多波长激光诱导荧光麦卢卡蜂蜜掺杂分类识别
2022-09-05陈思颖贾亦文蒋玉蓉杨文慧罗宇鹏李中石张寅超
陈思颖, 贾亦文, 蒋玉蓉*, 陈 和, 杨文慧,罗宇鹏, 李中石, 张寅超, 郭 磐
1. 北京理工大学光电学院, 北京 100081 2. 中国人民解放军军事科学院军事医学研究院, 北京 100071
引 言
麦卢卡(Manuka)是新西兰的一种天然红茶树, 蜜蜂采集这种茶树花酿制而成的蜜即为麦卢卡蜂蜜, 麦卢卡蜂蜜是一种医疗级蜂蜜, 具有很强的抗菌作用及较高的药用价值, 近年来在我国的进口蜂蜜中占比越来越大[1-2]。 与普通蜂蜜相比, 麦卢卡蜂蜜售价更高, 且不同等级的麦卢卡蜂蜜间价格差异较大。 在2014年1月国家质检总局发布的进口食品化妆品不合格名单中, 来自法国和新西兰的7个批次共计1 614千克的麦卢卡蜂蜜因被检出掺假而遭到了销毁或退货, 因此, 需要对掺假麦卢卡蜂蜜进行快速准确地分类识别。
激光诱导荧光技术检测速度快、 灵敏度高; 由于蜂蜜本身含有维生素、 氨基酸、 酚类等可以产生荧光的物质, 近年来国内外学者越来越多地开始利用激光诱导荧光技术对蜂蜜的产地、 植物来源以及真伪进行鉴别。 葛雪峰等[3]利用荧光光谱法得到了蜂蜜浓度和荧光峰值强度间的线性关系, 其决定系数为0.97。 Karoui等[4]利用正面荧光光谱法对瑞士产的7种蜂蜜进行了植物来源分类, 其校准样品和验证样品的正确分类率分别为100%和90%, 证明了基于荧光光谱对蜂蜜植物来源进行分类的可行性。 Chen等[5]将KS-GMM算法与激光诱导荧光技术相结合, 对不同种类的纯蜂蜜进行识别, 识别准确率最大为96.52%。 赵杰文等[6]基于三维荧光光谱技术对掺杂大米糖浆的蜂蜜进行无损鉴别研究, 最终LDA模型识别率为94.44%, BP-ANN模型识别率为100%。 与普通蜂蜜相比, 麦卢卡蜂蜜中含有leptosperin、 lepteridine等独特的荧光标志物, 其中leptosperin是鉴定麦卢卡蜂蜜的权威化学标志物; 新西兰麦卢卡蜂蜜协会规定麦卢卡蜂蜜中的leptosperin含量需>100 mg·kg-1[1, 7-8]。 这些独特的荧光标志物的存在使得麦卢卡蜂蜜的荧光光谱与普通蜂蜜或糖浆的荧光光谱有一定差异, 这为利用激光诱导荧光技术对掺假麦卢卡蜂蜜进行分类识别提供了理论基础, 但目前这方面的国内外研究还很少。
