基于堆叠卷积注意力的网络流量异常检测模型
2022-09-15董卫宇李海涛王瑞敏任化娟孙雪凯
董卫宇,李海涛,王瑞敏,任化娟,孙雪凯
(1.信息工程大学 网络空间安全学院,郑州 450002;2.郑州大学 网络空间安全学院,郑州 450001)
0 概述
在Internet 技术被广泛应用且复杂性不断提高的背景下,网络攻击数量也呈现日益增长的趋势。在过去几年中,超过90 000 个网站被钓鱼攻击工具包Angler Exploit Kit 的持续感染攻破[1]。随着云计算时代的到来,从云服务和应用程序到个人设备和远程访问工具,企业承受的攻击面不断扩大。此外,80%的安全和业务人员表示,由于远程工作,他们的组织更容易面临风险。据Security affairs报告[2],一种名为ERMAC 的新型病毒已经现身互联网,其主要针对安卓平台的银行应用,可以从378 个银行的钱包APP 中窃取金融数据。同时由文献[3]可知,2021 年发现了66 个0-day 漏洞,几乎是2020 年总数的2 倍,打破了0-day 黑客攻击的记录。
日益增多的网络攻击事件催生了网络流量异常检测技术的发展。通过收集网络流量数据和提取相关特征,可将流量分为正常流量和异常流量。在一般情况下,当正常流量数据存在于某些随机模型的高概率区域,而异常发生在该模型的低概率区域时,使用统计方法进行分类,此时随机模型要么是先验确定的,要么源自数据本身,这种方法的设计思想是测量异常分数,可通过使用假设检验和决策理论来完成[4]。在某些情况下,数据实例的几个维度(即特征)本质上是相关的,可利用降维的方法将原始数据实例嵌入到一个维数较少的子空间中。因此,为了确定流量数据实例是正常还是异常,可将其投影到正常和异常子空间[5]。从信息论的角度来看,数据实例被看作是由网络生成的一组符号,而每个实例都是以一定的概率独立生成的。因此,人们会试图测量每个实例所表示的平均信息量,这种方法利用了熵的概念。目前有研究通过使用信息增益或相对熵进行异常检测,旨在测量两个分布之间的统计距离。机器学习方法根据经验区分正常流量行为和异常流量行为,其通常会提供一种映射以适应看不见的网络异常。通过使用标记的训练集来学习映射函数的机器学习算法被称为监督学习算法,而使用完全未标记实例的训练集的机器学习算法被称为无监督学习算法。有监督的异常检测可建立正常数据模型,并在观察到的数据中检测与正常模型的偏差。无监督的异常检测将一组未标记的数据作为输入,并尝试找出隐藏在数据中的入侵行为。
多数网络安全解决方案都是基于人为构建的检索引擎,但是手动将最新的威胁和最新技术以及设备保持在最新的状态是很难的。传统的机器学习方法在进行异常流量检测时面临一些问题,如特征选择困难、模型不能表示各个特征之间复杂的关系以及检测误报率(False Alarm Rate,FAR)较高。虽然目前深度学习已经被广泛用于各种应用,包括图像处理、自然语言处理、目标检测、计算机视觉等[6],但是基于深度学习的网络异常检测研究却仍处于起步阶段。与机器学习相比,深度学习不仅能够以表示学习的方式自动提取特征,而且还可以表示特征之间复杂的非线性关系。注意力(Attention)机制是神经网络中的一个重要概念,并在不同的领域得到了应用,Attention 机制的引入可以提高神经网络的可解释性。
