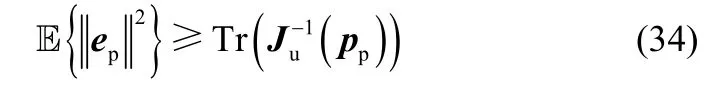基于深度强化学习的可见光定位通信一体化功率分配研究
2022-09-03马帅李兵盛海鸿谷荣妍周辉王洪梅王悦李世银
马帅,李兵,盛海鸿,谷荣妍,周辉,王洪梅,王悦,李世银
(中国矿业大学信息与控制工程学院,江苏 徐州 221000)
0 引言
随着移动互联网业务不断深入,无线设备数量的增长和高速通信需求的增多给传统的通信网络带来了很大压力[1]。据Cisco 预计,2023 年全球互联网用户规模将达到53 亿,移动设备总数将达到131 亿,且值得注意的是,超过50%的语音流量和70%的无线数据流量发生在室内环境,这使射频(RF,radio frequency)通信频谱资源短缺问题日益突出。可见光通信(VLC,visible light communication)和可见光定位(VLP,visible light position)由于具有远高于RF 频段的免授权带宽(430~790 THz)、绿色节能和电磁免疫等优点,近年来受到学术界和工业界的研究关注[2-3]。
VLC 通常利用简单的强度调制和直接检测方式进行信息传输,可同时实现照明和通信功能,被视为B5G 和6G 的关键技术之一[4]。目前已有大量文献研究如何提升VLC 系统的性能。文献[5]研究了多用户VLC 系统的容量区域,并提出了一种基于交替方向乘子法的干扰管理方案。文献[6]研究了无小区VLC系统的资源分配方案,可在满足光功率约束和用户速率要求的条件下提高通信速率。文献[7]利用五色硅基LED,实现了速率为14.6 Gbit/s 的水下VLC 系统。此外,作为VLC 的一个重要应用,VLP 能实现室内高精度定位,可应用于室内导航和物流管理等领域中。通过测量不同的可见光信号特性,现有的VLP 方案主要使用基于接收信号强度指示(RSSI,received signal strength indication)、到达角度、到达时间和到达时间差等技术。在上述方案中,RSS定位技术由于其复杂度较低和部署简单等优势被广泛采用。文献[8]使用RSS 和接收端多个光电二极管(PD,photodiode)之间的相对位置来确定目标的位置,在对称的圆形区域实现了定位精度小于1.5 cm 的定位误差。文献[9]研究了由单个LED和多个倾斜接收器组成的室内高精度VLP 系统,基于倾斜角的先验信息,使用RSS 定位方法进行二维和三维的定位,定位精度小于6 cm。文献[10]提出了使用机器学习方法提升基于RSS 的VLP系统的定位精度的方案,并通过线性插值减少了模型训练所需的样本数。
