基于生成式对抗网络的书法图像修复研究
2022-08-31何仁杰张立辉郭秀娟
何仁杰,张立辉,郭秀娟
(吉林建筑大学,吉林 长春 130118)
图像修复技术是一项依据残缺图像已有的图像特征推测并试图还原残缺处的技术手段,是极具竞争力的革命性技术,其应用领域遍及各类行业。传统的图像修复技术基于图像的纹理、内容的相似性,通过数学与物理理论建模,达到修复的目的。传统图像修复方法在解决大面积图像残缺问题时显得捉襟见肘,这是受限于计算机缺乏图像感知力和图像理解能力,导致修复结果内容缺失。现今,随着计算机科学与通信技术的迅速发展,各类深度学习模型如雨后春笋般出现。Goodfellow等人基于博弈思想与拟合数据分布提出生成式对抗网络(Generative Adversarial Networks,简称GAN)模型,使得图像修复技术有了突破性进展。生成式对抗网络在自然语言和计算机视觉领域中扮演着重要角色。本文基于生成式对抗网络建立双生成器模型在书法图像修复中的应用,阐明基于损失函数的优化可提升图像生成及模型收敛的速度,并对未来GAN的发展与研究方向作出展望。
一、GAN网络模型介绍
Goodfellow提出的GAN网络模型如图1所示,它的最重要的组成部分是生成器与判别器,通过彼此之间的相互博弈,达到模型平衡。它是一种生成式模型,相对于其他生成模型,只用到了反向传播,而不需要复杂的马尔科夫链[1]。

图1 GAN网络模型
式中,E(*)是分布函数期望值,Pdata(x)代表真实样本分布,Pdata(z)是定义在低维的噪声分布,D(x)是生成样本,D(G(z))是生成样本的判别。
(一)双生成器GAN模型
双生成器GAN模型是在经典GAN 网络模型的基础上进一步优化得来的,模型结构如图2所示。利用双生成器能够快速生成图像的特点,能够加快整个模型的收敛速度。

图2 双生成器GAN模型
向生成器G1、G2中输入两张预处理过的残缺图像,通过f(z)的映射关系将生成随机修复分布gi与gj。基于博弈对抗思想,训练生成模型与判别模型,经过多次迭代后,得到生成模型与判别模型最优的修复网络模型[3]。与一般的GAN相比,双生成器GAN网络模型输入的是残缺图像,并不是随机噪声,具有两个生成器,这就提高了图像生成与模型参数寻优的速度,加快了整个模型的收敛,从理论上来说,收敛速度是一般模型的2倍[4]。
(二)判别器损失函数
GAN训练是独自交替迭代的,因此损失函数同样是依次对判别器和生成器进行优化。第一对判别器进行优化,由于每次迭代都是由双生成器产生两个随机修复分布数据,所以判别器的损失函数由gi与gj决定[5],表达式如下:
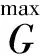
判断结果越接近1越好,因此损失函数为log(D(x)),而z是随机输入的,G(z)代表生成的样本,对于生成的样本,判别器的判断结果D(G(z))越接近0越好,也就是让总数值最大,所以两个生成器的随机修复数据期望分布选取最小值[6]。
(三)生成器损失函数
为了让双生成器生成更好的生成样本,可以让判别网络使两个生成器同概率提高,因此需要输出判别网络最小值,生成器损失函数如下:
陈果夫:《上蒋委员长建议今后党的宣传工作宜重人才培养延揽、启发鼓励书》(1943年5月7日),李云汉主编:《陈果夫先生文集》,(台湾)“国民党中央党史会”1993年版,第27页。
(四)模型的可行性分析
在实验之前,本文采用MNIST手写数据集来验证该模型的可行性。MNIST是28×28 的手写数字数据集,训练集包含60000个示例。这时网络的每次输入是两个随机噪声,主要是验证网络模型寻优参数的速度以及图像生成收敛速度。MNIST手写数据生成图见图3。

图3 MNIST手写数据生成图
在图3中,每张图片是间隔迭代100次的生成图,利用双生成器网络模型,1200步时已经达到了非常好的效果,可行性实验证明该模型的参数寻优速度比一般模型快了近2倍。这是由于每次迭代的两个随机修复分布数据都是取最小值去更新生成器G的参数[7],这使得梯度下降加快,从而加快了寻求全局最优点的速度。验证实验数据如图4所示。

