工业废水排放总量预测模型研究与仿真
2022-08-22张汛,李鹏
张 汛,李 鹏
(1. 天津大学环境科学与工程学院,天津 300072;2. 桂林电子科技大学海洋工程学院,广西 北海 536000)
1 引言
在水资源供需平衡、水污染防治规划研究过程中,工业废水排放量预测属于重要工作,将预测结果作为依据可以有效实现环境的科学管理[1]。治理能力、工业结构、管理水平、科技水平以及产品种类等因素都会对工业废水排放产生影响[2]。工业废水排放在空间和时间的变化下存在较强的随机性,因此工业废水排放预测的难度较高,需要对工业废水排放量预测方法进行分析和研究。
张金勇[3]等人结合ARIMA模型和马尔萨斯模型对GDP和人口进行预测,通过排污系数法获得工业废水排放量与人口、GDP之间的关系,根据分析结果完成工业废水排放量的预测,该方法获取的排放数据中存在大量的缺失数据,导致方法存在数据完整性差的问题。刘鸿斌[4]等人通过偏最小二乘法获取投影的重要性信息,根据获取的信息选择最优变量子集,并将其作为输入,输入至软测量模型中,构建工业废水排放预测模型,完成工业废水排放量的预测,该方法用完整度低的数据进行工业废水排放量预测,导致预测结果的精度较低。
为了解决上述方法中存在的问题,提出基于灰色GM(1,1)模型的工业废水排放总量预测模型。
2 缺失数据填充
获取的工业废水排放数据中存在一些缺失数据,对工业废水排放总量预测结果产生影响[5]。为了提高预测精度,需要对缺失数据进行填补处理。基于灰色GM(1,1)模型的工业废水排放总量预测模型通过矢量神经网络根据设定的可信度λp∈[0,1]对缺失数据进行填补。
基于灰色GM(1,1)模型的工业废水排放总量预测模型在矢量神经网络中引入可信度λp对矢量神经网络进行修正,利用修正后的网络完成缺失数据的填补。
2.1 矢量神经网络修正
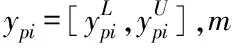
用(n-k-m)描述矢量神经网络的结构,设f代表的是神经元在网络中对应的激活函数,基于灰色GM(1,1)模型的工业废水排放总量预测模型用sigmoid函数代替激活函数,获得实际的网络输出youtput,其表达式如下
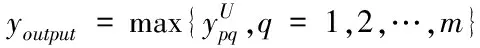
(1)
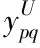
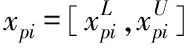
1)前向传播
区间类型矢量即为所有神经元在前向传播算法中的输入,也可以用区间类型的矢量描述网络输出,用sigmoid函数代替神经元对应的激活函数,此时输出节点可通过下式进行描述

(2)
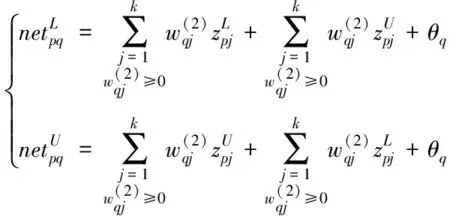
(3)
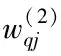
设Epq代表输出误差,其计算公式如下
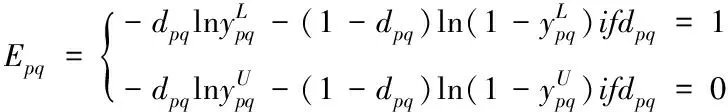
(4)
对上述公式计算的输出误差Epq进行修正,获得矢量神经网络对应的输出总误差Ep
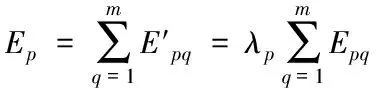
(5)

