语音识别中的DenseNet模型研究
2022-08-29刘想德王芸秋何翔鹏
刘想德,王芸秋,蒋 勤,张 毅,何翔鹏
(1.重庆邮电大学 先进制造工程学院,重庆 400065;2.重庆邮电大学 计算机科学与技术学院,重庆 400065)
0 引 言
传统的语音识别系统可以分为语音信号预处理、特征提取、声学模型、语言模型和解码器5个部分,其中,特征提取和声学模型对语音识别系统的效率有着关键性的影响。随着大数据集的出现以及硬件计算能力的提升,目前声学模型主要包括4种网络:深度神经网络(deep neural network, DNN)、循环神经网络(recurrent neural network, RNN)、长短时记忆网络(long short term memory network, LSTM)和卷积神经网络(convolution neural network, CNN)。第一个成功应用的声学模型是DNN,它利用受限玻尔兹曼机(restricted Boltzmann machine, RBM)进行无监督分层预训练[1-2]。然而,语音信号具有长时相关性,DNN只能看到预先设定长度的数据,因此对于语音识别任务其表达能力有限。在DNN之后,基于RNN的声学模型出现了一种对语音中的长时依赖性进行建模的方法,特别是基于LSTM体系结构[3]的RNN在性能方面得到进一步提升[4],但将RNN用于语音识别中存在长时依赖性的问题。
目前,受图像领域的启发,大量研究人员将CNN应用到了声学模型中,在抗噪声ASR中,这种模型在Aurora-4任务上实现了最佳性能[5]。2015年,文献[6]利用CNN在语音识别中提取出包含MFCC-SDC特征的语谱图,除了使用CNN对输入语音进行简单分类外,还用CNN为特征提取器取得了更好的性能。