融合多模态数据的人体动作识别方法研究
2022-09-15马亚彤刘英芳
马亚彤,王 松,2,刘英芳
(1.兰州交通大学 电子与信息工程学院,兰州 730070;2.甘肃省人工智能与图形图像处理工程研究中心,兰州 730070)
0 概述
人体动作识别是指根据传感器捕获的行为数据识别人类执行的动作[1]。人体动作识别技术被广泛应用于各个领域,主要包括监控、视频分析、辅助生活、机器人技术、远程医疗和人机交互,同时它也是健身训练和康复医疗的一部分[2]。
早期的人体动作识别研究的数据主要采用RGB摄像机、Kinect 传感器和可穿戴惯性传感器等单模态传感器收集。其中,利用传统的RGB 摄像机获取2D 图像,对光照条件、复杂的背景和部分遮挡等影响因素非常敏感,并且RGB 摄像机获取的2D 图像包含被拍摄者大量的隐私信息。与RGB 相机相比,深度传感器提供了3D 动作数据,在采集时对光线变化和照明程度不太敏感,所需的资源较少,并且可以很好地保护被监视人员的隐私信息,如室内监控系统,保护隐私信息是一个需要考虑的问题。但是,在深度图像的采集过程中,如视点变化、噪声等都对采集结果存在一定影响[3],而这些缺点可以在多模态人体动作识别中通过使用可穿戴惯性传感器采集的数据来解决。可穿戴惯性传感器的主要部件包括加速度计和陀螺仪,主要用于提供加速度信号数据和角速度信号数据。与深度传感器类似,可穿戴惯性传感器以高采样率的形式提供3D 动作数据,可以在环境复杂的条件下工作,其局限性主要是传感器采集数据的漂移[4]。因此,单一传感器模式很难满足实际应用需求。
针对单模态存在RGB 图像遮挡、深度传感器环境噪声、可穿戴传感器数据漂移等问题,本文提出一种基于深度和惯性传感器的多级多模态融合的人体动作识别框架,从不同模态中获取互补信息,找到不同模态的最佳融合阶段。在此基础上,采用特征级融合,在每个模态中分别增加一个附加模态提取互补特征,来弥补两种类型传感器的不足,以准确地执行分类任务,从而提高人体动作识别的性能。
1 相关工作
为满足人体动作识别在实际应用场景中的要求,提高人体动作识别效率,国内外学者聚焦于多模态感知融合,通过对两种或两种以上的不同传感器模式进行融合,以达到提高识别率的目的。
CHEN 等[2,5-6]提出基于深度相机和惯性传感器两种不同模态传感器的融合方法,并采用协同表示分类器对特征级融合和决策级融合进行了研究。DAWAR 等[7-9]提出一种基于卷积神经网络的传感器融合系统,从连续动作流中检测和识别感兴趣的动作,最后使用决策级融合实现动作识别。LIU 等[10]在隐马尔科夫模型框架内融合惯性传感器和视觉传感器的数据,提高手势识别的准确性。TU 等[11]提出一种新颖的基于人类相关区域的多流卷积神经网络,其中通过改进前景检测,可以在现实情况下稳健地检测与演员的外观和运动相对应的感兴趣区域。HWANG 等[12]利用单个固定摄像机的RGB 图像和单个手腕惯性传感器获取的数据进行传感器与人体动作识别的融合,通过这两种不同信息的互补,弥补基于RGB 和基于惯性传感器的人体动作识别方法的不足。KAMEL 等[13]在3 个卷积神经网络通 道分别使用深度运动图像、深度运动图像和关节点、仅使用关节点进行训练,并将3 个通道生成的动作预测相融合用于最终的动作分类。LI 等[14]实现了在不同传感器采集的实验数据中提取特征信息融合,指出使用单个传感器的性能限制,并且通过组合异构传感器的信息提高系统的整体性能。
