基于梯度提升决策树的电力物联网用电负荷预测
2022-08-26冯瑛敏姜美君
刘 瑾,赵 晶,冯瑛敏,周 超,姜美君,章 辉
(1.国网天津电力经济技术研究院,天津 300171;2.南开大学,天津市光电传感器与传感网络技术重点实验室 天津 300350)
0 引言
电力物联网日益受到全球技术人员的关注,是电力领域人与人、人与物和物与物的连接网络,延伸和扩展了信息交换的用户端[1]。作为电力物联网的一项重要应用,监控系统在电力生产实践中占据了越来越重要的地位[2],传统电力监控系统存在的问题通常集中于可连接的监测点数量少、监测数据类型单一、缺乏数据处理功能和不具备及时预警功能等[3]。
随着万物互联时代的到来,未来电力物联网的数据传输量将会出现井喷式增长[4],电力物联网监控系统的监测点规模化、多维化、智能化的需求越来越迫切。电力物联网为了实现泛在物联,具有连接节点数量多、监测点分布广和采集的数据类型多的特点[5]。如何实现海量传感器监测数据的预测功能是未来解决电力物联网部署的关键性问题[6-7]。由于配电网拓扑结构及运行环境复杂,部件种类繁多,容易受到设备故障、恶劣环境等因素的影响[8]。如何及时预测超负荷用电并制定有效的用电方案,指引企业合理调整用电负荷,保护用户安全用电、提升电网稳定性和安全性,是当前智能电网用电研究的重点[9-11]。
本文提出了一种基于极致梯度提升树和轻量梯度提升机(XGBoost-LightGBM)的交叉用电负荷预测方案,能够实现在线台区用电分析,实时预测未来时刻台区用电情况,当台区即将发生超负荷用电或者当前台区发生大规模停电时,提前向指挥平台发出预警,为用电的优化调度提供支持,提高电网运行可靠性。
1 梯度提升决策树
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是一类机器学习算法,其在预测和分类问题上的良好性能受到工业界的关注[12-15]。该算法由多棵决策树组成,利用损失函数的负梯度在当前模型的值作为提升树中残差的近似值来拟合回归决策树[16]。GBDT 算法的一般步骤为:
1)输入n个训练样本X,并设置相关参数,迭代次数为N,F为所有树组成的函数空间,fk为单决策树模型,初始值f0=0,GBDT 算法表达式为:
式中:xi为第i个样本的特征向量;K为弱回归树的数量;fk(xi)为第k棵弱回归树的输出值;为第i个样本的最终预测值。