本工作基于激光诱导荧光技术使用多个激发波长对三种品牌的新西兰进口麦卢卡蜂蜜进行了掺杂研究, 激发光波长选用266, 355, 405和450 nm, 掺杂物选用烘焙糖浆, 以0%~90%(间隔10%)的比例与麦卢卡蜂蜜进行混合, 对不同激发波长下三种蜂蜜掺杂溶液的荧光光谱分别进行处理分析。 预处理后使用主成分分析(PCA)结合线性判别分析(LDA)对数据降维, 降维后的数据分别使用K最近邻算法(KNN)和支持向量机算法(SVM)进行训练得到分类模型, 最终对测试集数据进行分类识别。 不同激发波长下各样品的分类识别率相差较大, 其中266 nm激发的荧光光谱分类识别正确率最高, 均在98.5%以上, 最高能达100%, 且标准差均小于0.01。 450 nm激发的荧光光谱分类识别正确率最低, 均低于66%, 且标准差均高于0.02。 与激发波长相比, 不同分类算法对分类识别的影响稍小, 但比较而言, KNN算法的分类识别效果要优于SVM算法。
1 实验部分
1.1 样本
选择三种品牌的新西兰进口麦卢卡蜂蜜(编号A, B, C)和国产烘焙糖浆(主要成分为麦芽糖和果葡糖浆)作为样品。 由于蜂蜜和糖浆粘度过大, 实验前先将其分别配置成5 g/100 mL的水溶液, 然后以10%为间隔, 在0%~90%的掺杂范围内将不同比例的糖浆溶液掺进三种蜂蜜溶液, 即每种蜂蜜有十种样品溶液, 共三十种样品溶液。 使用移液枪将其分别移至干燥洁净的4 mL比色皿中准备实验。
1.2 仪器及参数
实验系统如图1所示, 激光器发射266/355/405/450 nm激光至盛有待测样品的比色皿上, 激发出的荧光信号首先经过透镜收集, 高通滤光片滤除弹性散射光, 然后经透镜会聚至光纤(NA=0.22, 芯径600 μm), 最后由光谱仪分光探测后传输至计算机进行显示存储。 其中266 nm激光器(Beamtech Dawa-200)脉冲能量20 mJ, 频率20 Hz, 355 nm激光器(Beamtech Dawa-200)脉冲能量40 mJ, 频率20 Hz, 405 nm激光器(创联科技)和450 nm激光器(新产业LSR450NL-1W)功率均为500 mW, 滤光片为Semrock公司的272/355/405/458 nm长通滤光片, 需随激发光波长的改变进行更换, 光谱仪(BWTEK-Exemplar Plus)光谱探测范围190~1 100 nm, 分辨率设置为1 nm。 每个激发波长下每种样本溶液重复测试60次, 共7 200组数据。

图1 激光诱导荧光实验系统示意图
2 结果与讨论
2.1 数据处理流程及算法介绍
对于荧光光谱, 通常需要先做荧光波段截取、 平滑和归一化等预处理; 然后对光谱数据进行降维, 提取主要特征信息, 降维不仅可以缩减数据的运算量, 还能够去除部分噪声干扰信息; 最后通过分类算法训练降维后的数据得到分类模型, 进行荧光光谱的分类识别。
