一种基于注意力机制的语音情感识别算法研究
2022-08-26甘宏
甘 宏
(广州南方学院,510925,广州)
1 问题提出
随着计算机行业的不断发展,人工智能走进人们的生活,通过语音实现人机交互正逐渐成为主流的人机交互方式,语音情感识别能够让机器感知人类的情绪,听懂人的情感,在心理健康状态监控,教育辅助,个性化内容推荐,客服质量监控方面都具有广泛应用前景,但目前语音情感识别系统的识别率较低不足以大规模商用,提高情感识别准确度是一个亟待解决的难题。在人工智能研究中,情感的识别和表达是不可或缺的一个环节,人工智能想要达到真正的智能,应当具有同人类一样的情感感知和表达能力,因此语音情感识别研究格外重要。语音情感识别目前已经应用到一些领域,提供服务。例如,在医疗领域,进行儿童抑郁症检测以及临终关怀;在交通安全领域,进行驾驶人情绪检测,提供警告以保证驾驶安全;在客服系统中,通过情感识别模块识别客服工作中的情绪表达,辅助客服培训及日常工作监测等。
语音情感识别起源于20世纪80年代,Bezooijen和Tolkmitt最早提出采用声学特征进行语音情感识别研究[1-2]。此后,语音情感数据库逐步被建立,例如EMO-DB[3]和FAU-Aibo。提取出的声学特征被送入机器学习分类器进行情感分类,如GMM[4]、HMM[5]、SVM[6]、MLP[7]。
但是应用特征集进行语音情感识别很难找到表达语音情感的完备特征集和,今年学术界更倾向于采用深度学习技术进行语音情感识别。如采用MFCC或者语谱图作为特征,基于CNN和LSTM的深度学习网络进行情感分类[8-9]。深度学习中的神经网络可以模仿人类感知的过程,识别效果普遍优于传统特征工程,目前已经成为语音情感识别领域的主流方法。
除了传统的深度学习模型,注意力机制近年被广泛应用于人工智能各种细分领域,成为神经网络模型中不可或缺的一部分。注意力最早在机器翻译领域提出[10],其参照人类生物学知识进行算法创新,允许模型动态地关注有助于解决指定任务的输入的某些部分。
本文将通道注意力引入到语音情感识别网络中,实现对情感信息含量高的通道进行关注,提升网络情感识别能力。
2 语音情感识别基础
2.1 语音情感离散模型
在语音情感离散模型中,情感被划分为两两独立的类别,如1963年Tomkins将情感划分为愤怒、害怕、苦恼、开心、厌恶、惊奇、关爱、羞愧8种;1980年Plutchik划分为害怕、愤怒、悲哀、开心、厌恶、惊奇、容忍、期待8种。目前,广泛采用的有四分类法以及六分类法,详见表1。本文采用生气、高兴、悲伤、中性情感四分类法。
