基于多级特征融合的体素三维目标检测网络
2022-08-23张吴冉胡春燕陈泽来李菲菲
张吴冉,胡春燕,陈泽来,李菲菲
基于多级特征融合的体素三维目标检测网络
张吴冉a,胡春燕a,陈泽来a,李菲菲b
(上海理工大学 a.光电信息与计算机工程学院 b.医疗器械与食品学院,上海 200093)
为精确分析点云场景中待测目标的位置和类别信息,提出一种基于多级特征融合的体素三维目标检测网络。以2阶段检测算法Voxel−RCNN作为基线模型,在检测一阶段,增加稀疏特征残差密集融合模块,由浅入深地对逐级特征进行传播和复用,实现三维特征充分的交互融合。在二维主干模块中增加残差轻量化高效通道注意力机制,显式增强通道特征。提出多级特征及多尺度核自适应融合模块,自适应地提取各级特征的关系权重,以加权方式实现特征的强融合。在检测二阶段,设计三重特征融合策略,基于曼哈顿距离搜索算法聚合邻域特征,并嵌入深度融合模块和CTFFM融合模块提升格点特征质量。实验于自动驾驶数据集KITTI中进行模拟测试,相较于基线网络,在3种难度等级下,一阶段检测模型的行人3D平均精度提升了3.97%,二阶段检测模型的骑行者3D平均精度提升了3.37%。结果证明文中方法能够显著提升目标检测性能,且各模块具有较好的移植性,可灵活嵌入到体素类三维检测模型中,带来相应的效果提升。
三维目标检测;残差融合;自适应融合;特征增强;三重特征融合
随着无人驾驶、室内移动机器人等技术的发展,大量研究人员开始关注三维目标检测领域。基于三维目标检测可获取目标物体类别、位置、三维尺寸及姿态等更加详细的信息,借助检测结果可实现对周围环境的精确感知,保证设备安全运行。
目前,三维目标检测算法主要分为2类:基于点云表示[1-4]的方法和基于点云和图像多模态融合[5-7]的方法。其中基于点云表示的方法又可分为体素[8-11]方式(Voxel-Based)和原始点[12-14]方式(Point-Based)。其中体素网络以较快的推理速度广受欢迎。此类算法在点云采样阶段采用网格化处理,将离散的点云均匀分割成立体体素。但此种方法在采样过程中会导致信息丢失,影响目标检测效果。原始点的方式直接从初始点云数据中提取特征,相较于网格化的方式保留更多目标细粒度信息,但是逐点特征提取带来高昂的计算代价。基于多模态融合的方法则通过增加图像数据处理分支,对点云分支进行信息补充,缓解小目标物体漏检问题,但异构数据融合困难,计算复杂度较高,网络推理速度较低。文中为平衡网络精度和实时化性能,选取体素检测算法Voxel–RCNN[15]作为基线网络,并在此网络上进行分析和改进,实现对中小目标检测效果的提升。Voxel–RCNN网络第1阶段和SECOND[16]结构雷同,主要由3个部分组成:体素特征编码模块、三维稀疏特征提取模块、二维主干网络。其中,体素特征编码模块对输入点云进行均匀采样和特征处理,得到体素级特征表示。三维稀疏特征提取模块对输入的体素特征进行稀疏化及卷积运算等相关操作,实现对浅层特征的深层抽象。二维主干网络于二维鸟瞰图上进行最终检测,生成三维检测框。然而,SECOND网络在稀疏卷积特征提取模块仅使用简单的卷积塔结构对特征进行下采样抽象,忽略了多层特征之间的信息补充。二维主干网络由下采样层、上采样层组成,虽然在上采样层进行特征堆叠实现特征粗略的融合,但是忽略了多级特征之间的相关性。Voxel–RCNN第2阶段的精化模块仅对最高级的体素稀疏特征进行小范围特征搜索,忽视了低级特征和多范围邻域特征的重要性。为了解决以上不足之处,文中对Voxel–RCNN网络进行改进,设计基于多级特征融合的体素三维目标检测网络。