采用PCA-LDA算法对掺假麦卢卡蜂蜜的荧光光谱做降维处理, 其中PCA是一种常用的降维方法, 通过正交变换得到少数几个主成分, 使其尽可能多地保留原始数据的信息, 而LDA在选择投影直线时使同类样本的投影点尽可能接近, 异类样本的投影点尽可能远离, 即在降维的同时还能进行分类, 但LDA在对“小样本”降维时可能会出现过拟合现象[9], 而如果在使用LDA前先使用PCA进行特征提取, 就可以在一定程度上缓解过拟合问题, 因此选用PCA结合LDA的方法进行光谱数据降维, 先使用PCA将数据降至低维, 然后使用LDA继续降至二维。 基于PCA-LDA的降维结果, 使用KNN和SVM两种分类算法对不同激发波长下的掺假蜂蜜进行分类。 简单来说, KNN算法采用距离度量, 计算待测样本与每一类训练样本集的距离, 距离越小, 则属于该类别的可能性越大。 而SVM算法的目的是寻找一个最优平面, 在尽可能对样本进行准确分类的同时最大化该平面与最近样本点的距离[10]。
图2所示为数据处理流程。 光谱数据首先进行预处理, 对不同激发波长下每种样品溶液的60组数据, 随机选择80%的数据做训练集, 其余20%的数据做测试集, 训练集数据先经过PCA-LDA降维, 然后对降维后的数据分别训练得到KNN和SVM分类模型, 最终使用测试集数据对得到的分类模型进行测试。 随机分组及分类识别重复进行50次后对分类识别率取平均值, 最终分析比较不同激发波长下不同样品的平均分类识别率及对应的标准差。
图2 数据处理流程
2.2 不同激发波长比较
图3为四个激发波长下三种蜂蜜掺杂溶液光谱数据预处理后的平均归一化光谱图, 其中(a), (b)和(c)为266 nm激发的荧光光谱, 截取300~600 nm荧光波段, (d), (e)和(f)为355 nm激发的荧光光谱, 截取360~650 nm荧光波段, (g), (h)和(i)为405 nm激发的荧光光谱, 截取415~750 nm荧光波段, (j), (k)和(l)为450 nm激发的荧光光谱, 截取458~750 nm荧光波段, 且(a), (d), (g)和(j)为编号A麦卢卡蜂蜜掺杂溶液, (b), (e), (h)和(k)为编号B麦卢卡蜂蜜掺杂溶液, (c), (f), (i)和(l)为编号C麦卢卡蜂蜜掺杂溶液。 从图中可以看出, 当激发波长为266 nm时, 不同掺杂比例的荧光光谱有明显区别, 谱峰位置随掺杂比例的升高出现蓝移现象, 且315和520 nm处的小谱峰逐渐凸显, 光谱的这些差异有助于后续进行分类识别。 当激发波长为355和405 nm时, 不同掺杂比例下的荧光光谱谱型接近, 但从局部放大图可以看出, 谱峰位置有一定差异, 其随糖浆掺杂比例的升高出现轻微蓝移现象。 当激发波长为450 nm时, 如图3(j), (k)和(l)所示, 不同掺杂比例下的荧光光谱谱型和谱峰位置均差别不大, 对后续的分类识别造成一定困难。