此外,浅层CNN的代表中值得一提的是混合神经网络(convolution-LSTM-deep neural network, CLDNN)[7],该模型利用CNN优良的特征提取能力,用原始语音波形作为输入提取到比MFCC更好的特征,但由于其采用的卷积层数很少,模型表达能力十分有限。因此,为了加深网络深度,受残差网络(residual network,ResNet)[8]在图像识别中成功应用的启发,深度残差卷积神经网络已经成功应用到了语音识别中,解决了梯度消失问题。由于该网络参数量大,且需要用到大量的训练数据进行训练,通常其训练耗时较长。2014年,Google提出了GoogLeNet网络[9-10],其主要创新就是利用Inception思想解决过拟合以及计算量增大的问题,Inception V3即是在此基础上的改进版本。2017年,文献[11]提出的DenseNet在目标识别基准任务上有了显著的进步,更关键的是它比传统的卷积神经网络需要的参数更少,不仅有效加深了网络层数而且是一种相对紧凑的网络。
本文基于Inception V3非对称卷积思想,提出了一种改进的密集连接卷积神经网络模型,以下简称为IV3-DenseNet模型。该模型利用密集连接块建立不同层之间的连接关系以保存低层特征,并将卷积核的范围扩大后进行整合;借鉴Inception V3的非对称卷积思想,将稠密块模块中的卷积核替换为非对称卷积结构。实验结果表明,在THCHS30数据集上该模型与经典深度残差卷积神经网络模型相比,语音识别率有2.67%的提升,与原始DenseNet相比进一步减少了网络参数量,在保证识别率的情况下,模型训练效率提升了约51%。
1 改进的DenseNet模型
卷积神经网络早在2012年就被应用到了语音识别当中,但始终没有较大的突破。为了减少梯度消失等问题,传统较深层的卷积神经网络使用残差模块构建残差网络[12]来加深卷积神经网络,其输入输出为
Xl=Hl(Xl-1)+Xl-1