在异常流量检测研究中已有多种方法和实践,但无论是使用基于统计的方法还是基于传统机器学习的方法,从数据中找出正常数据和异常数据的能力都是有限的。数据决定了机器学习模型效果的上限,模型正是为了接近这个上限而构建。虽然深度学习方法已经在异常流量检测领域得到一些应用,但是在图像领域和自然语言处理领域中得到广泛关注的深度自注意力网络结构[7]中,Attention 机制却鲜有应用于异常流量检测。
本文结合Attention 机制,基于深度学习方法建立恶意流量检测的训练模型。对数据进行预处理,将人工提取的恶意流量数据转化为对应的二进制数据集,引入Attention 机制进行特征提取,并输入到前馈神经网络实现恶意流量的多分类和二分类。同时为优化检测效果,在Attention 网络中采用有效的激活函数,进一步提升异常检测的准确率。
1 相关工作
文献[8]在GRU 模型的最终输出层引入线性支持向量机代替Softmax,实现对京都大学蜜罐系统2013 年网络流量数据[9]入侵检测的二分类,但其只使用了流量的时间特征,且模型的二分类精度不高,真正例率约为84.37%。
文献[10]基于逻辑回归模型进行异常流量检测,通过源IP、目的IP 等多个网络流量基本特征建立网络异常行为和正常行为训练集,从而构建网络异常流量挖掘模型,但其构建的模型仅适用于样本线性可分且特征空间不大的情况。
文献[11]将728 维的原始流量数据转换为图像,并使用卷积神经网络(Convolutional Neural Network,CNN)以有监督表示学习的方式从原始流量中提取空间特征,以此对恶意网络流量进行分类,同时使用一维CNN 实现加密流量的分类[12]。该方案使用的是简单的CNN 模型,其将PCAP 流量数据的二进制内容映射到MNIST 数据集(大型手写数字数据库),进而通过深度学习库函数读取这些数据集。与文献[11]的设计思想类似,文献[13]提出一种空洞卷积自动编码器(Dilated Convolutional AutoEncoder,DCAE)的深度学习方法,该方法结合了堆叠式自动编码器和CNN 的优势,训练过程包括无监督的预训练和有监督的训练,两个训练过程分别使用大量未标记的原始数据和少量标记数据。然而,DCAE 作为一种生成模型,其训练每层的贪婪学习权值矩阵都耗费了过长的时间。
文献[14]通过循环神经网络学习模型来表示网络中计算机之间的通信序列,并将此方法用于识别异常网络流量。该文使用长短期记忆(Long Short Term Memory,LSTM)网络对流序列建模,IP 流[15]的定义为在预定时间间隔内的一组IP 数据包,这些数据包具有一组公共属性,包括源/目标IP 地址、TCP/UDP 端口、VLAN、应用协议类型(来自OSI 模型的第3 层)和TOS(服务类型),但该方法只能根据端口序列中前10 个端口号来预测下一个端口号,应用范围有限。
