领域专用低延迟高带宽TCP/IP 卸载引擎设计与实现
2022-09-15冯一飞叶钧超柴志雷
冯一飞,丁 楠,叶钧超,柴志雷,3
(1.江南大学 物联网工程学院,江苏 无锡 214122;2.江南大学 人工智能与计算机学院,江苏 无锡 214122;3.江苏省模式识别与计算智能工程实验室,江苏无锡 214122)
0 概述
随着网络带宽飞速增长,网络传输占用的CPU资源正逐年上升。以24 核计算型服务器为例,网络传输在25 GB 网络环境下占用CPU 资源的25%;当升级到100 GB 网络时,CPU 资源将被100%占用,导致算力资源严重缺乏[1-2]。此外,传统软件处理网络堆栈的方式存在吞吐率低、毫秒级别的套接字机制和软件处理延迟等问题,且由于CPU 的主频动态调整机制、操作系统的进程调度等因素,导致延迟具有不稳定性[3],使得基于CPU 的软件方案难以应用于高频通信传输等对延迟敏感的场景[4]。
在后摩尔时代,CPU 频率已趋于稳定,计算能力增速远低于网络传输速率的增速,且差距持续增大[5],预计至2025 年,算力差距将大于60 Gb/s[6]。因此,将网络协议等计算任务卸载到现场可编程门阵列(Field Programmable Gate Array,FPGA)等硬件的需求愈发急迫。随着市场规模不断扩大,各种应用场景不断出现,且在特定场景中不需要完整的传输控制协议/互联网协议(Transmission Control Protocal/Interner Protocal,TCP/IP)协议栈,这为采用纯硬件提供了可行性。如在量化高频交易场景下[7],仅需TCP 协议中数据收发、重排等基础功能即可满足通信功能需求。因此,领域专用TCP/IP协议与硬件加速相结合成为解决特定场景带宽和延迟问题的有效手段。
文献[8]提出一种针对高频交易的基础网络实现方案,使用高级合成(High-Level Synthesis,HLS)开发语言对UDP 协议进行实现,在配合交易算法的情况下,能使延迟小于870 ns。文献[9]提出一种基于SDAccel 开发的系统,使用HLS 实现了10 Gb/s TCP 协议和IP 协议的功能。文献[10]针对量化高频交易中的订单查询功能,使用VHDL 开发语言进行实现,最低延迟为253 ns。文献[11]提出一种基于总线的市场数据解码引擎设计,针对不同的市场数据模板,使用HLS 实现一种自动构建解码引擎的结构,平均延迟为1.3 μs。
传统的FPGA 开发方式以Verilog 等HDL 硬件开发语言为主,存在修改不便且开发周期长的问题。本文在Vitis 开发架构下[12]结合使用开放运算语言(Open Computing Language,OpenCL)和高层次综合HLS 进行开发,以大幅缩短开发周期,便于开发人员修改。同时,针对量化高频交易场景,在满足功能的条件下优化性能。
1 量化高频交易
近年来,量化高频交易(Quantitative High-Frequency Trading,QHFT)在不断改变金融市场结构。作为一种新型投资策略,量化高频交易通过快速买卖股票获取利润,持有时间通常以秒或毫秒为单位[13]。量化高频交易在美国股票市场的占比很大,截止2019年,高频交易占美国股票订单量的83%,占美国股票交易总额的70%以上[14],欧洲市场规模类似[15],国内市场起步相对较晚,但也展现出勃勃生机[16]。
1.1 量化高频交易困境