多模态融合的方法主要是对模型的数据级(原始级)、特征级和决策级(评分级)之间进行模态的融合[15]。数据级的缺点是对传感器提供的数据未进行任何处理即组合到一起;决策级的缺点是需要多个分类器来训练和测试多个模态,且决策级所需的相关数据不能在早期阶段进行组合。由于特征级包含了比数据级或分类器输出的决策级更丰富的输入特征信息,因此特征级的模型融合效果更好。同时,特征级融合了从模式中收集和集成相关的并发信息,而这些信息是分类器做出正确决策所必须的。AHMAD 等[16-17]在提出的深度多模态融合框架上通过训练深度和信号图像,将提取的特征相融合形成共享的特征层,将这些特征反馈给分类器,并利用多级融合的优势提高人体动作识别的精度。EHATISHAM 等[18]提出一种基于特征级融合的人体动作识别方法,该方法利用视觉和惯性两种不同感知方式的数据,采用有监督的机器学习方法,融合从单个感知模式中提取的特征来识别动作。RADU等[19]采用深度学习算法来解释多传感器系统捕获用户活动的上下文的优点。
2 多模态融合框架
本文提出的多模态网络融合框架是建立在仅通过卷积神经网络处理的单模态模型上,利用残差网络充当特征提取器,执行两阶段的特征拼接,最后进行基于判别相关分析[20](Discriminant Correlation Analysis,DCA)的多级特征融合。多模态融合框架如图1 所示。ResNet101 从深度运动投影图[21](Depth Motion Maps,DMM)和经过局部三值模式[22](Local Ternary Patterns,LTP)处理过的深度运动投影图中提取特征。同理,ResNet101 从信号图像和经过LTP 处理过的信号图像中提取特征,分别对提取到的特征进行特征级联。然后将特征级联得到的两个特征进行基于DCA 的融合,并与简单的特征向量拼接相比,DCA 将会产生高度区分的特征。最后将该特征向量作为支持向量机(Support Vector Machine,SVM)的输入,以实现对人体动作识别的研究。
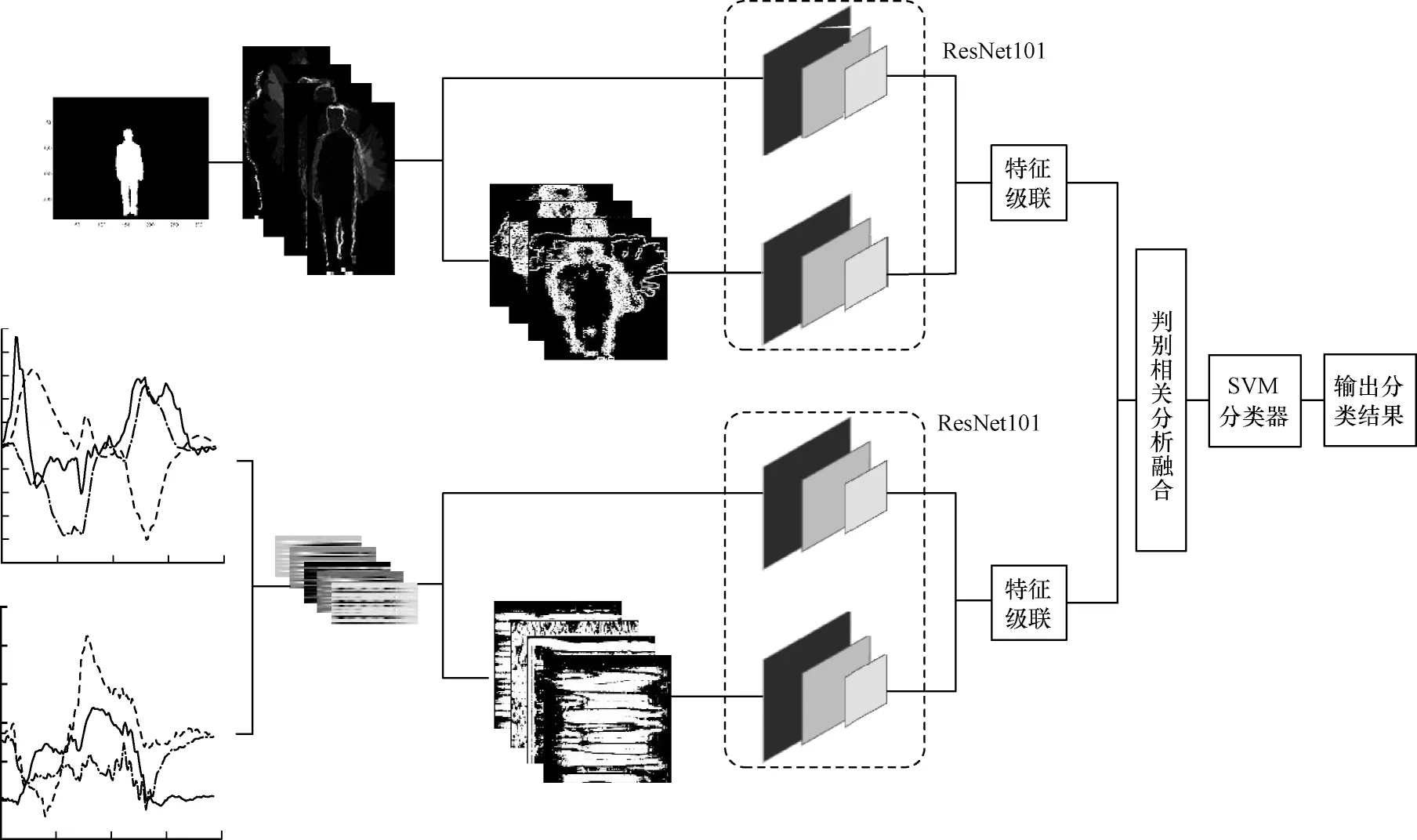
图1 多级多模态融合框架Fig.1 Multi-level multimodal fusion framework
2.1 信号图像
可穿戴惯性传感器中的惯性测量单元为加速度计和陀螺仪,用来测量加速度信号和角速度信号。加速度计和陀螺仪的组合比单独使用加速度计能获得更好的结果[23]。惯性传感器以多变量的时间序列生成数据。在UTD-MHAD 中有6 个信号序列,图2所示为角速度信号和加速度信号,其中,G-X、G-Y、G-Z 分别表示X、Y、Z 的角速度,A-X、A-Y、A-Z 分别表示X、Y、Z 的加速度。
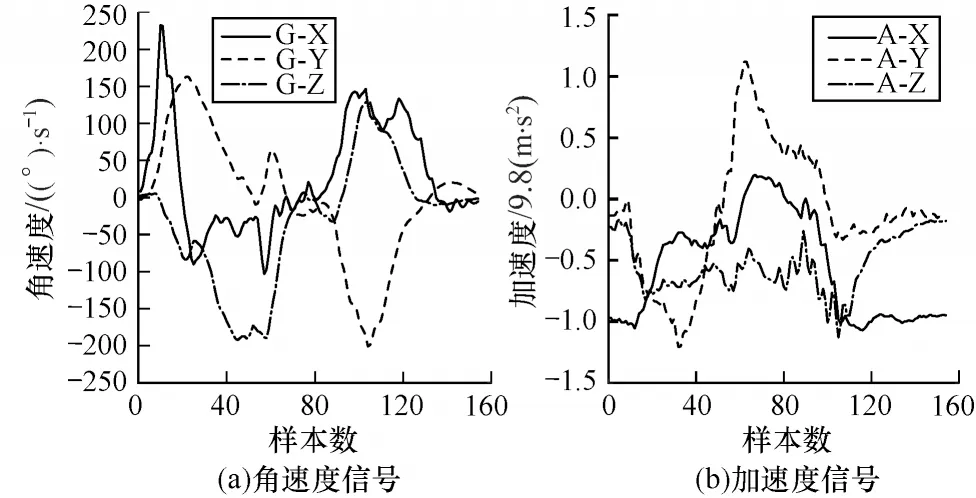
图2 三轴加速度信号和三轴角速度信号Fig.2 Tri-axis acceleration and tri-axis angular velocity signals
在文献[23]算法的基础上,本文将可穿戴惯性传感器采集到的6 个信号序列逐行堆叠以形成信号图像。在形成的信号图像中,任何一个信号序列都与其他5 个信号序列相邻,使残差网络可以提取各个相邻信号序列之间的隐藏相关性,并且可以充分利用各个信号序列之间的时间相关性。其中,6个信号序列的行堆叠顺序为:123456135246141525364326。
在上述堆叠顺序中,数字1~6 表示原始信号中对应的6 个序列号。序列号的顺序表明每个序列都和其他序列相邻以形成信号图像,每个信号在修改后的信号图像中出现4 次,所以信号图像的最终宽度是24。
信号图像的长度通过数据集中信号数据的采样率确定,而数据的采样率为50 Hz。为保证能够准确捕捉信号图像的运动,本文将信号图像的长度确定为50,则最终确定的信号图像的大小为24×50 像素。图3 所示分别对应不同动作的信号图像,每一个类别的信号图像都不同于其他类别的信号图像,这些图像中的视觉差异表明卷积神经网络可能提取有区别的图像特征进行人体动作识别。

