一种时序数据模式演化的跟踪与查询方法
2022-09-06万英格刘英博
赵 鑫 万英格 刘英博,2
1(清华大学软件学院 北京 100084)
2(工业大数据系统与应用北京市重点实验室(清华大学) 北京 100084)
(zhao-x19@mails.tsinghua.edu.cn)
在物联网与大数据广泛应用的背景下,各类感知设备每分每秒都会产生海量的时间序列数据,存储、查询和统计分析这些数据的需求使时序数据库的重要性日益凸显.在敏捷开发等软件工程的工业实践中,智能设备主控软件版本频繁变更,其所产生的数据模式也会形成多种版本.在实际应用中,一个时序数据库经常需要同时维护数量众多且版本多样的传感器数据,这就引出了时序数据模式演化的问题.
数据模式演化(schema evolution)[1]在数据库领域有多年的研究历史,一般指不会导致数据丢失的模式变更过程.目前已有的数据库对数据模式演化的功能实现各有侧重,本文对历史模式支持方式分为3类:
第1类是支持离线模式演化的数据库,具体包括使用DeltaSQL[2]等工具直接记录引起模式变更的语句,以及LiquiBase[3],Rails Migrations[4]等以数据库变更记录的形式跟踪模式版本演化过程.以LiquiBase为例,在根据变更记录主动切换模式版本时,将通过自动化方式严格顺序执行一系列的SQL脚本.在这类数据库中,数据往往只存在单一的数据模式,且在执行脚本期间,模式演化功能也会受到影响.因此,这一类研究很难满足工业物联网场景中实时读写数据的需求.
第2类是支持在线模式演化的数据库,如Bull-Frog[5],Ratchet[6]等.这一类数据库在支持模式演化的同时,不会影响数据读写功能,且在模式变更期间,可以通过新旧模式访问数据.以BullFrog为例,在模式变更时实现了数据懒迁移的基础上,还通过同步锁机制支持并发情况下的懒迁移.在工业物联网场景中,对历史模式的数据进行查询与分析是十分常见的需求,显然这一类研究也不能满足实际需求.
第3类是支持多模式版本管理的数据库,例如InVerDa[7],LESSQL[8]等.这一类数据库可以支持应用同时访问多个历史版本模式下的数据,功能最为全面,也是最受关注的一类模式演化方法.这一类方法在数量较少的关系表上实现多模式版本管理方面有较多研究,而对于维护大量设备、时间序列的时序库中的模式演化问题少有研究,对于时序数据及其模式演化的过程也缺少形式化表述.
时序数据库的关键是能够快速地读写和分析数据[9],在时序数据库的发展中,有3种不同的构建方式:第1种时序数据库是在关系型数据库的基础上,对SQL语言进行时序相关的扩展来实现的,例如Vertica[10]等.第2种时序数据库会选择HBase[11]和Cassandra[12]等列式存储数据库来管理时间序列数据,如OpenTSDB[13],KairosDB[14]等.这些方案不可避免地受到列式存储数据库自身问题的限制.第3种时序数据库是自底向上全部面向时序数据搭建的,例如InfluxDB[15],Apache IoTDB[16]等.这一类数据库根据时序数据库的特点作了针对性设计,查询性能和存储压缩等方面的表现显著优于第1种和第2种构建方式的时序数据库[16].以清华大学发起的开源工业物联网时序数据库Apache IoTDB(以下简称为IoTDB)项目为例,其数据模型是从工业物联网实践中抽象出的树型结构,有助于简化工业物联网中常见的建模需求.
随着工业信息化的高速发展,时序数据库维护的软硬件设备会发生滚动升级,这对时序数据模式变更的跟踪及控制提出了要求.以某工程机械生产商的控制器程序为例,一个于2008年上市的工程设备,当前在役数量超20 000台,在这些设备上部署的控制器主控程序多达72个版本.管理这些设备,需要收集并无损地存储不同版本的数据.选取其中任意一个或若干个版本的数据模式作为存放数据的标准模式,然而都会有大量设备的数据因为模式不兼容而需要进行有损转换后才能存储.即使采用最常见的20个版本作为标准模式进行存储,也只能覆盖不到90%的设备,即仍有数千台设备数据无法在无损情况下保存.
通过人工干预或简单的启发式方法很难满足时序数据采集设备在实际应用场景下不断滚动升级的需求,因此拟引入智能化控制方法结合模式演化研究应对时间序列数据模式演化的挑战.如何保存不同模式的时序数据,跟踪各设备模式的演化过程,对不同设备、不同模式的数据进行查询与分析,是该项智能化控制中的重要问题.
以上背景引出了本文进行的时序数据模式演化跟踪与查询方法的研究.本文工作的主要贡献有3个方面:
1) 提出了时序数据模式特征的形式化定义,将时序数据库的模式演化过程进行形式化表达.
2) 设计了多模式版本的存储与查询方案,并以非侵入方式,在IoTDB上扩展了多模式存储与跨模式查询功能.
3) 通过实验验证和评估了本系统的正确性、性能表现、可扩展性,为本系统未来扩展应用到其他时序数据库提供了借鉴方向.
1 时序数据及其模式的形式化定义
本文中设计的时序数据模式演化跟踪及查询方法是在时序数据库IoTDB基础上实现的,因此本节将在1.1节中简要介绍IoTDB的数据模型及架构,在1.2节与1.3节中分别提出时序数据及其模式的形式化表述.
1.1 时序数据库IoTDB简介
在工业物联网背景下,时序数据的使用场景丰富.为了提高面向工业应用的数据处理能力,清华大学发起研发工业物联网时序数据库IoTDB,其技术架构如图1所示.由图1可知,在IoTDB内部,时序数据以树型结构组织,从树的根节点到叶子节点涉及3个基本概念:
1) 存储组(storage group).一个存储组下可管理多个设备,同类的设备往往存储在同一个存储组中.
2) 设备(device).一个工业设备实例,设备上往往部署了多个传感器用于采集时间序列数据,同时设备也可以标注一些无关时间序列的信息即“属性”.
3) 测点(measurement).每组测点对应一个传感器采集的时序数据.传感器是IoTDB中存储的数据及路径组织的最小单元.存储组、设备和测点名称组成的路径可以唯一确定一个时间序列.
在IoTDB的查询语言中,描述设备、传感器和时间序列的表达式称为路径(path).查询语句也支持在路径中使用通配符“*”,例如“root.vehicle.*.status”代表分布在root.vehicle节点下、包含名为status的传感器的所有设备.
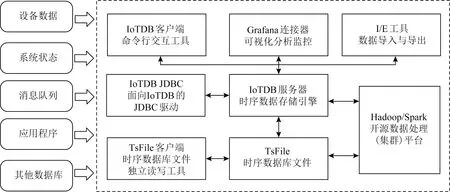
Fig. 1 Architecture of IoTDB图1 IoTDB架构
IoTDB的每个测点中存储着一系列时间戳-数据对(时间戳,数据),测点的每个时间戳都是唯一的.用户在创建时间序列时可以定义其数据类型和编码方式,以提高存储效率.
IoTDB采用如图2所示的客户端-服务器架构,由客户端将查询请求发送给服务端后,由服务端将查询请求进行解析、执行直至最后返回结果集.
