两阶段目标类指引的行人检测对抗补丁生成算法
2022-08-29杨弋鋆邵文泽邓海松李海波
杨弋鋆,邵文泽,2,邓海松,葛 琦,李海波
(1.南京邮电大学 通信与信息工程学院,南京 210003;2.南京理工大学 高维信息智能感知与系统教育部重点实验室,南京 210094;3.南京审计大学 统计与数据科学学院,南京 211815)
0 引 言
近年来,深度学习[1-2]成为了机器学习领域最为热门的研究方向之一。深度神经网络(deep neural network, DNN)技术的快速发展,也让图像分类[3]、物体检测[4]、语义分割[5]等计算机视觉技术得到了质的飞跃,智能驾驶、人脸识别[6]等新兴技术也日渐成熟。
然而,对抗样本的出现却为这片欣欣向荣之景蒙上了一层阴影。2013年,Szegedy等[7]首次发现了对抗样本[8]的存在。该团队在测试图片上附加一些经过特殊设计且人眼难以察觉的轻微扰动,并将其输入基于DNN的图像分类系统后,会得到错误的输出结果,而这个错误的输出甚至可以被他们任意指定。随着各方研究者对对抗样本的深入研究,针对其他模型或任务的攻击算法也随后出现[9-12]。各种深度学习模型如DNN模型、强化学习模型、循环神经网络模型等,以及各类任务包括图像分类、场景检测、语义分割等,都无一例外地被量身定制的对抗样本成功攻击。
对抗补丁(adversarial patch)[13]作为对抗样本的一种特殊形式,成为近几年的热门研究对象。对抗补丁是一种占据图像一小部分的贴纸样图案,主要针对的是物体检测系统,只需将该补丁放置在待测物体上,就可以成功欺骗检测器,使其无法对待测物体进行正常识别。如何生成具有强悍攻击能力与迁移能力的对抗补丁,便是当下的主要研究目标。对抗补丁的存在,给不少技术领域带去了潜在的威胁。来自比利时鲁汶大学的研究人员Thys等[14]发现,使用一个简单的打印图案就可以完全禁用行人检测系统。他们以降低检测器输出端的物体存在置信度(object score)和分类概率(class score)作为优化目标,通过反向传播训练生成对抗补丁,成功攻击了基于Yolo-v2模型的行人检测器。不过,Thys团队在对抗补丁生成方法上,依然是最常见的抑制检测得分的思路,他们的实验结果尽管展现出了显著的攻击能力,但实际还有很大的提升空间。本文将对Thys等的工作进行深入研究,分析其存在的问题,找到可行的优化空间。本文提出了一种基于两阶段目标类指引的对抗补丁生成算法,用以提升对抗补丁的攻击能力。新算法由目标类指引阶段和补丁增强阶段组成,本文第3节将对该算法进行详细介绍,并在第4节对新生成的对抗补丁的攻击能力进行详细的实验验证和数据分析。
1 相关工作
1.1 Yolo-v2物体检测模型
