基于注意力机制与特征融合的耳诊图像五脏反射区分割
2022-09-15冯跃梁惠珠徐红林卓胜张双胜胡敏儿
冯跃,梁惠珠,徐红,林卓胜,张双胜,胡敏儿
(1.五邑大学 智能制造学部,广东 江门 529020;2.江门市中心医院,广东 江门 529030)
中医学强调内脏和体表组织器官在结构和机能上的协调、完整性以及在生理上的密切联系和病理上的相互影响[1],耳诊是诊断辨证和疗效评价的重要依据之一. 在临床中,医者观察耳部不同区域颜色和形态变化可探知内在脏腑的健康状态[2-3]. 经历几千年的经验积累和多代科研人员的贡献,2008年国家颁布了《耳穴名称与定位》[4],明确划分了人体各脏腑器官在耳廓的反射分布区域,并得到了世界卫生组织的认可[5]. 但在临床中,耳诊仍然存在主观模糊性描述,使其应用广度和精度受到限制[6]. 随着计算机技术的不断发展,耳诊有望借助数字图像分析技术,实现快速高效的客观化诊断. 为了实现耳诊图像自动化分析,首先需要将脏腑反射区从图像中有效分割出来. 然而,标准耳穴图中各反射区仅占整体耳部的极小部分(如图1所示),其划分边界在现实耳部中大部分不可见,因此,从耳诊图像中分割出五脏反射区的难度极大. 相比于传统图像分割方法,基于深度学习的图像分割方法具有自动学习和提取重要特征的优势,在中医医学领域获得了有价值的结果,尤其在面诊[7]和舌诊[8-9]方面,这给本文耳诊图像五脏反射区分割任务提供了思路.

图1 中国标准耳穴图
深度学习中,特征融合和注意力机制的应用越来越广泛. U-Net[10]在医学图像分割领域有突出表现,其结构主要由编码端和解码端组成,编码端与解码端的同级卷积层通过跳跃连接相连,使图像的高层与底层特征相融合,以达到良好的分割效果. 但U-Net存在以下缺点:编码阶段连续下采样和卷积操作导致有用空间信息损失,在解码阶段这些信息不易恢复,使其对小目标区域及边缘细节关注能力不足. 为了提高对目标的关注能力,图像分割广泛应用注意力网络模块PAN(Pyramid Attention Network)[11]以GAU(Global Attention Upsample)作为底层特征指导,提供全局语义. DANet(Dual Attention Network)[12]采用空间、通道两个平行的注意力模块,考虑全局的空间和通道关系. Attention UNet[13]设计AG(Attention Gate)模块过滤由跳跃连接传递的特征以关注相关显著特征. CPFNet[14]设计SAPF(Scale Aware Pyramid Fusion)注意力模块置于编解码网络最底层,以融合不同尺寸的特征信息. 注意力机制与特征融合的结合有利于提取有效且丰富的信息,提高了对小目标及边缘细节的分割能力. 因此,本文以U-Net[10]作为基本结构,构建一个注意力与特征融合的深度学习模型.
1 五脏反射区分割模型
由于耳诊图像五脏反射区面积占比小且边缘不清晰,本文结合注意力机制与特征融合的思想,在U-Net[10]基础上提出五脏反射区分割模型,如图2所示. 除U-Net[10]基本结构外,主要由自适应平均池化分支、多视图空间注意力模块和多尺度特征融合模块3部分组成. 此外,通过改进二值交叉熵与交叉熵结合的损失函数,进一步聚焦于目标区域.

图2 注意力与特征融合网络
1.1 自适应平均池化分支
原U-Net[10]网络编码阶段下采样和卷积操作会造成边缘等有用空间信息损失,耳部五脏反射区面积小,若信息损失严重时在解码阶段难以恢复目标信息,为此设计自适应平均池化分支嵌入到网络中,如图2虚线框所示.Fm2、Fm3、Fm4和Fm5分别是原U-Net模型编码阶段经过最大池化2×2操作在第2层、第3层、第4层、第5层生成的高层特征.Fa2、Fa3、Fa4和Fa5分别是原始输入图像经过自适应平均池化操作后在第2、3、4、5层生成的3通道底层特征.aF的宽度和高度与位于同层的mF保持一致,两者在通道维度上进行拼接,得到对应层的输入特征. 由原始输入图像生成的底层特征包含丰富的边缘特征信息,向高层特征引入底层特征,有利于提升分割精度.
1.2 多视图空间注意力模块
由于耳部五脏反射区与背景具有一定相似性,且边缘模糊,为了提高目标区域的关注能力,引入经过线性注意力机制[15]简化计算的位置注意力模块[12](本文命名为空间线性注意力模块SLA),即使用泰勒展开的一阶近似以及2L范数,简化位置注意力模块中的自然常数指数运算,简化为:

式 中,输 入 特 征X∈RC×H×W,其中C、H和W分别为通道数、高度和宽度. 特征X经过卷积和重组操作后,生成3个特征A、B以及D. 特征A和B有H×W个C/r维位置向量,D有H×W个C维位置向量,即Ak∈RC/r、Bk∈RC/r以及Dk∈RC,r表示卷积操作中通道减少率,本文设为8,g是初始值为0,并在模型训练中可学习的参数. 位置j的输出Oj为注意力权重Wj和原始输入Xj对应元素相加,通过学习每个像素的重要程度,分配重要性权重,从而在空间维度上提取有用信息.以及对于B计算可以重复利用,从而达到减少运算量的目的.
结合反射区在全局视图中面积占比小而可能不易捕捉和建立长距离依赖性的问题,对此,通过划分原输入特征为子特征块,在子特征块上使用空间线性注意力模块(SLA),缩小指导范围,然后结合全局和局部范围设计位置重要性权重,兼顾全局与局部指导信息,设计了多视图空间注意力模块,如图3所示,具体步骤如下:

图3 多视图空间注意力模块
1)输入特征Fx∈RC×H×W经过空间线性注意力模块SLA转换,得到特征F1∈RC×H×W;
2)输入特征Fx在空间维度上被分成4等分:左上、左下、右上以及右下的子部分. 此4子部分分别经过SLA处理,得到4个子特征. 然后,这些子特征被放回原本的空间位置,得到特征F2∈RC×H×W;
3)输入特征Fx中间部分也应被考虑在内,因为在生成上述F2过程中,中间部分的信息一定程度上被忽略. 为了使特征F3的尺寸与F1、F2保持一致,在F3中心子特征周围区域以数值0填充;
4)特征F1、F2和F3在通道维度上进行拼接,得到特征Fc∈R3C×H×W. 特征cF通过1×1卷积操作进行信息融合和通道数降维,恢复与输入特征xF相同尺寸,再与可学习参数g相乘构成xF的注意力权重wF;
5)注意力权重wF与输入特征xF的总和得到注意力模块的输出oF.
1.3 多尺度特征融合模块
在五脏反射区面积占比小的情况下,反射区之间的面积大小还存在差异,对此,本文采用空洞卷积[16]融合不同感受野下的目标区域信息,以兼顾不同面积大小的反射区分割效果. 具体办法是在本文网络解码部分最后的输出层设计了带有空洞卷积的多尺度特征融合模块,结构如图4所示. 模块结构中,输入特征通道数C为128,由第一层编码层跳跃连接传递的特征与第二层解码层通过上采样后的特征拼接得到. 随后,常规3×3卷积对输入进行初步特征融合令通道数减半,紧接着常规1×1卷积逐像素点提取特征,通道数增加4倍,以获取空间更精细信息. 最后,模块并行使用卷积核大小为3×3,扩张率分别为6、12、18、24的空洞卷积,叠加不同感受野下的五脏反射区预测结果作为最后模型输出,其中n为6. 综上,模型会以在不同感受野中都得到目标区域为目的,从而提高分割准确率.

图4 多尺度特征融合模块
1.4 损失函数
为进一步优化模型,总损失函数是交叉熵LCE以及设计的改进二值交叉熵LBCE的结合.

式中,N表示图像像素数目.c∈{1 ,… ,C},C为分割类别数目.fic和qic分别为在图像位置i处对应类别c的标签值和预测概率.