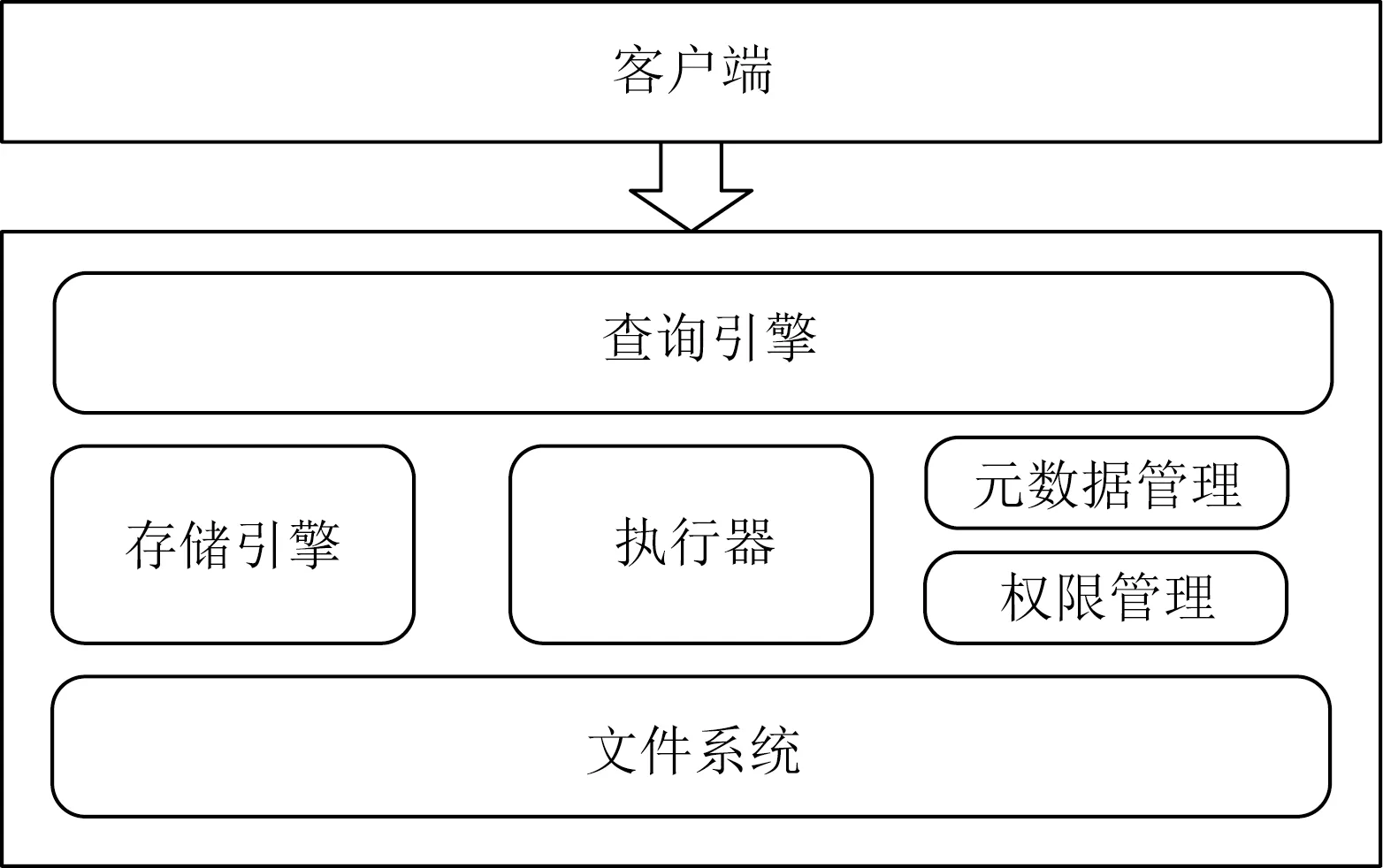
Fig. 2 Client-server architecture of IoTDB图2 IoTDB客户端-服务器架构
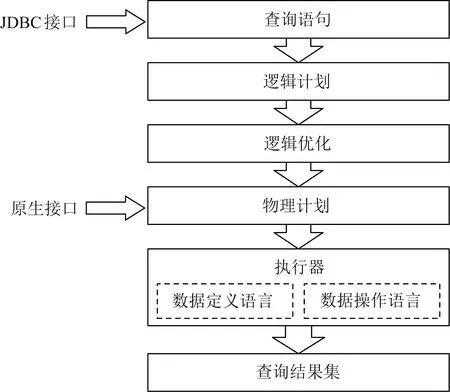
Fig. 3 Query engine of IoTDB图3 IoTDB查询引擎
IoTDB的查询引擎架构如图3所示,这与第3节密切相关.查询引擎收到原始查询语句后,使用ANTLR 4[17]将其解析成抽象语法树,并在ANTLR语法解析树监听器中构建逻辑计划.查询引擎对逻辑计划进行优化,并生成物理计划交给执行器执行,最后构造查询结果集.
相比基于关系型、列式存储的时序数据库和以InfluxDB为代表的原生时序数据库,IoTDB在高压缩、高吞吐、高效查询方面表现更优[18],易于分布式部署,可对接多种开源工具,便于学习和开发测试,因此本文选择以IoTDB为基础展开相关研究.
1.2 时序数据的特征与形式化定义
时序数据是带有时间戳的数据序列,其基本单元是带有时间戳的数据点.根据时序数据实践经验,可以定义时序数据.
定义1.ts=(c,{(ti,vi)}),i∈|{(ti,vi)}⊆T×V,i∈为时间序列,其中:
2)c表示该时序数据的元数据,在时序数据库中体现为该时间序列的路径及该序列的属性等;
3) {(ti,vi)}是时间戳与数据构成的序列,满足{(ti,vi)}⊆T×V,i∈,其中T是所有时刻的取值范围,V是所有数据的取值范围.
如果把一个时间序列看作是关系型数据库中的一张表,那么可以把c理解为表名与列名,把(ti,vi)理解为1行数据,把{ti}理解为表的主键,把{vi}理解为表中的1列数据.
时序数据具有时序特征,即具有时间上的先后顺序关系,因此,集合T上应定义有一种全序关系,即任意2个时刻t1,t2都可以比较大小,事实上几乎所有时序数据库的设计都应用了这个性质.在使用滑动窗口对时间序列进行分析时,还需要时刻间隔的概念.因此可以在集合T上定义一种二元运算,±:T×T→T,因而我们同样可以比较时刻间隔的大小关系等.一般地,时刻和时间间隔可以统称为“时间”,在时序数据库中一般用“Unix时间戳”表示.
计算机中的数据都有其特定的数据类型,即可以将时间序列中的度量值v展开为vi=(di,ui),其中di是数值部分,ui是数据类型部分,即有定义2.
定义2.时间序列中的度量值vi=(di,ui),di∈D,ui∈U,即有V⊆D×U,其中:
1)D是时序数据库中可以表示的所有数值的集合,在时序数据库中一般为一个字节数组;
2)U是时序数据库中所有数据类型的集合,在时序数据库中一般包含bool,uint32,float32等类型.
在时间序列数据中,还有一些与时间信息不直接相关的信息,例如时间序列在数据库中的路径、属性等信息,可以用c来表示,即有定义3.
定义3.时间序列中的c=(c0,c1,c2,…,cn,c*),其中:
1)c0,c1,c2,…,cn为时序数据在数据库中的路径,c0一般为时序数据库根节点“root”,cn一般为时序数据测点名称;
2) 一般来说,时序数据的路径也表征了测点传感器设备在物理空间的归属关系,一般有ci+1∈ci,例如某省市区某站某传感器的时序数据路径可以表述为“root.省.市.区.站.传感器”;
3)c*为时序数据自身的属性信息,例如标签、别名等,属于与时间无关的元信息.
1.3 时间序列模式的特征与形式化定义
数据模式是一种描述数的结构的形式化表述[6],因此时序数据的模式可以从一个简单的时间序列来考虑.对于时间序列ts=(c,{(ti,vi)}),i∈|{(ti,vi)}⊆T×V,i∈,其中vi=(di,ui),di∈D,ui∈U,集合T及其运算决定了时间的定义,集合V⊆D×U决定了取值的范围和单位,符号c决定了时间序列的物理含义.因此,三元组(c,T,V)决定了一个时间序列的结构和意义,是时间序列的模式.
定义4.对于时间序列ts=(c,{(ti,vi)}),其模式s有s(c,T,V).
其中,c定义了时间序列在时序数据库中的路径及其物理含义,T定义了时间序列的采样频率,V定义了时序数据数值的范围与类型.在IoTDB中,c与V中的信息都可以被改变,但采样频率精确度限定到毫秒,因此本文中的模式演化跟踪主要记录c与V中信息的变化.