2)定义GBDT 算法的目标函数为:
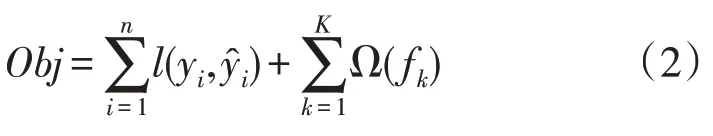
式中:Ω 为决策树的复杂程度;n为样本总数;l为损失函数;yi为第i个样本的真值。
复杂度由正则项定义:
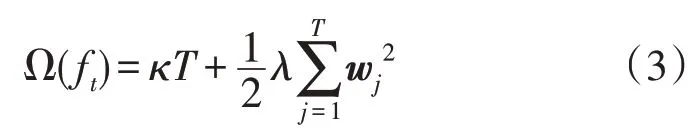
式中:T为叶子的节点数;wj为叶子节点对应的向量值;κ为树的叶节点分裂所需的最小损失减小量;λ为惩罚项系数。
3)根据GBDT 算法的加法结构,

式中:Gi=∑gi,Hi=∑hi,gi和hi分别为损失函数的一阶和二阶导数。
令Objt的一阶导数为0,可求得叶子节点的最优值
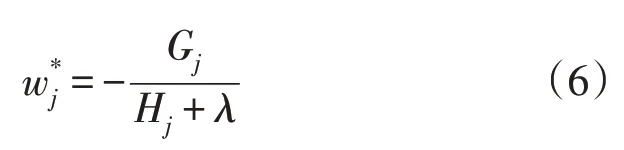
此时的目标函数值为:
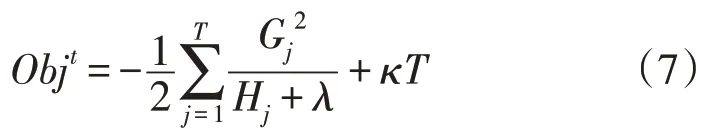
4)通过贪心策略生成新的决策树,使目标函数值最小,并求得叶子节点对应最优预测值,将新生成的决策树ft(x)添加到模型中,可得:

5)不断迭代,直到N次迭代结束,输出由N个决策树构成的GBDT 算法。
GBDT 算法有较多的有效实现,如XGBoost 算法和LightGBM 算法,均属于GBDT 的集成学习算法[17]。
1.1 XGBoost算法
XGBoost 是基于GBDT 的改进算法,使用多线程并行性改进算法以提高准确性,适用于分类和回归问题[18-20]。XGBoost 的基本原理与GBDT 相同,区别在于GBDT 使用损失函数的一阶导数,而XGBoost 使用一阶和二阶导数执行损失函数的二阶泰勒展开。
XGBoost 算法的损失函数为:
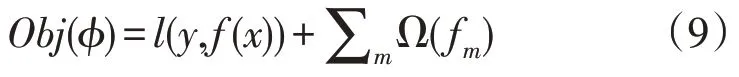
式中:y为当前样本x对应的真值;f(x)为样本x的预测值;l(y,f(x))为损失函数;fm为第m棵分类树模型;Ω(fm)为正则化项,用来反映算法的复杂程度;φ为需要求解的模型参数。
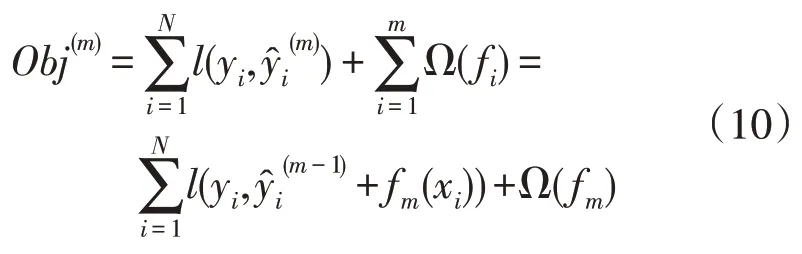
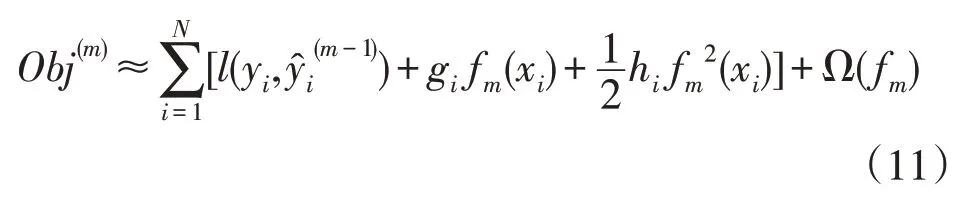
使用泰勒展开式来逼近函数fm(xi),式(10)变换为式(11),其中:
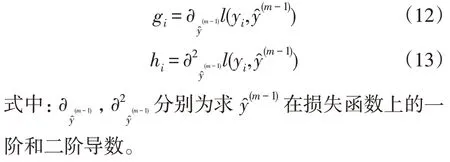
目标函数中的正则化项为:
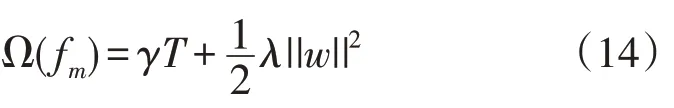