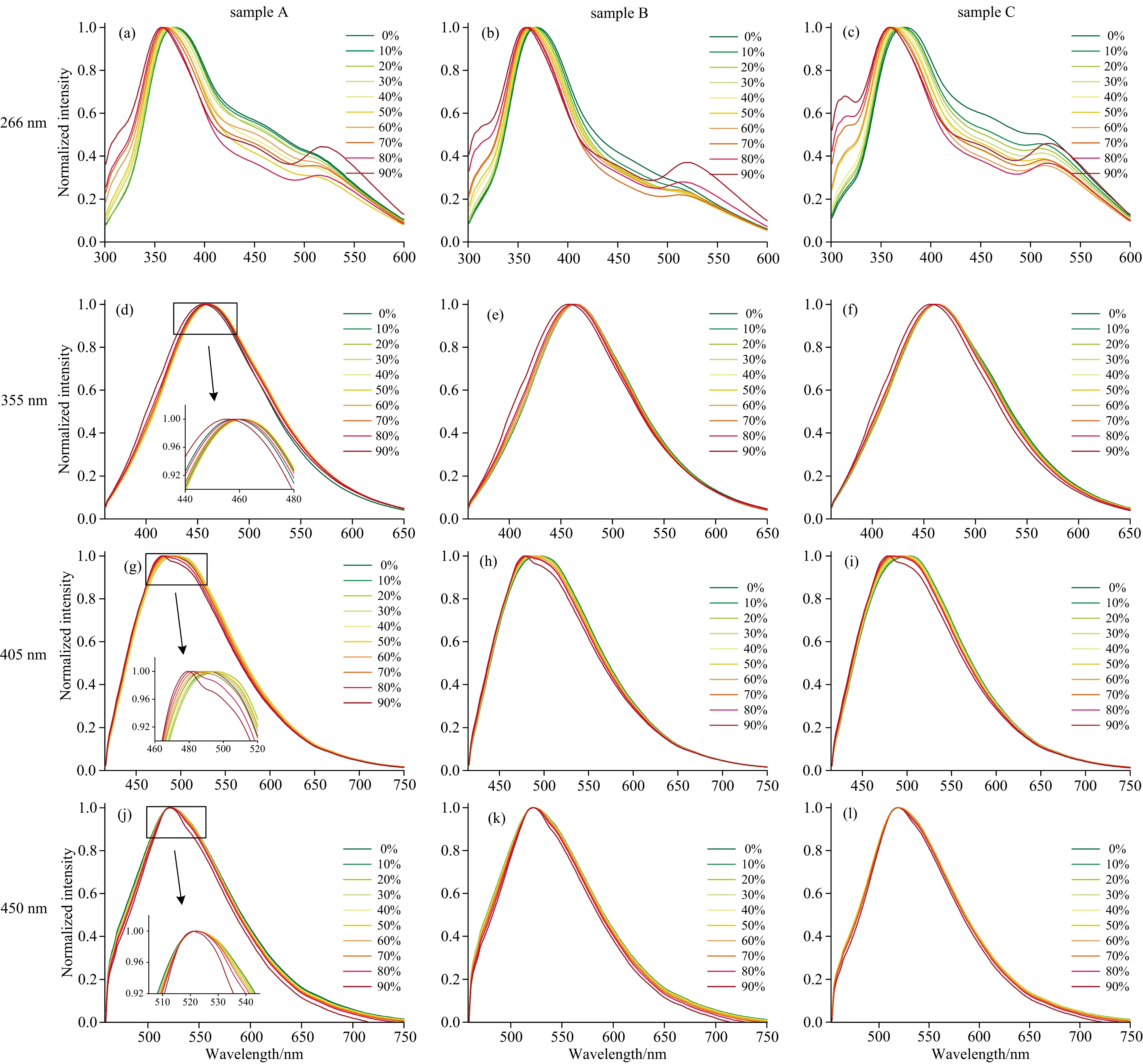
图3 预处理后荧光光谱图
光谱数据预处理后, 随机选择80%的数据作训练集, 20%的数据作测试集, 使用PCA-LDA算法对训练集数据做降维, 得到的二维散点图如图4所示, 其中(a), (b)和(c)为266 nm激发, (d), (e)和(f)为355 nm激发, (g), (h)和(i)为405 nm激发, (j), (k)和(l)为450 nm激发, 且(a), (d), (g)和(j)为编号A麦卢卡蜂蜜掺杂溶液, (b), (e), (h)和(k)为编号B麦卢卡蜂蜜掺杂溶液, (c), (f), (i)和(l)为编号C麦卢卡蜂蜜掺杂溶液。 可以看出, 随着激发光波长的增加, 同类散点逐渐分散, 不同类散点出现重叠, 降维效果变差, 与归一化光谱图的结果吻合。 其中266 nm激发得到的降维图效果最好, 同掺杂比例的散点聚合得较好, 不同掺杂比例的散点间很少出现重叠, 有利于后续分类识别。 与266 nm激发相比, 355和405 nm激发时相同掺杂比例的散点更加分散, 当掺杂比例大于等于60%时, 不同类的散点间距离较大, 而掺杂比例小于60%的不同类散点会有一定程度的重叠, 说明高掺杂比例更容易进行区分。 显然, 450 nm激发得到的降维图效果最差, 同掺杂比例的散点分散, 不同掺杂比例的散点重叠, 大大增加了后续分类识别的难度。
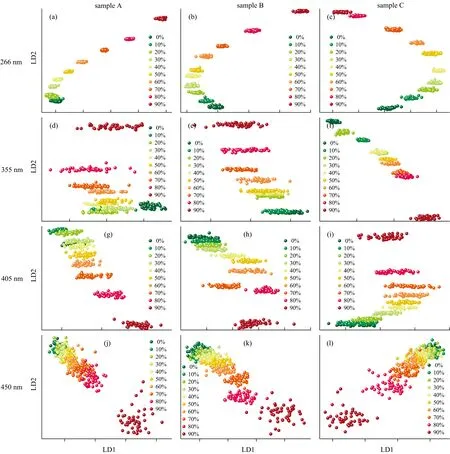
图4 训练集数据降维图
对降维后的训练集数据建立KNN模型, 然后对测试集数据进行分类识别, 重复进行50次随机分组及分类识别后对得到的分类识别率求平均值及标准差。 表1为四个激发波长下三种蜂蜜掺杂溶液的平均分类识别率及对应标准差, 可以看出, 三种蜂蜜掺杂溶液都是266 nm激发时得到的分类识别率最高, 均在98.5%以上, 且标准差最小, 三个标准差均值为0.003 2, 其中B掺杂溶液的分类识别率最高, 达到100%, 标准差为0, 说明50次计算得到的分类识别率每次都为100%, 结果稳定。 355和405 nm激发得到的分类识别率接近, 三种掺杂溶液的分类识别率均在92%以上, 最高达98.88%, 不同样品的标准差均值分别为0.019 8和0.016 4, 且比较而言, 对于B掺杂溶液, 405 nm激发的分类效果更好, 对于C掺杂溶液, 355 nm激发得到的分类识别率更高。 