图3 不同动作的信号图像Fig.3 Signal images of different actions
2.2 深度运动投影图
人体动作视图中的深度视频是一组深度图像序列,包含了相当丰富的时空信息。根据深度视频序列对人体动作进行识别,不仅要考虑人体动作在每一时刻的信息,还要考虑人体动作的累加效果的影响。深度图像用来捕捉人体的三维结构信息,使用DMM 表达人体动作的几何形状和特点。YANG等[24]提出的深度序列图像投影到3 个正交笛卡尔平面上,用于表示人体动作的运动过程。本文计算的DMM 为两个连续帧之间的差值,对于具有N帧的深度视频序列由式(1)计算获得:
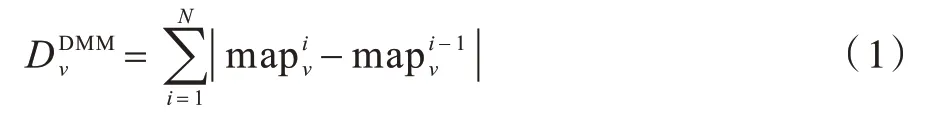
其中:i表示每一帧图像的索引;表示第i帧人体动作图像在平面v下的投影图,v∈{f,s,t},f、s、t分别表示正面、侧面和水平投影图。
本文实验中形成的DMM 并不是深度序列图像中的所有帧。数据集中的不同人体动作视频序列形成的大小不相同,因此利用双三次插值将人体动作视频序列形成的所有调整为大小相同,以减少每个组内的变化。图4 所示为一组“由坐到站”深度帧序列到合成DMM 的过程,其中左边是深度序列图像,右边依次是DMM 的前视图、侧视图和顶视图。
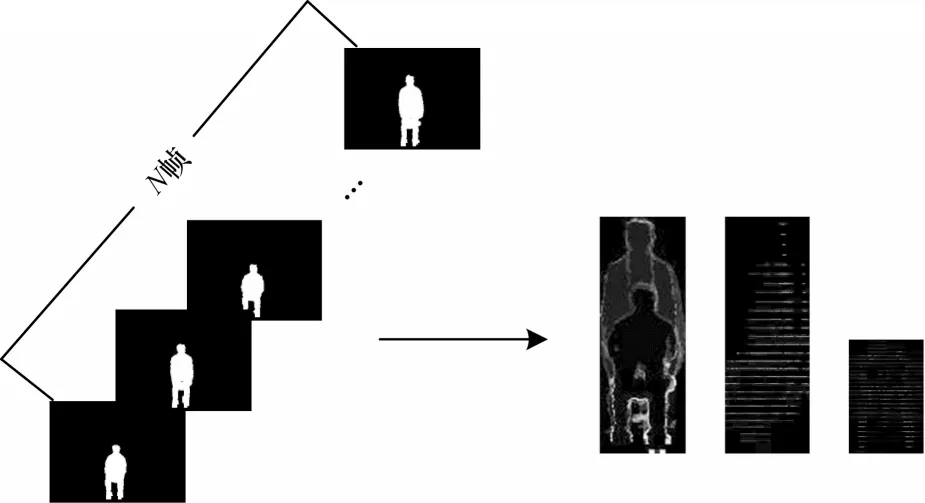
图4 DMM 的形成过程Fig.4 The formation process of DMM
2.3 局部三值模式
TAN 等[22]提出一种新的纹理算子LTP 对噪声更加鲁棒。应用LTP 为数据集创建了一个附加模态,附加模态的目的是使ResNet101 网络能够进一步提取不同模态的互补性和鉴别性的特征,丰富特征的可用性并且有助于分类器准确执行人体动作的分类任务。其中,在宽度范围内的灰度量化为0,高于此范围的灰度量化为+1,低于此范围的灰度值量化为-1,LTP 的数学表达式如式(2)和式(3)所示:

其中:gc表示圆的中心像素的灰度值;gb表示分布在半径为R的圆的相邻像素的灰度值;t为设定的阈值。
2.4 判别相关分析
典型相关分析[25](Canonical Correlation Analysis,CCA)是一种将两个多维变量之间的线性关系进行相关分析的方法。由于CCA 融合中忽略了样本之间的类结构,因此消除了特性之间的关系。为了解决基于CCA 的多模态融合中存在的问题,本文提出了基于DCA 的多级多模态融合框架。DCA 是一种特征级融合技术,在类融合中考虑了类结构,并且将类中的关联信息纳入特征级相关分析中,同时消除了类间相关性并将相关性限制在类内,有助于在人体动作识别中融合由不同传感器捕获的数据之间的相关性信息,并且最大化两个特征级之间的成对相关性。

通过映射Q→ΦbxQ获得Sbx的r个特征向量,如式(7)所示:
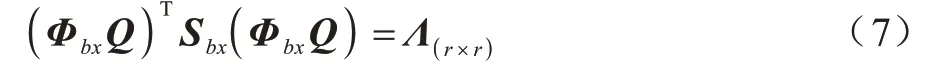
设Wbx=ΦbxQΛ-1 2是将Sbx白化并将数据矩阵X的维数由p降为r的变化,如式(8)和式(9)所示:

其中,X′是X的空间投影;I为类分散矩阵。
与上述方法类似,计算第2 个特征集Y和变换矩阵Wby,Wby使第2 个模态Sby的类间散度矩阵单位化,并将Y的维数由q降为r,且矩阵是严格对角占优矩阵。将变换后的特征集的集合间相关矩阵使用奇异分解值(SVD)对进行对角化,即,使一个集合中的特征与另一个集合中相应的特征具有非零相关性,如式(10)所示:

其中:X′和Y′的秩为r;是非退化矩阵;Σ是一个主对角元素非零的对角矩阵。设Wcx=UΣ-1 2和Wcy=VΣ-12,则有:

因此,对特征集进行如下转换,如式(12)和式(13)所示:

DCA 的特征级融合与CCA 类似,通过对变换后的特征向量进行拼接或求和实现。由于变换后的特征向量求和时,特征向量维数较少,计算简单方便,因此本文实验采用基于DCA 求和的方法进行特征级融合。
3 实验结果与分析
3.1 实验平台
本文实验环境为:Windows 10.0 操作系统,Intel®Xeon®Gold 5115 CPU@2.40 GHz,显卡NVIDIA Quadro P4000 GPU,采用Matlab 2019b 作为开发环境。
3.2 数据集及数据预处理
为验证所使用的多模态融合技术在人体动作识别方面的识别效率,本文使用UTD 多模态人类行为数据集[26](UTD-MHAD)和UTD Kinect V2 多模态人类行为数据集[27](UTD Kinect V2 MHAD)两个公开的数据集进行实验验证,并与最新的研究进行比较,同时采用消融实验验证本文提出的多模态融合框架的有效性。
UTD-MHAD 是使用Microsoft Kinect 传感器和可穿戴惯性传感器在室内环境中收集的。由8 名受试者(4 名女性和4 名男性)执行的27 个动作,每个受试者对每个动作重复4 次。去除3 个损坏的序列后,数据集共有861 个数据序列,包含深度传感器数据和惯性传感器数据。
UTD Kinect V2 MHAD是使用第2 代Kinect 捕获的新数据集,包括6 名受试者(3 名男性和3 名女性)执行的10 个动作,每个受试者重复每个动作5 次,包含深度传感器数据和惯性传感器数据。采用深度传感器数据生成的深度图像大小为424×512 像素。
本文选择UTD-MHAD 和UTD Kinect V2 MHAD两个数据集。首先使用的两个数据集用于涉及融合或同时使用深度传感器和惯性传感器。其次使用的两个数据集中的动作包含了比较全面的人体动作类别,如运动动作(篮球投篮,打保龄球,棒球挥杆,网球挥杆和网球发球)、手势动作(手臂向左滑动,手臂向右滑动,右手挥手,拍手,投掷,胸前手臂交叉,画x,画三角形,画勾,顺时针画圆,逆时针画圆,手臂卷曲,双手推,右手抓住物体和右手捡起东西并投掷)、日常动作(敲门,慢跑,步行,由坐到站和由站到坐)和训练动作(拳击,弓步,深蹲)。
由于UTD-MHAD 和UTD Kinect V2 MHAD 数据集中视频序列的前5 帧和后5 帧大多处于静止状态,动作比较轻微,对提取到的特征影响比较小,并且在转换为DMM 时,微小的动作会导致大量的重建误差。因此,在生成DMM 时需要删除影响较小的开始5 帧和最后5 帧的运动帧序列,使用剩余帧生成DMM。生成的DMM 图像与信号图像如图5所示。