以微秒为单位的量化高频交易的主要困境在于网络通信部分,在瞬息万变的金融交易市场中,行情商获取的行情信息延时越低,意味着有越多的交易机会和更大的决策空间[17]。传统软件处理网络的方式存在高延迟、高占用、带宽利用率低、延迟不稳定等问题,而采用纯硬件实现网络通信功能具有低延迟、高带宽、固定延迟等特点,符合行情商的期望。
1.2 基于FPGA 的网络解决方案
应交易所要求,行情商的服务器架构如图1 所示,其中:主端口进行正常的TCP/IP 连接,镜像端口只进行数据的监听与接收。由于交易所与行情商间的网络通信传输内容单一、方向固定,且按照固定频率发送,因此仅需基础TCP 通信功能即能满足通信需求。与完整协议栈相比,TCP 协议的通信灵活性下降,可靠性不变,但通信效率得到极大提升。针对量化高频交易应用场景,本文提出一种领域专用的TCP/IP 卸载引擎设计,在满足功能的前提下简化TCP 协议,将通信延迟极度降低的同时保持稳定的带宽,实现效能的最大化。
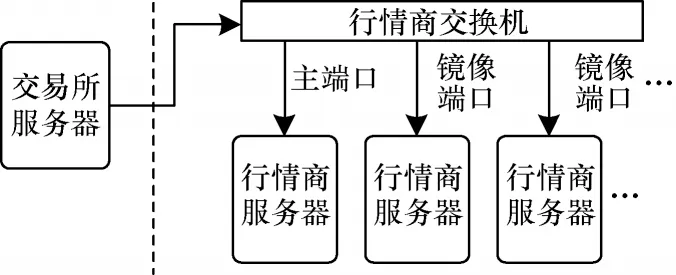
图1 行情商服务器架构Fig.1 Server architecture of quotes suppliers
2 领域专用TCP/IP 协议的设计与实现
TCP/IP 协议是因特网的基础,包含应用层、运输层、网络层、数据链路层和物理层5 个部分[18-20],其架构如图2 所示。其中,5 层协议将网络接口层细分为数据链路层和物理层,其余与4 层协议一致。
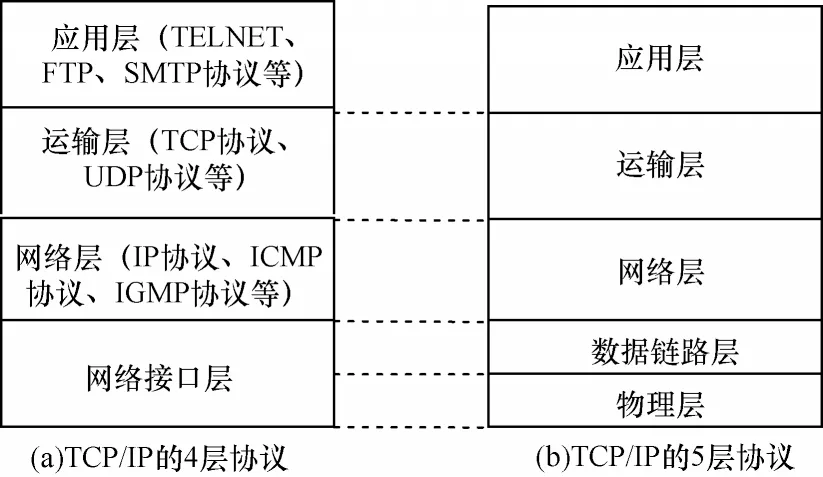
图2 TCP/IP 协议的架构Fig.2 Architecture of TCP/IP protocol
本文采用模块化设计原则,将TCP/IP 协议中不同的功能分离成不同的模块。FPGA 端分为CMAC内核、TCP/IP 内核和用户自定义内核3 部分,具体架构如图3 所示。CMAC 内核将接收到的光信号转换为电信号数据并传输给TCP/IP 内核,TCP/IP 内核将数据报解析后发送至用户自定义内核处理。

图3 FPGA 端的整体架构Fig.3 Overall architecture of FPGA end
2.1 CMAC 内核
CMAC 内核包含1 个10 GB/25 GB 高速以太网子系统(High Speed Ethernet Subsystem,HSES)[21]的IP 核模块。该IP 核模块采用IEEE 802.3 标准,包含完整的以太网MAC 及物理编码子层/物理介质连接(Physical Coding Sublayer/Physical Medium Attachment,PCS/PMA)功能,可以在每块FPGA开发板上进行单独配置,极大提升网络协议在不同FPGA开发板间的可移植性。该IP 模块将整个计算平台基础架构与GT 引脚相连,GT 引脚指向QSFP28 网络接口,与外部网络进行数据通信。CMAC内核可以根据实际应用需求,配置为10 GB和4×10 GB 两种模式。CMAC 内核和TCP/IP 内核间通过AXI4-Stream 接口相连,用于接收和发送网络数据包,CMAC 内核的具体架构如图4 所示。
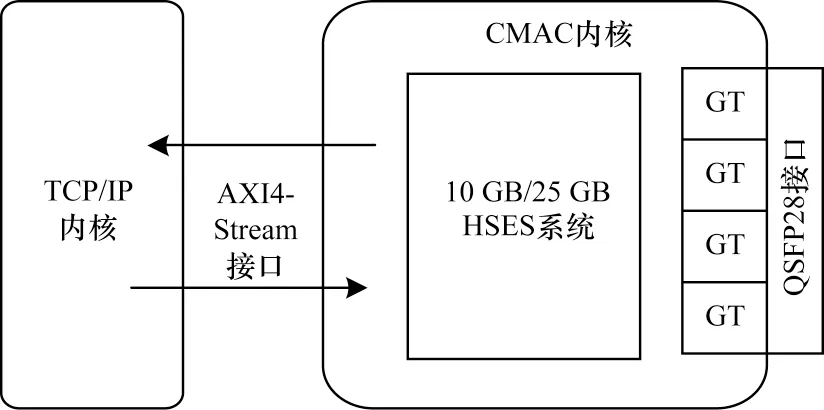
图4 CMAC 内核的架构Fig.4 Architecture of CMAC kernel
2.2 TCP/IP 内核
