融合遗传算法的特定领域情感词库构建
2022-08-29杜茂康李晓光
杜茂康,李晓光,刘 岽
(重庆邮电大学 电子商务与现代物流重点实验室,重庆 400065)
0 引 言
随着互联网的深度发展及应用,社交媒体在过去几年迅速发展,网络用户不断增加,使得社交媒体成为最大的舆论数据来源。在社交媒体网站上发布消息已成为人们最受欢迎的活动之一[1],网络上因而产生了海量的信息,怎样从这些信息中获取到用户所需的内容,快速而精准地满足互联网用户的个性化服务需求是当前的一个研究热点。
文本情感分析是一种提取和评估文本意见的技术,已被广泛用于社交媒体的文本分析中[2-5]。文本情感不仅与主题相关,而且与领域和时间也有联系。一些研究者引入表情符号作为判别情感的依据,并将情感维度与意见强度等结合起来进行情感分类[6-8],将多特征融合和上下文信息用于情感分类和强度识别过程中[9]。在文本情感分析中,情感词库作为关键的资源被广泛使用,如与NB、SVM等算法结合进行情感分析[10-11]。当前已有不少词库被用于情感分析的词库,如英文情感词库General Inquirer(GI)[12]、Bing Liu词库[13]等;中文情感词库,如知网(How Net)[14]、大连理工大学中文情感词汇本体库[15]等。传统的情感词库由语言专家根据经验总结并进行标注得到,需要耗费大量的时间且情感词的数量也有所限制。一些研究收集整理了网络上产生的新词并对这些传统情感词库进行扩展[16]。此外,Fernández-Gavilanes等[17]整理了网络上常用的表情符号,并进行标注以构建表情符号词库用于判断用户的观点、喜好等。尽管这些方法在一定程度上提升了情感词的覆盖率,但由于情感词的情感强度或情感极性会随着领域的不同而有所差异,使得这些情感词库的通用性受到了限制。
目前,很多研究针对特定领域构建情感词库。Hung等[18]使用标记化和消除歧义的方法,构建了面向电影和酒店领域的情感词库,较好解决了原词库中部分单词语义不清的问题。Wu等[19]提取目标词以及情感词作为意见对,并对其极性进行分类。Oliveira等[20]利用StockTwits大型标记数据集创建了股票市场的情感词库。在已有情感词库的基础上,识别出特定领域的情感词,对已有情感词库进行调整并进行扩展,在一定程度上提升了特定领域情感分析的性能[1,21-23]。这些方法都具有很强的领域相关性,但仅仅给出了情感词的极性而没有具体的情感分值。
由于领域的异质性,不少情感词往往具有专业性的特点,词汇的情感取向因内容领域的不同而存在很大差异,如“韭菜”在股市领域表达的是负向情感,而在其他领域往往与情感无关。目前,通用情感词库不能完全满足特定领域情感分析的需求,现有研究构建的特定领域情感词库存在以下问题:耗费大量时间、依赖于现有情感词库、方法适应性较差、不能很好地移植到其他领域。为解决上述不足,本文利用遗传算法构建适应于特定领域的情感词库,对情感词的分值根据情感词库对文本分类的准确率自适应调整,有效提高了该领域文本情感分类的准确率。本文构建情感词库的方法主要具有以下优势:①耗时短;②情感词分值可以根据领域的不同而自适应调整;③方法可以很好地应用到其他领域;④词库的构建不依赖于现有情感词库。选取特定领域微博及Twitter评论文本作为语料,构建特定领域的情感词库,相较于现有词库,在情感分析上优势明显,证明了本文方法的有效性。
1 基于遗传算法的情感词库构建框架
与传统的情感词库构建方式不同,本文借助机器学习思想来构建针对特定领域的文本词库,构建情感词库的框架如图1所示。