1 网络设计
提出的基于多级特征融合的体素三维目标检测网络结构见图1,主要包含4个部分:稀疏特征残差密集融合模块、残差轻量化高效通道注意力机制、多级特征及多尺度核自适应融合模块和三重特征融合策略。文中主要改进点如下。
1)在三维稀疏特征提取部分设计稀疏特征残差密集融合模块(Sparse Feature Residual Dense Fusion Module,SFRDFM)。为了高效地处理三维特征,使用三维稀疏卷积[17]和子流形卷积[18]算法,设计稀疏特征残差半密集融合层,混合叠加此卷积层形成主干,缓解特征冗余的同时加强逐层特征之间的信息交流补充。
2)在二维主干网络模块中,通过降低特征通道数量以降低计算量,同时增加残差轻量化高效通道注意力机制(Residual Light-Weight Efficient Channel Attention Mechanism,RL-ECA)对损失的通道信息进行补充增强,减少计算量的同时提升了检测器性能。
3)在二维主干网络上采样阶段增加了多级特征及多尺度核自适应融合模块(Module of Multi-Level Feature And Multi-Scale Kernel Adaptive Fusion,MFMKAF),通过编码多级特征依赖关系,自适应地融合低层空间特征,中层复合特征和高层语义特征,实现多级特征之间的交流融合,进一步提升特征表达能力。
4)在第二阶段精化模块部分,设计三重特征融合策略(Triple Feature Fusion Strategy,TFFS),包含多级特征融合、多范围分组聚合和多尺度格点采样策略,组合以上3种策略用于二次搜索聚合体素稀疏特征。并设计2种不同的格点特征融合模块:深度融合模块(Deep Fusion Module,DFM)对输入特征进行多重提取压缩融合;由细粒度到粗粒度的融合模块(Coarse to Fine Fusion Module,CTFFM)自适应地融合输入特征,生成更具区分性的格点特征,进一步精化三维建议框。

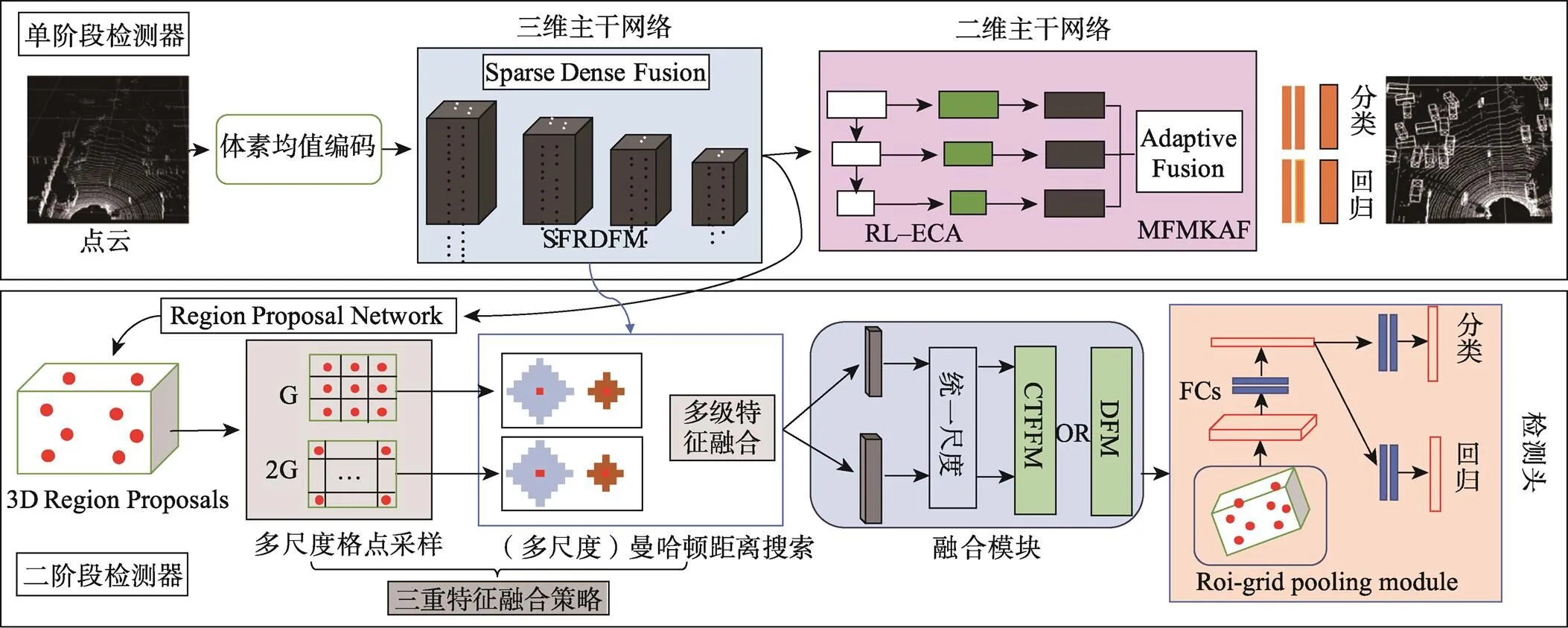
图1 文中提出的三维目标检测网络框架图

图2 稀疏特征残差密集融合模块
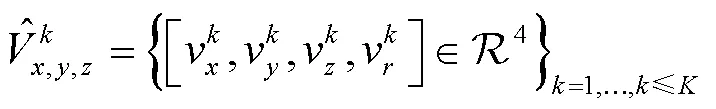
接下来使用卷积算法对特征进行深层处理。
1.1 稀疏特征残差密集融合模块
在点云体素化过程中有超过90%体素为空值体素,传统三维稠密[19]卷积会遍历所有区域,加大计算代价和内存负担的同时,还会导致稠密数据失真。为了进一步的提升体素特征提取算法的实时性,Graham等[17]提出稀疏卷积(SC)和子流形卷积算法[18](SSC)替换稠密卷积,保证稀疏算法仅在稀疏化数据上运行,核心思想是通过输入数据的稀疏性限制输出数据的稀疏性,降低三维卷积操作的计算量和内存占用。为缓解稀疏卷积(SC)随着网络深度的扩展出现稀疏性弱化的问题,增加子流形卷积(SSC)算法处理数据,此算法仅对输入的非空值区域进行相应运算,且只对非空值区域赋值,最大程度保持数据稀疏性。对于深层特征提取网络而言,多层特征图包含多尺度详细信息,这些信息对于场景中目标的检测是非常有用的。Voxel-RCNN的三维骨架是经典的由浅入深式稀疏卷积下采样结构,考虑到此结构忽视了各层特征之间的信息交流,损失大量的细粒度信息。