基于大数据的智能农业云服务平台设计与实现
2022-09-03陈荣宇林伟君吴丽丹
江 顺, 陈荣宇, 林伟君, 吴丽丹
(1.广东省农业科学院农业经济与信息研究所, 广东广州 510640;2.农业农村部华南都市农业重点实验室, 广东广州 510640; 3.海丰县农业科学研究所, 广东海丰 516400;4.汕头市农业科学研究所, 广东汕头 515031)
进入21世纪,大数据、物联网和云计算技术推动信息技术和互联网进一步蓬勃发展,现阶段互联网成为了正在发展中的高效率信息库和信息交换中心,使人类生产生活方式产生了巨大变革,大数据技术和云计算技术是这一阶段信息技术和互联网发展的核心焦点。物联网技术的更新迭代促使万物互联的互联网时代来临,网络数据规模进一步膨胀,这些数据中大部分为非结构化数据。据IDC的调查报告显示,企业中80%的数据是非结构化数据且这些数据每年都按指数增长60%(该年度数据规模为前1年的1.6倍)。大数据系统既是在这样一个时代背景之下诞生,使这些非结构化数据被有效管理和利用成为可能。从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分,大数据必然无法用单台的计算机进行处理,必须采用分布式架构,它的特色在于对海量数据进行分布式数据挖掘,但它必须依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术。
随着物联网、大数据、云计算等技术应用领域不断下沉至社会生活生产实践中,数字农业也越来越成为现在和未来农业产业发展的焦点,数字农业在中国农业生产中应用的不断加深,促使中国传统农业的生产方式发生重大变革,越来越多粗放的、机械的、经验的生产模式不断向集约化、智能化、科学化发展。如今数字应用已经成为工业生产和社会生活的主流,而农业生产中数字化技术应用仍然处于初创期,农业领域可能是信息化和数字化普及的最后一个产业。导致农业领域数字化技术的应用普及缓慢的原因是多层次的,其中最主要的原因在于中国农村分散的生产经营模式不利于信息化系统的数据资源集中。而随着农村通信基础设施的不断完善、农业物联网技术的逐步成熟,国家大力推动现代农业产业园的建设,农业全产业链的数据集成成为可能。鉴于此,笔者在对大数据架构的研究基础上提出一种基于Lambda Architecture大数据架构的农业云服务平台解决方案。
1 研究方法与关键技术
Lambda 架构(Lambda Architecture)是由工程师南森·马茨(Nathan Marz)根据他在Backtype和Twitter从事分部式数据处理系统工作的经验提出的大数据处理架构,其目的是指导用户充分利用批处理和流式技术各自优点,用于实现复杂的大数据系统。在大数据处理系统中,批处理系统(如Hadoop MapReduce)具有较高的可靠性,但数据的实时性较差;流式处理系统(如Storm)则情况正好相反,数据处理延迟低,但可靠性差强人意。Lambda Architecture的目的即为协调2种技术的优缺点,使得大数据处理系统既满足高可靠性需求,又具有较低的延迟性。Lambda Architecture设计主要目的是满足以下4个方面的需求:①系统故障或人为错误不丢数据;②数据分析低延迟;③系统具备线性扩展能力;④系统中很容易增加新特性。
