NDN 中边缘计算与缓存的联合优化
2022-09-03张宇程旻
张宇,程旻
(1.北京理工大学信息与电子学院,北京 100081;2.上海机电工程研究所,上海 201109)
0 引言
随着互联网业务的蓬勃发展,网络的业务模式正在由传统的点对点数据传输模式演变为以信息共享为主的转发模式。通信方式中数据物理位置的重要性被逐渐淡化,用户关注的重心转向了数据内容本身。在此趋势下,美国国家科学基金会针对基于TCP/IP 的传统网络架构提出的解决方案——命名数据网络(NDN,named data networking),其采用基于内容名称的路由和转发实现对数据的检索和获取[1],成为当前的研究热点。与此同时,随着计算和存储逐渐成为网络的重要功能,计算、存储与网络基础设施的融合也正成为未来网络发展的重要趋势。边缘计算作为5G 网络的关键技术之一,将计算和存储资源一同下沉到靠近终端用户的边缘节点,以缓解带宽压力、改善用户体验。NDN 的相关机制如基于内容名称进行路由、节点具备一定存储能力等,与边缘计算的设计方向不谋而合,恰好能够为构建网络、计算、存储一体化的未来网络提供重要的技术支撑,因此在NDN 中设计与边缘计算相结合的综合框架并实现对计算和缓存资源的协同管理具有重要的研究意义与价值。
传统的资源分配和缓存策略根据特定的数学模型做出决策[2-7],忽略了节点之间流量波动的相关性和不同区域用户偏好的差异性,使计算和缓存资源不能得以有效利用。此外,虽然全球每天产生约80 EB 的数据量,但用户对其中绝大部分内容的评价是没有记录的,而长尾理论表明,在网络时代,冷门内容的运营收益未必会低于当前关注度高的内容。事实上,当前大多数缓存策略的设计都忽略了长尾内容的潜在收益。
现有的优化方法如凸优化和博弈论等虽然已被广泛应用于改进资源分配方案和缓存策略,但仍存在以下问题:1)一些关键因素如无线信道条件、不同应用的具体要求和内容流行度等被提前设定,而在现实中,这些信息难以直接获得且会随时间变化;2)除Lyapunov 优化[8]外,目前大多数算法只对系统快照进行优化而没有考虑到当前决策对资源管理的长期影响,即系统的动态问题没有得到很好的解决。
机器学习作为一种新兴的数据分析及处理手段,可以从传统方法难以建模和分析的数据中得到隐含的趋势和关联,能够更好地在内容流行度未知且动态变化的网络中赋予计算和缓存更多的自主性和智能性,帮助其学习如何根据已有的经验进行协调优化,有望推动实现未来网络的内生智能。深度强化学习作为机器学习领域中最具潜力的研究方向之一,将深度学习的感知能力和强化学习的决策能力相结合,有助于解决实际场景中的复杂问题。深度Q 网络(DQN,deep Q network)算法作为经典的深度强化学习算法,虽然解决了高维观察空间的问题,但其依赖于找到使价值函数最大的动作[9-10],在连续域的情况下需要在每个步骤进行迭代优化,因此目前只能处理离散和低维的动作空间。此外,DQN 采取随机的动作策略,即每次进入相同状态的时候,输出的动作会服从一个概率分布,这导致智能体的行为具有较大的异变性,参数更新的方向很可能不是策略梯度的最优方向。
