基于联邦学习的短期负荷预测模型协同训练方法
2022-09-02车亮徐茂盛崔秋实
车亮,徐茂盛,崔秋实
(1.湖南大学电气与信息工程学院,湖南长沙 410082;2.重庆大学电气工程学院,重庆 400044)
电力系统短期负荷预测是指根据过去一段时间的负荷以及日期、气象等数据,对未来短时间的负荷变化进行预测[1].精准的负荷预测是电网实施精确调度、制订发电计划以及设置合理备用的基础,是保证电力系统可靠运行与增加经济效益的必要条件[2].随着电网数字化程度不断加深,电力公司陆续安装了多种智能仪表,获得了更多精细的负荷与气象等数据,这使得采用人工智能方法进行精准负荷预测变得可行[3].
近年来,机器学习算法被广泛应用在短期负荷预测领域,研究者们对各种算法进行改进,提出了许多解决短期负荷预测领域相关问题的方法[4].研究者将支持向量机、BP(Back Propagation)神经网络(Neural Network,NN)、LSTM 网络等多种机器学习算法应用于负荷预测,并对其进行改造以提升预测精度.文献[5]提出基于深度信念网络的短期负荷预测方法,将无监督与有监督训练结合,进而提升预测准确度;文献[6]将Attention 机制加入LSTM 网络构建预测模型,从输入数据中提取对负荷预测起到关键作用的特征;文献[7]基于Hadoop 架构中的MapReduce 框架构建BP 神经网络预测模型;文献[8]构建基于双向长短期网络的预测模型,并融入特征选择方法,选择出最佳输入特征.一般来说,单一类型的神经网络只擅长挖掘数据的某一类特征,而负荷预测数据包括负荷、气象和日期等多类特征,利用不同的神经网络能更有效提取不同数据类型的特征[9];文献[10]先运用卷积神经网络(Convolutional Neural Network,CNN)提取特征与负荷的联系,最后将结果输入到GRU 网络中进行负荷预测,提升预测准确率;文献[11]将卷积神经网络(CNN)和长短期记忆(LSTM)网络相结合以构建短期负荷预测模型;文献[12]综合集合经验模态分解(Ensemble Empirical Mode Decomposition,EEMD)、门控循环单元神经网络(Gated Recurrent Unit,GRU)和多元线性回归(Multiple Linear Regression,MLR)方法构建预测模型;文献[13]提出了一种基于GRU-NN 模型的短期电力负荷预测方法;文献[14]提出了基于LSTM 和XGBoost的组合预测模型.
由上可见,目前机器学习方法在短期负荷预测领域的应用已取得了一定的成果,但在实际应用中,现有方法还存在以下问题:
1)未解决实际情况下负荷数据样本数量与特征不足的问题.现有基于机器学习的负荷预测方法依赖于预测者拥有样本数足够多、特征种类足够丰富的训练数据集,但在实际负荷预测工作中,部分预测者往往难以满足该条件(例如小规模电力公司、新接入电网的用户和负荷聚合商等通常难以建立满足负荷预测需求的数据量和特征足够的训练数据集[15-16]).
2)预测模型泛化能力问题.仅使用单个地区数据训练出的模型,难以直接移植到新的地区进行预测,预测模型的泛化能力亟待增强.
3)数据隐私问题.若能实现不同地区间共享数据训练模型,就可以有效提升模型预测能力[17].但目前各电力公司均具有较高的数据保密要求,历史负荷等数据是严格保密的,这限制了数据共享训练,因此相关数据隐私保密问题亟待解决.
因此,目前亟需一个在保护负荷等数据隐私的前提下实现协同构建负荷预测模型的方法.针对这一需求,本文引入联邦学习(Federated Learning,FL)方法.联邦学习可以实现多个数据持有者在不共享其数据情况下协同训练机器学习模型,在保护数据隐私的同时降低数据通信量,提高通信效率[18].目前,联邦学习已被研究者们应用在一些需要考虑数据隐私及降低通信开销的场景[19].文献[20]将深度强化学习模型进行联邦,实现高准确率、低时延的设备节点选择;文献[21]将联邦学习应用于物联网框架下的边缘计算过程;文献[22]将联邦学习应用于雾计算过程;文献[23]将联邦学习应用在电力计量系统中,分别应用于计量装置故障诊断、无线接入安全检测以及电费风险识别场景,均取得了较好的效果,证明了将联邦学习方法应用在电力系统领域具有实用性和可行性.
针对上述负荷预测模型构建所需数据样本数量与特征不足、模型泛化能力差以及负荷相关数据高度保密无法共享训练的问题,本文引入联邦学习方法,以LSTM 网络的短期负荷预测模型为基础,提出基于联邦学习的短期负荷预测模型协同训练方法,结合短期负荷预测场景的特点,对数据传输过程与模型聚合过程进行优化改进.该方法实现了各负荷运营商在保护数据隐私的前提下对模型进行协同训练,并且有效提升了短期负荷预测模型的预测准确率和泛化能力.
1 基于LSTM 的短期负荷预测模型
1.1 长短期记忆(LSTM)网络
LSTM 网络是由循环神经网络改进而来的,解决了循环神经网络存在的长期依赖问题.相比常规循环神经网络,LSTM 添加了输入门、遗忘门和输出门[24].LSTM网络基本单元如图1所示.