图1 基于遗传算法的情感词库构建框架
以微博文本为例,主要工作步骤如下。
步骤1利用网络爬虫技术从新浪微博获取关于评论的微博文本。将文本进行必要的清洗和规整之后,对微博文本进行情感趋向的人工标注。形成由若干短文本构成的关于评论的情感语料库。在爬取微博文本过程中,按照关键词进行筛选,以得到特定领域的文本数据。
步骤2将这些文本中出现的超过一定频率的词均视为情感词,并随机为这些情感词指定初始的情感值,形成初始的情感词库。
步骤3以情感词库对文本分类的准确率为目标,采用遗传算法对情感分值进行调整。
1)计算文本的极性。对语料库中的文本逐一进行扫描,根据情感词库,提取文本中的情感词和情感值。将文本中所有情感词的情感值进行累加得到该文本的情感极性,对应的计算式为
(1)
(1)式中:P为文本的整体情感值,若P大于0,则为正向文本,反之则为负向文本;n为文本中包含的情感词总数;Vw为第w个情感词的情感值。例如股市评论文本为“欧美股市下跌,A股或会低开”,包含情感词“下跌”和“低开”,对应的情感值为-7和-3,则该文本的情感分值为-7-3=-10,表明该文本的情感极性是负向的。
2)确定情感分类的准确率。将计算出的语料库中所有文本的情感极性与人工标注的极性进行比较,计算情感词库对文本进行情感分类的准确率。对应的计算公式为
(2)
(2)式中:C为预测分类与人工标注分类一致的文本数;N为数据集中文本的总数。
3)确定反馈调整的策略。尽管情感分类的准确率与情感词库中的情感词和情感词的取值密切相关,但是却难以建立它们之间的解析关系式。因此,难以使用机器学习中的一些常用的反馈方式,比如梯度下降法。为此,从计算简便的角度,采取随机调整情感值的策略。同时,为了保证调整的有效性,采用启发式算法对情感分值进行优化,本文中用到的启发式算法为遗传算法。
步骤4以情感分类的准确率作为优化目标。通过随机的方式,尝试调整词库中情感词的情感值,并以是否增加分类的准确率作为调整方案是否可行的判定。通过反复尝试调整情感词的值,逐步实现情感词分值调整过程。
2 情感词库构建算法
在基于遗传算法的情感词库构建框架中,目的是找到一个情感词库能够使得文本分类的准确率最大。由于优化算法采取的是先尝试性修改,然后再判定是否进行更新的模式,这种模式希望优化算法具备高效的随机搜索能力。遗传算法正好具备该能力,所以本文选用该算法作为基础,并作适当的改进,实现情感词库的构建。
在本文算法中,将一个情感词库对应为种群中的一个个体。将个体的适应度值与词库情感分类的准确率相关联,适应度值高的个体所对应的情感分类的准确率越高。利用遗传算法强大的优化功能,个体的适应度值不断提高,保证了所构建的情感词库向着提高分类准确率的方向不断更新,直至产生最终的情感词库。
2.1 编码规则与种群的初始化
将情感词库编码为一个个体,情感词库中的每个情感词均被映射为个体中唯一的基因,即一个基因表示一个情感词。初始时,采取随机方式为个体中的基因随机赋予-10到10之间整数值。正值表示正向的情感趋向,负值则表示负向的情感趋向,10和-10分别代表了最高的正向和负向情感倾向。按照上述编码规则,初始化种群。种群中初始化的个体示例如表1所示。

表1 种群初始化
2.2 适应度值计算
适应度值大小反映了词库情感分类准确率的高低。此处,词库对文本的情感分类按照(1)式进行计算,若对文本分类正确,则词库对应个体的适应度值加1,若分类错误,则适应度值减去一个惩罚值。为此,当利用个体k对训练集D中的第i条文本Ti进行预测时,定义此时产生的预测准确率度量值R(k,D,Ti)表示为
(3)
(3)式中,ω为惩罚参数。根据(3)式定义个体k在数据集D中的适应度表示为
(4)
2.3 保优与交叉策略
保优策略的目的是在遗传过程中尽可能地保留种群中优秀的个体或个体的基因。一般有2种常用的方式:①让种群中较优的个体作为精英集直接进入下一代;②选择部分较优的个体作为精英集,并让精英集中的个体与非精英个体进行交叉变异操作产生新的个体[24]。第1种方式能防止精英个体的基因在交叉变异操作中遭到破坏,但是没有充分利用精英个体的基因;第2种方式充分利用了精英个体,但却有可能破坏了精英个体的基因。因此,本文将2种方式进行结合,设计的保优与变异策略示意图如图2所示。

