一种改进YOLOv3的交通标志识别算法
2022-09-14陈德海孙仕儒王昱朝
陈德海,孙仕儒,王昱朝,邵 恒
(江西理工大学 电气工程与自动化学院,江西 赣州 341000)
0 引言
交通标志识别(traffic sign recognition,TSR)在智能交通快速发展的今天占据着重要的位置,在促进车辆通行和交通安全等领域具有积极作用。对交通标志识别的研究,不仅可以提高交通安全,还可以推动智能交通的发展[1-3]。
在卷积神经网络运用到交通标志检测之前,传统的交通标志检测主要包括区域选择、组合特征提取和背景纹理建模等[4-7],但是此类算法鲁棒性较差,很容易受到光线强度、遮挡和背景复杂度的影响,在交通标志检测中达不到精准识别的要求。近年来,随着计算机视觉的快速发展,深度学习算法在目标检测和图像处理领域取得了较好的成果。文献[8]采用图像分割技术和卷积神经网络技术,结合压缩与激励结构和残差思想,将训练出的模型运用到道路交通标志识别,达到了较高的识别精度。文献[9]提出了一种基于膨胀卷积的VGG网络模型来进行道路交通标志识别,可以达到实时检测的需求。在深度学习中,你只能看一次(you only look once, YOLO)算法[10]的提出,大大增加了目标检测的准确度和实时性,应用较为广泛。文献[11]在YOLOv3算法基础上,通过引入注意力机制和语义分割的方法进行改进,改善了对小目标交通标志的检测性能。在目标检测问题上,文献[12]提出了特征金字塔网络(feature pyramid network, FPN)用于检测多尺度目标,将高层特征图和低层特征图进行特征融合,获取更多的目标特征信息。在应用YOLO算法进行目标检测时,现有的研究往往在提高整体检测精度上努力,而忽视了实际存在的小目标。在实际的交通场景中,背景较为复杂,存在广告牌、路标、遮挡和光线强弱等因素,容易造成误检、漏检等问题,且针对小目标的交通标志牌,存在检测精度低的现象,在这种情况下,能精准识别交通标志牌的算法显得尤为重要。
针对YOLOv3算法在交通标志识别上的不足之处,本文在充分实验研究的基础上,提出了基于双尺度注意力和特征增强模块的YOLOv3算法,在进行特征通道重校准的同时,增强了特征提取网络的关联度和目标特征信息的提取能力。
1 交通标志识别模型设计
1.1 YOLOv3算法
YOLOv3算法共包含两个部分:Darknet-53特征提取器和多尺度特征融合。其中,Darknet-53特征提取器使用一系列的1 pixel×1 pixel和3 pixel×3 pixel的卷积,共由5个残差结构构成,残差结构内的卷积层采用跳层连接方式,构成残差网络,经过多次卷积操作可以将416 pixel×416 pixel×3通道的图像输出为13 pixel×13 pixel×1 024通道的图像[13]。YOLOv3算法的特征融合部分借鉴特征金字塔网络的思想,采用自顶向下的方式,将高层预测层与底层进行融合,加强了特征流的传递,然后预测输出3个不同尺度的特征图。
1.2 双尺度注意力模块

图1 FA模块图
注意力机制像人的视觉系统一样,会自觉地从众多目标信息中抓取对自己最有用的信息,可以学习有用特征,抑制无用特征[14]。文献[15]通过对特征网络的研究,提出了一种使用注意力机制的卷积神经网络,随着网络的深入,注意力模块会自适应地学习,来提取图像的有用信息。随着注意力机制被越来越多的研究者使用,验证了其对于网络性能的提升具有积极作用。针对YOLOv3算法在交通标志检测中存在的缺陷,本文构建一个双尺度注意力(feature attention,FA)模块,进行特征通道的重校准,以此达到强化目标特征、抑制干扰特征的目的。FA模块如图1所示,其中,激活函数1为Rectified Linear Unit(ReLU)激活函数,激活函数2为Sigmoid激活函数。
具体步骤如下:首先,在全局平均池化前面加入1 pixel×1 pixel和3 pixel×3 pixel的卷积,可以实现跨通道的信息整合,将其与标准注意力模块相结合,构成双尺度注意力模块,加强不同尺度下的交通标志图像的空间联系,加强了多尺度特征的提取能力。通过全局平均池化,将特征图的全局空间信息转化为一维矢量进行求和,获得其全局信息。具体公式如下:
(1)
其中:Gc为特征图全局平均池化后的矢量求和;H、W为输入特征图的宽和高;Uc(i,j)为第c个通道Uc在(i,j)处的值,然后特征图的大小从C×H×W变为C×1×1。
然后,为了加强特征通道间的空间联系,获得不同通道特征图的权重,需要对Gc进行如下处理:
Xc=σ(W2δ(W1Gc)),
(2)