图5 UTD-MHAD 和UTD Kinect V2 MHAD 数据集预处理后生成的DMM 和信号图像Fig.5 DMM and signal images generated after pre-processing of UTD-MHAD and UTD Kinect V2 MHAD datasets
为克服UTD-MHAD 和UTD Kinect V2 MHAD数据集中训练样本较少的问题,本文对原始数据生成的DMM 和信号图像分别进行数据增强[17],并将增强的数据集按照80%和20%的比例分为训练集和测试集。表1 所示为UTD-MHAD 和UTD Kinect V2 MHAD 的训练集和测试集的样本。

表1 UTD-MHAD 和Kinect V2 MHAD 在数据增强后的训练集和测试集Table 1 Training and test sets of UTD-MHAD and Kinect V2 MHAD after data enhancement
通过随机选择相同百分比的训练和测试样本进行20 次实验,并计算平均精度。为了对ResNet101 进行训练,将图像大小调整为224×224像素,直到验证损失停止。此外,为了和AHMAD等[16]的实验相比,训练过程中的详细实验参数如表2 所示。

表2 训练参数Table 2 Training parameters
3.3 消融实验
本文以图6 所示的融合框架为基础,验证本文中提出的多级多模态融合框架中各个部分的有效性,以及使用基于DCA 多模态融合的有效性。

图6 消融实验融合框架Fig.6 Ablation experimental fusion framework
3.3.1 深度运动投影图和信号图像
本文在如图6 所示的基础多模态融合中分别与使用DMM 和信号图像融合的实验进行比较。从表3 可以看出,在UTD-MHAD 和Kinect V2 MHAD 数据集中DMM 和信号图像的融合识别精度更高,因此DMM 相比深度序列图像能得到较高的识别准确率。

表3 DMM 和深度序列图像与信号图像的CCA 融合Table 3 CCA fusion of DMM and depth sequence image with signal image %
3.3.2 局部三值模式
2.3 节提出的基于LTP 处理的DMM 和信号图像,在图像预处理阶段增加一个通用的模态,使输入模态进一步成为多模态。从表4 的实验结果可以看出,创建的附加模态使ResNet101 进一步提取互补性和鉴别性的特征,因此更丰富的特征有利于提高SVM 分类器的准确率。

表4 DMM、深度序列图像和信号图像的LTP模态Table 4 DMM,depth sequence image and signal image with LTP modality respectively %
3.3.3 判别相关分析
基于DCA 的特征级融合消除了类间相关性并将相关性限制在类内,有利于不同传感器捕获数据信息之间的融合。从表5 的实验结果可以看出,基于DCA 的多模态融合相较于CCA 的多模态融合,进一步证明了基于DCA 的特征级融合在多模态融合中的优势。

表5 DCA 与CCA 的实验结果Table 5 Experimental results of DCA and CCA %
3.4 结果分析
对于UTD-MHAD 中的27 个动作类别在多级多模态融合后的混淆矩阵如图7 所示。从图7 可以看出,尽管多模态融合会误判个别动作类别,但是整体表现较好。因为在错误分类的动作中,除了极为相似的动作外,其余动作的识别率为100%。不同方法对UTDMHAD 中深度和惯性分量融合的精度对比如表6 所示。其中AHMAD 等[16]采用基于CCA 的特征级融合对不同模态的特征进行融合。相比之下,本文所使用的多级多模态融合识别率更高,证明DCA 对多模态融合的人体动作识别性能更好。