文献[16]研究基于全连接卷积网络(Fully Convolutional Network,FCN)、变分自动编码器(Variational AutoEncoder,VAE)和LSTM 网络构建的深度学习模型,实验结果显示,基于LSTM 序列到序列(Seq2Seq)结构的模型在公共数据集上达到了99% 的二分类精度。但该文进行的实验仅对文献[9]中数据集进行了二分类的检测,并没有对多分类进行检测,并且模型不能很好地处理文献[9]中数据集不平衡的问题。
文献[17]从网络流中取出网络包的时序特征、一般的统计特征和环境特征,以提取网络流数据中有效和准确的特征。文献[18]提出基于改进的一维卷积神经网络进行异常流量检测,为了不丢失数据,其去除了卷积层之后的池化操作。
针对NSL-KDD 数据集,也有较多异常流量检测研究。文献[19]将深度神经网络和关联规则挖掘相结合设计一种异常检测系统,首先使用深度神经网络对NSL-KDD 数据集进行分类处理,然后在离散的特征和标签之间建立关联规则,从而降低神经网络处理结果的误报率,该系统对NSL-KDD 测试集异常流量的多分类预测准确率为71.01%。文献[20]对NSL-KDD 数据集进行了特征的缩减和标准化处理,使用人工神经网络(Artificial Neural Network,ANN)进行二分类和五分类的训练和测试,模型的二分类测试准确率达到81.20%。文献[21]基于NSL-KDD数据对入侵检测系统(Intrusion Detection System,IDS)中的卷积神经网络进行评估,设计一种数据预处理方法将属性(特征)数据转换为二进制向量类型,然后将数据转为图像形式,采用ResNet50 和GoogLeNet 作为底层的卷积神经网络对数据集进行二分类异常检测,该方法达到了79.41%和77.04%的二分类预测准确率。文献[22]使用包含4 个隐藏层的深度神经网络搭建了IDS,在NSL-KDD 数据集上的实验结果表明,该方法达到了84.70%的二分类预测准确率。
目前,对网络流量异常检测的研究多采用深度学习的方法,如使用CNN 提取空间特征、使用RNN提取时序特征等,但现有模型在可解释性和检测效果方面仍有可提升的空间。本文将注意力(Attention)机制和CNN 相结合,提出一种基于堆叠卷积自注意力的网络流量异常检测模型。通过堆叠多个Attention 模块增加网络深度,并在Attention 模块中引入CNN、池化层、批归一化层和激活函数层,防止模型过拟合。在此基础上,将Attention 模块的输出向量输入到深度神经网络(Deep Neural Network,DNN)结构中,对模型进行有监督的训练,使模型能够对新的测试数据进行预测,识别出对应的网络攻击类型。
2 基于堆叠卷积注意力的网络异常检测
Attention 机制最早应用于图像领域,近年来,其在自然语言处理领域也受到了广泛的关注。2017 年,谷歌发布的《Attention is all you need》[7]提出在机器翻译任务中大量使用自注意力机制来学习文本表示。本文提出的模型堆叠多个Attention 模块,并在模块中引入CNN、池化层、批归一化层和激活函数层,进而将Attention 模块的输出向量输入到DNN中,对模型进行有监督的训练。
2.1 堆叠卷积注意力模型