为缓解以上问题,文中在此基础上设计了稀疏特征残差密集融合模块(Sparse Feature Residual Dense Fusion Module,SFRDFM),模块结构见图2。由于子流形卷积(SSC)对有值位置作强制限制导致一定程度的信息丢失,稀疏卷积(SC)带来位置信息失真的缺点,文中采用稀疏卷积和子流形卷积混用的结构平衡两种算法带来的问题。首先叠加5层子流形卷积对输入的稀疏体素数据进行特征处理,再叠加一层稀疏卷积(SC)和4层子流形卷积(SSC)继续提取特征。密集融合前3层和后3层稀疏特征,这里称为稀疏特征残差半密集融块(Sparse feature Residual Semi-Dense fusion Block,SRSDFB),以半数融合5层特征方式,防止过多特征叠加冗余,影响检测效果。区别于文献[20]通道堆叠(Concatenation)方式,模块使用逐元素相加进行融合,达到稳定网络训练、降低计算代价、复用浅层特征的作用。通过使用步长为2的稀疏卷积和ReLU激活函数进行特征下采样,得到3组不同尺度的稀疏特征,起到特征由低到高的抽象、增大感受野和降低特征维度的作用。理论上可以对SRSDFB叠加更多子流形卷积层设计更深的特征提取模块,但考虑到推理时间的消耗和参数复杂度提升,仅使用5层叠加形式。
1.2 二维特征自适应融合模块
如果在三维特征图上生成锚框(Anchor)将出现数量过多的空三维框,导致计算资源的负担和正负锚框不平衡的问题。而在自动驾驶场景中,目标物体基本处于地面上,目标空间位置相对固定,位于轴的高度信息变化较小,为了进一步降低计算复杂度,将三维特征图沿着轴方向向下投影得到二维鸟瞰特征图表示,再基于鸟瞰图进行三维框的估计。文中二维主干网络模块见图3,此模块在基线网络的基础上进行改进,在初始的2层卷积塔结构上增加第3层卷积块,并增加残差轻量化高效通道注意力机制和多级特征及多尺度核自适应融合模块。
1.2.1 二维卷积塔模块
本模块由常规的特征下采样和上采样结构组成,模块架构图如图3中左框图所示。文中在基线网络Voxel-RCNN的第1阶段卷积下采样模块增加一组卷积块得到3层卷积塔结构,加深网络特征提取能力和尺度变化,此3组卷积块均是常规的5层二维卷积堆叠组成,用作提取鸟瞰图的语义信息。文中将自上而下的3组卷积块命名为卷积块_0,卷积块_1,卷积块_2。将卷积块_0的步长设置为1,输出通道数为64,卷积块_1和卷积块_2的步长设置为2,输出通道递增为128和256,此操作对特征进行提取抽象的同时起到缩减特征尺度和增大感受野的功能。
其中卷积块_0可以保留更细节的目标位置信息,卷积块_1可提取到相对细节的位置信息和语义信息,卷积块_2提取得到更加抽象的语义信息。上采样结构则使用转置卷积操作对下采样模块中输出的不同尺度的特征图进行尺度恢复,并且固定3组特征通道数为128,相比于原网络,此操作加深卷积层的同时降低了通道数量,虽然损失了一些有效信息,但是增加了小尺度的特征计算,能够提升大目标的检测性能,而且通过压缩特征通道数量去降低计算代价,维持计算量的平衡。
1.2.2 残差轻量化高效通道注意力机制
由于在上采样阶段减少了特征通道数量,虽然降低了计算复杂度,但是会损失一些有效信息导致特征质量降低,为缓解此问题,在该模块中增加残差轻量化高效通道注意力机制(Residual Light-weight Efficient Channel Attention Mechanism,RL-ECA)对以上3组特征的通道信息进行特征增强。该模块的网络架构见图4。沿用文献[21]的网络框架,此文献中注意力模块首重轻量化及高效性,通过使用一维卷积实现跨通道的信息交互来降低计算复杂度。区别于其他注意力模块在特征提取阶段的维度压缩操作,此模块通过保持通道数量恒定的方式,保留更多通道信息。文中在此基础上进行简单修改,移除自适应卷积核提取函数,固定一维卷积提取核的尺寸为3,增加残差融合操作对输出特征进行有效补偿,详细过程见式(2)。
