参数自适应下基于近邻图的近似最近邻搜索
2022-09-15甘红楠
甘红楠,张 凯
(1.复旦大学 软件学院,上海 200438;2.复旦大学 计算机科学技术学院,上海 200438)
0 概述
最近邻搜索(Nearest Neighbor Search,NNS)是指从被检索对象集合中搜索出与给定目标最相似的一个或多个对象,其中相似程度由欧氏距离、余弦相似度等度量标准确定。在文档检索[1]、推荐系统[2]等应用程序中,图像、文档、商品等查询和检索对象被嵌入稠密连续向量,查询对象间的相关性可以表示为嵌入向量间的距离。然而,随着数据库中检索向量数量的增长和维度的增加,几乎只有扫描所有数据,才能检索到所需查询的精确最近邻[3-4],该现象被称为维度灾难[5]。线性扫描会导致搜索效率低下,无法满足大规模向量应用查询的需求。近似最近邻搜索(Approximate Nearest Neighbor Search,ANNS)通过牺牲较小的查询精度提升查询效率,并返回近似最近邻(Approximate Nearest Neighbor,ANN)[6]。
ANNS 算法主要包括基于局部敏感性哈希[7-8]、基于树结构[9-10]、基于量化[11-12]和基于近邻图[13-14]4 类算法。由于能够高效地对稠密连续向量进行ANNS,基于近邻图的ANNS算法[15]被广泛应用于人工智能相关领域,将数据库中的向量视为点,向量间的距离表示点间的距离,根据距离将它们组织成近邻图。由于近邻图结构能够灵活地表达点间的近邻关系,基于近邻图的ANNS 算法只需搜索少量的点就可以达到给定的目标召回率[16]。DiskANN[17]、HNSW[18]、NSG[16]等是近年来提出的典型的基于近邻图的ANNS 算法,搜索过程采用贪心搜索[19],从一个固定的入口点开始搜索并选择与查询向量最接近的邻居进行迭代遍历,每轮迭代中沿着近邻图遍历距离查询向量更近的点。所有遍历过的点被放入一个固定大小的动态搜索列表(Dynamic Search List,DSL),如果超过DSL 大小,离查询距离更远的点将被移出。搜索过程直到某一轮迭代中没有找到与查询向量距离更近的点为止。DSL 越大,遍历的点越多,召回率越大,但是吞吐量越小。由于不同应用程序对召回率的要求不同,用户需要手动调节DSL 大小以达到目标召回率,然而处理不同查询负载所需DSL 大小也不同,因此用户通常通过设置足够大的DSL 保证达到目标召回率,但是过大的DSL 使得基于近邻图的ANNS 算法搜索更多的点,从而大幅降低了吞吐量。
本文面向基于近邻图的ANNS 算法,提出一种参数自适应方法AdaptNNS。使用聚类方法生成分散在近邻图中不同位置的点,利用聚类中心点和最近邻分类器提取查询集合的特征,将其与不同的召回率相结合来训练梯度提升决策树(Gradient Boosting Decision Tree,GBDT)模型[20]。通过GBDT模型为查询集合预测最优DSL 大小,提升最近邻搜索的吞吐量。
1 近似最近邻搜索
1.1 相关定义
最近邻搜索的目标是在给定集合中找到与给定查询向量距离最近的向量。近似最近邻搜索通过牺牲较小的查询精度提升查询效率,以获取近似最近邻[6]。给定查询的最近邻形式化定义[21]如下:
定义1(最近邻)给定大小为N、维度为D的有限向量集合X={x1,x2,…,xN}⊂RD,表示被索引点的集合,给定查询向量q∈RD,dist 表示两个向量之间的距离,如欧式距离等。q在X中的最近邻表示如下:

召回率是衡量ANNS 结果相关性的指标。最近邻搜索通常要求返回K个最近邻。Recall@K是搜索K个最近邻时的召回率。召回率越高,返回结果与真实结果越接近。
定义2(召回率)假设集合C'包含q的K个近似最近邻、C包含q的K个真实最近邻,则Recall@K的计算公式如下:

定义3(搜索路径)在给定的图结构G上进行搜索,从点ps沿着G中的(有向)边搜索到pe,中间依次经过点p1、p2、…、pn,形成搜索路径s1:ps→p1→p2→…→pn→pe。搜索路径长度即为搜索路径中经过的边的数目,单位为跳(hop)。s1的搜索路径长度为n+1。在搜索过程中,搜索路径越长,花费时间越久。
1.2 基于近邻图的ANNS 算法
现有基于近邻图的ANNS 算法主要分为如图1所示的近邻图构建和搜索2 个阶段[15]。在近邻图构建阶段将数据库中的点组织成近邻图结构,如DiskANN 采用近似的稀疏邻域图[22]组织被检索向量、HNSW 采用近似的德劳内图[18]构建近邻图。尽管不同算法采用的近邻图结构不相同,但是它们的搜索阶段基本一致。贪心搜索广泛用于基于近邻图的ANNS 算法的最近邻搜索过程[19],如算法1 所示。概括来说,搜索算法从一个固定入口点开始搜索近邻图,通过贪心搜索逐渐接近查询向量的最近邻。在搜索过程中,算法将已访问的点存储在DSL 中,随后访问它们的邻居。当DSL 中点的数目超出指定大小时,只有与查询向量距离较近的点才会保留在DSL 中。
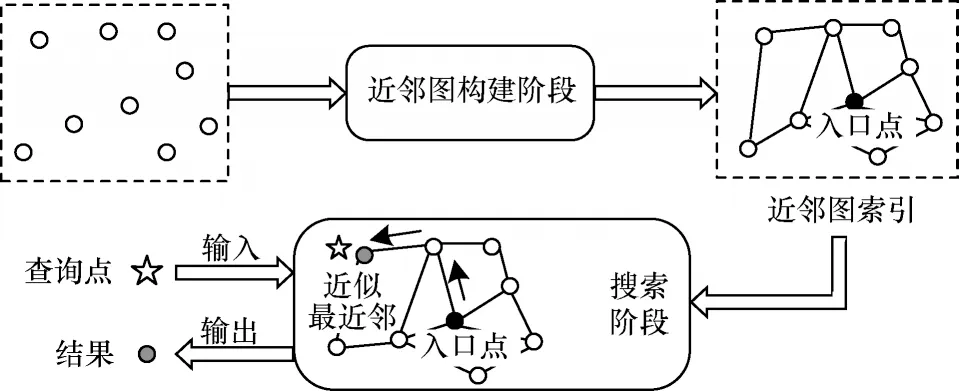
图1 基于近邻图的ANNS 算法流程Fig.1 Procedure of ANNS algorithm based on neighbor graph
算法1基于近邻图的ANNS 搜索过程


根据在多个数据集上的评测结果[23],DiskANN和HNSW 算法在搜索时的性能表现优异,并且综述文献[15]也将它们作为具有代表性的基于近邻图的ANNS 算法,因此本文以DiskANN、HNSW 算法为例,基于此实现AdaptNNS 方法,从而提高搜索性能。
2 参数自适应下基于近邻图的ANNS 算法
本节分析为基于近邻图的ANNS 算法设置过大DSL 所存在的问题,进而提出一种参数自适应方法并将其命名为AdaptNNS。AdaptNNS 方法主要包括2 个步骤:1)抽取查询负载的特征;2)在给定召回率下为查询集合预测DSL 大小。
2.1 参数设置问题分析
2.1.1 参数设置
给定一个查询集合和目标召回率,用户需要手动调节DSL 大小,使得查询集合ANNS 达到目标召回率。如算法1 所示,在搜索时每轮迭代的中间结果被放入DSL,下一轮迭代从DSL 中未被访问的点的邻居开始,新访问的点作为中间结果放入DSL。如果DSL 中点的数目超过了它的固定大小,将DSL中与查询距离最远的点删去。DSL 越大,召回率越大,相应的吞吐量越低。
不同的查询负载在不同的召回率要求下,存在一个最优的DSL 大小,可使吞吐量最大化。然而,最优的DSL 大小随查询负载和不同召回率要求而变化,用户通常会设置足够大的DSL 保证满足召回率要求,这也导致了吞吐量的大幅降低。
以图2 为例,分析DSL 过大导致的吞吐量性能低下问题。给定R2空间中的12 个向量a、b、c、d、e、f、h、i、k、m、n、o,根据它们之间的近邻关系构建近邻图,图中的边都是双向边,每个点有两条邻边,点a是搜索入口点。给定查询Q1、Q2,它们与图中所有点的距离如表1 所示。由表1 可知,当K=2 时,点n、d是查询Q1的最近邻,点c、b是查询Q2的最近邻。
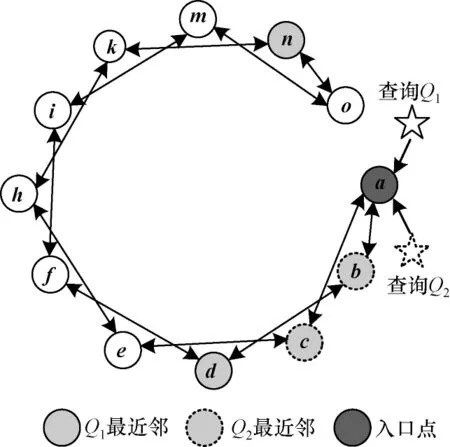
图2 近邻图实例Fig.2 Example of neighbor graph