卷积注意力(CON-ATTN)模型是将卷积神经网络(CNN)和注意力机制(Attention)相结合,其结构如图1 左部分所示。
CON-ATTN 模型上层是卷积块,中间是注意力块,下层是两个卷积块,每个卷积块由二维卷积、批标准化和激活函数层组成。其中:二维卷积层提取特征并扩展通道;批标准化层对每批训练数据做标准化处理,并将分散的数据统一;激活函数层引入非线性因素并处理非线性可分数据。Attention 模块处理来自上层卷积块的输出向量,并把该输出向量中通道的数目平均分为三个部分,分别赋值给Q、K和V三个向量,每个向量的维度均为(b,c,w,h),其中:b为批大小(batch size);c为通道数(channel size);w为宽度(width);h为高度(height)。通道数c如式(1)所示,其中:nhead表示头的个数;dhead表示每个头的维度。
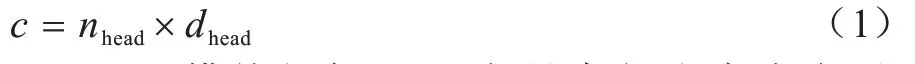
Attention 模块根据Q、K向量求得注意力向量Α,如式(2)所示。其中:fsoftmax为softmax 函数;fpos为位置编码函数,用于学习向量Q中各个数据的相对位置信息。将得到的位置向量作为注意力向量的一部分,可确保提取到流量数据中重要的特征。
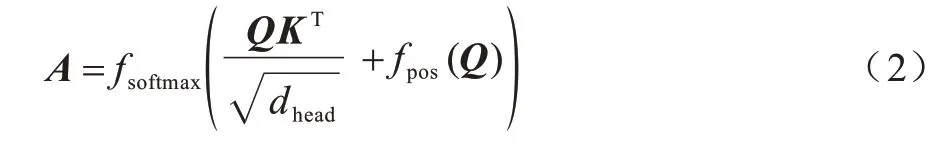
将注意力向量Α和V向量相乘,得到Attention模块的输出向量O,如式(3)所示。其中:向量O是向量V经过注意力向量Α处理之后的输出向量,用于使模型关注V向量中更关键的那部分特征。

CON-ATTN 模型的下层是含有多个隐藏层的神经网络,用于加深网络深度并进一步从Attention 模块的输出向量中提取特征。
本文将多个图1 左部分所示CON-ATTN 结构和DNN 相结合,提出一种堆叠卷积注意力网络(STACON-ATTN)模型,如图1 右部分所示。CONATTN 结构从输入向量中提取关键特征并使输入向量的通道数发生改变或者保持不变,因此,原始输入向量可以输入到多个CON-ATTN 结构中。多个CON-ATTN 结构通过残差连接方式结合在一起,在一定程度上避免了随着网络层数的加深而出现的梯度消失问题[23]。在STACON-ATTN 结构的末尾是一个DNN 结构,本文将该DNN 结构设计为由5 个全连接层连接而成,这是因为全连接层数过少会使得模型陷入过拟合状态,而全连接层数过多会增加模型训练的代价且不能显著提升模型性能。本文把DNN结构输出向量的维度设置为异常流量标签类别的个数,将DNN 结构输出向量与流量数据真实标签一起输入到一个损失函数中,如多分类时输入到交叉熵损失函数中,然后通过反向传播和梯度下降法进行模型训练。
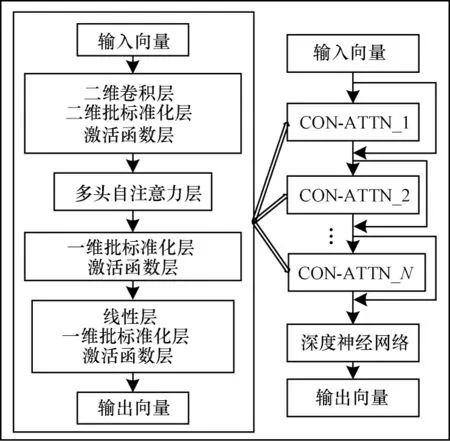
图1 STACON-ATTN 模型结构Fig.1 Structure of STACON-ATTN model
2.2 网络流量异常检测模型
基于堆叠卷积注意力的网络流量异常检测模型架构如图2 所示,其中主要包含数据预处理、训练和测试3 个阶段。
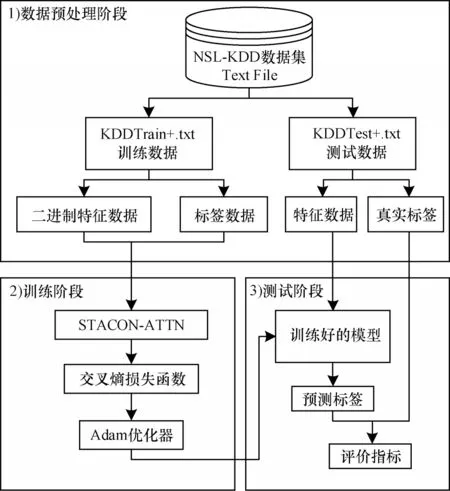