式中:γ为在树的叶节点进一步分裂所需的最小损失减小量,表征每一个叶子的复杂程度;w为叶子节点的值。
1.2 LightGBM算法
LightGBM 算法是一种改进的梯度提升决策树框架[21-23]。它的基本思想是通过M棵弱回归树线性组合为强回归树,如式(15)所示:
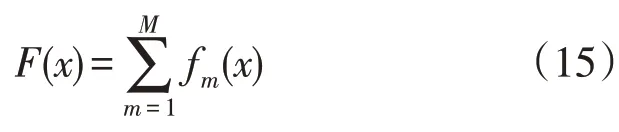
式中:F(x)为最终的输出值;fm(x)为第m棵弱回归树的输出值。
LightGBM 算法的主要改进包括直方图算法和带深度限制的叶子生长(Leaf-wise)策略。直方图算法将连续数据离散划分为P个整数,并构造一个宽度为P个数的直方图。遍历时将离散化的值作为索引在直方图中累积,进而搜索出最优的决策树分割点。在LightGBM 中,叶节点的直方图可直接从父节点的直方图和兄弟节点的直方图获得,该策略加快了算法的计算速度。
带深度限制的Leaf-wise 策略是指在每次分裂时,找到最大增益的叶子进行分裂并循环下去。通过树的深度以及叶子数限制,减小模型的复杂度,防止出现过拟合。LightGBM 的Leaf-wise 每次从当前叶子中找到具有最大分割增益的叶子,然后进行分割,依此类推。因此Leaf-wise 可减少错误,并在相同数量的分割时获得更好的准确性。Leaf-wise的缺点是可能会产生较深的决策树,从而导致过拟合。因此,LightGBM 在Leaf-wise 之上增加了最大深度限制,以防止过拟合并确保高效率。
通过直方图算法和带深度限制的叶子生长策略,LightGBM 算法减少了内存的占用,训练时间仅为XGBoost 的1/10,并且准确率有所提升,适合处理用电负荷预测这类数据量较大的问题。
2 XGBoost-LightGBM交叉
在LightGBM 算法和XGBoost 算法的基础上,本文提出了一种基于XGBoost 和LightGBM 交叉的方案,算法交叉融合过程如图1,分别用LightGBM和XGBoost 对初始输入特征进行五折交叉验证,同时将验证过程中计算的验证集结果保留,当作下一轮的输入特征。考虑到2 种算法的决策树生长策略不同,将XGBoost 得到的特征n+1 放入LightGBM中重新训练,然后LightGBM 得到的特征n+2 放入XGBoost 中重新训练。最后将重新计算后得出得结果进行加权融合。
