基于Intel DPDK的高性能数据流处理技术的实现
2022-08-23北京电子科技职业学院牟晓玲张萍董大波
北京电子科技职业学院 牟晓玲 张萍 董大波
在网络监控与管理领域,防火墙、上网行为管理、IDS、IPS等产品都需要对数据包进行采集和分析。本文在深入研究Intel DPDK技术的基础之上,利用DPDK设计了一套具有普适性的高性能数据流处理系统,使用TCPReplay对该系统进行测试,验证了在高速率高并发的网络环境中,该系统能高效抓取数据包并维护通用数据流表,最后将其成功的应用在了上网行为管理系统和上网行为审计系统中。
1 传统Linux捕包方式
传统Linux捕包的方法主要有三种:(1)Libpcap,利用数据链路层捕包接口PF_PACKET的捕包程序库。该接口为通用的网络应用程序设计,接口简单且和底层网卡驱动无关,但是效率不高。(2)PF_RING,开源的捕包接口,其原理是在内核开辟环形缓冲区,通过在内核队列注册HOOK函数获取数据包并放入环形缓冲区,这个环形缓冲区数据包只进行了一次内存拷贝,比通用的方法PF_PACKET效率高很多。(3)零Copy机制,这种机制下,网卡的数据包直接拷贝到用户空间,而且是零系统调用。这种机制的包捕获效率高,但是需要修改网卡驱动,和硬件相关。
基于传统Linux捕包在高速网络下的问题,本文基于DPDK平台进行数据包捕获和会话流管理。
2 Intel DPDK技术原理
Intel DPDK全称Intel Data Plane Development Kit,是Intel提供的数据平面开发工具集,它专注于网络应用中数据包的高性能处理。具体体现在DPDK应用程序绕过了Linux内核协议栈对数据包的处理过程,从而大幅提升了数据包收发处理的速率。DPDK架构一共由五个组件构成:环境适应层EAL(Environment Abstraction Layer):提供了一套API,主要用于系统的初始化; 缓冲区管理(Buffer Management ): 提供了一套API,用于获取内存和创建缓冲池;环管理(Ring Functions):针对入列和出列操作提供了无锁的实现,支持大批量操作以减少开销;流分类(Packet Flow Classification)和轮询模式驱动程序(NIC Poll Mode Library)。
鉴于这种架构,基于DPDK的用户态软件崩溃,不会影响系统的稳定性。同时避免了内核态和用户态的报文拷贝,减少了操作系统的内核开销,从而实现了加速;研究表明,DPDK可以将数据包处理性能最多提高十倍。
3 高性能数据流表技术
3.1 基于DPDK的数据包采集技术