(1)
(1)式中:Hl(·)为非线性变换函数;Xl表示l层的输出。残差网络计算效率以及特征提取如图1所示。
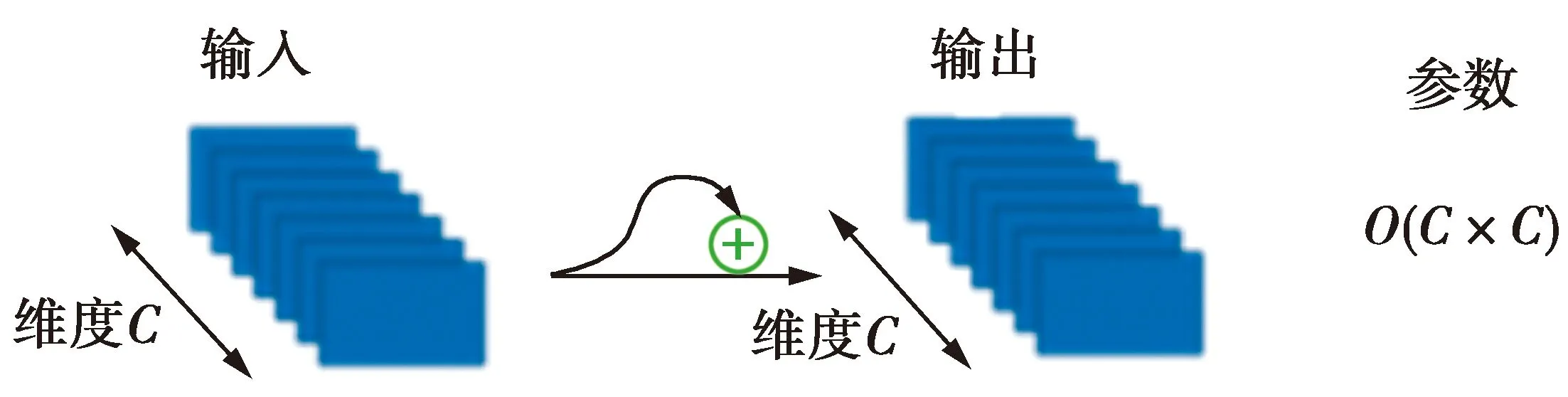
图1 残差网络计算效率
图1可见,残差网络将上一层的输入通过恒等映射直接传输到之后的某层。然而,残差网络在每一层网络中都会生成大量的特征图,导致参数太多,训练更加困难[13];另一方面,由于只将CNN作为特征提取器,卷积层数很少、最终输出只利用了最高层次特征,因此模型的表达能力有限。
在传统的深度卷积神经网络中,模型的最终输出只利用了提取到的最高层次的特征,如图2所示,这种方式也将增加特征参数、降低计算效率。

图2 传统CNN的特征提取
针对上述问题,文献[14]在图像领域提出的DenseNet模型,加强了特征传播,且其参数更少,计算效率更高。
1.1 Inception V3模型
非对称卷积Inception V3将1个二维卷积分解为2个一维卷积核组,其结构关系如图3所示。在3×1卷积之后接1个1×3卷积,相当于与3×3卷积核相同的感受量[14]。
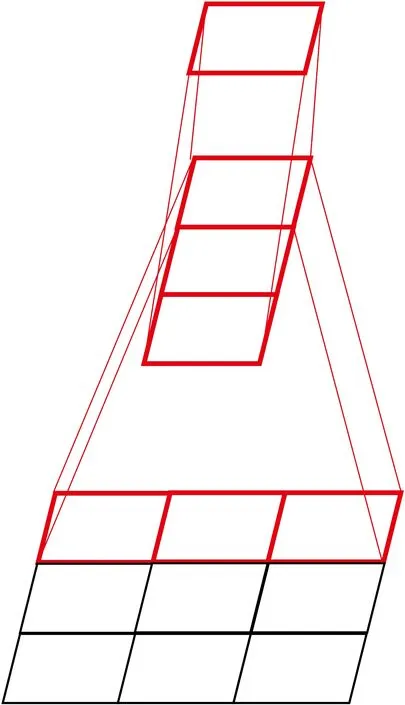
图3 二维卷积核和一维卷积核组
相比DenseNet中利用到的将7×7的卷积核替换为3个3×3的小卷积核可以减少11%的计算量,这种非对称卷积核组可以减少33%的计算量。在填充(padding)相同,每步偏移为1的情况下,5×5的图用1个3×3的卷积核卷积,需要计算5×5×9=225次,而使用3×1和1×3两个卷积核去卷积,则需要计算5×5×3×2=150次。因此,与对称卷积结构相比,非对称卷积核组能够更好地处理特征,增加特征多样性,同时计算量更少。
1.2 DenseNet结构