Yolo-v2[15]是一个强大的一阶段物体检测模型,它是Yolo系列[16]的第二代作品。当其检测到物体时会产生3个输出:物体边界框、存在置信度和分类概率,这3个数据均是输入样本在单个网络上作前向传递后一步得到,其速度很快,能轻松达到每秒几十帧。常与Yolo相提并论的是候选区域卷积神经网络(region convolutional neural network, RCNN)模型系列,其中Faster-RCNN[17]最为典型。Faster-RCNN的精度更高,但其计算量较大、速度较慢,在高实时场景下仍是Yolo-v2更受青睐。Yolo-v2是完全卷积的,在网络的末端没有全连接层。一个输入图像被传递到网络中后,会在这个网络中被逐层缩小,并以网格的形式呈现于输出端,其分辨率相对于原始输入显著下降。例如,608×608的图像最终以19×19的网格形式呈现于Yovo-v2网络终层。每个网格中包含5个预测点,每个预测点都拥有自己的输出[x,y,w,h,obj,cls1,cls2, …,clsn]。x和y表示物体边界框的中心位置,w和h代表边界框的宽度和高度,obj表示在该边界框内有物体存在的概率,即物体存在置信度,cls1至clsn表示该物体属于各类的概率,即分类概率。Yolo-v2物体检测概图如图1所示。图1a表示图像输入网络后会在多层卷积之后分割成若干网格单元,图1中为7×7的网格;图1b表示每个网格单元中,生成的5个候选的物体边界框,每个边界框都有对应的输出向量信息;图1c表示每个网格单元中的物体属于某一类的概率,如紫色表示判断为自行车,绿色表示判断为狗;图1d则是经过筛选后最终输出的效果图。目前,Yolo-v2仍然应用广泛,它也是计算机视觉领域的热门研究模型。本文中的行人检测器基于Yolo-v2模型,其参数模型由COCO数据集[18]训练而来,共包含80个分类。
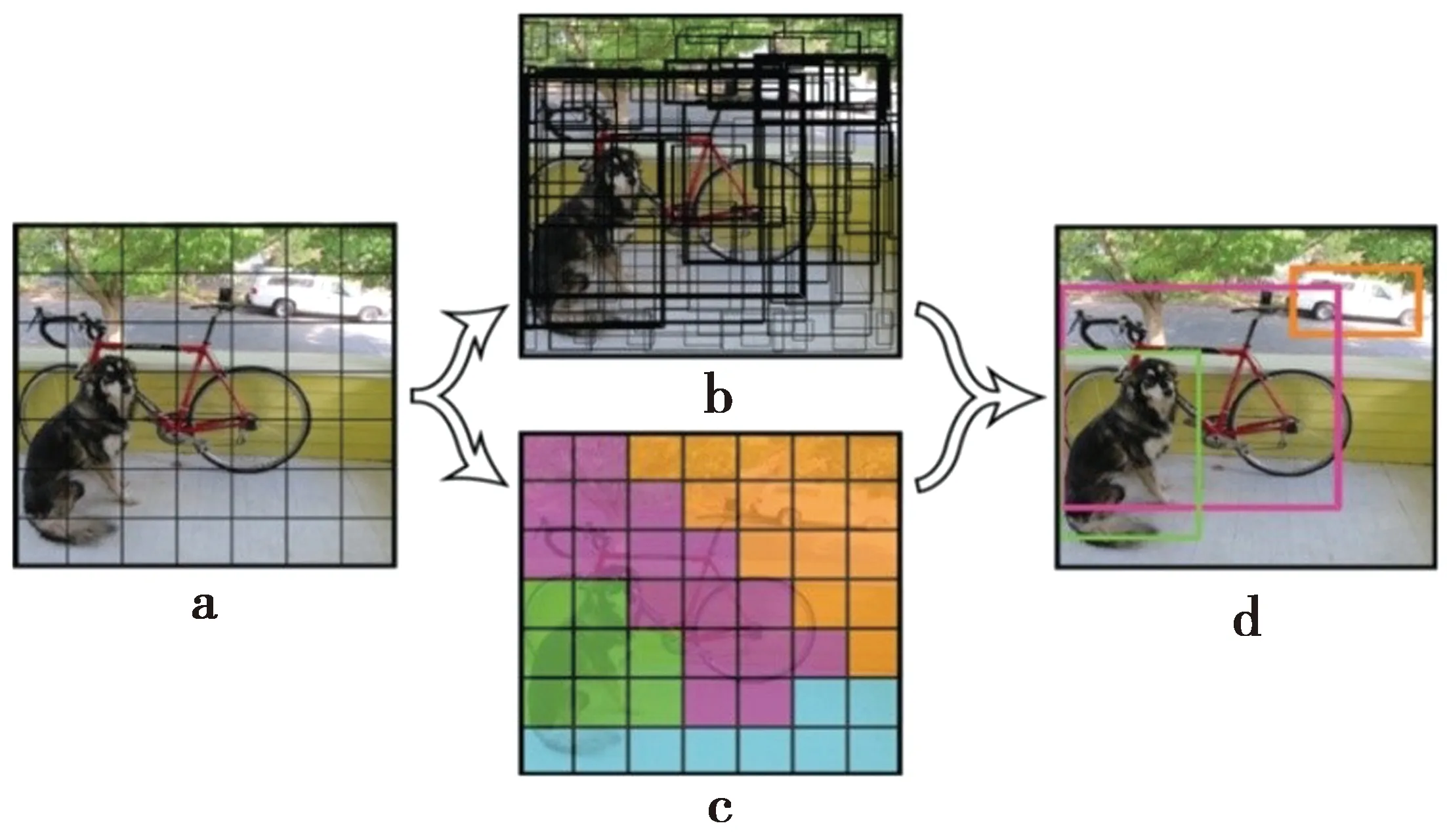
图1 Yolo-v2物体检测概图
1.2 针对物体检测对抗补丁攻击的相关研究
到目前为止,针对物体检测对抗补丁的研究取得了不少突出的成果。Eykholt研究团队[19]通过训练生成了一些不起眼的小贴纸,将它们贴在交通标志上后,智能汽车的检测系统便无法识别这些交通标志了。该团队对Robust Physical Perturbations[20]算法进行了一系列改进,引入了Disappearance Attack Loss算法,生成一系列用于攻击检测系统的小型对抗补丁。这些小补丁可以伪装成涂鸦艺术或类似的东西融入路标图像,使人们很难注意到。Thys等[14]则利用对抗补丁成功地让行人逃避了检测器的检测。他们通过Adam[21]反向传播算法迭代优化损失函数来训练对抗补丁。对于损失函数,其以降低行人检测框中的物体存在置信度和分类概率两个数值作为优化目标,生成的对抗补丁只需放置在行人身上即可对检测器产生有效的攻击。