基于分层聚合的通信信息冗余数据检测方法
2022-08-30张玉良王艳兵
张玉良, 王艳兵
(徽商职业学院 电子信息系, 安徽 合肥 231201)
文献[1]设计了一种基于长短期记忆网络-自编码器的流数据异常检测算法。该算法可以保证数据演化的有效性,提高了检测结果的准确性。文献[2]删除了不利于处理的数据记录,选取了依赖于关键词体系的邻近排序算法,优化了算法中的时间复杂度体系,在冗余数据处理效果不佳时计算关键词对应权重,并选择容易计算的灰狼算法作为冗余数据的检测方法。该方法提高了检测结果的准确率、召回率以及F度量值,但是其参数并未得到最大优化。文献[3]基于单机系统计算了海量数据中的冗余体系,在待测数据与指纹映射间进行了二进制的串符设计,并提出了基于计算引擎(Spark)的通信信息海量冗余数据检测方法,该方法局限于Spark体系与海量的冗余数据,对不同数据集中的适应性较差。
为了解决上述问题,基于分层聚合设计了通信信息冗余数据检测方法。分层聚合[4]运用数据的特征量进行时间窗口的感知,通过设计数据流去重过滤器,可以得到冗余数据流检测算法的基本构造,具有检测精度较高的优势,因此,本文利用分层聚合方法以进一步提高通信稳定性。
1 通信信息冗余数据检测方法
1.1 提取通信信息冗余数据样本特征
根据冗余信息位置的不同,将数据的冗余检测分为原端检测与目的端检测,只有被检测数据只含有单一的样本时,数据源中才能避免冗余数据的传输,从而降低检测的传输量,提高检测效率。而信息网络传输过程中,需提前分辨冗余数据的样本特征,避免原端节点占用计算资源,影响网络的传输效率。检测通信信息中的冗余数据,首先提取冗余数据的通用样本特征,在通信网络中由于采集对象的不同,传感器节点会被划分为不同的信道[5],此时传感器的节点结构如图1所示。图中,A~D为通信信道;a~d为通信子信道。

图1 信道对应传感器节点
在图1所示的节点结构中,使用单片机提取不同的数据样本特征,在静态通信网络中,传感器节点中样本提取层中函数的采集概率为

式中:Ei为发送数据所需要的能耗;Ec为传输单位能量的信息所需要的能耗;Tp为传输数据的总时间[8]。
在保证通信冗余的条件下,需要将其进行最小化处理,最小化的通信冗余数据能耗为

式中:Tk为发送最少的通信数据所需要的时间;Pic为采集冗余数据的功率能耗;Pu为传输冗余数据的功率能耗[9-10]。
通过以上公式可以标注冗余数据的作用目标,识别冗余数据中的重复性样本,为冗余数据的识别奠定基础。
汤翠得到小道消息,说是火车站太小,不适应当下城市的发展,得扩大,移出城外,移到南菜这边。这消息太好,汤翠简直不敢相信。如果消息属实,南菜这片儿,搬迁补偿不说,发展的步伐将会更大。汤翠自己先做了分析,结论是消息虽然是从小道来的,可能性还是很大的。北有新市委市政府,西面是生活小区,东面是沙河,火车站真要是移出来,南菜是科学的选择。
1.2 基于分层聚合更新过期未删除数据位置结构
根据分层聚合原理,在第一存储序列的阅读器中设计单元值的初始化函数[11-12]。设过滤器中滑动窗口[13]的哈希函数取值范围为

依据值域式(4)可以在新数据到达以后,判定哈希函数标签的时间信息,如果存在冗余数据的窗口,可以适当更新时间节点的信息,得到如图2所示的位置结构。将不同存储单元分层统计,其中显示为0的部分为不存在冗余数据的存储单元,而TUB表示数据的格式,RID表示数据的位置信息,TIME表示数据的事件信息,上述信息都是存储单元中未删除的冗余数据[14]。

