一种应用于电力技术专业领域的信息萃取算法
2022-08-30倪吉祥闫欣悦徐大亮
倪吉祥,闫欣悦,徐大亮
(1.国家电网有限公司高级培训中心,北京 100192;2.北京数睿思德技术有限公司,北京 100083)
1 研究背景
信息萃取一直是国内外的研究热点。异构数据的信息萃取是国内外计算机算法研究领域的热点与难点。信息萃取经历过2个阶段的发展历程:信息提取与关键信息萃取。早在20世纪90年代初,科学家和研究者们开始关注信息提取(Information Extraction,IE)相关研究。
随着网页文本信息的急剧增长,越来越多的人投入到IE领域的研究,IE研究人员逐渐将兴趣转移到Web网页信息提取的研究上。其中比较知名的项目是卡耐基梅隆大学自动学习和发现中心的Web挖掘项目,他们采用机器学习算法,目标是通过训练自动从Web中提取信息[1-4]。随着信息技术的发展,信息萃取已经广泛运用于搜索引擎、知识问答、信息检索、知识服务等领域,同时成为知网、Google、百度、知乎、今日头条等知名产品的核心技术竞争力[1-4]。然而,在电力等专业领域的业务中,一方面对知识的需求量是巨大的,另一方面由于数据异构以及专业知识的特点,目前主要使用人工方式进行信息萃取。这需要专家进行人工分析总结,并由具有经验的萃取师进行提炼,存在效率低、时效性差、时间人工成本高等问题。近年来,国内外有关公司与机构积累了大量的研究成果[5-6],联想公司提出了著名的四步复盘方法,进行信息萃取,四步复盘方法具体为回顾目标、评估结果、分析原因、总结规律。美国陆军还曾提出AAR的方法,华为公司亦提出知识收割方法,通过选择项目、单个项目知识收割、组织资产刷新、知识传递等方法步骤进行信息萃取。此外还有PREFS方法和STAR内容模型,均根据培训过程管理的知识数据,进行信息萃取。
针对电力专业领域的实际情况,本文将创新性地结合AI神经网络技术,包括自然语言处理技术、信息检索技术、知识图谱技术等等,提出一种适用于电力专业领域的数据萃取算法,能够更高效地从海量数据中进行信息萃取,主要实现对最新的政策、行业新闻、前沿技术等外部信息,领导讲话、制度文件、内部通知以及其他工作文件等内部信息的高效率、自动化萃取。相比现存技术萃取效率更高、人力需求更低、时效性更好。
2 算法描述与实现方法
2.1 全文数据获取与语言模型建立
本文算法作用为采用人工智能技术从内外部海量数据中完成从数据抓取到异构化处理,最后完成摘要主题关键信息萃取等研究工作,其算法流程如图1所示。

图1 本文算法总流程
对于外部数据源的全文抓取,采用了以下方法实现:①爬虫+订阅的方法,自动化地获取数据的更新;②采用文档智能去重等关键算法保证数据的唯一性;③存储结构化后的文件信息,同时保存必要的文档来源等meta信息。其中爬虫的算法步骤如下。
爬虫算法框架:所有信息源的数据,都通过一个扩展性较好的通用爬虫框架进行爬取。可以自动识别需要爬取的网页链接,每日定时更新。也可以很方便增加数据源。
HTML解析技术:通过一个较为先进的网页HTML解析框架,可以快速定位文章标题、正文、发布时间等一系列信息,剔除无用内容。同时也可以找到网站的头条新闻,区分外部信息的重要程度。
模拟浏览器行为技术:可以自动模拟点击、下拉网页等行为,获取更完整的网站信息。也可以在一定程度上解决网站的反爬措施。
对于内部文件的全文抓取,采用了以下方法实现:①文件自动化解析功能,自动抓取不同文件格式中的有效信息Word/PPT/Excel/PDF(非加密状态);②对于加密状态的文件,采用了OCR技术进行文本内容识别;③存储结构化后的文件信息,同时保存必要的文件来源等meta信息。
2.2 专业领域语言模型建立
本文采用了BERT模型来构建语言模型[5-7],BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
本文最后采用构建专业领域语言模型的全文语料规模为20万条,其中19万条来源于外网(公网)的数据,剩余的来源于内部文件。
2.3 摘要提取算法
摘要提取算法流程如图2所示。