图2 网络流量异常检测模型结构Fig.2 Structure of network traffic anomaly detection model
1)数据预处理阶段。首先分别将训练数据和测试数据中离散文本类型的特征字段转换为数值类型,对整型和浮点型的特征字段进行类型的扩展;然后将数值128 填充到二进制特征的空缺字节中;最后将填充完成的二进制数据以二维单通道图形的形式存储到文件中,完成对数据集的预处理。
2)训练阶段。向架构中的神经网络输入预处理之后的特征数据和标签数据,使用交叉熵损失函数和Adam 优化器[24]对训练的过程进行不断调整,损失函数的输入是真实标签和预测标签,模型的训练目标是预测标签和真实标签之间差异最小。二分类情况和多分类情况下交叉熵损失函数的定义如式(4)所示,其中:m表示样本的个数;yi表示实际为正类的概率;表示预测为正类的概率。
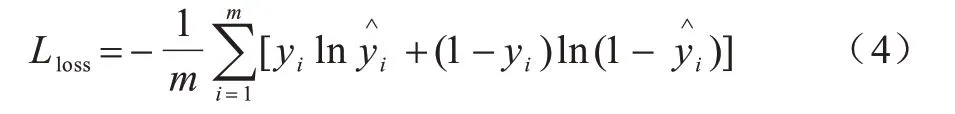
3)测试阶段。对训练好的模型,输入测试集中的特征数据和真实的标签数据,通过分析预测出的标签数据和真实标签数据之间的差异,对模型的效果进行评估。
3 实验设置与评价标准
3.1 数据集
本文实验使用公开的NSL-KDD 数据集,该数据集是KDD99 数据集[25]的进一步发展,也是第三届国际知识发现与数据挖掘工具大赛使用的数据集。KDD99 数据集中存在一些固有的问题[25],NSL-KDD数据集为了解决这些问题而建立。NSL-KDD 数据集虽然不是现实世界真实网络的反映,但由于目前缺乏基于网络的IDS 公共数据集,因此仍被用于检验IDS 中不同的入侵检测方法。
3.1.1 NSL-KDD 数据集攻击类型
NSL-KDD 数据集所有攻击类别下存在的攻击类型如表1 所示。从表1 可以看出,NSL-KDD 数据集中共有4 种不同的攻击类别、38 种不同的攻击类型。在训练集和测试集的每个攻击类别下都存在若干个攻击类型,训练集中有22 种不同的攻击类型,测试集中有16 种不同的攻击类型。由于在测试集中存在训练集中不存在的攻击类型,因此使用NSL-KDD 数据集能够很好地对模型的泛化能力进行检验。

表1 各攻击类别下的详细攻击类型Table 1 Detailed attack types under each attack category
对原始数据集做进一步处理,将属于同一攻击类别不同攻击类型的数据样本设置为同一标签,得到训练集和测试集正常攻击类别样本数量以及其他各攻击类别样本数量的统计信息,如表2 所示。
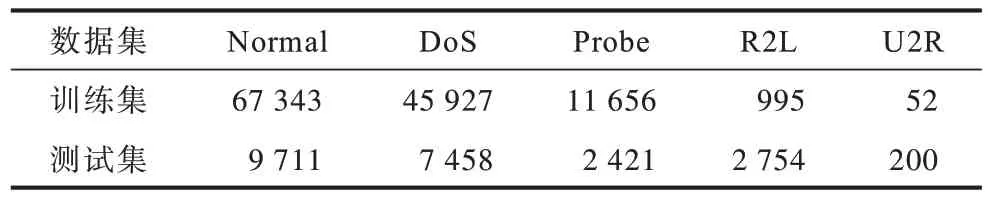
表2 训练集和测试集中各类别样本数量统计Table 2 Number of samples of each category in training set and test set
3.1.2 数据预处理
由于深度神经网络善于处理“像素”数据,每个“像素”可以用一个字节(Byte)表示,因此本文对手工提取的特征进行预处理,包括数据标签处理和数据特征处理2 个步骤。
1)数据标签处理。在4 种攻击类别下共有38 种攻击类型,因此,需要将各个攻击类别下的所有攻击类型标签都转换为其所属的攻击类别标签。经过处理后,数据标签就从初始的样本类型转变为样本类别。
