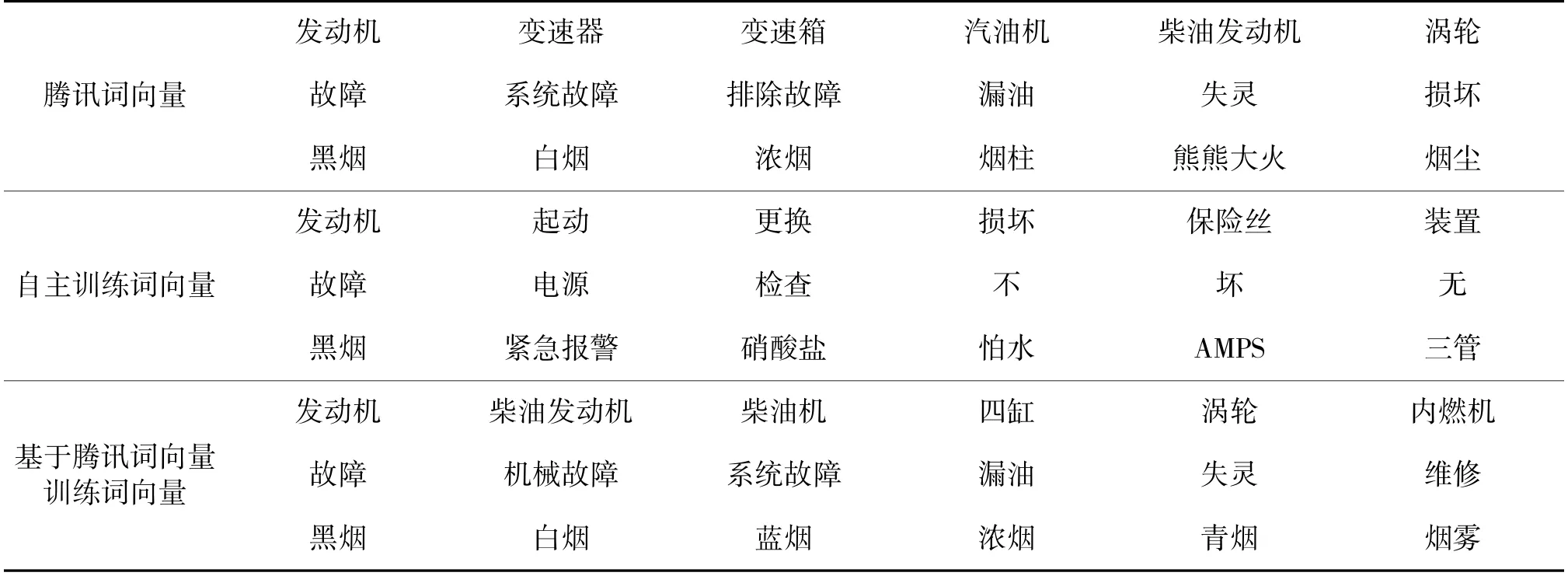
表3 不同模型下部分词与其邻近的5 个词
4 结论
基于腾讯词向量训练得到的装备领域词向量,无论是在相似度匹配效果方面还是在词向量可视化方面,表征效果都明显要比自主训练的效果好,而且受装备领域语料的限制,基于腾讯词向量模型得到的领域词向量表征效果更稳定,更能体现出语义之间的关联关系。实验表明,基于腾讯词向量训练的装备领域词向量,较自主训练提高了词性语义的关联性,较腾讯词向量具备装备领域的针对性,更适用于装备故障案例的统一知识表达。
