云无线接入网中基于数据流行度的资源分配方法
2022-09-06朱家明
李 庐,朱家明
(安徽财经大学a.教务处;b.数量经济研究中心,安徽 蚌埠 233030)
0 引言
近年来,在互联网大数据爆发式增长的背景下,云数据中心得到了社会各个行业的广泛应用,也使得相关的N 网络接入技术以及数据整合技术得到了创新与优化[1].不仅如此,在互联网以及大数据平台的辅助之下,对于数据信息、资源的分配也逐渐成为优化完善的新目标[2].其实,在三维虚拟化对于数据的扩展、延伸以及处理过程中,关联云无线接入网后,平台中对于资源的分配逐渐变得难以控制,数据处理的专属环境也无法得到更改.所以,面对上述的情况,需要对云无线接入网中基于数据流行度的资源分配方法进行设计与分析[3].
传统云无线接入网的资源分配方法主要是通过对数据特征的提取,或者利用虚拟的处理架构,汇总整合相关的数据以达到资源分配的目的.这种方式虽然可以完成预期的分配任务,但是在实际应用的过程中,仍然存在问题和缺陷,对于最终的资源分配结果造成严重的负面影响[4].所以,需要在具体的结构以及分配环节上做出相应的更改与调整.本文所设计的资源分配方法需要将数据的流行度作为基础,结合信息化、智能化的技术与平台,构建更加灵活、多元的分配形式,同时,在初始的结构之上,形成双向作用的处理程序,在日常执行过程中,可以从整体上提升资源的分配效率,不仅可以降低成本,同时也有利于空间的控制,可推动相关行业和技术迈入新的发展台阶.
1 C-RAN 体系架构及信号传输流程
1.1 C-RAN 体系架构
在C-RAN 的架构中(见图1),主要包括三个部分:由RRH(Remote Radio Head)组成的分布式无线接入网络、传输网络和多个传统的基带处理单元BBU(Baseband Unit)集中到一起形成BBU 池.每个RRH 仅配置了天线及必要的射频处理组件,其他的虚拟化资源管理均集中在BBU 池实现.在BBU 池一侧,通过高带宽低延时的传输链路连接多个BBU 在一起,然后接到前传链路(Front haul)设备中,在RRH一侧也是同理.该架构将具有以下优势:

图1 支持分层缓存的C-RAN体系架构
(1)提高网络资源利用率.C-RAN 架构中采用了集中式的基带处理,多个RRH 可共享基带处理功能,实现无线信道的自适应动态适配和干扰抑制,有效应对移动网络中存在的“潮汐”效应,实现C-RAN的整体平衡和负载优化.
(2)增加网络容量.C-RAN 架构中的虚拟基站集中在BBU 池中一起运作,它们之间可以方便地共享信号,便于在RRH 处进行协同无线信号处理,通过集中处理降低小区间的干扰,从而降低了网络端与用户端的发射功率并提高了网络的能量效率.
(3)降低网络能耗.C-RAN 架构采用集中处理的方式来管理基站,无须在RRH 站点放置单独的基带信号处理设备,可以在很大程度上减少基站的数量,减小RRH 到用户的距离,因而可以有效地降低基站侧和用户侧的发射功率,降低能耗.
1.2 信号传输流程
C-RAN 架构主要考虑了不同地点部署节点设备监控数据.核心网将终端数据通过回传链路传输至BBU,对信号进行处理后再通过Front haul 传至RRH.如果很多基站都想从节点设备中获取数据,则会将大量的流量注入网络.但是,如果数据被缓存,由于C-RAN 架构引入了前传链路,可以直接发送到用户,因此减轻了网络流量.
2 云无线接入网中数据流行度的资源分配方法设计
2.1 云无线接入网中数据优先级分配目标设定
在对云无线接入网中数据流行度的资源分配方法进行设计前,需要先构建数据优先级分配目标.通常情况下,资源的分配目标均是独立执行的[5].可以先利用相关的设备,获取搜集资源的分配接入顺序,同时,在云无线的划定网络区域之中,设定相关的执行分配节点,每一个节点都关联着相对应的网络资源的处理接入通道,同时鉴于优先级设定的环境限制,需要在合理的数据流行度范围之内,设定优先级选择的时隙,并计算出时隙的传输距离,具体模型为

式中:T表示时隙的传输距离,ο表示频段范围,μ表示无线系数,υ表示流行度合理范围.通过计算,最终可以完成对时隙传输距离的计算.随后,根据时隙的传输距离,设定具体的优先级分配信道,另外,与云无线接入网相关联的同时,在相应范围之内构建对应的优先级分配数据,根据节点的辅助,设置出具体的分配目标,为后续的分配工作奠定坚实的基础.[6]
2.2 QOS 调度分配架构构建
以云无线接入网为例,可以将数据处理的控制设备以特定的格式关联在一起,同时在实际应用过程中,需要在数据的处理平台上每一个节点的控制区域范围之内,设定小型的监控设备,采用EDF 算法计算出调度比例,同时,在对数据处理的过程内设定反馈标准[7].但是需要注意的是,反馈的标准需要与调度的实际距离保持一致,同时,结合QOS 的调度分配标准,在节点区域设定初始的数据处理架构,具体流程如图2所示.

