基于深度强化学习的深圳市急救车调度算法
2022-09-15吴仍裕于海龙王亚沙
吴仍裕,周 强,于海龙,王亚沙
(1.深圳市急救中心,广东 深圳 518000;2.北京大学 信息科学技术学院,北京 100871;3.北京大学 软件工程国家工程研究中心,北京 100871;4.北京大学 高可信软件技术教育部重点实验室,北京 100871)
0 概述
在拥有1 300 万人口的深圳市,每年有20 余万名市民因突发事故或疾病,需要急救车将他们运送至医院,其人数占深圳市总人口的2%[1]。在城市的院前急救中,急救中心派遣急救车将患者及时地送到医院,对于患者的生命安全具有重要意义。统计数据表明,急救反应时间超过5 min 的患者死亡概率为1.58%,而低于5 min 的患者死亡概率为0.51%[2]。因此,急救车尽早到达现场能够有效保障患者的生命安全。
目前,中国大部分城市的院前急救模式是患者拨打120 急救电话后,急救中心派遣离事发地点最近急救站的急救车前往现场,负责将患者送至医院,之后急救车将返回到归属的急救站。但是在急救资源有限的情况下,无法保证每一个急救需求都能够从离事发地点最近的急救站派遣急救车。
为缩短整体的急救反应时间,研究人员专注于急救车静态分配策略的研究,将急救车分配问题建模成静态的优化问题[3-4]。这类方法通常使用整数线性规划模型求解最大化急救覆盖范围的急救车分配方案,为每辆急救车分配一个基站,在急救车执行完任务后返回自己的基站。但是,在急救系统中,无论是急救资源还是外部环境都是动态变化的,静态分配策略无法充分利用这些动态信息。研究人员对急救车动态调度策略进行研究[5-7]。急救车的动态调度策略[8]是指急救车执行完任务后,通过重新调度到合适的急救站,为服务未来的急救请求做好准备,从而达到缩短整体急救反应时间的目的。在急救车动态调度中,调度策略的制定需要实时考虑环境的多种动态因素,例如,急救站附近的急救需求数量、急救站当前拥有的急救车数量、其他正在执行任务的急救车状态等,这些动态因素对于调度策略的制定至关重要。
现有的调度策略研究通常基于专家知识设计特定的规则和指标[6-8],将少数几种动态因素相结合。但是这种方式需要同时考虑多种因素,如果仅考虑少数几种动态因素,模型难以全面捕捉急救环境的变化情况,无法优化调度效果。