DenseNet是一种具有密集连接的CNN架构。相比传统的深度卷积神经网络模型,DenseNet通过建立前面所有层与后面层的密集连接实现对特征的重用,即使在更深的结构中也能进行很好的训练。对于L层的网络,在DenseNet中会有L(L+1)/2个连接。第L层的输出关系如下。
xL=HL,G([x0,x1,…,xL-1])
(2)
(2)式中:HL,G(·)是复合函数,即稠密块中卷积层之间的非线性转化函数,是批量处理化(batch normalization, BN)函数、线性激活函数(rectified linear units, ReLU)和Conv的组合;G是增长率(growth rate),对应输出特征图的数量。
由HL,G(·)和特征图串联构成了L层的稠密块模块,如图4所示。
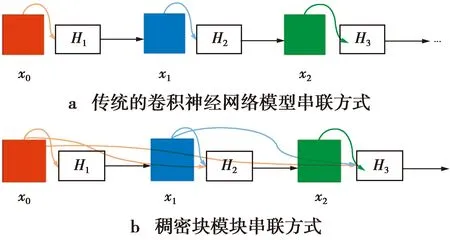
图4 传统CNN与稠密块结构
由图4可见,稠密块模块直接连接不同层的特征,不需要消耗时间逐层复制前面网络层的状态,就可从网络内的任何层访问前面低层特征,更好地保存了低层网络特征,从而实现特征重用提升网络性能。
稠密块模块与过渡层交替串联构成了DenseNet结构,如图5所示。在输入端,传统模型使用了各种人工设计的滤波器组来提取特征且不可避免地使用了帧移,从而造成了信息损失。而DenseNet直接将输入的语音信号转化为语谱图,极大地减少了信息损失。并且,DenseNet由多个稠密块组成,每个稠密块可划分为几个密集连接的卷积层,每层卷积之后均输出G个特征图。

图5 DenseNet结构图
稠密块之间的复合函数一般采用的结构为:BN+ReLU+1×1 Conv+BN+ReLU+3×3Conv。其中,BN+ReLU+1×1 Conv是附加的瓶颈层。在本文中,该层Conv设置为(1,4G),输出固定为4G个特征图。此外,在每个稠密块之间都连接过渡层,由1×1的卷积和2×2的平均池构成,用于降维、减少计算量,从而提升计算效率。