Lambda Architecture由批处理层(batch layer)、流式处理层(speed layer)、服务层(serving layer)组成(图1)。

图1 Lambda Architecture组成示意图Fig.1 Lambda Architecture composition diagram
(1)批处理层。批处理层的主要职责是保证数据处理的准确性和可靠性,该层将数据以原始格式存储于HDFS上,以保障和加强数据系统的可靠性,利用Hadoop MapReduce框架对数据进行处理,并保存计算结果,经该处理过程后的数据视图称之为批处理视图(Batch View)。Hadoop MapReduce框架具有优秀的鲁棒性,运行过程中即使出现异常也不会产生数据丢失。这种批处理方式只需要数据存储系统进行随机读取、追加写入操作,不需要处理随机写、加锁、数据一致性等问题,因而较大简化了存储系统的设计。但是批处理层的数据处理通常有几小时到几天的延迟。
(2)流式处理层。流式处理层的主要职责是满足所有实时性处理的需求。流式处理层通常基于Storm这样的流式计算平台,通过快速的增量式算法,以分钟级、秒级甚至毫秒级来读取、分析、保存数据。对于存储系统,由于需要支持持续的更新操作,其设计要复杂得多。为了简化问题,通常使用划窗机制来保存一段时间的数据,划窗的时间一般和批处理层的数据处理一致。流式处理往往使用内存计算,这意味着当出现异常(比如升级或工作节点异常)时,可能会导致数据的丢失或计算结果错误。然而,Lambda Architecture却不需要过多考虑这类问题,因为下一次批处理作业会再次处理所有数据并获得准确的结果。
(3)服务层。流式处理层的服务层职责是将流式处理层输出数据合并至批处理输出数据上,从而得到一份完整的输出数据,并保存到诸如HBASE这样的NoSQL数据库中,以服务于在线检索应用。在批处理计算结果之上结合少量实时数据,其结果与完全使用批处理计算相比,具有很好的近似性。
分布式文件系统(Distributed File System,DFS)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点(可简单理解为一台计算机)相连。Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是指被设计成适合运行在通用硬件(Commodity Hardware)上的分布式文件系统。HDFS有高容错性(Fault Tolerant)的特点,并且设计用来部署在低廉的(Low Cost)硬件上。而且它提供高吞吐量(High Throughput)来访问应用程序的数据,适合那些有超大数据集(Large Data Set)的应用程序。HDFS放宽了POSIX的要求,这样可以实现流的形式访问(Streaming Access)文件系统中的数据。