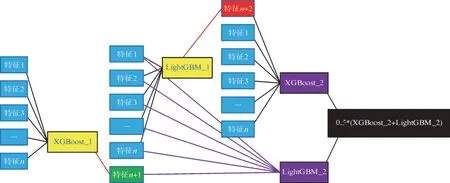
图1 XGBoost和LightGBM交叉过程Fig.1 Model fusion process between XGBoost&LightGBM
如图1 所示,通过XGBoost 和LightGBM 特征的有序交叉,可有效融合二者决策树的生长优势。XGBoost 和LightGBM 主要不同点在于决策树的生长策略。XGBoost 采用的是带深度限制的levelwise 生长策略。level-wise 能够同时分裂同一层的叶子,可以进行多线程优化,且不容易过拟合。但不加区分地对待同一层叶子,会带来很多不必要的算力开销,很多叶子的分裂增益较低,没必要进行搜索和分裂。LightGBM 采用leaf-wise 生长策略,每次从当前所有叶子中找到分裂增益最大的一个叶子,进行分裂,如此循环,但会生长出比较深的决策树,产生过拟合。本文提出将XGBoost 和LightGBM 特征进行有序交叉,既在分裂部分同一层的叶子,又分裂部分增益大的叶子,限制了叶子的深度,可有效规避XGBoost 的算法效率问题和LightGBM 的过拟合问题。
2.1 交叉验证
为了获得更准确的估计,使用交叉验证来训练和测试数据集的每个子集中的模型,原始样本被随机分为a个大小相等的子集。对于a个子集,将单个子集作为验证数据以测试模型,其余(a-1)个子集用作训练数据。然后,将交叉验证过程重复a次,每个子集都恰好使用一次作为验证数据。
在本文中,将数据集随机分为5 个大小相等的独立子集。如图2 在验证的每个步骤中,保留1 个子集(数据集的20%)作为验证数据集,以测试所提出方法的性能,而其余4 个子集(数据集的80%)用作训练数据集。重复上述过程五次,直到使用了每个子集,并计算5 个测试子集的平均值,最终结果是该算法在5 次交叉验证中的总体性能。将该验证过程中计算的验证集结果予以保留,作为下一轮的输入特征。

图2 交叉验证过程Fig.2 Cross-validation process
2.2 算法评价
均方根误差通常用来衡量观测值与真值之间的偏差,因此在工程测量中广泛采用[24]。为了评价算法的优劣,本文采用均方根误差(Root Mean Square Error,RMSE)作为评判标准,其值ERMS通常为:
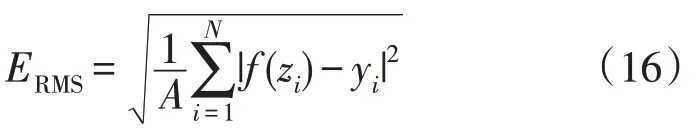
式中:N为测试样本总数;f(zi)为算法输出的第i个时刻预测值。