图2 保优策略
在产生子代个体时,将子代个体分为2部分:①从父代中挑选出的精英个体,未进行任何操作直接加入子代中,从而保留了精英个体的整体性;②采用轮盘赌的方式选择父代个体,通过交叉产生。在这部分子代个体中,则很大概率地利用了精英个体的基因。
交叉过程具体为:采用轮盘赌的方式,从父代中选取个体p1,p2;根据交叉概率pc对p1,p2进行交叉操作,即将p1,p2上相同位置的基因值进行交换得到子代个体c1,c2。此处,交叉的位置随机产生,交叉的基因个数由交叉概率进行控制。
2.4 变异策略
文本的情感极性与情感词极性之间有密切的联系,在微博、博客等文本中,情感的表达方式是使用情感词,通过对文本中情感词的使用情况,就可以判断该文本所表达的情感[25]。若某个情感词以高概率出现在正向文本中,则该情感词为正向情感词的概率也很高。反之,则高概率为负向情感词。在遗传算法中,变异操作通常是随机改变个体中某个或多个基因的值。为了更好引导种群的进化,此处将文本情感极性与情感词极性的联系考虑到了变异策略中。基于SIGMOD函数,设计了新的变异策略。
对SIGMOD函数
(5)
求其反函数,可得
(6)
由于本文情感词分值的取值为[-10,10],并设情感词w在数据集D中的正向文本中出现的概率为Pw,基于(6)式构建的基因变异导向函数为
(7)
其对应的函数曲线如图3所示。

图3 导向函数f(Pw)
从图3可以看出,函数值为[-10,10],当Pw∈(0.4,0.6),函数f(Pw)的值在0附近,且变化幅度不大,即当情感词出现在正向文本和负向文本中的比例差不多时,函数f(Pw)对变异过程的引导作用就很小;当Pw∈[0,0.2],即当情感词80%以上都出现在负向文本中,函数f(Pw)极大可能引导情感词的极性为负向极性;同理,当Pw∈[0.8,1],即当情感词80%以上都出现在正向文本中,函数f(Pw)极大可能引导情感词的极性为正向极性;当Pw∈(0.2,0.4)或Pw∈(0.6,0.8),函数对变异过程的引导作用相对较小。
结合函数f(Pw)提出新的变异策略,公式表示为
Vw=R+f(Pw)
(8)
(8)式中:R是一个在[-10,10]的随机数;Vw为变异后情感词的情感分值,Vw的值若超出[-10,10],则相应地取边界值10或-10。
2.5 算法描述
步骤1对数据集进行整理并抽取出情感词。
步骤2根据2.1节的编码规则完成种群的初始化。
步骤3根据2.2节的方法计算每个个体的适应度值,并根据2.3节的保优策略产生部分子代个体。
步骤4采用轮盘赌的策略从父代种群中挑选出2条父染色体p1,p2,并根据2.3节的交叉策略产生新的子代个体c1,c2。
步骤5针对交叉产生的新子代个体c1,c2,对其进行变异操作。利用变异概率Pm控制个体中变异基因的总数,变异基因的位置是随机产生的。
步骤6重复步骤4和步骤5,直到子代种群个体的数量和父代种群一样,完成父代种群与子代种群的更替。
步骤7重复步骤3—步骤6,直到种群收敛。
3 实验与分析
3.1 实验准备
3.1.1 数据获取
1)NLPCC2018数据集。中国计算机学会中文信息技术专业委员会学术年会(conference on natural language processing and Chinese computing,NLPCC)2018年发布的关于微博文本情感分析的通用数据集NLPCC2018(1)http://tcci.ccf.org.cn/nlpcc.php,该数据集包含正向文本1 049条,负向文本851条,总计1 900条文本。
2)股市评论数据集。以“上证指数”“上证综指”“股市”“A股”等作为关键词进行搜索,利用“八爪鱼采集器”从新浪微博进行文本采集得到。总计314 827条微博数据。
由于获取的微博数据中掺杂了重复或无效的文本,需要对获取的微博文本进行清洗。清洗规则是把无个人对股市观点的微博文本进行剔除。通常需要清洗3种类型的微博文本,如表2所示。