强化学习能够解决序列决策问题,在共享单车重定位[9]、网约车派单[10-12]等类似调度问题上取得了良好的效果。网约车派单[13-14]与急救车调度都属于车辆调度问题,在优化目标中都需要考虑长远收益。但是,网约车派单问题是将短时间内接收到的大量乘客订单与平台司机进行匹配,本质上属于二部图的匹配问题。文献[10-12]通过强化学习司机和订单之间的匹配价值,在派单阶段利用二部图匹配算法实现最大权匹配。文献[13-14]将短时间内大量司机的派单视作多智能体问题,通过多智能体强化学习实现司机间的协作,使得平台整体收益最大化。而急救车调度问题是处理单一急救车的调度,难点在于急救环境的动态性和复杂性。此外,急救车调度是院前急救领域的重要问题,需要贴合真实环境设计方案,才能更好地保障人民的生命安全。
虽然强化学习可以用于解决网约车派单的调度问题,但是在急救车调度领域上的应用是非常少的,仅文献[5]提出一种基于强化学习的急救车动态调度模型。该模型利用神经网络融合环境中的动态因素,并建立强化学习框架,得到合适的急救车调度策略。然而,该模型对急救环境进行较强的假设和简化,无法直接应用于深圳急救的真实环境,其原因为仅基于道路限速值估计急救车的行驶速度,未考虑道路拥堵的现象。深圳是我国一线城市,道路拥堵频繁发生,需根据道路拥堵情况规划急救车路径。该模型对急救车行为做了较大简化,例如,认为总是距离患者最近的急救车出车,并到达现场后,立刻将患者送往距离最近的医院。然而,从深圳和急救的历史数据可以看出,在很多情况下急救车到达现场后需要先对患者进行现场处置,并可能根据病情,将患者送至有救治能力且距离较近的医院。此外,文献[5]利 用REINFORCE 算法[15]优化策略函数,REINFORCE 是一种策略梯度算法[16],使用蒙特卡洛法估计期望收益,但是存在训练速度慢、方差大、样本利用率低的问题。
本文提出基于深度强化学习的急救车调度算法。利用多层感知机将急救站的动态信息映射为各急救站的评分,同时将急救车动态调度建模成马尔科夫决策过程,使用强化学习中演员-评论家(Actor-Critic)框架[16]下的近端策略优化(Proximal Policy Optimization,PPO)算法[17]学习评分网络的参数。通过考虑急救环境因素、道路交通因素和急救车行为模式因素,建立较真实的模拟器环境。
1 强化学习
强化学习是机器学习的一种范式,通过智能体与环境进行不断交互,以学习策略,使得累积期望收益最大化。强化学习组件包括S,A,P,R,γ五个要素。S是环境的状态,A是智能体的动作,P是环境状态的转移概率矩阵,R是环境提供的奖励,γ是折扣因子。在强化学习中,马尔科夫决策过程(Markov Decision Process,MDP)是序列决策的一种数学模型,假设环境的状态具有马尔科夫性质。马尔科夫性质是指在给定环境当前和过去的状态下,未来环境状态的条件概率分布仅依赖于当前环境状态。本文利用S(t)表示环境的状态,则马尔科夫性质的表示如式(1)所示:
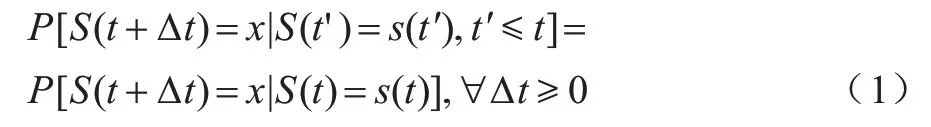
在MDP 中,智能体以试错的方式与环境进行交互,在每个时间步中,智能体观测到环境状态并产生一个动作,之后环境将会转移到下一个状态。在这期间,智能体收到一个奖励,这个奖励作为指导信号评估当前动作的好坏。因此,强化学习是通过最大化长期奖励来学习环境状态到动作的映射关系。
强化学习和神经网络的结合开始于20 世纪90 年代[18-19]。近年来,随着计算力的提升和深度学习的发展,结合深度学习与强化学习的深度强化学习成为研究热点。深度强化学习融合强化学习的决策能力和深度学习的表示能力,在很多序列决策问题中取得了巨大的进展,如AlphaGo[20]、网络对战游戏[21-22]、车辆调度问题等[5,9-10]。
受此启发,基于急救车调度模型的特点,本文使用强化学习中的策略梯度框架,通过深度神经网络对环境状态进行表征,使用PPO 算法学习网络参数。
2 调度算法
本文将急救车调度问题形式化成MDP,使用强化学习框架选择合适的调度策略。本文网络结构的主体部分称为评分网络,使用多层感知机表示,用于综合急救站的多种动态因素,以评估急救车调度到该急救站的概率。为优化评分网络参数,本文使用PPO 强化学习框架,以试错的学习方式更新网络参数。
2.1 强化学习建模
强化学习的关键是将急救车调度问题进行形式化建模。在强化学习建模过程中需要对状态、动作、奖励、状态转移这4 个主要组件进行定义。
1)状态,指外部环境的状态。在急救车调度过程中,环境是完全可观测的,因此智能体观测到的环境状态等同于环境的实际状态。本文将状态定义为与急救车调度有关的环境信息,包括急救站附近的急救需求数量、急救站当前拥有的急救车数量、被调度车辆到达该急救站所需时间以及其他正在执行任务的急救车到达该急救站所需时间这4 种动态因素。
2)动作,指智能体执行的动作。在急救车调度问题中,本文将动作定义为调度到哪一个急救站,因此动作空间的大小等同于急救站的数目N。at表示t时刻智能体执行的动作,则at∈(1,2,…,N)。
3)奖励,指智能体执行动作后收到的奖励。R(st,at)表示智能体在状态st下执行动作at,当环境从状态st转换成st+1后智能体接收到的奖励。本文将R(st,at)定义为在时间阈值(10 min)内到达现场的急救车数目。例如,在t~(t+1)时刻内,整个系统共有5 辆急救车到达事发现场,其中有3 辆急救车花费的时间小于10 min,则奖励值就是3。