2)后向传播

(6)
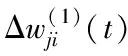
2.2 缺失数据填补
用{(xp,dp,λp),p=1,2,…,N}描述训练样本集STr;N′代表完备训练样本在训练样本集STr中存在的数量;STe描述测试样本集,Sf=STr-Ste代表的是残缺数据构成的样本集,用Nf=N-N′描述残缺数据的数量,填补缺失数据的过程如下:
1)网络训练
①初始化处理训练参数,设置训练样本在训练样本集Str中的可信度为λp,并将训练次数的上限设置为Nt,输出误差上限设置为Emax,同时设定惯性项系数α和训练步长η,计数器在训练过程中的次数设置为1,赋予权值矩阵w(1)、w(2)相应的数值,并将训练样本对应的标志p设定为1。
②在训练过程中将输出误差变量E设定为0,并在矢量神经网络的输入节点中输入训练样本集Str中存在的训练样本。
③通过上述过程获得修正后的权值矩阵w(1)、w(2),并计算输出误差E。
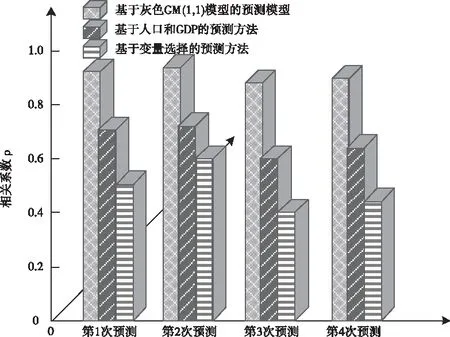
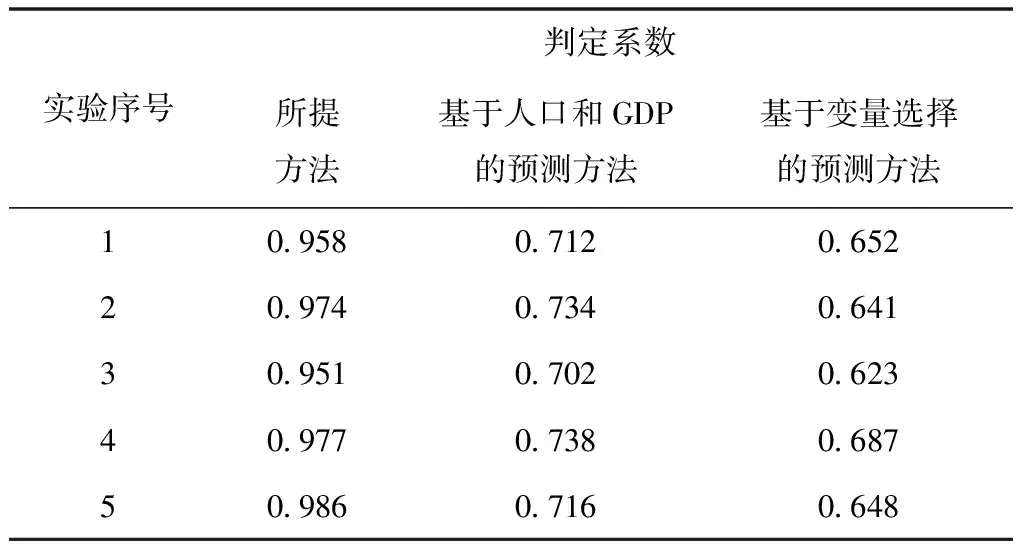
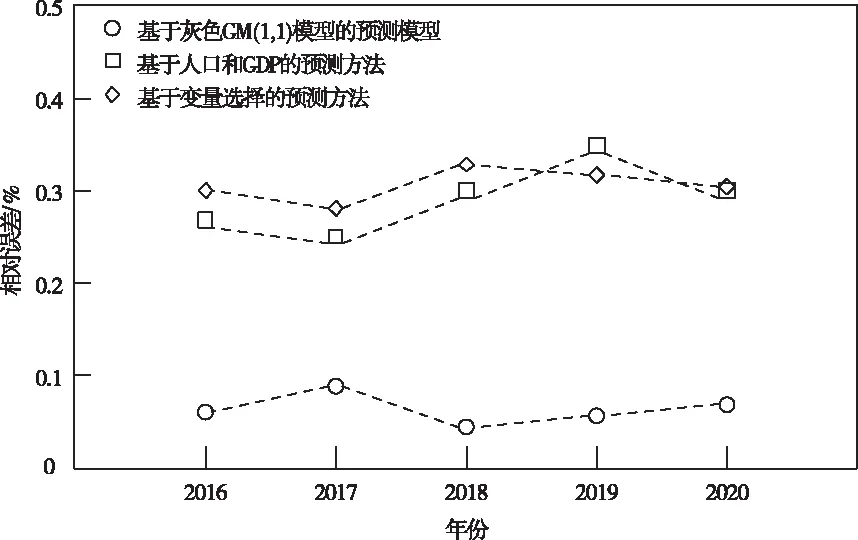
④在训练样本集Str中检查训练样本是否完成训练,如果p 2)填补残缺数据 ①初始化处理参数以及残缺样本标志l=1,设置样本l对应的填充矩阵Al。 在工业废水排放总量预测过程中GM(1,1)模型的应用较多[8,9],其主要过程如下: 用{x(0)(t)}描述原始时间序列,其中t=1,2,…,n,用{x(1)(t)}描述新数据序列,可通过累加原始时间序列获得 (7) 通过下式描述上式的微分方程 (8) 根据式(8)获得 其中,-a代表的是发展系数,用来描述预测数据序列与原始数据序列之间的发展趋势;u描述了数据在变化过程中的关系,代表的是灰色作用向量。在此基础上获得还原模型 (9) 实际值与上述GM(1,1)模型获得的预测值之间存在误差,根据误差的实际情况对误差进行划分,获得n个状态⊗i=[⊗1i,⊗2i],设置马尔可夫过程对应的状态转移概率pij(n),当{Xn,n∈T}为齐次马尔可夫链时,n不对转移概率pij(n)产生影响,此时下一步系统状态对应的转移概率矩阵P可通过下式描述 (10) (11) 通过以下两种方式,在马尔可夫模型的基础上改进GM(1,1)模型,构建灰色GM(1,1)模型: (12) 2)根据状态转移矩阵和预测状态对灰色预测相对误差在下一时刻所处的状态进行计算,根据计算结果获得系统灰色预测相对误差在未来不同时刻对应的状态,预测区间可通过修正灰色预测结果获得,预测值即为预测区间对应的中值[10]。 (13) 式中,pijmax对应的jmax即为最大数据在状态转移矩阵中对应的列。 通过上述方法预测未来时刻对应的数值,预测结果即为预测数值对应的平均值,构建工业废水总排放量预测模型 (14) 为了验证基于灰色GM(1,1)模型的工业废水排放总量预测模型的整体有效性,需要对基于灰色GM(1,1)模型的工业废水排放总量预测模型进行测试。分别采用基于灰色GM(1,1)模型的工业废水排放总量预测模型、基于人口和GDP的主要水污染物排放量预测方法和基于变量选择的废水排放总量预测方法进行如下对比实验。 