图1 LSTM网络基本单元Fig.1 LSTM network basic unit
图1 中,σ为sigmoid 激活函数,xt为该时刻输入序列值,tanh 代表tanh 激活函数.Ct-1和Ct分别表示上一时刻和当前时刻的单元状态,ht-1和ht分别表示上一时刻和当前时刻的隐藏状态,ft、it和ot分别表示当前时刻的遗忘门、输入门和输出门计算变量,C^t表示该时刻输入的单元状态.上述变量计算公式如下:

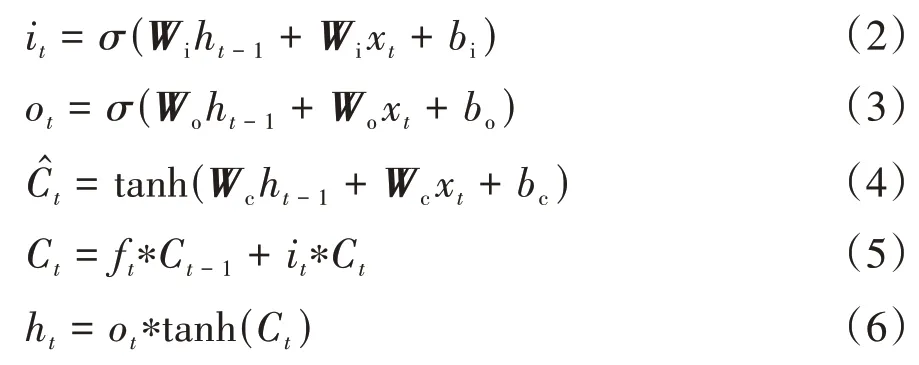
式中:Wf、Wi、Wo分别为遗忘门、输入门、输出门的权重矩阵;bf、bi、bo分别为遗忘门、输入门、输出门的输出偏置项;*表示矩阵的Hadamard积.
1.2 基于LSTM 网络的短期负荷预测模型构建

由于负荷数据数量级较高,与温度、日期等特征数量级差距较大,不利于模型训练.为了消除各类特征之间量纲不同的影响,使模型快速收敛,并且考虑到各负荷运营商之间负荷数据数量级存在较大差异,故利用本文方法对输入数据进行归一化处理,将所有输入数据归一化在[0,1]内,如下式所示:


图2 LSTM网络模型结构Fig.2 Structure of LSTM network model
负荷预测效果评价指标采用均方根误差(Root Mean Square Error,RMSE)和平均绝对百分比误差(Mean Absolute Percentage Error,MAPE),指标值越小,表示预测值与真实值之间的误差越小,模型的预测效果越好.指标计算公式分别如式(8)和式(9)所示.