4)状态转移,指环境状态的转移。当急救车执行完任务等待重新调度时,智能体从环境中观测到状态st,并随之产生一个动作at,将该急救车调度到某个急救站。此后智能体处于空转的状态,直到有新的急救车执行完任务等待调度。此时环境状态转成st+1,并被智能体观测到。环境状态的转移是一个随机性事件,在两次状态之间的时间间隔是不固定的,但是这并不影响系统的马尔科夫性质,因此强化学习算法仍然可以工作。
强化学习模型的整体架构如图1 所示。首先智能体观测环境状态,即各个急救站的动态因素,并将其输入到Actor 的评分网络中以得到各个急救站的分数。智能体基于急救站的分数选择急救车调度的站点,并执行相应动作。环境在转移到下一个状态前,将奖励反馈给智能体,该奖励作为学习信号,送入Critic 网络中计算时序差分损失(TD error),使得智能体能够不断更新Actor 和Critic 网络的参数。
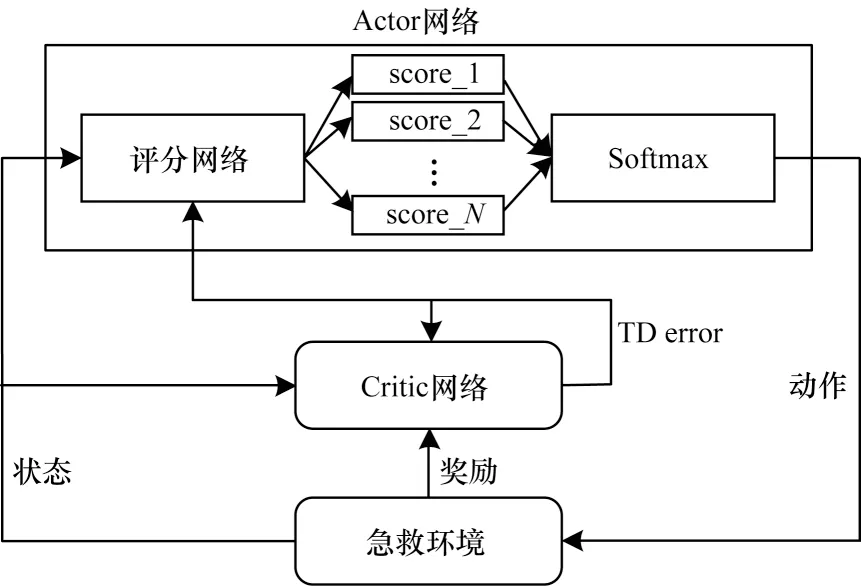
图1 强化学习模型整体架构Fig.1 Overall framework of reinforcement learning model
2.2 评分网络
评分网络用于表征环境状态,将每个急救站的动态信息映射为一个得分,该得分决定了被调度急救车前往该急救站的概率。本文使用多层感知机作为评分网络结构,以接收到急救站4 种动态信息作为输入,包括急救站附近的急救需求数量、急救站当前拥有的急救车数量、被调度车辆到达该急救站所需时间以及其他正在执行任务的急救车到达该急救站所需时间,最后输出急救站的得分。所有急救站的得分经过Softmax 函数后获得急救车调度到每个急救站的概率。
2.3 PPO 参数优化
对于强化学习中的策略梯度算法,目标函数如式(2)所示:

其中:V(s)为状态值函数,表征当前状态的期望收益。使用蒙特卡洛法对序列进行估计,但是会产生较大的估计方差,且更新参数的效率较低。针对该问题,在演员-评论家框架中引入Critic 网络对V(s)进行估计,使得每步动作执行后都能够得到当前状态期望收益的反馈,以减小估计方差,从而提高更新效率和样本利用率。
PPO 算法在演员-评论家框架下,待优化的策略函数(即演员-评论家框架下Actor 网络)是πθ,而与环境交互采样的策略是πθ′。针对采样得到的数据分布和待优化策略下状态分布失配的问题,在目标函数中引入重要性采样进行优化,如式(3)和式(4)所示:
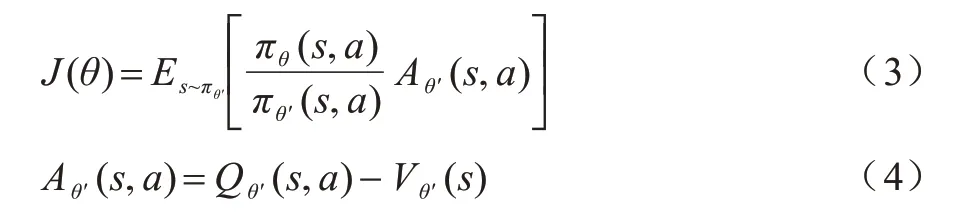
重要性采样是一种对原始分布期望的无偏差估计方法,如果引入的提议分布与原始分布差异较大,会产生较大的估计方差。因此,在PPO 算法中设计一种权重修剪机制,将重要性权重限制在[1-ε,1+ε]内,其中ε是超参数。此时,PPO 算法的优化目标表示如式(5)和式(6)所示:

clip(rt(θ),1-ε,1+ε)函数将重要性权重rt(θ)限制在[1-ε,1+ε]的范围内,简称为clip(ε)。
本文使用PPO 算法优化评分网络的参数,以学习调度的策略。在图1 的Actor 网络中基于评分网络生成各个急救站的评分,经过Softmax 函数得到急救车被调度到各个急救站的概率。Critic 网络和评分网络具有相同的网络结构,仅输出层不同,本文使用φ表示Critic 网络的参数。在训练期间,Critic 网络将接收的环境状态作为输入,估计当前状态下执行动作a的期望收益Aφ(s,a),根据环境反馈的奖励R计算时序差分损失δ,如式(7)所示:
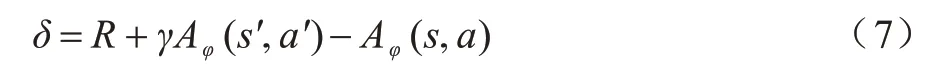
时序差分损失δ用于更新Actor 网络的参数,网络参数如式(8)所示:

Critic 网络参数基于均方误差损失函数进行更新,均方误差损失函数如式(9)所示:
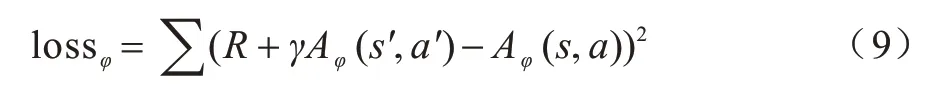
算法1 表示在PPO 算法中急救车调度算法的训练流程。
算法1调度算法训练流程


2.4 急救车动态调度算法
本文基于PPO 算法框架学习Actor 网络πθ(s,a)的参数θ,以得到急救车调往各个急救站的概率。在调度模型的训练阶段,基于各个急救站的概率确定急救车调往哪个急救站。这种随机性的策略有助于强化学习模型跳出局部最优。但是在测试阶段运行该急救车调度算法时,不适合继续采取这样的随机性策略,因此,在测试阶段,调度算法会选择概率最高的急救站作为调度的站点。
本文构建一个基于强化学习的急救车调度算法。当有急救车请求调度时,该调度算法首先观测环境的状态,包括所有急救站的动态因素,通过Actor 网络生成该急救车调往各个急救站的概率。在测试阶段,该调度算法会选择概率最高的急救站作为急救车被调往的站点。算法2 表示急救车动态调度算法运行的整体流程。
算法2急救车动态调度算法运行流程

3 实验与结果分析
3.1 数据集