针对上述问题,本文提出在NDN 边缘节点部署计算模块,使节点兼具缓存和计算能力,在网络边缘创建分布式的轻型数据处理中心[11];利用深度确定性策略梯度(DDPG,deep deterministic policy gradient)算法对计算和缓存资源的管理进行联合优化,以实现网络、计算和缓存功能动态协调的综合框架。具体创新点如下。
1)在NDN 中设计与边缘计算相结合的综合框架。在NDN 边缘节点部署计算模块和智能体,在将内容和资源向终端用户靠近的同时,实时感知网络状态,在与环境的交互中学习最优的计算和缓存的资源分配以及缓存放置策略。
2)提出基于矩阵分解[12]的局部内容流行度预测算法。矩阵分解算法引入了隐向量的概念,将高维矩阵映射成2 个低维矩阵的乘积,使之具有强大的处理稀疏矩阵的能力;通过补全用户对内容的评分矩阵,将与边缘节点直接连接的所有用户对某个内容的相对评分作为该内容的局部内容流行度。
3)在平均时延的约束下,以系统运营收益最大化为目标,利用DDPG 算法对计算和缓存资源分配以及缓存放置策略进行联合优化。DDPG 算法将动作策略的探索和更新分离,前者采用随机策略,后者采用确定性策略[13];可以在高维的连续动作空间中学习策略,适用于边缘计算和缓存联合优化时的连续性控制问题。
4)在ndnSIM 中构建仿真环境,通过DDPG 算法和经典的DQN 算法在边缘计算和缓存的联合优化问题上的横向对比,证明本文方案在稳定性、收敛速度和性能表现上都有明显优势;与传统缓存放置策略相比,本文方案可以有效地提高缓存命中率、降低系统成本和平均时延,改善用户体验。
1 框架设计
NDN 中基于机器学习实现网络、计算和缓存动态协调的综合框架如图1 所示,在边缘节点部署计算模块,结合NDN 的网内缓存机制,将网络功能、内容和资源向终端用户靠近[14-15];为了优化资源分配,处理具有多样性和时变性的复杂问题,在边缘节点部署智能体,通过状态、行动和奖励与环境互动。智能体首先实时地感知网络状态,例如,与节点直接连接的用户发布的计算任务和请求的内容、节点当前可用的计算资源和缓存容量、局部内容流行度等,继而根据当前状态自主地设计行动,包括计算和缓存的资源分配以及缓存放置策略,最后基于环境反馈的奖励来更新和改进其行动策略,形成感知−动作−学习的循环结构。
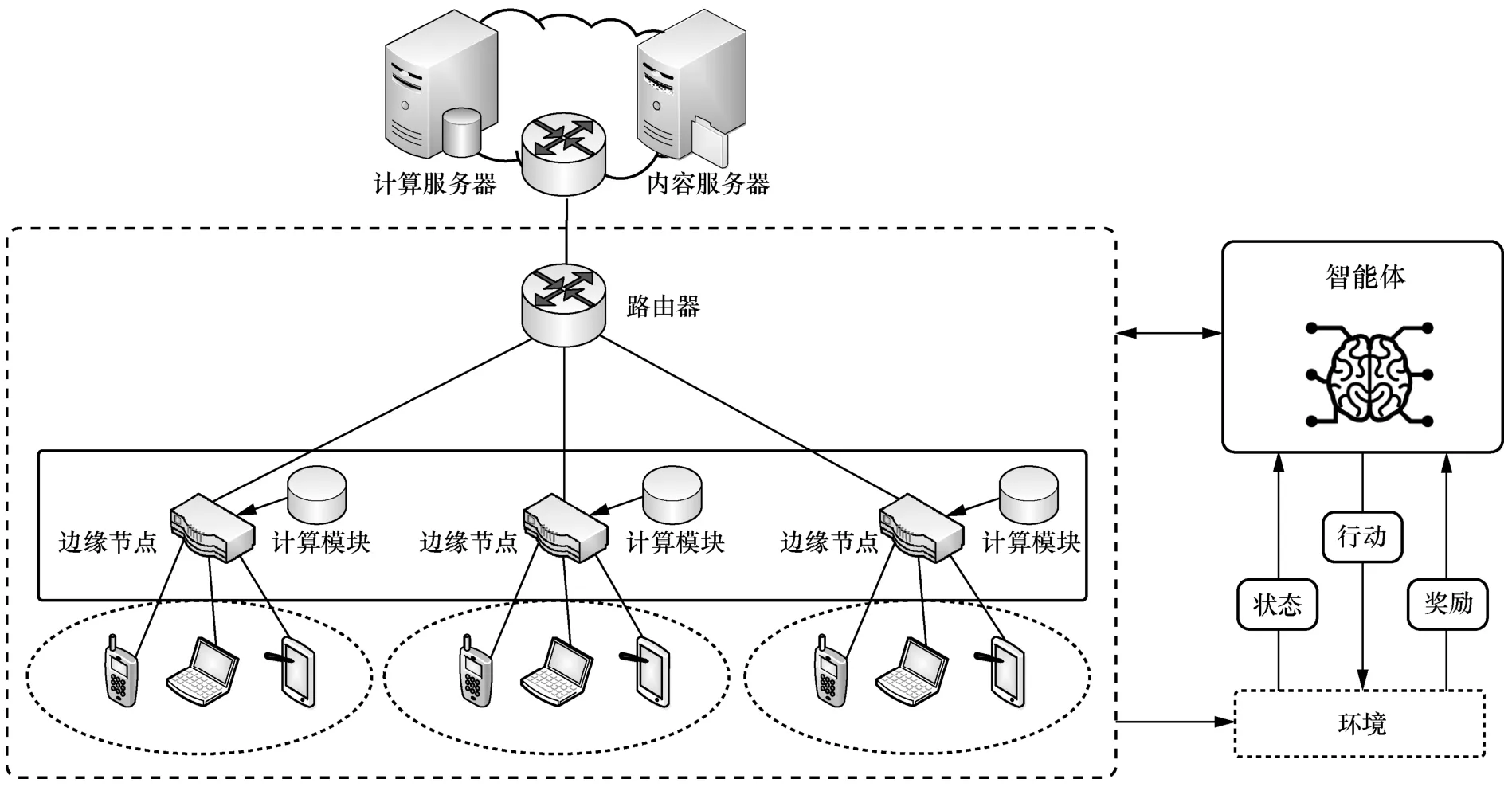
图1 NDN 中基于机器学习实现网络、计算和缓存动态协调的综合框架
在此框架中,边缘节点为其覆盖区域内的用户提供通信、计算和缓存功能,同时考虑到节点计算和缓存能力的变化、不同区域用户偏好的差异性以及内容流行度的时变性,智能体自适应地调整行动策略,为不同区域的用户提供个性化的解决方案。相比边缘节点,远程服务器具有更丰富的计算和缓存资源。当边缘节点不足以支持用户的计算任务或没有缓存用户的请求内容时,计算任务或请求内容可以被卸载到远程服务器(即计算服务器和内容服务器)。因此,智能体在优化计算资源和缓存容量外,还需要学习在边缘节点缓存更受欢迎的内容和处理时延敏感的计算任务,以降低网络时延、改善用户体验。
2 具体方案
2.1 局部内容流行度预测