现有研究大多仅关注VLC 或VLP 系统,而在室内场景下关于可见光定位通信(VLPC,visible light position and communication)一体化系统资源分配的研究具有很强的现实意义,近年来受到了研究者的重视。文献[11]研究了一个面向物联网的VLPC 一体化系统的资源分配问题,在保证定位精度约束的同时,通过联合优化用户接入、带宽分配和功率分配以最大化传输速率。文献[12]基于正交频分复用(OFDM,orthogonal frequency division multiplexing)技术,提出了一种适用于室内可见光通信和定位的稳健传输方案,通过将LED 的发射信号调制到不同的子载波以克服用户间干扰,仿真结果表明该方案能同时满足通信和定位要求。文献[13]提出了基于滤波器组多载波调制技术的VLPC 一体化系统传输方案,相较于OFDM,该方案可有效提高带宽利用率。文献[14]考虑到VLPC 一体化系统中定位精度和用户最低通信速率要求,提出了一种基于无模型强化学习的资源分配方案来最大化多用户和速率。
在实际的VLPC 系统中,由于用户的移动性、不准确的信道状态信息(CSI,channel state information)和对服务质量的要求,导致很难获得动态系统的完整信息,使传统优化方法很难解决该类具有时变特征的优化问题。近年来,深度强化学习(DRL,deep reinforcement learning)被广泛应用于多种复杂无线通信环境下的动态资源分配问题中,其主要思想是在与环境的长期交互过程中,利用深度学习感知环境,利用强化学习改善策略[15-16]。为了解决上述问题,本文旨在研究VLPC 一体化系统的基本原理,并提出一种基于深度确定性策略梯度(DDPG,deep deterministic policy gradient)的动态功率分配方案,主要的研究工作如下。
1)建立了移动用户场景下VLPC 一体化系统模型,通过帧结构的设计,使发射端不需要利用导频序列进行信道状态信息估计,而是根据定位信息获得该结果,这可以显著降低系统开销;推导了定位误差的克拉美罗下界(CRLB,Cramér-Rao lower bound)和可达通信速率的表达式,揭示定位和通信的内在关系。
2)研究了满足CRLB 门限、实际光功率约束和总功率约束条件下的动态功率分配问题,以最大化移动用户的平均速率。由于该问题难以用传统优化方法解决,首先将该问题重构为马尔可夫决策过程,然后提出一种基于DDPG 的动态功率分配算法,以充分发掘历史数据中有价值的信息。
3)仿真结果表明,本文所提算法能取得良好的通信性能,并能缓解定位误差带来的影响。与深度Q 网络(DQN,deep Q network)和等功率分配方案对比,验证了本文算法的有效性。
1 VLPC 一体化系统模型