2)数据特征处理。通过查看数据文件可以发现,如果把difficult_level 字段也考虑进去,那么数据集中共有43 个字段,由于有1 个字段表示标注信息,因此共有42 个表示特征的字段,其中有3 个字段是离散的,即协议类型(protocol_type)、服务(service)和标记(flag)字段。首先需要将这3 个离散的字段转换为数值类型,对应类型的数值为0,1,…,n-1(n为对应离散字段中离散值的个数)。对数据集中的各个特征只保留Int 和Float 数值类型,然后将这2 种数值类型的所有特征字段分别转换为Int64 和Float64 类型,并进行不同程度的特征值放大,即分别将各个特征的值乘以100、104和109。
由于本文使用了批归一化技术[26]来对每批训练数据进行标准化,因此不需要对原始数据进行标准化处理,每个样本的每个特征均占用8 Byte(Int64 和Float64 类型)的内存,42 个特征字段共占用336 Byte的内存。将每个样本映射到一个19×19 像素的图中,因为每个像素占用1 Byte,所以为了便于神经网络的处理,还需要填充25 Byte(19×19-336)。由于每个字节最终都是一个Uint8 类型,一个字节表示的数值范围是0~255,采用这256 个数的中位数填充数据可以给原始的数据集带来较少的影响,因此本文对每个字节填充的是数值128,而非0。通过对训练集和测试集进行同样的处理,并将每个样本的数据和标签在数据集中设置为同样的索引,由此完成二进制数据集的构造。
3.2 评价标准与相关设置
为了更全面地验证模型的效果,针对NSL-KDD数据进行多分类和二分类的异常流量检测,并将本文模型实验结果与文献[19-22]模型实验结果进行对比。本文使用整流线性单元(ReLU)函数作为模型的激活函数,该函数不仅能够加快模型的训练速度,而且可避免使用Sigmoid 和Tanh 激活函数导致的梯度消失问题[27]。
3.2.1 评价标准
本文实验采用准确率、精确率、召回率、F1 分数和ROC 曲线对模型性能进行评价。以TP表示将样本预测为正类且预测正确的样本数,TN表示将样本预测为负类且预测正确的样本数,FP表示将样本预测为正类且预测错误的样本数,FN表示将样本预测为负类且预测错误的样本数。
准确率为所有预测正确的正负样本数量之和与总体样本数量的比值,计算公式如式(5)所示:

精确率也称为查准率,用于评估模型找到相关目标的能力,计算公式如式(6)所示:

召回率也称为查全率,用于评估模型找到全部相关目标的能力,即模型给出的预测结果最多能覆盖多少真实目标,计算公式如式(7)所示:

F1 分数是基于精确率和召回率的调和平均,计算公式如式(8)所示:
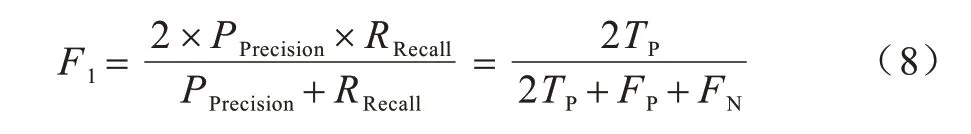
受试者工作特征(Receiver Operating Characteristic,ROC)曲线上点的横坐标为假正例率,也被称为误报率,计算公式如式(9)所示:

在异常流量检测任务中,常常将攻击类别定义为正例,将正常类别的流量定义为负例,误报指的是把正常流量识别为了攻击流量,而这是IDS 中最不能容忍的。