在高速率高并发的网络环境中,采用基于DPDK的高速数据包捕获技术进行数据包抓取。捕包模块同时从不同的网卡抓包,为了提高处理效率,每个网卡均有相应的抓包线程,同时可以根据配置文件中的配置规则进行条件抓包,所有的抓包线程将所抓取的数据包存储在一个共享缓冲区中。具体的抓包过程如下:
(1)使用函数rte_eal_init对DPDK应用程序进行环境抽象层(EAL层)初始化工作。包括获取系统可用的CPU数量、查询可用的PCI网卡设备、建立日志文件等。
(2)使用函数init_port对端口进行初始化配置,查看和配置对应端口的状态。
(3)使用函数init_mbuf_pools对DPDK的mbuf和pool队列进行初始化。
(4)利用死循环,持续从网卡抓包。在循环中,使用rte_eth_rx_burst函数从端口接收数据包。
(5)根据配置文件中的配置规则对每一个数据包进行初步处理,需要进一步分析的数据包将其存储到一个共享内存缓冲区中。
通过上述处理,数据包采集模块将所有发送到该网卡的网络数据包抓取并保存在一块共享内存区中,实现了数据包的采集工作,抓包线程如图1所示。
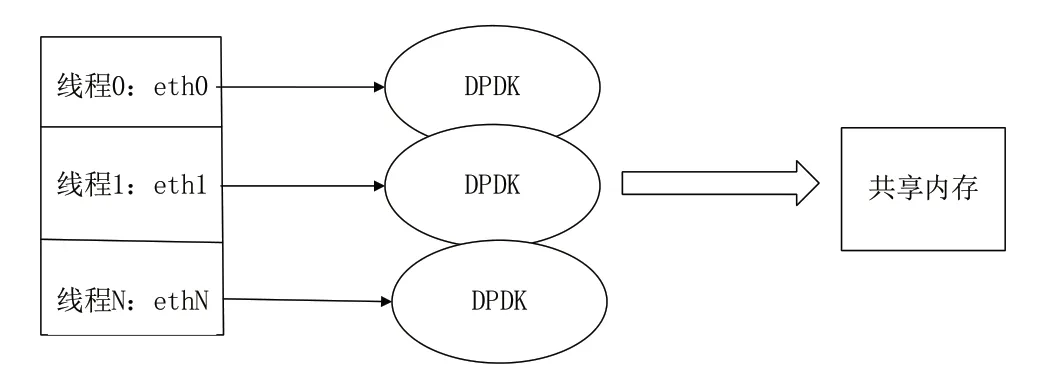
图1 基于DPDK的抓包处理过程Fig.1 Packet capturing process based on DPDK
3.2 基于哈希算法的会话流存储技术
在高速率高并发的万兆网络中,存储和查找会话流是进行数据分析的基础和关键步骤。哈希表是一种以键-值(key-index) 存储数据的高效数据存储结构,能够根据键值快速定位,从而提高插入数据和查询数据的效率。采用高效的哈希算法可以解决万兆网络中数据流的存储问题。哈希算法由3部分组成:数据存储方式、冲突解决方式和哈希函数。
在高性能数据流表的设计中,采用改进的经典哈希算法,将数据存放在一张大小固定的哈希表中,该哈希表为一个二维数组conntrack_ssn_hash[SSN_HASH_BUCKET_SIZE][SSN_HASH_BUCKET_DEPTH],其中一维下标用来表示Key值,二维下标用以解决哈希冲突。该算法在存储上有一定的上限,可能造成数据丢弃。因此在实际应用中,可以综合内存大小和效率要求,设置合适的SSN_HASH_BUCKET_DEPTH。
均匀性是衡量哈希函数性能的重要指标。研究证明,移位运算和异或运算能够保证哈希结果具有较好的均匀性。在高性能数据流表的实现中,我们采用基于位运算和异或运算的哈希函数,根据会话流中的5元组<源 ip 目的 ip 源 port 目的 port 协议 >进行哈希运算,具体运算过程如图2所示。
3.3 会话流老化技术