图2 存储单元位置结构
当对象位置变化时,可将其中已更新的监控区域全部设定为存储单元的目标节点,若存在过期未删除的冗余数据,则需要将其全部删除。在建立副本信息时,可以通过拓展系统节点的方式,将指纹查询请求与定向存储过程中的服务器集群全部应用于通信开销中,以保证在线数据的冗余检测精度。通过上述操作,冗余数据在更新了存储单元的位置信息后被直接丢弃。
1.3 设计冗余数据流检测算法
结合过期数据的删除,可以将随时间变化的存储单元信息逐渐变成满值空间,以保证过滤算法中能够拥有足够的空间存储冗余数据流,设计如图3所示的冗余数据检测算法。

图3 冗余数据检测算法
在插入新数据后,需要通过标注位置节点和哈希操作[15]等方式,建立通信信息冗余数据的节点位置判定模型。随机抽取存储单元,将过期数据的位置结构全部更新,并判断节点位置是否为零,此时通过计算存储系统的吞吐率,判断节点位置。存储位置中各节点位置的吞吐率为

式中:Tα、Tβ与Tw分别为数据流在优化前、优化中与优化后需要的导引时间;Tχ为优化提高需要的时间;Ci为数据块的数量;Dκ为存储系统的写入吞吐率。
通过上述算法优化通信信息冗余数据的检测效果。
2 实验研究
为了分析本文提出的基于分层聚合的通信信息冗余数据检测方法的有效性与优越性,测试本文方法对不同数据集中冗余数据的检测性能。
2.1 建立通信信息数据集
采用Windows 10操作系统,收集不同的通信信息建立数据集,其中包括两个公开的数据集与一个实验室服务器自行建立的数据集,将所有数据备份以便随时查询。在上述数据库中,需要经过两个阶段性的检测,以降低网络传输负载与错误率,因此,建立如图4所示的冗余数据检测模型。图中,H1~H4为4个阅读器,在降低网络传输负载时,可通过移动Ta~Th的模拟标签,其中a~h表示标签序号,验证算法性能。

图4 冗余数据检测模型
设置冗余数据检测模型的信息检测参数,将合并基数限制在1 024 MB之内,并制定相应的分段基数。其中布隆过滤器中通常包含64个组,每组的假阳性率均不超过0.001%。建立特征向量的标准数据集,根据特征向量引入{0.4,0.5,0.6}作为均匀分布的噪声,并将每个节点中的数据平均分配到5个异常数据中。根据特征向量的不同,将其分别设置为数据集A、数据集B、数据集C。
在该算法中,哈希函数的数量、过滤器的大小、数据流大小、滑动窗口大小的变化,均会对检测结果造成影响,因此,通过该算法分析不同因素对通信信息冗余数据检测结果的影响。在此过程中,利用假阳性率PFPR与假阴性率PFNR对检测结果进行评价,两个指标的计算公式分别为