互联网时代信息量的成倍增长导致了信息过载问题,即不仅用户在海量数据面前束手无策,网络运营商也很难发现用户的兴趣点为其提供个性化的服务。推荐系统通过研究用户的历史行为、兴趣偏好或者不同区域的人口统计学特征,产生用户可能感兴趣的内容列表,精准高效地满足不同用户的信息需求。将每个节点对所有内容的评分抽象为一个m行(m个与该节点直接连接用户)、n列(n个内容)的矩阵,然而由于大多数用户只对网络中极少部分的内容有过评价记录,这个矩阵是很稀疏的。基于矩阵分解的协同过滤算法引入了隐向量的概念,将高维矩阵映射成2 个低维矩阵的乘积,加强了处理稀疏矩阵的能力,同时能挖掘更深层的用户与用户、用户与内容间的关系,较高的预测精度使之成为当前热门的推荐系统主流算法。矩阵分解对原稀疏矩阵进行填充,达到了通过分析已有数据来预测未知数据的目的,从而有助于边缘节点提前缓存当前冷门但未来很可能会流行的内容,挖掘长尾内容的潜在收益。
如图2 所示,矩阵分解算法将m×n维的共现矩阵R分解为m×k维的用户矩阵U和k×n维的内容矩阵I相乘的形式,其中,m为用户的数量,n为内容的数量,k为隐向量维度。k的大小决定了隐向量表达能力的强弱,k的取值越小,隐向量包含的信息就越少,但泛化能力较高;反之,k取值越大,隐向量的表达能力就越强,但泛化能力相对降低。通常k在实验中折中取值,以保证推荐效果和空间开销的平衡。
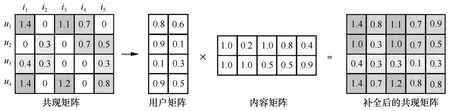
图2 矩阵分解算法
用户u对内容i的预估评分为

其中,pu是用户u在用户矩阵U中对应的行向量,qi是内容i在内容矩阵I中对应的列向量。
采用梯度下降法优化。定义目标函数为

其中,K是共现矩阵中已知评分rui的集合,λ是正则项系数。系统基于已知的评分以最小化均方误差为目标来学习qi和pu,并通过引入正则化项来避免过拟合。
分别对qi和pu求偏导数,得到梯度下降的方向和幅度分别为
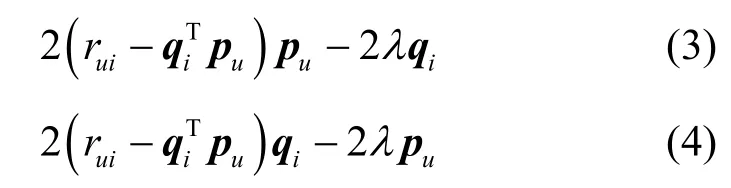
其中,γ是学习率。然后,沿梯度的反方向对qi和pu进行更新,即
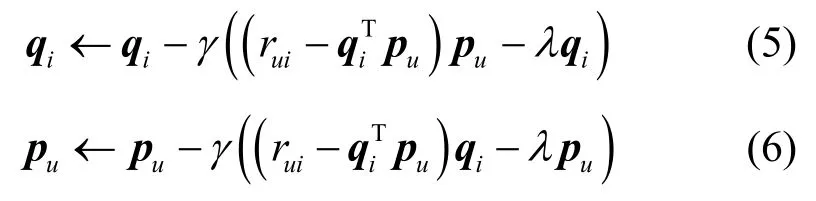
重复式(3)~式(6),直至迭代次数达到设定的上限或者损失函数(目标函数)收敛,由此得到节点对所有内容的评分矩阵。
在补全边缘节点覆盖区域内的用户(与该边缘节点直接连接的所有用户)对所有内容的评分矩阵后,将该区域内所有用户对某个内容的评分之和除以对所有内容的评分之和(即相对评分)作为该区域内该内容的局部流行度。局部流行度即当地用户对该内容的请求概率,记为P={P1,P2,…,PI},其中,I为网络内容总数,Pi∈P为内容i的局部流行度,有

其中,U为与节点直接连接的用户总数。
2.2 边缘计算和缓存的联合优化
设缓存放置策略为C={C1,C2,…,CI},其中,Ci∈C表示内容i是否被选择缓存。Ci=0时表示未缓存该内容,Ci=1时表示已缓存。缓存命中率η表示为

设δ1为因没有缓存而经完整回程链路传输一个内容的成本。假设各内容大小一致,且所有用户都处于请求内容状态,根据缓存放置策略C,有η的概率可以直接从节点获取,所以因缓存放置而无须经回程链路传输请求内容的收益为ηUδ1。