在时序数据应用中,一个工业设备上经常配备多个传感器,在设备滚动升级的过程中,每个设备上时序数据的模式也需要进行跟踪管理,因此也需要对单个设备产生的时序数据模式进行定义.
定义5.如果时间序列tsa=(ca,{(ta,i,va,i)})与tsb=(cb,{(tb,j,vb,j)}),满足ca,k=cb,k,0≤k 定义6.一个时间序列组TS的模式可以定义为ds{C(n-1),m,V′,mv},其中: 1)C(n-1)是这些同设备时间序列中元数据相同的部分; 2)m是该时间序列组下各时间序列cn及c*的并集; 3)V′是所有时间序列的数据及其类型的集合; 4)mv是各时间序列名称与其数据及其类型的对应关系. 例如,对于某地气象站某气候传感设备,可能存在温度传感器与湿度传感器,那么其时间序列的元数据可以分别表示为: 因为对于k=0,1,2,3满足ca,k=cb,k,且k=4时,ca,4=temp,cb,4=humidity即ca,4≠cb,4,所以可称tsa与tsb属于同一个时间序列组TS={tsa,tsb}.按照定义6,对于时间序列组TS,其数据模式ds可以表述为 这也是本文对模式版本表进行建模的理论基础. 时序数据演化的本质是时间序列的模式发生了变化.因此对于时间序列ts=(c,{(ti,vi)}),其模式三元组s(c,T,V)中的任一项发生变化时,即认为发生了时间序列模式变更.将时间序列模式变更发生的时刻,以及变化前后的模式作为时间序列数据模式的变更记录,其形式化定义如定义7所示. 定义7.时间序列模式的变更记录scn+1(t,sn,sn+1),n∈是模式发生变化的时刻t及变化前后模式sn,sn+1组成的三元组.特别地,对时间序列最初的模式取s0. 研究时间序列模式演化的过程中,经常涉及时间序列模式多个变更记录.每一次变更前后的模式存在前驱与后继关系,即有定义8. 定义9.时间序列模式的前驱与后继关系具有传递关系,即若存在si→sj∧sj→sk,{i,j,k}⊆,则si与sk之间也存在前驱与后继关系,记为si→→sk. 类似地,对于时间序列组的模式也可以定义其变更记录及前驱后继关系. 定义10.时间序列组的模式变更记录SCn+1(t,ds,n,ds,n+1),n∈是时间序列组模式变更的时刻t及变更前后时间序列组模式ds,n,ds,n+1组成的三元组. 定义11.时间序列组的模式变更记录间也存在前驱、后继与直接前驱、直接后继的关系. 结合定义4~11,时序数据或时间序列组的模式演化过程,可以用一系列时间序列组的模式变更记录描述.作为形式化表述,考虑到应与具体的时序数据库设计无关,本节中对时间序列组变更记录的具体变更内容并不作限定,但在后续内容中会根据IoTDB的实现对本文研究的时间序列组模式变更记录进行具体描述.图4用本文定义的形式语言描述了一个时间序列组的模式变更的过程. Fig. 4 Example of schema evolution on timeseries group图4 时间序列组模式演化示例 与关系型数据库中模式演化需要解决的问题类似,时序数据模式演化带来的问题主要集中在存储与数据库当前模式不同的数据(跨模式存储)及查询存在多个模式版本的数据(跨模式查询).本节将对这2个问题进行建模与分析. 2.2.1 跨模式存储 本文研究的问题模型中,需要区分时序数据库与工业设备2个概念,前者是用于存储数据的虚拟概念,后者是产生数据的物理概念,所以需要考虑数据库模式变更与设备产生数据的次序关系.在考虑数据库模式变更与设备模式变更时间关系的条件下,数据模式演化的各类情况,可以简化到从一个“时间戳-数据对”的角度进行讨论.一个时间戳-数据对(t,v),称其在传感器中产生的时刻为tval(valid time),一般地有t=tval.这个时间戳-数据对被存储到时序数据库中的时刻为ttra(transaction time),其在数据库中被外部应用查询或更新的时刻为tque(query time).