表1 查询点与被索引点之间的距离Table 1 Distance between query points and indexed points
2.1.2 相同负载和不同召回率下的搜索吞吐量变化
对于同一个查询集合,为了达到不同的召回率目标需要设置不同大小的DSL。查询的最近邻答案有的与入口点之间的搜索路径短、有的与入口点之间的搜索路径长。因此,当要搜索更多最近邻答案(更高的召回率要求)时,必须设置更大的DSL。
以图2 中的查询Q1为例。当召回率的要求为Recall@2 不低于50%时,DSL 大小可以设为2。使用算法1 执行搜索,DSL 中点的变化过程如表2 所示,其中,DSL 列表示DSL 缓冲区中的内容;visited 列表示对应点的邻居是否被访问过,其中,√表示被访问过,×表示没有被访问过。算法1 中的循环体总共迭代了4 轮。在搜索过程中,算法总共访问过a、b、c、d、f5 个点。因为在访问f时DSL 中已经有两个元素并且f与查询Q1距离最远,所以f没有被放入DSL。因为点d、b各自的邻居到查询点Q1的距离比d、b自身到查询点的距离远,所以第4 轮迭代之后循环终止。这种现象类似数学中的局部最优。当DSL 大小为2 时,搜索算法找到了Q1的1 个最近邻d(另一个是n),召回率满足大于50%的要求。当召回率要求Recall@2 为100%时,DSL 大小则必须不小于6 才能搜索到Q1的所有最近邻。仍用算法1 进行搜索,DSL 中点的变化过程如表3 所示,第11 轮遍历点n的邻居,点n的visited 标志位变为√。算法1 中的循环体总共迭代了11 轮。在搜索过程中,算法将所有12 个点都访问了一遍。
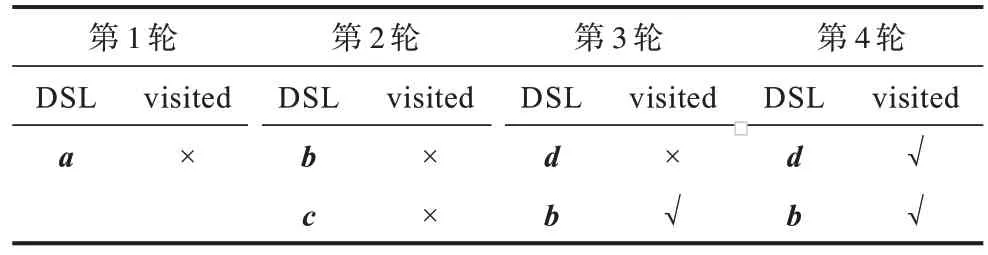
表2 搜索查询Q1时DSL 大小为2 的搜索过程Table 2 Search process of DSL size equal to 2 when search query Q1
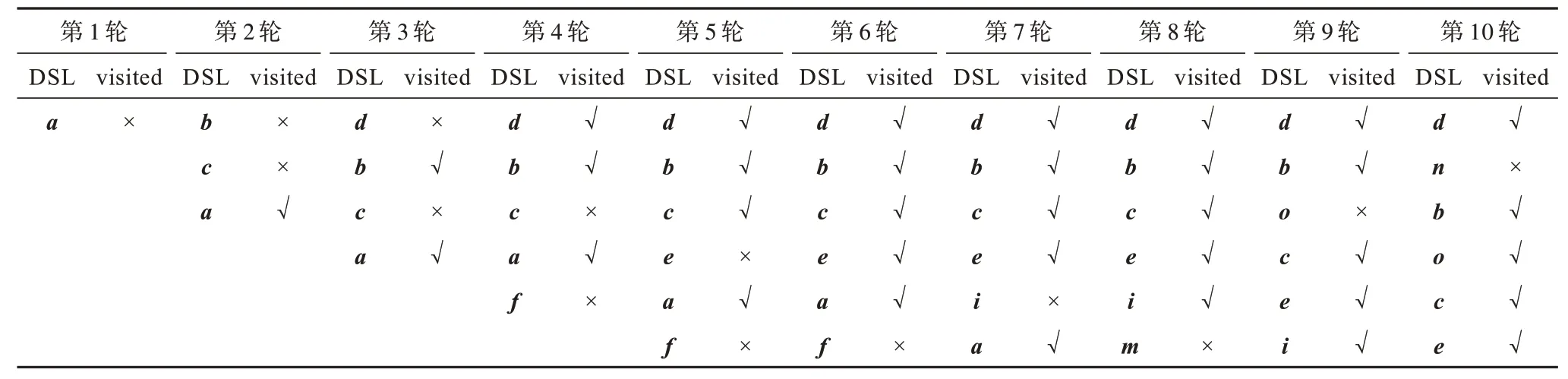
表3 搜索查询Q1时DSL 大小为6 的搜索过程Table 3 Search process of DSL size equal to 6 when search query Q1
给定查询负载q1,使用DiskANN 算法和Text-to-Image 10M 数据集(包含10 000 000 个被索引向量)进行实验。如图3 所示:当召回率目标为Recall@1不低于99%时,最优DSL 大小为40;当召回率目标为Recall@1 等于100%时,最优DSL 大小为80。由图3 可以看出,在不同目标召回率下,最大吞吐量对应的DSL 大小(最优DSL 大小)不同。如果在召回率要求大于99%时若将DSL 大小设为80,则吞吐量将下降约35%。