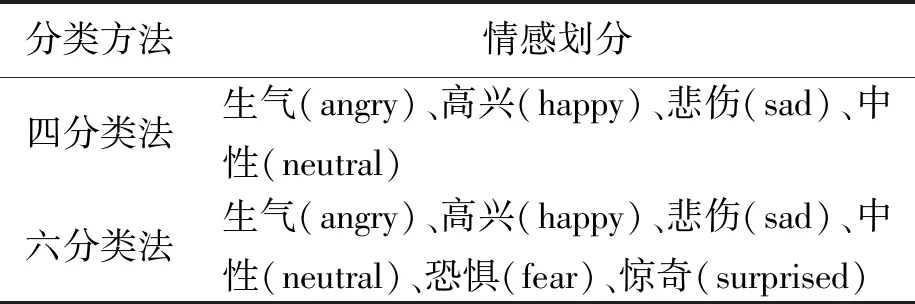
表1 离散情感划分方法
2.2 语音情感数据库
本文采用英文情感数据库IEMOCAP,该数据库在语音情感识别领域最为常用。
IEMOCAP数据库中包含5男5女的对话音频、说话内容、对话视频以及运动捕捉的记录,本文采用单模态识别方法,仅使用数据库中的音频数据。数据库一共包含5段对话,每段对话由1男1女完成,分2种表达方式,分别是自发类和表演类,其中自发类表达方式更贴近现实中的自然发话,本文实验仅采用自发类情感数据。
数据库中每段对话根据情感异同进一步被分为语句,对每条语句同时进行离散维度和连续维度的打标。对于离散维度,3个人同时标注为生气、高兴、悲伤、中性、沮丧、兴奋、害怕、惊喜、厌恶、其他中的一种,少数服从多数;对于连续维度,2个以上标注者在愉悦度、激活度、优势度3个维度进行打标,最终结果取平均。本文进行情感分类任务,采用离散标签。
该数据库语音总长度为12 h,音频采样率为16 kHz,存储为wav格式。本文采用情感四分类法,即应用数据库中生气、高兴、悲伤、中性4种情感,其中高兴情感为原数据库中高兴和惊喜2种情感合并而成。
3 实验方法
不同情感通过CNN进行特征提取后,不同通道关注的不同的语音情感信息,不同通道所关注的信息对最终的情感识别作用大小不一,本文引入通道注意力对语音情感的通道维度进行关注,原始语音情感识别模型如图1,通道注意力模型图如图2。
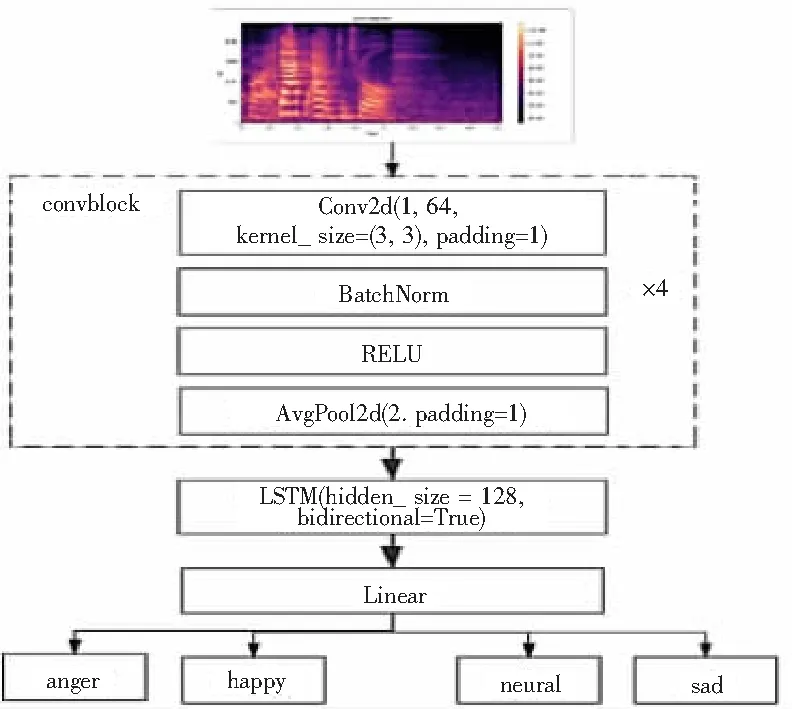
图1 原始语音情感识别模型
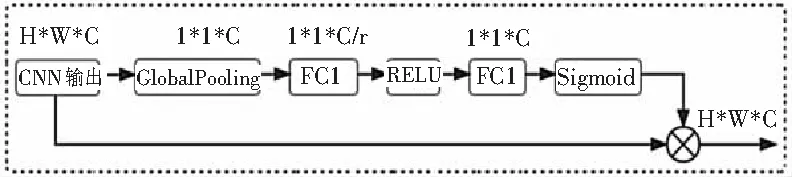
图2 通道注意力模型
具体实现方式为:将CNN特征提取网络输出的三维数据,在频率和时间2个维度进行全局池化,池化为通道维度的一维数据;之后通过2层全连接对通道进行先降维再升维的操作;通过Sigmoid函数计算通道注意力分数,与CNN原始输出特征进行相乘实现特征在通道维度的注意力关注。
本文对于计算注意力分数中全局池化阶段,分别尝试平均池化和最大池化2种方式,分析2种池化方式对最终情感识别的影响。此外,为增加整体模型的表现力,本文还在通道注意力的基础上引入残差,实现在对通道进行关注的同时保留原有的特征分布,引入残差的通道注意力模型如图3。