前面介绍的对抗攻击需要将补丁放置在目标物体之上产生部分区域的重叠,而Liu等[22]则展示了一种特殊的对抗补丁攻击,他们所设计的对抗补丁只需放置在图像的一角即可对整张图片的所有物体产生攻击。不过,这种对抗补丁也有局限性,其图案类似于马赛克,对测试图片和补丁图案也有尺寸上的限制,并不适用于真实世界的攻击。Lee等[23]则对文献[22]的工作做了进一步优化,使其生成的对抗补丁成功在真实世界产生了攻击。除了针对特定模型的攻击能力,在不同模型间的迁移能力也是一个重要的研究点。Wu等[24]利用Yolo-v2、Faster-RCNN和SSD这3个模型进行联合训练,成功在R101-FPN、X101-FPN、FCOS、RETINANET-R50等多种骨干模型,以及VOC2007、Inria等多个数据集之间产生较为显著的迁移攻击能力。尽管他们使用的核心思路依然是白盒条件下的以抑制检测得分为损失函数优化目标的反向传播法,但实验结果确实展现出了近似黑盒条件下的攻击能力。
2 本文方法
2.1 抑制检测得分算法
本算法中涉及的基本函数情况如下。
x′=x+tr(p)
(1)
(1)式中:x表示原始输入样本;p表示对抗补丁;tr(p)代表对补丁进行角度偏转、加噪、亮度对比度调节等操作;x′表示被放置了对抗补丁的样本,即对抗样本。
(2)
(2)式中:i代表的是当前批次的第i幅图像,每个批次会选择m幅图片进行训练;Fx′表示样本x′输入检测器后的输出信息,包括边界框、物体存在置信度和分类概率;Jobj[·]函数用于提取物体存在置信度的值,Jobj[Fx′,y]则代表了在输出信息Fx′中提取出被检测为y类(即“person”类)物体的存在置信度;Lobj表示本次迭代参与训练的所有样本的置信度均值,在优化过程中其值越低越好。
(3)
(3)式中:Jcls[·]表示分类概率的提取函数;Jcls[Fx′,y]则表示被检测为y类(即“person”类)的分类概率;Lcls表示本次迭代参与训练的所有样本指向y类的分类概率均值,在优化过程中其值越低越好。(3)式的目的是阻止检测器将行人识别为“person”,其结构与Lobj相似。
为适应真实世界的对抗攻击,Thys团队还引入了(4)—(5)式所示的两个函数。
(4)
(4)式中:Lnps表示不可打印指数(non-printability score);p表示对抗补丁;pi,j表示对抗补丁i行j列像素的色值;C表示打印机的色域;ck是打印机色域中第k个色值。对抗补丁的每个像素会选取距离其最近的ck进行损失计算。这个函数的目的是让数字化的对抗补丁以尽量小的颜色失真被色域有限的打印机打印出来。
(5)
(5)式中:Lpns表示补丁噪声指数(patch noise score)。该损失计算的是对抗补丁相邻像素间的色值差,其目的在于让相邻的像素颜色尽可能接近,使补丁图案更显平滑,让对抗信息显示区块化。