考虑一个室内下行链路VLPC 一体化系统,如图1 所示,包括一个配备N个LED 的发射基站和一个配备单个PD 的移动用户。定义LED 的索引集为N≜{1,2,…,N},第i个 LED 的位置为vi=[xi,yi,zi]T,∀i∈N,在时隙t处用户的位置为u(t)=[xu(t),yu(t),zu(t)]T,且信道状态在每个时隙内保持不变。
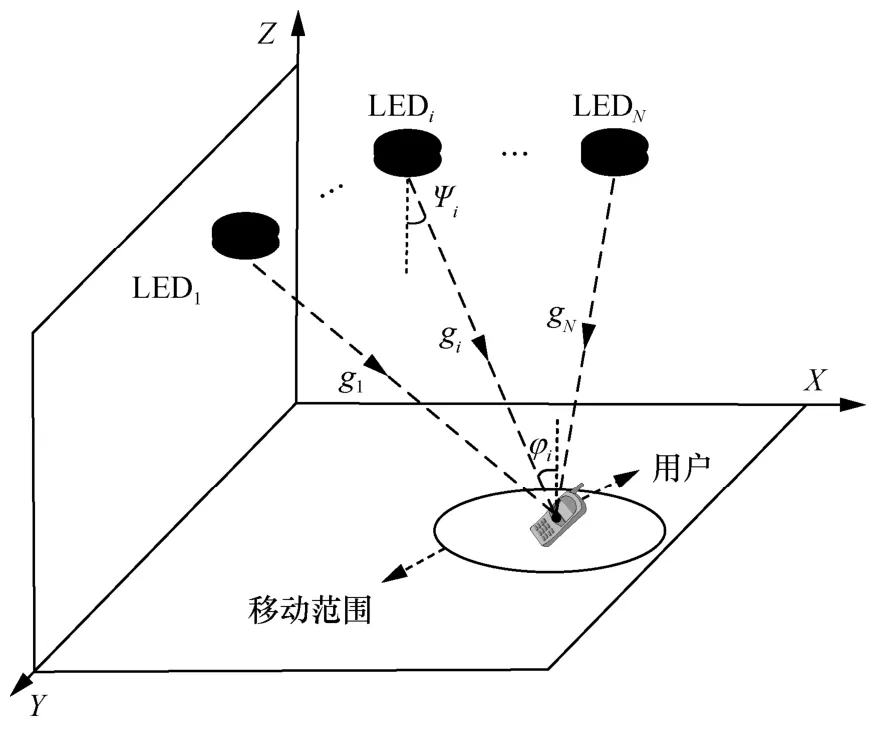
图1 VLPC 一体化系统模型
如图2 所示,在每个时隙上,VLPC 一体化系统发送的信息帧被划分为定位子帧、反馈子帧和通信子帧。具体地,在定位子帧中,基站先向用户发送定位信号,接收端则通过接收到信号的RSS 值来估计用户位置。在反馈子帧中,用户的估计位置被反馈给基站,基站再根据估计位置计算每个LED与用户之间的CSI 估计值。在通信子帧中,基站根据CSI 估计值与用户进行定向通信。考虑到LED 与用户之间的信道增益取决于直射链路[17],定义时隙t处第i个LED 和移动用户之间的信道增益为

图2 VLPC 一体化系统帧结构

1.1 定位子帧
在定位子帧中,基站先发送定位信号给用户,接收端根据获得的RSS 值计算用户的估计位置。具体地,在时隙t处,定义sp,i(t)表示第i个LED 发送的定位光信号,满足峰值约束 −A≤sp,i(t)≤A,均值约束 E{sp,i(t)}=0,均方约束=ε,其中,A>0和ε分别表示光信号的峰值和方差。第i个LED 发送的定位信号xp,i(t)为
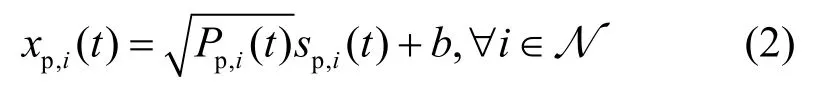
其中,Pp,i(t)表示分配给第i个LED 的定位功率,b表示LED 的直流偏置。为了保证发送信号的非负性,定位功率应满足≤b。

移动用户在时隙t处接收到来自第i个LED 的定位信号yp,i(t)可表示为
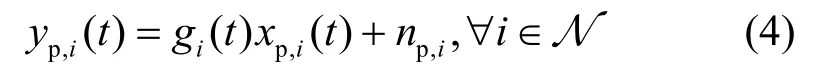
其中,np,i表示服从均值为零和方差为的高斯白噪声。
根据式(4),用户接收到来自第i个LED 的信号的电功率为

联立式(3)和式(5),可得到时隙t处关于用户位置的等式,表示为
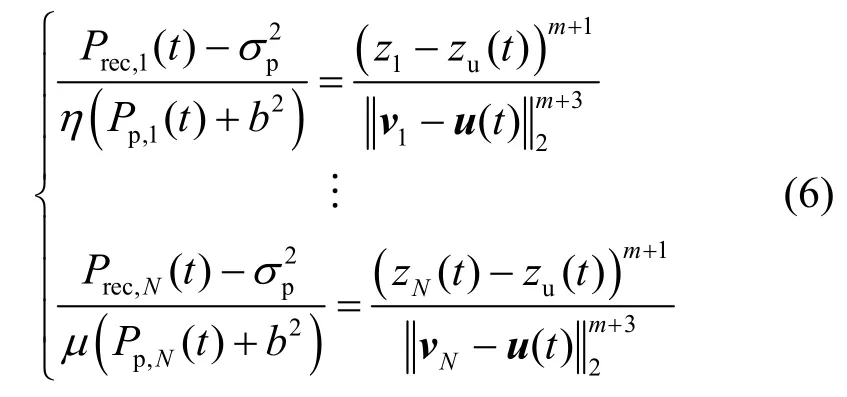
通过最小二乘法求解式(6),可以得到时隙t处的用户估计位置。
从实际角度看,由于噪声和非视距传输等因素的影响,定位误差难以避免,令ep(t)=u(t)−表示定位误差,且在每个时刻上服从高斯分布[18],则定位误差的CRLB 可表示为[19]
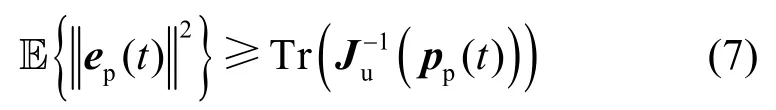
1.2 反馈子帧
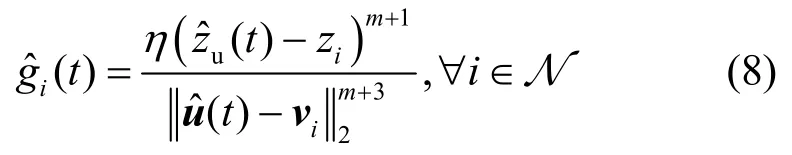
则第i个LED 和用户之间理想的CSI 可表示为gi(t)=+Δgi(t)。