3 基于XGBoost-LightGBM 交叉的用电预测
图3 为基于XGBoost-LightGBM 交叉的用电预测流程图,通过获取台区用户的用电量数据,并对异常缺失数据和多个数据集进行预处理,然后进行算法迭代,算法流程如下:
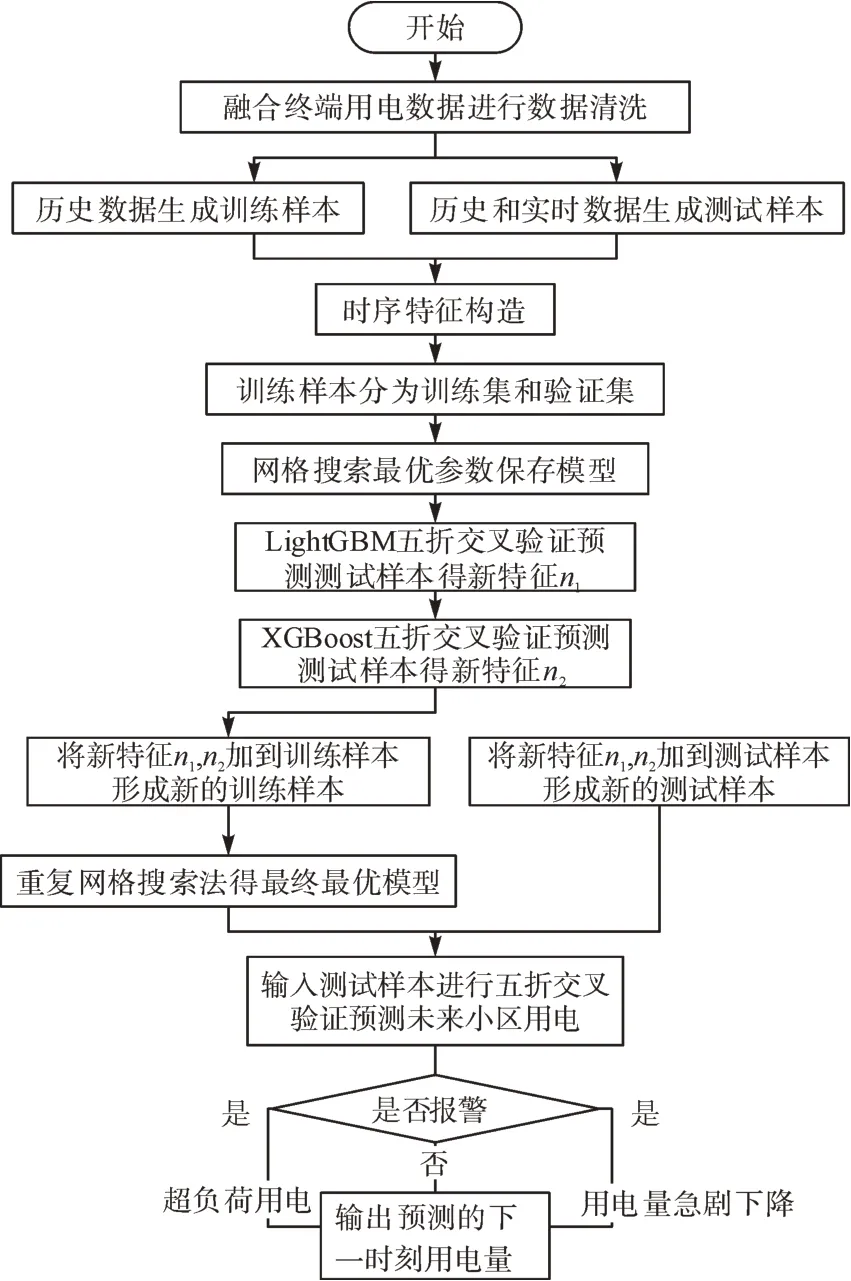
图3 用电监控预警流程Fig.3 Power distribution monitoring and alarm process
1)从智能融合终端存储数据库里获取用户历史用电情况和实时用电情况(每30 min 采样获取1次实时用电数据)作为输入上传至机器学习算法模块中,并进行数据筛选后得到训练样本TrainData 和测试样本TestData。后续可根据TestData 与预测结果的残差分析进行预测精度的评估。
2)对TrainData 和TestData 进行时序特征构造。
3)将TrainData 分割为训练集Train 和验证集Val。
4)使用LightGBM 预测Val,并通过网格搜索法寻找最优参数组合,保存最优模型LightGBM_1。
5)使用XGBoost 预测Val,并通过网格搜索法寻找最优参数组合,保存最优模型XGBoost_1。
6)将TestData 输入到XGBoost_1 模型和LightGBM_1 模型分别进行5 折交叉验证,得到输出结果特征n1和特征n2。
7)将特征n1合并到TrainData 最后一列,得到TrainData_1。使用TrainData_1 作为新的训练集,重复步骤(4),得到最优模型LightGBM_2。
8)将特征n2合并到TrainData 最后一列,得到TrainData_2。使用TrainData_2 作为新的训练集,重复步骤(5),得到最优模型XGBoost_2。
9)将TestData 和特征n1输入进LightGBM_2 模型,TestData 和特征n2输入进XGBoost_2 模型,分别进行5 折交叉验证,得到输出结果result_1 和输出结果result_2。
10)将result_1 和result_2 按照1:1 的比例融合,得到最终结果result(result 表示的是未来时刻用户的用电量),输出为未来时刻用电量的预测结果。
若预测结果不在正常配电范围内则发出预警信息,当用电量大于正常配电范围最大值,则发出即将超负荷用电报警信息;当用电量小于正常配电范围最小值,则发出即将大规模停电报警信息。
