基于改进YOLOv3的PVC皮革瑕疵检方法研究①
2022-08-24王美林
唐 勇, 王美林
(广东工业大学信息工程学院,广东 广州 510006)
0 引 言
PVC皮革是由塑料异型材料构成的人造革产品,随着科学技术的不断发展,对于生产深度加工PVC皮革的表面质量要求也越来越高。如汽车内饰皮革是其必不可少的装饰配件,汽车购买者对乘用小汽车内饰皮革的要求也越来越挑剔,而蚊虫叮咬及加工过程的精细不足使得原始皮革表面不可避免地产生了各种缺陷,如针孔、条纹、划伤、气泡、垫伤等等;因此,皮革瑕疵检测已然皮革生产和质量管理的重要环节。
针对具有复杂纹理背景的皮革瑕疵检测,Kwon Jang-Woo等人[1]使用直方图的分布的方法判断皮革有无缺陷,但是无法对皮革缺陷进行具体定位。崔杨等人[2]通过改进模糊C-均值算法对皮革缺陷进行检测,使得检测精度得到了很大的提高,但增加了很多的计算量。刘利华等人[3]构建了一种基于模糊数学的皮革制品质量综合评判应用模型,辛登科等人[4]利用类间方差和类内方差进行自适应确定分割区域数的方法,贺福强等人[5]采用了小波重构的方法对皮革表面进行了缺陷检测。常竞[6]对皮革缺陷进行了分类检测,提高缺陷检测准确性,但不易检测皮革缺陷色差、污斑等。于彩香[7]提出利用纹理图像中缺陷区域灰度值和背景中像素之间的相关性来识别缺陷。
传统的检测方法准确性较低,在训练和测试过程中也比较耗时。到目前为止,高性能的检测算法都基于深度学习。工业生产皮革中,需要对皮革的瑕疵实时检测。因此在考虑保证实时检测速度的前提下,本文选择此类算法中检测精度较高的YOLOv3[8]算法作为基础。但YOLOv3在PVC皮革瑕疵检测中的准确性还有待提高,针对这个问题,提出一种改进后的PVC皮革瑕疵检测网络YOLO-D。
1 经典YOLOv3算法
在2016年,Redmon等 人 提 出You Only Look Once[9](后面统称为YOLO),这是一种运行速度非常快的目标识别和定位算法。之后在2018年提出基于YOLOv2[10]演变而来的YOLOv3。YOLOv3与前面两个版本不同的地方之一,是在整个模型作特征提取部分时使用Darknet-53网络。YOLOv3通过利用NMS非极大抑制算法[11],筛选出置信得分较高的预测框,得到最终的目标的边框位置和类别信息,并返回。
2 改进YOLOv3算法
2.1 MixConv混合深度卷积核
在Darknet-53作为特征提取网络中,每个卷积核大小都为1*1或3*3,即卷积核的大小单一。研究表明,每个卷积核都负责捕获一个局部图像模式,单一的卷积核尺寸大小具有局限性:需要大的卷积核来捕获高分辨率模式,也需要小卷积核来捕获低分辨率模式。在皮革瑕疵检测中,同种类型的瑕疵分辨率大小可能不同。
Google Brain提出的Mix Conv[12]混合深度卷积核,是在一个深度卷积过程中,混合了多个不同大小的卷积核,便于从输入图像中获取不同类型的模式。根据精度和效率的权衡,改进后的YOLOv3网络结构如图1所示。

图1 YOLOv3改进后的网络结构图
2.2 GIo U损失
目标检测中最常用的指标是IoU(Intersection over Union),它的值等于两个区域的交集比上两个区域的并集,如公式(1)所示。IoU也用于YOLOv3,但是IoU存在一个明显的问题:当目标的预测框和真实框没有重叠的情况下,IoU将会为0。在这种情况下,将IoU用作为边框损失的话,导致边框损失将无法进行优化。由于YOLOv3采用3个尺度的特征图预测,每个尺度的特征图分配3个先验框,存在比较多预测框和真实框不重叠的现象,如式(1):
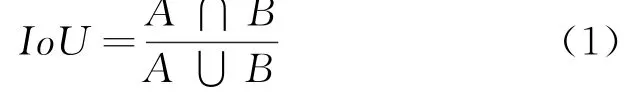
GIo U[13]可以一定程度解决上述问题。GIo U的设计思路是在两个现有的并且是随机选取的性质A和性质B,能够找得到一个封闭形状包含A与B,并且C是最小的封闭形状,接着计算形状C中未覆盖A和B的面积的绝对值与形状C总面积的绝对值的比率,然后用性质A与性质B的Io U减去这个比率,如式(2)所示:
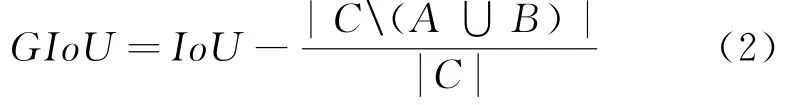
同样地,GIoU也可以用作距离,loss可通过L GIoU=1-GIoU计算。GIoU在保留IoU原始性质的同时,弱化了IoU的缺点,使得检测准确率有所提升。
2.3 标签平滑
在YOLOv3作类别预测时,不再使用softmax,而是使用独立的逻辑分类器。在训练过程中使用二元交叉熵作为类别的预测损失。交叉熵损失函数表达式如(3):