同时,记录时序数据库中对应时间序列组发生模式变更的时刻为tevo(evolution time). Fig. 5 Relation between data lifetime and schema evolution图5 模式演化时间关系 对于一个时间戳-数据对,其读写过程与数据库模式变更的关系可以用时段逻辑[19]建模,并用图5来描述.图5中标记有tval,ttra,tque的横线描述了数据产生、记录及查询更改的时间区间,即满足tval 情况③与情况④中,数据库模式变更发生在数据完成存储之后,即ttra 情况①与②中,数据产生模式变更时刻tevo在数据存储到数据库时刻ttra之前,即tevo Fig. 6 Relation between schema evolution of database and device and timeseries data图6 数据库和设备的模式演化与时序数据的关系 情况①中,因为满足tevo 情况②③④中,因为存在tval 2.2.2 跨模式查询 跨模式版本查询的应用需求,来自工业物联网中滚动升级导致的同类设备模式不统一、设备与数据库模式不统一等情况时,对不同设备、不同模式的各个时间段进行统一查询与分析要求.从功能上来说,跨模式查询系统的内容主要包括3种情形: 1) 对同一设备生命周期中多个模式版本的数据进行统一查询,如图7所示; 2) 对指定时间范围内多个设备的历史模式数据进行同时查询,如图8所示; 3) 以历史或当前的模式版本定义查看指定时间范围的数据,如图9所示. Fig. 7 Crossing schema version query on single device图7 同一设备跨模式版本查询 Fig. 8 Designated time interval crossing schema version query on multiple device图8 多设备指定时间范围跨模式版本查询 Fig. 9 Crossing schema version query on designated result schema and time interval图9 指定结果模式版本与查询时间范围的跨模式版本查询 在满足3种情形要求的同时,本系统也兼容IoTDB原生各类查询命令,并扩展支持部分语法,如统计设备下的时间序列计数等,保证了本系统功能的一致性. 本文用关系代数语言对跨模式版本查询进行了形式化描述.首先定义在时序数据库中进行跨模式版本查询的若干运算符号: 2) 查询语句中SELECT关键字可进行投影运算∏; 3) 查询语句中WHERE关键字可进行选择运算σ; 4) 查询语句中聚类关键字如GROUP BY,SUM,AVG等聚合运算G. 对于时间序列组TS={tsi},可以定义某个设备为Dts1ts2…tsn,用Di表示第i个设备,用Di,j表示第i个设备的第j个版本.因此对于一个原生的跨设备查询可以表述为Q=G(∏(σ(D1D2…Dn))),对于单设备查询可以取n=1,对所有相关设备可取D={D1,D2,…,Dn}.可以用符号简化表述为O(·)=G(∏(σ(·))),此时一个原生的多设备查询可以表述为Q=Q(D,O). 对于跨模式版本查询,用户还需要指定查询模式版本范围R、结果集投影模式S,因此一个跨模式版本查询可以记为Q=Q(D,O,R,S).实际应用中可以在模式版本表中通过R确定D,例如在图8中可以得出D={D1,0,D1,1,D1,2,D2,0,D2,1}.特别地,如果用户没有指定结果集投影模式S,本文系统中将默认取所有模式中各字段的并集S0作为结果集投影模式. 在实际执行跨模式版本查询时,系统会将Q=Q(D,O,R,S)分解为Q={q1,0,q1,1,…,q1,j,…,qm,n}对每个设备、每个模式版本的查询,其中qi,j是对第i个设备第j个模式版本的查询的投影结果,即有qi,j=∏S(σ(Di,j)).在跨模式版本查询最后,将这些子查询进行合并得到结果,即有Q=∪Di,j∈DO(Di,j). 为了扩展时序数据库对模式演化的支持能力,验证第1节中相关形式化定义及讨论的正确性,本文在IoTDB基础上实现了一套模式跟踪系统,并在不同场景下设计了跨模式版本查询的支持方案.本节将依次介绍模式跟踪系统及跨模式版本查询的设计与实现. 