联立式(3)和式(8),CSI 误差 Δgi(t)为
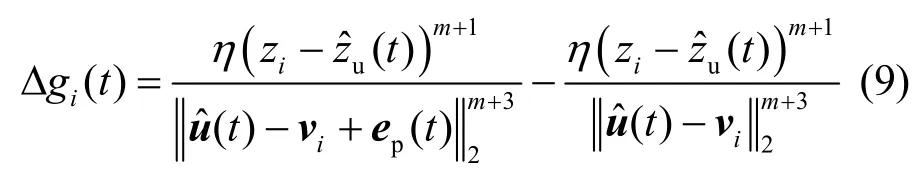
1.3 通信子帧
在通信子帧中,基站根据估计的CSI 值与用户进行定向通信。具体地,在时隙t处,定义sc(t)表示基站发送的通信光信号,满足 −A≤sc(t)≤A、E{sc(t)}=0和=ε,其中,A>0和ε分别表示通信光信号的峰值和方差,定义表示对应的波束成形向量,则发射端通信信号表示为
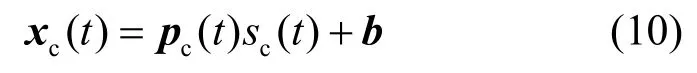
其中,b=[b,…,b]T∈RN×1表示直流偏置向量。
考虑到CSI 误差的存在,接收端信号表达式为

其中,nc表示服从均值为零和方差的高斯白噪声。
利用α-β-γ(ABG)分布[5],移动用户在时隙t处的可达通信速率为
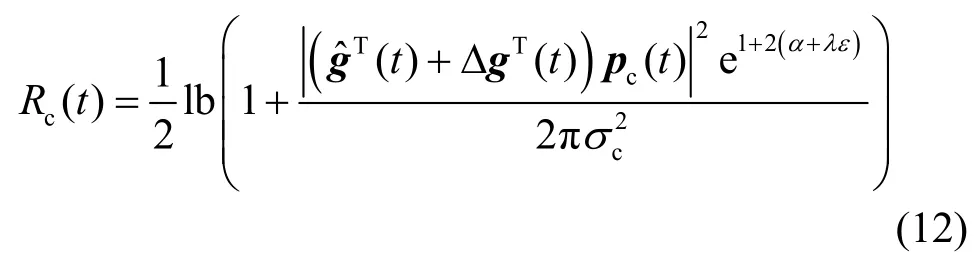
其中,α、β和λ为ABG 参数。
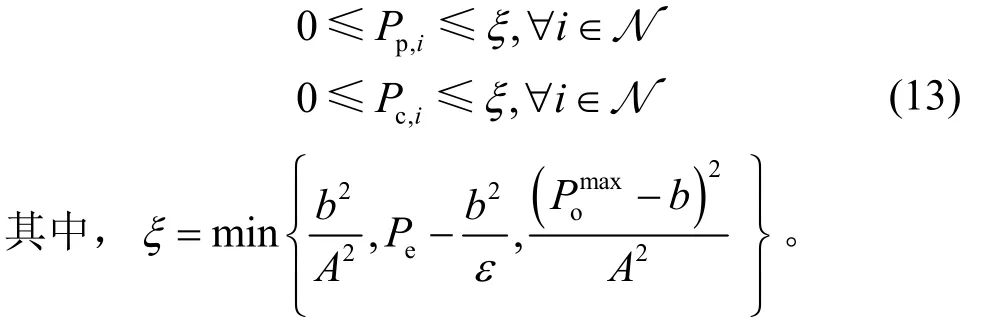
1.4 问题建模
在满足定位精度要求、总发送功率约束和LED实际功率约束条件下,最大化移动用户在整个移动时间T上的平均可达速率。数学上,可达速率最大化可建模为如下问题
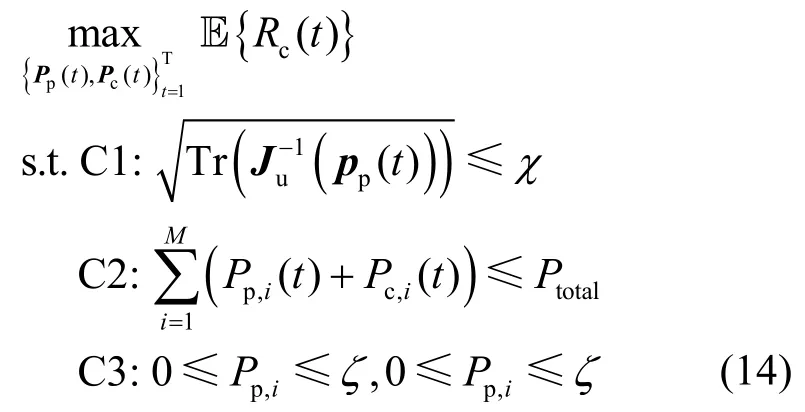
其中,χ表示定位误差门限,Ptotal表示每个时隙上总的发送功率门限。
由于用户具有移动性,问题(14)是在总时隙T上的组合优化问题,传统的优化方法需要在大空间上进行搜索,很难以较低的时间复杂度得到此类问题的高质量解[15]。此外,由于目标函数和约束C1的影响,问题(14)的优化变量相互耦合,很难直接获得功率分配的解析解。因此,本文提出了一种基于DRL 的功率分配算法,以高效地解决该问题。
2 算法设计
2.1 强化学习问题建模
作为机器学习的一个重要分支,强化学习旨在通过不断地“试错”与环境交互,进而学习到最佳的策略,以最大化系统的长期奖励或者实现特定的目标。强化学习方法的训练过程可被建模为形如(S,A,P,R)的马尔可夫决策过程[21],其中,S 表示状态空间,包含了系统完整的状态信息;A 表示动作空间,包含了有限个可能采取的动作;P 表示状态转移概率的集合;R 表示系统即时奖励的集合。具体地,在时隙t处,处于状态st∈S 的智能体会根据某一策略执行动作at∈A,然后通过与环境交互获得即时奖励rt∈R,接着会根据概率转移到下一状态st+1∈S。在本节中,状态、动作和奖励的定义如下。
