非结构化工艺数据转换方法分析
2022-09-09刘香福姚岳李睿哲
刘香福 姚岳 李睿哲
(中车长春轨道客车股份有限公司 吉林省长春市 130062)
当前工艺数据是制造业企业中较为重要的技术资料,为了保证此类数据有效使用需要完善软件的功能,以此辅助制造业对工艺数据进行翻译,从而优化工艺数据,确保工艺数据可以独立存在。因此在此过程中需要满足软件的编制需求,确保可以对数据进行转化,最终形成数据集,促使非结构化的工艺数据形成分散化的形式,所以此类数据使用的共享性较低,并且重用性也不能满足实际需求。在数据积累过程中,很多数据中的信息内容都具备挖掘和利用性,因此形成了数据丰富但是知识匮乏的状态。为了规避此类问题,相关技术人员需要不断改善上述问题,确保系统采用结构化的数据存储方式对积累的数据进行优化,以此满足实际需求。
1 数据存储结构分析
1.1 结构化数据
结构化数据主要指的是此流程具有一定的结构性和可分化性,同时形成固定的组成部分,以此通过多个二维因素进行数据的表述。同时结构化数据也需在数据库中表述出存储能力,因此整体需要满足逻辑结构需求,并且还需在数据库中建立相应的表格,以此满足数据库建设结构需求,最终为后续发展奠定良好的选择方向。
1.2 非结构化数据
非结构化数据与结构化数据之间存在关联,属于结构化数据以外的一种数据体系,在结构方面具有一定特性,此时还可对数据库进行存储,因此也出现了不固定的特点。整体类型如下:文本文件、图片、财务报表等。因此可以看出非结构化数据在内容方面会出现一定缺陷,还会影响软件的浏览,此时数据库可以保存字段,还可以检索数据内容。
1.3 半结构化数据
半结构化数据主要指的是介于结构数据和非结构数据之间一种模型,此类数据和上面两种数据方式之间存在一定差异性,在此过程中结构变化较大,因此数据不能按照简单的方式进行组成,同时也不能建立简单的结构,因此具备一定可区分性。此类数据模式更加适合异构数据的交换。
2 非结构化到结构化数据转化系统需求
2.1 文件结构类型
文件结构可以被分为形式、列式、链式。三种不同结构各自具有规律,所以在选择过程中需要结合自身需求进行选择。其中形式文件较为简单,列式文件具有逆置能力,而对于链式文件而言,整体复杂性较高。但是三者之间存在一定的关系。
2.2 系统功能需求
在此类系统设定过程中需要实现非结构到半结构的数据转换需求,并且还需保证文件输出可以对子系统进行优化,最终获取仿真文件,以此结合接口对标准结构文件进行优化,最终提取出文件内容。此过程还需实现半结构化到结构化数据转换的需求,此过程可以形成结构映射和语义映射,因此需要建设相应的数据库,以此满足结构需求。最后还需生成标注结构文件,以此满足不同结构数据的转换需求。
2.3 系统性能需求
系统性需求需要保证满足文档内容与 结构内容之间的分离,其次还需确保可以实现大数据文档解析的需求,最后需要保证可以对海量数据进行快速插入处理。此流程可以对大量的数据进行分析,以此完成计算机的操作工作,从而满足大数据文件的转化。
3 基于可扩展标记语言的非结构化工艺数据转换