TCP/IP内核包含TCP卸载引擎(TCP Offload Engine,TOE)模块、UDP 模块、IP 模块、ICMP 模块和ARP 模块,所有模块均使用HLS 进行实现,模块之间使用64 位AXI4-Stream 接口连接。该内核支持最大64 个并发TCP 连接,每个连接提供32 KB 的buffer作为发送和接收的缓冲区。TCP/IP 内核的整体架构如图5 所示。

图5 TCP/IP 内核的架构Fig.5 Architecture of TCP/IP kernel
由图5 可知,TCP/IP 内核的各功能模块均封装为单独的IP 核,可以依据应用场景、板卡资源等因素进行选择性配置。针对量化高频交易等特殊应用场景,本文开发出一种类TCP 协议解决此类问题。与CMAC 内核相同,TCP/IP 内核暴露出固定的接口,供开发人员调用。
IP 模块包含IP 接收和IP 发送2 个部分,支持IPV4 协议,可以通过主机端设置固定的IP 地址、子网掩码和网关地址。IP 接收部分会首先判别协议类型,丢弃IP 和ARP 以外的数据包,同时将ARP 数据包转发至ARP 模块。之后对IP 帧包进行首部校验和检查以及上层协议类型检查,将数据部分转发至对应上层模块。发送模块同样对ARP 和IP 模块进行分开处理,并计算IP 帧的首部校验,将数据部分与头部封装后发送给CMAC 内核。
ARP 模块包含ARP 请求的发送和接收功能以及ARP 响应的发送和接收功能。ARP 映射表放在BRAM 内,最多能同时保存128 组映射关系。在发出ARP 请求后,会在映射表中保留500 ms,若仍未收到ARP 响应,则会被删除并标记为未答复的请求。
ICMP 模块包含接收回送请求报文和发送回送回答报文的功能,会对接收到的ICMP 帧进行校验、检测和计算,并封装为回送回答报文,传输至IP 发送部分。
UDP 模块包含报文的接收和发送功能,通过主机端来设置目的IP 地址、目的端口和源端口。UDP模块在作为接收端时支持最大64 KB 可编程监听端口,对于无效数据将直接舍弃,且能够进行校验和计算,将解析后的数据传输给自定义模块;在作为发送端时,会先添加伪首部计算校验和,之后封装为UDP帧,传输给IP 协议。
2.3 TOE 模块
针对不同的需求,TOE 模块开发出以下2 种TCP 变体协议模块:
1)通用TOE 模块。针对量化高频交易中主端口设计,建立正常的握手连接、支持发送和接收功能,实现TCP 拥塞控制,包括拥塞避免、快速重传等;
2)镜像TOE 模块。针对量化高频交易中交换机的镜像端口开发,只实现TCP 数据报的接收功能和数据重排功能,并将解析出的数据部分传输给上层用户自定义内核。2 种模块均为每个TCP 连接提供了32 KB 大小的buffer 作为数据缓冲区。镜像TOE模块能够接收的最大报文长度为MSS 字节,不支持对巨型帧的接收。
通用TOE 模块分为接收部分、发送部分、计时器部分、状态控制部分、缓冲查找部分和缓冲存储部分,具体结构如图6 所示。
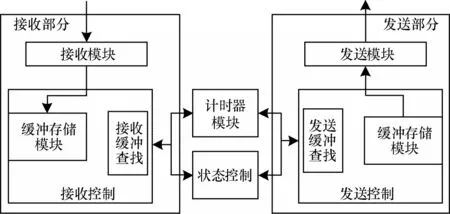
图6 通用TOE 模块结构Fig.6 Structure of general TOE module
由图6 可知,接收部分会先对TCP 数据报进行解析,解析后的数据报依据TCP 首部分为以下5 种:
1)仅SYN 标志位有效的数据报,为客户端发送的连接请求。
2)SYN 和ACK 标志位有效的数据报,为服务器发送的确认报文。