在时序数据库IoTDB中,时间序列模式的演化主要在存储结构中的设备层进行研究.一个设备上可配多个传感器测点,这些测点的数据一般在数据库中存储为一个时间序列组.参照关系数据库中模式演化的基本类型[20],时序数据模式演化中的基本类型主要包括设备的创建和删除,设备中时间序列的创建和删除,设备或时间序列的重命名,时间序列定义与别名、标签、属性等元信息的修改等.由于IoTDB自身不支持设备、时间序列的重命名和时间序列的数据类型、编码方式和压缩方式等属性的修改,模式跟踪系统要重点设计实现3个模块. 1) 监听时序数据模式变更操作,包括:①设备的创建与删除;②时间序列的创建与删除;③时间序列元信息的修改; 2) 自动记录所监听操作产生的模式版本信息; 3) 追溯历史模式版本、切换指定模式版本等版本控制相关功能. Fig. 10 Architecture of schema tracing modules图10 模式跟踪模块架构 图10中,监听功能通过解析IoTDB查询语句实现.版本自动记录可在IoTDB中存储,也可以在外部文件、数据库中存储.追溯历史模式版本、切换指定模式版本等功能涉及模式与数据的映射关系,需要对数据库存储结构中的逻辑模式或物理模式进行修改.本文将逻辑模式和物理模式进行分离,逻辑模式是用户直观接触的数据模式,也是模式演化与版本控制的呈现结果;物理模式是数据库服务端具体实现的存储结构,本文中是IoTDB实际存储文件结构的模式.在需要将本系统扩展到其他时序数据库上时,与逻辑模式的定义相似,主要修改与物理模式相关的模块即可适配应用. 本文系统采用非侵入式设计,以IoTDB命令行接口客户端为基础进行扩展,将查询语句监听与解析的过程、用户可见的逻辑模式在IoTDB数据服务系统以外实现,系统结构如图10所示.用户在使用本系统时的体验与原生IoTDB客户端接近,易于上手且不影响IoTDB原生SQL语法与查询、处理数据功能的使用. 模式版本表记录了物理模式和逻辑模式之间的映射,以及模式的前驱后继关系.该表可以描述模式演化的过程,记录了版本号、变更内容等追溯历史模式版本、切换指定模式版本所必须的信息,以及逻辑模式与物理模式的对应关系、当前版本与历史模式数据的联系等.模式版本表的具体定义如表1所示,表1中的每行数据对应一个设备(时间序列组)的一个模式版本. 对照本文对时间序列组模式的定义,即ds{C(n-1),m,V′,mv},表1中存储的virtual_device与physical_path实际存储了C(n-1)中的信息,schema_delta与schema_snapshot存储了m,V′,mv的信息,timestamp,version_id,parent_version中存储的信息可以便于代码检索实现. 历史模式数据包含了各设备各版本模式下的数据,包括因为模式变更而删除的数据(如删除某时间序列).这些数据与当前版本模式的数据分别存放在不同存储组,确保命名空间不冲突,同时支持历史版本模式数据的恢复. Table 1 Definition of Schema Version表1 模式版本表定义 本文系统将模式版本表和历史模式数据(下称“系统数据”)与一般的时序数据(下称“用户数据”)存放在同一个IoTDB中,在具体实现上对系统数据加以屏蔽,使用户无法通过IoTDB原生语句直接访问系统数据,避免了系统数据与用户数据之间的冲突. 3.2.1 系统实现的关键问题 本文所设计系统的目标是自动记录、跟踪时间序列模式演化,同时存储各版本模式的数据.在实现系统的过程中,有3个关键问题需要进行说明: 1) 非侵入式模式变更命令监听与解析.除在数据库服务端进行的解析语句过程之外,在客户端额外对查询语句进行了一次解析,得到抽象语法树,获取各个语义节点.相比侵入式地在数据库服务端进行解析或在客户端简单地进行关键词过滤,本文的方案虽然需要额外的语法解析时间开销,但正确性高且维护成本低,扩展性也更强.在遇到路径中含有通配符时,本文方案需要额外执行查询来确定对应的时间序列和设备,但大多数时候不用额外查询即可确定模式变更的范围. 2) 用户数据虚拟映射,提高系统效率.