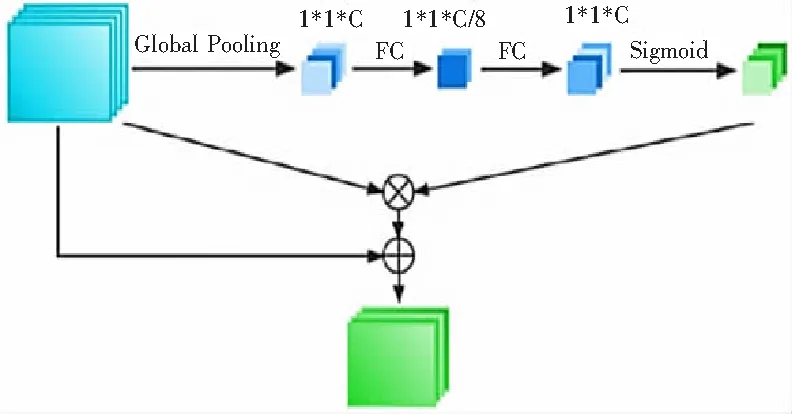
图3 引入残差的通道注意力模型
4 实验结果
4.1 实验设置
本文采用语谱图作为网络的输入,提取语谱图时帧长设置15 ms,帧移设置为7 ms,mel谱维度设置为128。IEMOCAP数据库中共包含5段音频,本文以段为单位,进行5折交叉验证实验。
此外,因IEMOCAP数据库中音频不等长,本文在数据处理部分将数据时长统一为7.5 s,短于7.5 s的音频进行补零操作,长于7.5 s的音频截短至7.5 s。
4.2 评价指标
本文采用混淆矩阵来评价分类性能,混淆矩阵示例见表2。

表2 混淆矩阵示例
混淆矩阵包括不加权召回率(Unweighted Accuraterecall,UA)与加权精度(Weighted Accuracy,WA)2个具体的评价指标,具体计算方式。
(1)
(2)
4.3 实验结果
根据表2中的方法,首先本文在计算通道注意力时,全局池化分别尝试采用平均池化和最大池化,并与未添加通道注意力时的模型进行评价指标的对比,结果如表3。
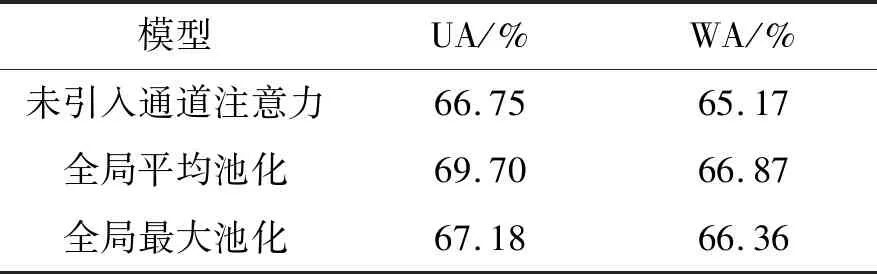
表3 通道注意力交叉验证结果
引入通道注意力之后,不论采用全局平均池化还是全局最大池化,相较未引入通道注意力时的模型都有明显的性能提升,其中采用全局平均池化的通道注意力效果最为明显,UA实现了2.58%的提升,WA实现了1.48%的提升。
为增强网络的表现能力,保留原始特征分布,本文在通道注意力的基础上引入残差结构,并调整残差比重,实验结果如表4。
引入残差结构后的通道注意力模型比未引入残差结构的通道注意力模型情感识别准确率最高,其中采用全局平均池化且残差比重为1的通道注意力模型,相较未引入残差结构时,UA实现了0.17%的提高,WA实现了0.30%的提高。
5 结论
本文将通道注意力引入到语音情感识别深度学习网络之中,在网络学习的过程中实现对不同通道的关注。在计算通道注意力分数时尝试全局平均池化和全局最大池化2种方式,并引入残差结构,对不同种通道注意力方式进行探讨。最终试验结果显示,引入通道注意力后的语音情感识别准确率得到明显提升,这表明CNN输出的不同通道包含的情感信息不同,引入注意力之后可以关注对最终情感识别作用较大的通道,从而提高整体模型的识别能力。