1.3 IV3-DenseNet模型
在传统DenseNet网络中每个稠密块采用相同的多个1×1+3×3卷积核组,本文针对语音识别的特性,在DenseNet网络基础上,将所有3×3卷积核替换为3×1和1×3的非对称卷积结构。在DenseNet中,每个稠密块都使用相同数量的3×3卷积核,因此,很难得到不同尺度的周期性特征[15]。为了提取到语音序列中的长期和短期周期特征,本文将卷积核范围扩大,并将所有长度的周期性特征进行整合,以此获得不同尺度的周期性特征,得到更多抽象特征来提高分类精度。
本文中,每一个稠密块表示为稠密块(L,G),每个密集块采用不同尺度的感受野,即每个稠密块中的卷积层数L不同。上层的稠密块中的感受野相对大一些,可以生成更多特征映射来提取中长期特征。稠密块的卷积层数依次递减,在最下层的稠密块中采用3层3×1和1×3的小卷积核得到更细致的短期特征。在稠密块之间连接过渡层,即用1×1的卷积层减少特征图数量,然后使用平均池降低维度。
本文设计的语音识别IV3-DenseNet网络如表1所示。网络第一层是3×3的卷积,步长为1,其后是不同尺度的密集卷积块,每层都将利用密集连接使得上一层的特征图与本层新生成的特征图合并,每层特征图的数量以增长率G增加。除了最后一个稠密块模块,其他稠密块模块后都连接一个过渡层;过渡层参数代表通道输出缩小的倍数,取值为0到1,本文设置为0.5。网络最后为一个全局平均池化层,将softmax函数作为损失函数。

表1 用于语音识别的IV3-DenseNet网络
2 实 验
2.1 实验准备
本文使用THCHS30清华中文语音数据集进行测试,该数据集在安静的办公环境下录取,采样频率为16 kHz,采样大小为16 bits。表2为数据集的详细说明。
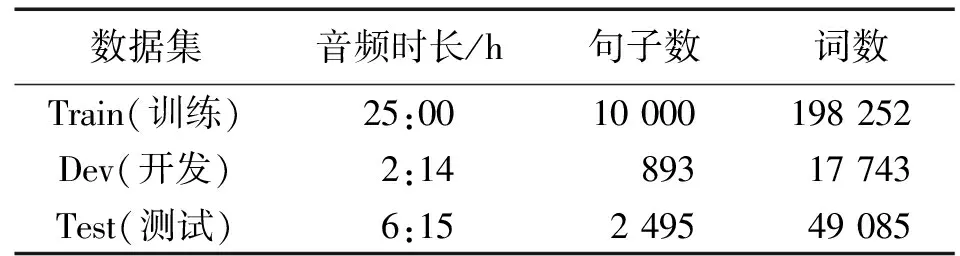
表2 THCHS30数据集