当前在信息社会中,信息数据类型可以分为以下三种:结构化数据、半结构化数据和非结构化数据。此时信息数据建设需要创建相应的表格,通过表格可以对信息内容进行描述。但是由于现代企业在不断优化更新,因此在信息化系统建设过程中可以直接对工艺数据进行处理,以此满足数据转换的特殊性需求,此过程,规避了管理上的各类不便内容,从而为工艺数据转换提供结构化需求,以此满足读取和解释需求,最终利用工艺知识进行集成和管理。
工艺数据转换需要对数据和目标数据的结构进行分析,非结构化工艺数据转换需要以半结构化数据转换为基础进行设计,此过程中还需涉及到非结构化数据转换到半结构化数据的过程,因此为后续非结构化数据转换的思想奠定了基础,在此过程中可以优化工艺数据的转换流程。当前在XML 技术中,平台具有字面属性和可扩张性,并且整体使用较为简单,可以满足平台无关性需求,因此在半结构化数据采集过程中使用此类系统进行过渡具有一定优势。非结构化数据转换过程如图1所示。因此在非结构化数据转换过程中需要建立相应文档,以此传输数据资源,将其应用在不同的卡片之中,并且对类型和格式进行设定,以此构建数据抽取策略,在数据输出过程中需要对模板进行设定,结合工艺数据,将指定数据输入在文档格式之中。
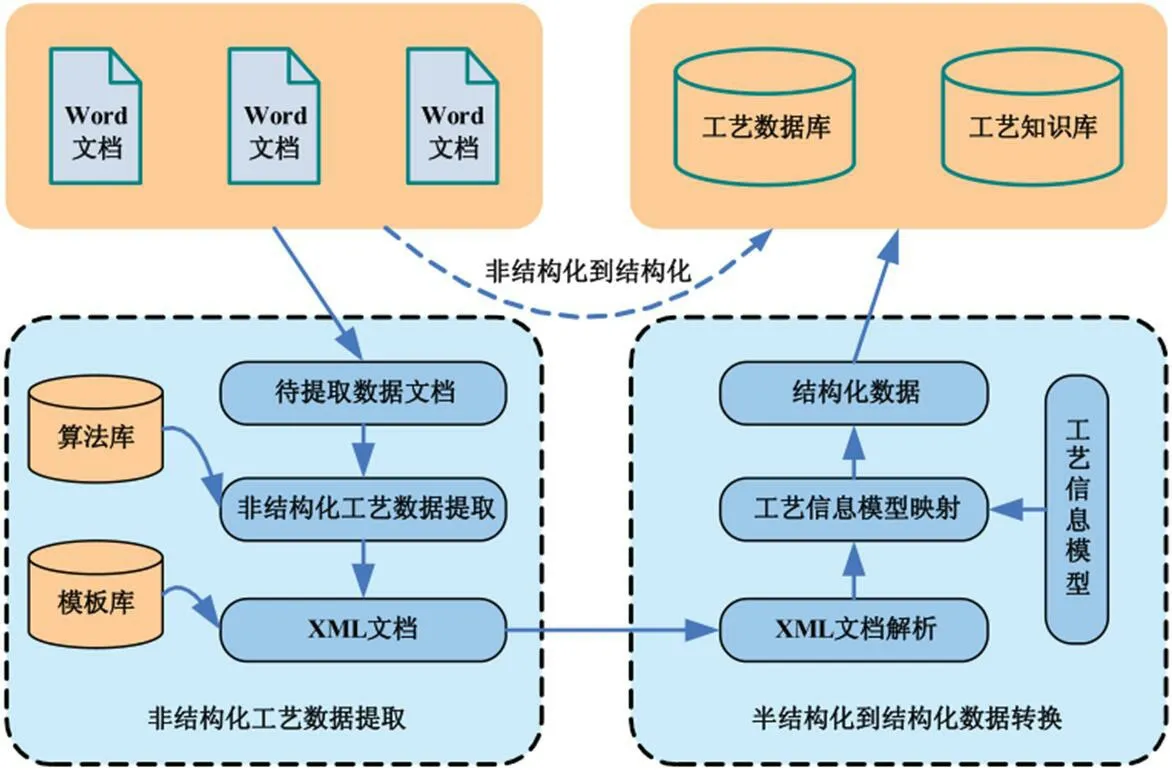
图1:工艺数据模型图
4 基于可扩展标记语言的工艺数据描述
4.1 非结构化工艺数据结构分析
实际的工艺流程包括多个形式,各种形式需要结合不同的企业需求,才可保证工艺规程的不完全性,总而言之,工艺规程需要通过表格的形式进行表述,此过程还需包括以下内容:封面、工艺目录卡、工序卡等。因此此过程更可以对工艺信息进行整合,以此将数据进行规划,整体也可以按照一定表述方式进行表达,此过程具体描述如下:首先通过封面建设相应的工序目录表,后续结合工序目录表对设备明细表进行分析,后续结合工装明细表设定工序卡,最后将各类信息进行整合。具体表述如下:首先设定目录信息,后续结合工序卡片的工序进行信息分析,信息分析主要包括公布信息和工序设备,后续还需结合工装设备进行信息整合,除此之外,还需结合工装明细表对信息进行整合,此过程也需结合工序中的设备进行整合,每道工序都需反应信息的整合。在此过程中会对工艺规程中的格式和数据进行组成和分解,其次对每张卡片中的数据进行处理,以此将抽象变为具体,从而构建出相关的工艺数据模型图,如图1所示。
4.2 基于分治法的工艺数据抽取算法描述
当前我国非结构化工艺数据处理具有一定特点,因此为了保证可以提取出相应的数据内容,选择使用分治法对其进行支持,此过程可以自动进行数据提取,并且还可以满足实际要求。当前工艺规程中各个表格呈现除了差异性的特点,因此格式出现了不一致的现象,此时每张表格都需考虑组成部分,并且还需制定数据抽取策略,此策略需要结合建设思路共同分析。同时还需应用表述工艺,对信息内容进行表述,后续结合表格对复杂内容进行规范,以此描述出更多的工艺信息,以此对非结构化的信息内容进行划分。后续还需使用分治法对数据信息进行整合,分治法思想如下所述:首先需要对规模进行判断,后续结合问题对其进行划分,此过程还需对规模较小的问题进行划分,以此结合各个子问题进行分析,其中还需将其组合在一起,才可对问题进行解决,此时如果问题交代,还可以反复进行分治法进行分析,直到问题足够小为止,满足不在分割需求。此过程也需制定相应的工序卡对数据进行分析和表述,具体流程如下所述:
Step1-分解:工序卡的组成部分如下:表头信息和工序的基本信息,后续结合简图信息和参数信息对工装量信息进行分析,以此对表格和表位信息进行设定,在组成过程中形成了七个数据子集。此时还需对工序卡进行固定,在数据集中标题中,将标记进行分割,同时抽取相应的自己信息对其进行标记,此过程可能出现复杂性,并且整体数据不具备规则可循,因此还需简化数据的表格。Step2-求解:在数据抽取过程中表格已经得到,所以数据子集有一定基础,因此在分割标记过程中还可对位置进行确定,后期结合数据子集对分割数据集位置进行分析,此时还需结合数据子集的表格形成规范表格,此时则可以获取更多的数据信息。重复步骤Step2,此时子集的数据信息被获取。Step3-合并:最后将各类子数据信息进行合并,最终形成XML 格式输出,以此满足后续数据提取需求。
4.3 工艺数据的可扩展标记语言描述
当前非结构化的工艺数据转换的目的是工艺数据的整合,同时还需明确可扩展标记语言,以此才可保证描述出更多工艺卡片的格式,最终对抽取的工艺数据进行分析。在数据描述过程中,XML 中数据会以树型结构进行存储,因此在逻辑上呈现出了主次关系。当前按照工艺数据的结构,XML在描述过程中需要以机械加工工艺流程为基础和节点,此时还需满足工艺数据逻辑关系,具体步骤如下:首先设置封面对设备表进行明细,结合工装明细表对工序目录进行设定,再次结合工序节点对各类元素进行表述,最终将其表述在卡片之中,此过程需要结合子元素和属性表述出逻辑关系。此过程还需对工序信息进行表述,以此满足每道工序对节点和子元素的表述,此时还会分析到数据子集的几点,此时子元素需要包括以下内容:表头信息、表尾信息、工序基本信息、工序简图信息、工步信息、切削参数信息、工装量具信息。此过程中每个元素之中包含了子集的具体信息内容,同时工部信息内容还包括了描述性内容。在一定基础之上需要应用描述性数据对各类多重值和树型结构进行扩展,因此规范了后期相关问题的规范性,最终可以对工艺数据进行描述,同时减少属性特性,以此构建出更多的子元素用来描述工艺信息。
5 XML到结构化数据模型的映射
在实际的系统中,结构化工艺数据一般的存储会在系统数据库中进行,但是系统中工艺信息模型与关系型数据库之间存在一定关联,此时数据库中的数据储存结构发生了一定变化,整体还会出现对应关系。此时如果想要实现半结构化工艺数据需要对半结构化工艺转换为结构化数据,才可建立相应的XML 数据结构,以此满足工艺信息模型的映射关系。在建设树型结构后,文档数据模型需要结合各类不同的方式对文档进行演练,其次还需对每一个节点中不同的内容进行标记,同时按照不同的节点对工艺信息模型形成映射关系,此时所有节点信息都可存储在数据库中。