ROC 曲线上点的纵坐标为真正例率,计算公式如式(10)所示:

3.2.2 实验环境与超参数设置
实验的软件环境是Ubuntu18.04 操作系统、Pytorch1.9.1 和Cuda9.0,硬件环境是Genuine Intel®CPU @ 2.00 GHz,32 GB 内存,Tesla K80 GPU 11 GB 显存。
实验所采用的批大小设置为128。虽然可以在每次训练之前设置不同的批大小,但经过验证可知,批大小的设置应当采取折中的方案。例如当批大小设置为2、4、8 等较小的值时,虽然能够降低显存的占用,但带来了训练时间的大幅提升,而当批大小设置为512 等较大的值时,会占用5.6 GB 左右的显存,易使模型陷入局部最优状态,也会减慢模型训练的速度。因此,本文实验将批大小设置为128,使得显存占用、训练速度和模型的收敛达到一种比较理想的平衡状态。
卷积核的作用是从特征图中提取特征,其形态和大小的设置会给模型的效果造成显著影响。文献[28]研究表明,当特征图不大时,使用较小的卷积核可以获得更好的效果,相反,较大的特征图可使用稍大的卷积核。因此,本文实验将卷积核大小设置为3×3。
一般学习率的设置在0.000 1 到0.01 之间,在神经网络的训练过程中,学习率设置得过大会导致模型很容易跨越最优解,而学习率设置得过小会导致梯度更新不显著从而不能到达最优解。本文实验设置的学习率初始大小为0.002,且学习率会随着总轮数(Epoch)动态减小。文献[29]研究表明,学习率的衰减可以提升模型的泛化能力,本文实验将每10 个Epoch 作为学习率衰减的时间节点,此时将学习率设置为当前值的0.8 倍。
4 实验结果分析
4.1 激活函数对模型性能的影响
将预处理后的训练集分别输入到使用不同激活函数的STACON-ATTN 网络中得到测试模型,再将预处理后的测试集输入到测试模型中,测试结果如表3 所示。从表3 可以看出,GeLU 激活函数在数据量较多的Normal 类别和数据量较少的U2R 攻击类别中表现较好,Mish 激活函数对U2R 这种攻击类别识别的精确率比其他的激活函数高0.31 以上,使用ELU 激活函数使得模型的误报率最低降到0.029 9,而ReLU 激活函数在各项评价指标上表现均较为优秀。
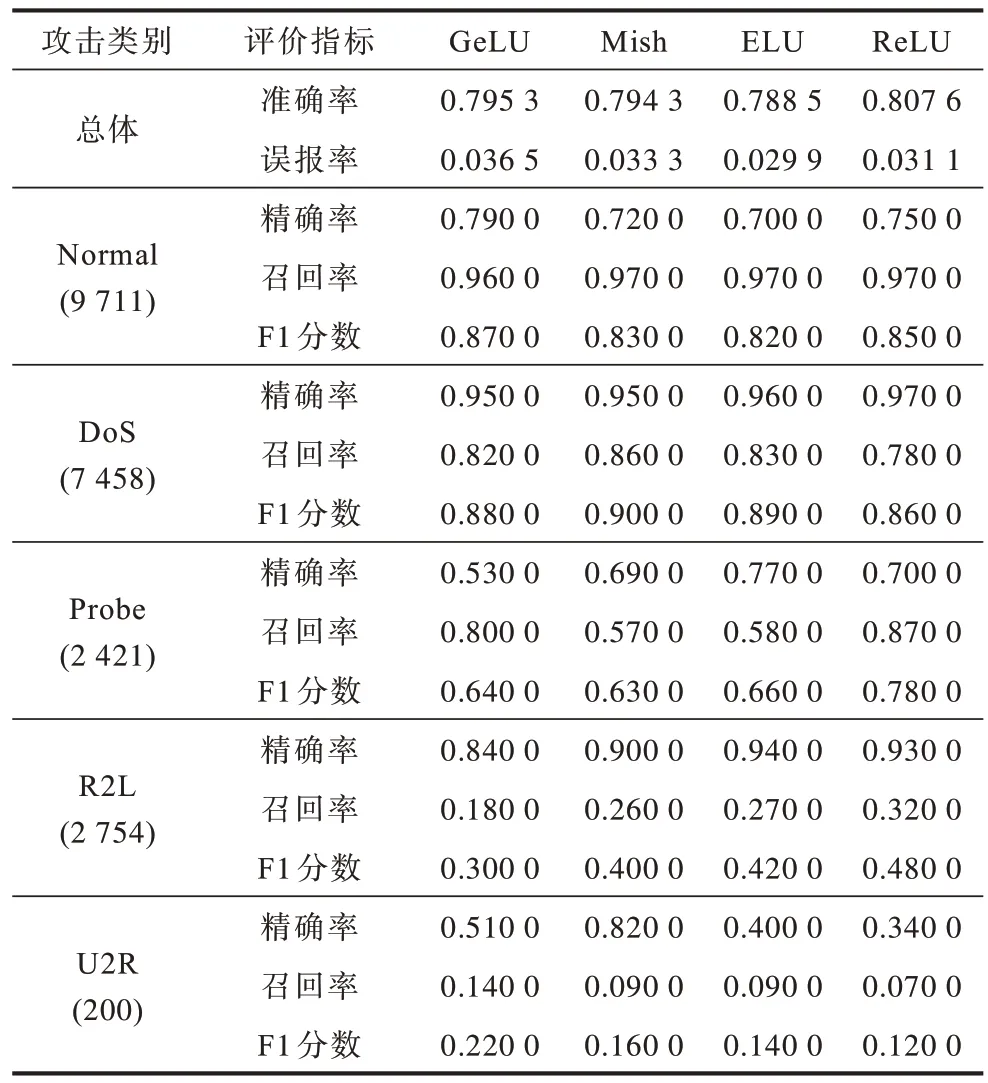
表3 各激活函数在STACON-ATTN 多分类测试中的检测效果对比Table 3 Comparison of detection effect of various activation functions in STACON-ATTN multiple classification test
4.2 不同模型在多分类情况下的性能比较