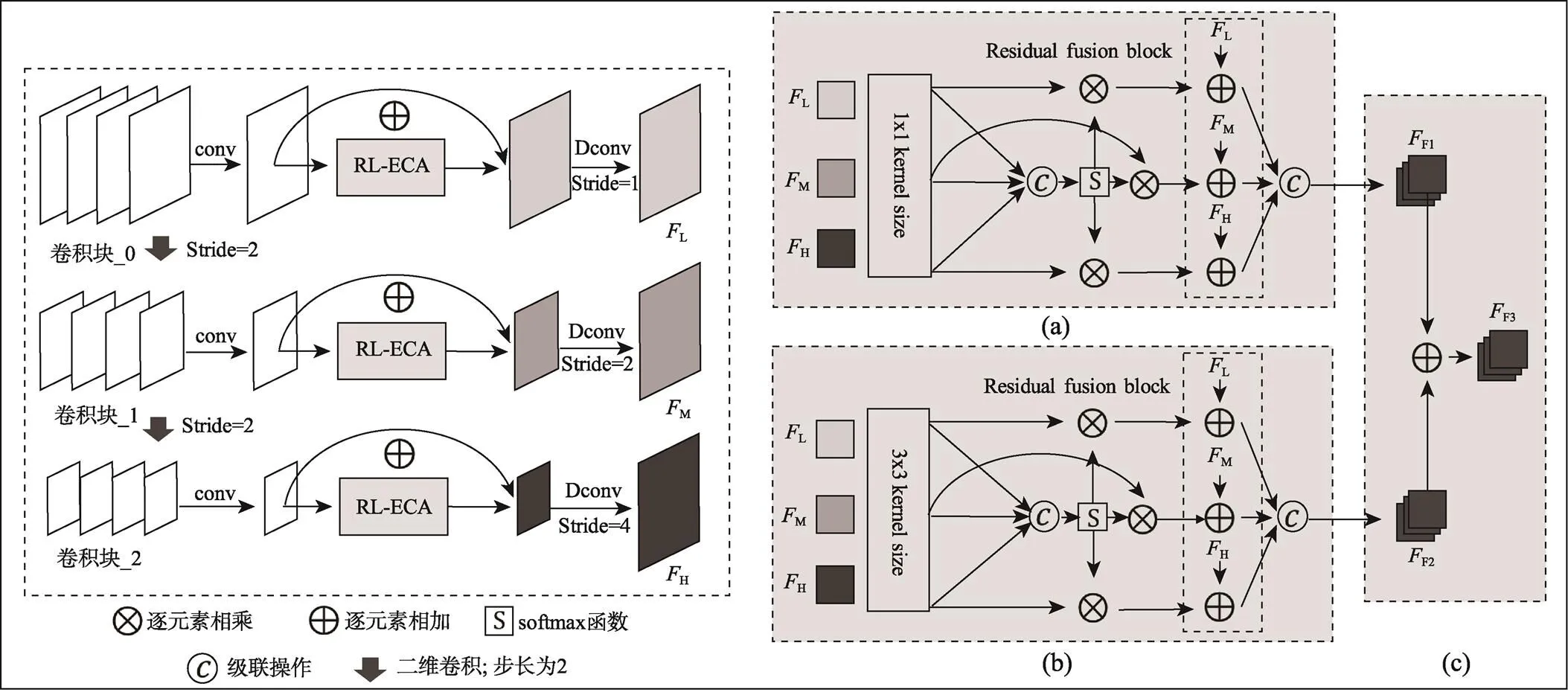
图3 多级特征及多尺度核自适应融合模块

式中:为输入特征;为全局平均池化;为sigmoid函数。
1.2.3 多级特征及多尺度核自适应融合模块
在卷积塔结构中获取了3种不同级别的特征,分别是低层空间特征、中层复合特征和高层语义特征。基线网络中作者仅对多级特征进行简单的堆叠融合(这里称为弱融合操作),没有充分利用不同级别特征的依赖关系。考虑到多级特征对于目标精确定位和分类的重要性[22-23],文中设计了多级特征及多尺度核自适应融合模块(Module of Multi-Level Feature And Multi-Scale Kernel Adaptive Fusion,MFMKAF)对3种级别的特征进行深层的融合。此模块的网络框架如图3右半部分a、b、c 3个框图所示。首先使用多尺度的卷积核将3组特征图压缩成1维通道,对其空间信息进行自适应的特征提取。如模块a所示,使用1×1尺寸卷积核对多级特征分别处理,然后在通道维度上对3组1维的权重图进行堆叠拼接(Concatenation),并使用Softmax函数归一化建立三组特征之间的关联性得到空间权重,详细过程见式(3)。
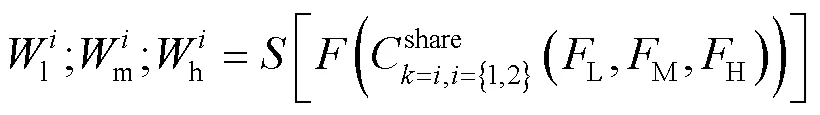
式中:表示堆叠融合(Concatenation);表示Softmax函数;表示卷积算子。
将3组权重和相应的输入特征逐元素相乘后逐通道堆叠融合(Concatenation),再增加残差融合块(Residual Fusion Block,RFB)将输入特征以加和的方式融合到新特征上,从而实现多级特征自适应的强融合,详细过程见式(4)。
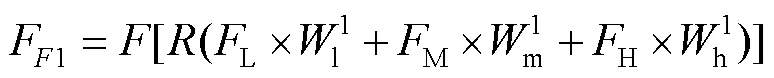
模块b整体流程似模块a,详细过程见式(5)。

二者区别在于不同尺度的核操作,模块a采用1×1核,能够提取更详细的小目标位置信息,模块b采用3×3核,能够提取较大目标位置信息,交替使用模块a、b能够让网络拟合不同的任务要求。模块c则是将模块a、b输出的特征进一步的相加融合,从而得到更具表达能力的新特征,详细过程见式(6)。
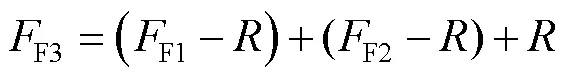
1.3 三重特征融合策略
体素化三维检测网络分为单阶段和两阶段三维检测器[24],两者主要区别在于两阶段算法增加了区域建议模块(RPN)和精化模块。其中,精化模块的主要作用是对区域建议模块得到的三维建议框进一步的细化处理,一定程度上增加了计算量,但对精度提升较大。
一阶段检测器将特征处理成二维鸟瞰特征表达,降低了计算代价,但忽略了三维空间结构信息。Voxel–RCNN通过增加二阶段精化模块,对具有完整三维结构的体素稀疏特征进行相关操作,恢复特征的三维结构上下文信息。首先基于RPN网络对鸟瞰特征进行处理,生成大量三维建议框(3D Region Proposals)。然后将三维框进行网格分割,将分割格点作为关键点保存并映射回稀疏体素特征空间,基于关键点对邻域内的体素特征进行二次采集,获取的格点特征用于进一步精化三维框。