进行模式变更时,有3个步骤:①翻译用户命令中的逻辑模式至物理模式;②在模式版本表中增加新记录;③将当前用户数据移入历史模式数据.当数据量较大时,步骤③的运行将成为系统性能的瓶颈,因此本系统在所有时序数据写入时就存入历史模式数据,用户数据中仅保留相应模式定义,如图11所示.这种策略带来的额外复杂度是对操作数据点的语句也要进行改写,但与移动某模式版本下所有时序数据相比,该方案运行开销更小. 3) 将逻辑设备各模式版本数据分别存储到系统数据的物理设备中.历史模式的定义存储在模式版本表的模式快照列,结合模式变更内容列中的语句,用户可以将指定设备手动恢复到历史模式定义中.对于每个逻辑设备,其各模式版本的数据分别存储在不同的物理设备数据中,跨模式版本查询时从对应的物理设备中分别取出结果,再进行结果集合并.该方案使多模式版本查询的过程较为复杂,但可以完整地保留历史数据,是一个初步可行的解决方案,实际结构如图12所示. Fig. 11 Reflection from user StorageGroup to system StorageGroup图11 用户存储组与系统存储组映射关系 Fig. 12 Relationship of storage between logical device and physical device图12 逻辑设备与物理设备的存储关系 除上述3个关键问题以外,本文系统设计实现中还解决了屏蔽系统数、版本号命名空间定义等问题. 3.2.2 系统实现功能描述 本文系统的模式跟踪功能是在IoTDB原生客户端基础上扩展实现的,即在客户端增加了一套语法解析代码,并在解析树中增加了模式跟踪相关的逻辑,以达到支持模式演化且向用户屏蔽系统数据的目的.为了使用户可以使用查看模式历史版本信息、修改历史版本模式中的数据等功能,本系统在语法解析树中扩展了一套语法规则,具体规则内容及含义如附录A表A1所示. 跨模式版本查询架构如图13所示.跨模式版本查询是在模式跟踪的基础上扩展实现的.相比于模式跟踪系统,跨模式查询功能只需访问而不需要对已有数据进行修改,但对查询结果需要合并投影,这些功能实际在客户端-服务器通信的双向过程中分别加以实现. Fig. 13 Architecture of crossing schema version query图13 跨模式版本查询架构 3.4.1 系统实现的关键问题 实现跨模式版本查询的关键是对数据查询的拆分与合并,并对IoTDB中其他相关查询的功能进行兼容支持.在实现的过程中,有3个关键问题需要说明: 1) 自动推断并缺省填充时间序列在某些模式版本不存在的数据点.对于某些时间序列,可能在某些模式版本中被删除或尚未创建,当这些时间序列相关模式版本被查询时,本文系统将进行自动推断并缺省填充.具体在返回包含该时间序列的结果集中,对不存在的时间戳-数据对补充空值NULL.出于效率考虑,对于在任何模式版本中都不存在的时间序列不予展示. 2) 限制不同模式版本间数据类型的转换.即对于某些时间序列,在不同模式版本中可能有不同的数据类型,在这些时间序列相关模式版本被查询时,本文系统将不同类型数据转换为本文类型数据.这一方案会对部分数据带来精度损失,但针对设有不同数据类型的底层时序数据库有更高的兼容性.同时,当结果集需从众多不同模式版本的子结果集合并时,这一限制也可以提高合并效率. 3) 提前解析通配符路径加速跨模式版本语法解析.对于存在通配符的路径,本系统无法直接根据模式版本表进行改写,需要在改写前向时序数据库读取通配符匹配的完整逻辑路径,即在用户数据中执行一次通配路径的查询命令以确定符合条件的所有完整逻辑路径,再将其应用到改写过程中,以及早确定返回结果集的定义,方便构建结果集. 3.4.2 系统实现功能描述 跨模式版本查询的功能主要基于SELECT语句进行扩展实现,以支持对多设备或单设备进行跨模式版本的查询功能.扩展后的语法及功能说明见附录A表A2. 此外,本系统对IoTDB中部分统计数据查询语句也进行了相应的跨版本语法扩充支持,附录A表A3对其语法代表的原生功能和本系统扩充后的功能进行了简要介绍. 