式中:mp为过滤器中随机数的单元数据量,p为随机数的单元数量;ε为过滤次数;Cph为过滤器中随机数的存入数据量;mi为过滤器的整体数据量;ti为过滤器中的间隔长短;Gi为一次冗余数据检测中被减少的间隔;aε为被过滤器减少的次数。
2.2 不同参数对冗余数据检测结果的影响
在滑动窗口中,当过滤器的大小为10 000位,数据的总量为100 000时,分别设置哈希函数的数量为1~9,过滤器的大小为1~9,数据元的数量为10~50,滑动窗口的大小为10~50,并以此测试3个数据集的假阳性率与假阴性率,得到如图5和图6所示的参数分析结果。
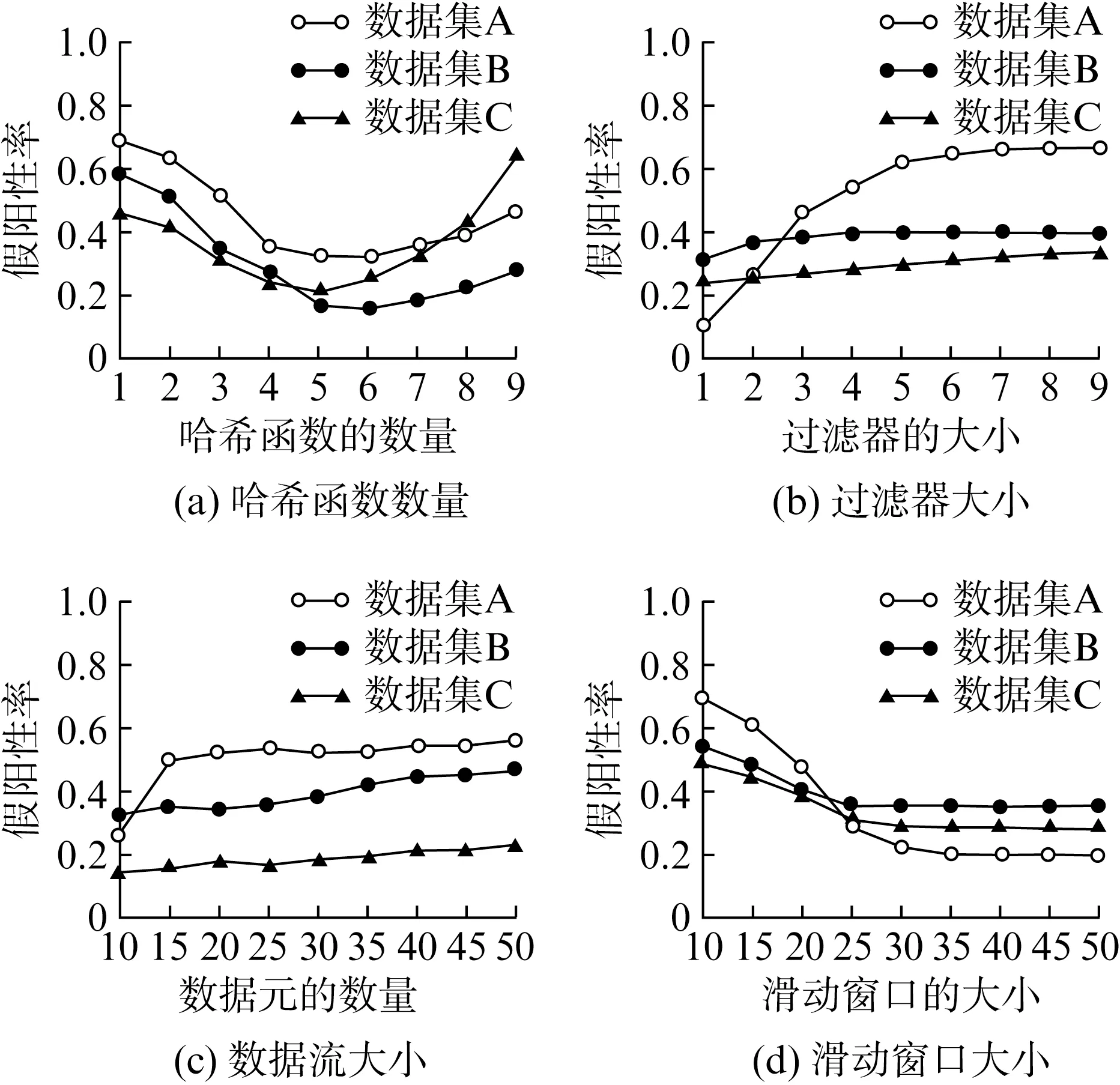
图5 冗余数据检测假阳性率

图6 冗余数据检测假阴性率
由图5、图6可见,当哈希函数为5时,其冗余数据的假阳性率和假阴性率均可以达到实验测试中的最低值;当过滤器大小为1时,其假阳性率为最小值,而在假阴性率的测试中,过滤器的大小对其影响效果不大;当数据流为10时,3个数据集均可以得到最小的假阳性率与假阴性率;当滑动窗口大于30时,假阳性率达到最小值,在假阴性率中,其最小值在滑动窗口为30~40之间。由以上实验结果可知,当哈希函数为5,过滤器大小为1,数据流为10,滑动窗口为35时,可以得到该算法下通信信息冗余数据检测的最优结果。
3 结 语
大规模的数据应用产生了海量的通信数据,为了避免冗余数据对通信稳定性造成的影响,本文设计了一种基于分层聚合的通信信息冗余数据检测方法。该方法可以基于提取的信息特征,实时更新冗余数据的位置节点,并建立一个相关的冗余数据检测算法。在实验中,哈希函数为5,过滤器大小为1,数据流为10,滑动窗口为35时,可以得到通信信息冗余数据检测过程中最优参数的结论。