1.3.1 多级特征融合
对于稀疏的点云场景而言,低级特征具备更多的细粒度信息,为进一步获取信息量丰富的格点特征,Voxel–RCNN采用多级特征融合策略。具体结构见图5中的模块a。通过对各个级别的稀疏体素特征进行曼哈顿距离搜索,将采集的L2、L3和L4级体素特征进行堆叠(Concatenate)融合,然后进行三维候选框的进一步精化。
1.3.2 多范围分组聚合
对于场景检测任务而言,目标局部邻域的范围大小选取尤为重要,搜索范围越小,能采集到的有效信息越少,相反,搜索范围越大,能采集的信息越多,但过大范围会引入更多的背景噪声,影响检测性能。文中对曼哈顿距离搜索算法设置2种大小不同的度量距离,分别为和2,同时作用于特征空间进行信息采集,获取基于格点的多范围邻域特征,最后将两种范围内的邻域特征进行堆叠(Concatenate)融合。详细结构见图5中的模块b。
1.3.3 多尺度格点采样
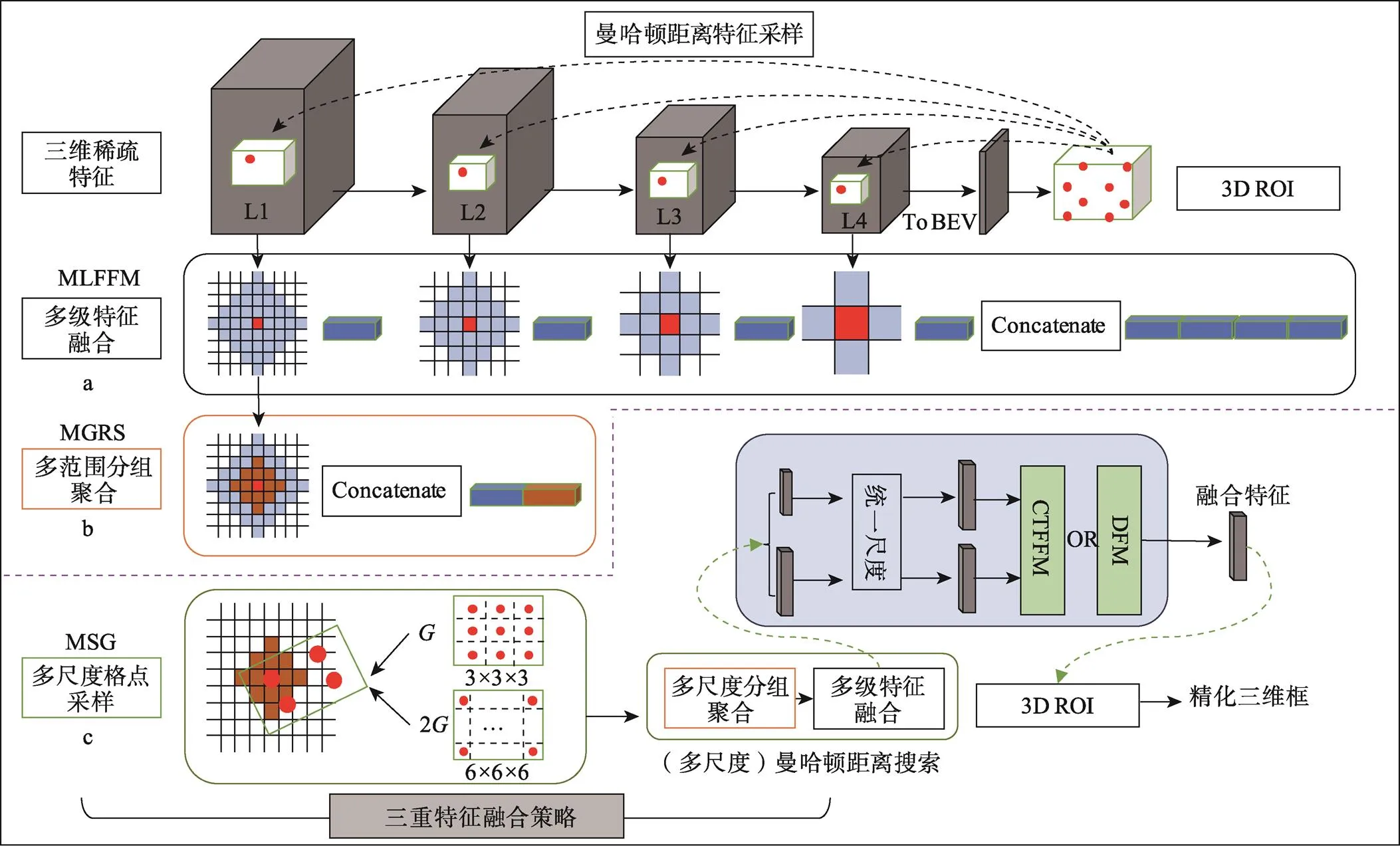
图5 三重特征融合策略
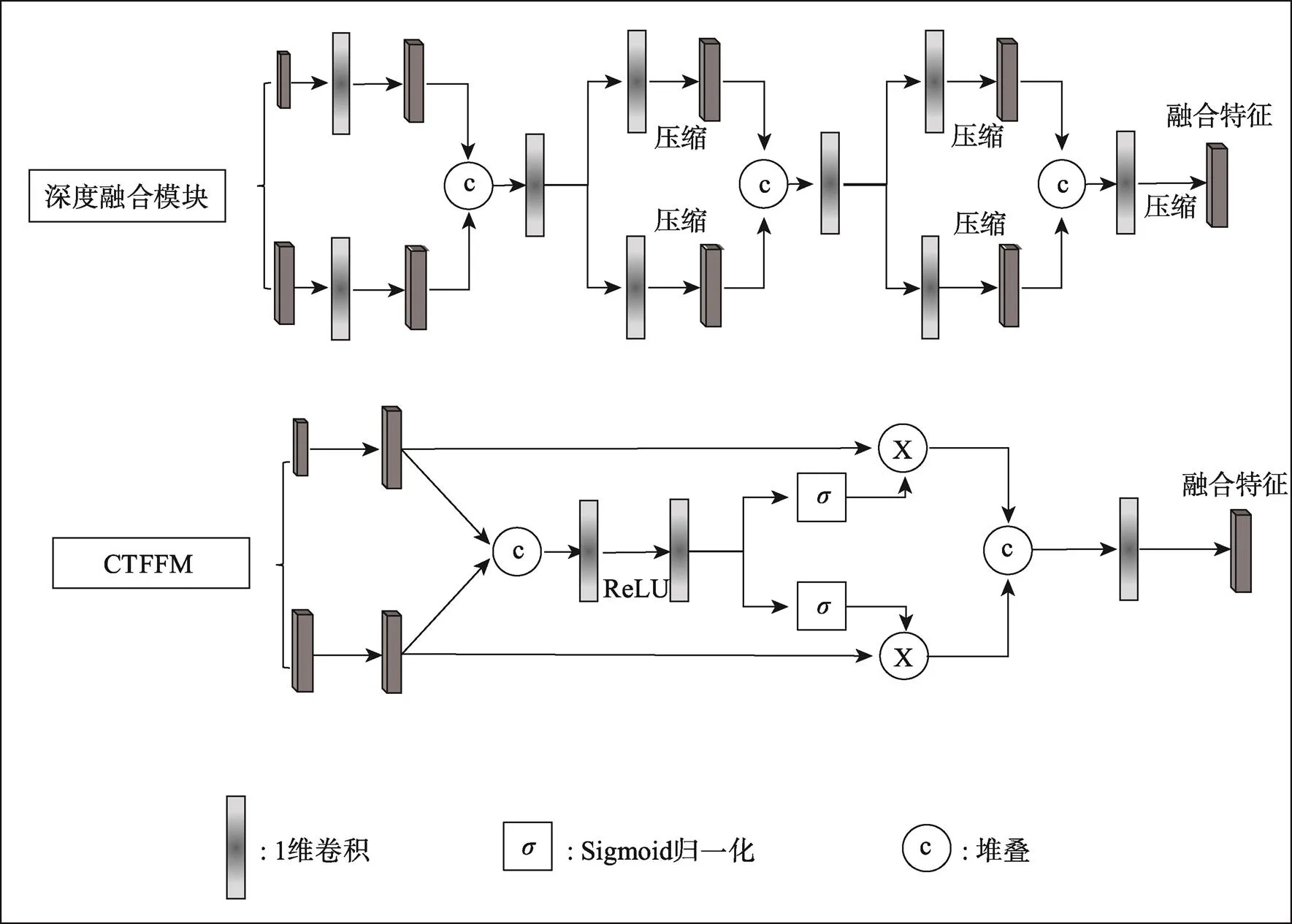
图6 格点特征融合模块
1.4 损失函数
为优化网络,文中使用和文献[4]相同的锚框设置和损失函数,对于每个锚框(Anchors),使用7维向量表示框的位置,1维向量表示类别信息。本网络需要预测汽车、行人、骑行者三种类别,不同类别需要匹配不同的IOU阈值来筛选正负锚框,分别计算出3种类别的锚框和真实框的交并比。对于汽车而言,如果交并比大于0.6则被认为是正锚框,小于0.45则被认为是负锚框,其他锚框不做训练使用,行人和骑行者的设定阈值为[0.35, 0.5]。
文中损失函数设置主要分为2个部分。
第1部分为RPN损失函数,详细见式(7)。

第2部分为检测头损失,详细见式(8)。
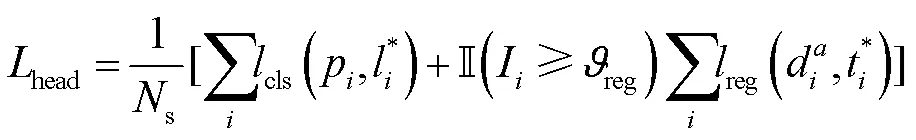
2 实验结果与分析
2.1 实验配置
文中网络使用的服务器硬件配置为:Linux64位操作系统:Ubuntu 18.04,英伟达RTX 3080 10 GB显卡。
环境配置为:Pytorch1.8.0、python3.7.2、CUDA11.3、CUDNN11.3。
网络参数设置:将点云数据进行范围切割,范围为[0, 70.4],[−40, 40],[−3, 1](单位:米),对切割好的点云数据进行体素化,其中单个体素的分辨率为[0.05, 0.05, 0.1]。设置3种类别的锚框(Anchors)尺寸:汽车为[1.9, 3.6, 1.56]、行人为[0.6, 0.8, 1.73]、骑行者为[0.6, 1.76, 1.73],计算锚框和真实框的交并比(IOU)并根据设定阈值筛选正负锚框。在训练时使用初始学习率为0.003的Adam[29]优化器,优化动量参数为0.9,该实验在单个GPU上训练,batch_size设置为2,一共训练80个epochs。
2.2 数据集和数据评估
实验使用KITTI[30]数据集,使用不同的传感器对市区、乡村、高速公路等主要场景进行数据采集,其中三维点云数据由64线激光雷达扫描获得,根据数据场景中目标遮挡程度,目标尺寸,截断程度等因素,将目标难易度划分为3个等级:简单、中等、困难。根据训练和测试要求划分,获取7 481个样本的训练集和7518个样本的测试集,再将训练集被进一步的划分为3 712个训练样本和3 769个验证样本。参考文献[11,16]的测试和验证标准,文中对目标中汽车(Car)、行人(Pedestrians)、骑行者(Cyclist)3种主要类别进行评估。