HDFS的结构。HDFS由4部分组成(图2):HDFS客户端(HDFS Client)、名称节点(Name Node)、数据节点(Data Node)和辅助名称节点(Secondary Name Node)。HDFS是1个主-从(Mater/Slave)体系结构,HDFS集群拥有1个名称节点和一些数据节点。名称节点管理文件系统的元数据,数据节点存储实际的数据。

图2 HDFS结构示意图Fig.2 HDFS structure diagram
(1)名称节点:负责管理分布式文件系统的命名空间(Namespace),保存了2个核心的数据结构,即镜像文件(FsImage)和操作日志(EditLog)。镜像文件用于维护文件系统树以及文件树中所有的文件和文件夹的元数据。操作日志文件中记录了所有针对文件的创建、删除、重命名等操作。
(2)HDFS客户端:提供一系列命令用于管理和访问HDFS,如启动和关闭HDFS。用于与数据节点交互,读取或者写入数据;读取时,要与名称节点交互,获取文件的位置信息;写入HDFS时,Client将文件切分成多个的数据块(Block),然后进行存储。
(3)辅助名称节点:它是用来保存名称节点中对HDFS元数据信息的备份,并减少名称节点重启的时间。辅助名称节点一般是单独运行在1台机器上。
(4)数据节点:数据节点是HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
HDFS的数据读取。HDFS读取数据流程(图3)如下:
(1)打开HDFS文件。HDFS客户端首先调用“DistributedFileSystem类”中的“open方法”打开HDFS文件,底层会调用“ClientProtocal类”中的“open方法”,返回一个用于读取的“HdfsDataInputStream”对象。
(2)从名称节点获取数据节点地址。在构造“DFSInputStream对象”的时候,调用“ClientPortocal类”中的“getBlockLocations方法”向名称节点获取该文件起始位置数据块信息。名称节点返回的数据块的存储位置是按照与客户端距离远近排序的。所以“DFSInputStream对象”可以选择一个最优的数据节点,然后与这个节点建立数据连接读取数据块。
(3)连接到数据节点读取数据块。HDFS客户端通过调用“DFSInputStream对象”从最优的数据节点读取数据块,数据会以数据包(Packet)的形式从数据节点以流式接口传送到客户端,当达到一个数据块末尾的时候,“DFSInputStream对象”就会再次调用“getBlockLocations方法”获取下一个数据块的位置信息,并建立和这个新的数据块的最优节点之间的连接,然后HDFS继续读取数据块。
(4)HDFS客户端关闭输入流。
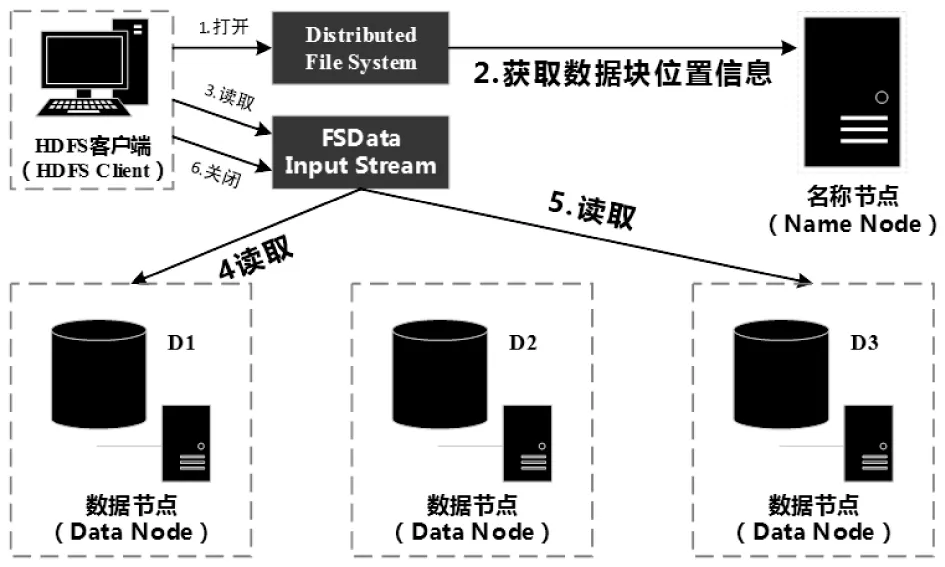
图 3 HDFS读取数据流程 Fig.3 HDFS data reading process
HDFS数据写入。HDFS写入数据流程见图4:
(1)HDFS 客户端调用“DistributedFileSystem类”中的“create()方法”
(2)底层调用“ClientProtocal类”中的“create()方法”在名称节点的文件系统目录树中创建一个文件,并且创建新文件的操作记录到操作日志(EditLog)中,返回一个输出流对象(HdfsDataOutputStream)。