2 基于FL 的短期负荷预测模型协同训练方法
2.1 方法概述
基于联邦学习的短期负荷预测模型协同训练方法能在保护各负荷运营商数据隐私的同时,利用各个运营商所拥有的负荷数据资源协同训练短期负荷预测模型,有效提高模型的预测准确率及多场景泛化能力.
本文方法整体系统架构如图3 所示.其中,本文第1 节所构建的负荷预测模型部署在服务器端与各个负荷运营商端,负荷运营商可以是某地区电力公司或某些电力用户的集合.
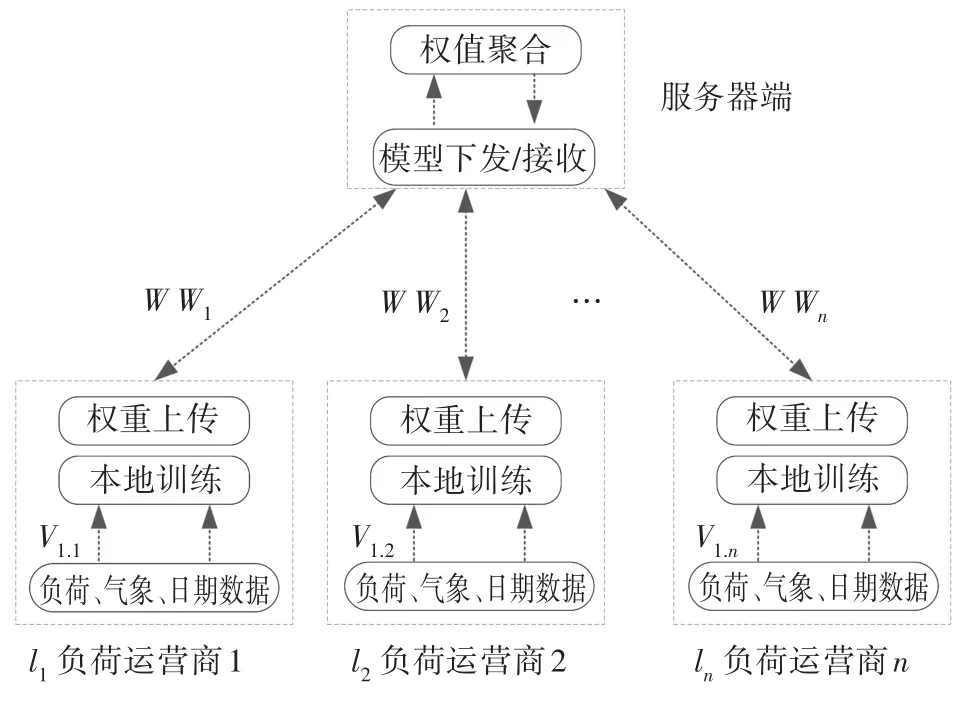
图3 本文方法整体系统架构Fig.3 The overall system structure of this method
在结构上,本文方法整体组成包括服务器端、通信网络、本地负荷运营商及其对应的负荷、气象和日期数据.令L={l1,l2,…,ln}表示所有参与协同训练的负荷运营商的集合,每一个lk(k=1,2,…,n)具有对应的训练数据以及进行本地模型训练、模型推理的能力.图3 中,令V表示训练数据(包括负荷数据、气象数据、日期数据)集合,则第k个负荷运营商lk所拥有的训练数据表示为Vl,k;W表示服务器下发到本地的模型权重参数;令Wk(k=1,2,…,n)表示第k个本地端lk从本地服务端上传至服务器端的模型权重参数.
整体流程主要包括预测模型下发、负荷运营商本地训练、各运营商模型上传以及模型聚合4 个步骤.具体步骤如算法1所示.
1)以LSTM网络的短期负荷预测模型为基础,服务器端初始化各参数,并下发模型到本地端.
2)本地端接收下发的模型,用该模型参数更新自身模型参数,并以自身数据训练模型.
3)将已训练完成的模型上传至服务器端,采用不传输梯度而是直接传输完整权重参数的方法降低数据泄露风险,避免被针对模型参数进行攻击的算法窃取数据.