为验证文中算法性能,实验结果将和当前的主流网络进行对比。使用平均精度(Average Precision)作为评估指标,设置汽车(Car)交并比的阈值为0.7,行人(Pedestrians)和骑行者(Cyclist)阈值为0.5,并对简单、中等、困难等级的目标分别进行验证。
2.3 主流网络对比实验
该小结将网络验证结果和当前的主流三维目标检测网络结果进行比较,表1、表2分别展示了汽车(Car)、骑行者(Cyclist)、行人(Pedestrian)在3D和鸟瞰图指标下的检测精度。并且对简单(Easy)、中等(Moderate)、困难(Hard)3个等级的目标分别进行评估。
实验结果如上图表1和表2所示,其中*表示基线网络(baseline),由表1和表2结果可知,增加了SFRDFM、RL–ECA和MKMKAF的一阶段网络和SECOND网络比较,在3D指标下行人类别的3种难度等级检测精度分别提升了6.37%、3.26%和2.28%,在鸟瞰图指标下分别提升了5.02%、2.84%和2.22%,并且在汽车和骑行者两种中大型目标类别均有小幅提升。
在一阶段结构基础上增加TFFS和CTFFM的二阶段网络和Voxel-RCNN比较,在3D指标下骑行者类别的3种难度等级检测精度分别提升了3.2%、3.92%和3%,在鸟瞰图指标下提升了1.81%、3.07%和2.99%,并且在汽车和骑行者均有不同程度的提升和下降。由此可证明提出的方法能够有效提升检测器性能。
表1 KITTI数据集中不同类别在3D指标下和主流网络结果对比
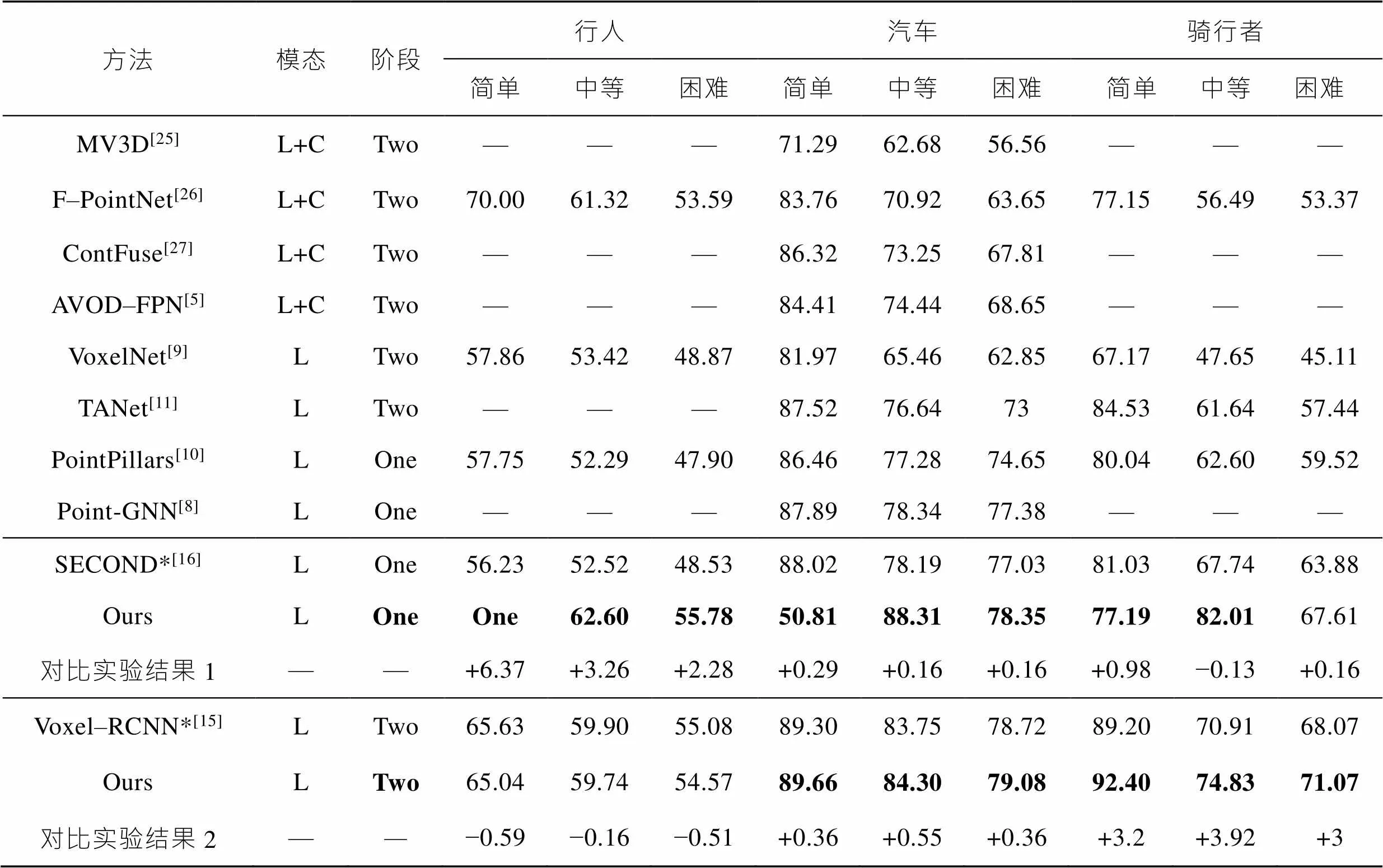
Tab.1 Comparison of the results of pedestrians, cars and cyclists in the KITTI data set with the mainstream network under 3D indicators
注:L+C表示激光雷达和相机多模态融合方法;*表示基线网络;加粗数字表示最优效果。
表2 KITTI数据集中不同类别在鸟瞰图指标下和主流网络结果对比
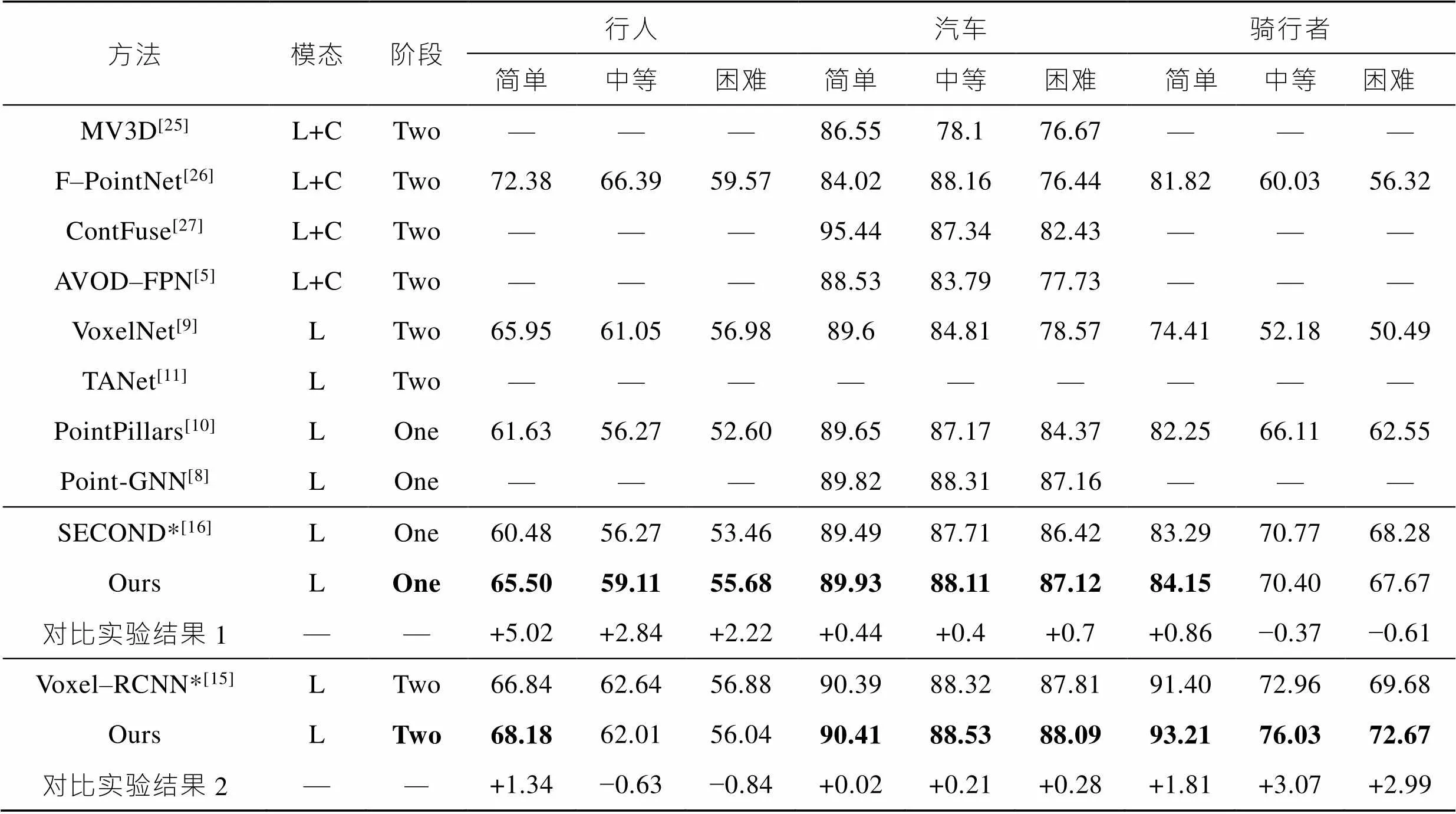
Tab.2 Comparison of the results of pedestrian, car and cyclist in KITTI data set with the mainstream network under aerial view indicators
注:L+C表示激光雷达和相机多模态融合方法;*表示基线网络;加粗数字表示最优效果。
2.4 消融实验
此章节对上文一阶段的三组模块和二阶段的2组模块分别进行组合实验。
一阶段:表3中,组合1、2和3可知,SFRDFM模块、RL–ECA模块和MFMKAF单模块均提升了3种类别目标的检测效果,证明了3种模块的有效性。组合4使用2种模块,中等难度下,行人类别目标检测精度有较高上升,其他类别有所下降。组合5、6和7是3种模块的组合实验,从组合7的实验结果来看,小尺度核的模块a能够显著提升行人类的小目标效果,由组合6的实验结果可知,中尺度核的模块b能够提升骑行者此类中型目标检测效果,组合5实验结果可知融合模块c能够提升目标检测综合性能,但单一类别检测性能方面有所降低。综合以上实验证明改进网络能够更好地学习小目标的特征信息,并且灵活的模块搭配能够应对更多的任务要求。