本节将通过测试用例对本文所设计的系统进行正确性验证,包括模式演化跟踪功能及跨模式版本查询功能等.时序数据模式的生命周期,可以分为创建、更新、查询与删除4个阶段.其中,更新查询又包括对数据模式自身的更新查询以及对数据模式下数据点的更新查询.针对时序数据模式的生命周期,可以设计一组较为完备的测试用例,具体来说包括6方面的内容: 1) 查看指定设备的模式演化历史及其元信息; 2) 跟踪并记录创建、更新、删除时间序列; 3) 切换设备模式到指定的历史版本上,并同步切换对应设备的时序数据; 4) 创建、删除某一模式下逻辑设备的数据点时,物理设备数据被相应地修改; 5) 在指定范围的模式版本上查询时序数据,系统能合并查询结果; 6) 对IoTDB历史上的设备及时间序列元信息进行查询和统计,并按模式版本展示. 需要说明的是,本文中的验证部分仅对功能的正确性及实现效率进行了测试与分析,并未对设计及实现的先进性进行分析,这是因为截至本文撰写修订期间,其他时间序列数据库尚未发布模式演化相关的功能.而对于InVerDa[7],LESSQL[8]等数据库虽然实现了多模式版本的管理,但其设计本身基于关系型数据库,对于标签型或树型结构模式的时序库并不支持,因此本文并未进行对比实验. 本节测试的硬件环境使用Intel®CoreTMi7-8565U处理器,内存规格为16 GB 2133 MHz,磁盘规格为WDC PC SN720 SDAQNTW-512G-1001.测试在Windows 10 Pro 64系统中开展,使用JDK 8u271开发测试,使用语法解析工具ANTLR 4.9.1,底层数据库为IoTDB 0.11.0,系统所改造的客户端也基于该版本扩展开发. 附录B中表B1和图B1以创建时间序列的过程为例,检查了设备模式定义发生改变时,本系统的模式演化跟踪有关功能运行情况. 修改时间序列元信息与删除时间序列时的模式版本控制功能,其测试步骤、相应的版本控制功能与创建时间序列类似,测试用例一致通过,受篇幅所限不在本文中详细描述相应的测试用例和测试结果. 附录B中表B2和图B2中测试了检出设备模式到指定版本的功能,检查了新模式版本被正确创建和记录,且与指定版本具有一致的模式定义,测试过程也验证了查看模式版本命令能正常运行并返回正确的结果. 附录B中表B3和图B3中以删除历史版本中的时间序列数据点为例,检查了指定版本数据记录能准确地变更,且当前模式版本中的数据不受影响.另外,本系统进行了向历史模式版本新增数据点的功能测试,其测试步骤、预期结果与删除历史模式版本中的数据点相似,测试用例通过,因篇幅所限本文不再赘述. 附录B中表B4和图B4中展示了测试跨模式版本查询数据的结果,测试显示各个模式版本中的数据均被正确地筛选,且正确地被合并展示. 附录B中表B5和图B5以模式演化历史上时间序列的计数为例,测试了本系统在IoTDB上为历史模式扩展的元信息查询功能正常运行.历史设备计数、历史子节点查看等扩展功能与历史时间序列计数测试逻辑类似,本文不再赘述. 4.2.1 模式跟踪系统性能分析 本文提及的系统基于非侵入式理念在IoTDB上扩展实现,因此本节中仅对IoTDB原生系统以外部分的开销进行分析.具体来说,在创建时间序列时,本文系统根据所创建时间序列的新模式版本在物理存储组上创建了一个模式定义一致的新设备,时间、空间上的额外开销均为O(k)倍,其中k为该设备具有的传感器数量.在删除时间序列时,本文系统时间上的额外开销为O(k)倍;空间上,本文系统为了实现历史模式版本查询,实际并未释放存储空间.修改时间序列元信息时,本文系统时间、空间上的额外开销均为O(k)倍. 在真实的工业物联网应用场景中,传感器实时地产生大量的数据点,数据点插入是非常高频的操作,这也可能是整个系统的性能热点.对于向当前模式版本新增或删除数据点的操作,本文还通过哈希表结构维护每一个设备与其当前版本的对应关系,此时本系统中新增或写入数据点的时间开销与IoTDB原生实现的差异可控制在O(1),对内存的额外需求是O(n),其中n是设备的数量. 4.2.2 跨模式版本查询性能分析 本文实现的跨模式查询功能,在查询并不跨越模式版本的情况下,实际与IoTDB原生查询在时间复杂度上的差异为O(1).