设δ2为节点内部署单位缓存容量的成本。总缓存部署成本随缓存容量V的增大而增大,所以部署缓存容量的支出为Vδ2。
设 Δτ为在最后期限τmax前完成计算任务的平均节省时间。设δ3为运营商执行计算任务期间支付的成本。假设与节点直接连接的用户都处于发布计算任务状态,由于在节点部署了计算模块,部分计算任务可由节点处理而无须卸载到远程计算服务器,因此计算收益为 ΔτUδ3。如果节点在其最后期限前完成任务,则节省的时间为正,相应的计算收益也为正;否则节约的时间和计算收益皆为负,因为对于时延敏感的任务来说,如果没有在最后期限前完成,可能会导致一定的损失。
设δ4为节点内部署单位计算资源的成本。总计算部署成本随着计算资源S的增大而增大。所以部署计算资源的支出为Sδ4。
上述部署缓存容量和计算资源的支出Vδ2和Sδ4为经济成本,而因缓存放置直接从节点获取内容和因部署计算模块提前完成计算任务的收益ηUδ1和 ΔτUδ3并不直接反映在经济盈利上,其不仅包含无须经完整回程链路传输所节约的能量,也包含用户愿意为了更低时延而支付的费用以及运营商因为更低的带宽资源消耗所减少的开销。从网络优化的角度看,支出和收益都是可以通过经济指标来衡量的,因此优化目标为:使利润(运营收益)ρ=ηUδ1−Vδ2+Δτ Uδ3−Sδ4最大。约束条件如下。
3)计算资源:S≤U。S个用户发布的计算任务由边缘节点处理,根据不同用户不同应用对时延的要求选择这S个用户。
综上,在平均时延的约束下,以系统运营收益最大化为目标,资源分配与缓存放置策略的联合优化问题可表示为
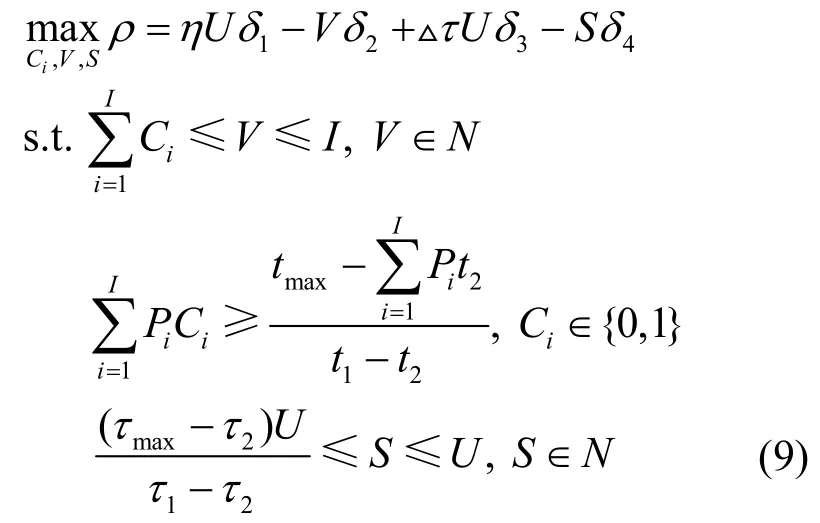
显然,这是一个混合整数规划问题,且是NP-Complete 的,本文利用深度强化学习对其进行求解。边缘节点的计算及缓存能力、用户发布的计算任务和请求的内容以及局部内容流行度等信息被收集并发送给智能体,在获得上述信息后,智能体会设计一个动作来执行资源分配和缓存放置策略,由此进入新的环境状态,并计算系统运营收益作为对该行动的反馈。上述过程对应深度强化学习中的3 个关键要素,即状态、行动和奖励。
1)状态。作为深度强化学习算法的输入,状态包含了智能体做出动作所需要的全部信息。本文的状态由3 个部分组成:State=(ui,si,vi),其中,ui是与节点i直接连接的所有用户的状态,包括其发布的计算任务、请求的内容、任务的截止期限以及该区域的局部内容流行度;si和vi分别是该节点的可用计算资源和缓存容量。
2)行动。作为深度强化学习算法的输出,行动是智能体对环境产生影响的方式。本文的行动由3 个部分组成:Action=(Si,Vi,Ci),其中,Si和Vi分别是智能体分配给节点i的计算资源和缓存容量,Ci是该节点采取的缓存放置策略。
3)奖励。作为智能体学习的指导,从Learning=Representation+Evaluation+Optimization 的角度看,奖励是Evaluation 的重要组成成分。由于深度强化学习的目标是最大化累积奖励,故即时奖励的设置应与上述联合优化问题的目标(尽可能找到使系统运营收益最高的资源分配和缓存放置策略)相关。本文将当前的系统运营收益ρ与现有的最高系统运营收益ρmax的差值作为即时奖励 Reward=ρ−ρmax。当累积奖励收敛时,表明最佳资源分配和缓存放置策略训练完成。