状态。在VLPC 一体化系统中,定位功率的分配决定了定位的准确性和CSI 估计值的准确性。进一步,由于LED 根据CSI 估计值进行定向通信,CSI 估计值的准确性在很大程度上影响系统的功率分配策略。因此,在时隙t处,定义状态st为所有LED 到用户之间的CSI 估计值,其可以通过上一个时隙t处分配的定位功率,利用式(6)计算得

动作。当智能体处于状态st时,会进行定位功率和通信功率的分配,则at定义为

奖励。在每个训练回合中,智能体会根据当前所处的状态st选择一个动作at执行,然后从环境中获得一个奖励值rt作为反馈。由于问题(14)的优化目标是在满足约束的条件下最大化用户的平均可达通信速率,则rt定义为[15]
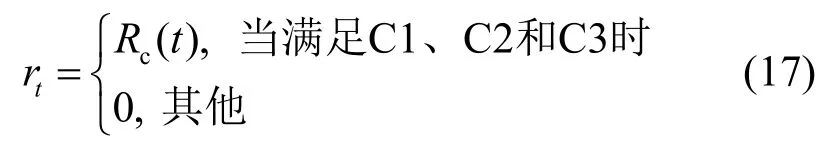
通过不断地与环境交互,智能体可以学习到一个最优策略θ*,以最大化长期折扣奖励,定义为

其中,γ∈[0,1]表示折扣系数,用于智能体权衡当前奖励和未来奖励的重要性。当γ越靠近1 时,表示智能体越重视长期奖励;当γ越靠近0 时,表示智能体仅注重短期奖励。
强化学习的目标是找到一个策略以最大化智能体获得的长期折扣奖励。令Qθ(st,at)表示Q值函数,用于评价智能体在策略θ的指导下,以状态st选择动作at的价值,可根据贝尔曼方程推导如下[22]

2.2 基于DDPG 的功率分配算法
问题(14)可以通过使用基于强化学习的DQN算法来解决,其中关键步骤是将功率在可行域内量化为一些离散值。然而由于量化误差难以避免,这可能导致某些关键的功率分配取值丢失。虽然可以通过增大量化等级减少误差,但同时也会增大DQN的搜索空间,给算法收敛带来困难。受文献[24]启发,本文提出了一种基于深度确定性策略梯度的功率分配算法,其框架如图3 所示。
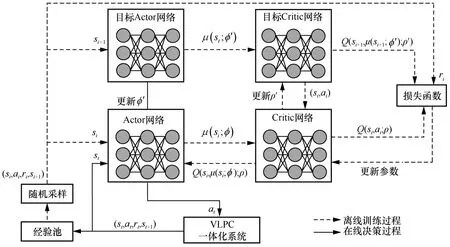
图3 DDPG 算法框架
基于Actor-Critic 模式,DDPG 网络由4 个深度神经网络(DNN,deep neural network)组成,包括一个权值为φ的Actor 网络μ(si;φ),用于输出对应的动作;一个权值为ρ的Critic 网络Q(si,a i;ρ),用于评估所选择动作的Q值;一个权值为φ′的目标Actor 网络μ(st;φ′);一个权值为ρ′的目标Critic 网络Q(si+1,μ(si+1;φ′);ρ′),用于产生训练的Q值。
为了保证问题(14)中光功率约束C3,需要对DDPG 网络的动作输出层进行改写。具体地,令xt=μ(si;φ)表示Actor 网络的输出,使用高斯随机噪声n平衡对新动作的探索和对已知动作的利用。考虑到定位和通信功率的上界ξ,DDPG 网络的实际动作at可表示为

其中,S(xt)=为sigmoid 函数。式(20)确保每一个LED 的发送功率被约束到[0,ζ],以使其满足问题(14)中的约束条件C3,若为其他激活函数则不满足问题(14)中的约束条件C3。