3)ACK 标志位有效但不携带数据的数据报,为客户端的确认报文。
4)ACK 标志位有效且携带数据的数据报,为数据报文。
5)FIN 和ACK 标志位有效,为连接释放报文。依据分类启动对应的状态机模块。
数据发送部分会在等待连接缓存中存放的数据达到MSS 字节后,就将其组装为1 个TCP 报文段发送出去。初始窗口大小定义为10 MSS 字节,当触发拥塞控制机制后,将会被介绍到MSS 字节,直到所有的数据报被确认。
镜像TOE 模块分为接收模块、发送模块和数据缓冲排序模块3 个部分。具体结构如图7 所示,该模块是针对镜像端口的设计。
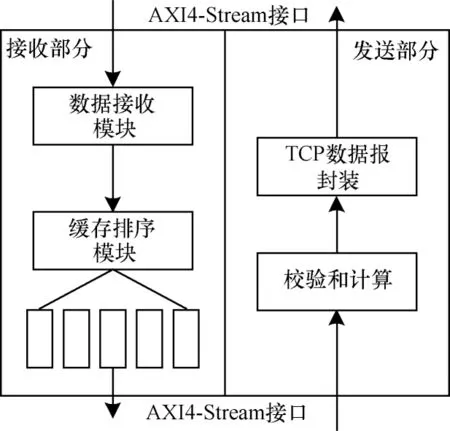
图7 镜像TOE 模块结构Fig.7 Structure of mirror TOE module
由图7 可知,在接收到TCP 数据报后,由于镜像接口不需要也无法进行握手协议的建立,镜像TOE模块会直接对其进行解析,若不携带数据部分,则直接舍弃。在缓冲区,数据部分将被按照序列号保存为5 组数据,并被进行排序设计。发送模块与UDP协议类似,先添加伪首部计算校验和,之后封装为TCP 协议数据报传输给IP 模块。镜像TOE 模块设计也可用于FPGA 片间通信。
2.4 用户自定义内核
在用户自定义内核中,用户能够依据应用场景需求,设计对应硬件加速模块,通过预设的接口,处理从网络中接收到的数据,同时将处理完的数据通过网络发送出去。该内核与TCP/IP 内核中的UDP模块和TOE 模块通过AXI4-Stream 接口相连,同时通过XDMA 与主机端进行数据交互。用户自定义内核的整体架构如图8 所示,该模块提供了一个量化高频交易中FAST 解码协议的硬件实现,并作为对整体网络通信的功能性验证。依据上海证券交易所的FAST 协议规范,设计实现3 201 逐笔成交模板和5 801 逐笔委托模板中无运算符、常量、复制、缺省和自增5 种操作,接收从镜像TOE 模块传输来的数据,并进行处理,将结果传输回主机端,方便后续数据的金融决策计算。
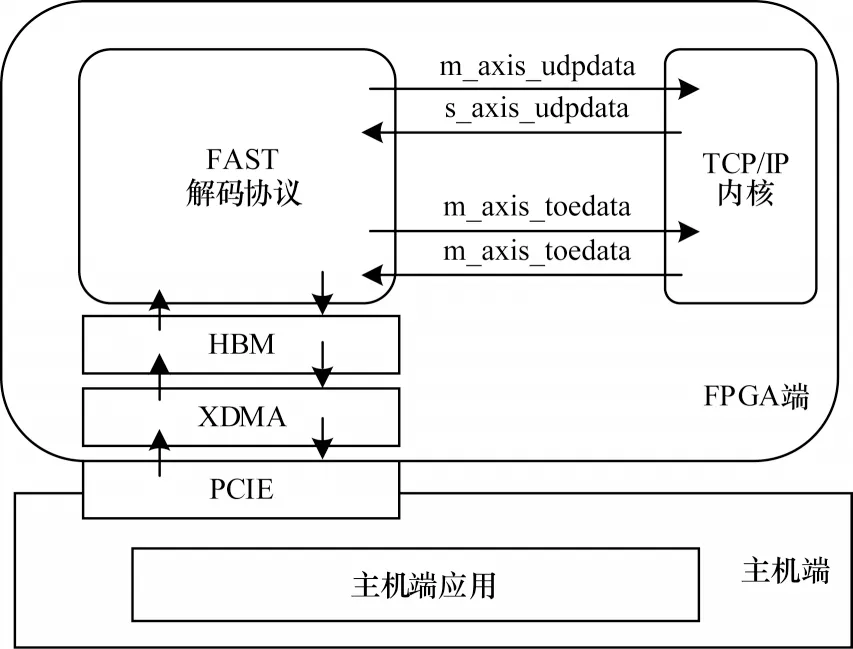
图8 用户自定义内核的整体架构Fig.8 Overall architecture of user defined kernel
3 基于OpenCL 的整体平台设计与优化
3.1 基 于OpenCL 的FPGA 开发
Vitis是目前最先进的FPGA开发框架之一[22],用户可以通过调用OpenCL API 来管理Xilinx 运行时库(Xilinx Runtime Library,XRT)与硬件加速器部分的交互。Vitis 提供3 种对FPGA 内核的调度模式:顺序执行模型、流水线模型和自由运行模型[23]。由于TCP/IP 协议使用监听机制,因此本文采用自由运行模型的调度机制,当FPGA 从主机或其他内核接收流式数据时,便会对数据进行处理,当没有数据时,则会自动停止运行。
3.2 数据位宽优化