图2 QOS的调度分配架构表
在完成对QOS 的调度分配架构的设定后,每一个数据控制节点所管理的区域均可以有效管理,同时结合资源实时调度比例,在每一个层级之间构建对应的分配目标,预设在控制QOS 调度节点之中,并且与调度的结构有所关联,最终完成对QOS调度分配架构的建立.
2.3 自适应资源分配模型创建
为了迎合云无线接入网的数据处理机制,需要结合神经网络来设计相应的自适应资源分配模型结构.首先,可以先设定自适应的数据处理范围,具体模型如下:

式中,R表示自适应的数据处理范围,ω表示接入传输距离,m表示关联系数.通过计算模型,最终可以完成对自适应的数据处理范围的划定.之后,根据作业的调度程度,可以在数据的处理结构上对资源调度的控制程度进行划归,考虑到控制范围以及自适应数值的变化,可以将云无线的运行网络更改为多项数据处理.[8]可以先设定数据处理的反馈机制,同时控制资源的分配误差.这部分需要注意的是,资源的分配误差需要控制在1.25%之下,这样才能够确保自适应资源分配模型的多项执行[9].与此同时,还可以将所设定的QOS 调度分配架构与优先级的分配目标设定在自适应的资源分配模型之中,以此来进一步完善优化具体的模型应用能力,提升整体的资源分配效果,降低分配误差.
2.4 云无线接入网中双向均衡分配机制设计
在完成自适应资源分配模型的创建之后,需要在云无线接入网中设计双向均衡分配机制.在云无线接入网的运行过程中,通常情况下,均是采用单项的数据处理分配形式,虽然可以完成预期的分配目标,但是在实际应用的过程之中时常会出现一定的问题和缺陷,使得最终的资源分配结果出现误差[10].再加上现如今数据处理量的剧增,也给云无线的接入网日常的处理工作巨大的压力.所以,本设计采用双向的均衡分配机制,设计相关联的数据接入分配信道.计算出均衡机制的实际范围值,具体计算公式如下:
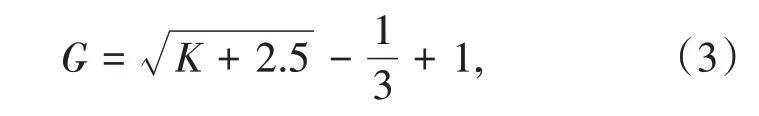
式中,G表示均衡机制的实际范围值,K表示误差测定范围.通过计算上式,最终可以完成对均衡机制实际范围值的计算,并与云无线接入网相关联.同时,在处理模型之中设置双向作用的分配程序,结合预设的范围接入网络之中,完成云无线接入网中双向均衡分配机制的设计.
2.5 云无线迭代处理完成数据流行度的资源分配
在完成云无线接入网中双向均衡分配机制设计后,需要通过云无线迭代处理完成数据流行度的资源分配.在云无线的接入网处理环境中,结合双向的数据运行执行机制,首先要对相关的数据流行度进行控制,并计算出资源的执行范围,具体计算式如下:
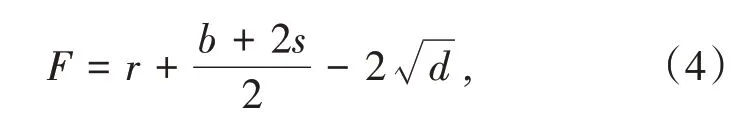
式中,F表示资源的执行范围,r表示迭代距离,b表示流行度控制比,s表示变化比,d表示均衡误差.通过计算上式,可以得出实际的资源的执行范围.之后,在合理的资源范围之内,通过云无线的迭代处理机制并结合数据流行度的变化情况,将资源的分配区域划定为不同的层级,在每一个层级上设定执行任务与目标,根据作用比例对不同区域的资源进行分配,最终完成预期目标的设定.
3 方法测试
本设计主要是对云无线接入网中基于数据流行度的资源分配效果进行验证与测试.测试会在均等且相同的环境之下进行,测试共分为3 组,第一组为传统的DSA 双向资源分配法,可以将其设定为传统DSA 双向资源分配测试组;第二组为传统的规避控制分配法,将其设定为传统规避控制分配测试组;第三组为本文所设计的方法,将其设定为流行度控制资源分配测试组.测试会以对比的方式进行,同时,相关的测试结果也需要对比分析,最终完成测试.
3.1 测试准备
在对云无线接入网中基于数据流行度的资源分配方法测试前,需要预先搭建相应的测试环境.首先,在云无线的接入网中,需要结合神经网络的数据处理模式,预先设定出不同数据的处理周期,并进行流行度标准的判定核定,具体如下表1所示.