当前工艺信息模型需要以分析对象为基础,以此选择合适的分析方法,此时树型描述方式也要对层次关系和结构关系进行明确,最终对各个结构的特性进行描述,从而优化相关模型的建设。具体步骤如下:对象类名称包括以下内容:属性、方法、实例、数据关系。对象属性包括名称、别名、值型、约束等多个方面对属性进行分析,同时工艺信息模型包括了多个类别,具体如下:产品类、零件类、工艺类、工序类、工步类、非属性类等。其中对象类内容还包括多个对象属性和结构。因此在建立文档过程中,需要结合各类节点信息,以此获取更多的信息内容。从而完善不同属性的对象类内容,其中还包括了每一个节点中形成的不同对象内容,在此过程中还需将各类对象进行关联,以此满足对其的分析需求。举个例子比如说:元素,需要按照工序下的子元素进行分析,还需结合元素的型号对映射关系进行分析,以此分析出零件类别下的内容属性进行分析,最终对材料的名称和规格进行完善,以此满足后续实际需求。
6 系统性能优化
6.1 系统性能分析
非结构化到结构化的转换完成初期需要对各个测试环节进行分析,以此分析出可以预料的瓶颈问题,从而针对各类问题减少对系统运行的阻碍。在实际测试过程中系统会占用计算机的资源,因此转换过程较为缓慢,所以后期性能方面会受到影响,因此也不能满足实用性需求。
文件在转换文档后,数据量会逐渐增加,因此在项目不断时间过程中数据量会受到文件大小的影响,所以很容易出现措施,此时内存容易出现溢出的问题。系统在运行的过程中为了规避时间长的问题需要插入数据库表格,以此对文件进行导出,此过程需要的时间较长,因此整体效率较低,所以很难在规定时间内容完成数据转换。
基于此本文用软件对非结构化到结构化的过程进行系统设定,前期需要对性能进行测试,以此分析出系统的瓶颈问题,同时在运行过程中还需在内部设定相应的程序信息,集成多个命令和可视化工具,生产换数据减少内存泄漏的问题,从而优化监控,执行内存工作。此时开发人员也需分析出监控和信息浏览内存之间的关系。
6.2 大数据文档解析
系统需要分析出函数库,以此解析文档,从而获取更多具有价值的数据信息内容,此时解析方式也可以被划分为两种,一种是SAX,一种是DOM。两类方式的函数接口均符合一定建设需求。用户需要结合自身需求和接口对文档进行访问。在文档解析过程中需要结合不同的编程语言进行使用,还需结合不同的方法合理选择解析方式,一般情况下会使用JAVA 语言版本进行应用。
对于DOM 模式而言,需要定义文档,还需明确行为和属性以此分析出对象和对象之间的关系,最终形成树型结构。此时在文档创建过程中还需针对储存问题进行修改,以此满足上下查询需求,最终对其进行一次性处理。
对于SAX 模型而言,需要利用解析器建立完整的文档属性,后续确保文档的流通性,最终保证可以对数据进行读取,并且针对数据文档进行转换,此过程比第一种模式时间快。
对于JDOM 模型而言,需要分析出工具包,并且还需结合DOM 建立相应的属性,以此弥补传统模型的确定,同时此过程也不需要解析器的支持,因此可以有效处理文档内容,并且还可以对各类文档进行解析,以此分析出有效的文件内容。
而对于DOM4J 而言,此类模型属于一种较为智能的模型,可以将其应用在平台之中,并且还可建设相应的集合框架,以此支持各个模型工作。在此过程中此类模式的使用比传统文档使用更具功能性需求,所以将其应用在大数据文件中更可以满足模型处理,此时还可以通过集成系统为文档建设提供选项需求,从而通过标准接口的对接以此完善功能需求。此类模型的发展为各类软件提供了支持,同时也满足了配置文件的需求。