在整体设计中,为保持网络4×10 Gb/s 的传输速率,主要瓶颈在于网络内核模块和内存之间的数据交互。在TCP/IP 内核中,数据部分会暂时存储在内存中,起到重新传输或缓冲目的。从理论上来说,若想达到4×10 Gb/s 的带宽效率,则需要至少40 Gb/s的内存带宽。Vitis 开发架构针对64 Byte 对齐的顺序内存访问提供了优化,若使用未对齐的内存访问,则会显著减少内存带宽,因为在这种情况下,网络将触发自动对齐的内存访问。对于每个TCP/IP 连接,在建立时均会分配一个初始内存地址,并在初始内存地址的偏移量中存储即将到来的数据报。初始内存地址在连接建立时确定,有很大几率不是64 Byte对齐。同时,在默认的TCP/IP 设置中,MSS 为1 460 Byte,并非64 Byte 的倍数。结合应用场景下实际网络的传输情况,网络设备通常倾向于发送较短数据报,以最大程度提高网络利用率。因此针对上述2 个问题,本文将初始内存地址默认为0,同时将MSS 降低为1 408 Byte,这是比1 460 小且为64 Byte 的最大倍数。每个连接的偏移内存均固定为1 408 Byte,故定义初始内存地址的物理偏移量为64 Byte 的整数倍,以此降低网络内核模块和内存之间的读取延迟。
3.3 AXI4-Stream 接口的使用
Vitis 开发架构支持使用AXI4-Stream 流接口来完成内核之间的数据传输,本设计中各个模块间均使用AXI4-Stream 接口。使用流接口进行开发的优势在于内核之间可以直接进行数据流式传输,相当于申请一个无限深度的FIFO,而不必通过全局内存进行数据传输,能够显著提升传输性能。在Vitis 开放框架下,必须使用AXI4-Stream 接口才能使用自由运行模型,各模块在接收到数据的同时,便可进行处理,不需要主机端的控制信号,从而提升数据传输处理效率。
3.4 并行设计优化
并行优化设计主要通过数据流优化、数据展开等来提升整体设计的并行度。数据流优化即对规模较大的组合逻辑进行分级处理,在各级之间添加寄存器暂存中间数据,通过消耗一定的寄存器资源实现任务级流水,以达到更高的吞吐量和更低的延迟。TCP/IP 各层协议间以及每层协议内的数据均没有数据依赖性,因此可以进行流水线设计。以IP 接收模块的实现为例,流水化设计如图9 所示。
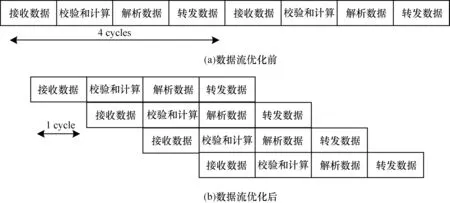
图9 内核数据流水化模型Fig.9 Kernel data pipeline model
由图9 可知,该模块可以简化为接收数据、校验和计算、解析数据和转发数据4 个部分,假设每部分的时间消耗为1 个时钟周期,未使用数据流优化时,每组计算消耗4 个时钟周期,在使用数据流优化之后,除去首次延迟外,每组计算只消耗1 个时钟周期。其他模块也采用相同的流水型设计,以最大程度地缩短整体平台的执行时间。
数据展开通过增加并行度来缩短数据延迟。以TCP/IP 协议中常用的校验和计算为例,数据以64 Byte 流输入,将其全展开,分为4 个16 Byte 的数据,并分别进行累加和移位运算,减少校验和计算的时间开销,内核数据展开模型如图10 所示。由图10 可知,当未使用数据展开时,执行校验和计算需要11 个时钟周期完成;在使用数据展开后,只需2 个时钟周期便可完成,可见数据展开能够大幅缩短数据延迟。
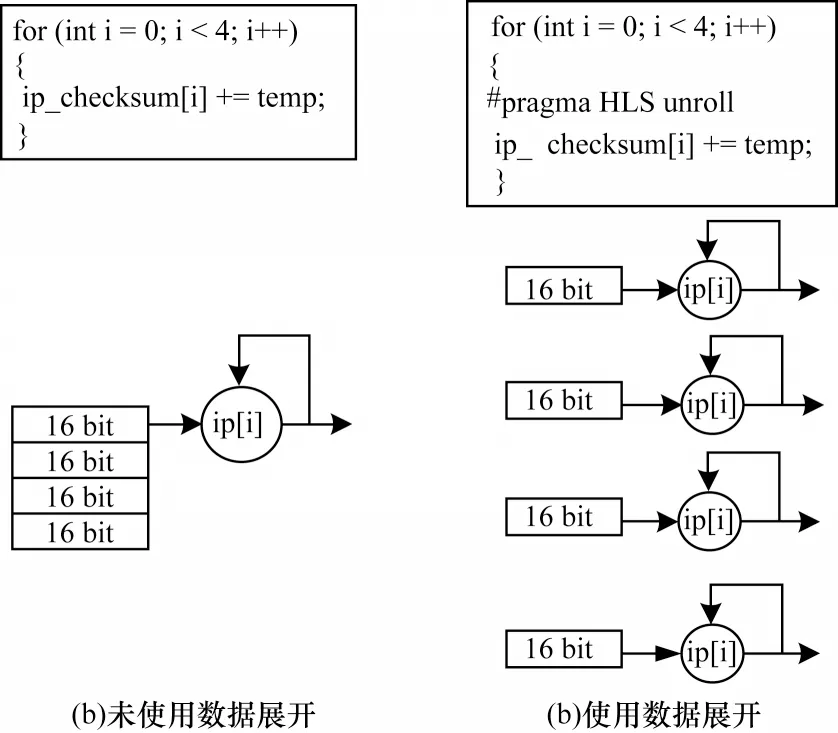
图10 内核数据展开模型Fig.10 Kernel data unroll model
3.5 内存架构优化