本文使用深圳市的真实数据集对模型进行训练、测试和验证。数据集包括深圳市的急救电话数据、急救患者数据、急救站数据、医院数据、道路网络数据和速度数据。急救电话数据包含深圳市120 急救电话记录,每条记录均包括时间信息和事发地点。时间跨度从2019 年9月1日到2019 年10 月31日。其中9 月份的有效记录共有16 278 条,10 月份的有效记录共有15 327 条,平均每天约有518 条有效急救电话请求。本文以9 月份的急救电话数据作为训练数据,将10 月份的急救电话数据作为测试数据。急救患者数据包括每条急救记录中患者的基本信息、救治情况等内容。急救站数据包括深圳市急救站的地理位置信息。医院数据包括深圳市医院的地理位置信息。道路网络数据和速度数据包括深圳市路网信息和道路速度信息。
3.2 模拟器设计
本文基于上述数据集,构建一个较真实的模拟器。模拟器的作用是模拟真实情况下急救系统的运行状况,需要实时生成急救请求,并模拟派遣急救车接送患者至医院,最后根据调度算法重新调度执行完任务的急救车。
本文在模拟器中考虑了城市的道路网络数据和道路拥塞程度,基于城市的道路拥塞程度对急救车进行路径规划和时间估计,通过考虑不同道路的拥塞程度对急救反应时间的影响,以减小在仿真环境和真实环境中对路上时间估计的偏差。
本文基于对急救患者数据的观察,发现真实情况下急救车到达现场后,出于多种原因患者可能被当场救治。因此,在本文的模拟器中急救车被派往现场后,以概率的方式选择将患者送往医院或停留在原地。此外,本文观察到患者被送往的医院通常不是距离最近的,存在一定的随机性。因此,在本文的模拟器中根据距离获得急救车前往各个医院的概率。本文综合考虑急救车的这些行为模式,能够增强模拟器的真实性,使得算法适用于真实场景并进行落地部署。
3.3 实验设置
为评估基于强化学习的急救车调度算法,本文选用以下6 种算法作为基准算法:1)Fixed 算法,目前深圳市使用的急救车分配策略,基于贪心算法计算得到不同的车辆数;2)MEXCLP 算法[3],是一种经典的静态分配模型,通过最大化急救站的覆盖范围,为每辆急救车选取一个基站,优化过程使用整数线性规划求解;3)DSM算法[4],是一种经典基于覆盖的静态分配模型,将双重覆盖作为优化目标;4)Random 算法,是一种随机的动态调度策略,将急救车重新调度到一个随机的急救站;5)Nearest算法,是一种基于贪心算法的动态调度策略,将急救车重新调度到距离最近的急救站;6)Least算法,另一种基于贪心算法的动态调度策略,将急救车重新调度到车辆数目最少的急救站。
