多种机器学习方法对人脸图像性别识别的适用性研究
2022-08-31王硕珩罗凯鸿赵梓鉴赵航刘雪飞
王硕珩 罗凯鸿 赵梓鉴 赵航 刘雪飞
摘要:针对人脸图像的性别识别领域,从准确率、计算速度、稳定性等多个角度出发,采用无监督学习、半监督学习、有监督学习等多种机器学习方法进行计算识别。将不同机器学习方法的运行结果进行统计整理,分析各个方法的优缺点。通过参数特征的对比,得出不同应用场景下的机器学习方法适用性结论,为实际应用场景提供具有参考价值的机器学习方法选择方案。
关键词:性别识别;机器学习方法;适用性
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2022)18-0064-03
开放科学(资源服务)标识码(OSID):
随着机器学习方法的不断发展,人脸识别技术的水平也在逐渐提高。与其他的生物特征相比较而言,人脸特征更加清晰且易于观察,轮廓与构造的微小差异即可提供较为显著的区分效果。这使得对于人脸特征的识别与分析,在身份验证及日常生活中的人机交互等方面的应用存在巨大的提升空间与潜在价值。在生活中,人们通过自身视觉的判断可以轻易通过人脸来判断其性别,但是让计算机来进行识别判断并不容易。这需要计算机能够对人脸图像进行特征处理及提取,并使用搭建好的模型进行训练。目前,人脸识别技术的应用场景,大多数情况采用人脸图像特征提取存储,在人脸识别时进行相关特征点差异性分析比较。
人脸识别在生活中应用的深度与广度都在持续增加,应用场景的不断扩展使得识别过程对所采取的机器学习方法有了不同的侧重,需要针对不同具体场景的功能需求做出选择。与此同时,性别识别作为人脸识别重要的前置工作,能够大幅降低人脸识别的工作量,节约资源并提高效率。因此,研究不同机器学习方法对人脸性别识别的适用程度,分析得出在不同种类应用场景中,适用度较高的机器学习方法,为人脸识别的后端实现提供相应建议与参考。以人脸图像性别识别为着手点,尝试使用多种机器学习方法,并且对比分析这些方法在此领域的适用性,在学习使用多种机器学习方法的同时,判断在此领域上哪种机器学习方法更具优势。
1 核心技术
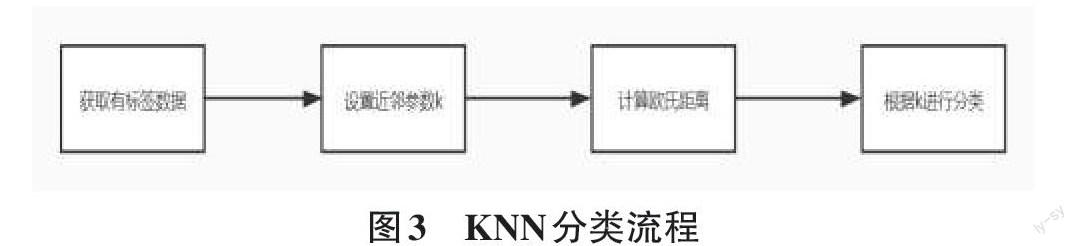
PCA(主成分分析方法)[1];K-Means[2];标签传播算法[3];K最近邻分类算法[4];卷积神经网络[5]。
2 数据集
2.1 数据集信息
数据集分为两类,一类是无性别标签的人脸图像,另一类是已根据性别划分好的有标签人脸图像。其中,无标签数据集掺杂有建筑、动物等非人脸的无效数据,以及侧面照、模糊照等不良数据。
2.2 数据读取
数据集较大,故使用Total Commander文件管理器,将数据集包含数据划分到多个文件夹中,划分文件夹结构见图1。采用多线程方式进行读取,以提高数据读取效率。使用Python的Threading库创建多线程,划分了多少个文件夹即为多少个线程。关键代码截取如下:
path:划分的文件夹所在路径
x:读取划分文件夹编号
"""
threads = []
x = 1
for t in range(0, 5):
t = threading.Thread(target=read_img, args=(path, x))
threads.append(t)
x += 1
2.3 数据预处理
数据集图像均为彩色,像素较高、规模较大,通过图片灰度化操作进行优化。在RGB模型中,当R=G=B时,可表示一种灰度颜色,灰度图像中的每个像素只需要一个字节用于存放灰度值即可。灰度化处理后,图像所占空间从原先存放R、G、B三个轨道信息变为存放灰度值一个轨道的信息,能够大幅减小图像的规模。
数据集中包含个别非人脸的无效图像,通过人工筛选缩略图的方式进行删除处理。
数据集中存在侧面人像、模糊人像、全身人像等,通过人脸裁剪的方式,将人脸以外的部分进行筛选及裁剪,排除图片背景与无用信息,保留面部主要特征。
运用主成分分析技术(PCA),对人脸图像进行降维处理,在保留人脸主要特征的前提下,压缩数据空间,将多元数据的特征在低维空间里直观地表示出来。
最后,将预处理后的数据转存到本地,以便后续使用数据集时节省时间。
3 数据集添加標签
3.1 无监督学习
采用K均值聚类算法。算法将按照数据最明显的特征进行聚类,聚类中心通过参数K进行设置。预处理后的图像,男女人脸特征差异不大,性别特征无法在图片中直观显现。进行灰度化处理后,灰度值特征贡献度超过男女性别特征,使聚类算法按照灰度值划分,最终导致结果不准确,结果为不宜采用K均值聚类算法添加标签。
3.2 半监督学习