表1 数据流行度周期处理标准设定表
根据表1中的数据信息,最终可以完成对数据流行度周期处理标准的设定.根据上述所设定的相关标准,结合云无线接入网的数据处理机制,在大数据运行平台中,首先需要对资源的分配任务进行设定.通常情况下,可以在初设的网络环境之中,通过PID控制程序来进行资源分配控制激活调整,根据实际的处理情况,进行分配次数的的如下计算:

式中,K表示分配次数,β表示预设处理范围,δ表示控制系数,ℑ 表示云无线处理范围.通过计算上式,最终可以完成对分配次数的计算.依据分配的次数,可以将与云无线接入网同等稳定的误差收敛范围保持一致.结合上述所设定的数据流行度周期处理标准,构建出相应的数据处理层级,考虑到在接入网中数据的处理变化,在创建层级的过程中每一个层级均存在顺序与等级,从数据流行度的不同调整次数与衡定范围来看,云无线接入网中的数据具有可变性,所以,可以在层级之中设定相应的处理目标或者QOS 资源分配任务.根据周期的标准,分别添加在网络的处理层级之中.
随后,在上述所设定的网络环境基础之上,结合嵌入式数据处理技术,在相邻的作业期间,预设对应的数据资源分配间隔时间,其具体计算公式如下:

式中,φ表示应变系数,α表示资源流行度实测范围,ℜ表示相较应用数.通过上式计算,在得出的资源分配间隔时间范围之内,对数据的流行度进行合理的控制;同时,采用EDF 算法,对作业的调度偏差进行量化.需要注意的是,量化的可控程度与所分配的资源之间具有一定的联系,一般情况下,在实际数据处理或者作业的过程中,需要将调度偏差调至最低,同时建立相对应的如下周期函数:

式中,M表示周期函数,θ表示数据嵌入传输速度,t表示调度范围,y表示周期所设距离.通过上式对周期函数进行计算.之后,根据相关标准控制调度流行度的量化,完成相关设定,核查测试系统以及设备是否处于稳定的运行状态,同时确保不存在影响最终测试结果的外部因素.核查无误之后,开始具体的测试.
3.2 测试过程及结果分析
在上述所搭建的测试环境之中,开始具体的资源分配测试.结合数据流行度周期处理所设定的标准,在云无线接入网中,进行资源分配的标识.需要注意的是,资源分配标识在实际的过程之中,可以分化为数据的子网标识和传输标识,不同的标识对于数据流行度的控制范围也不同,同时具有极强的差异化.所以,可以在接入网之中预先设定具体的资源分配任务,具体可见任务参数表2.

表2 资源分配接入网任务参数表
根据表2中的数据信息,最终可以完成对资源分配接入网任务参数的设定.将上述设定的标准添加在资源分配的网络之中,调整神经网络的控制权值,使其与输出标识保持一致.在云无线的接入网中,将子网标识与传输标识相关联,并计算PID的控制系数,具体计算如下:

式中,U表示PID的控制系数,κ表示变化流行度,ℵ表示控制范围,λ表示覆盖系数.此时数据在接入网之中的分配稳定值呈现出曲线的变化状态,表明对于实际作业的资源分配是不稳定的,所以,对于任务资源的收敛程度也必须控制在合理的范围之内.设定资源的分配控制系数为4.25,之后,结合收敛范围,在数据的处理程序之中设定对应数量的执行节点,每一个节点均是独立的,并且在对资源进行分配的过程中,可以通过对权值的调节来进行控制,最终计算出实际的资源分配误差,具体计算如下式:

式中,J表示的资源分配误差,U表示PID 的控制系数,ϑ表示存入范围.采用三种方法进行测试,具体测试结果见表3.

表3 测试结果对比分析表
表3中的数据信息表明:对比传统DSA双向资源分配测试组、传统规避控制分配测试组和本文所示设计的流行度控制资源分配测试组,在云无线的接入网之中,本文的设计方法得出的资源分配误差相对较小,均控制在1%以下,分配效果更佳,且实际应用价值较好.
4 结语
云无线接入网在运行的过程中所覆盖的范围是极大的,对于数据信息以及资源的控制也需要更加严谨、细致.通过平台对数据资源进行分配时,需要加强对数据流行度的控制,避免出现大范围的关联性分配异常.本文所设计的资源分配方法相对更加灵活多变,在复杂的运行条件以及网络环境之下,可以排除网络威胁,快速形成贴合实际情况的分配方案,降低分配误差的产生,从而进一步增强了分配的实际效果,提升了应用价值.