在交叉熵LCE中,已经将背景计算在内,而耳部图像中背景区域较大,因此式(4)中,LBCE不关注背景,即c∈{2 ,…,C},目的是为了更加聚焦于目标分割区域;e为 1e-9,分母包含类别数是为了防止计算溢出.
2 五脏反射区分割实验与结果分析
2.1 数据集和评价标准
本文使用两个带五脏反射区标注的耳诊图像数据集对模型进行训练和定量评价,分别为数据集一和数据集二. 数据集一由549张耳部图像组成,在符合中医耳诊检查要求下筛选自公开的AMI Ear数据集[17],图像均为492×702. 数据集二由424张图像组成,由本课题团队在符合医学伦理标准下采集自157位参与者. 数据集二使用中医面舌诊仪采集数据,采集的图像尺寸较大且含有较大部分的脸以及头部等非耳部区域,要对图像进行适当裁剪. 裁剪后的图像尺寸不一,其宽度和高度大部分在400~1 000像素之间,耳部区域面积约占图像的一半. 本文使用Labelme工具对上述两个数据集的耳部五脏反射区进行逐像素点标注,由两名临床医生全程指导. 标注有6类分割区域,分别为背景、心、肝、脾、肺、肾. 每份样本经3位医生检查核实.
数据集一和二的划分均为60%用于训练集,20%用于验证集,20%用于测试集. 对耳部五脏各反射区域分割效果使用Jaccard系数、Dice系数以及平均对称面距离ASSD评价,公式如下:

式中,A为真实标签,B为分割结果代表点a至B中所有点的最短欧氏距离. Jaccard系数与Dice系数的取值范围是[0,1],其值越高代表分割越准确. ASSD值越低代表分割越准确.
2.2 硬件环境与参数设置
实验在配置有Nvidia GeForce GTX 1080显卡和16Gb RAM的计算机上进行,使用Pytorch 1.1.0训练. 实验采用SGD优化器,批大小设为4,采用poly学习率策略,power为0.9,初始学习率为0.01,训练1 000轮.
2.3 数据增强
数据增强有助于网络获得所需的鲁棒性. 本文数据增强分两个阶段. 模型训练前,参照文献[7]对训练集进行几何和光度变换,使图像数目扩充7倍. 几何变换中,以0.5概率进行水平翻转、0.9~1.5倍随机尺寸变换以及-45°~ 45°随机旋转. 光度变换使用伽马变换,伽马值为{0.5,0.8,1.2,1.5}.模型训练期间,对图像随机位置裁剪为128×128. 为了验证前述数据增强的有效性,以U-Net[10]为基础,采用五折交叉验证,共设计3种方式,结果如表1所示.