在Vitis 框架下,主机端和FPGA 端通过全局内存进行数据交互。在默认情况下,Vitis 自动把全部计算单元(Computing Unit,CU)连接到同一全局内存,这导致每次只有一个内核可以和全局内存进行读写数据,这限制了整体平台的性能。本文对内存架构进行优化,将CU 链接至不同的HBM 伪通道(Pseudo Channels,PC)单元,同时设置CU 和内存到同一块超级逻辑区域(Super Logic Regions,SLR)[24]上,以最大化带宽的使用。以用户自定义内核为例,该模块有4 个返回值,通过将其分配在和SLR 0 相连的HBM 0 的4 个PC 单元中,可将传输速率提升为之前的4 倍。内存架构的优化设计如图11 所示。由图11可知,虽然每PC 单元的传输性能为14.3 Gb/s,低于DDR 通道的传输性能19.2 Gb/s,但是可以通过内存架构的优化,实现对多PC 的访问连接,从而达到提高总体传输效率的目的。此方法在Xilinx Alevo系列和Intel Stratix V 系列板卡上均有较好的适用性。
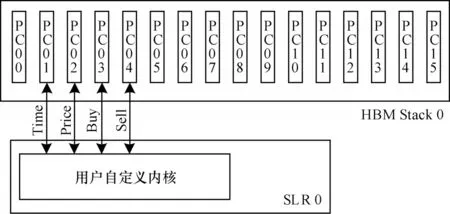
图11 内存架构的优化设计Fig.11 Optimized design of memory architecture
3.6 整体功能设计
如图12 所示为本文TCP/IP 引擎结构,其主要分为主机端和FPGA 端2 大部分。其中:主机端负责与OpenCL 程序外部的交互、与FPGA 端的数据交互及内核部分的调度与管理;FPGA 端负责TCP/IP 协议及后续数据加速模块的实现。FPGA 端包含CMAC 内核、TCP/IP 内核以及用户自定义内核3 个模块。其中,在TCP/IP 内核中,用户可以通过量化高频交易中的不同场景进行自由配置。在上述3个模块间使用AXI4-Stream接口进行数据交互,通过使用数据对齐来降低数据模块和内存之间的数据延迟。针对TCP/IP 协议各功能模块及校验和计算间无数据关联性的特点,采用数据流优化和数据展开优化形成流水线并行架构,同时对内存架构进行优化,降低内核和主机端间的数据传输延迟。
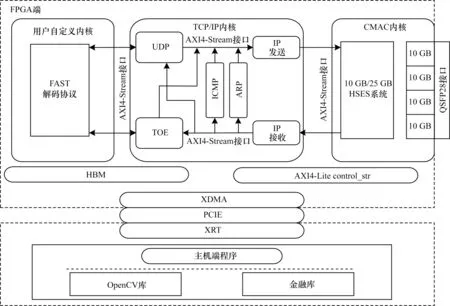
图12 本文TCP/IP 卸载引擎结构Fig.12 Structure of TCP/IP offload engine in this paper
4 实验与结果分析
4.1 实验环境
本文的软件环境为Centos Linux release 7.7.1908,Vitis 的版本为2021.1,XRT 版本为202110.2。硬件环境为2张XilinxAlveo U50数据中心FPGA加速卡、Intel i9-9900x 的CPU 及华为S5720-28X-LI-AC 交换机。该款FPGA加速卡拥有872 KB的LUTs、8 GB的HBM和1个QSFP28网络接口。其中,QSFP28网络接口支持10 GB、25 GB、40 GB、100 GB、4×10 GB 和4×25 GB 的网络配置。使用PCIE Gen 3×16 和服务器连接,支持Vitis 开发平台通过Gen 3×16 XDMA 进行开发。FPGA 加速卡的资源配置如表1 所示。

表1 FPGA 加速卡的资源配置Table 1 Resource configuration of FPGA accelerator card
4.2 实验结果
本文整体实验平台搭建如图13 所示。由图13可知,在FPGA 平台中例化3 组MAC 层和IP 层IP核,即3 个IP 地址,并分别和UDP、通用TOE、镜像TOE 这3 个模块直连,各模块间可同时使用10 GB SFP+光口与交换机通信。本设计全局使用300 MHz时钟,内核的延迟数通过在硬件内部构件(Intergrated Logic Analyzers,ILA)进行统计,和时钟相乘获得延迟时间。