在跨版本的情况下,本文系统需要对多个版本模式的查询结果进行合并,时间复杂度与IoTDB原生查询的差异为O(v),其中v是查询结果涉及模式的版本数量.为了最大限度保留原始数据的信息,本文系统将旧模式的数据在数据库中直接保存,而并不进行格式转换,对数据存储空间的需求增加为O(v);作为对比,在最大限度保留原始数据精度的前提下,如果将数据转换到不同版本模式上进行保存,数据查询的额外时间消耗可降低到O(1),而对数据存储空间的要求将增加O(mv),m是模式的版本数量.因此,本文的实现方案在时空开销的均衡上是较为合理的. 本文对时序数据库出现的背景和发展过程进行了简要的回顾,对不同类型模式演化跟踪与跨模式查询的方法进行了调研与综述,对时序数据库Apache IoTDB的架构、特点等进行了简要介绍.在此基础上,本文对时间序列及其模式的特点进行了分析,提出了形式化的定义.针对工业物联网和相关时序数据库中使用的“设备”概念定义了时间序列组及其模式.在此基础上本文对时序数据模式演化的特点进行了分析,提出了形式化的定义,重点分析了时序数据的时序特点导致其模式演化与跨版本查询中存在的主要积累情况. 为了验证模式管理方法的可行性,本文基于IoTDB设计并实现了一套基于时间序列组的模式演化跟踪、模式版本控制与跨模式查询方案,分别对模式演化跟踪方案、跨模式查询方案进行了详细的描述,对实现的方案进行了完善的功能测试,并对性能进行了评估.测试与评估表明,本文实现的系统能够有效地拓展IoTDB的功能,为用户提供了时序数据模式演化跟踪与跨模式查询的支持. 对于时序数据上的模式演化问题,未来的工作可在5个方面展开: 1) 完善时序数据上对模式演化形式化表述,在本文对时间序列、时间序列组形式化描述的基础上,扩展到对海量类似模式的时间序列组间的关系进行描述. 2) 增强模式演化跟踪功能,应对在工业物联网中工业设备经常发生更换、升级的情况.这些情况下,理论上可以根据数据与模式的关系,推断设备是否发送损坏或替换. 3) 提升跨模式版本查询效率.当前系统的实现中,始终需要将查询拆解为多个子查询执行并合并,如设备及模式版本过多,将极大影响系统效率. 4) 支持更多时间序列数据库命令语句,目前系统中主要对时间序列模式变更及查询修改命令进行了扩展,但在权限管理、数据存活时间等方面仍有结合扩展的空间. 5) 在更多时间序列数据库中适配模式演化功能.本系统设计时充分考虑了与底层数据库的解耦问题,可以在不同时序数据库中扩展适配模式演化功能,不断验证与完善相关形式化表述与方案设计. 作者贡献声明:赵鑫负责论文的撰写及研究框架设计;万英格负责系统实验及测试;刘英博负责论文的研究方向理论及论文撰写指导.2 时序数据模式演化的定义与特征
2.1 时间序列模式演化的定义
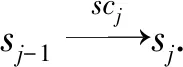
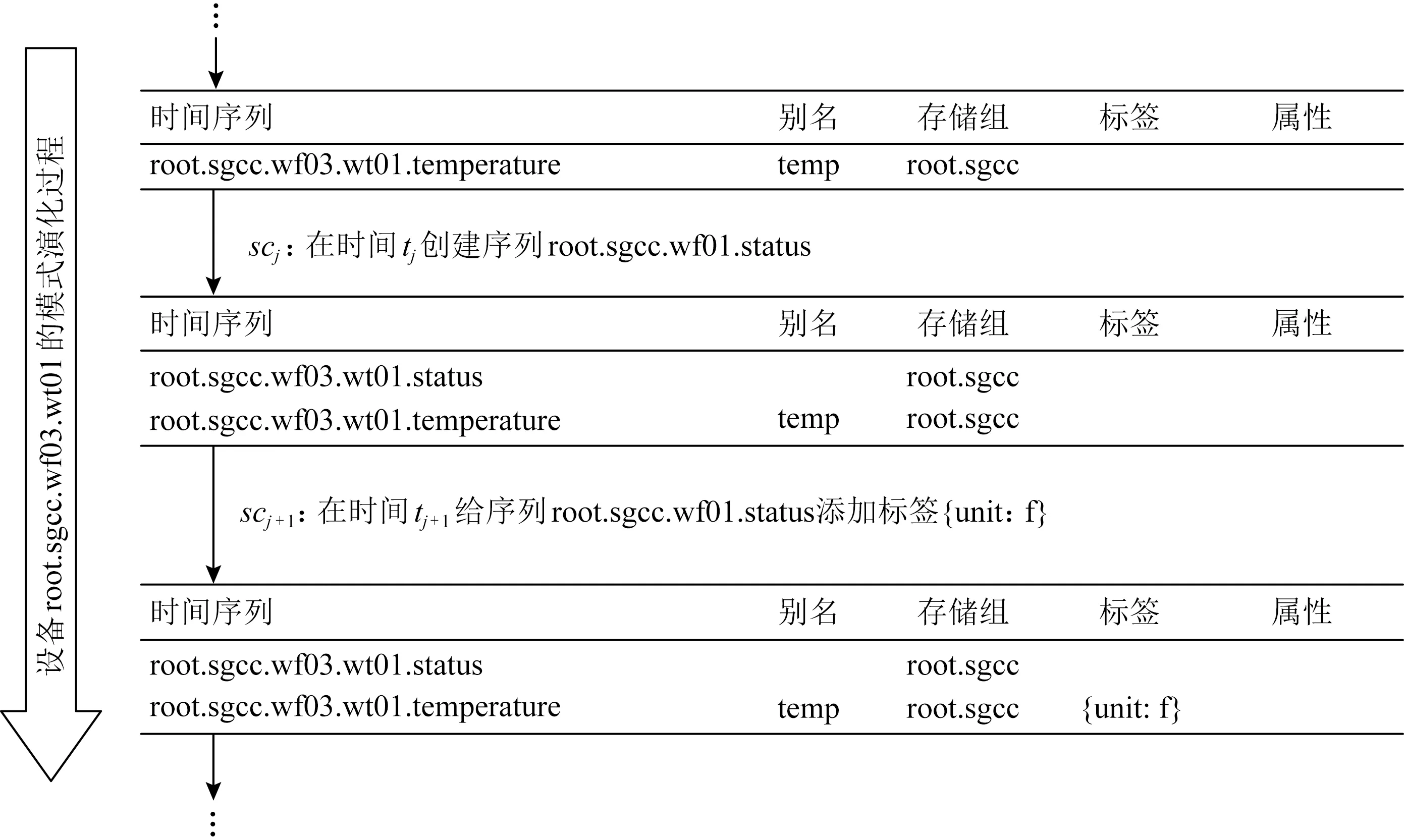
2.2 时序数据模式演化的特征与问题
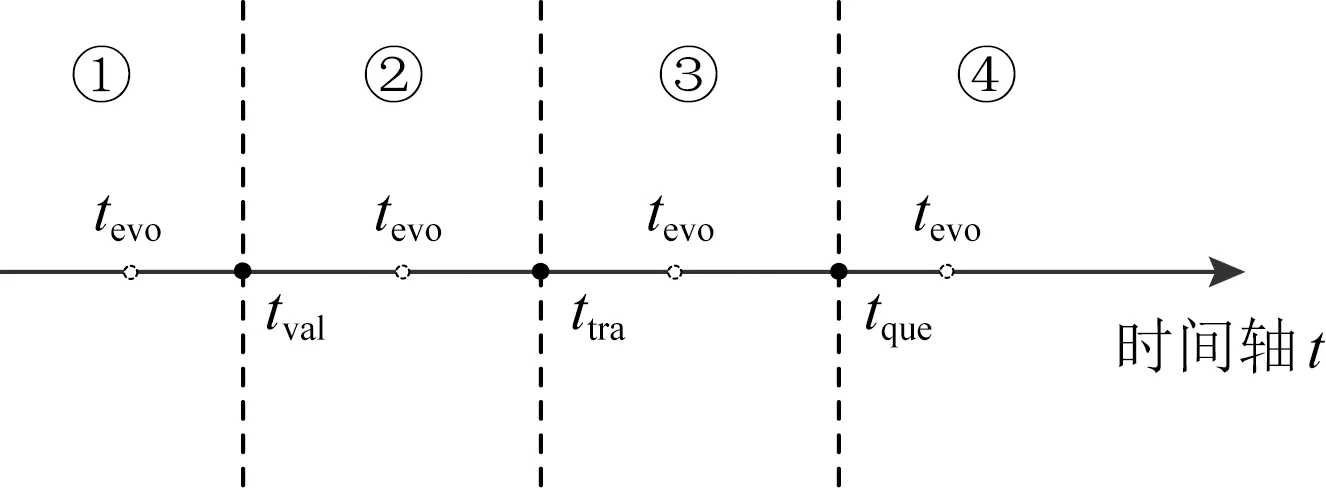
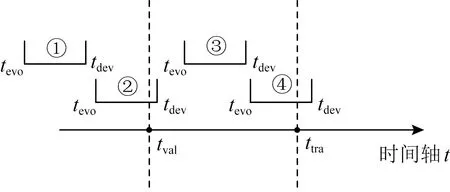
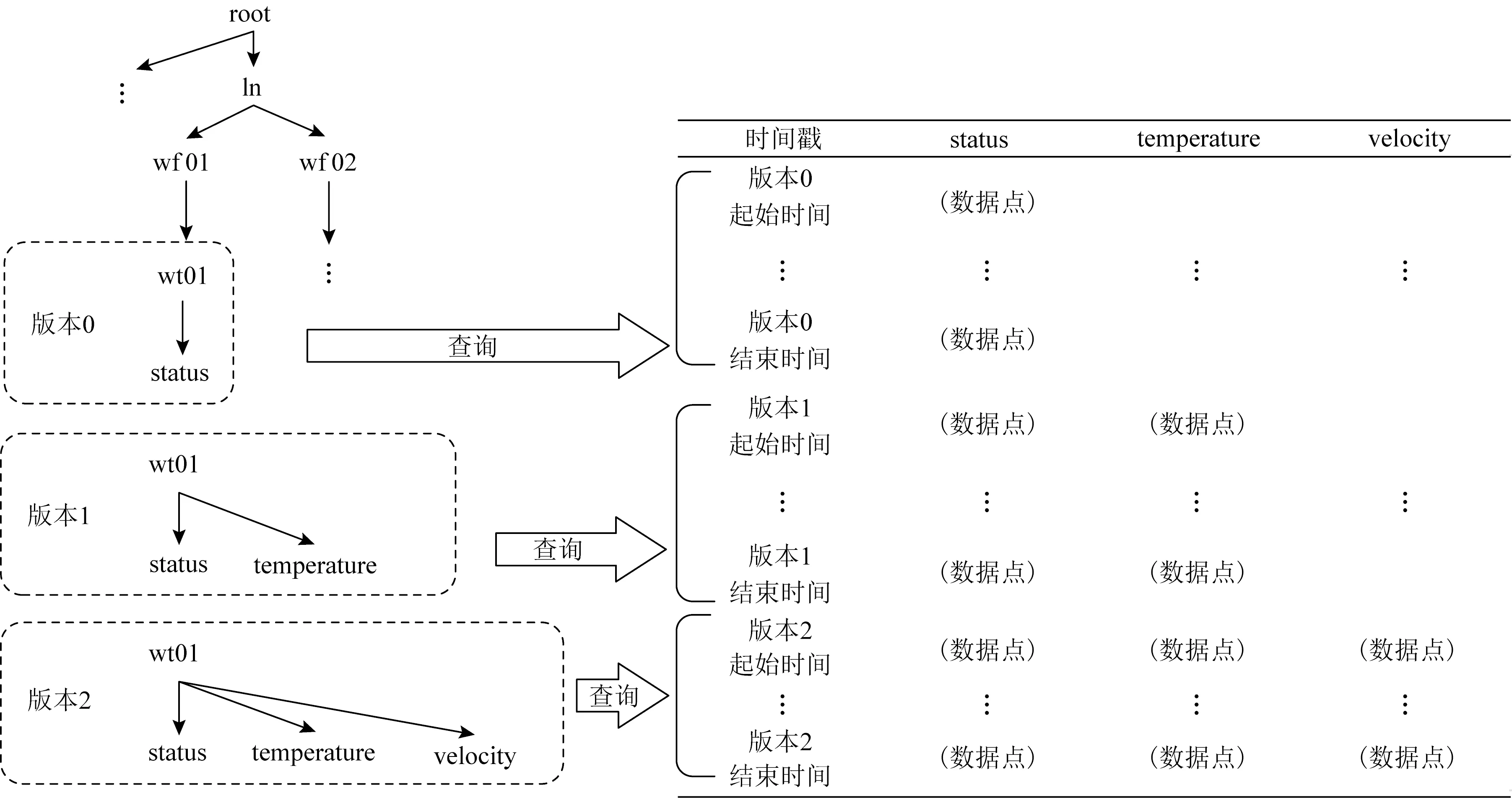

3 模式演化系统设计与实现
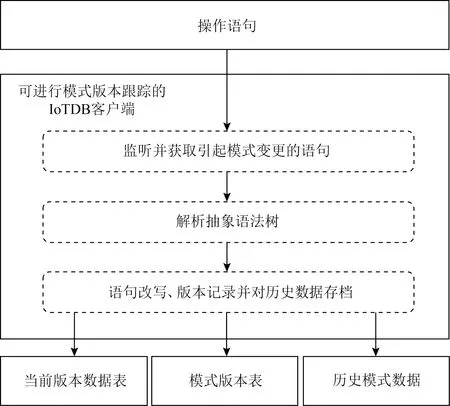
3.1 模式跟踪系统设计与架构
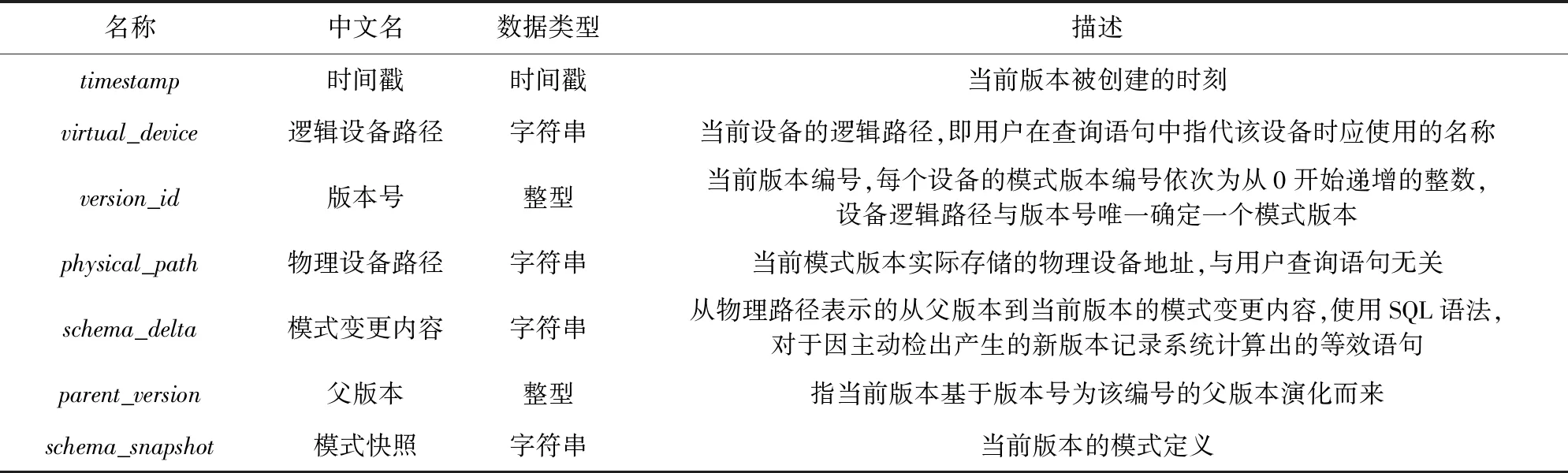
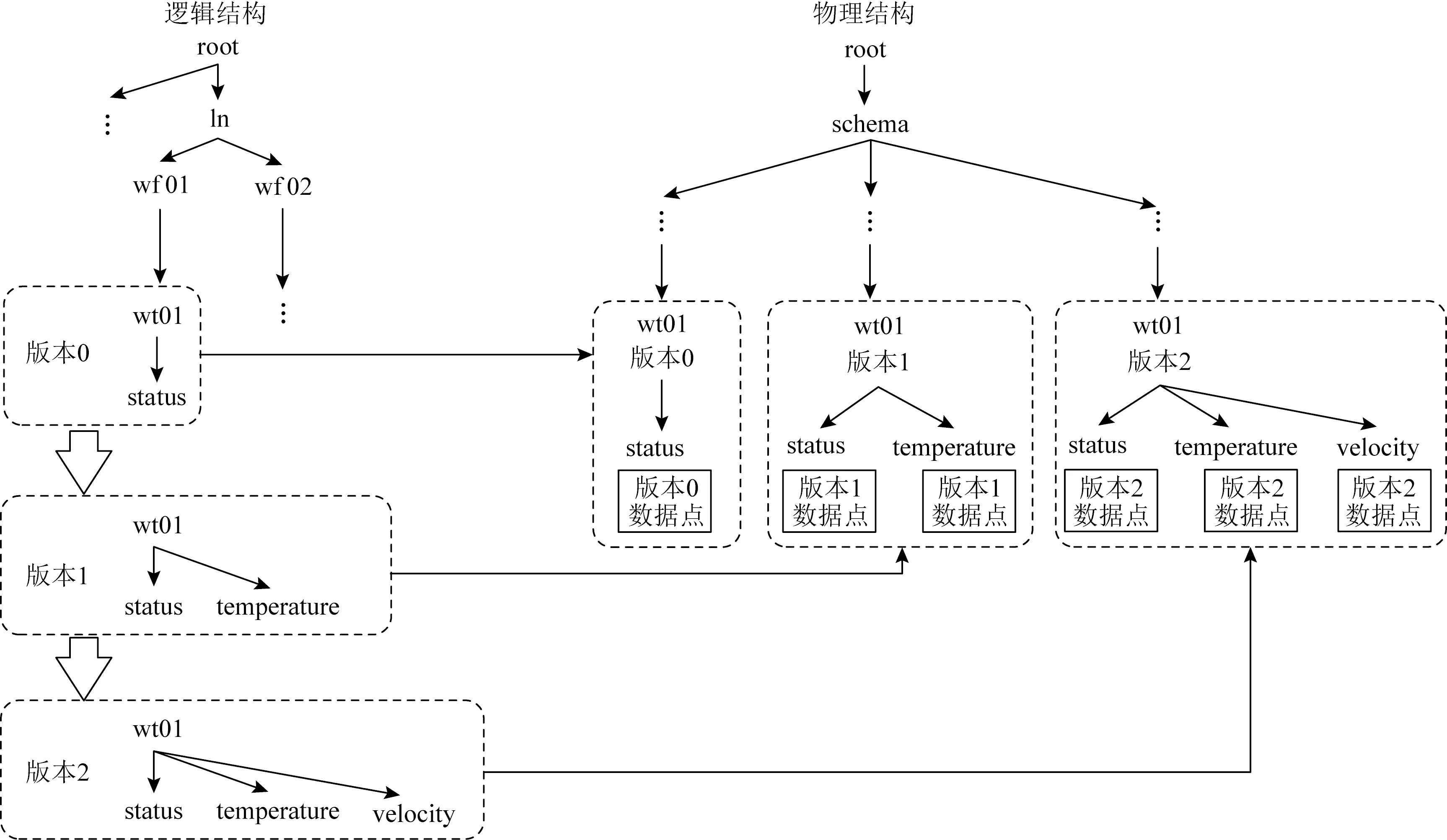
3.2 模式跟踪系统实现

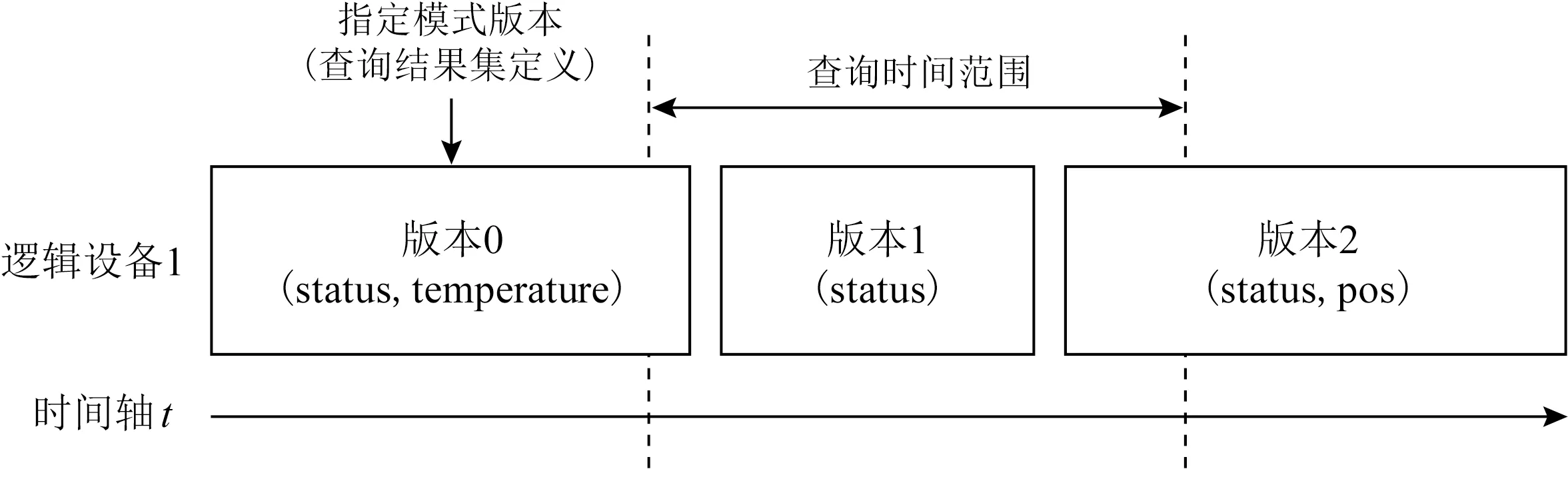
3.3 跨模式版本查询设计与架构
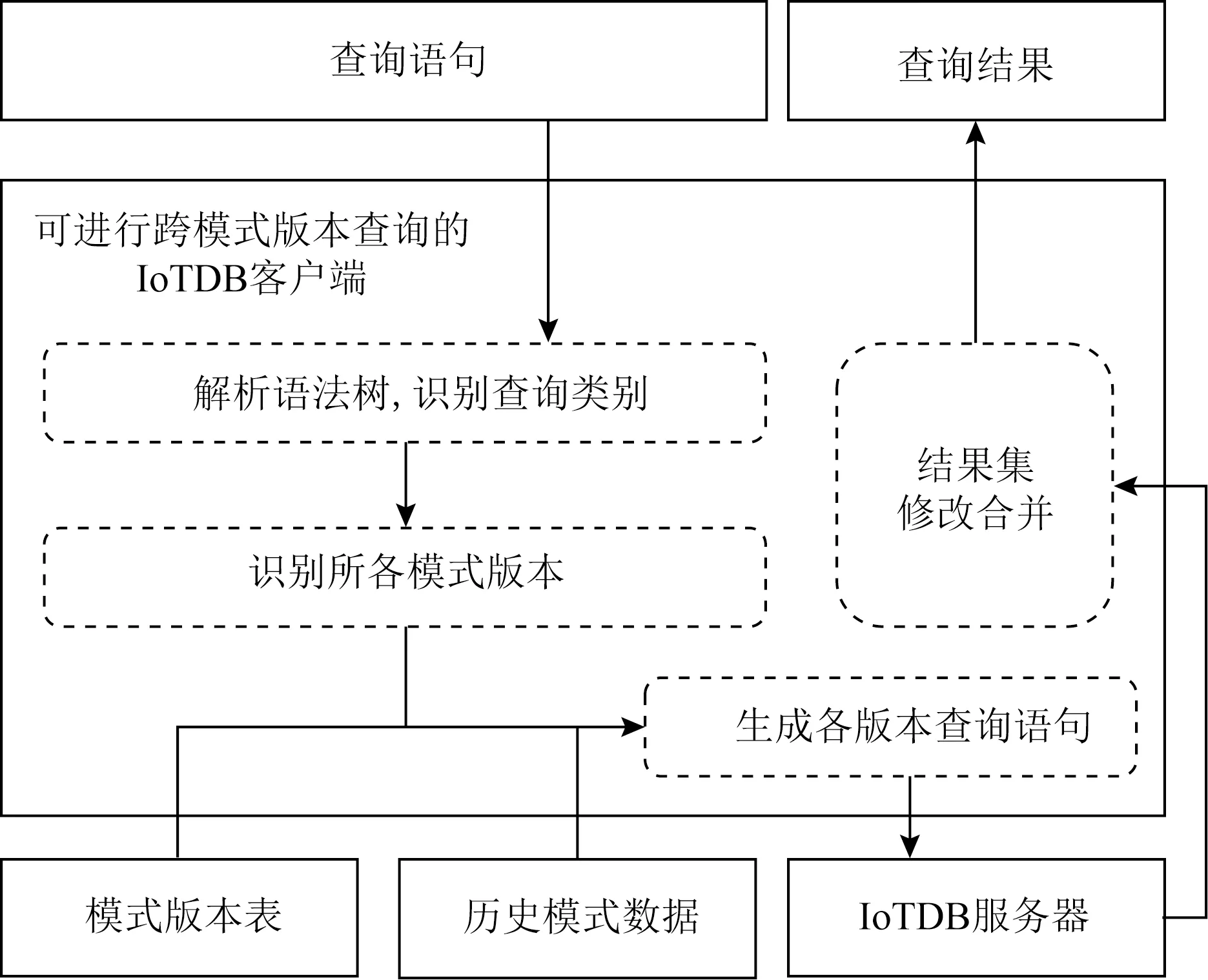
3.4 跨模式版本查询系统实现
4 系统验证与分析
4.1 测试用例
4.2 性能分析
5 总结与展望