表1 数据增强实验结果对比
由方式一、二可得,几何、光度变换用于模型训练前有利于提高分割效果,这是因为增加了每轮训练的图像数目并丰富了图像多样性. 由方式二、三可得,模型训练期间,随机位置裁剪相比于对耳部图像整体进行尺寸调整为128×128,更适合耳部图像训练. 在输入图像尺寸相同的情况下,对图像整体调整尺寸可以在模型训练时保持全部反射区之间的位置关系,但五脏反射区本身在耳部图像中所占面积小,经过整体图像尺寸缩小后使模型更难以发现目标分割区域;再者,随机位置裁剪增加图像多样性,利于提升模型分割性能.
2.4 分支评估与模块性能对比
为验证自适应平均池化分支及在分支情况下添加其余模块的有效性,以U-Net作为基本网络[10],采用五折交叉验证,结果如表2所示. branch是自适应平均池化分支;MV是多视图空间注意力模块,MV1、MV2、MV3、MV4分别是在第一、二、三、四层跳跃连接处放置模块,MVall是在四层所有跳跃连接处都放置模块;“*”采用本文改进二值交叉熵与交叉熵结合的损失函数,其余只使用交叉熵函数;D是多尺度特征融合模块.
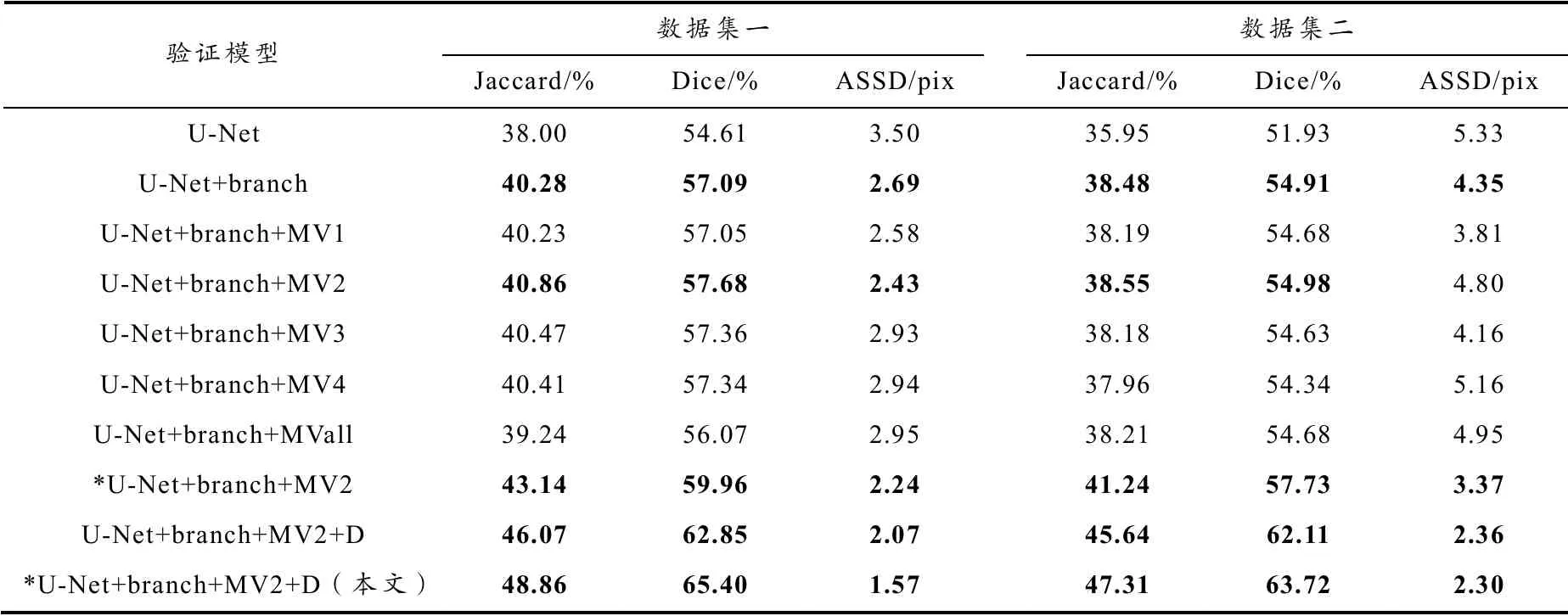
表2 分支评估与模块性能对比
首先,U-Net+branch说明U-Net嵌入自适应平均池化分支在两个耳部数据集上都能提高分割性能,有效补偿信息损失. 在添加分支的情况下,U-Net+branch+MV2,与注意力模块分别置于其他3层跳跃连接处情况相比,得到最高Jaccard值与Dice值;进一步,U-Net+branch+MV2在Jaccard、Dice与ASSD指标上都比U-Net+branch+ MVall表现更优,说明多视图空间注意力模块的使用不是越多越好,而是与模块所处的网络位置有关.结合各层注意力模块输出的通道图可视化效果进行分析,如图5所示. U-Net+branch+MV4突出显示整体耳部轮廓;U-Net+branch+MV3相比于前者,对耳部轮廓关注减弱,对耳部内小部分感兴趣区域关注增强;U-Net+branch+MV1关注区域包含五脏反射区外,还有较多非目标区域;U-Net+branch+MV2相比以上3种情况,既更好地关注五脏反射区特定区域,抑制其他非目标区域的特征响应. 综上,本文算法采用分支与第二层跳跃连接处的注意力模块相结合.
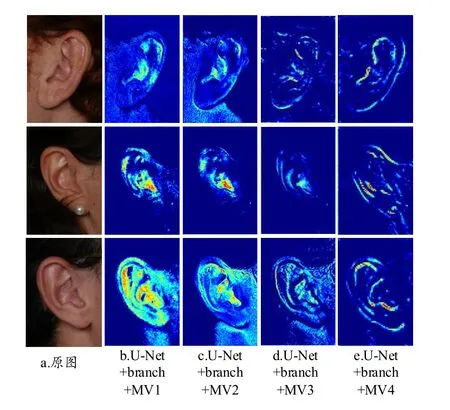
图5 注意力模块的输出通道图可视化结果
然后在U-Net+branch+MV2基础上,添加多尺度特征融合模块于网络输出端,模型在数据集一上Jacarrd和Dice分别提高5.21%和5.17%,ASSD下降0.36像素;在数据集二上Jaccard和Dice分别提高7.09%和7.13%,ASSD下降2.44像素,模型性能得到提升. U-Net+branch+MV2与U-Net+branch+MV2+D在使用交叉熵与改进二值交叉熵结合的损失函数后,Jaccard、Dice与ASSD都达到更优的结果,验证了本文损失函数的有效性.
2.5 不同网络性能对比
为了进一步验证所提模型在耳诊图像五脏反射区的分割性能,在数据集一、二上分别用PAN[11]、DANet[12]、CPFNet[14]、U-Net[10]以及Attention UNet[13]进行对比,所有网络均采用本文损失函数,并进行五折交叉验证,实验结果如表3所示. 在数据集一上,所提模型在Jaccard、Dice以及ASSD均优于其他模型,Jaccard和Dice比次优模型分别高8.91%和8.56%,ASSD低1.13像素;在数据集二上,所提模型在五脏反射区整体分割性能都最高,Jaccard、Dice以及ASSD分别为47.31%、63.72%以及2.30像素.