数据集样本量太小,难以获得更好的模型性能。为此,本文对数据集进行了扩展,包括随机裁剪、随机翻转、变灰、添加噪声点[16]等,最终得到约430 h的数据集。实验采用TensorFlow完成所提出的网络模型的构建和训练,实验平台的架构如表3所示。在本文识别过程中,性能指标为字错误率(word error rate, WER),以此检验识别结果的准确性。

表3 实验平台架构
2.2 参数设计
为了验证模型的有效性,本文将模型与文献[17]中的DCNN-CTC模型和原始DenseNet模型作了比较。各模型参数如表4所示。模型1采用了残差网络的结构,其相关参数为:设定帧长为20 ms,帧移为10,帧长不足20 ms的在其后补0,窗函数为汉明窗。模型1进行MFCC特征提取,得到39维语音特征。模型2和模型3(本文模型)均采用了稠密块模块,模型深度均为42,输入均为语谱图,设定帧长为20 ms,帧移为10,窗函数为汉明窗,每一帧的能量谱密度的维度是514,将多帧拼接为1个514×16的语谱图作为输入。本文选择的语言模型均为N-gram模型。
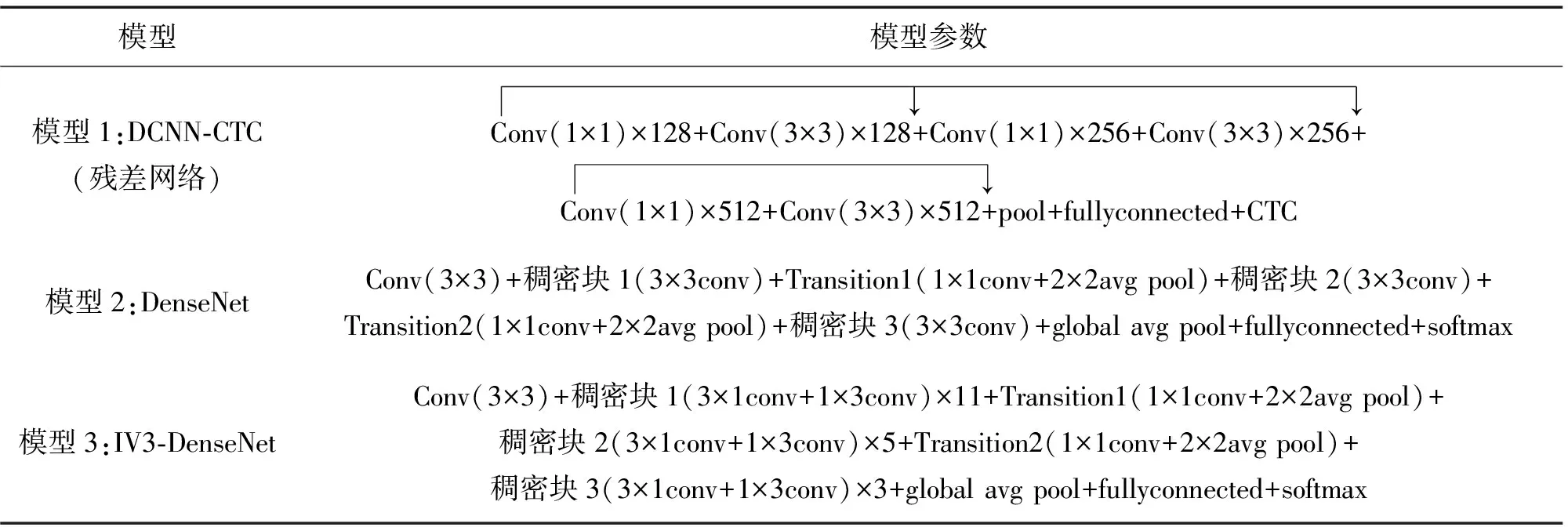
表4 模型参数
2.3 模型训练
本文使用标准的反向传播训练IV3-DenseNet模型,优化器为Adam,学习速率为10-4,批量大小(batch size)为50,使用softmax交叉熵损失函数。模型分两步训练。第一步,在输出层使用softmax函数将输出映射到[0,1]内,表达式为
(3)
(3)式中:zi表示第i个神经元的输入;Si表示第i个神经元的输出;k=1,2,…,i。
第二步,使用交叉熵损失函数来表示实际输出值与真实值之间的误差,表达式为
(4)
3 实验结果分析