图4 DG模型的损失值
图4是判别器模型与生成器模型在训练过程中的损失值变化数据,横坐标表示训练迭代次数,可以清楚地看到Gloss在训练之处损失值迅速下降,在迭代200次时逐渐平缓。这里的Gloss数值取的是两个生成器损失值的平均值[8],公式如下:
GLoss=average(G1 Loss+G2 Loss)
GAN网络模型就是通过生成器与判别器不断地博弈来更新网络参数,提升网络的性能。最理想的网络模型是生成一张图片,判别器判别结果是50%为真,50%为假,这就是网络模型的纳什平衡状态[9]。验证实验的判别准确率如图5所示。

图5 判别准确率
在实验迭代100次时,判别准确值的波动非常大,可以判定生成器还处于“盲猜”水平,输出迭代100次时的图像非常模糊。当训练继续进行后,500次迭代时基本上处于纳什平衡状态,输出的生成图片相当清晰,与实验思路基本符合。此实验结果表明双生成器GAN网络模型在图像处理方面是可行的。
二、实验
(一)数据集
本文提出对残缺书法图像进行修复的方案,数据集是100个汉字,每个汉字400张, 为不同书法风格,像素值为160×160,总计40000张图片,将其中的一半进行随机高斯掩膜处理,得到残缺图像,如图6所示。

图6 奉、白、常掩膜残缺图示
将图片进行随机掩膜处理,每张图片的残缺位置随机,这样就有效避免了同一位置掩膜导致模型欠拟合的问题。在数据集在被训练之前,为了更加有效地利用数据集,还要进行批量的归一化处理,采用批标准化Batch Normalize(BN)的方法。BN网络拥有加速网络收敛速度、防止“梯度弥散”、可以使用较大的学习率等优点。公式如下:


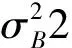
每张图片的残缺位置随机,为了快速定位残缺位置,本文以SSD框架对残缺图像进行精确定位。SSD框架可以被简单地理解为YOLO与快速卷积的优点集合。这种做法可以使模型快速地定位于待修复区域,从而有效地提升模型的性能。
(二)训练过程
生成式对抗网络训练分两步走,当训练其中一种模型时,另一种模型的参数保持不变,这就是确定标准化,可以有效地避免模型在训练过程中不稳定,难以达到理想的结果。以“白”字为例,对其进行随机掩膜处理之后,打乱样本,以输入顺序作为训练集,经过几次迭代,结果如图7所示。

图7 训练损失值
在图7中,上下两条曲线是对于生成器与判别器训练损失的拟合曲线。Gloss代表两个生成器损失值的均值,数值先快速下降,然后发生平缓变化。Dloss代表判别器的损失值,在输出Gloss值时添加负号,为了让其能更好地取到最小值以及画图时与Dloss能够区分开来,Dloss下降一点儿之后便开始平缓变化。随着生成函数的损失值逐渐变小,判别函数损失值变大后逐步调整,输入的残缺图像逐渐得到修复。从图7可以看出,当模型训练迭代200次之后,损失值变化浮动不大,表明模型的稳定性较好。
(三)实验结果
将残缺的书法图片输入网络模型中,将学习率调为0.001,经过1000次迭代,从模型的生成文件中可以看到图像被修复之后的样子。图8为“奉”“白”“常”修复图片。

图8 奉、白、常修复图片
图8中三个汉字的修复效果达到了实验的预期效果,在“白”字的虚化图像中,也有较好的表现,表明该模型在修复书法方面有着很好的实用性。
单生成器与双生成器模型修复图像质量评价数值见表1。

表1 两种模型图像质量评价标准PSNR/SSIM数值
由表1中的数据可以看出,双生成器的GAN模型PSNR/SSIM数值要大于单生成器的GAN模型PSNR/SSIM数值,这说明本文提出的模型在书法修复应用上,修复图像的质量优于单生成器模型。
三、结语
本文提出的生成器模型在残缺书法修复上的应用是具有可行性的,并且达到了实验的预期结果,后续改善网络模型可以从更大的数据集以及损失函数构建着手。更大的数据集可以修复和完善更多的汉字,优化损失函数,更加契合网络快速收敛的特性,服务于古字画研究。笔者希望今后验证在两个G损失函数中选择下降最快的损失更新参数的算法模型。本文提到的快速收敛是相对于其他模型来说的,在生成式对抗网络模型中,收敛问题一直是非常棘手的问题。为了最终收敛,需要添加设置参数去平衡生成器与判别器,这就给模型增加了更多的计算量,这可以通过设计更好的网络模型和一些训练技巧来解决。