其中y表示真实值,p表示预测值。可以看出如果模型分类正确,则L的结果为0;否则L为无穷大。即交叉熵对分类正确的给予最大鼓励,对分类错误的给予最大惩罚。在皮革瑕疵检测中,可能把背景花纹分类成瑕疵,因此会出现过拟合问题而损伤检测的精度。
Szegedy等人在2016年提出的标签平滑[14],可以一定程度上减轻这个问题。标签平滑的交叉熵实现公式为(4):
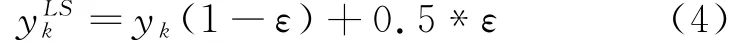
3 实验过程
3.1 实验数据集
所使用的PVC皮革实物全部来自皮革生产工厂,总共采集到544张图像,并对原图像进行旋转、添加噪声、调节亮度和平移等数据增强操作,图像数据扩增至17883张,并将瑕疵种类分为bubble,dirt,stripe,hole,ribbon五类。其中训练集为16095张,测试集为1609张,验证集为179张。
3.2 训练过程
实验主要在PC端完成,PC的主要配置为CPU:i7-9700K,GPU:NVIDIA RTX-2070 8 GB,内存:16GB,系统:Ubuntu 18.04,框架:Pytorch,语言:Python。
4 实验结果分析
4.1 评估标准
在目标检测实验中,除了目前流行目标检测评估指标Precision,Recall,AP,m AP之外,在进行算法性能评价时还采用F1指数,F1是P-R的调和平均,能很好的区别算法的优劣,F1值越高,物体识别算法就越好。
4.2 数据对比分析
迭代100个epoch之后,不同目标检测网络AP对比如表1所示。其中,YOLO-1为原始的YOLOv3,作为基线;YOLO-2是加了GIo U损失的版本;YOLO-3是在YOLO-2的基础上加了Mix Conv混合深度卷积核的版本;YOLO-D是在YOLO-3的基础上做了标签平滑处理的最终版。从表1中可以看出,采取了改进措施后,各个类型的瑕疵AP均有不同程度的提高。
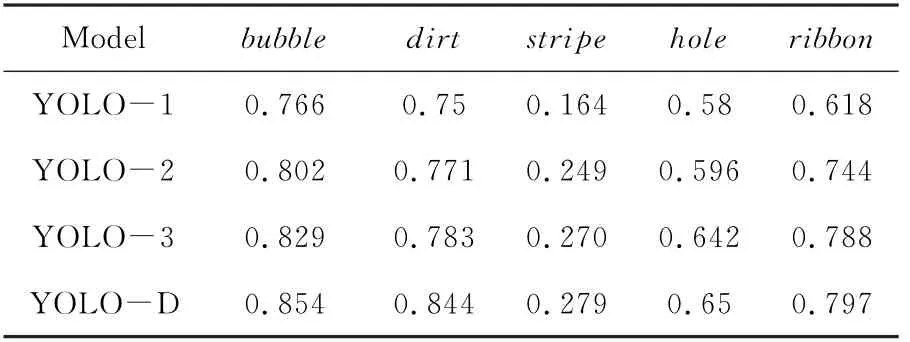
表1 不同目标检测网络AP对比
不同目标检测网络性能对比如表2所示。总体来说,在略微牺牲平均检测时间的情况下,YOLO-D比YOLOv3在性能上有较大幅度的提升。
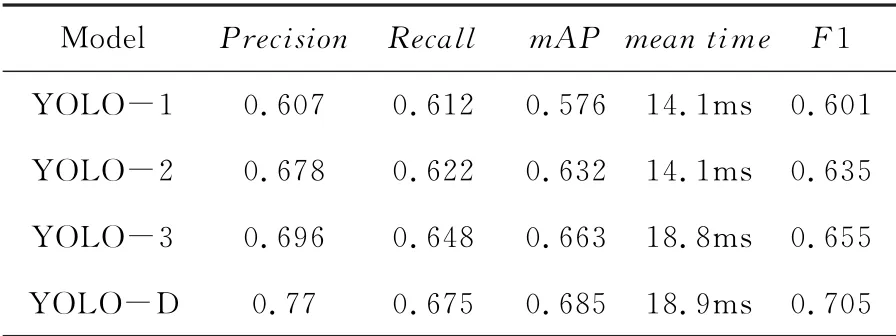
表2 不同目标检测网络性能对比
4.3 检测结果对比
原始算法模型YOLOv3与改进后的算法模型YOLO-D的检测结果对比如图2所示。

图2 检测结果对比图
在图2中的a,b,c,d,e,f对比中可以看出,加入GIo U和MixConv后的YOLO-D比YOLOv3降低了漏检率;在g、h对比中可以看出,加入标签平滑的YOLO-D比YOLOv3降低了误检率。改进后的YOLO-D检测的精度确实比改进前的YOLOv3有所明显提升。
5 总 结
针对传统人工智能算法在PVC皮革瑕疵检测过程中,存在检测精度低下、检测速度慢,导致无法实时检测等问题,在选取当前主流的目标检测算法之一YOLOv3作为基础框架,分别从三个方面提出了改进措施。改进后的模型可以明显提高识别的准确性,可以达到实时监测的标准,改进后的算法模型更加适合现实中PVC皮革的瑕疵检测。