图3 相同查询负载和不同目标召回率下的吞吐量变化情况Fig.3 Throughput variation under the same query loads and different target recall rates
2.1.3 不同负载和相同召回率下的搜索吞吐量变化
为达到同一个召回率目标,处理不同的查询集合需要不同的DSL 大小。不同查询集合中查询的最近邻答案与入口点之间的搜索路径长度不同。因此,为搜索到相同比例的最近邻答案,最近邻答案与入口点之间距离远的查询集合在进行查询时需要更大DSL。
以图2中的查询Q1、Q2为例,Q1、Q2代表不同的查询负载。当召回率要求为Recall@2 等于100%时,处理Q1时的最优DSL 大小为6,而处理Q2时的最优DSL 大小为2。搜索查询Q2时DSL 的变化如表4 所示,循环体总共迭代4 轮,遍历a、b、c、d、e5 个点。相比于处理Q1时的11 轮循环、遍历12 个点,搜索速度更快。Q1、Q2达到相同召回率时的最优DSL 大小不同。
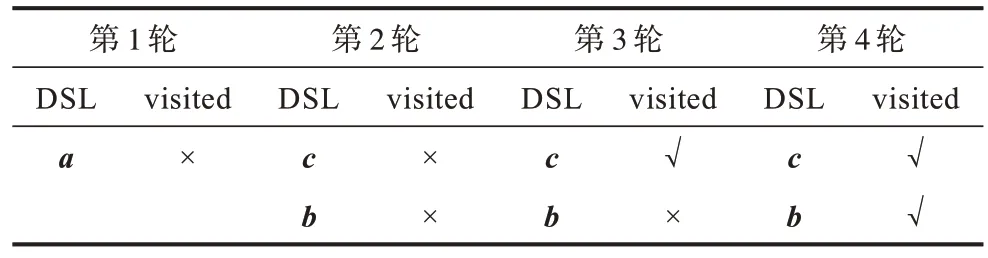
表4 搜索查询Q2时DSL 大小为2 的搜索过程Table 4 Search process of DSL size equal to 2 when search query Q2
给定不同的查询负载q11、q12、q13,使用DiskANN算法和Text-to-Image 10M 数据集(包含10 000 000 个被索引向量)进行实验。如图4 所示,当召回率要求为Recall@1 不小于94%时,q11、q12、q13的最优DSL 大小各不相同,分别为10、70、110。如果将DSL 大小统一设置为110,则虽然处理3 个负载的召回率都能满足条件,但是q11的吞吐量将下降超过50%、q12的吞吐量将下降超过20%。