最后,对特征通道进行重校准,然后将权值Xc与输入特征图Uc相乘。具体公式如下:
(3)

1.3 双向特征融合结构
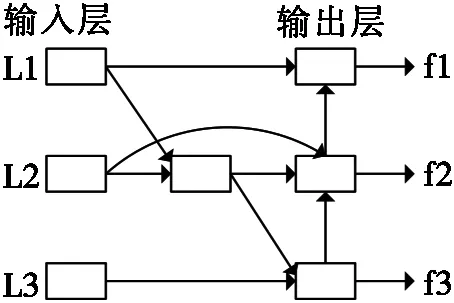
图2 双向特征融合结构
输入的交通标志图像传输至YOLOv3的特征提取网络,会进行卷积操作提取目标特征信息,经过多层卷积之后,会存在部分目标特征信息不足的问题。文献[16]采用特征层融合的方法来提高目标检测性能,本文借鉴这种思想,设计双向特征金字塔网络,将原始的自上而下的特征融合设计为自上而下和自下而上的双向融合方式,使得不同尺度特征更加充分融合,通过使用跳层连接的方式来减少额外参数量。双向特征融合结构如图2所示,其中,L1、L2和L3为特征融合结构的输入层,f1、f2和f3为特征融合结构的输出层,L2层的特征节点通过跳层连接,直接连接到输出层对应的f2节点上,在不增加额外参数的同时获得更多小目标特征信息。
1.4 网络整体结构设计
由于交通标志街景复杂的特性和小目标交通标志牌的存在,增加了交通标志牌的识别难度,考虑小目标交通标志牌的识别特点,需要获取更多的小目标特征信息,在此基础上设计了双尺度注意力模块,将其嵌入Darknet-53网络中,进行特征通道权重再分配校准,抑制图像中的干扰特征,同时改进特征融合结构,提高小目标交通标志牌检测精度。网络整体结构如图3所示。

图3 网络整体结构图
在图3中,虚线框外为本文设计的网络结构,虚线框内是对网络结构两个模块的介绍。其中:注意力残差网络×n,代表n个注意力残差网络结构;DBL包括卷积层(convolution)、批归一化层(Batch Normalization)和激活函数(Leaky ReLU)。整体网络设计过程如下:(Ⅰ)在Darknet-53网络中,将设计的FA模块嵌入调整后的残差结构中,重新分配特征提取网络中的通道关系的权重,加强了交通标志牌在不同尺度上的空间连接,增强了模型的学习和表达能力;(Ⅱ)改进原始YOLOv3的特征融合结构,采用自上而下和自下而上的融合结构,加入跳层连接方式,避免增加额外参数的同时,加大了对于小目标特征信息的提取能力。
2 实验结果与分析
2.1 实验数据集与环境
中国交通标志检测数据集(Chinese traffic sign detection benchmark,CCTSDB)[17]是由长沙理工大学张建明老师团队制作完成,共包含15 724张图片,分别收集于真实场景的城市道路和高速公路,共分为3个类别,分别为指示标志(mandatory)、禁令标志(prohibitory)和警告标志(warning)。其中:指示标志用于指示车辆和行人的行驶方向;禁令标志是对车辆禁止或限制的标志;警告标志是警告车辆和行人注意安全、减速慢行等。
针对小目标交通标志牌的检测,分为绝对小和相对小,绝对小是指交通标志牌的尺度和像素较小,导致目标图像信息少、噪声多;相对小是指交通标志在整张图像中占比小,此时存在较多干扰,这些问题都会对于交通标志的监测点造成很大的影响。
数据集的好坏决定了模型的优劣,网络在类别较少的交通标志牌上难以收敛,在进行训练前,利用Python软件通过数据增强的手段,将较少的警告标志的数量进行扩充。同时考虑到数据中的噪声会导致网络的泛化能力降低,为了提升网络的泛化能力,减少过拟合的发生,在训练前使用OpenCV将一部分图像加上椒盐噪声,可以帮助网络在训练的时候看到更加多样的数据,提高其泛化能力。本文选取该数据集中不同场景相似度低、差异性大的图片进行训练,进行数据增强和添加椒盐噪声后,共计9 000张图片,其中,7 000张进行训练,2 000张进行测试。
本文实验是在Ubuntu 18.04.5操作系统上进行,提供的GPU型号为GTX1080Ti,使用PyTorch框架,初始学习率为0.001,batch size为32,训练次数为150 epoch。
2.2 实验评价指标
为了验证本文改进的算法在交通标志识别领域的优越性,本文以平均精度(mAP)作为评价指标,包含精确率(P)和召回率(R)。mAP计算公式[18]如下所示:

(4)
精确率和召回率与坐标轴围成的图形叫P-R曲线图,其面积为mAP大小,面积越大,说明模型的性能越好。根据模型检测结果分为真正例(实际为正样本,在测试中被成功地检测为正样本)、真反例(实际为负样本,在测试中被成功地检测为负样本)、假正例(实际为负样本,在测试中被错误地检测为正样本)、假反例(实际为正样本,被错误地预测为负样本)[19]。精确率和召回率的计算公式如下所示:
(5)
2.3 结果分析与算法对比
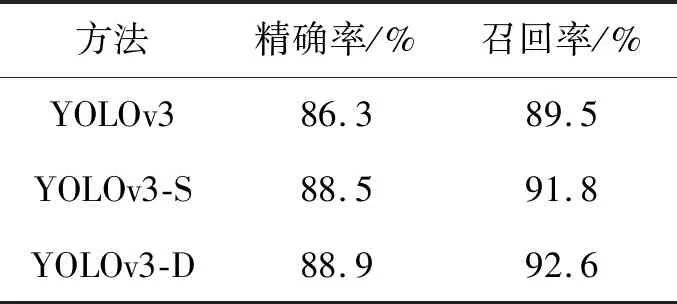
表1 注意力机制对比实验
本文针对双尺度注意力的构建进行对比实验,验证双尺度注意力对于算法性能的提升效果。以原始YOLOv3作为基准实验,分别将不加卷积的注意力模块、加入不同大小卷积的双尺度注意力模块嵌入YOLOv3的特征提取网络,在相同的实验环境和实验参数下进行训练,得到的对比实验结果如表1所示。表1中,YOLOv3-S为不加卷积的单尺度注意力模块,YOLOv3-D为加入不同大小卷积的双尺度注意力模块。
由表1可以看出: 原始YOLOv3算法在CCTSDB数据集上的精确率和召回率分别为86.3%和89.5%,基于单尺度注意力模块的YOLOv3的精确率和召回率分别为88.5%和91.8%,本文的精确率和召回率提升至88.9%和92.6%。经过对比实验,验证了注意力机制对于算法性能的提升具有积极作用,构建的双尺度注意力模块有助于增强不同尺度特征的提取能力,加强不同尺度下的空间信息联系。