至此,本文建立主损失函数为
Loss=αLnps+βLpns+γLdet
(6)
(6)式中:Ldet是主损失函数的核心部分,当Ldet=Lobj时,表示仅抑制物体存在置信度;当Ldet=Lcls时,表示仅抑制分类概率;而Ldet=LclsLobj则表示同时抑制这两个数值。α,β,γ是3个在训练过程会被手动微调的参数,以寻找3个损失部分的最佳组合比。
2.2 基于两阶段的目标类指引算法
2.2.1 目标类指引阶段
本文对Thys团队用抑制检测得分算法生成的几个对抗补丁进行了攻击实验,实验结果如表1所示,其中IOU为交并比(intersection over union)。

表1 Thys等[14]工作的统计结果
由表1可见,由LclsLobj生成的对抗补丁的攻击能力弱于单独使用Lobj,分析如下。
当损失函数仅引入Lobj时,整个训练过程会非常专一,对抗补丁上的所有信息都集中于对物体存在置信度的攻击。引入Lcls后,训练过程将试图寻找一个最佳的结果,让受攻击的行人在高维空间中的特征偏离“person”的特征域。但是,特征空间毕竟是高维的、复杂的,其特征向量实际可以朝任意方向偏离。尽管训练使用的Inria数据集[23]是行人数据集,但其中的行人有着不同的姿势、朝向、着装以及背景环境,这些繁杂的因素都会影响对抗补丁的收敛,从而使特征向量无法产生统一的指向。这样一来,通过使用LclsLobj生成出的补丁图案中将会包含两个部分的信息,一部分用于攻击物体存在置信度,另一部分则用于攻击分类概率。由于Lcls无法让受攻击目标在特征空间中拥有确定的偏移方向,对于新的输入,这部分的攻击信息往往无法产生实际的攻击效果。因此,在损失函数中使用LclsLobj反而会劣于Lobj。
为了验证上述推断的合理性,并生成更具攻击能力的对抗补丁,引入一个目标类的损失函数Ltar,对原有的损失函数进行优化。其作用是引导受攻击物体在特征空间中的偏移方向。Ltar的结构为
(7)
(7)式中:yt表示目标类(target class);Jcls[Fx′,yt]表示样本x′被识别为yt类的分类概率。与前文表述的损失函数Lcls不同,在优化过程中,Ltar的值应该越大越好。因为Ltar实际表示的是检测器将受攻击行人检测为目标类yt的概率,该目标类可以根据COCO数据集[16]中所包含的类进行任意指定。主损失函数可以表示为
Lossp=αLnps+βLpns+γLp
(8)
(9)
从理论上讲,如果将新的损失函数产生的对抗补丁放置在行人身上,检测器不仅无法检测出行人,还会在同一区域内检测出原先不存在的目标物体,比如“clock”。
2.2.2 补丁增强阶段

Losse=αLnps+βLpns+γLe
L1=Lobj1Lcls1
L2=Lobj2Lcls2
(10)