(3)HDFS 客户端根据返回的输出流对象调用“write方法”来写数据。
(4)由于之间创建的新文件是一个空文件,并没有申请任何数据块,所以“DFSOutputStream对象”首先会调用“ClientProtocal类”中的“addBlock方法”向名称节点申请数据块,数据块的大小可以由用户自己配置,默认为128 M,名称节点返回一个“LocatedBlock对象”,该对象保存了该数据块所有数据节点位置信息,然后就可以建立数据流管道写数据块。
(5)建立通向数据节点的数据流管道,写入数据:建立数据流管道之后,HDFS客户端就可以向数据流管道写数据。它会将数据切分成一个个的数据包(Data Packet),然后通过数据流管道发送到数据节点。
(6)每一个数据包(Data Packet)都有一个确认包(Ack Packet),逆序的通过数据流管道回到输出流。输出流在确认了所有的数据节点已经写入了这个数据包,就会从对应的缓存队列删除这个数据包。
(7)当数据节点成功接收一个数据块时,数据节点会通过“DataNodeProtocal类”中的“blockReceivedAndDelete方法”向名称节点汇报,名称节点会更新内存中数据块和数据节点的对应关系。
(8)完成操作后,客户端关闭输出流。

图4 HDFS写入数据流程 Fig.4 HDFS data writing process
HDFS的优缺点。HDFS具有鲜明的优势,它兼容廉价的硬件设备,支持流数据的读写和大数据集的集成,采用十分简单的文件模型,拥有强大的全平台性能。但同样有不容忽视的局限性:HDFS数据读取效率低且速度慢,不适合有低延迟需求的数据访问,且无法高效存储大量小文件,不支持数据集的并行处理,即不支持多用户写入及任意修改文件。
批处理技术。MapReduce是面向大数据并行处理的计算模型、框架和平台,它具有3层隐藏含义:
(1)基于集群的高性能并行计算平台(Cluster Infrastructure)。它允许用市场上普通的商用服务器构成一个包含数十、数百至数千个节点的分布和并行计算集群。
(2)并行计算与运行软件框架(Software Framework)。MapReduce提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务。
(3)并行程序设计模型与方法(Programming Model & Methodology)。它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce共2个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理。
流式计算技术。Storm是一种开源的分布式实时计算框架,可以简单、可靠的处理大量的数据流。Storm有很多使用场景,如实时分析、在线机器学习、持续计算、分布式远程过程调用(Remote Procedure Call ,RPC)、数据抽取转换加载(Extract-Transform-Load,ETL)等。Storm是一个分布式的、可靠的、容错的数据流处理系统,Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理,而且处理速度很快(在1个小集群中,每个结点每秒可以处理数以百万计的消息)。Storm的部署和运维都很便捷,而且更为重要的是可以使用任意编程语言来开发应用。