表2 4种算法的平均精度
为了验证本文提出的算法的优越性,将本文算法与原始YOLOv3、Faster R-CNN、SSD进行对比实验,在CCTSDB数据集上测试得出各个算法的平均精度,如表2所示。针对小目标交通牌的检测标准,参考文献[20]提出的方法,目标尺度在32及32像素以下的为小目标,32像素以上的为中大目标,分别计算4种算法在小目标和中大目标上的精确率和召回率。
由表2可知:本文提出的算法相较于其他主流算法在交通标志牌上的检测性能得到了较大的提升,平均精度为95.3%。说明双尺度注意力机制和双向特征融合结构可以促进算法的性能,尤其是双向特征融合结构,可以融合更多目标的特征信息,避免了卷积计算过程造成的特征丢失。4种算法关于小目标交通标志牌和中大目标交通标志牌的P-R曲线图如图4所示。由图4可以得出: 本文算法关于小目标和中大目标交通标志牌的检测精度明显高于其他主流算法,尤其是小目标的检测,得到了显著的提升,这是其余3种算法所不具备的。说明双尺度注意力模块在学习目标信息的问题上具有积极作用,极大地改善了原始算法的卷积提取特征信息的缺陷,同时双向特征融合使得多尺度信息的融合更加充分,大大促进了算法的性能。
本文改进算法在CCTSDB数据集上的直观检测如图5所示。由图5可以看出:改进的算法在小目标交通标志牌上检测的效果较为优异,针对广告牌等背景较为复杂的场景下,交通标志牌的检测也取得了良好的效果,在存在椒盐噪声的图片上皆精准检测出存在的交通标志牌,克服了算法在复杂场景下误检以及小目标检测精度低的问题。
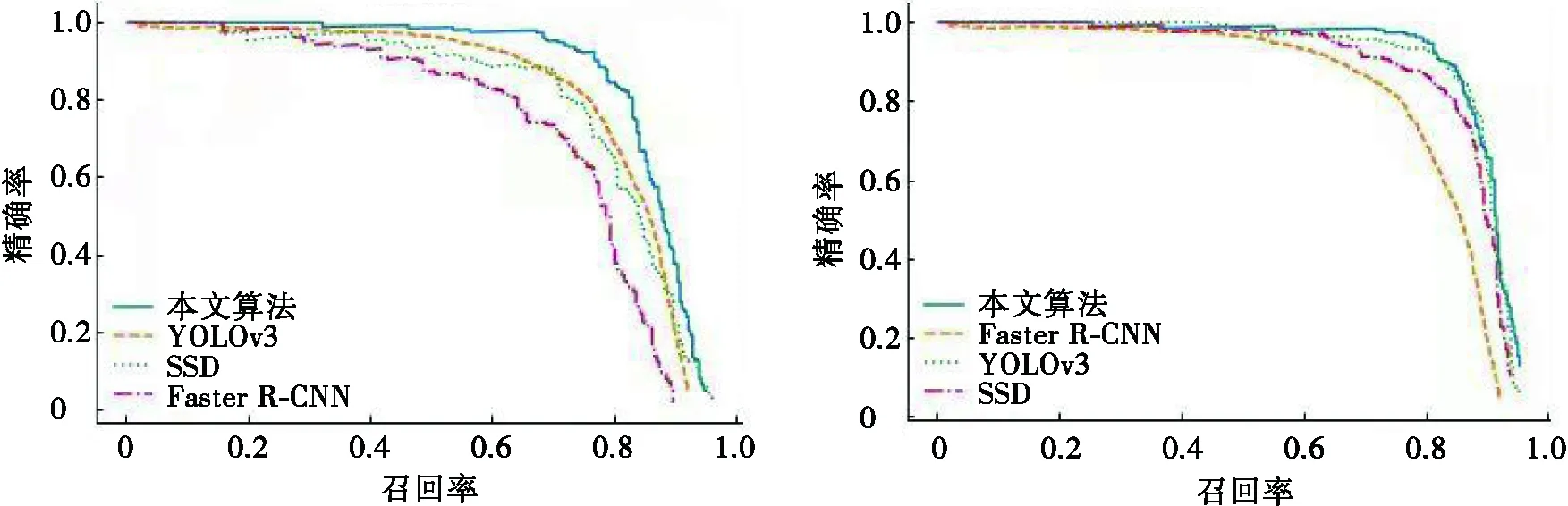
(a) 小目标的P-R曲线图 (b) 中大目标的P-R曲线图

(a) 椒盐噪声下中大目标检测
3 结束语
本文提出了一种基于改进的YOLOv3交通标志识别算法,通过在交通标志检测数据集上进行实验,改进后的算法平均精度达到95.3%。与其他主流算法相比,提高了对交通标志牌的检测性能,同时也克服了场景干扰。下一步将重点针对极端天气下的交通标志牌检测进行研究,进一步提升对交通标志牌的检测性能。