本文基于DDPG 算法对计算和缓存的资源分配以及缓存放置策略进行联合优化,算法流程如图3 所示。DDPG 智能体由3 个部分构成:主网络、目标网络和经验回放池。

图3 DDPG 算法流程
主网络由2 个深度神经网络组成,即一个行动网络Actor-M 和一个评价网络Critic-M。行动网络用于动作的探索,根据随机动作策略尽可能完整地探索动作空间,即通过引入随机噪声,将动作的决策由确定性过程转变为随机过程,再从该随机过程中采样得到要采取的行动。评价网络通过Q值评估行动网络选择的动作,并通过计算策略梯度来更新行动网络。
目标网络包括一个目标行动网络Actor-T 和一个目标评价网络Critic-T。目标网络的输入是经验元组(si,ai,ri,si+1)的下一个状态si+1,输出是用于更新Critic-M 的目标Q值。
经验回放池用于储存经验元组,经验元组为智能体在与环境交互过程中所得到的状态转移序列(si,ai,ri,si+1),包括当前状态、所选动作、奖励和下一个状态。在主网络和目标网络的更新阶段,会从经验回放池中随机采样,以减小数据相关性的影响。
基于DDPG 算法的详细工作过程如下。
1)将当前环境状态st输入主网络的Actor-M,智能体根据随机动作策略采取行动at,即计算资源和缓存容量的分配以及缓存放置策略。

其中,μ是由Actor-M 的卷积神经网络(CNN,convolutional neural network)模拟的确定性动作策略,θμ是Actor-M 的动作策略参数,Νt是动作探索噪声。
2)环境进入下一个状态st+1,并向智能体反馈即时奖励rt。
3)将(st,at,rt,st+1)存入经验回放池。
4)从经验回放池中随机采样小批量的含有N个经验元组(si,ai,ri,si+1)。
5)将si和ai输入主网络的Critic-M,Critic-M利用CNN 模拟贝尔曼方程计算在状态si下选择动作ai的Q值为
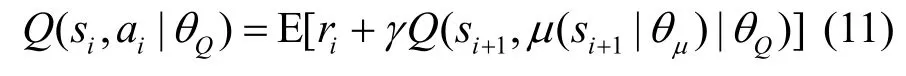
其中,θQ是Critic-M 的Q值参数。
6)将si+1输入目标网络的Actor-T,Actor-T 通过确定性动作策略μ′得到动作ai+1=μ′(si+1|θμ′),其中,θμ′是Actor-T 的动作策略参数。再将si+1和ai+1输入Critic-T,得到在状态si+1下、选择动作ai+1的目标Q值Q′(si+1,μ′(si+1|θμ′)|θQ′),其中,θQ′是Critic-T 的Q值参数。由ri和Q′(si+1,μ′(si+1|θμ′)|θQ′)得到在状态si下选择动作ai的目标Q值为

7)将Q′(si,a i|θQ′)传入Critic-M,通过最小化损失函数Loss 来更新Critic-M 的Q值参数θQ,即

8)将si输入主网络的Actor-M,Actor-M 通过确定性动作策略μ选择动作a=μ(si|θμ)。再将si和a输入Critic-M,通过策略梯度来更新Actor-M的动作策略参数θμ,即