云计算是一种IT资源的交付和使用模式,指通过网络以按需、以扩展的方式获得所需的资源(硬件、平台、软件及服务等),提供资源的网络被称为“云”。与其说云计算是一种新的技术领域,不如说它是一种在业务模式方面的创新。“云”中的资源在使用者看来是可以无限扩展的,并且可以随时获取,按需使用、随时扩展、按使用付费。公共云是最基础的服务,多个客户可共享一个服务提供商的系统资源,他们无须架设任何设备及配备管理人员,便可享有专业的IT服务,这对于农业经营主体来说,无疑是一个降低资金和管理成本的理想软件架设方式。公共云还可细分为3个类别,包括软件即服务(Software-as-a-Service,SaaS)、平台即服务(Platform-as-a-Service, PaaS)、基础设施即服务(Infrastructure-as-a-Service, IaaS)。
SaaS(Software as a Service)应用即服务,软件即服务也是其服务的一类,通过互联网提供按需软件付费应用程序,云计算提供商托管和管理软件应用程序,并允许其用户连接到应用程序并通过全球互联网访问应用程序。在SaaS中从底层的网络和存储设备到上层的数据和应用的管理都通过云服务托管的方式进行架设和管理(图5),用户可以从任意位置、通过任意设备登录SaaS应用程序,由SaaS服务的提供商进行系统的日常管理和更新,用户无须安装部署或维护更新,无论是农业生产企业和SaaS服务提供商,都大大降低了成本的投入。SaaS服务提供商可以随着使用量的增加提供更多的数据存储能力、计算能力或网络接入能力。
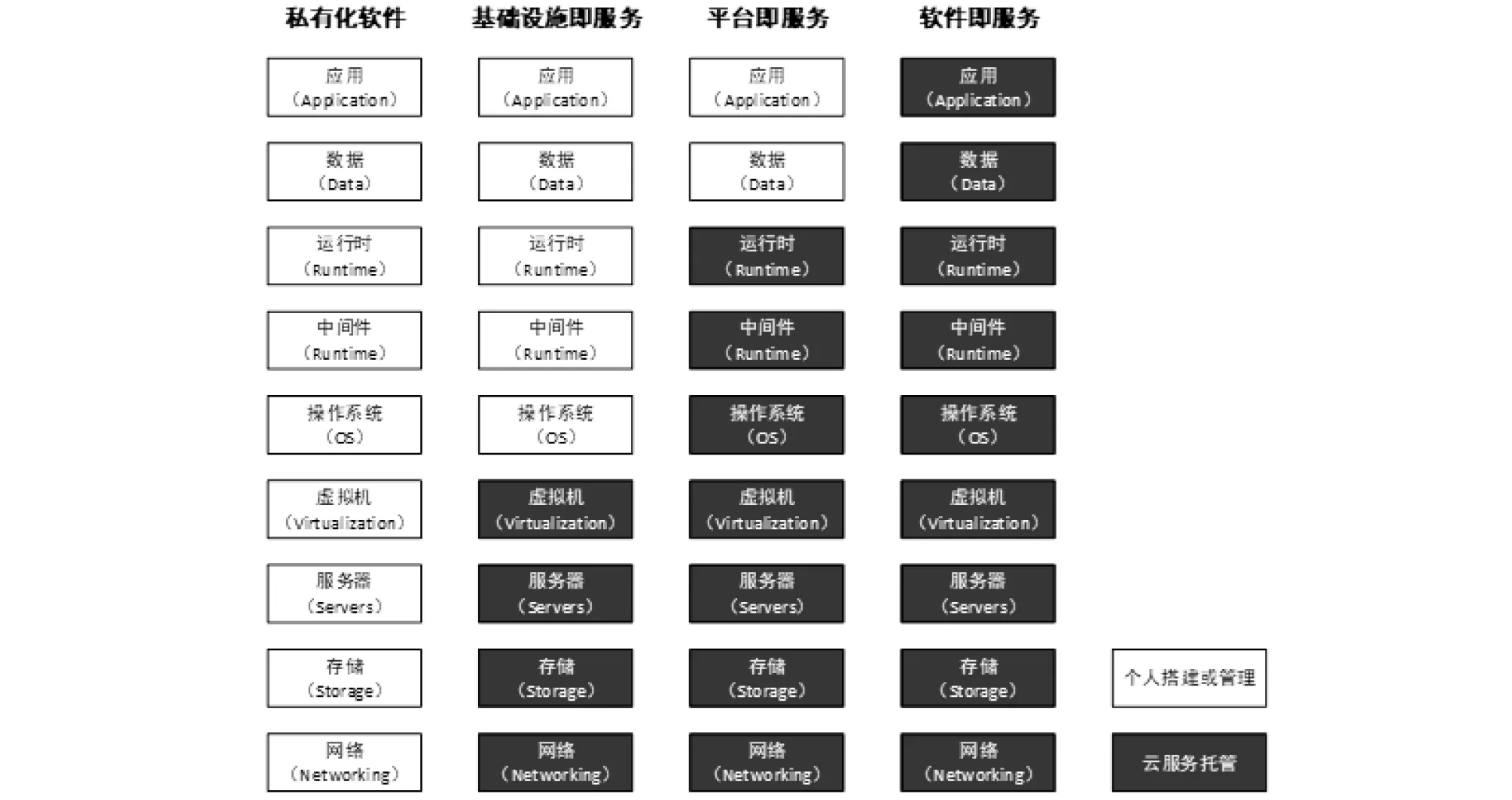
图 5 云服务架设方式对比[27-28]Fig.5 Comparison of cloud service setup
2 研究内容
基于HDFS和NoSQL的多元农业数据集成。在农业从原料、加工、生产到销售的全产业链中会产生海量类型多样的数据,这些是融合了农业的地域性、季节性、多样性、周期性等自身特征后产生的来源广泛、类型多样、结构复杂、具有潜在价值,并难以应用通常方法处理和分析的数据集合,是典型的大数据的特征。农业大数据保留了大数据规模巨大(Volume)、类型多样(Variety)、价值密度低(Value)、处理速度快(Velocity)、精确度高(Veracity)和复杂度高(Complexity)等基本特征,并使农业内部的信息流得到了延展和深化。
物联网、遥感等先进技术的使用使得农业大数据的来源更加丰富、结构更加复杂、类型更加多样,农业大数据按产生的场景可以概括为3种数据类别:生产端数据、市场端数据和知识库。按数据的组织结构不同又可以分为结构化业务数据、半结构化数据(Semi-structure Data)和非结构化数据(图6)。