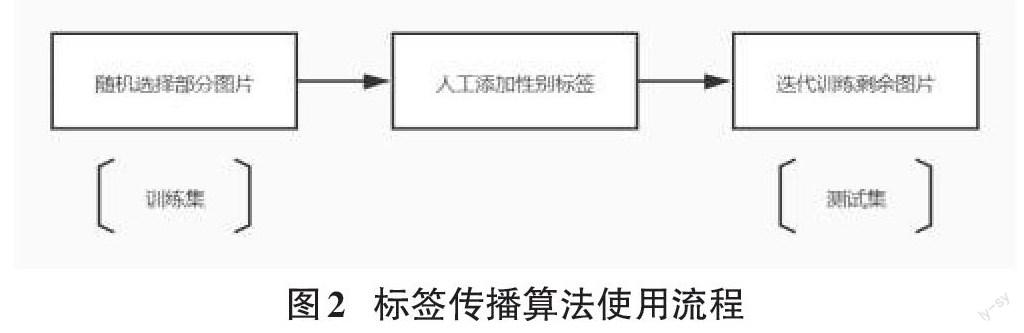
采用标签传播算法。面对数据集中的人脸图像,通过人工识别的方式判断性别,几乎不会出现判断错误。因此,首先随机选择一部分人脸图像,通过人工识别判断性别,为无标签的数据添加标签。随后,以这部分人工添加标签的数据为基础,使用标签传播算法,对模型进行训练,通过迭代的方式为剩余无标签的数据添加性别标签。
4 适用性分析
针对有标签的人脸图像数据,即可进行不同机器学习方法的适用性分析。通过分析结果,便可为实际运用中机器学习方法的选择提供较为准确的参考意见。本项目中,使用KNN算法和CNN两种算法进行适用性分析及比较。
4.1 KNN
如图4所示,K值在1~100的取值范围中,可直观地观察到K值与模型预测准确率的关系变化。首先,将K取值为1作为起点,随着K值取值的逐渐变大,预测准确率整体处于上升的大趋势中。当K值处于1~30的取值区间时,准确率数值处于不稳定的震荡状态,不具备参考价值与实际意义。当K值处于30~60的取值区间时,震荡幅度减小,准确率开始稳定上升。继续增大K的取值,当K值处于60~100的取值区间时,准确率趋于稳定,以较小幅度的波动分布于0.7以上。由上述可知,使用KNN算法时,K值取60以上,可得到稳定准确率高于0.7的预测结果。
4.2 CNN
如图5所示,参数Epoch取值范围设定为0~60,代表准确度的accuracy值随着Epoch的增大而逐渐增加。初始的增长速度较快,当Epoch值超过50时,accuracy的增长速度逐渐降低,趋于平缓。而loss值与lr值都随epoch值增加而减少,有所不同的是,loss值从初始便急剧减少,而lr值下降则是呈阶梯状的。此外,lr的实际数值变化不大,图中的lr数值的坐标轴数量级很小,这样做的原因是为了通过放大图形细节,清晰地观察参数数值的变化规律。在epoch值趋近于60时,loss值与lr值均趋近于0。
4.3 综合比对
综合比对KNN和CNN两种算法,在参数设置为最优时,采用CNN算法的模型,其判断的准确率平均高于KNN算法模型的准确率 10个百分点。然而在运行速度上,KNN算法的计算速度远快于CNN算法。因此,对准确率的需求较高情况下,建议在一定程度上降低运算速度为代价,使用CNN算法建立模型,从而在识别人脸图像性别的过程中获得更佳的效果。
5 结语
近年来,人脸识别随着计算机技术的发展与算法的优化逐渐成熟,并与传统技术相结合,在许多领域初步投入使用,如银行业务办理、人脸身份识别、刷脸支付技术等。与此同时,在多领域应用的反馈,又加快了人脸识别技术的发展与改进。作为一个已经基本明确的发展方向与趋势,大量专业人员涌入,为该技术添砖加瓦,注入活力,呈现出百花齐放的盛况,这为人脸识别技术的飞速发展奠定了基础。而在市场竞争日趋激烈的今天,百家争鸣,意味着在效率和准确率等参数方面的锱铢必较。项目中,笔者仅针对人脸图像性别识别领域,使用了有限的几种机器学习方法进行计算,对比结果具有局限性。
下一步工作,有两个研究方向可供选择。一是扩展识别的功能维度,如通过面部特征识别人脸所属年龄段,又如通过表情特征判断人脸此刻大致的心情状况等。二是扩充对比队列中的机器学习方法。机器学习方法种类繁多,本项目所涉及的仅为极小部分,而每种机器学习方法都有其特征及适用场景。不仅如此,同一种机器学习方法,其本身,也是在人们的不断改进与完善中保持成长的。如项目中使用到的K-means聚类算法,其改进算法之一是K-means++算法,聚类中心的选择由完全随机变为距离其他聚类中心更远的点,有更高的概率被选为新的中心。另一种改进是ISODATA,在算法过程中可根据某个类别的样本数占比和分散程度,自动调整聚类中心的数量。此外还有将样本映射到特征空间再进行聚类的Kernel K-means等。改进后的机器学习方法,其特征及使用场景均值得深入研究和探索。
参考文献:
[1] 陈佩.主成分分析法研究及其在特征提取中的应用[D].西安:陕西师范大学,2014.
[2] 李正兵,罗斌,翟素兰,等.基于关联图划分的K-means算法[J].计算机工程与应用,2013,49(21):141-144,151.
[3] 陶剑文,Fu-Lai CHUNG,王士同,等.稀疏标签传播:一种鲁棒的领域适应学习方法[J].軟件学报,2015,26(5):977-1000.
[4] 张著英,黄玉龙,王翰虎.一个高效的KNN分类算法[J].计算机科学,2008,35(3):170-172.
[5] 周飞燕,金林鹏,董军.卷积神经网络研究综述[J].计算机学报,2017,40(6):1229-1251.
【通联编辑:唐一东】