表6 UTD-MHAD 中不同方法融合方式的识别准确率对比Table 6 Comparison of recognition accuracy of different method fusion modes in UTD-MHAD %
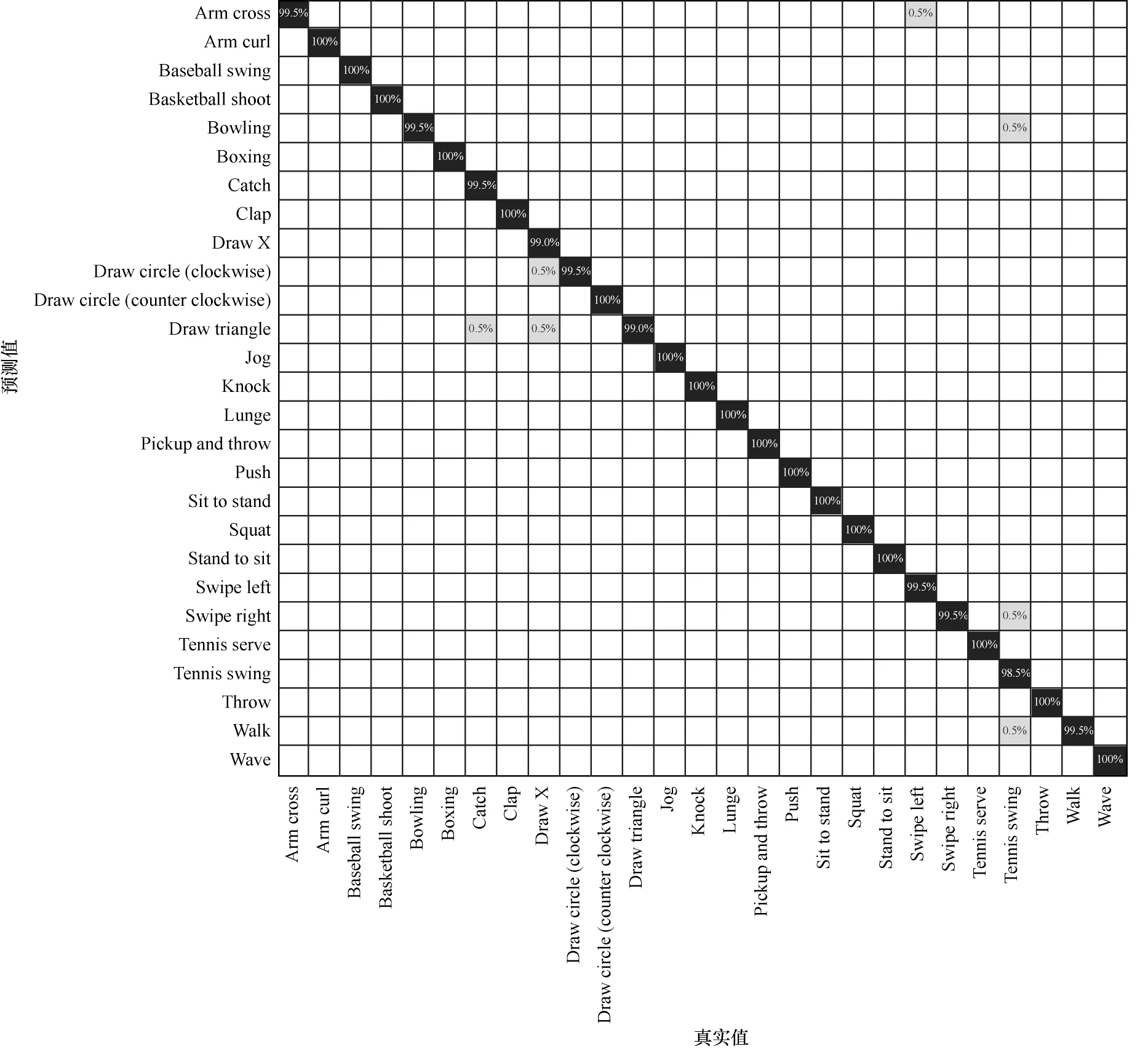
图7 多级多模态融合在UTD-MHAD 数据集上的混淆矩阵Fig.7 Confusion matrix of multi-level multimodal fusion on the UTD-MHAD dataset
对于Kinect V2 MHAD 中的10 个动作类别在多级多模态融合后的混淆矩阵如图8 所示。在融合UTD Kinect V2 MHAD 数据集中的深度和惯性数据,本文方法与其他不同方法的比较如表7 所示。与AHMAD 等[16]提出的方法相比,本文提出的多级多模态融合方法识别性能更好,相较于最新的研究识别进度有所提高,证明了该方法的有效性。UTD Kinect V2 MHAD 与UTD-MHAD 数据集相比,不同类间区分度更高。这也是UTD Kinect V2 MHAD 的识别精度高于UTD-MHAD 的原因。在训练样本较少的情况下,基于深度学习的分类模型通常会有潜在的过拟合影响,导致模型在训练集上的误差很小,而在测试集上的误差不够理想。因此,本文首先在数据预处理阶段对数据集进行数据增强处理,然后通过ResNet101 训练深度模态和惯性模态,在模型中使用BN、L2 正则化和Dropout 层用来抑制过拟合。在两个数据集上的训练与测试误差如图9 所示,从图9 可以看出,本文的实验没有出现过拟合。