图4 不同查询负载和相同目标召回率下的吞吐量变化情况Fig.4 Throughput variation under the different query loads and same target recall rates
由上述分析可知:对于相同查询负载,达到不同目标召回率时的最优DSL 大小不同;对于不同查询负载,达到相同目标召回率时的最优DSL 大小也不同。如果将DSL 设置过大,则ANNS 算法将在达到召回率要求后继续搜索,增加额外的搜索开销,导致搜索吞吐量降低。
2.2 AdaptNNS 方法
针对基于近邻图的ANNS 算法,本文提出参数自适应方法AdaptNNS。AdaptNNS 方法利用采样、聚类得到最近邻分类器,并利用其抽取查询负载的特征,同时结合查询负载的特征与不同的目标召回率训练机器学习模型,使得模型能够预测给定查询负载和目标召回率下的最优DSL 大小。AdaptNNS方法相比于人工调节参数的方法,能够在搜索效率与召回率之间达到更好的平衡。
2.2.1 模型选择
选择GBDT 作为AdaptNNS 方法中预测搜索参数的模型。GBDT 是一个基于决策树的集成模型,将上一轮迭代产生的残差作为下一轮训练的目标,通过不断减小残差实现梯度的下降,从而最小化预测误差,被认为是泛化能力较强的模型。GBDT 主要具有以下3 个优点[20]:1)能够在短时间内做出预测;2)占用内存少;3)是可解释的,可以计算每个特征的重要性,有助于特征搜索。
2.2.2 特征构建
根据上文分析可知,最优DSL 大小随着查询负载、目标召回率的不同而变化。因此,综合考虑两者构建模型特征。通过采样、聚类获取最近邻分类器,将查询负载中的不同查询进行分类。由于每种类别与入口点之间的搜索路径长度不同,影响DSL 大小设置,因此利用最近邻分类器抽取查询负载特征,再结合召回率构建模型所需特征。
1)最近邻分类器查询
首先对近邻图中的点以采样率r进行随机抽样(算法2 中的第1 行),使得采样得到的点分布在近邻图的不同位置。当总的时间开销在可接受范围内时,采样率可以设置的尽可能大(但不超过1),有利于更加准确地进行分类查询。然后将采样出的点聚类成大小相同的类簇,并选出所有类簇的中心点作为区分查询的最近邻分类器,具体为:首先用k-means++算法[24]初始化类簇中心点(算法2 中的第2 行),然后利用均衡化kmeans[25]思想(算法2 中的第3 行)保证聚类结果中每个类簇的大小近似相等(最大相差1),从而使得各个类簇的中心点不受离群点影响。
算法2查询的最近邻分类器获取


2)模型特征构建
由算法2 得到查询的最近邻分类器,即T个向量,它们分别对应T个类别。利用最近邻分类器将查询集合中每个查询向量进行分类。每个查询集合对应的特征用一个T维向量表示,每一维对应一个类别;向量表示查询集合中不同类别查询的数量。模型特征F 由表5 中的F0、F1、F2 连接而成,是一个T+2 维向量。

表5 模型特征描述Table 5 Model feature description
2.2.3 模型训练
获取不同工作负载在不同目标召回率下的最优DSL 大小,结合工作负载和召回率要求抽取特征F。特征F 和最优DSL 大小构成GBDT 模型的训练数据,然后用模型为给定查询预测在给定召回率下的最优DSL 大小。这是一个回归任务,确定DSL 大小的公式如下:

其中:Fm(x)表示最终预测DSL 大小的GBDT 模型,由m个决策树组成。当i>0 时,i表示第i棵决策树的下标,Ti(x,θi)表示第i棵决策树,x表示决策树的输入数据,θi表示第i棵决策树的参数值,λi表示第i棵决策树的权重值;当i=0 时,T0(x,θ0)与F0(x)相等(表示Fm(x)初始值)并且λ0=1。给定训练数据{(xj,yj)},xj属于特征集合F,yj表示最优DSL 大小,则训练过程如下:
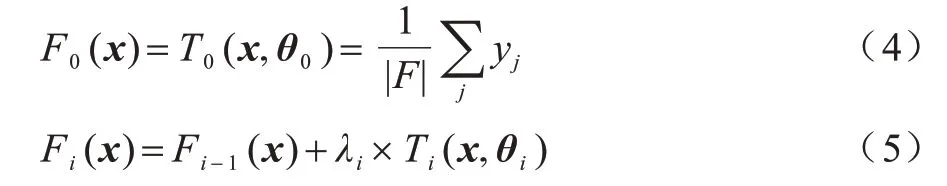
其中:Fi(x)、Ti(x,θi)均为分段函数。训练数据(xj,yj)在第i轮的残差为yj-Fi-1(xj),即决策树Ti(x,θi)需要拟合的目标值。GBDT 的训练过程是通过决策树拟合残差以及选择权重λi从而最小化损失函数的过程。本文使用平方差损失函数,其公式如下:
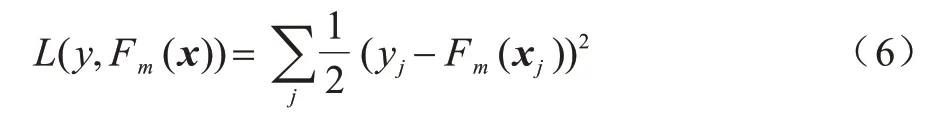
2.2.4 参数自适应的在线应用
当用户给定查询负载集合Q、目标召回率R后,将AdaptNNS 的最近邻分类器M1 和GBDT 模型M2加载到内存中,后续搜索过程如算法3 所示。首先,由最近邻分类器抽取查询负载的特征(算法3 中的第1 行)。然后,结合目标召回率和K值构建模型特征(算法3 中的第2 行)。接着,利用GBDT 模型预测最优DSL 大小(算法3 中的第3 行)。最后,使用预测的DSL 大小并行处理查询负载(算法3 中的第4~6 行)并返回结果(算法3 中的第7 行)。
算法3面向近邻图的参数自适应ANNS 算法

3 实验与结果分析
3.1 实验环境与参数设置
实验所用服务器的CPU 型号为Intel®Xeon®Gold 5218 CPU @ 2.30 GHz。使用AdaptNNS 方法优化DiskANN、HNSW 算法。DiskANN 算法常用于内存有限的场景,因此为DiskANN 分配8 个线程、4 GB 内存、1 TB 固态硬盘;HNSW 算法常用于内存充足的场景,为其分配8 个线程以及充足的内存资源。
使用Text-to-Image、DEEP、Turing-ANNS 这3 个真实世界中的数据集来分析AdaptNNS 的各项性能,数据集具体信息见表6。由于训练和测试AdaptNNS 中的模型时需要设置不同的查询负载,而这3 个数据集分别提供了真实应用中的查询集合,因此使用它们构建不同的查询负载。首先对查询进行聚类,然后随机选择不同的类簇合并为查询集合,从而得到不同工作负载的查询集合。针对每个数据集,生成1 000 个查询负载训练AdaptNNS 中的模型,利用同样的方法生成用于测试算法性能的查询负载。在训练时,目标召回率的取值范围为0.7~1.0,步长为0.02。

表6 实验数据集Table 6 Experimental dataset
AdaptNNS 方法能优化搜索参数,但不改变近邻图的构建。构建近邻图时有2 个重要参数,其中,r是近邻图中点的出度,l用于控制所构建近邻图的质量。DiskANN 和HNSW 算法需要先构建近邻图,构建近邻图的参数设置如表7 所示。由于使用不同图结构,因此它们的构图参数也不同。