(10)式中:L1表示针对“person”类的损失函数;Lobj1表示“person”的存在置信度;Lcls1表示“person”的分类概率,其数值越小越好;L2表示针对目标类的损失函数;Lobj2表示目标类的存在置信度;Lcls2表示目标类的分类概率,其数值越大越好。

之所以能够提取目标类物体的检测框信息,是因为该阶段是在前一阶段中已生成的对抗补丁上进行的,被攻击的样本会被检测出之前不存在的目标对象,并生成相应的检测框信息。这也意味着补丁增强不适用于在第一阶段中未能形成成型补丁的类。
2.3 对抗补丁训练过程
对抗补丁训练过程如图2所示。首先,选择初始补丁图案,如果是第一阶段,即目标类指引阶段,则它是一个噪声图案;如果是第二阶段,即补丁增强阶段,则它是对应类的已生成的对抗补丁。其次,借鉴Expectation-of-transform[25]的策略,对补丁进行角度偏转、加噪、亮度对比度调节等操作,并将其置于训练图像中行人边界框的中间位置。再次,将训练图像输入检测器,在输出端提取边界框信息并构建损失函数。如果是第一阶段,则从“person”检测框中提取Lobj和Lcls;如果是第二阶段,则分别提取“person”检测框和“target class”检测框中的Lobj和Lcls信息。最后,使用Adam算法进行反向传播,并更新补丁图案的像素值,经过多次迭代,直到图案收敛不再产生变化为止。
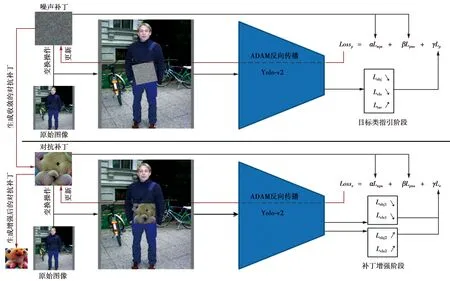
图2 对抗补丁训练过程概图
3 实 验
3.1 实验配置
本文实验使用的训练样本集为Inria数据集[26],测试样本集则为Inria和Cityscapes[27]两个数据集。Inria数据集是一个多环境的行人数据集,Cityscapes数据集是一个大型的行车视角道路场景数据集。实验在Inria数据集中选取148张图片用于实际的测试图片集,其中一共包含了235个行人样本,每个行人样本都将被独立统计,且所有指标的数值都基于该235个行人样本; 从图片总数超过20 000张的Cityscapes数据集中筛选100张包含行人对象的图片,共220个行人样本,用于测试对抗补丁迁移攻击能力。
本实验针对的Yolo-v2模型由COCO数据集训练而来,该数据集共有80个类。对于每一个类指引,生成的对抗补丁不会具有相同的图案和攻击能力,本实验将对所有目标类进行统计分析。
3.2 统计指标
