基于深度学习的木刻版画图像生成方法
2022-09-02郭丽娟任维鑫魏嵬
郭丽娟,任维鑫,魏嵬
(1 延安大学 鲁迅艺术学院,延安716000;2 延安大学 物理与电子信息学院,延安716000;3 西安理工大学计算机科学与工程学院,西安710048)
木刻版画有着悠久的历史与极高的艺术价值,它是一项对审美与雕刻技法有极高要求的艺术创作过程.在近代印刷术兴起之前,它是唯一可藉雕版刷印大量复制的艺术传播形式.在有了近现代印刷之后,木版画以其独特的艺术风格与魅力依然流传于世,甚至逐步发展为一种非物质文化遗产.但是木版画的创作需要专业人士在木板上刻绘出图案,然后配色并拓印获得,整个创作过程需要极高的技术并且极为耗费时间与精力,极大地限制了木版画的创作与传播.随着人工智能的发展,近些年有一部分工作尝试通过人工智能赋能艺术创作,但艺术创作作为一种创造性的劳动,目前的大多方法仍然无法与专业人士的创作水平比拟.以往的许多木版画图像生成方法仅仅是通过构造方法去模仿木版画的纹理,色调等方面,在生成过程中无法人为干预,缺少交互性与创造性的创作过程,如李倩等[1]基于线积分卷积技术,提出一种木刻版画模拟合成算法.李杰等[2]基于木刻版画的刻痕,提出一种自动套刻风格化算法.王雪松等[3]根据绝版套刻版画的真实创作过程,从刻痕建模,模拟刻制和模拟套印颜色来模拟合成绝版套刻版画.李应涛等[4]使用基于神经网络语义分割算法分割内容图像,使用Labelme 工具分割风格图像,然后使用具有空间引导通道的风格转换神经网络进行分区域风格转换.这些方法作为木刻画图像生成的初步探索,虽然取得了不错的效果,但是具有方法较为复杂,表征能力有限,作用范围小等不足.为了推广木版画这一艺术形式与辅助木版画创作,本文进行了以下研究:
(1)收集了一个有数千张木版画图样的数据集,其中包含中外、古今等多尺度人物,风景等多种版画;也包括黑白,彩绘等多种形式的数据;
(2)提出一种基于风格转换的简单但强大的木版画图像生成基线模型,可以根据给出的某种风格的木版画把一幅图片转化为木版画风格的图像;
(3)提出了自然语言文本驱动的木版画风格图像的生成方法,使之不局限于简单的风格转换而缺失了艺术创作中的抽象和再加工过程,以探索更具创造性的艺术作品生成.
1 方法
1.1 总体框架
木版画图像生成任务定义为:给出风格信息Si,辅助内容信息Ci,给定输入图像Ii,将Ii输入转换网络f,获得输出图像Io,使得输出图像Io具备辅助内容信息Ci和Ii联合表达的内容,并且使得Io具备风格信息Si表达的风格.其中风格信息Si为给出的特定风格的木版画图像或描述期望获得的风格的文本,辅助内容信息Ci为描述期望内容的文本.本文提出的方法与以往的木版画图像生成方法相比,首次将文本描述的风格与内容信息刻入,使得在生成过程中创作者可以用语言文本交互式的引导模型生成图像,使得生成图像具备一定的创造性,更加符合艺术创作的理念和需求.
由于难以收集Ii、Io,Si和Ci数据对以进行显式的有监督学习,因此借助预训练模型的表征能力来提供监督信息,具体的,使用预训练的VGG[5]作为图像表征,使用预训练的CLIP[6]作为图像和文本交互的表征,以构造损失并使用梯度下降的方式更新转换网络f的参数.其总体结构如图1所示.

图1 总体结构图Fig.1 General structure diagram
1.2 模型设计
针对本项工作任务,设计了非对称桥式残差U形网络,称其为DBRU network,并把这个模型作为总体结构中的转换网络f.其模型结构如图2所示.