为了验证IV3-DenseNet模型的识别精度和性能,本文将3种模型分别在训练集上训练,然后在测试集上测试,记录训练过程中的损失函数值变化以及测试集上的语音识别正确率,以此观察添加了残差结构的CNN、添加了密集块的CNN与本文模型的差别。3种模型对训练集和测试集的识别精度如图6所示。
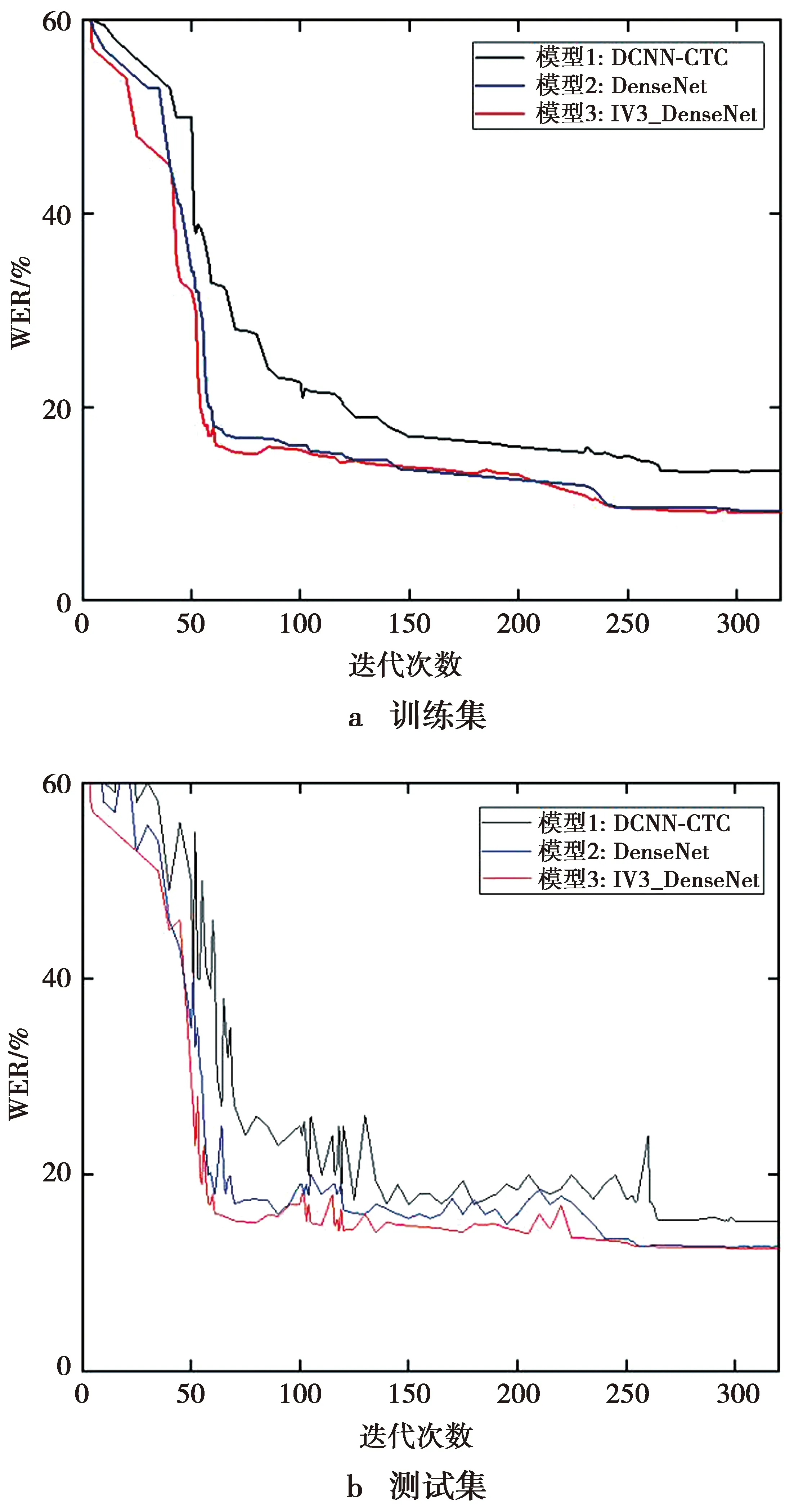
图6 模型词错率对比
由图6可以看出,随着网络迭代次数的增加,WER不断减小并趋于平稳。将模型1与模型3对比,在将残差结构替换为稠密块之后,模型的WER明显降低,且收敛速度明显提升,这表明添加稠密块的卷积神经网络相较于添加残差结构的卷积神经网络更易训练,具有计算量更小、收敛速度更快的优点。另一方面,对比模型2与模型3,收敛时的迭代次数相差不大,但模型3的收敛速度更快且识别率高于模型2,由此可看出非对称卷积结构的优势。
在上述3种模型中,随着迭代次数的增加,模型的损失值趋于稳定,如图7所示。
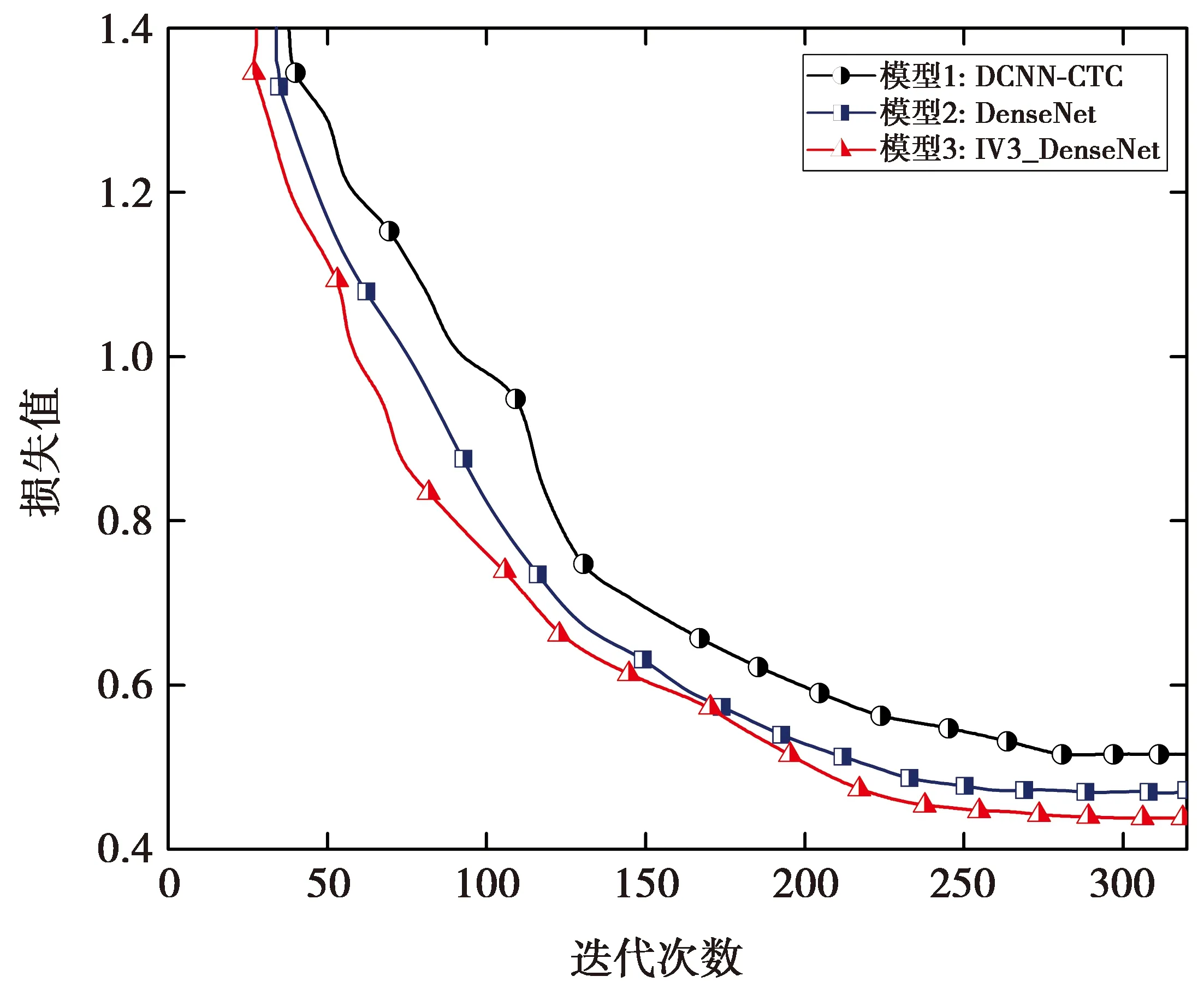
图7 模型损失函数对比
由图7可见,模型1的损失值在迭代次数大约为260时收敛,模型2和本文模型3在迭代次数大约为240时收敛。相较于模型1和模型2,模型3的收敛值更低。表5列出了3种模型的识别率和参数量。
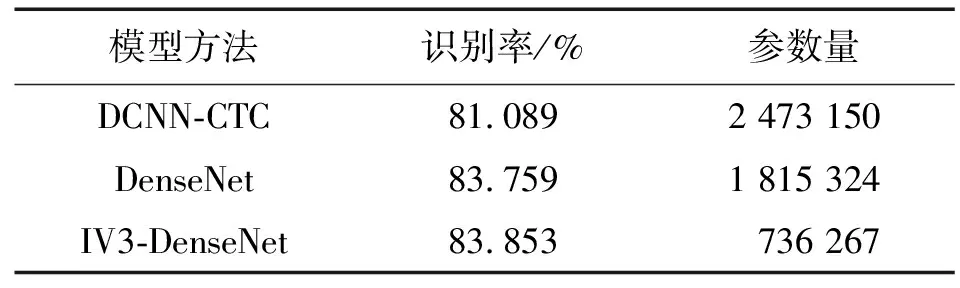
表5 各模型实验参数
由表5可以看出,相较DCNN-CTC模型,IV3-DenseNet模型识别率提升了2.67%。DCNN-CTC模型的参数量,远大于原始DenseNet模型IV3-DenseNet模型,大约为后2种模型的3倍。另一方面,由于利用了Inception V3非对称卷积网络思想,本文提出的IV3-DenseNet模型相较原始DenseNet模型,在保证了识别率的同时,参数量减少了1 079 057。