4 实际案例分析
4.1 构建样本
本文使用的数据记录了某区域某年1 月至12月的用电量,其中用电量每半个小时采集1 次,数据如表1 所示。
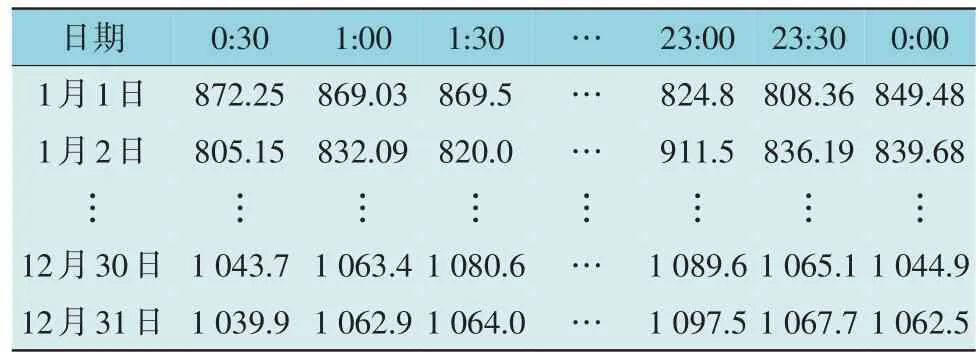
表1 初始数据Table 1 Initial data kWh
首先是预处理这些数据,主要执行数据清理和缺失值处理。数据清理主要是去除噪声数据,缺失值处理主要是填充缺失数据。
4.1.1 数据清理
首先,去除一些异常数据,例如用电量低,用电量突变,远离平均值的数据。这些数据属于异常情况的数据,例如传感器采集错误、线路故障等,因此将其删除。
4.1.2 缺失值处理
由于设备,线路或数据本身之类的问题,数据中可能存在大量缺失值。这将使算法预测不准确。因此,缺失值必须得到补充。这里使用的补充方法是:如果某些部分严重缺少数据并且丢失值的比例在一天中超过50%,则直接丢弃一整天的数据;如果某些部分中缺失少量的值,并且一天数据相对完整,则将其使用平均值进行填充。
随后是基于数据集的分析,探索各种因素对用电负荷的影响,选择合适的向量构造特征。本文使用距离分析方法中的皮尔逊相关性来估算社区用电数据与其他数据之间的相关性。式(17)是计算2个维向量x和y中的Pearson 相关系数的公式[25]:
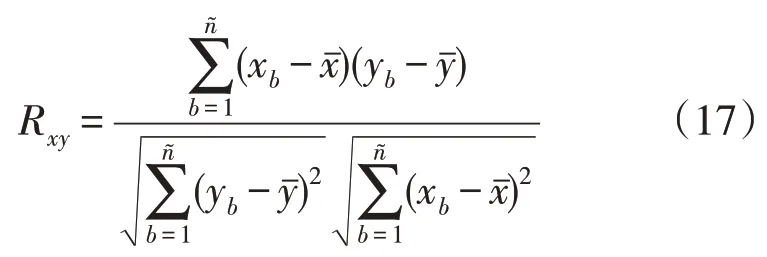
式中:xb和yb分别为向量x和向量y在位置b上的值;和分别为向量x和向量y中所有值的平均值。
皮尔逊相关系数Rxy是一个介于[-1,1]之间的实数。Rxy>0 则这2 个变量是正相关的,否则它们是负相关的。较大的 |Rxy|表明x和y之间的相关性越高。部分特征的皮尔逊相关系数如表2 所示。表2 中P为当前时段用电量,其中P为当前时段的用电量,Second,Minute 和Hour 分别为当前时段的秒、分和时的时间特征,LP为上一时段采集的电量信息,LPD为当前时段与上一时段用电量的差值。
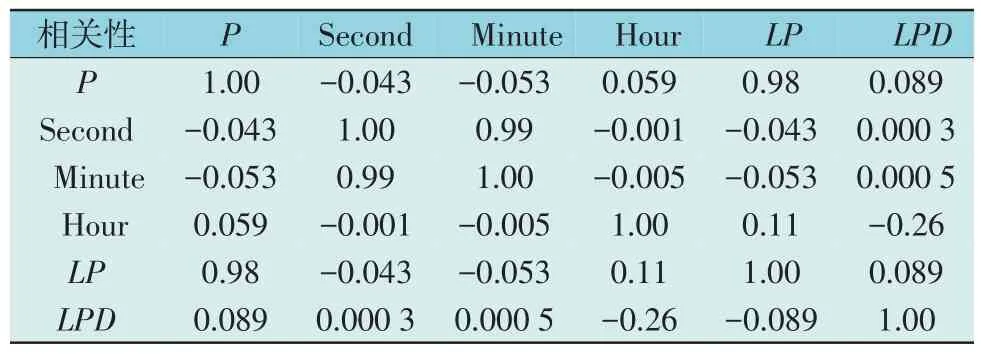
表2 皮尔逊相关系数Table 2 Pearson correlation coefficient
由表2 中可知用电量P与上一时段用电量LP呈强相关性,因此我们对LP进行下一步特征构造。