其中,ρμ(s)是在确定性动作策略μ下状态s服从的分布函数;是状态s服从ρμ(s)分布时,智能体根据策略μ选择动作能够产生的Q值的期望,用以衡量策略μ的表现。
基于蒙特卡罗方法,将小批量N的经验元组数据代入式(14),可以作为对策略梯度的无偏估计。
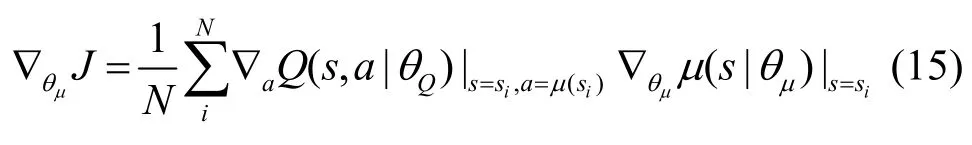
9)通过软更新算法对目标网络中Critic-T 的Q值参数θQ'和Actor-T 的动作策略参数θμ'进行更新。
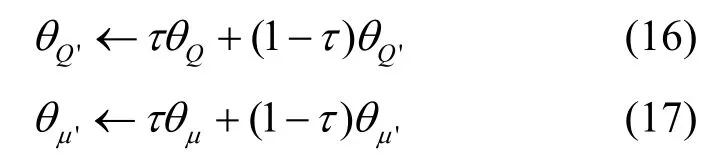
其中,τ=0.001。
如果当前的资源分配和缓存放置策略满足联合优化问题的所有约束条件,并且当前的系统运营收益大于现有的最高系统运营收益,则每幕(episode)的最高系统运营收益更新为当前的系统运营收益,且节点基于当前的资源分配和缓存放置策略更新其状态。如果当前的资源分配和缓存放置策略满足联合优化问题的所有约束条件,但当前的系统运营收益小于或等于现有的最高系统运营收益,则表明智能体没有产生更好的优化方案,每幕的最高运营收益保持不变,且节点仍根据现有的最佳资源分配和缓存放置策略进行状态更新。如果当前的资源分配和缓存放置策略不能满足联合优化问题的任一约束条件,智能体将受到惩罚。
基于DDPG 算法联合优化资源分配和缓存放置策略的伪代码如算法1 所示。


3 仿真分析
3.1 实验环境和参数设置
本文的仿真使用ndnSIM2.8 模拟器。仿真场景如图4 所示,3 个边缘路由器(即边缘节点)覆盖了3 个不同区域内的用户。在豆瓣电影数据集中收集了3 个省份共500 名用户对1 000 部电影的评分(包含未评分,即一些用户只对其中某些电影打过分)来预测局部内容流行度。对应的远程内容服务器提供1 000 种不同的内容,每种内容的大小相同。为了体现内容流行度的地域差异性,各边缘路由器覆盖区域内的用户均来自同一省份,每个用户群共50 人,用户请求兴趣包的频率为100 个/秒,兴趣包的请求概率分布与局部内容流行度一致。缓存替换策略均采用最近最少使用(LRU,least recently used)策略,仿真时长为100 s,从用户到远程服务器的路径时延为60 ms。性能评价指标采用各边缘节点的运营收益、缓存命中率、用户获取数据包的平均时延、平均跳数和远程服务器负载。
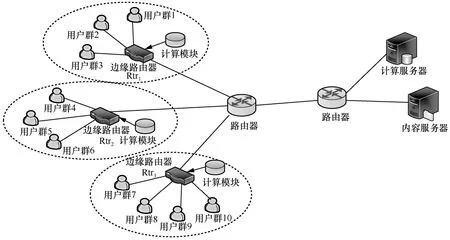
图4 仿真场景
3.2 结果分析
矩阵分解算法中的可调节参数为学习率γ、正则项系数λ和隐向量维度k。学习率决定每次更新的幅度。对于固定的学习率,如果设置偏大,则会导致结果振荡不收敛;反之,则会导致收敛速度过慢。本文采用指数衰减学习率。
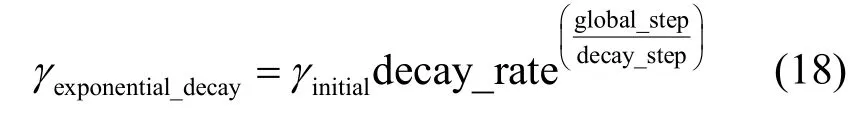
其中,γinitial=0.002为初始学习率,decay_rate=0.9为衰减系数,decay_step=50 用来控制衰减速度。在训练前期,采用较大的学习率可以快速获得一个较优的解,随着迭代的继续,学习率逐渐减小,使模型在训练后期更加稳定。
图5 对比了不同的正则项系数λ和隐向量维度k组合对矩阵分解损失函数的影响,得出当λ=0.005、k=100时损失函数最小,故在后续仿真中均采用此组合。