对于大量的半结构化数据和非结构化数据的存储、并发计算和扩展能力需求,大数据系统普遍采用非关系型数据库(NoSQL)解决方案,如Apache的Hbase分布式数据库系统。大数据系统中,结构化数据和半结构/非结构化数据有着截然不同的2套处理流程和体系,结构化数据一般可以直接存入分布式数据库环境中,半结构化数据/非结构化数据则通过2种途径存入至分布式文件系统或分布式数据库中:对于能够序列化的数据,直接经过ETL(抽取、转换、加载)清洗处理后直接存放至数据库中;对于不能够序列化的数据,一般通过数据整理后存放至分布式文件系统中。
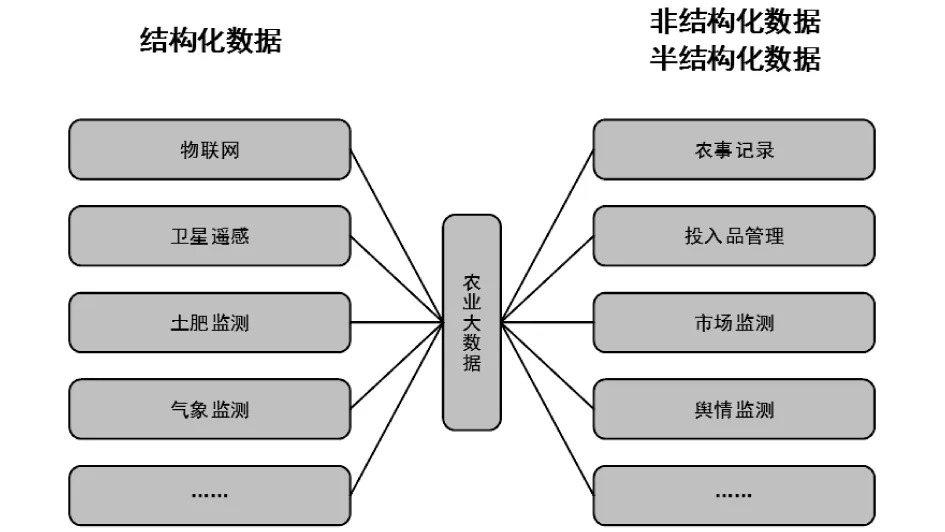
图6 农业大数据集成示意图Fig.6 Schematic diagram of agricultural big data integration
基于Lambda Architecture的农业大数据架构。在由实际监测、手工录入或信息采集所产生的数据流进入系统后,同时发往批处理层和流式处理层处理。批处理层以不可变模型离线存储所有数据集,通过在全体数据集上不断重新计算构建查询所对应的批处理视图。流式处理层处理增量的实时数据流,不断更新查询所对应的即时视图。服务层合并批处理视图和即时视图中的结果数据集到最终的数据集并响应用户的查询请求(图7)。

图7 农业大数据服务架构示意图Fig.7 Schematic diagram of agricultural big data service architecture
系统架构设计。该研究示例系统从系统底层至系统上层依次为云计算的硬件系统和虚拟系统、大数据的获取、存储、查询计算、分析、服务和应用业务模块(图8)。
平台应用界面。该研究的大数据系统架构已经在广东省农业生产领域中形成了多套应用,涉及的农业细分行业包括茶叶产业、蔬菜产业、水稻产业等(图9、10),通过对农业资源基础数据、农业生产数据、生产经营主体数据、市场信息数据、科技服务数据的整合,实现“一个平台,多套系统”的系统集成方式,测试系统服务器配置如表1所示。
大数据应用平台在云端共部署数据存储服务节点7个,其中1个主名称节点、1个辅助名称节点、5个大数据存储节点(数字节点),均为高性能数据计算配置。应用服务器主要承担网络接口任务,部署一套Web集群服务器,架设nginx服务框架,承担网络高并发处理任务,部署Web服务器2套,另设1套redis缓存服务器。
大数据服务系统目前已在广东省部分现代农业产业园部署(图9~11),以上3个平台基于一套大数据云服务系统,由SaaS服务提供商提供系统的架设、维护和升级服务,在系统的设计和开发过程中,研究和开发团队设计了全面的访问控制功能,保证私密生产数据的安全性。农业产业园在资源和产业方面集中化和规模化的特点,使得农业大数据的获取相对于分散小农更具便利性,物联网设施的应用也更为普遍,由于生产的集约化和农村劳动人口的流失,对农业生产的自动化需求也更为迫切,大数据系统的部署为农业生产的进一步自动化提供基础性的服务。
数据管理视图。系统数据的采集、管理系统界面如图12所示,数据管理视图主要用于档案信息和农事操作信息等

图8 农业云服务平台架构示意图Fig.8 Schematic diagram of agricultural cloud service platform architecture