表2 待清洗的文本示例
对数据集进行清洗之后,对数据集中的微博文本进行人工标注,用“1”表示积极的情感倾向,“0”表示消极的情感倾向,最后形成的股市微博文本数据集,包括正向文本1 783条、消极文本2 287条,共计4 070条文本。
3)HCR数据集。HCR(healthcare reform dataset)数据集是关于医疗领域的英文情感分析数据集。该数据集包含1 286条tweets,其中,正向文本369条,负向文本917条。
3.1.2 文本分词
由于文本情感分析的最小单元是词语,而中文文本不像英文文本那样天然地用空格将单词进行了划分,需要利用分词工具对中文文本进行分词处理。在本研究中,采用jieba分词包对文本进行分词处理,在分词过程中,一些特定领域的专有词汇,如“垃圾股”“翻绿”等,jieba分词语料库中并没有包含,故将这部分词汇进行人工总结并建立相应的词典添加至jieba分词包中,以有效地发现新的情感词,保证模型的强健性和时效性。
3.1.3 参数设定
实验代码采用Python语言编写,在PyCharm环境中运行。设置种群数为2 000,交叉概率Pc为0.8,变异概率Pm为0.10,惩罚因子ω为60,保优概率Pe为0.1。实验将数据集80%作为训练集,20%作为测试集。
3.2 实验结果与分析
3.2.1 通用领域的词库性能测试
首先,本文方法构建的词库具有一定的通用性。为了验证其在通用领域的有效性,在NLPCC2018数据集上进行测试。利用本文构建的情感词库、大连理工大学中文情感词汇本体库、清华大学情感词库[16]、台湾大学情感词库[26]以及BosonNLP词库(2)https://bosonnlp.com/dev/resource在该数据集进行了情感分析对比。采用准确率和F1-Measure作为评价指标,所得结果如表3所示。
从表3可以看出,基于本文词库进行情感分类的准确率为79.53%,F1-Measure为78.83%,优于其他常用的通用情感词库。这说明本文方法虽然是针对特定领域构建情感词库,但所构建的情感词库仍然具有良好的通用性,能够很好地满足情感分析的需求,为短文本的情感分析奠定了良好的基础。