通过相关系数ρ验证上述方法获取数据的完整性,相关系数ρ在区间[0,1]内取值,相关系数ρ越高,表明数据的完整性越高。相关系数ρ的计算公式如下 (15) 不同方法的测试结果如下: 分析图1可知,在多次工业废水排放总量预测测试过程中,基于灰色GM(1,1)模型的工业废水排放总量预测模型获得的相关系数ρ均在0.8以上,基于人口和GDP的预测方法和基于变量选择的预测方法获得的相关系数ρ均低于所提方法获得的相关系数ρ。因为所提方法在构建工业废水排放总量预测模型之前,对获取的数据进行填补处理,获取的数据中存在缺失数据,通过矢量神经网络对缺失数据进行填补处理,提高了数据的完整性。 图1 不同方法的相关系数 通过判定系数R2和相对误差测试不同方法的整体有效性。判定系数R2描述的是因变量对回归自变量拟合程度产生的影响,R2的值越接近1表明预测结果的精度越高,判定系数R2的计算公式如下: (16) 上述方法的测试结果如表1所示。 表1 不同方法的判定系数 根据表1中的数据可知,所提方法的判定系数均在0.9以上,判定系数更接近1,表明预测结果的精度较高,通过上述分析可知,所提方法可精准地实现工业废水排放总量的预测。 采用不同方法对不同年份的工业废水排放总量进行预测,获得预测相对误差如图2所示。 图2 预测结果的相对误差 分析图2可知,采用不同方法对不同年份的工业废水排放总量进行预测时,基于人口和GDP的主要水污染物排放量预测方法和基于变量选择的废水排放总量预测方法预测结果的相对误差均高于所提方法,所提方法预测结果的相对误差均保持在0.1以内,因为所提方法利用填补后的数据构建了工业废水排放总量预测模型,提高了模型的预测精度,进而降低了预测结果的相对误差。 水体污染情况随着我国工业的发展不断加重,在这种背景下我国政府开始重点控制工业废水排放总量。通过预测未来工业废水排放总量相关部门可以制定合理、科学的污染减排方案。目前工业废水排放总量预测方法存在数据完整性差、预测精度低的问题,提出基于灰色GM(1,1)模型的工业废水排放总量预测模型,对缺失数据进行填补处理,利用灰色GM(1,1)模型完成工业废水排放总量的预测,为治理我国工业废水排放提供了相关依据。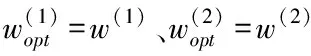
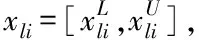
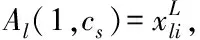
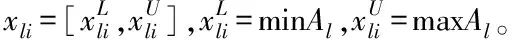
3 工业废水排放总量预测模型
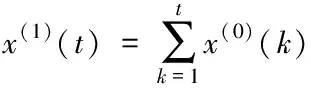
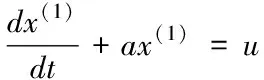
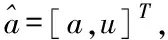
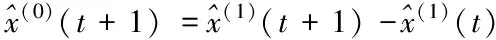
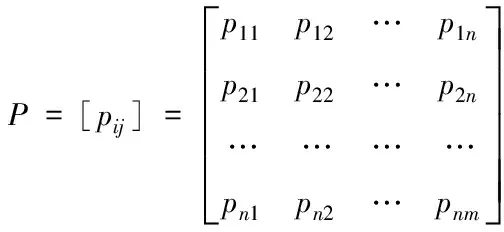


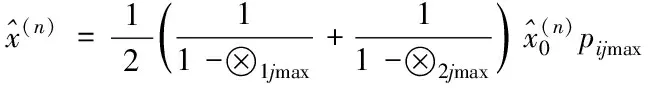
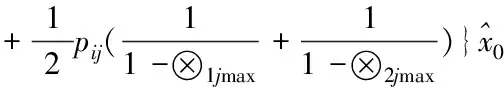
4 实验与分析

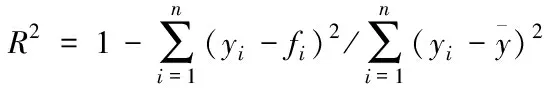
5 结束语