为进一步验证模型的性能优势,本文设置了第二组实验。每训练完500条数据,用测试集测试4次,取平均值得到此时的识别率。记录3种模型在识别率分别达到30%、60%、80%以及最终收敛时的训练时长。图8为3种模型的训练时长对比。
由图8可以看出,与传统深度残差卷积神经网络相比,加入稠密块模块的网络模型极大地缩短了模型训练时间,且识别率更高。对比模型2和模型3可以看出,模型3在达到相同识别率时所用时间更短。最终收敛时,模型3训练时长约为385 h,模型2训练时长约为788 h。因此,模型3在保证了识别率的情况下,训练效率比原始DenseNet模型提高约51%。由此可以证明,本文IV3-DenseNet模型比原始DenseNet模型的性能更优。
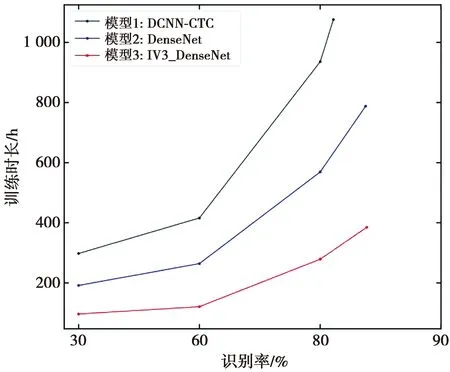
图8 训练时长对比
4 结 论
本文成功地将DenseNet模型应用于语音识别,将原始DenseNet模型的卷积核范围扩大的同时根据Inception V3 的核心思想,利用非对称卷积改进原始DenseNet模型中的稠密块模块,进一步优化原始DenseNet模型,最后对传统的DCNN-CTC模型、原始DenseNet模型以及IV3-DenseNet模型进行训练和测试,探讨其对语音识别性能的影响。
实验结果表明,原始DenseNet网络相较于传统深度残差卷积神经网络识别率更高且参数量明显减少,解决了传统DCNN-CTC模型参数量大、训练困难的问题。IV3-DenseNet模型识别率相较于原始DenseNet模型在保证了识别率的情况下,网络参数量减少、模型训练效率提高,这一性能优势有助于在一些算力较弱的环境中部署语音识别模型。由于提取语音频谱图的过程比起传统语音特征提取过程相对耗时,下一步将在该模型上优化语音特征提取。为了学习到判别度更高的特征,接下来将在模型最后的输出端改进损失函数,探究不同损失函数对模型最终效果的影响。