图2 模型结构示意图Fig.2 Diagram of the model structure
本模型主要基于卷积神经网络设计,使用的卷积层和上采样卷积层如图3 所示,本文使用的卷积层如图3(a)示意,由ReflectionPadding 和2维卷积层组合而成,ReflectionPadding 有助于去除边界伪影.上采样卷积层的结构如图3(b)示,特征先使用NearestInterpolate 方法进行N 倍上采样,之后再经过ReflectionPadding和2维卷积层组合.
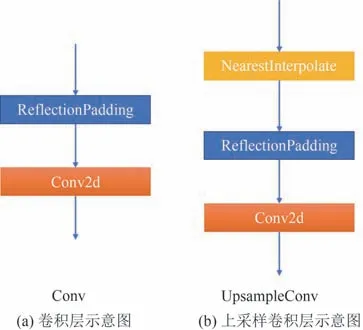
图3 卷积层与上采样卷积层示意图Fig.3 Diagram of the conv and upsampleconv
本模型使用与HE 等人[7]提出的ResBlock 作为特征提取的基本单元,比JOHNSON 等人[8]所使用的线性堆叠卷积层的结构具有更强的表征能力,更快的收敛速度,更不易发生梯度消失或梯度爆炸现象.其结构如图4(a)所示.本文的模型使用了ULYANOV等人[9]的InstanceNorm作为归一化层替换了IOFFE[10]等人的BatchNorm 的归一化方法.另外,DBRU 模型的输入层被设计为类似ResBlock 的组合层,其结构如图4(b)所示.
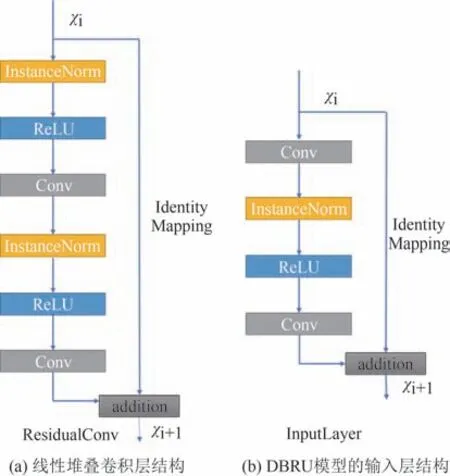
图4 ResBlock与输入层示意图Fig.4 Diagram of the ResBlock and InputLayer
实验表明显式的在模型设计中引入功能模块,可以使得模型学习更容易,收敛更快,学到的知识也更容易迁移,因此,本模型总体架构设计遵循这一原则展开.
与JOHNSON 等人类似,本文模型包含编码器和解码器两部分,如图2 所示,编码器为图2 左半侧部分,解码器为图2 右半侧部分,与之不同的是,本模型使用设计的ResBlock 作为特征提取单元构成U型结构,而JOHNSON 等人使用普通的卷积层组成的线型堆叠结构.ResBlock 提供了比线型堆叠卷积层更强的特征提取能力,而U 型结构更是在下采样与恢复重建的过程中引入了多尺度特征,极大地增强了模型的性能.
所有的Bridge模块和最底部的ResBlock模块在编码器和解码器之间架起桥梁.编码器负责对输入图像Ii在自然图像域逐层提取高维特征,高维特征是对输入图像的高层次抽象表示,解码器负责从高维特征中逐层上采样与重建在特定风格域的图像,最终获得输出图像Io,模型采用U 形结构,使得模型可以在重建输出图像的过程中逐步加入浅层的细节信息,此方法比JOHNSON 等人提出的方法能捕获更多图像细节信息.由于编码器重建过程中需要从自然图像域获取细节特征,为了在获得细节特征的同时不被域相关的特征干扰,本文设计了桥梁模块负责将自然图像域的特征映射到特定风格域,在本模型中,Bridge模块被设计为简单的1×1卷积,实验表明,即使使用这样简单的Bridge 模块依然可以极大的提升模型性能.由于重建任务比特征提取任务更困难,本模型在解码器上设计了更多的ResBlock层以取得更好的解码效果.
1.3 损失函数
对于内容损失和风格损失,延续GATYS等人[11]的方法,即内容损失为:

其中,Ii代表输入图像,Io代表输出图像,φ代表预训练的VGG16 模型,j这里取relu3_3,Cj×Hj×Wj是第j层输出的特征图的尺寸,即φj(x)指图像x 输入到VGG以后的第j层特征图.
当给定一张代表风格的图片Is作为风格信息时,其风格损失为:

其中Gφj(x)指图像x的第j层特征图对应的Gram 矩阵,其计算方法为:
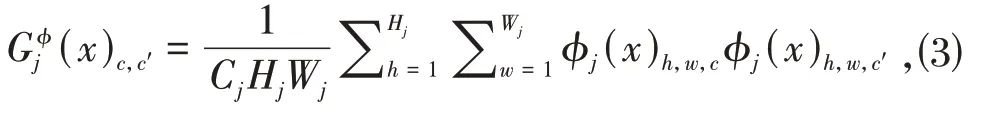
其中φj(x)h,w,c指的是特征图(h,w,c)坐标对应的值.(x)c,c"指的是Gram矩阵中(c,c")坐标对应的值.
除此之外,对于自然语言驱动的图像生成,使用CLIP[6]作为预训练模型,CLIP 本身包含图像编码器EI和文本编码器ET两部分,这两部分可以把图像和文本分别嵌入到512 维的高维空间.基于此设计CLIP Loss,包含以下两部分:
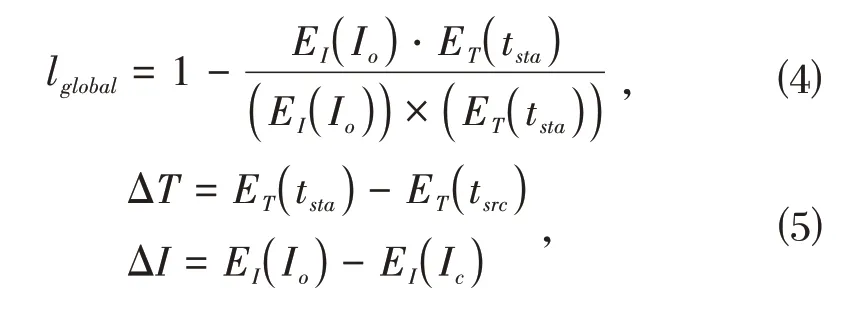
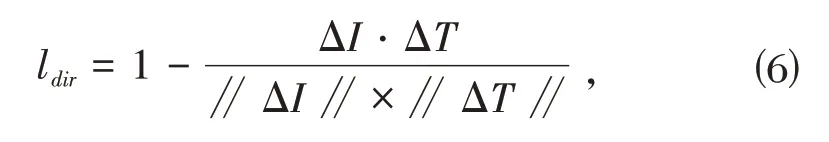
其中,tsrc是对图像的源描述,即描述图像目前情况的自然语言文本,tsta是对图像的目标描述,即描述希望图像转换到的情况的自然语言文本.lglobal是使得输出图像在全局范围内和目标描述保持语义一致的损失函数.ldir是受StyleGAN-NADA[12]启发设计的作用于局部的语言引导图像变化方向的损失函数.综上,CLIP Loss可以表示为:

本文中所有λi均为权重调节系数.
1.4 算法
首先本文的模型可以和JOHNSON 等人[8]的训练方式兼容,即:给定风格图片Is,并给出一个辅助数据集DA,在DA上使用:
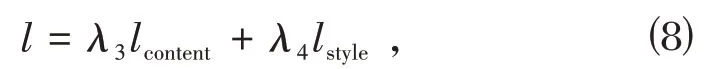
作为损失函数,使用随机梯度下降法优化模型f,从而获得对任意输入图像Ii转换为Is表征的特定风格的模型Fs.