本文设置了6个统计量用于实验结果的统计分析,分别是:无框(no-box)数、异常框(anomalous-box)数、全框(full-box)数、召回率a(recall-a)、召回率b(recall-b)和交并比(IOU)。无框数表示被检测后没能产生边界框的行人样本数量,这里要注意的是没产生边界框的底层原因是其对应的物体存在置信度低于阈值(默认是0.5),实际上其边界框信息仍是可以从模型中提取的。异常框数表示被检测后生成了不合理的边界框的行人样本数量。比如一些边界框只能框出行人一半的身体,还有一些边界框则没有框入行人的头和脚,这些都被视为异常边界框。全框数表示被检测器完全框住的行人样本数,不过这并不意味着这些边界框与真实边界框高度吻合。IOU是物体检测任务中常用的指标,表示预测边界框与真实边界框的交并比。IOU的含义如图3所示。图3中,A表示正确检测框,B表示实际检测框,C则是两个检测框的交合部分,区域C的面积与区域A和B的总面积的比值即为IOU。召回率a是手动计算的召回率,按full-box/235计算,也就是把所有的full-box看作正样本。召回率b是以IOU为判定标准计算的召回率,实验将所有IOU大于0.7的行人包围框判定为正样本,并同样除以235来计算出结果。
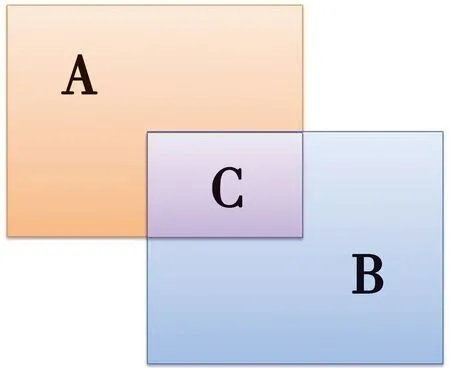
图3 图像交并比(IOU)解释图
本文实验使用Thys等所用的Inria数据集,还添加了噪声补丁作为对照,以证明补丁遮挡不会对检测器产生明显的影响,真正的影响还是来自补丁上的图案。
3.3 目标类指引阶段的实验结果
COCO数据集包含了80个类,实验对除“person”之外的其他79个类全部进行了数据统计。结果表明,并非所有的类指引都能产生满意的结果,只有部分的类指引可以生成更加强大的对抗补丁,大部分类指引的结果劣于LclsLobj的数据;另外还有部分类指引根本无法生成收敛的对抗补丁,但它们依然拥有攻击能力,只是检测器没能根据设计目的检测到对应的目标类,这些未能收敛成形的补丁无法参与后续的补丁增强阶段。表2展示了该实验的部分统计结果。

表2 目标类指引阶段的部分统计结果展示
仅以IOU作为评判指标,在79个类中,有17个类指引生成的对抗补丁优于单独使用Lobj损失函数,7个类指引的结果介于Lobj和LclsLobj之间,15个类指引无法生成收敛成形的补丁,剩下39个类指引的结果则劣于LclsLobj。
该结果证明目标类指引算法可行。目标类指引算法让受攻击行人对象在深度模型中的特征向量向目标类的特征空间偏移。由于特征空间的高维性和复杂性,目标类特征区域太小或是太远,都会导致特征向量无法到达有效的位置。构建该算法的根本目标,是生成更加强大的对抗补丁,因此,对于这79个类,只要有一部分的类指引获得成功,就表明了本算法的可行性。
综上所述,使用目标类指引算法确实可以生成攻击能力更强的对抗补丁。在这之中,由“clock”生成的对抗补丁产生了最低的IOU数值,其值从0.244 8下降至0.098 1,效果明显。图4展示了由目标类指引算法生成的部分对抗补丁图像。

图4 在目标类指引阶段生成的部分对抗补丁图像
3.4 补丁增强阶段的实验结果