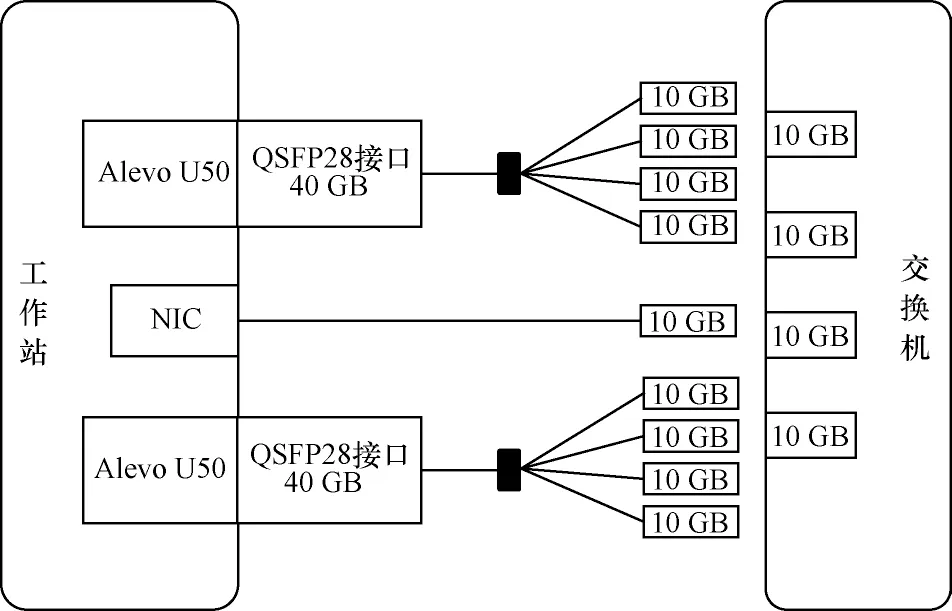
图13 实验平台的架构Fig.13 Architecture of experiment platform
整体平台的资源消耗如表2 所示,LUTS 消耗超过5 成,DSP 的使用率很低。其中基础网络平台部分的LUTS 和FIFO 的资源占用率都未超过10%,为后续加速程序开发留出充足的资源。
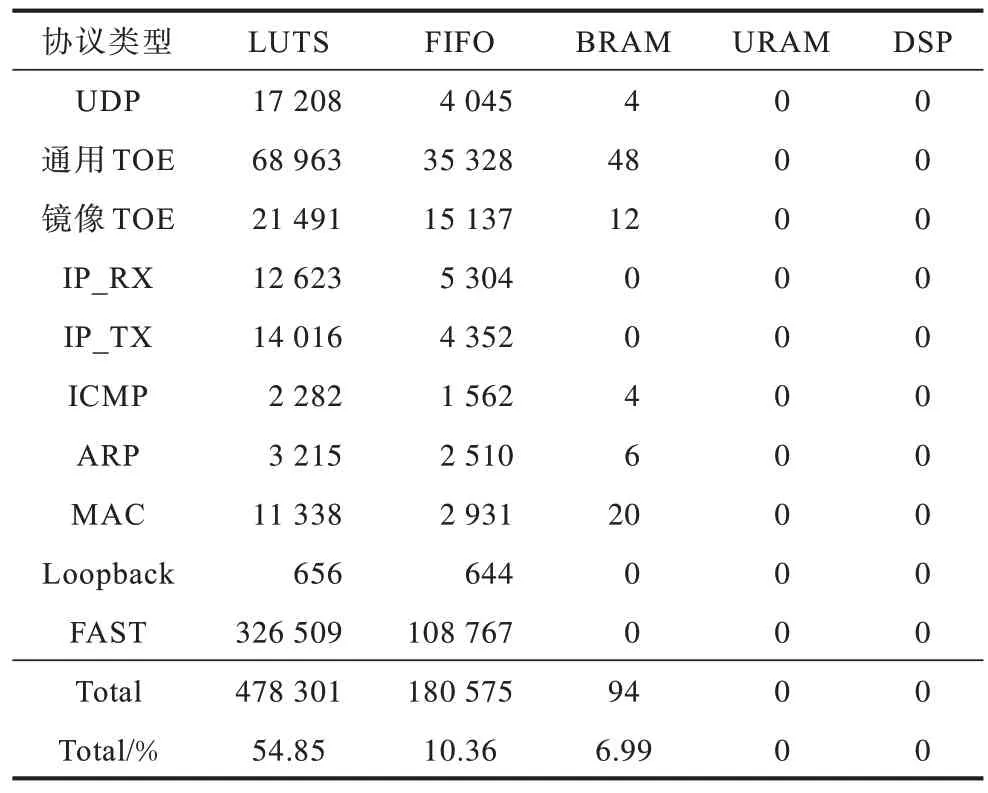
表2 计算平台的FPGA 消耗Table 2 FPGA consumption of computing platform
本文网络计算平台在UDP、通用TOE 和镜像TOE 这3 种通信协议下的通信延迟如图14 所示。测试使用100 Byte 的数据,由Host 端按照UDP 协议和TCP 协议发出,发送至UDP 通信协议和通用TOE 通信协议对应的IP 地址,同时设置交换机镜像接口并将数据发送至镜像TOE 模块。在FPGA 端,UDP 和镜像TOE 协议的延迟几乎一致,在量化高频交易应用场景下有极大的使用空间。
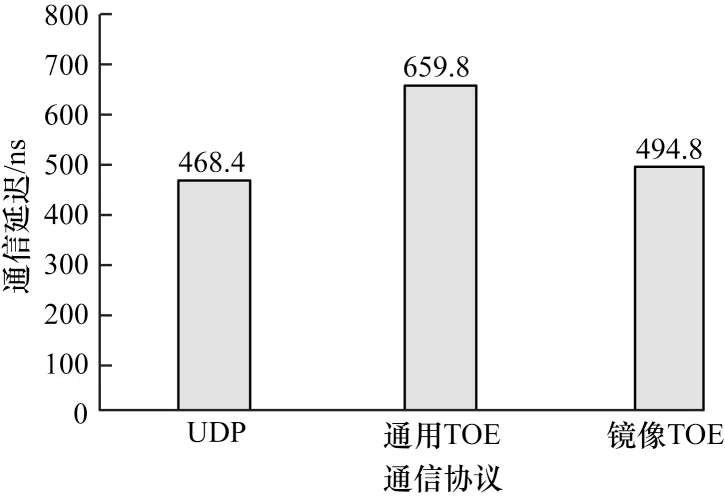
图14 3 种通信协议的通信延迟Fig.14 Communication delay of three communication protocols
将MAC 中的输出端口和接收端口通过Loopback IP 核回环起来,测试数据包的生成和吞吐量的测试也在FPGA 端完成。理想的吞吐量T可以通过式(1)计算获得:

其中:P为发送的数据包长度;H为首部长度。根据式(1)可得,采用较大的P可以提高网络的吞吐量。UDP 协议下的首部总长度为28 Byte,TCP 协议下的首部总长度至少为50 Byte,因此使用UDP 协议在理论上可以获得更高的吞吐率。图15 显示了不同通信协议下P与吞吐率间的关系。

图15 4 种通信协议的吞吐量对比Fig.15 Comparison of throughput of four communication protocols
由图15 可知,UDP 协议的吞吐量最高,可以达到9.57 Gb/s,两种TOE 模式也分别能达到9.36 Gb/s和9.42 Gb/s,QSFP28 光口的本质为4 路SFP+接口的叠加,因此3 种模式可以分别接入不同的GT 实现并行运行,最大吞吐量可达38.28 Gb/s。
4.3 存储速率的测试与分析
本文针对HBM 和DDR 通道进行速率测试,分别测试了主机端PCIE 与HBM 的速率,以及FPGA上每个内核与HBM 和DDR 的速率,测试方式参照Xilinx 的Xbtest 架构,统一使用256 MB 大小的数据包,测试结果如表3 所示。

表3 内存读写速率对比Table 3 Comparison of memory read and write rates
由表3 可知,主机端至HBM 的速率最低,因此在设计加速程序时,除必要数据外,应尽量减少FPGA 和主机端间的数据传输。虽然HBM 上单个PC 的传输速率低于DDR,但是同时访问4 个PC 的速率远大于DDR 的访问速率。通过对内存架构进行优化,将内核中不同数据块进行分离,每个输出都使用单独的AXI 口与不同的PC 相连,实现对多PC的访问,以大幅提升访存速度。