4)服务器端执行模型聚合,考虑电力负荷预测场景的特点,在模型聚合阶段,根据各参与方数据集质量形成适用于负荷预测场景的模型聚合策略.最终,形成完整的基于联邦学习的短期负荷预测模型协同训练方法.
选取算法1 步骤中较为主要的10)~12)在2.2 节详细介绍;步骤13)和14)在2.3 节详细介绍;步骤16)和17)在2.4节详细介绍.
2.2 模型下发与本地训练更新
在服务器端进行模型预训练,得到服务器端模型权重参数W.通过通信网络将W下发至各个参与训练的联邦参与本地端lk.各lk接收服务器下发的W,更新本地模型参数Wk.随后以其所拥有的数据集Vl,k作为本地训练样本集,进行本地训练并更新Wk.
模型训练过程采用Adam(Adaptive Moment Estimation)优化算法.该算法在RMSprop 算法的基础上添加了动量项,根据t时刻梯度gt的一阶矩估计和二阶矩估计来动态调整每个参数的学习率.该算法的主要优点为:经过偏置校正后,每一次迭代学习率都存在于一个确定的范围,使得参数较为稳定.
基于Adam的模型训练过程描述如下:
1)根据t时刻的梯度gt分别计算梯度和梯度平方的指数移动平均数mt和vt,β1与β2分 别 取0.9、0.999,m0与v0均设为0:

2)为降低偏差对训练初期带来的影响,需对m0=0和v0=0带来的偏差进行纠正,将mt和vt分别纠正为和,如式(11)所示:

3)按式(12)更新模型权重参数Wk,t,式中η为学习率(一般取0.001),ϵ为用于避免除数为0 的很小常数(一般取10-8).

4)模型权重参数更新如式(13)所示,式中Wk表示参数更新后的第k个本地模型权重,∑ΔWk,t表示第k个本地模型总的权重变化量:

采用平均绝对误差(Mean Absolute Error,MAE)作为模型的目标损失函数yMAE.

2.3 模型上传
本地模型训练完成后,每个负荷运营商lk经过通信网络上传模型权重参数Wk至服务器端,但在参数传输过程中存在多种不同的传输方式.
经典的联邦学习方法在训练迭代时传输梯度数据gt,每位本地参与者首先将当前训练的模型梯度相关系数上传至服务器,服务器通过求取每位参与者最新的梯度相关系数的平均值来更新全局模型;在下一次迭代中,参与者再下载最新的全局模型参数继续训练.但是,此种方法已被指出存在隐私泄露风险.有学者发现在联邦过程中,如果发生梯度参数泄露,则可用算法通过梯度反推出该次迭代对应的训练数据.例如较为典型的Deep Leakage from Gradients(DLG)算法[25]:首先假设虚拟的输入和对应的标签;随后,计算虚拟的梯度,在此基础上优化虚拟梯度与真实梯度之间的距离,通过梯度的匹配使得假设的虚拟数据不断靠近原始数据;最终,获取参与方的真实训练数据.
为了避免由于梯度参数泄露导致反推出对应数据样本的风险,本文采用不传输梯度而是直接传输完整权重参数的方法,在参与方本地模型训练完成后,上传整体模型权重参数Wk,而非单个数据样本训练时产生的梯度.权重参数经过该参与方使用自身全部数据通过Adam 算法进行多次迭代训练,根据上述Adam 训练过程及DLG 算法原理,此时已无法推导出每一条数据样本训练时所对应的梯度计算值,从而无法推导出对应的原始数据样本.因此,在权重参数上传过程中,即使遇到模型参数窃取行为,窃取者也无法推导出该参与方对应的所有训练数据集样本.
同时,为了服务于模型聚合阶段的权值计算过程,在此阶段还需上传各本地负荷运营商lk所拥有数据Vl.k的时间跨度信息Uk.
2.4 模型聚合
当所有本地负荷运营商lk完成模型上传流程后,服务器端对接收到的全部模型执行聚合.以下介绍本文执行模型聚合步骤时权值wB,k的计算方法.
现有的联邦学习模型聚合方法并不适应负荷预测场景.例如,在经典联邦学习方法中,某联邦参与方lk模型聚合的权值wB,k仅与其参与训练的样本数量大小有关.这种方法没有结合实际的应用场景,未充分考虑各个联邦参与方数据样本的质量.这会导致在聚合时使用了不合理的聚合权重参数,影响最终模型的预测准确率和泛化能力.而在本文方法所针对的短期负荷预测场景中,拥有越多样化、越全面的数据的负荷运营商所训练出的本地负荷预测模型往往有着更优秀的预测准确率与泛化能力,在模型聚合时应该给予更高的聚合权重.
本文结合负荷预测场景的特点,定义各个负荷运营商的贡献度G,进而更新聚合权值wB,k.贡献度Gk与运营商lk所拥有的数据样本数量大小以及对应的数据日期跨度Uk均有关;当一个负荷运营商自身数据样本数量越大或其所拥有的相对其他运营商数据的新时刻数据越多,其贡献度G应该越大;该模型对服务器模型的聚合过程也应该有更大的影响,参数聚合时拥有较高的权重.
对每一个存在数据的时刻赋予总量为1 的贡献量,对于i时刻,若在该时刻共有Qi个负荷运营商存在数据样本,则共同平分该时刻的贡献量,每个运营商得到的贡献分量为Bk,i;若负荷运营商lk在该时刻i没有数据样本,则其贡献分量Bk,i=0.