当在线决策处于初始阶段时,基站作为智能体,先给所有LED 分配相等的定位功率,通过式(6)获取初始的用户估计位置。在时隙t处,基于式(8),智能体将估计的CSI 视为状态st,并将其发送到DDPG 单元中,然后基于式(20),得到对应的功率分配动作at,并利用at中分配的通信功率获得用户的即时通信速率,进而基于式(17)获得奖励rt。之后,随着用户移动到下一位置,通过at中分配的定位功率得到用户移动后的估计位置,进而获得状态st+1。
本节采用随机从经验池D 中采样Z个样本(si,ai,ri,si+1)的方法,以打破训练时数据的相关性。具体而言,在离线训练过程中,利用目标Actor 网络μ(st;φ′)和目标Critic网络Q(si+1,μ(si+1;φ′);ρ′)生成用于训练的目标Q值,即
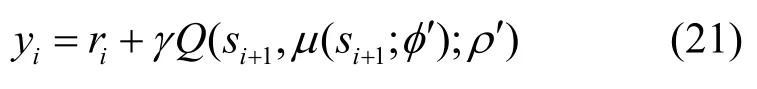
同时,Critic 网络通过最小化均方误差(MSE,mean square error)损失函数来更新其权重ρ,MSE函数曲线光滑、连续、处处可导,便于使用梯度下降算法,是一种常用的损失函数。而且随着误差的减小,梯度也在减小,这有利于收敛,即使使用固定的学习速率,也能较快地收敛到最小值。因此本文选用MSE 作为误差度量函数,即
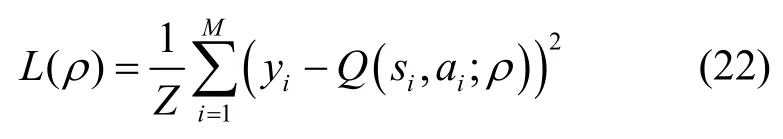
根据确定性策略梯度定理[23],Actor 网络μ(st;φ)在获得更大的累积折扣奖励的方向上更新其权重φ,即
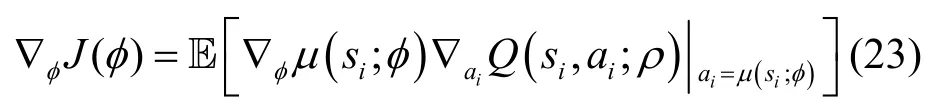
其中,J(φ)=表示在所有状态都遵循策略θ的预期总回报。
使用D 中的Z个随机采样元组,式(23)可以通过近似计算式(24)得到
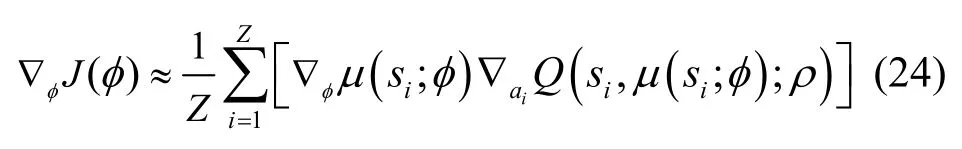
最后,使用软更新的方式更新目标网络的权值
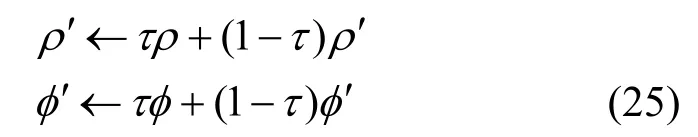
其中,τ表示软更新系数,且满足0≤τ≤1。算法1总结了基于DDPG 的功率分配算法。

3 仿真分析
为了验证本文算法的有效性,本节给出了数值结果用于评估所提出的基于DDPG 功率分配算法的性能,并与DQN 算法和等功率分配算法进行对比。在仿真中,考虑一个部署在5 m×5 m×3 m 房间内的VLCP 一体化系统,其中距离单位为m。将房间建模为三维坐标系(X,Y,Z),房间的一角为坐标原点(0,0,0),VLPC 系统参数如表1 所示,DDPG算法参数如表2 所示。基站包括4 个LED,其坐标分别为(1,1,3),(3,3,3),(1,3,3),(3,1,3)。移动用户起点坐标为(2,2,1.3),移动范围为半径2 m 的圆形区域,移动速度为0.2 m/s,且在每个时隙上从向前、向后、向左与向右这4 种移动方向中随机选择一种。