表3 不同网络性能对比
此外,结合表1与表2实验结果,在同种实验设置下,数据集二上的Jaccard、Dice低于数据集一上的值,ASSD值较高. 进一步,表3中除Attention UNet[13]外,其他网络在数据集二上的整体分割性能比在数据集一上都有所下降. 与数据集一相比,数据集二图像总数量少、尺寸不统一且相差较大,呈现五脏反射区情况更复杂,结合本文实验结果较大程度上说明在数据集二上实现五脏反射区分割更具挑战性.
结合图6和图7,原本用于自然场景分割的DANet[12]与PAN[11],在两个数据集五脏反射区的分割形状与真实标签相比存在明显差异. DANet[12]在脾区域存在欠分割问题且分割边缘带锯齿状;PAN[11]在心区域存在过分割问题. 用于医学图像分割的CPFNet[14]、U-Net[10]和Attention UNet[13],与本文方法分割效果相比存在明显差距. 前述3种医学图像分割网络,对于心和肺反射区存在以下情况:肺区域的形状预测更趋于包围心反射区,与标签图像的肺反射区U型形状存在差距,而本文模型有效改善肺部反射区形状分割. 与上述网络相比,本文方法预测的目标区域更完整,形状更接近标签,预测边缘比前述大多数网络更连续. 综上,对于小区域且边缘模糊的耳部图像五脏反射区分割任务,本文模型表现出较好的分割性能.
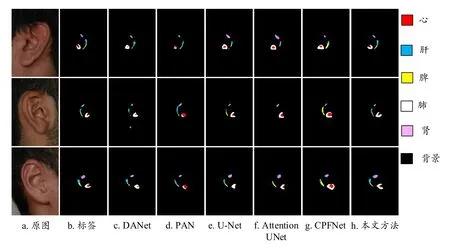
图6 数据集一的分割结果

图7 数据集二的分割结果
3 结论
本文采用U-Net基本结构,结合注意力机制与特征融合,设计了一个面向耳诊图像五脏(心、肝、脾、肺、肾)反射区的分割模型,针对分割小目标的五脏反射区域和完善分割边界细节,并在两个耳诊图像数据集上进行五脏反射区分割实验. 设计自适应平均池化分支从输入图像中提取丰富的底层信息并与不同高层信息融合,补偿信息损失;在跳跃连接处设计多视图空间注意力模块,兼顾全局、局部范围,提高对目标区域的关注能力;在模型输出端设计多尺度特征融合模块,不同程度地扩大感受野,捕获更多目标区域细节特征. 实验表明,本文算法在耳诊图像五脏反射区分割任务精度上具有优越性,分割效果与其他方法相比具有较大提升. 但本文算法在一定程度上增加了训练代价,未来工作将对模型进一步探讨,在保证分割性能的前提下对模型进行精简.