负荷运营商lk在所有时刻的贡献分量之和可计为∑iBk,i.事实上,不同运营商拥有的数据所覆盖的时段可能不一致;将所有这些时段的并集构成的时段包含的时刻点数量记为H;换言之,H表示有一个或以上运营商拥有数据的时刻点的总数量.那么,∑iBk,i与H的比值,即为运营商lk的贡献度Gk,如式(16)所示.

贡献度确定后,按照各参与方对联邦模型的贡献度Gk更新wB,k,执行模型聚合,更新模型参数.更新方法如式(17)(18)所示.
式中:W为已更新后模型权重参数;Wk为参与方lk在经过本地训练后所上传的模型权重参数.
3 仿真验证
3.1 试验环境
本文采用多个相互独立的计算机模拟参与联邦的各个负荷运营商,进而验证本文所提出方法对预测准确率与泛化能力的提升.采用5台计算机模拟5个本地负荷运营商(地区),各计算机配置均为英特尔至强6248R CPU,RTX 3080 GPU,512 GB 内存;同时采用一台个人计算机作为服务器端,配置为Intel i7 CPU,16 GB 内存,Intel UHD Graphics 630 集成显卡.上述设备之间可点对点通信.
本文采用在负荷预测中具有代表性的GEFCom2012比赛数据[26],作为试验样本数据集.该数据集包含20个地区每1 h记录1次的电力负荷数据、对应温度数据以及日期信息,将其整理成可用于本文LSTM 模型输入的数据集.深度学习算法采用Python 3.6 编程语言编程,负荷预测模型的深度学习框架采用TensorFlow2.
3.2 仿真结果
1)为了验证本文方法对模型预测能力的提升,同时排除日期等因素对预测精度的影响,在3.2.1 节中将参与协同训练的各地区所拥有数据的时间跨度均设置为同一时间段,样本设为相同数量.
2)为了验证本文方法对模型泛化能力的提升,在3.2.2 节中将各参与方的数据时间跨度设置为不同时间段,样本设为不同数量.设置3 个算例验证其在3种场景下对模型预测精度和泛化能力的提升.
3.2.1 相同时间跨度与数据量的参与方进行联邦
为了体现本文方法对模型预测准确率的提升,选取5 个地区作为相互独立的负荷运营商参与联邦过程,分别记为l1、l2、l3、l4、l5.数据集选择该5 个地区2004 年量测数据Vl,1~Vl,5,每1 h 有1 次记录,全年每个Vl,k有8 784个数据样本.
需要说明的是,本算例主要目的是验证本文方法对预测精度的提升,所以应排除各地区数据量及选取日期差异的干扰.因此,本算例采用1 月1 日至7 月27 日的数据样本作为模型训练样本集,以7 月28日的24个数据样本作为测试集.
依次将5 个地区作为目标对象,每一个地区均进行以下工作:首先以地区lk(k=1、2、3、4、5)自身所拥有的数据集进行模型训练,并将该训练好的模型作为服务器模型,记录此时模型对该日负荷的预测结果;随后,将该服务器模型下发至除lk外其余4 个本地端,各lk根据自身所拥有的数据集进行本地模型训练;依次进行本地模型更新、本地模型上传、服务器接收模型、服务器模型聚合更新流程;地区lk得到更新后的服务器模型,并在测试集进行测试.最终,记录5 个地区单独模型负荷预测及联邦后预测的结果,并对比实际负荷、单一模型及本文方法的预测结果.各地区负荷预测结果对比分别如图4~图8所示,RMSE和MAPE结果对比分别如表1和表2所示.
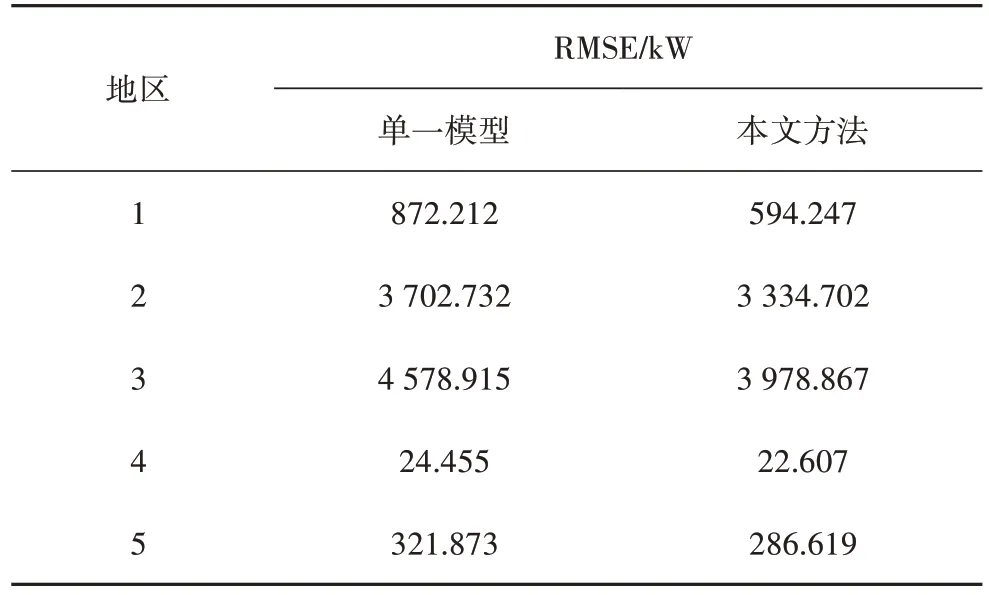
表1 RMSE对比Tab.1 RMSE comparison