表7 构建近邻图的参数设置Table 7 Parameter setting for building neighbor graphs
将对比方法记为Baseline,具体步骤为:基于近邻图的ANNS 算法人为设置DSL 大小;用户使用历史查询集合,获取达到不同召回率时的DSL 值;对于新来的查询集合,根据目标召回率选择相应的DSL值。在本文的对比实验中,将数据集提供的查询集合作为历史查询集合,将其达到指定召回率的DSL大小用于测试查询负载。
3.2 性能评估
本节对AdaptNNS 方法的性能进行端到端的评估。首先,使用DiskANN、HNSW 算法为3 个数据集构建近邻图。其次,分别使用AdaptNNS、Baseline 方法设置DSL 大小,得到各自在指定召回率要求下的吞吐量。然后,针对每个召回率,使用最优DSL 大小的方法记为Optimal,并得到对应的吞吐量。计算AdaptNNS 方法对应的吞吐量相对于Baseline 方法的提升、相对于Optimal 情况的差距,如图5 所示。从图5 可以看出:当达到相同的召回率时,相比于Baseline 方法,使用AdaptNNS 方法为DiskANN、HNSW 算法设置DSL 大小使得吞吐量有不同程度的提升,其中在HNSW 算法和Turing-ANNS 数据集上,相比于Baseline 方法,AdaptNNS 方法将相同召回率下的吞吐量提升了1.3 倍;AdaptNNS 方法相比于Optimal 情况有一定的差距,AdaptNNS 方法得到的吞吐量与Optimal 情况对应的吞吐量最大相差不超过50%(图5(f)中召回率为95%),最小相差约1%(图5(d)中召回率为94%)。
AdaptNNS、Baseline、Optimal 对应吞吐量的差别源于它们设置的DSL 大小不同。以DiskANN 算法和3 个数据集为例,进一步探究它们设置的DSL大小的差异。表8 分别给出了Baseline 和AdaptNNS方法设置的DSL 大小与最优DSL 大小(Optimal 情况)之间相差的比率。由表8 可以看出,在给定目标召回率下,AdaptNNS 方法设置的DSL 大小与最优DSL 大小的误差比Baseline 方法的更小。表9 分别给出了AdaptNNS 方法和Baseline 方法在不同召回率下平均访问的点的数目,前者相对于后者访问的点更少,最多可少访问62%的点。

表8 AdaptNNS 和Baseline 方法设置的DSL 大小与最优DSL 大小的差距对比Table 8 Comparison of difference between the DSL size set by AdaptNNS or Baseline methods and the optimal DSL size

表9 AdaptNNS 和Baseline 方法的平均访问点数对比Table 9 Comparison of the average number of points accessed by AdaptNNS and Baseline methods
根据文献[16],使用不同的K值(对应召回率Recall@K中的K)大小来控制近似最近邻与真实最近邻的近似程度。若K值越小,则要求搜索结果的近似程度越大。本文使用DiskANN 算法并将K值分别设为1 和10 进行实验,探究不同近似程度要求对AdaptNNS 性能的影响。K=10 时的实验结果如图6 所示,在不同数据集上,AdaptNNS 对应的吞吐量高于Baseline 方法,可高出1 倍多;在AdaptNNS与Optimal 情况下的吞吐量最少相差不到1%。结合图5(a)、图5(b)、图5(c)可知,在不同近似程度下(K为1 或10),AdaptNNS 方法的吞吐量均比Baseline 方法高。

图6 AdaptNNS 方法对吞吐量的影响(K=10)Fig.6 Effect of AdaptNNS method on throughput(K=10)
4 可扩展性分析
AdaptNNS 方法针对4 类ANNS 算法中的基于近邻图的ANNS 算法(以DiskANN 和HNSW 为例)而设计,基本原理为:给定目标召回率,结合查询特征,通过机器学习算法调节平衡召回率和搜索开销的相关参数,使得ANNS 的召回率达到指定目标的前提下提升搜索速度。如1.2 节所述,基于近邻图的ANNS 算法中都需要将DSL 大小作为参数,该参数平衡搜索召回率和开销,由机器学习算法调节。AdaptNNS 方法框架同样适用于其他3 类ANNS 算法,具体如下:基于量化的ANNS 算法将向量进行压缩编码,编码长度越短搜索越快,但是精度越低;基于局部敏感性哈希的ANNS 算法将被检索向量进行分桶,分桶粒度越大搜索越快,但精度越低;基于树的ANNS 算法在搜索时允许回溯、遍历树的不同分支,最大回溯次数越少搜索越快,但精度越低。因此,可以利用机器学习算法动态设置相关参数(如编码长度、分桶粒度、最大回溯次数),使得ANNS 达到指定召回率的同时提升搜索速度。
5 结束语
为优化现有基于近邻图的ANNS 算法的参数设置,本文提出一种搜索参数自适应的方法AdaptNNS,根据查询负载的特征以及目标召回率自适应调整DSL 大小。使用DiskANN 和HNSW 算法在3 个数据集上进行实验,结果表明在相同目标召回率下,AdaptNNS 方法的吞吐量比Baseline 方法的吞吐量最高提升了1.3 倍,与Optimal 情况下的吞吐量最少相差不到1%。下一步拟将AdaptNNS 方法应用于更多的基于近邻图的ANNS 算法,以验证AdaptNNS 方法的通用性,并尝试使用模型预测基于近邻图的ANNS 算法的搜索入口点、最大搜索深度等参数,进一步提升ANNS 算法的搜索效率。