算法1:基于小批量随机梯度下降法的转换网络训练.本实验令k=5,m=4.输入:DA,Ds,随机初始化的转换网络f输出:优化后的转换网络f 1 2 3 4 5 6 7 8 for DA 的迭代次数 do从Ds中采样一张风格图像Is for k步do从DA 迭代m个图像作为小批量输入{I1 i,…,Im i}.将输入图像送入转换网络f进行前向传播计算损失并更新网络f的参数θ.∇θ∑i = 1 m l(Io,Ii)end for end for
其次,将训练对于特定风格图片Isi的转换模型Fsi视为一个任务Taski,则SHEN 等人[13]的元神经网络可以认为对于每个Taski都生成一套模型参数,属于对于特定任务生成特定参数的元学习方法.在元学习中,还有一种流派,以MAML[14]为代表,追求为任务生成良好的初始化参数,并使用较少的迭代次数以获得良好的结果.但有研究表明,元学习能快速适应特定任务的另一原因是良好的特征重用.基于这种启发,本文提出在多个Task 上预训练Meta-Pertrained Model 作为在未知任务Taski上的良好初始化参数,并使用fine-tuning 的方式经过少量迭代以获得模型Fsi.如此,获得了良好的初始化参数与较少的迭代次数的同时避免了设计元神经网络带来的引入更多需要优化的参数量的问题.预训练的算法步骤见算法1.
当获得Meta-Pertrained Model 后,对于任意任务Taski,就可以使用常规的fine-tuning 方式进行训练,此时,辅助数据集DA的数据量甚至可以为一,这显示了本文方法强大的迁移能力.当使用单张图像微调训练时,使用了随机裁剪与随机透视变换的数据增强方法.试验发现随机裁剪的尺寸与模型捕捉风格图像细节的能力相关,使用较小的裁剪尺寸可以获得风格图像中更细节的笔触,而使用更大的裁剪图像会使得模型更关注全局,随机透视变换可以获得不同视角的图像,对效果也有较好的增益.
对于自然语言驱动的图像生成,最显而易见的做法是如GATYS等人[11]的思路,将图像视为可优化的参数集合,即使用转换后的图像Io作为初始化参数,然后优化参数集合,使其与描述文本在预训练的CLIP[6]的嵌入空间里余弦距离最小,但是实验发现这种方式并不能正常工作,于是本文把转换模型f作为优化对象,并与fine-tuning 过程相统一,其算法详细步骤见算法2.

算法2:文本驱动的转换网络微调.本实验令k=500,m=4.输入:Ii,Is,tsrc,tsta,预训练转换网络f输出:微调后的转换网络f 1 2 3 4 5 6 7 8 for k 步do Data=[]for m do对Ii进行数据增强后添加到Data end for使用Data 作为小批量输入图像,对转换网络f 进行前向传播,以获得输出图像批量Io计算损失并更新转换网络f的参数θ.∇θ∑i = 1 m λ5lcontent(Io,Datai) + λ6lstyle(Is,Datai) +λ7 Max i = 1,...,m(lCLIP(Io,Datai,tsrc,tsta))end for
2 实验
2.1 实验环境与实施细节
本文的实验环境:AMD 2700x 处理器,2×8 G 内存,Geforce GTX1080Ti 显卡;深度学习框架为pytorch.
为 了 和JOHNSON 等 人[8]保 持 一 致,本 文 的BDRU 模型也使用了[16,32,64,128]这样一组数值作为下采样阶段各个Block的特征图深度.
本项工作中均使用AdamW 作为优化器,初始学习率均为1e-3,有趣的是,即使在微调的时候,使用与预训练一致的初始学习率并没有破坏模型良好的初始化权重,并且可以获得非常快的收敛速度.
当使用edir时,λ1为2e4,λ2为1e4,当不使用edir时,可以认为,λ1为3e4,λ2为0.λ3为1e5,λ4为1e10.算法2中λ5为1e4,λ6为1e9,λ7为1.
使用的DA来自COCO2017 数据集中的测试集,共40670个图像.
2.2 数据集
虽然先前已经有一些对木版画风格的图像生成的研究,但是他们仅集中在某一流派的风格或者几张图像.众所周知,在人工智能背景下,大量的数据是进行进一步研究的必要条件,然而到目前为止并没有发现面向木版画风格图像生成的数据集,于是,本项工作从互联网上收集了木版画图样,组建了一个木版画风格图像的数据集,其样本量为两千张以上,其内容涵盖中外,古今等多尺度版画;人物,风景等多种内容;黑白,彩绘等多种形式,将其记为Ds,本数据集为进一步开展算法研究提供了保障.其样例如图5所示.