二阶段:表4中,组合1和组合2表示三重融合策略中第3个多尺度格点采样策略的分解实验,格点尺度分别为3和6的二阶段网络检测结果,尺度为3时,行人效果较好,尺度为6时,汽车和骑行者效果提升显著。组合3是融合2种尺度格点特征的检测结果,相较组合1和组合2,3种目标类别精度均有提升。组合4表示在三重融合策略基础上增加了深度融合模块(DFM),结果表明此模块能较高提升骑行者指标。组合5在三重特征融合策略基础上增加了CTFFM模块,相较于深度融合模块,此模块能够进一步提升骑行者指标,且在汽车类别也有小幅提升。
表3 SFRDFM、RL–ECA和MFMKAF 3组模块组合对比实验(一阶段)
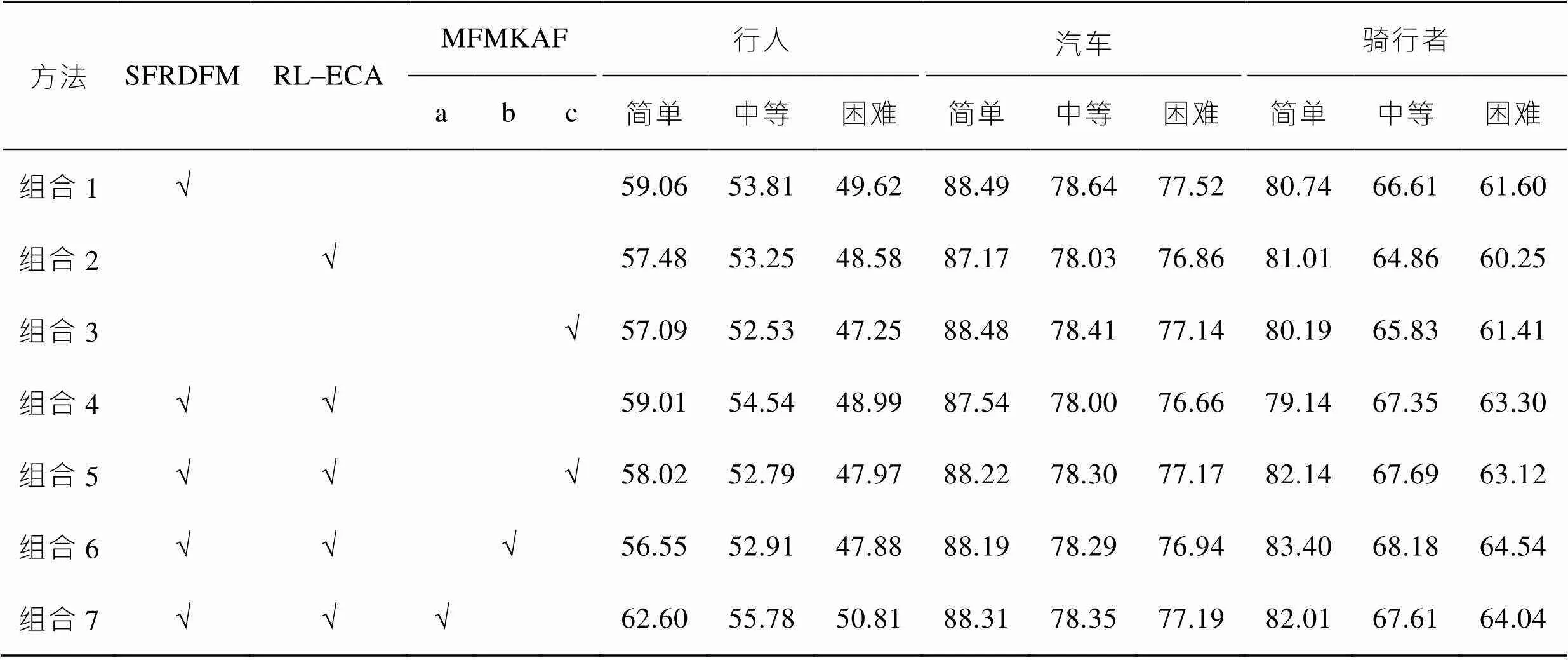
Tab.3 Comparison experiment of three sets of module combination of SFRDFM, RL-ECA and MFMKAF (the first stage)
表4 TFFS和GFFM 2组模块组合对比实验(二阶段)
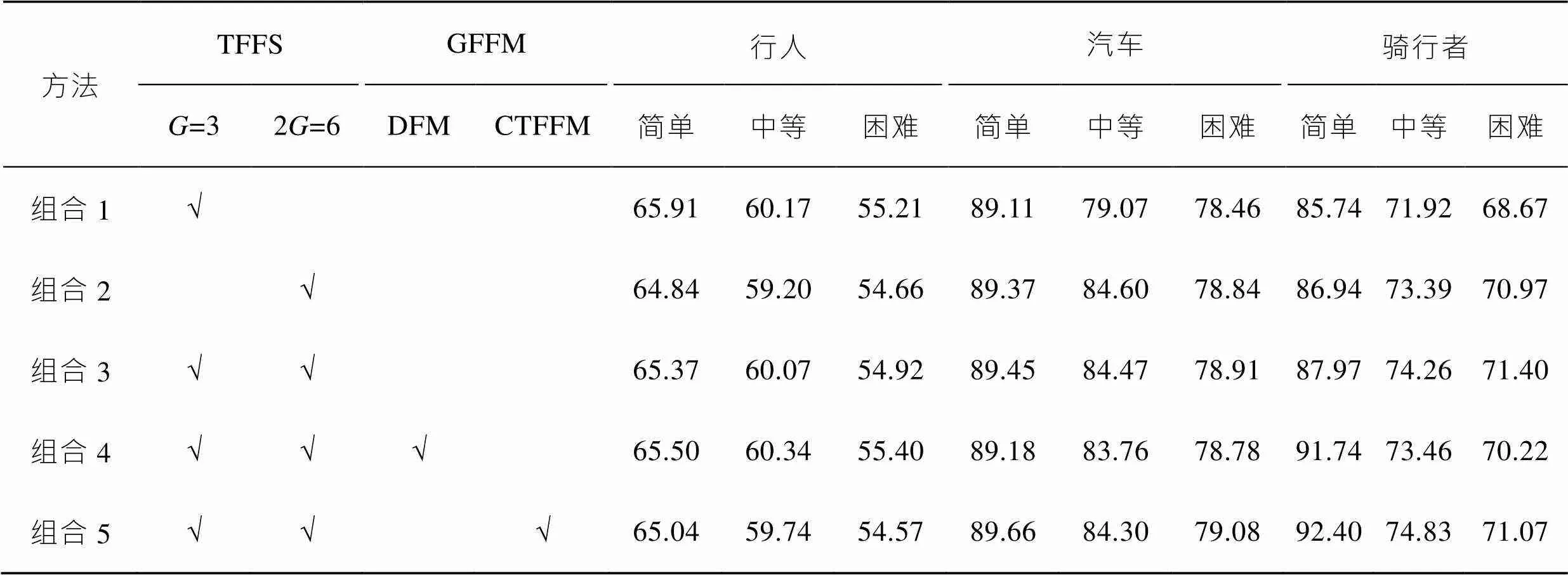
Tab.4 Comparison experiment of two sets of module combination of TFFS and GFFM (the second stage)
2.5 点云结果可视化
对改进网络的检测结果进行可视化,一共处理了6组场景,每组场景分别由原始图像、基线网络和文中网络(一阶段)和(二阶段)可视化结果4张图像组成。
可视化图见图7。从图7a的点云可视化实例分析可知,文中检测网络均可很好的学习到汽车类别信息,并有效提升了汽车精度。图7b—e场景中,基线网络出现大量的误检结果,如图7中矩形框所示,将杂物识别成汽车行人等类别,而文中检测网络误检结果逐渐变少。图7f场景下,文中网络能够很好的检测行人目标,且遮挡问题情况下,依然能够正确分类汽车目标,而基线网络错把汽车识别成行人。以上可视化结果可直观表明文中算法的有效性。

3 结语
文中以体素两阶段网络为基础,于一阶段框架中增加稀疏特征密集融合模块,对稀疏特征逐层进行半密集融合,加强浅层小目标特征复用的同时减少特征冗余。使用轻量化残差高效通道注意力机制稳定计算量的同时对通道特征进行增强。提出多级特征及多尺度核自适应融合模块,以不同尺度的卷积核自适应编码多级特征之间的依赖关系,设置3种不同的融合模块以适应不同的任务要求。在2阶段,设计了三重特征融合策略,对三维体素稀疏特征空间进行密集的邻域信息搜索聚合,并提出深度融合模块(DFM),使用3组双层卷积块对格点特征进行多层次的深度特征抽象融合。另外,还设计CTFFM模块分析2组格点特征的依赖关系,有区分性地融合2组特征以提升特征表达能力,从而进一步提升了检测框的输出质量。
[1] MEYER G P, LADDHA A, KEE E, et al. LaserNet: An Efficient Probabilistic 3d Object Detector for Autonomous Driving[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019: 12677-12686.