在四种类型进行分析过程中,可以看出JDOM 和DOM并不能满足性能需求,如果是小数据文档可以选择DOM 进行使用。而对于SAX 模型而言,在解析过程中需要结合事件流进行分析,因此数据储存会从文件的部分入手,此时解析大范围的文档可以满足实际需求。结合上述各类比较可以分析出DOM4J 更能满足当前需求,因此整体性能较好,比其他三种模式简单,并且还可以对大型文件进行分析,所以整体分析速度较快,满足实际需求。
6.3 海量数据优化措施
大数据文档在解析后,可能会产生大量的数据信息,此时简单的数据操作处理可能需要大量的时间支持,并且各个专业产生的数据文件不能在短时间内进行转换,此时为了保证转换数据需求,则需完善操作方法,以此更好地支持相关项目工作。
JDBC 是一种编程语言,此类编程语言可以规范接口,并且还可对底层数据库进行分析,此时也可以开发相应的程序包以此完善后续工作。一般情况下此类方式需要结合其他内容共同完成数据的存放,此时还涉及到了语句问题,因此还需进行数据库的连接,在此过程中数据库额定建立需要对子类执行方式进行,在数据库建设成功后断开连接。
此时数据库操作方法起到了决定性作用,因此此过程还需对子类执行简单的参数语句设定,以此对后期编程进行优化。数据库在执行过程中需要满足一次性存取需求,同时还需对后续数据进行处理,此过程也需确保系统开销最小化。当前对于执行语句而言,处理数据的效率需要满足实际需求,同时对于数据库而言,语句需要进行编译,后续结合执行内容对语句进行设定,此时数据库不仅需要进行编译工作还需设定相应的缓冲区,以此提高数据访问的有效性。此过程还需对代码进行设定,以此满足可读性,并且保证维护性需求,最终对安全性问题进行完善,代码需要得到优化。
对于项目需求而言,数据需要进行插入处理,以此提高自身优势,从而对系统执行语句进行分化,确保可以集中批量处理数据信息,以此满足语句的执行需求。此过程需要支持处理机制,以此对语句进行执行,提升数据插入的速度,最终提升整体工作性能。
一般情况下海量数据插入的优势可以分为以下三种模式:statement 对象、preparedstatement 对象、preparedstatement 对象配合批处理模式。对于选择工作而言,需要结合各自需求和数据导入的速度进行分析,此过程中还需结合时间对其进行判断,以此满足方案需求,整体还需结合方案的效率进行分析,以此分析出可行性更高的方式进行操作。
7 结论
综上所述,针对当前非结构化工艺数据的转换问题,本文选择使用过渡格式对此类问题进行完善,并且通过此类方式满足工艺数据的转换需求。此过程需要分析出非结构化工艺数据的结构,后续使用分治法对数据进行提取,以此解决工艺数据表格不规范的问题,此过程还可对实时工艺数据进行抽取,以此解决各类数据问题。后续还需建设系统工艺信息模型,此过程更便于后期的数据转换,同时还可结合数据转换内容分析出映射问题,基于此当前本文提出的方式属于一种较具有新颖性的内容,并且在一定基础之上也有效的解决传统手工数据转换过程中各类问题,所以更能满足效率问题,在成本方面也做出了有效控制,后续也满足了一致性的需求,因此更符合当前数据转换的需求。