本文实验对所有在目标类指引阶段中成功收敛的对抗补丁都进行了增强训练,表3展示了部分统计结果。
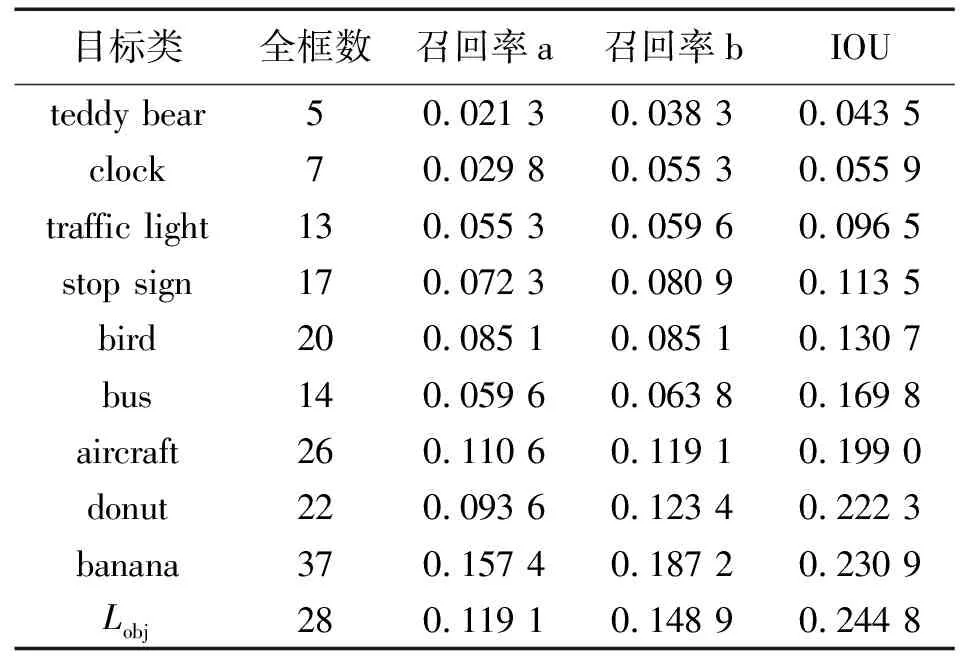
表3 补丁增强后的部分统计结果展示
不难发现,一些新的类在进行增强训练后其攻击能力显著提升,如“teddy bear”;也有类的效果下降,如“banana”。实验表明,补丁增强方法并不是对所有类都有正面效果,许多类在进行补丁增强操作后生成的对抗补丁的攻击能力反而下降了。尽管如此,实验依然有效证明了补丁增强阶段可以使对抗补丁的攻击能力得到进一步提升。该阶段对部分类指引产生了极强的正面效果,如“teddy bear”。由“teddy bear”作为目标指引所生成的对抗补丁,让边界框的IOU从0.098 1更进一步地下降到了0.043 5。图5展示了在补丁增强阶段生成的部分对抗补丁图像。

图5 在补丁增强阶段生成的部分对抗补丁图像
图6展示了部分测试结果。图6中,第一行是使用噪声补丁后的测试结果图,可以看到所有行人对象都被成功检测出来,这证明补丁的遮挡不会明显影响检测器性能;第二行是当损失函数仅抑制Lobj时生成的对抗补丁的测试结果图,可以看到仅有个别行人对象被检测出来;第三行是目标类指引算法的第一阶段以“clock”作为目标类所生成的对抗补丁的测试结果图,行人大都未被检测出来,且补丁图案也被识别为“clock”;第四行展示的是第二阶段以“teddy bear”作为目标类所生成的对抗补丁,在进行补丁增强后得到的部分测试结果图,可以看到所有行人对象都未能被识别出来,而补丁图案则被识别为“teddy bear”。

图6 部分测试结果图
3.5 Cityscapes数据集迁移攻击实验
针对行人检测系统的实际应用最先出现在高度依赖视觉感知的智能驾驶系统中。Cityscapes数据集作为智能驾驶视觉系统最常用的实验数据集,将被用于进一步验证新算法的有效性。
本部分选择表3中攻击效果最佳的8个类进行实验。表4展示了Cityscapes数据集攻击实验的统计结果。实验同样测得了在Cityscapes集上仅使用Lobj损失函数时的IOU,由表4中的Lobj表示。

表4 Cityscapes数据集部分统计结果展示
对比表4与表3可以发现,相较于在Inria数据集上的结果,所有的对抗补丁的攻击能力都有所下降。如Thys团队的补丁,其IOU从Inria数据集的0.244 8上升至0.299 6;攻击能力最强的指向“teddy bear”类的对抗补丁,其IOU也从0.043 5上升至0.113 3。另外,参与实验的8个类指向的对抗补丁在排序上也发生了很大的变化。IOU值最小的,即攻击能力最强的两个对抗补丁依然是“teddy bear”和“clock”。图7展示了9个对抗补丁之间攻击能力的对比。图8展示了部分实验结果图。综合来讲,数据集的迁移攻击会导致各补丁攻击效果产生不同程度的下降,但其总体攻击能力能够被有效保留。