为验证STACON-ATTN 模型的多分类异常检测效果,将其与传统的机器学习方法进行对比,对比结果如表4所示,从表4可以看出,STACON-ATTN 模型对多种攻击类型检测的准确率最高(0.807 6)。除DoS 攻击类别的F1 分数略微低于KNN 和SVM 模型以外,在Normal、Probe、R2L 和U2R 攻击类型中的F1 分数都是最高的。F1分数是精确率和召回率的调和平均,同时结合了查准率和查全率,因此,F1分数能够体现出一个模型的整体质量。从表4 还可以看出,对于Normal 类别,各个模型的召回率都非常高,说明Normal 类别的样本被各个模型识别为异常的概率非常低,因此,对Normal 类别的误报率也不高。DoS 攻击类别识别的精确率要高于召回率,这说明其他类型的攻击一般不会被识别为DoS 攻击,而DoS 攻击有可能被识别为其他的攻击类别。STACON-ATTN 模型可以显著提高对Probe 和R2L攻击类别检测的召回率,说明模型已经充分学习到了这2 种攻击类别的特征。从对U2R 类别攻击的识别结果可以看出,极低的召回率明显拉低了F1 分数,说明各个模型很难学习到U2R 攻击类别的特征,这和该类别样本数较少有关。
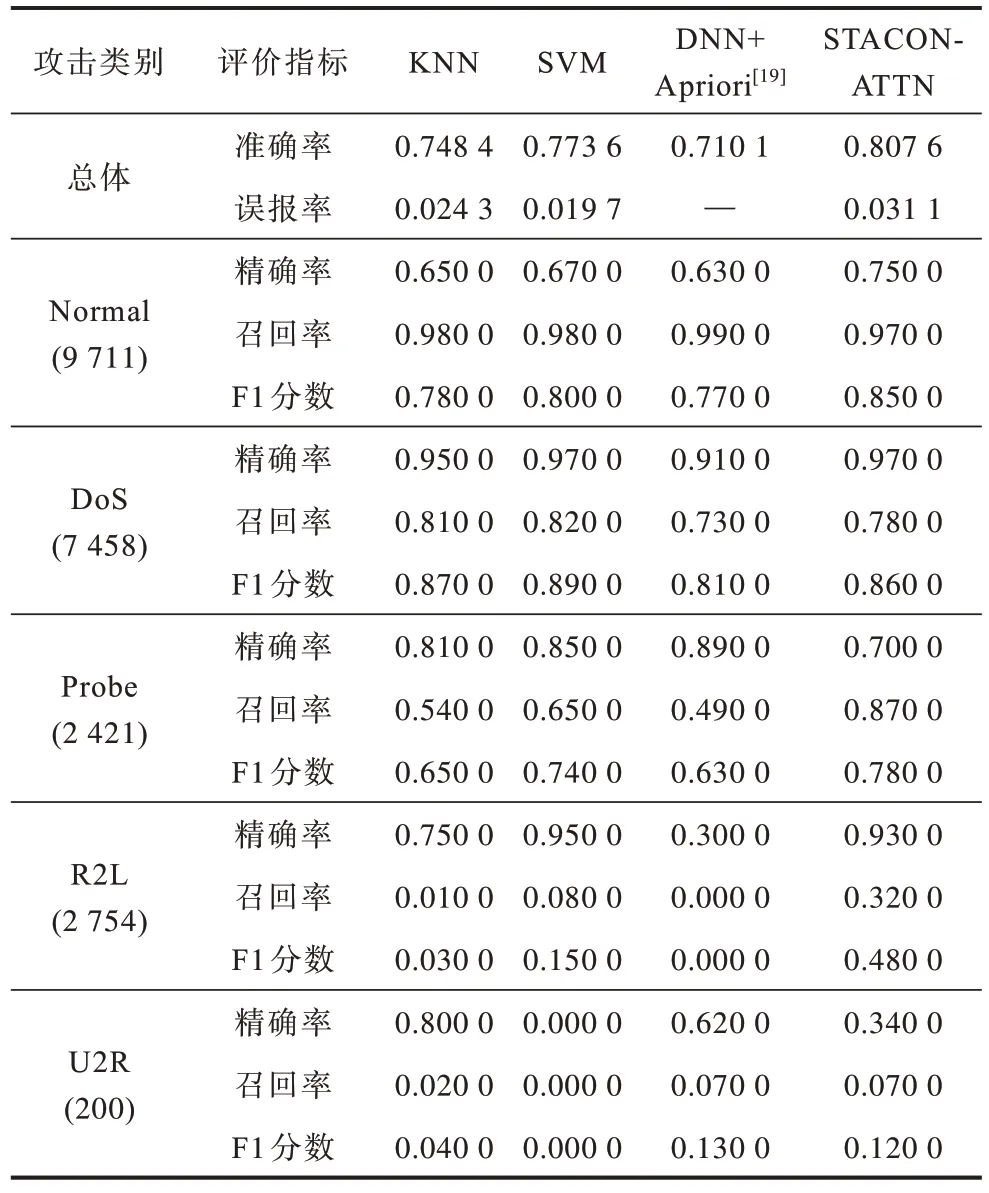
表4 STACON-ATTN 与机器学习模型的多分类性能对比Table 4 Comparison of multiple classification performance among STACON-ATTN and machine learning models
对各种攻击类别以及Normal 类别识别的ROC曲线如图3 所示,其中样本数差异较大的4 种攻击类型分别对应4 条不同的ROC 曲线。从图3 可以看出,每条曲线下方的面积(AUC 值)都超过了0.93,且最大的AUC 值达到0.97,说明本文模型对NSL-KDD数据集中各种攻击类别识别效果较好。
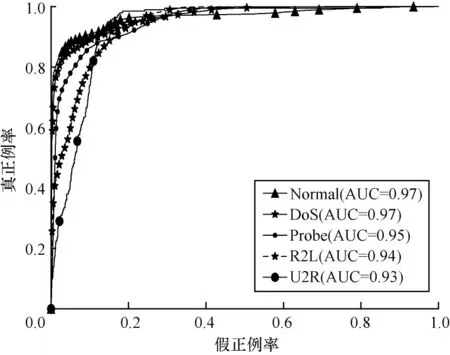
图3 多分类情况下的ROC 曲线Fig.3 ROC curve in the case of multiple classification
4.3 不同模型在二分类情况下的性能比较
为进一步验证模型效果,对NSL-KDD 数据集进行二分类的异常检测。对预处理后的多分类数据集的标签做进一步处理,得到2 种类别的数据集,其中:0 代表正常类别;1 代表异常(攻击)类别。使用新处理完成的数据集进行模型的训练和预测,并与6 种经典的分类方法以及4 种深度学习模型进行对比,对比结果如表5 所示。

表5 STACON-ATTN 与深度学习模型的二分类性能对比Table 5 Comparison of two classification performance among STACON-ATTN and deep learning models
5 结束语
本文提出一种堆叠卷积注意力网络模型用于异常流量分类和检测,并基于公开的NSL-KDD 数据集分别验证多分类和二分类异常检测性能。实验结果表明,该模型能够从输入数据中提取出有效的空间特征信息和相对位置特征信息,F1 分数和AUC 值等综合指标优于对比的机器学习方法和深度神经网络。后续将对数据预处理和样本增强过程进行优化,采用自然语言处理领域中的词嵌入技术将原始数据集中的特征表示为一种嵌入向量,在此基础上对少数类中的恶意流量数据进行样本增强,从而进一步提升对恶意流量样本的检测性能。