表3 NPCC2018数据集准确率及与F1-Measure对比
3.2.2 特定领域词库性能测试
1)股市领域。基于3.1节中构建的股市微博文本数据集,利用本文算法产生关于股市的情感词库。受文章篇幅所限,随机选取该库中的30个情感词,如表4所示。从表4可以看出,由本文算法得到的情感词可分为3类:①股市特殊情感词,如表4中的“跌停”“牛市”“翻绿”等词;②通用情感词,如“看好”“繁荣”“较差”等;③无实际作用的情感的噪声词,如表4中的“觉得”“调整”等词,对这部分词可以考虑从情感词库中删除,从而精炼词库。
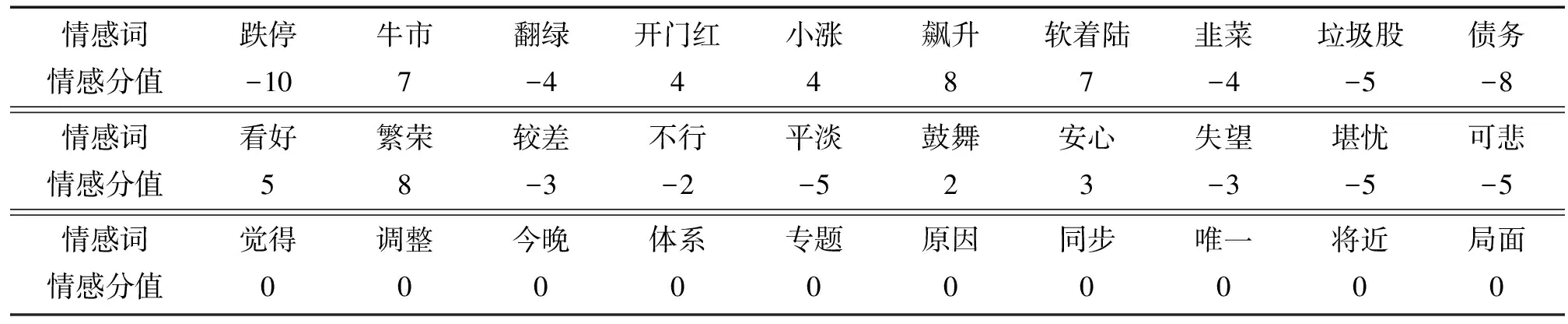
表4 股市情感词库部分信息
测试本文词库在股市微博文本数据集中的性能,结果如表5所示。同时,为了说明本文词库在特定领域比通用词库更具有优势,采用同样的方法,测试大连理工大学中文情感词汇本体库、清华大学情感词库、台湾大学情感词库、BosonNLP词库在股市微博文本数据集上的性能。
从表5可以看出,利用本文方法构建的词库得到的准确率和F1-Measure分别为85.70%和83.53%,高出其他通用情感词库20%以上。由此可见,本文词库在特定领域更具有针对性,相对于通用词库的优势更加明显。

表5 股市微博数据集准确率及与F1-Measure对比
2)医疗领域。同样,随机选取HCR数据集构建的部分情感词,如表6所示。从表6可以看出,“obstruction”在其他领域不带有情感极性,在本文方法中,则将该词分为负向情感词,可以表明本文方法也能有效地识别英文数据集中特定领域的情感词汇。

表6 医疗领域部分情感词汇
为了说明本文方法在HCR数据集所构建的情感词库的效果,同样,选取英文常用的情感词库Bing Liu词库进行对比实验,结果如表7所示。

表7 HCR准确率及与F1-Measure对比
从表7可以看出,本文方法构建的词库准确率为83.72%,F1-Measure为76.40%,优于Bing Liu词库。这表明通过本文方法所构建的词库在医疗领域仍然具有优势。同时,也验证了本文方法具有很好的扩展性和适应性。
在本文算法中,通过种群适应度值判断算法是否收敛。种群每进行一次迭代都会更新,在HCR数据集上的算法收敛过程如图4所示。

图4 算法在HCR数据集上收敛过程
从图4可以看出,种群在迭代140代后,适应度值不再变化,即算法收敛。
通过以上结果可以得到:①本文算法利用遗传算法进行情感词库构建;②整个过程不需要外部情感词库资源;③能够根据领域的不同构建适应的情感词库,证明了本文方法的优势。
4 结束语
情感词库是进行情感分析和情感决策的关键资源。针对特定领域急需高质量情感词库的需求,提出了一种采用遗传算法训练的方式,构建专业领域情感词库的方法。该方法以文本分类的准确率作为学习目标,设计了针对情感词库构建的遗传算法。通过不断调整情感词的情感值,最终形成高质量的情感词库。实验结果表明,本文提出的方法在构建情感词库上不仅具有良好的通用性,而且对股市、医疗等特定领域具有很好的针对性,综合性能优于传统的情感词库,能够为基于文本的情感分析及决策提供良好的支持,具有很好的应用价值。
未来的工作中,可考虑从以下方面进一步完善:引入同义词的度量方法,进一步优化情感词库;对情感词的选取进行专门研究,精炼情感词库中的情感词。