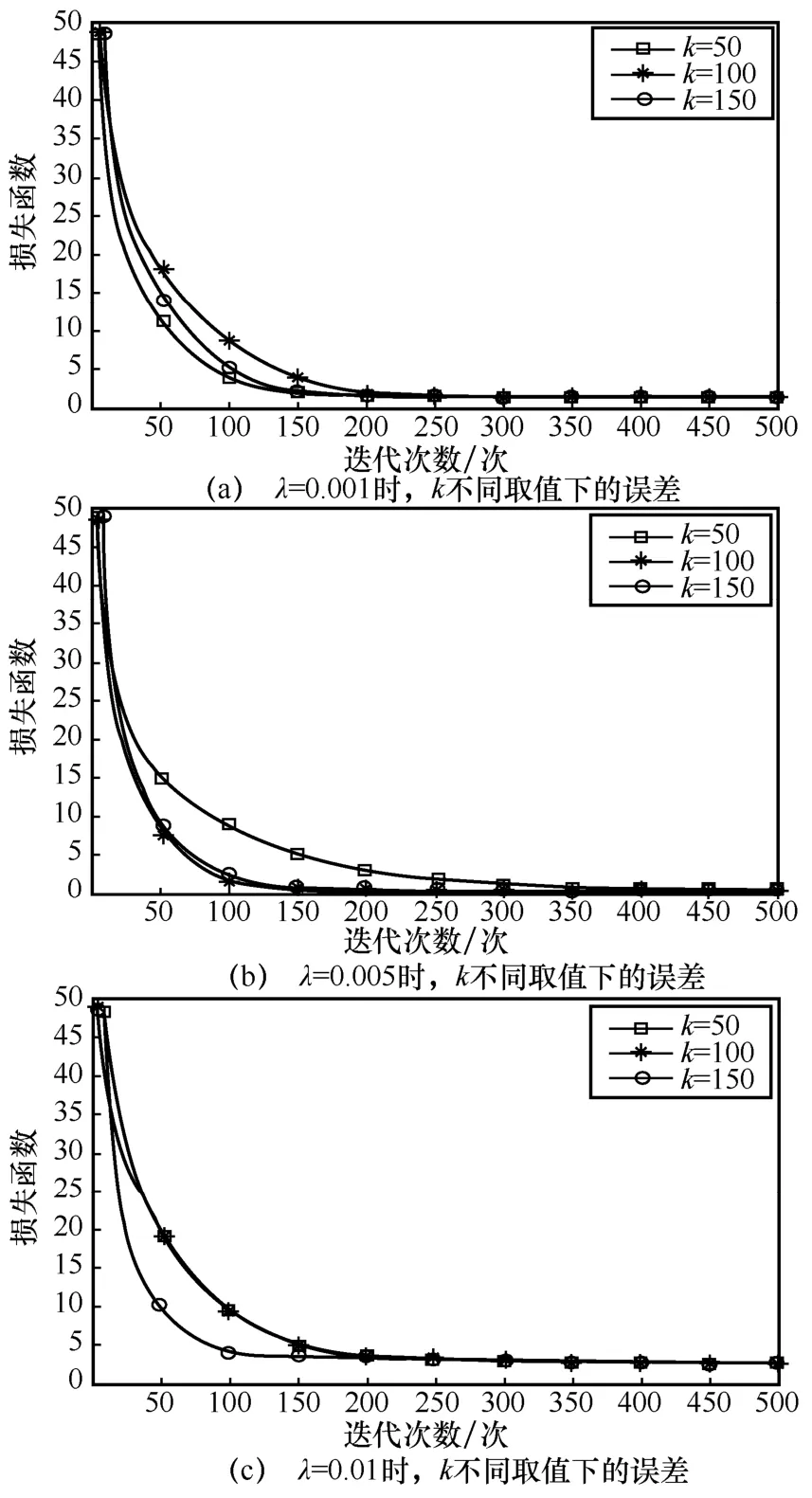
图5 不同参数组合的矩阵分解误差对比
在确定了矩阵分解的参数组合之后,按照2.1 节的算法来预测内容流行度。图6 以全局流行度排名前100 位的内容为参照,展示了全局和局部内容流行度的差异性。其中,数据集内全部500 名用户的评分反映全局内容流行度,而局部内容流行度则由在同一省份随机抽取的50 名用户计算而得。
如图6 所示,全局内容流行度大致符合Zipf 分布,即网络中的少数内容占据了用户的大部分关注度,但在尾部也有持续稳定的小众需求。局部内容流行度则更显著地表现了冷门内容的潜力,出现了很多突出的尾部内容。全局和局部内容流行度的差异性表明本文基于局部内容流行度制定缓存放置策略更加有效,为不同区域用户提供个性化网络服务的同时,还能获得更高的系统运营收益。
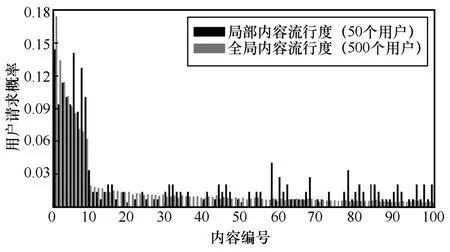
图6 全局和局部内容流行度对比
在对局部内容流行度完成预测后,边缘节点Rtr1、Rtr2和Rtr3以系统运营收益最大化为目标,基于DDPG 算法对计算和缓存的资源分配以及缓存放置策略进行联合优化。图7 显示了各边缘节点每幕运营收益最高时的资源分配情况及最高运营收益。当节点缓存容量V=108,计算资源S=127时,运营收益达到峰值。
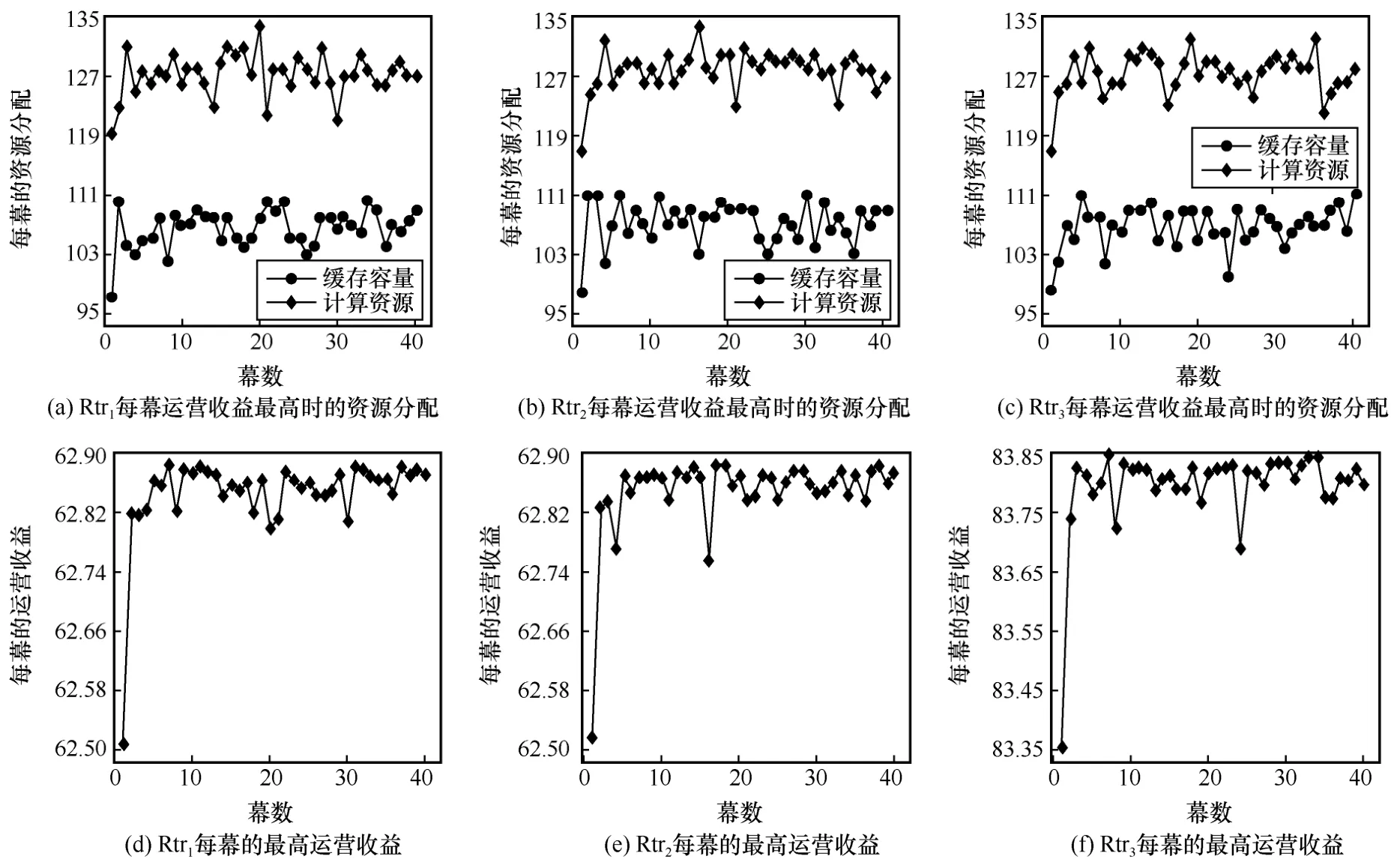
图7 基于DDPG 算法优化的各边缘节点的资源分配和运营收益
δ1(经完整回程链路传输一个内容的成本)、δ2(节点内部署单位缓存容量的成本)、δ3(运营商执行计算任务期间支付的成本)和δ4(节点内部署单位计算资源的成本)的值皆根据实际边缘计算和缓存设备厂商提供的相关价格资料设置,表1 对比了δ1、δ2、δ3和δ4不同组合下运营收益最高时的资源分配情况。本文方案在不同组合下能够自适应地调节计算和缓存资源的分配,达到相对稳定的平均收益。

表1 δ1、δ2、δ3和δ4不同组合下的资源分配和运营收益
本文将DDPG 算法和经典的DQN 算法进行了横向对比,如图8 所示,DDPG 算法在平均缓存命中率和平均运营收益两方面的表现都明显优于DQN 算法,主要原因为DDPG 采用软更新算法更新目标网络的参数,这种加权移动平均法保证了目标网络训练的稳定性;与DQN 在每步都计算所有可能动作的Q值来进行决策不同,DDPG 采用确定性策略,直接由神经网络Actor预测出该状态下需要采取的动作,降低了算法复杂度、加快了收敛速度。

图8 基于DDPG 算法和基于DQN 算法优化的性能对比
LCE(leave copy everywhere)策略和LCD(leave copy down)策略[16]是NDN 缓存放置的基准策略。LCE 策略是NDN 中默认采用的缓存放置策略,其在数据包返回路径上的每个节点都会缓存该内容的副本,这极易导致网内缓存的冗余度较高且在缓存容量较小时缓存替换频繁。LCD策略相对LCE 策略更加保守,只在命中节点的下一跳进行缓存,避免了相同内容在网络中大量复制,在一定程度上降低了缓存冗余度;此外,LCD策略需要对同一内容进行多次请求才能将其缓存到网络边缘,间接地考虑了内容流行度,使缓存利用率有所提升。