本文采用平均到达时间和平均到达比例来评估急救车的调度问题。平均到达时间是指急救车从派遣至到达现场的平均时间,如式(10)所示:

平均到达比例是在时间阈值内(10 min)到达现场的急救车比例,如式(11)所示:
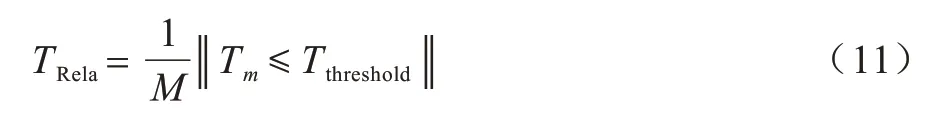
本文深度强化学习模型的代码在PyTorch 框架下实现,Actor 和Critic 网络使用相同的网络结构,采用三层的多层感知机,仅输出层不同,以Relu 作为激活函数。本文算法的超参数设置如表1 所示。
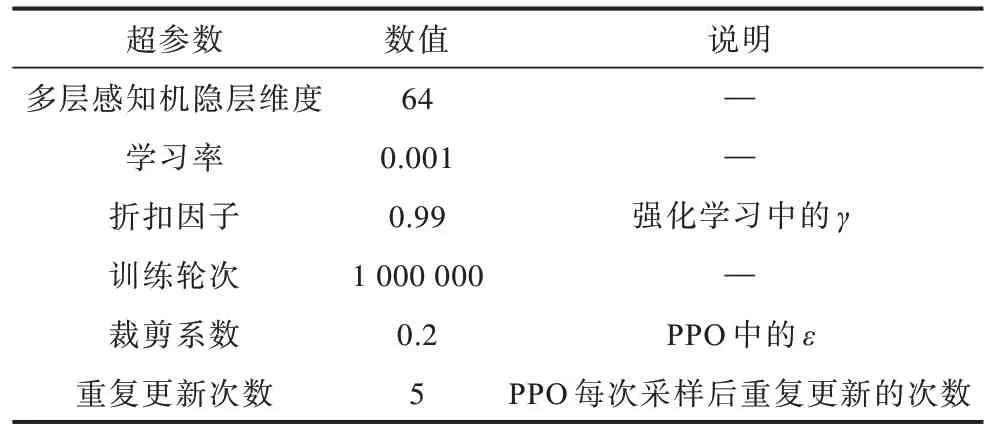
表1 本文算法的超参数设置Table 1 Hyperparameter settings of the proposed algorithm
3.4 结果分析
目前,深圳市实际部署的急救车数量是108 辆。深圳市作为中国的一线城市,急救资源相对充足,但是很多经济欠发达地区的急救资源可能相对紧缺。因此,本文在实验中还探究了在其他急救车数量的情况下,特别是急救车数量较少时的实验结果。
在不同的急救车数量下不同算法平均到达时间对比如表2 所示。当急救车数量为108 辆时,即目前深圳市的急救车实际数目,本文算法的平均到达时间是12.63 min,而Fixed 算法的平均到达时间是13.93 min。相比Fixed 算法,本文算法的平均到达时间缩短约80 s,性能提升了约10%。相比基准算法中MEXCLP,本文算法的平均时间缩短约40 s。
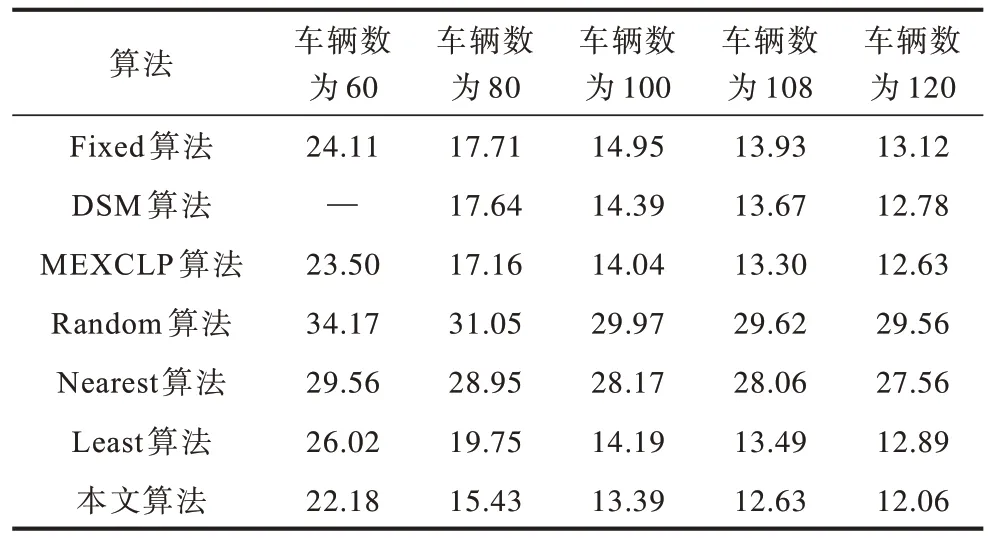
表2 不同算法的平均到达时间对比Table 2 Average arrival time comparison among different algorithms min
在不同急救车数量下不同算法的平均到达比例对比如表3 所示。在108 辆急救车配置的条件下,Fixed算法和本文算法的平均到达比例分别为32.3%和36.5%,相比基准算法Least,本文算法提高了1.1 个百分点。此外,当急救车辆数目较少时,本文算法的优势更为显著,其原因为静态调度策略在急救车数量较少时容易出现一些花费时间特别长的极端情况,基于贪心算法的动态调度策略则难以捕捉多种动态信息,而基于强化学习的调度策略能够捕捉到环境的动态变化。这也说明在急救资源紧缺的城市中部署本文急救车调度算法,在资源受限情况下能够有效提高院前急救效率。
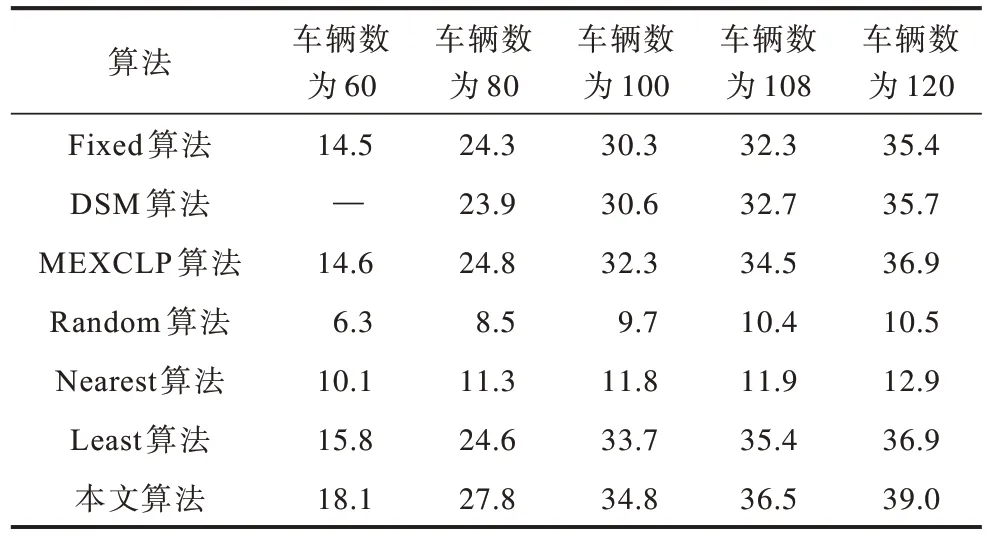