接着对原始变量进行特征构造,选择合适的输入特征变量对模型预测结果的优劣有极大的影响,根据特征之间的相关性,本文选取台区前几个时刻的时段用电量构造滑动窗口特征,包括前10 个时段的用电量、10 个时段用电量的统计数据(最大值,最小值,标准差,中位数)以及后9 个时段与第一个时段的用电量差值dc,差值dc为:
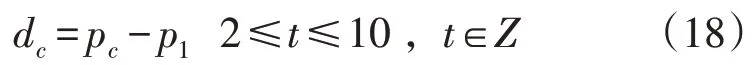
式中:pc为第c个时段的用电量;p1为第1 个时段的用电量;Z为选取的时段总数。
4.2 网格搜索法调参
LightGBM 和XGBoost 都包括多个参数,称之为超参数。超参数对LightGBM 和XGBoost 算法的性能有重大影响。它们通常是手动设置的,然后在连续的反复试验过程中进行调整。在算法参数设置中,本文使用网格搜索的方法,即设置特定参数的范围和参数搜索的步长,连续迭代,并根据分数获得最佳结果。使用网格搜索法以调整LightGBM 和XGBoost 算法的超参数,调整的超参数包括:num_leaves(每棵树的叶子数)、max_depth(树的最大深度)、n_estimators(树的棵数)和learning_rate(学习率),其余参数均使用默认参数。表3 显示了训练过程中算法的参数设置,均为无量纲参数。表3 中的斜杠表示无此参数。
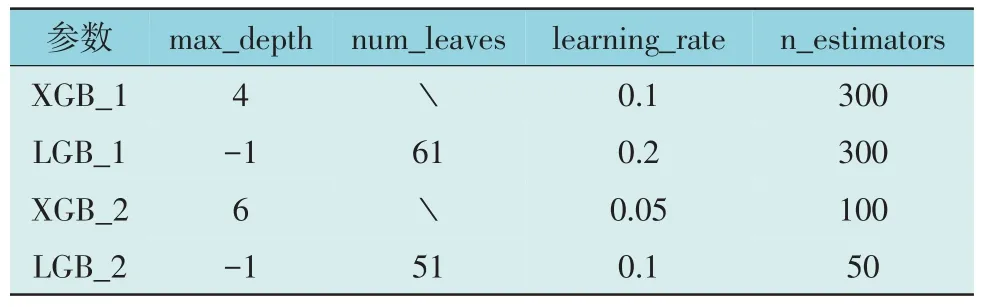
表3 算法参数Table 3 Model parameters
4.3 结果分析与对比
为了验证算法的精度,分别使用XGBoost、LightGBM,传统随机森林(RandomForest)以 及XGBoost-LightGBM 交叉算法来预测台区用电量。为了体现算法的公平性,本文算法模型和对比算法模型均已经过调参,达到了最优效果。图4 是4 种算法的仿真对比结果,展示了4 种算法拟合10 月20 日这一天的用电情况。由图4 中可以看出4 种算法的用电量都与真值变化趋势一致,具有较高的准确性,说明构造的特征对算法有较大增益。
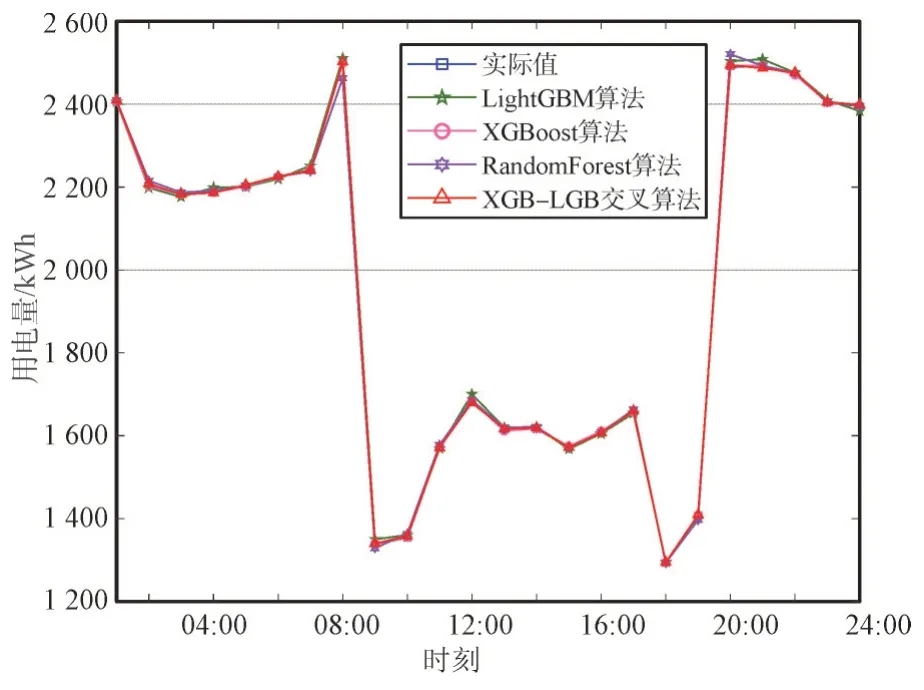
图4 算法用电量预测结果Fig.4 Power consumption prediction results with different algorithms