表2 MAPE对比Tab.2 MAPE comparison

图4 地区1负荷预测结果对比Fig.4 Comparison of load forecast results for region 1

图5 地区2负荷预测结果对比Fig.5 Comparison of load forecast results for region 2

图6 地区3负荷预测结果对比Fig.6 Comparison of load forecast results for region 3
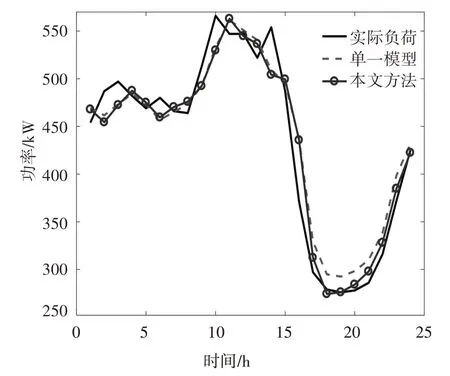
图7 地区4负荷预测结果对比Fig.7 Comparison of load forecast results for region 4

图8 地区5负荷预测结果对比Fig.8 Comparison of load forecast results for region 5
从图4~图8 可以看出,使用单一负荷预测模型预测的负荷曲线与实际负荷曲线存在着明显差距,但经过本文方法训练的模型所预测的负荷曲线与真实曲线之间的差距明显缩小.由表1 和表2 可知,在5次测试中,各地区单一模型的预测结果相对该地区实际负荷的误差均较大,地区4的MAPE甚至超过了5%,这表明单独使用单一负荷预测模型并不具备良好的误差控制效果.使用本文所提方法,模型的误差指标RMSE 与MAPE 都有了明显下降.地区1的误差下降最为明显,相比单一模型,RMSE 与MAPE 分别减少了32%和43%.由此可见,本文所提方法在保护数据隐私的情况下,丰富了参与到模型训练的数据特征,弥补了单一地区数据集特征不够全面的缺陷,最终验证了经过本文所提方法训练的负荷预测模型具有比单一数据集训练的模型更加优秀的预测准确度和更好的误差控制能力.
3.2.2 多场景测试