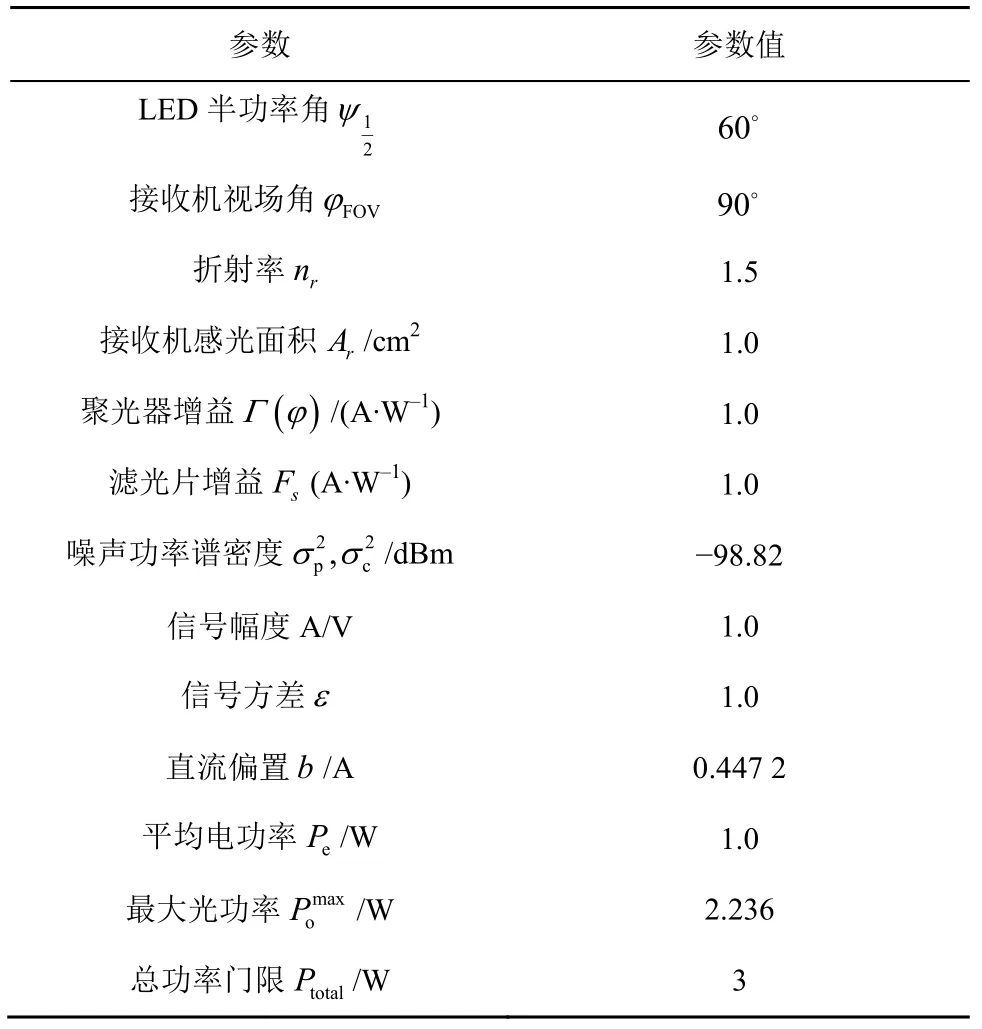
表1 VLPC 系统参数
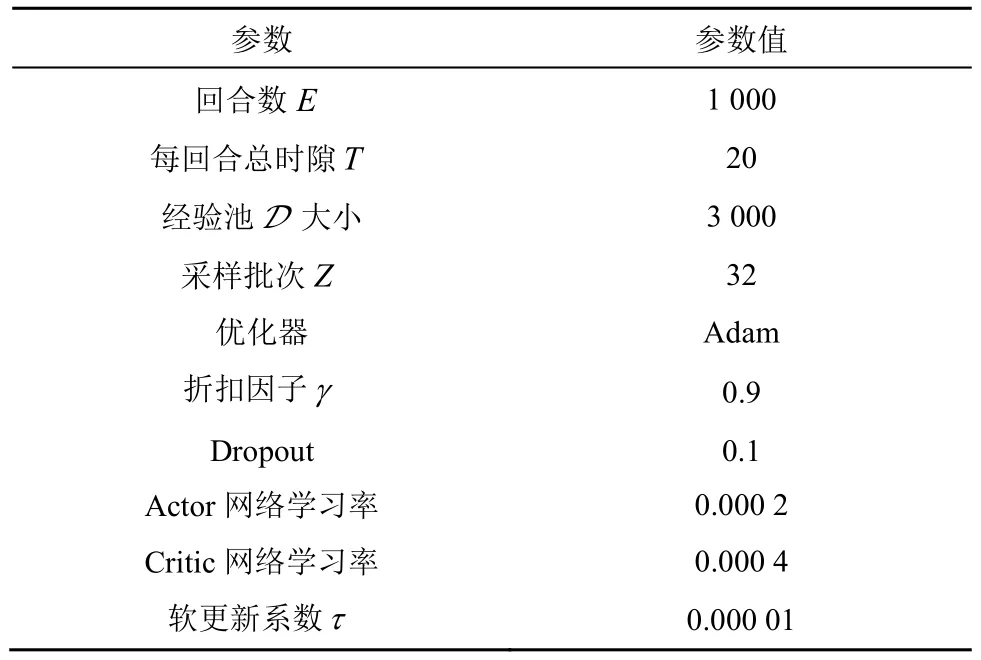
表2 DDPG 算法参数
为了直观地比较DDPG 和DQN 方案在平均可达速率上的差距,图4 给出了2 种方案的平均可达速率随量化等级的变化情况,以DDPG 方案为基准,其中量化等级集合设置为{3,6,10,15,20,30,40,50} 。从图4 可以看到,当量化等级从3 提高到50 时,DQN 方案的平均可达速率先逐渐增加,然后开始减小。这说明通过增大量化等级可以提升DQN 方案的性能,但是过大的动作空间会导致DQN 方案的实际训练困难,并且通过简单地增加动作空间的维度来消除量化误差是不可行的。而DDPG 方案本质上不需要对功率进行量化取值,因而其性能优于DQN 方案。由图4 可知,不同量化等级下的DDPG 方案的平均可达速率均大于DQN 方案。
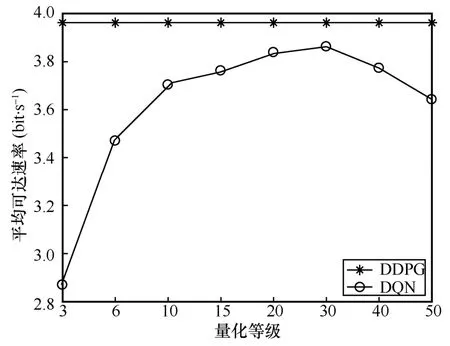
图4 平均可达速率随量化等级的变化情况
图5 给出了3 种方案的平均可达速率随训练回合数的变化曲线以及2 种量化等级下的DQN 变化曲线。从图5 中可以看出,DDPG 和DQN 方案的平均可达速率刚开始都比较小,经过训练后都分别收敛到一个相对稳定的值,这说明这2 种基于DRL的方案均能在与环境的不断交互中学习到新信息,具备良好的收敛性,而等功率分配方案通过在每个时隙上给LED 分配相等的定位和通信功率,并没有自主决策的能力,故难以取得较好的通信速率。由图5 可知,量化等级k=30 的DQN 方案的平均可达速率优于量化等级k=10 的DQN 方案的平均可达速率,并由图4 知当量化等级k>30 时,平均可达速率随之减少。由图5 可知,DQN 方案的收敛训练回合数为200,DDPG 为300。本文采用分布式DQN[15,24]方案,使用多DQN 单元分布式运行结构以减少动作空间维度,加快了收敛速度。此外还可以看出,当所提出的2 种方案收敛后,基于DDPG 的方案在平均可达速率上优于DQN 方案。这是因为DDPG 单元采用Actor-Critic 架构来构造策略函数来直接输出所选择的动作,可以解决DQN 因量化功率取值导致的误差问题,因而能取得更优的性能。
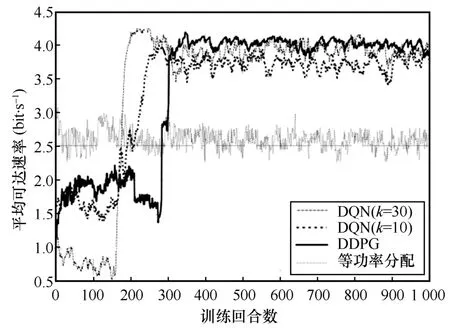
图5 平均可达速率随训练回合数的变化曲线
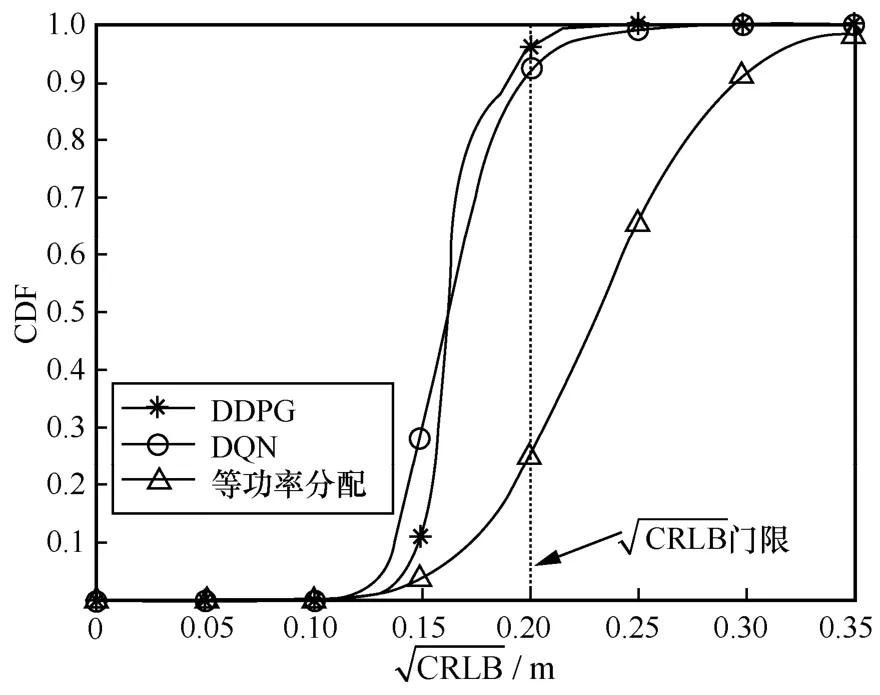