图5 是4 种算法预测结果与10 月20 日这一天的用电量绝对误差对比结果,由图5 中可看出,RandomForest 算法与XGBoost 算法、LightGBM 算法以及本文提出的交叉算法相比误差更大,说明本文提出的算法较传统算法有较大提升。
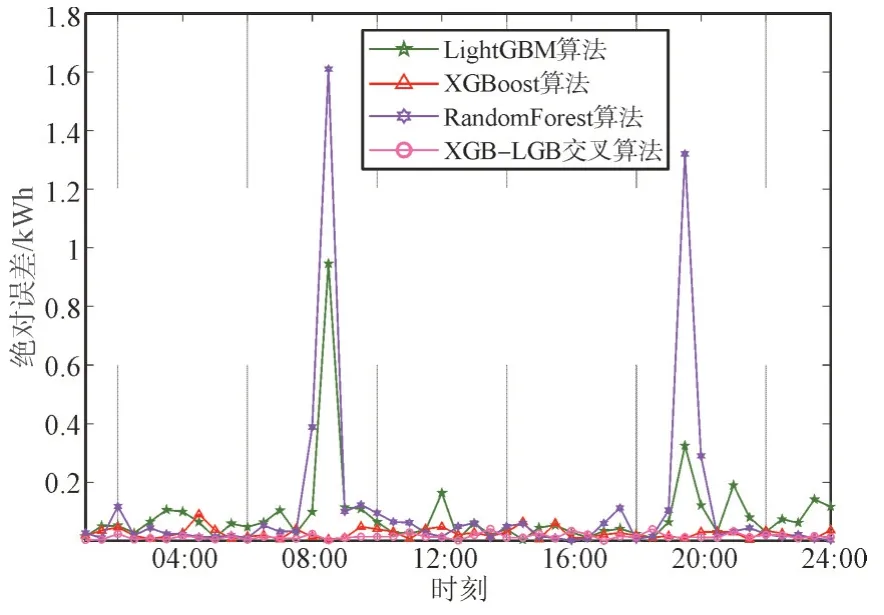
图5 算法预测结果绝对误差分析Fig.5 Absolute error analysis of prediction results with different algorithms
为了验证算法的交叉次数是否最优,本文将不同交叉次数对结果的影响进行了对比验证,结果如图6 所示。从图6 中可见,交叉次数的增加并不会提升模型的精度,这是因为每一次交叉的结果都存在一个额外的误差,多次交叉会出现误差累积,影响预测精度。基于上述分析,为了避免误差积累,本文对算法进行1 次交叉。
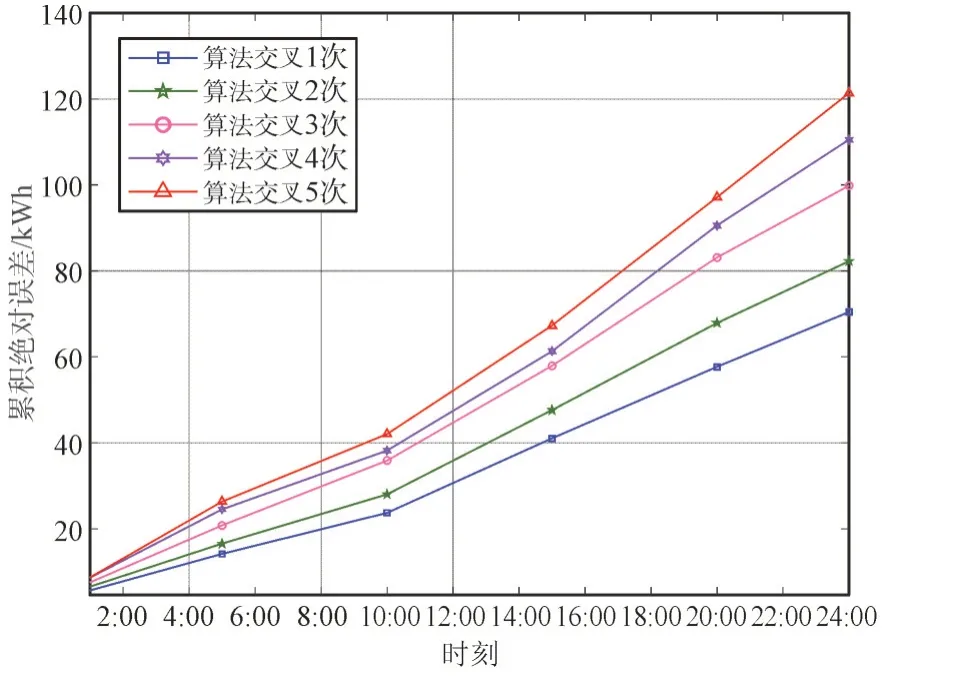
图6 算法交叉次数累计绝对误差分析Fig.6 Analysis of cumulative absolute error of algorithm crossover times
表4 计算了4 种算法在10 月19 日16∶00 到11 月9 日11∶30 共1 000 个时间点的均方根误差。由表4 中可以得出,本文提出的XGBoost-LightGBM交叉算法优于LightGBM 和XGBoost 的单一算法,同时较传统随机森林算法有较大的提升。

表4 算法结果比较Table 4 Algorithm result comparison
图7 是本文提出的交叉算法预测出的台区用电量与实际用电量的比较,由图7 中可以看出本文提出的算法具有较高的准确性。并且当用电量高于台区超负荷用电阈值时,将会自动上报系统为用电的优化调度提供支持,从而提高电网运行可靠性。
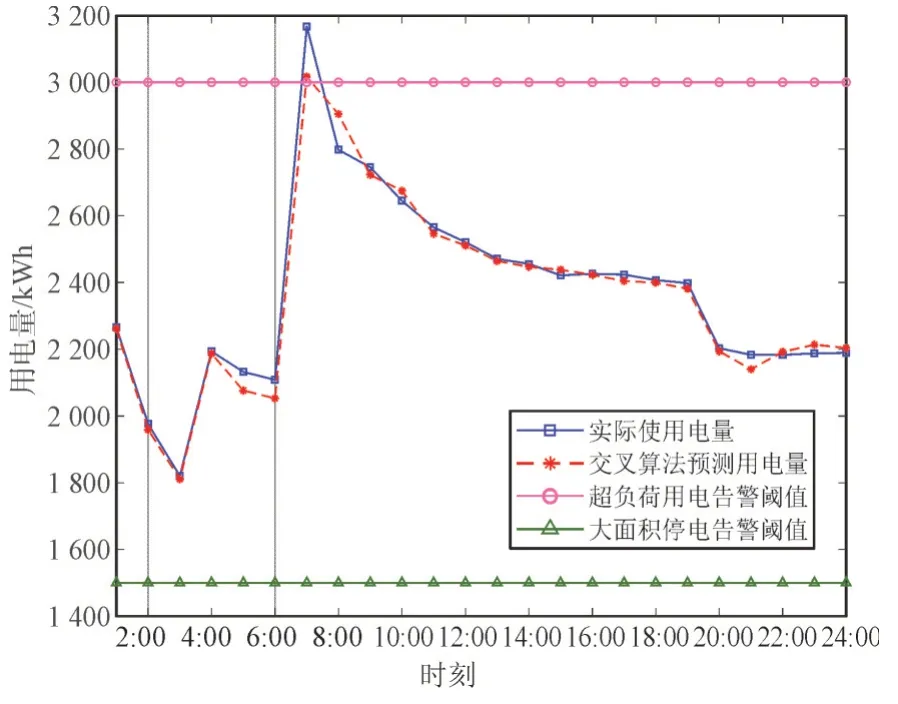
图7 用电量仿真结果Fig.7 Electricity consumption simulation results
5 结论
本文提出了一种基于XGBoost-LightGBM 交叉算法的用电预测方案。经实际外场实验表明,本文提出的用电负荷预测算法鲁棒性好,准确性高,相较于传统算法和XGBoost、LightGBM 等单一算法有更高的准确性,在发生超负荷用电或者当前台区发生大规模停电时,能够及时发出预警,具有较强的实用性。