图2 摘要提取算法流程
摘要算法的核心步骤如下。
候选句获取:本文通过一些句法、句式特征获取摘要的候选句。根据的特征有3项:①词性;②句子成分(主谓宾从属结构这种);③一些重点词语。根据这些的排列组合建立了几十条规则,用于获取候选句。
重要性排序算法:通过TextRank算法为候选句构建相关性模型,计算候选句的重要性排序,得到初步摘要。TextRank的思想借鉴于网页排序算法——PageRank,是一种用于文本的基于图的排序算法。通过把文本分割成若干组成单元(句子),构建节点连接图,用句子之间的相似度作为边的权重,通过循环迭代计算句子的TextRank值,最后抽取排名高的句子组合成文本摘要。
二次相关性计算:通过相关性计算方法,得到最终的摘要。
2.4 主题关键词萃取算法
主题关键词提取算法流程如图3所示。
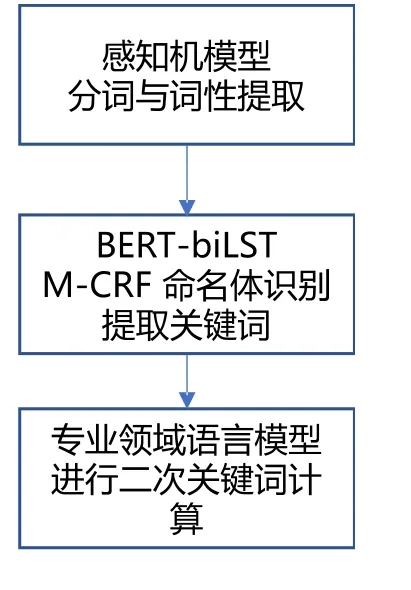
图3 主题关键词提取算法流程
主题关键词萃取算法的步骤如下。
分词与词性分析:通过感知机模型进行分词与词性分析,分词后的结果和词性结果是获取关键词的重要依据。其中,感知机模型可以描述为感知机是一种二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,+1代表正类,-1代表负类。感知机属于判别模型,它的目标是要将输入实例通过分离超平面将正负二类分离。感知机模型可以分为单层与多层,本文采用了3层的感知机模型。
词语重要性分析:通过基于BERT-biLSTM-CRF的命名实体识别神经网络算法,获取候选关键词。命名实体识别指识别中文文本中实体的边界和类别。命名实体识别是文本处理中的基础技术,广泛应用在自然语言处理、推荐系统、知识图谱等领域,比如推荐系统中的基于实体的用户画像、基于实体召回等。本文方法将基于神经网络的BERT-biLSTM以及基于统计的CRF相结合,其中BERT方法在上文中已经进行了描述。CRF(Conditional Random Field,即条件随机场)是自然语言处理的基础模型,广泛应用于中文分词、命名实体识别、词性标注等标注场景。本文将条件随机场CRF与Attention机制(BERT)结合,中文分词、命名实体识别、词性标注效果有了显著提高。通过关键词的实体类别、TF-IDF信息、词性、句子成分分析,得到重要性分数。另外在判断重要性时,也结合了内容分类分类体系,与内容体系相关的关键词会增加一定比例的分数。
采用语言模型对词语上下文进行相关性分析:根据词向量和文章向量,得到词语和文章的相关性,相关性过低的无法成为关键词。
3 实验结果
本文设计人工盲评实验如下。
实验人数:20人。
数据样本:100。
实验过程:将本文算法处理的数据样本与人工处理的数据样本混合,进行盲评。
最后实验结果如表1所示。结果表明,本文算法结果基本上与人工结果相似。本文算法示例如图4所示,从示例中能看出算法自动提取结果能够体现算法的有效性。

表1 实验统计结果

图4 信息萃取示例
4 结论
本文提出一种新的基于AI神经网络技术的信息萃取算法,能够有效针对外部和内部的异构多元数据进行信息萃取,能够快速自动化地萃取全文中的摘要和主题关键词等关键知识信息。人工盲评实验表明了本文算法的有效性,后续我们将继续围绕信息萃取在电力教育培训领域中的知识图谱、方案智能设计等相关数字化应用展开探索性研究。