450 nm激发得到的分类识别率最低, 均低于66%, 且标准差最大, 标准差均值为0.040 3。 整体来看, 不同激发波长下三种麦卢卡蜂蜜掺杂溶液的平均分类识别率结果与图2归一化光谱图和图3降维图的情况相符, 即266 nm激发分类效果最好, 355和405 nm激发次之, 450 nm激发分类效果最差。

表1 不同激发波长下三种蜂蜜的分类识别率及标准差
2.3 不同分类算法比较
由于450 nm激发分类效果较差, 后续分类算法的比较仅使用266, 355和405 nm三种激发波长。 其他处理方式不变, 仅改变分类算法, 对训练集数据建立SVM分类模型, 然后对测试集数据进行测试, 随机分组及分类识别重复进行50次, 对分类识别率求均值。 不同样品溶液在两种分类算法下的分类识别率、 识别率差值及对应标准差如表2所示。 从表中可以看出, 相比于SVM算法, KNN算法的分类效果更好, 对于三种激发波长和三种麦卢卡蜂蜜的掺杂溶液样品的任意组合, KNN算法的分类识别率比SVM算法均有提升, 且除405 nm激发A掺杂溶液, 其他情况下KNN算法50次分类识别率的标准差均小于SVM算法。 具体来看, 266 nm激发A掺杂溶液两种算法的分类识别率相差1.57%, 提升最为明显, 405 nm激发A掺杂溶液两种算法的分类效果仅相差0.10%, 最为接近。 整体来看, 266 nm激发下KNN算法的分类识别率比SVM算法的分类识别率均提高1%以上, 效果最好, 而对于C样品, KNN算法的识别率对三种激发波长都能提升大约1%, 效果最为明显。

表2 不同激发波长及分类算法下的分类识别率及标准差
3 结 论
基于激光诱导荧光技术对掺杂糖浆的麦卢卡蜂蜜进行了分类识别研究, 选用266, 355, 405和450 nm四个激发波长, 预处理后使用PCA-LDA算法做数据降维, 然后基于降维后的训练集数据建立KNN和SVM分类模型, 最后对测试集数据进行分类识别。 通过对实验数据处理分析发现, 激发光波长对分类结果影响较大, 450 nm激发的分类识别效果最差, 而266, 355和405 nm激发下不同样品的平均分类识别率均可达到92%以上, 其中266 nm激发配合PCA-LDA降维及KNN分类得到的分类识别率最高, 均在98.5%以上, 且B品牌麦卢卡蜂蜜掺杂溶液的分类识别率能够稳定达到100%, 证明了激光诱导荧光技术用于麦卢卡蜂蜜掺杂分类识别的可行性, 可用于掺假麦卢卡蜂蜜的快速准确鉴别。