表3 不同算法的平均到达比例对比Table 3 Average arrival proportion comparison among different algorithms %
在院前急救领域较为重视盲点的情况。本文将盲点定义为急救车到达现场的路程距离超过3 000 m。当急救车数量为108 辆时,不同算法的盲点和距离情况如表4 所示。
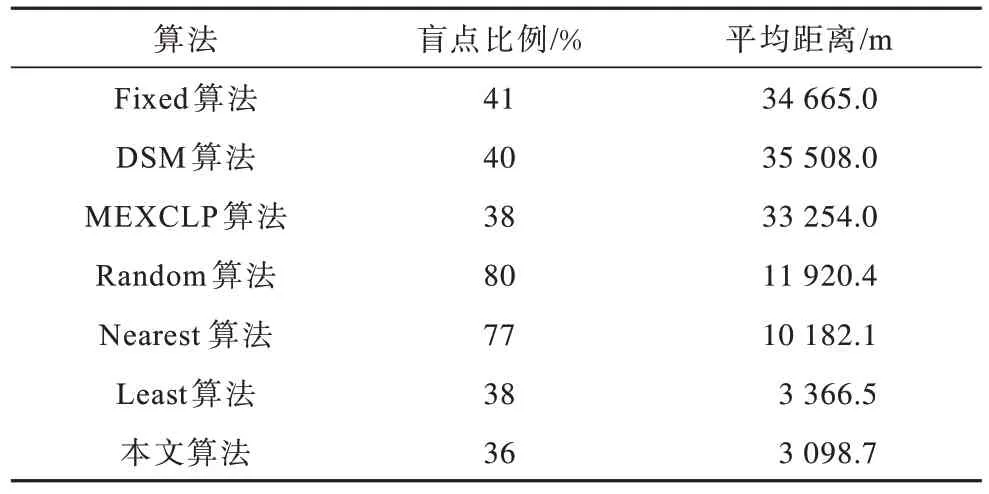
表4 不同算法的盲点和平均距离Table 4 Blind spots and average distances of different algorithms
从表4 可以看出,本文算法的平均距离在3 100 m左右,而最优的基准算法的平均距离约为3 300 m,说明强化学习模型能够隐式地预估未来的急救需求,预先将急救车调度到可能有需求的急救站,从而在急救事件发生时能够从最近的急救站派遣车辆。本文算法将盲点比例控制在36%,同样优于其他基准算法。
本文算法的盲点可视化分析如图2 所示(彩色效果见《计算机工程》官网HTML 版)。图2(a)表示本文算法在运行过程中盲点分布热力图,可以看出:盲点的分布与急救电话的分布整体上较为一致。在局部地区盲点分布情况和急救电话分布情况存在显著的差异。图2(b)和图2(c)分别表示急救电话和盲点在深圳市龙岗区龙城广场附近的分布情况。区域A 中的急救电话需求较多,但在区域B 中的盲点分布较少。区域C 和区域D 的情况则恰好相反。这说明盲点的产生不仅受急救电话数量的影响,同时也与其他因素有关,例如交通状况、急救资源分配情况等。
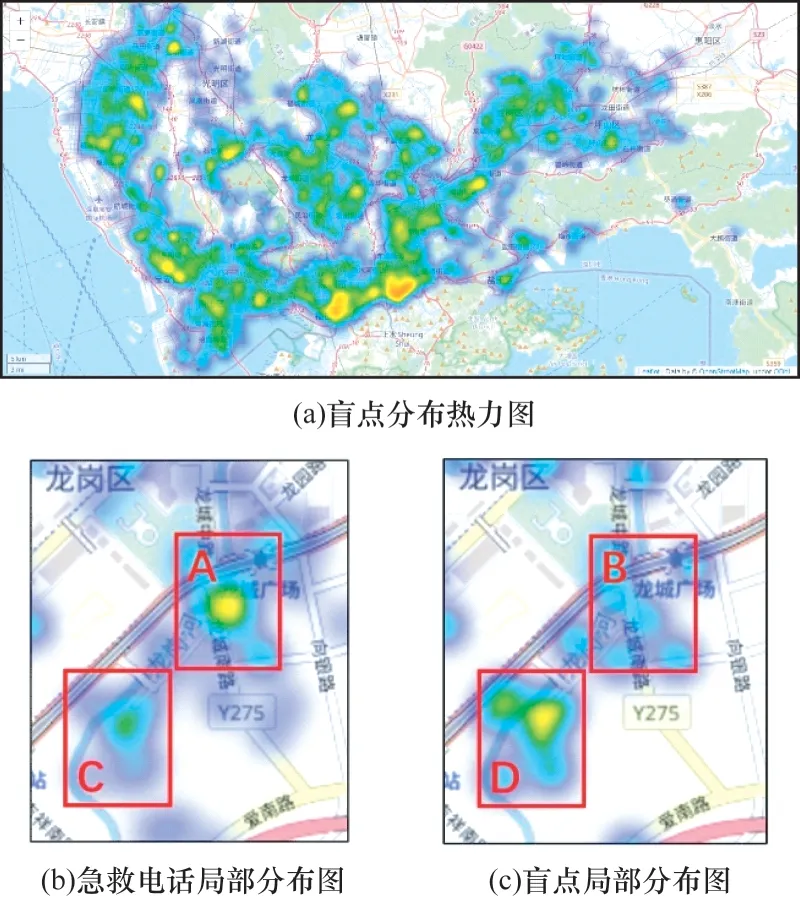
图2 本文算法的盲点可视化分析Fig.2 Blind spot visual analysis of the proposed algorithm
4 结束语
针对急救环境的动态性和复杂性,本文提出一种急救车动态调度算法。将多层感知机作为评分网络用于综合急救站的多种动态因素,以评估急救车调度到该急救站的概率。在PPO 强化学习框架下,采用试错的学习方式优化评分网络参数。实验结果表明,本文算法的平均达到时间和平均到达比例分别为12.63 min 和36.5%,与Fixed、DSM、MEXCLP 等算法相比,能够有效提高数据的利用率,并且具有较优的鲁棒性。下一步将利用图神经网络对不同时刻的交通资源进行编码,并把急救车的行为模式与交通资源引入到环境状态中,进一步缩短院前急救反应时间。