表1 测试系统服务器配置Table 1 Test the system server configuration

图9 农业产业大数据服务平台 Fig.9 Agricultural industry big data service platform
需要手动输入的信息录入和管理,目前大数据系统的数据管理系统实现了田块管理、农业投入品(化肥、农药等)管理、生产批次管理、农事计划和溯源信息管理等关键的管理功能。
在研究中对常规系统和大数据系统的集群查询性能进行了对比试验,试验在实验室虚拟化环境中运行,分别针对该研究的Hadoop数据集群和普通MySQL数据集群,试验结果如图13所示。从图13可以看出,当数据规模较小时,大数据集群效率无法体现,甚至还落后于相同硬件配置下的 常规数据集。在300万条数据级别时,常规数据集与大数据集群效率基本持平。在 500 万条数据级别时,大数据集群的效率明显高于常规数据集,数据查询效率提升超过25%。

图10 农业产业大数据服务平台Fig.10 Agricultural industry big data service platform

图11 农业产业大数据服务平台Fig.11 Agricultural industry big data service platform
3 结论与讨论
该研究中的大数据架构在保障数据的不可变性的基础上做到了数据的重新计算,批处理层保存了原始数据,可以极大避免数据的损失,算法可以同时分析历史数据和短期实时数据,兼顾数据的准确性和实时性,但事实上大数据系统的2个计算层进行了大量的重复计算,从计算资源角度看,这样的大数据系统架构消耗了较多的资源。
大数据和云计算服务2种焦点技术的结合,为农业生产和流通产生了有益的结果,在云计算系统中的大数据分析有多种优势。首先,云计算服务有助于整合来自众多来源的数据,随着云计算技术的进步,大数据分析得以更加完善;其次,云计算服务为农业大数据分析提供了灵活的基础架构,大大简化了大数据分析的系统规模,可以根据需求进行扩展,使得管理工作负载变得容易;最后,云计算服务使得用户无需大规模的大数据资源即可进行大数据处理,大大降低了涉农企业和组织机构的大数据系统运营成本,为农业发展带来巨大的价值。
在系统的实际应用中,时常会出现实时与批量计算结果不一致引起的数据口径问题,因为批处理和实时计算是2个并行的计算框架和计算程序,批处理计算是整体数据计算框架,实时计算则是局部数据计算,常会出现某一数据在一定时间后发生变化的现象。
平台已经完成技术集成和整合,在农业大数据领域应用

图12 数据管理视图Fig.12 Data management view

图13 Hadoop数据集群与MySQL数据集群性能对比Fig.13 Comparison between Hadoop data clustering and MySQL data clustering
具备应用的超前性和技术的先进性,但目前在应用上没有突出的亮点,尚处于前端应用的缺乏阶段,平台的进一步开发与研究过程中,应当挖掘平台更深层次的应用,实现技术的社会经济效益。