图6 定位误差的 的CDF 曲线
本文通过运行1 000 次回合所需时间来比较方案的复杂度,等功率分配方案为1 160 s,DQN 方案为1 100 s,DDPG 方案为6 428 s,虽然DDPG 方案所需时间较长,但DDPG 方案的平均可达速率最高。
图7 给出了3 种方案的平均可达速率随总功率门限Ptotal的变化曲线。由式(12)可知,平均可达速率随着功率增加而增加。从图7 可以看出,3 种方案的平均可达速率都随着Ptotal的增加而增加,这是因为随着总功率门限的增加,用于定位的功率就越多,CSI 估计就越准确,且LED 获得的通信功率也会随之增加,从而使用户的平均可达速率增加。
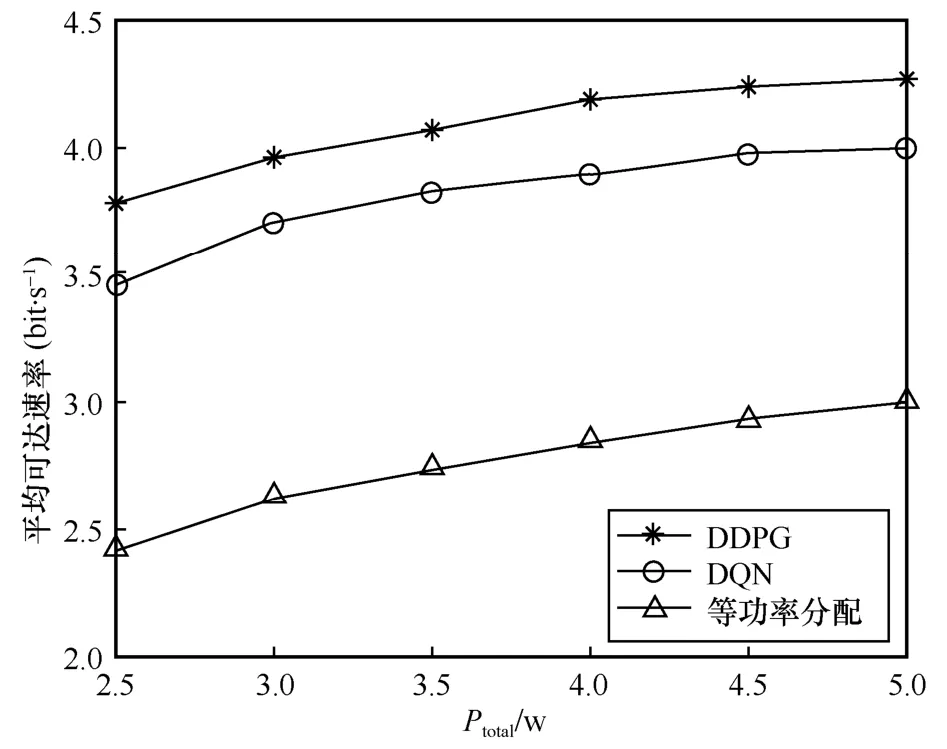
图7 平均可达速率随总功率门限 Ptotal 的变化曲线
4 结束语
本文提出了一种基于深度强化学习的VLPC 一体化系统的功率分配方案。首先,提出了定位通信一体化帧结构设计;然后,利用定位信息实现了信道状态信息的估计,并推导了定位误差的CRLB 和通信速率,阐明了定位精度和通信速率的内在耦合关系;在此基础上,研究了满足CLRB 门限、LED 实际功率约束下的动态功率分配问题,以最大化移动用户的平均通信速率。由于传统优化方法难以解决该动态功率分配问题,本文提出了基于DDPG 的VLPC 动态功率分配方案。仿真结果表明,所提方案能取得良好的通信性能,并能有效缓解定位误差带来的影响。
附录1 CRLB 的推导
简洁起见,本节推导省略时隙t。定义用户的三维位置坐标u=[xu,yu,zu]T表示待估计的用户位置向量,根据式(4),定位信号yp,i的似然函数可表示为

其对数似然函数可表示为
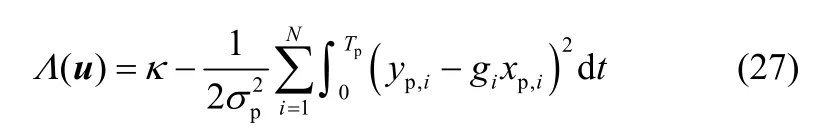
其中,κ是与未知参数无关的常数,Tp是定位信号的持续时间。
FIM 矩阵Ju(pp)是定位功率向量pp=的函数,可表示为

其中,一阶导数计算过程为
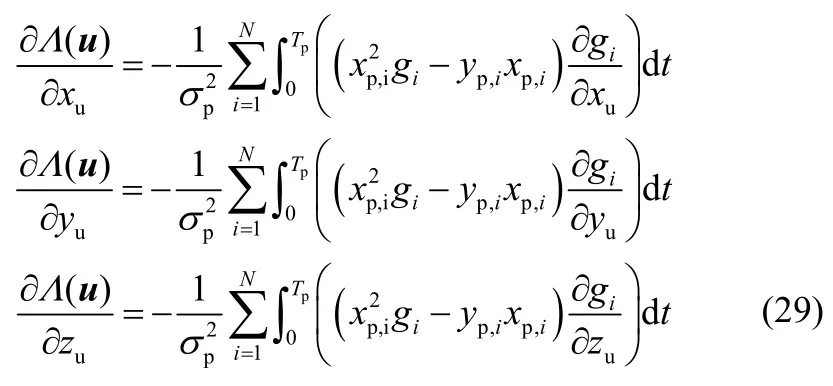
基于式(29),二阶导数计算过程为
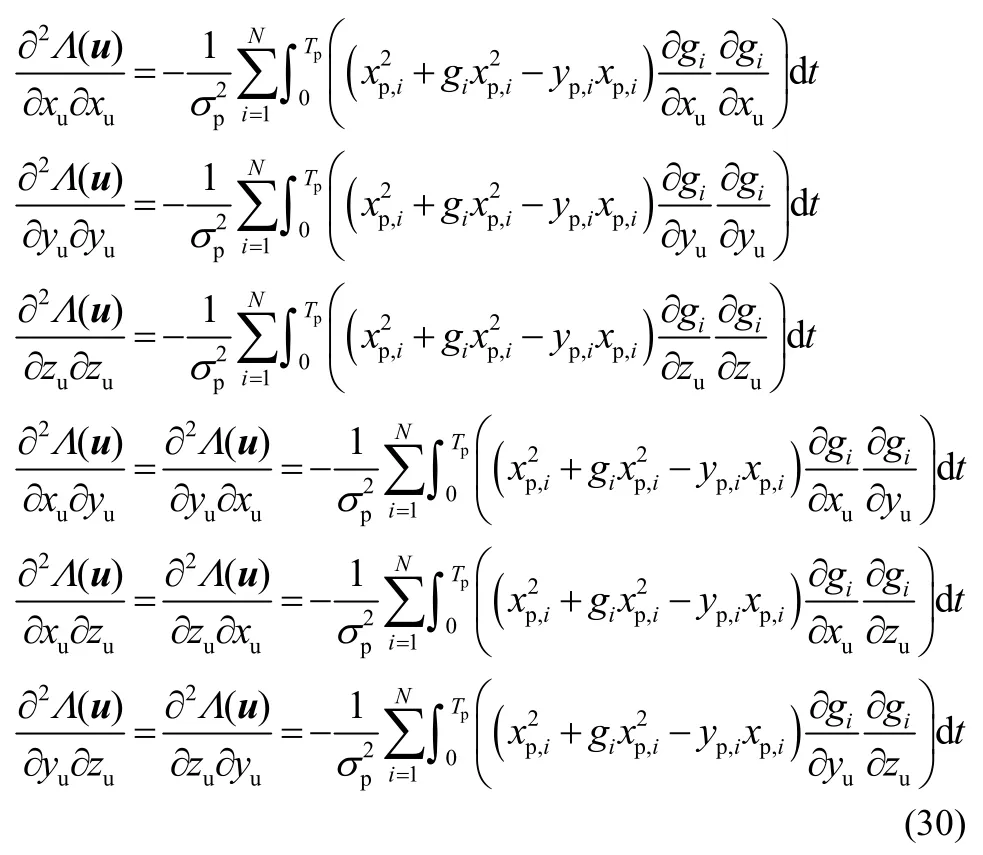
由于定位信号满足 E{sp,i}=0,=ε,式(28)可重新表示为
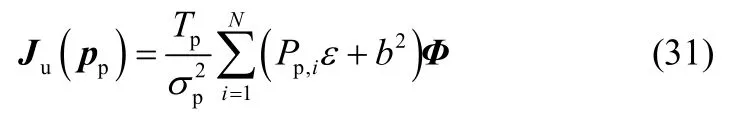
其中,矩阵Φ可表示为
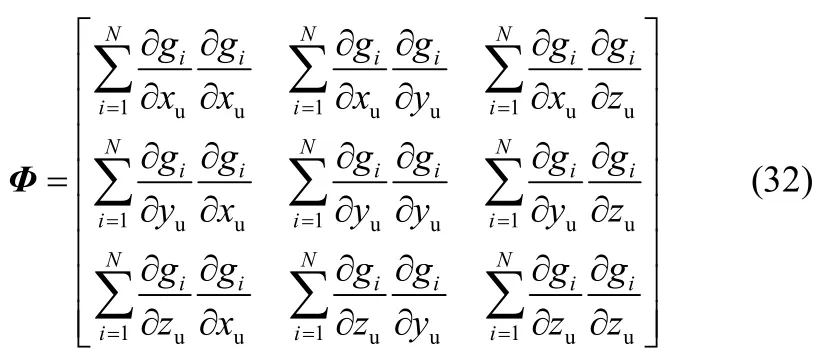
其中,相关微分项可表示为
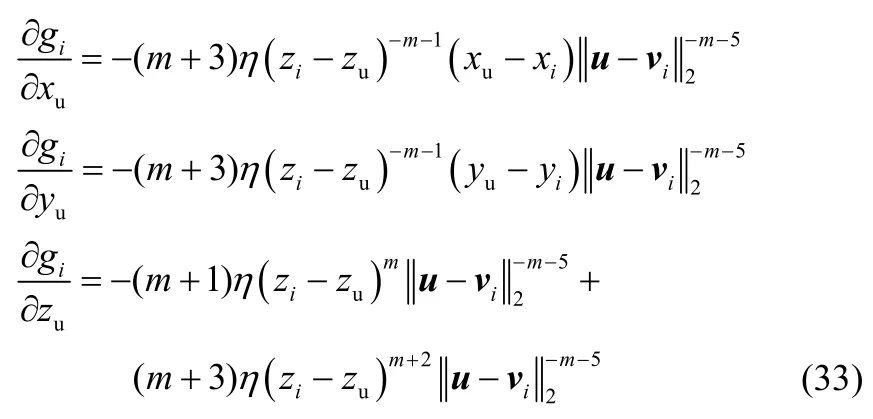
根据CRLB 对任何无偏估计量的均方误差的定义,定位误差ep的CRLB 可表示为