本文所提方法也适合更多复杂的场景.为了验证经过本文方法训练后的模型在多场景下具有良好的预测准确率和泛化能力,设置如下3 个算例:算例1 和算例2 模拟利用本文方法实现扩充数据集时间跨度的场景;算例3 模拟将模型移植到新的地区进行预测的场景.
对仿真所用到的数据集进行预处理,地区1~地区5的数据量及日期特征均不相同.其中地区4由于为新设立的区域,并无历史数据,但具有负荷、气象等数据量测能力.详细设置如表3所示.
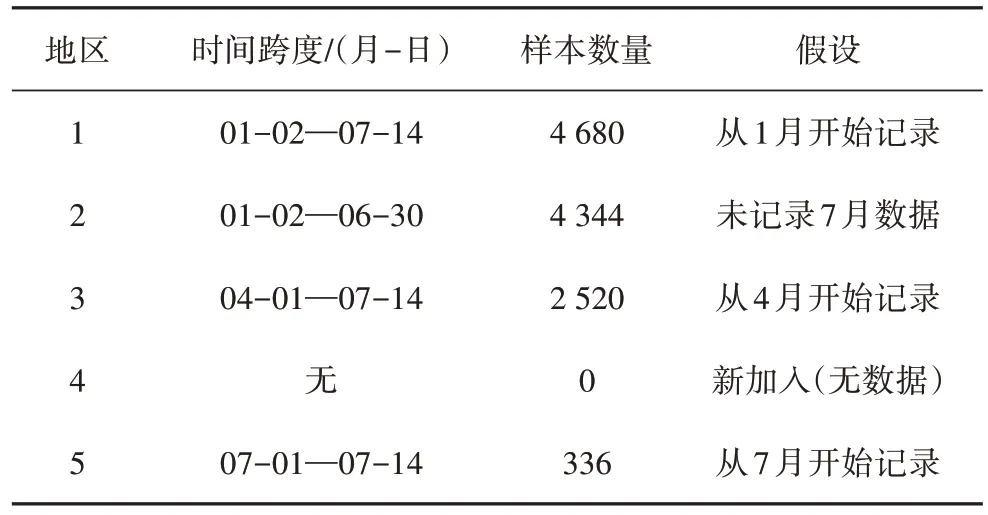
表3 数据集设置Tab.3 Dataset settings
算例1以地区2 的数据进行训练,得到地区2负荷预测模型,并用该模型预测地区2 的负荷,记录预测结果;再以地区1 联合地区2 进行协同训练,用训练出的模型预测地区2 的负荷,记录此时预测结果.算例1 负荷预测结果对比如图9 所示,预测误差对比如表4所示.

表4 算例1预测误差对比Tab.4 Comparison of forecasting errors of example 1

图9 算例1负荷预测结果对比Fig.9 Comparison of load forecast results for example 1
由图9 和表4 可知,采用本文所提方法后,在保证地区1 数据隐私的同时,训练出的模型降低了地区2 因7 月数据缺失造成7 月份负荷预测准确度下降的影响,预测出的负荷曲线更接近实际数据,其误差也大幅降低,RMSE 与MAPE 分别降低了21%和28%.这体现出本文方法有效地丰富了地区5模型训练可利用的样本特征,验证了本文方法在数据量不足情况下对模型预测准确率的提升效果.
算例2以地区5 的数据进行训练,得到地区5 负荷预测模型,并用该模型预测地区5 的负荷,记录预测结果;再以地区3 联合地区5 进行协同训练,用训练出的模型预测地区5 的负荷,记录此时预测结果.结果如表5 所示,预测负荷曲线图如图10 所示.