图9 对比了在节点缓存容量为108(运营收益最高时的缓存容量)和108×2 时,本文LCD 策略和LCE 策略的相关性能。在缓存命中率、平均时延、平均跳数(数据包从远程服务器或缓存节点返回所经过的网络跳数)和远程服务器负载方面,本文方案都优于LCD 策略和LCE 策略,尤其在缓存容量相对较小时,其优势更加明显:在节点缓存容量为108 时,相对LCD 策略,本文方案的缓存命中率提高了70.97%,平均时延、平均跳数和远程服务器负载分别降低了 25.97%、21.11%和9.91%。
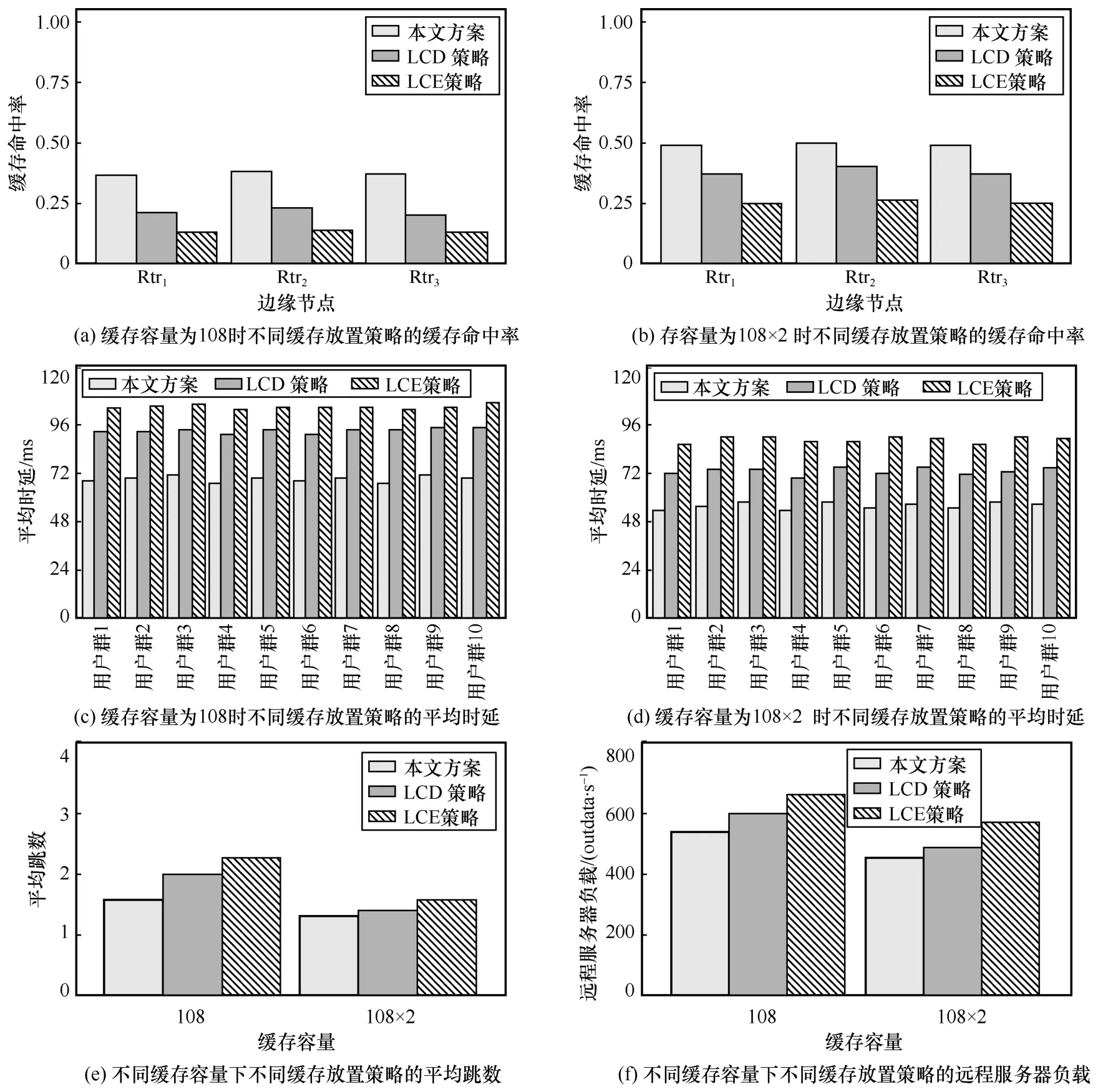
图9 不同缓存容量下不同缓存放置策略的性能对比
4 未来方向
前文讨论了基于机器学习在NDN 网络边缘联合优化计算和缓存的潜力,通过仿真证明了其对运营收益和系统性能的提升。在此基础上,本文提出以下未来的研究方向。
1)通过各边缘节点间的相互合作进行实时的情境感知[17-21],包括信道条件、用户的移动性、计算任务和内容请求的规模与优先级等,以优化移动性管理和主动资源分配。例如,实现对计算任务的自适应分流,缓解单一边缘节点计算压力的同时,充分利用当前相邻区域的闲置资源,提供更低时延的计算服务;挖掘不同区域内容流行度之间的相关关系,预判和缓存呈现由局部到全局流行态势的内容,缩短用户获取内容的时延。
2)利用联邦学习这一面向隐私保护的分布式机器学习框架[22]。联邦学习在不共享原始数据的基础上,聚合各边缘节点的本地训练的中间结果,构建具有较高泛化能力的共享模型,以推进全局范围内的性能优化,既保证了各参与方之间的数据隔离,又实现了数据价值的安全流通。
3)利用机器学习优化种类庞杂的计算和缓存服务时,往往需要一定的时间才能使模型收敛,如何提高边缘节点机器学习的效率亦是一个亟待解决的问题。可以基于软件定义网络(SDN,software defined network)和网络功能虚拟化(NFV,network function virtualization)实现网络切片[23],结合机器学习为不同类型的服务提供差异化的支持,实现高效灵活的边缘计算和缓存,并采用灵活以太网(FlexE,flexible Ethernet)技术使业务流以最短、最快的路径抵达用户[24]。
5 结束语
本文提出了一个NDN 与边缘计算相结合的综合框架并基于深度强化学习对资源分配与缓存放置策略进行联合优化,以实现网络、计算和缓存的动态协调。首先,在NDN 边缘节点部署计算模块,结合NDN 的网内缓存机制,将网络功能、内容和资源向终端用户靠近;然后,利用矩阵分解算法强大的处理稀疏矩阵的能力,补全各区域用户对内容的评分矩阵,将区域内所有用户对某个内容的相对评分作为该区域内该内容的局部流行度;最后,在平均时延的约束下,以系统运营收益最大化为目标,利用DDPG 算法对计算和缓存资源分配以及缓存放置策略进行联合优化。仿真结果显示,本文方案在稳定性、收敛速度和性能表现上都优于经典的DQN 算法;与传统的缓存放置策略相比,本文方案可以更有效地提高缓存命中率、降低用户获取内容的平均时延,综合提升运营收益和用户体验质量。