4.4 整体通信功能的验证与分析
为验证TCP/IP 引擎设计的整体功能完备程度,以及对量化高频交易的支持度,本文从主机端发送不同数量1 408 Byte 大小的上交所逐笔成交PCAP数据包,使用ILA 测试镜像TOE 模块下,从数据接收到FAST 协议解析的平均时间延迟,同时测试Linux环境下使用10 GB 网卡接收数据包并解析的平均时间延迟,结果如图16 所示。由图16 可知,Linux 搭配网卡的平均延迟在120 μs~200 μs 之间,受CPU 的波动影响较大,TOE 模式下平均延迟稳定在9.5 μs 左右,时间固定、无波动,此外,TOE 模式下的延迟缩短到软件方案的1/12。
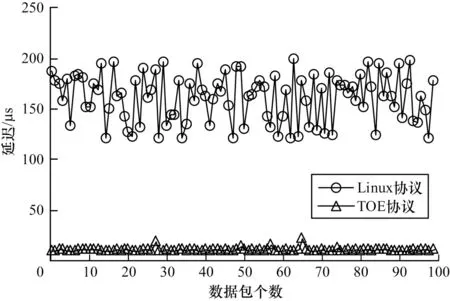
图16 通信延迟对比Fig.16 Comparison of communication delay
本文对在Xilinx Alveo U50 数据中心上实现的网络通信和FAST 解码协议的穿透延迟进行了测算,包含从MAC 层进入,经过IP 层和镜像TOE 的解析,传输至FAST 协议模块解码的数据处理总延迟。各部分的延迟如表4 所示。由表4 可知,针对FAST 解码协议的通信延迟最低可至677.9 ns。在镜像TOE 模块下,网络部分的延迟最低为468.4 ns,可以满足高频通信应用场景的需求。
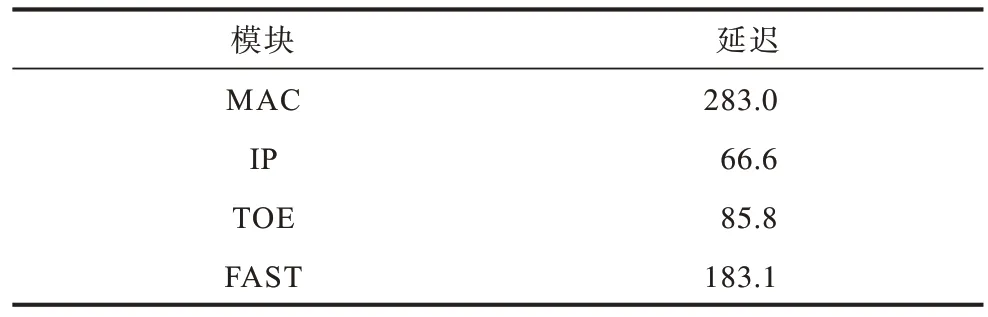
表4 FAST 协议穿透延迟测试结果Table 4 Penetration delay test result of FAST protocol ns
4.5 与其他方法的对比
表5 所示为不同方法的对比,方法1[4]、方法2[5]、方法3[8]、方法4[9]、方法5[14]皆在FPGA 上实现了TCP/IP功能。本文在Vitis 框架下,使用HLS 进行开发,通过数据位宽优化、内核存储优化以及数据流优化,实现了TCP/IP 引擎。与使用Verilog/VHDL 等开发语言的实现方案相比,本文方法开发周期短,便于修改,开发人员可以依据经济、政治等因素快速在自定义模块中对量化高频交易政策作出调整,同时本文方法的最大吞吐率达38.28 Gb/s,最低通信延迟为468.4 ns,取得了效能的最优解。
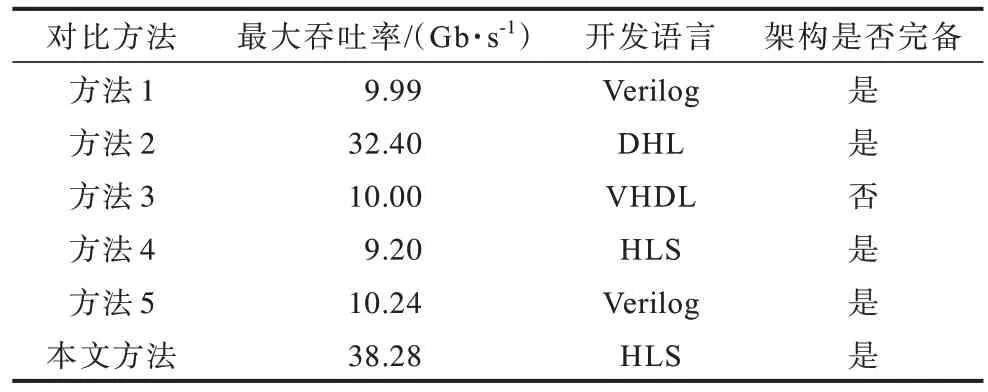
表5 不同方法的对比Table 5 Comparison of different methods
5 结束语
本文提出一种领域专用低延迟高带宽TCP/IP协议栈,并在TCP/IP 协议卸载引擎架构的基础上将其嵌入Vitis 开发框架中。采用模块化设计,各模块使用相同规范的接口,开发人员只需按照接口规范封装自定义模块即可实现对网络功能的自主配置和调用。通过优化数据位宽设置固定MSS,优化内核和HBM 间的存储效率,使用AXI4-Stream 接口优化内核间的传输效率。此外,使用数据流优化和数据展开方式形成流水线型架构,使整体性能达到最优,并针对高频交易场景设计一种镜像TOE 模式。实验结果表明,与传统Linux+NIC 相比,该方法传输效率提升了12 倍,且获得了更稳定的传输波动。下一步将着重于完善TCP 协议的功能,增加最大连接数及对巨型帧的支持,并针对更多应用场景开发专用型TOE 模块,从而达到TCP 协议的传输效率最大化。