表5 算例2预测误差对比Tab.5 Comparison of forecasting errors of example 2
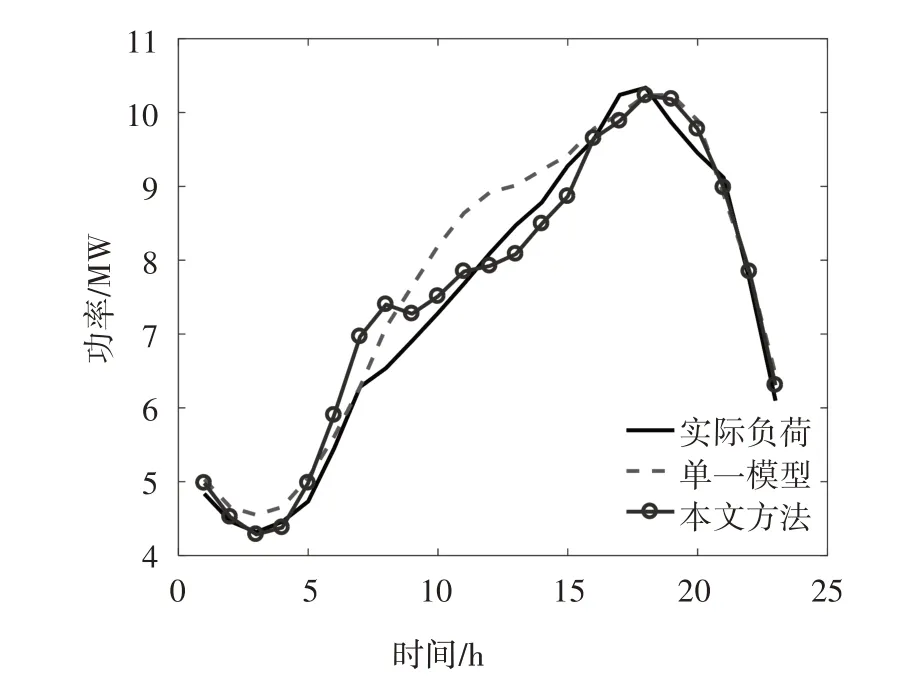
图10 算例2负荷预测结果对比Fig.10 Comparison of load forecast results for example 2
从表5 和图10 可以看出,相较地区5 仅用自身数据训练的模型,采用本文方法训练后的模型预测曲线与真实曲线之间的差距大幅缩小,对应的误差RMSE 和MAPE 分别下降了74%和80%.在本算例中,地区5 自身所拥有的数据极少,仅用该数据训练出的模型预测能力和泛化能力非常弱.由于本文方法对数据量进行了大幅扩充,且补充了更多不同日期的特征,对预测准确率的提升十分显著,使得误差大幅降低.这也符合深度学习在样本不够全面的情况下,当训练样本增加时模型性能也提升的特点.与此同时,在协同训练过程中有效地保证了地区3、5各自的数据隐私.综上所述,本算例说明本文方法能有效提升模型的预测能力.
算例3利用地区1、2、3、5的数据协同训练负荷预测模型,将该模型应用于新加入联邦的地区4 的负荷预测;先量测地区4 预测时刻前24 h 时刻的历史负荷数据以及预测时刻的气象、日期数据,作为联合预测模型的输入,进而预测下一时刻的负荷变化,记录下一日预测结果.预测负荷曲线图如图11 所示,预测误差对比如表6 所示.从图11 和表6 中可以看出,模型在新地区具有良好的预测准确率,相比单一模型,本文方法预测曲线与真实负荷曲线差距较小,RMSE 和MAPE 分别降低了19%和23%.这是因为本文方法训练出的短期负荷预测模型学习了多个地区数据的特征,适应能力更强,具有良好的泛化能力.

表6 算例3预测误差对比Tab.6 Comparison of forecasting errors of example 3

图11 算例3负荷预测结果对比Fig.11 Comparison of load forecast results for example 3
4 结论
本文针对构建负荷预测模型所需数据样本数量与特征不足、模型泛化能力差以及负荷相关数据高度保密无法共享训练的问题,引入联邦学习方法,提出基于联邦学习的短期负荷预测模型协同训练方法,实现各负荷运营商在满足保证数据隐私的前提下协同训练短期负荷预测模型.在GEFCom2012 比赛的多个地区负荷数据集上进行了仿真测试,验证了所提方法对模型预测准确率的提升,证明了通过本文方法训练出的短期负荷预测模型在多场景下具有优秀的泛化能力.在本文基础上,未来可进一步研究配电网多主体协同的去中心化分布式训练机制.