[2] QI C R, SU H, MO K, et al. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 652-660.
[3] QI C R, YI L, SU H, et al. PointNet++: Deep Hierarchical Feature Learning on Point Sets in A Metric Space[J]. Advances in neural information processing systems, 2017: 30-39.
[4] BELTRÁN J, GUINDEL C, MORENO F M, et al. BirdNet: A 3d Object Detection Framework from Lidar Information[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 3517-3523.
[5] Ku J, Mozifian M, Lee J, et al. Joint 3D Proposal Generation and Object Detection from View Aggregation[C]// Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2018: 1-8.
[6] Liang M, Yang B, Chen Y, et al. Multi-task and Multi-sensor Fusion for 3D Object Detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019: 7345-7353.
[7] Paigwar A, Erkent O, Wolf C, et al. Attentional PointNet for 3D Object Detection in Point Clouds[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019: 1357-1369.
[8] Yan Y, Mao Y, Li B. SECOND: Sparsely Embedded Convolutional Detection[J]. Sensors, 2018, 1: 3337-3344.
[9] Shi W, Rajkumar R. Point-GNN: Graph Neural Network for 3D Object Detection in A Point Cloud[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1711-1719.
[10] Zhou Y, Tuzel O. Voxelnet: End-to-end Learning for Point Cloud Based 3D Object Detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 4490-4499.
[11] Lang A H, Vora S, Caesar H, et al. PointPillars: Fast Encoders for Object Detection from Point Clouds[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 12697-12705.
[12] Liu Z, Zhao X, Huang T, et al. TANet: Robust 3D Object Detection from Point Clouds with Triple Attention[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 11677-11684.
[13] Deng J, Shi S, Li P, et al. Voxel-RCNN: Towards High Performance Voxel-Based 3D Object Detection[C]// Proceedings of the AAAI Conference on Artificial Intelligence, 2021: 1201-1209.
[14] Shi S, Wang X, Li H. PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 770-779.
[15] 李文举, 储王慧, 崔柳,等. 结合图采样和图注意力的3D目标检测方法[J/OL]. 计算机工程与应用, 2022: 1-9. http://kns.cnki.net/kcms/detail/11.2127.TP.20220422. 1214.006.html
LI Wen-ju, CHU Wang-hui, CUI Liu, et al. 3D Object Detection Method Combining on Graph Sampling and Graph Attention[J/OL]. Computer Engineering and Applications, 2022: 1-9. http://kns.cnki.net/ kcms/detail/11. 2127.TP.20220422.1214.006.html.
[16] Ding Z, Han X, Niethammer M. Votenet: A Deep Learning Label Fusion Method for Multi-Atlas Segmentation[C]// Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, 2019: 202-210.
[17] Graham B. Sparse 3D Convolutional Neural Networks[C]// Proceedings of the British Machine Vision Conference, 2015: 356-368.
[18] Graham B, Engelcke M, Van Der Maaten L. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 9224-9232.
[19] Yan C, Salman E. Mono3D: Open Source Cell Library For Monolithic 3D Integrated Circuits[J]. IEEE Transactions on Circuits and Systems I, 2017, 65(3): 1075-1085.
[20] Huang G, Liu Z, Van Der Maaten L, et al. Densely Connected Convolutional Networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 4700-4708.
[21] Wang Q, Wu B, Zhu P, et al. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 11534-11542.
[22] Yoo J H, Kim Y, Kim J, et al. 3D-CVF: Generating Joint Camera and Lidar Features Using Cross-View Spatial Feature Fusion for 3D Object Detection[C]// Proceedings of 16th European Conference on Computer Vision (ECCV), 2020: 720-736.
[23] Zheng W, Tang W, Chen S, et al. CIA-SSD: Confident IoU-aware Single-Stage Object Detector from Point Cloud [C]//Proceedings of the AAAI conference on artificial intelligence. 2021, 35(4): 3555-3562.
[24] Shi S, Guo C, Jiang L, et al. PV-RCNN: Point-voxel Feature Set Abstraction for 3D Object Detection[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 10529-10538.
[25] Chen X, Ma H, Wan J, et al. Multi-View 3D Object Detection Network for Autonomous Driving[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1907-1915.
[26] Qi C R, Liu W, Wu C, et al. Frustum Pointnets for 3D Object Detection from RGB-D Data[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 918-927.
[27] Liang M, Yang B, Wang S, et al. Deep Continuous Fusion for Multi-sensor 3D Object Detection[C]//Proceedings of the European Conference on Computer Vision (ECCV), 2018: 641-656.
[28] Lin T Y, Goyal P, Girshick R, et al. Focal Loss for Dense Object Detection[C]// Proceedings of the IEEE International Conference on Computer Vision, 2017: 2980-2988.
[29] Kingma D P, Ba J. Adam: A Method for Stochastic Optimization[J]. International Conference for Learning Representations, 2014, 21(12): 6980-6995.
[30] Geiger A, Lenz P, Stiller C, et al. Vision Meets Robotics: The KITTI Dataset[J]. The International Journal of Robotics Research, 2013, 32(11): 1231-1237.
Voxel-based 3D Object Detection Network Based on Multi-level Feature Fusion
ZHANG Wu-rana, HU Chun-yana,CHEN Ze-laia,LI Fei-feib
(a. School of Optical-electrical and Computer Engineering b. School of Medical Instrument and Food Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China)
The work aims to accurately analyze the location and classification information of the object to be tested in the point cloud scene, and propose a voxel-based 3D object detection network based on multi-level feature fusion. The two-stage Voxel-RCNN was used as the baseline network. In the first stage, the Sparse Feature Residual Dense Fusion Module (SFRDFM) was added to propagate and reuse the level-by-level features from shallow to deep, to achieve full interactive fusion of 3D features. The Residual Light-weight and Efficient Channel Attention (RL-ECA) mechanism was added to the 2D backbone network to explicitly enhance channel feature representation. A multi-level feature and multi-scale kernel adaptive fusion module was proposed to adaptively extract the weight information of the multi-level features, to achieve a strong fusion with a weighted manner. In the second stage, a Triple Feature Fusion Strategy (TFFS) was designed to aggregate neighborhood features based on the Manhattan distance search algorithm, and a Deep Fusion Module (DFM) and a Coarse to Fine Fusion Module (CTFFM) were embedded to improve the quality of grid features. The algorithm in this paper was tested in the autonomous driving data set KITTI. Compared with the baseline network at three difficulty levels, the average 3D accuracy of pedestrians in the first stage detection model was improved by 3.97%, and the average 3D accuracy of cyclists in the second stage detection model was improved by 3.37%. The experimental results prove that the proposed method can effectively improve the performance of object detection, each module has superior portability, and can be flexibly embedded into the voxel-based 3D detection model to bring corresponding improvements.
3D object detection; residual fusion; adaptive fusion; feature enhancement; triple feature fusion
TP311
A
1001-3563(2022)15-0042-12
10.19554/j.cnki.1001-3563.2022.15.005
2022–05–16
上海市高校特聘教授(东方学者)岗位计划(ES2015XX)
张吴冉(1995—),男,上海理工大学硕士生,主攻计算机视觉与目标检测。
胡春燕(1976—),女,硕士,上海理工大学讲师,主要研究方向为图像处理与模式识别、计算机视觉等。
责任编辑:曾钰婵