图5 木版画数据集照片示例Fig.5 Example of a woodcut print dataset
2.3 结果及分析
本 文 主 要 对 比 对 象 为fast neural style[15]和CLIPstyler[16],fast neural style 是pytorch 官方实现的JOHNSON 等人[8]的方法,但将其中的BatchNorm 改为了InstanceNorm.
如图6,(a)为内容图像,(b)为风格图像,(c)为fast neural style 以4 为batch size 迭代500 次的结果,(d)为DBRU 模型使用相同超参数迭代500 次的结果,(e)为fast neural style 在整个DA上迭代4个epoch的结果,(f)为DBRU 模型在整 个DA上迭 代4 个epoch 的结果,均随机初始化模型参数.可以看出,本文设计的DBRU模型即使在训练早期也可以很好的保留图像细节,收敛速度更快,而早期fast neural style 图像失真严重.且经过4 个epoch 后,fast neural style 虽然在图像细节上有所进步,但其整体色调偏绿,与风格图像不符,而DBRU在尽可能保留图像内容细节的同时,与风格图像的风格和色调更相近.

图6 结果示例1Fig.6 Example of result 1
如图7 所示,(a)为原图,(b)为CLIPstyler 生成,使用的文本为Traditional Chinese woodcut Print,(c)为使用的风格图像,(d)为DBRU模型使用微调法生成的图像.虽然CLIPstyler 使用自然语言表征风格是一个开创性的方法,但是在实际操作中,往往很难精确的掌控其内容,图7(b)中CLIPstyler 得到的木版画虽然在总体上较为符合风格,但是细节上出现了奇怪的红色和楼阁等暗影,消融试验发现是由字段“Chinese”导致的,这可能是由于CLIP 模型的偏见导致的奇怪现象.

图7 结果示例2Fig.7 Example of result 2
与之相比,本文的方法可以通过收集的木版画数据集里的图片更为精确地控制转换过程,得到更准确的输出图像.更进一步,两种方法甚至可以配合使用,以获得更具创造性的转换图片,这留给未来去探索.虽然fine-tuning 方法已经足够强大,但是艺术创作更希望创作者可以交互式的引导生成过程.如图8所示,(a)为原图,(b)为fine-tuning法获得的转换图像,(c)是在CLIP 损失中不使用ldir的自然语言驱动的图像生成法获得的结果,(d)是使用自然语言驱动的图像生成法获得的结果.使用的tsrc,tsta分别是it is a photo which has a girl 和it is a photo which has a beautiful girl.本文提出的自然语言驱动的图像生成方法为木版画创作者提供了交互式的引导手段,由图8(c)可以看出,在语言引导中只使用lglobal作为CLIP 损失时已经可以很好的指导图像转换过程,但是,如图8(d),当加入ldir损失后,图中人像的脸部更加的明亮有光泽,显现出一个漂亮女孩皮肤白皙有光泽的特点,同时,其眉毛眼睛等部位的线条更加清晰有美感,符合人类对于漂亮的直观感觉.

图8 结果示例3Fig.8 Example of result 3
3 结论
本文以木版画为研究对象,探索了一种简单的木版画图像生成方法,本文的贡献可以概括为:
(1)收集了一个有数千张木版画图样的数据集,其中包含中外,古今等多尺度版画;人物,风景等多种内容;黑白,彩绘等多种形式的数据.填补了这一领域的数据集的空白,为进一步研究基于人工智能的木版画艺术创作提供了数据保障;
(2)提出一种基于风格转换的简单但强大的木版画图像生成基线模型,可以根据给出的某种风格的木版画把一幅图片转化为木版画风格的图像;
(3)提出了自然语言文本驱动的木版画风格图像的生成方法,使之不局限于简单的风格转换而缺失了艺术创作中的抽象和再加工过程,以探索更具创造性的艺术作品生成.
但本文的方法对每个特定的风格和特定的文本仍然需要对模型做几次迭代,未来的研究重点将放在将自然语言文本驱动的图像生成与任意风格实时转换的结合上.