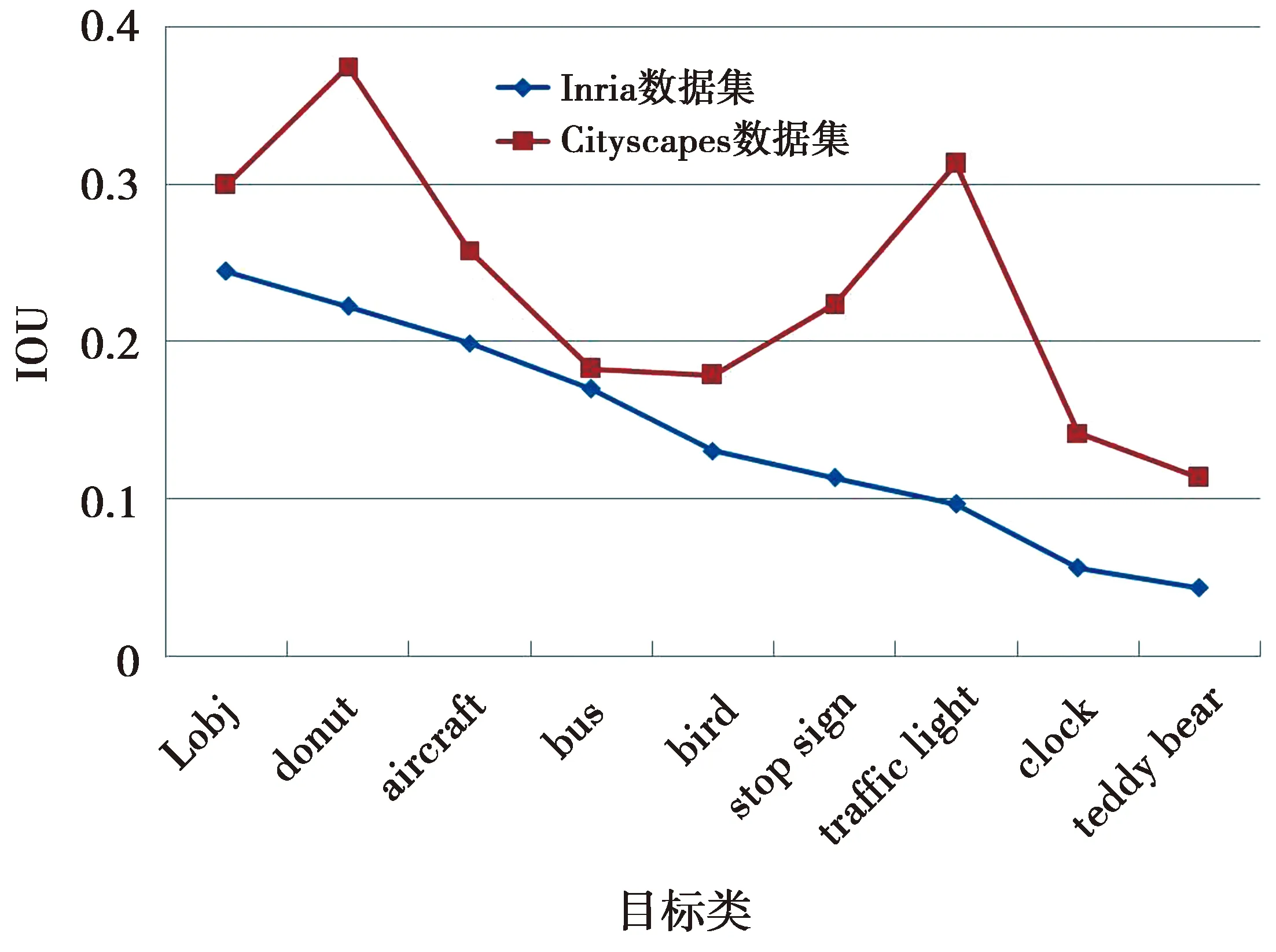
图7 各类指向对抗补丁IOU结果对比

图8 Cityscapes数据集攻击实验部分结果图
3.6 收敛性和复杂度分析
算法生成对抗补丁所采用的训练样本集为Inria数据集,共包含580个样本,算法每使用一次全部样本称为一次迭代(Iteration)。算法的两个阶段在反向传播过程采用的优化算法均是Adam,初始学习率设置为0.008,迭代次数上限设置为2 000次,batchsize设定为8。此外,两个阶段的损失函数Lossp、Losse的参数α、β、γ均设置为0.05、0.1和1。
本节实验选择在目标类指引阶段和补丁增强阶段表现最优的“clock”和“teddy bear”作为分析对象,分别给出补丁攻击能力(以IOU表示)随着迭代次数的变化以及补丁训练过程的实际耗时。图9和图10分别展示了上述对抗补丁在算法两个阶段的迭代训练过程。
由图9可见,“clock”和“teddy bear”的IOU在迭代次数为400至1 000时均快速下降,在1 000次迭代后逐渐收敛,在大约1 300次迭代后达到最佳效果。算法每次迭代大约50 s,目标类指引阶段生成上述对抗补丁大约耗时18 h。

图9 目标类指引阶段对抗补丁攻击能力变化曲线
由图10可见,不管是“clock”还是“teddy bear”,IOU在训练初期快速上升,而后在约100至600次迭代中快速下降,最终在约800次迭代后达到最佳效果。补丁增强阶段使用的初始补丁在第一阶段训练完成,由于损失函数的改变,两阶段的训练过程没有接续性,因此,补丁在第二阶段的训练初期会出现图案“重构”的过程,使补丁攻击能力出现一定的回撤。此外,该阶段算法的每次迭代耗时同样是大约50 s,在补丁增强阶段生成上述对抗补丁大约耗时11 h。

图10 补丁增强阶段对抗补丁攻击能力变化曲线
本文共进行了针对79个目标类的两阶段实验,耗时量巨大。如何在保证对抗补丁攻击能力的同时大幅提升补丁生成效率是值得本文下一步探讨的问题。
4 结 论
本文针对行人检测对抗攻击提出基于两阶段目标类指引的对抗补丁生成算法。该算法首先提出目标类指引的概念,添加新构建的损失函数模块,使生成的对抗补丁能够引导检测器将行人识别为目标类;其次,针对自我抑制的问题进一步优化损失函数,提出补丁增强训练方法,提升对抗补丁攻击能力。实验结果显示,所提算法的两个阶段都大幅提升了对抗补丁的攻击能力。其中,通过补丁增强获得的目标类为“teddy bear”的对抗补丁产生了最佳攻击效果,对应IOU指标为0.043 5,相比Thys团队的0.244 8明显下降。此外,数据集迁移实验显示,对抗补丁在不同数据集上的攻击效果虽有下降,但依然能保证有效的攻击能力。