高速率高并发的万兆网络中,基于对内存和效率的考虑,需要定期对会话流进行老化处理。TCP流在收到FIN包后,会话流结束。UDP流的结束没有明显特征,需要自己设定老化时间。为了提高老化处理效率,将统计老化会话流及处理老化会话流分开处理。分别设置统计定时器和老化定时器。在会话流老化技术中,定时器和老化统计时钟的设置是关键,需要综合考虑系统数据分析周期、系统内存大小和数据分析处理精度。
4 高性能数据流表的实现
高性能数据流表的实现主要由两部分组成:数据包采集模块和会话流存储模块。处理架构如图3所示。数据包采集模块,主要根据配置文件中的抓包规则进行数据包采集,并将采集的数据包存入一块包共享内存中。会话流存储模块,该模块启动后,开辟一块流共享内存区域,之后生成两个处理线程,一个线程负责读取包共享内存中的Packet进行包处理。另外一个线程负责会话流老化,两个线程共同维护会话流,为后续的数据处理提供支撑。
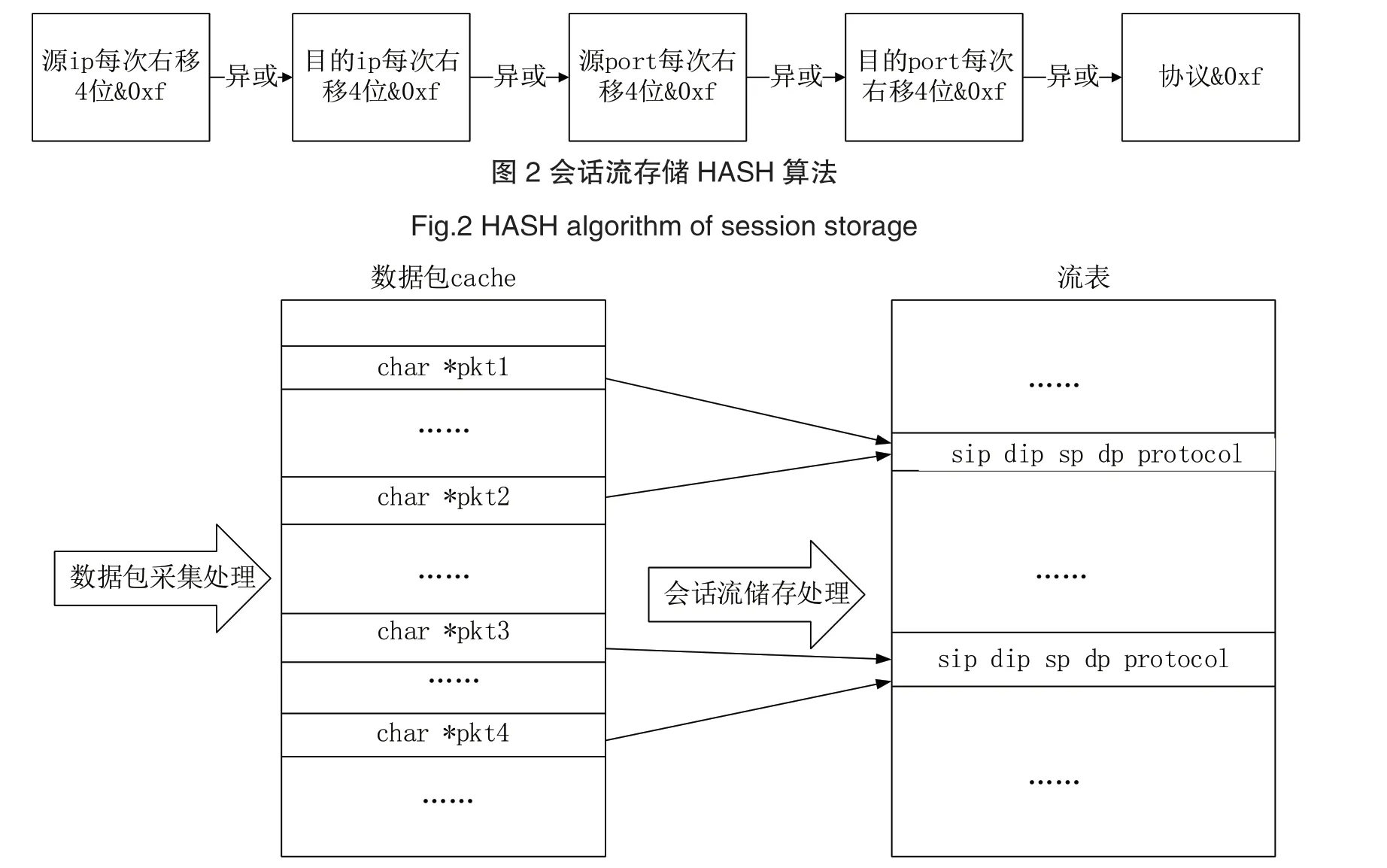
图3 高性能数据流表处理架构Fig.3 Architecture of high performance data flow table processing
5 实验分析
搭建实验平台,实验的网络拓扑图如图4所示。一台TCPReplay发包测试机、一台H3C交换机、一台普通PC、一台基于DPDK的高性能数据流处理系统。
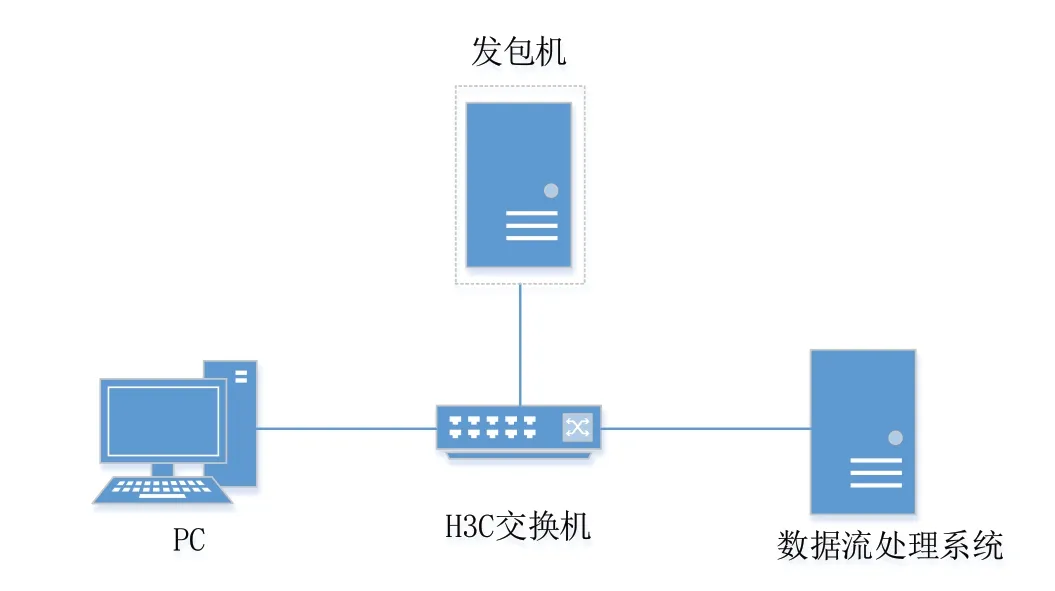
图4 实验平台网络拓扑图Fig.4 Topology of experimental platform
实验将Field Test和Lab Test相结合,采用Tcpreplay进行发包测试,先在Field Test场景下将真实流量捕获,存为PCAP文件,然后将PCAP文件作为Lab Test的背景流量,在其上指定发包速率、发包次数,对设备进行测试。
本实验用于测试的PCAP文件从真实的万兆网络环境中捕获,时长为5min,大小为247GB。将该PCAP文件使用tcpreplay -i eth1 -t /ft1.pcap进行全速发包,对高性能数据流处理系统进行流量统计。通过统计实际捕获到的流量总量为247GB,可以看出,基于DPDK的高性能数据流处理系统在高速率高并发的网络环境中能高效的抓取数据包并维护数据流表。
6 结语
本文主要对DPDK的技术原理进行了分析并将其应用在数据包采集上,同时对基于DPDK采集的数据包进行数据流表的维护,采用基于哈希算法的会话流存储技术和基于定时器的会话流老化技术,并成功将其应用在上网行为管理系统和上网行为审计系统中,作为高性能数据流表,后续还将继续研究并实现将其应用在防火墙、IPS、IDS设备中。