图9 UTD-MHAD 和UTD Kinect V2 MHAD 数据集的损失变化曲线Fig.9 Loss variation curves for UTD-MHAD and UTD Kinect V2 MHAD datasets
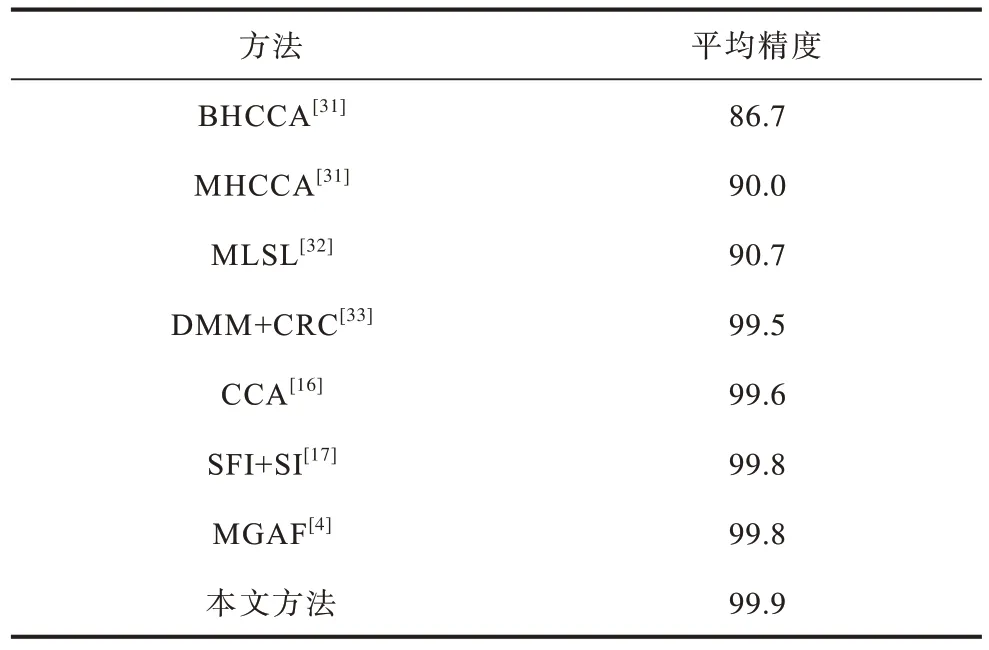
表7 Kinect V2 MHAD 中不同方法融合方式的识别准确率对比Table 7 Comparison of recognition accuracy of different method fusion modes in Kinect V2 MHAD %

图8 多级多模态融合在Kinect V2 MHAD数据集上的混淆矩阵Fig.8 Confusion matrix for multi-level multimodal fusion on the Kinect V2 MHAD dataset
UTD-MHAD 对训练卷积神经网络主要有以下3 个局限:1)可穿戴惯性传感器佩戴在志愿者的右手腕或者右大腿上,而传感器仅佩戴在两个位置上,用于收集27 个动作的数据,不足以捕获所有数据的相关性和特征;2)当使用UTD-MHAD 训练深度网络时,由于数据集的样本数据较少,可能导致训练结果不够准确;3)在UTD-MHAD 中,有部分动作的区分度不明显,例如,右臂向左滑动和右臂向右滑动,由坐到站和由站到坐具有很高的相似性。
4 结束语
为解决单模态人体动作识别方法在实际应用场景中的局限性和CCA 融合忽略样本间类结构等问题,本文提出一种基于DCA 的多级多模态融合的人体动作识别方法。该识别方法从不同模态或者特征集捕获与其他模态或者特征集互补的信息,找到不同模态的最佳融合阶段,多模态融合的人体动作识别可有效解决单模态方法的局限。实验结果表明,本文提出的多模态融合方法具有较高的识别准确率。下一步把神经架构搜索技术应用到多模态融合动作识别中,利用其可以对不同时期网络自动确定网络结构的特性,将通过卷积神经网络提取到的不同模态的特征,利用神经架构搜索技术自动搜索其融合结构,从而提高多模态人体动作识别的效率。
