手势深度交互识别技术的研究与仿真
2022-08-22张明星陈彦卿
张明星,陈彦卿
(1. 湖南科技学院,湖南 永州 425199;2. 齐齐哈尔大学计算机与控制工程学院,黑龙江 齐齐哈尔 161003)
1 引言
近年来,人机交互在人类生活中占据越来越重要的地位,也开始变得越来越简单和自然[1,2]。手势深度交互由于具有自然、简洁以及丰富等特点,成为现阶段人机交互领域研究的重要内容。在人机交互过程中,人和机器之间的沟通不再需要借助其它设备,可以将手部动作直接作为交互系统的输入,用户还可以自主定义手势,进一步提升了人机交互的灵活程度。随着手势深度交互的大范围使用,开始出现了全新的问题,需要研究有效的方法对这些问题进行及时解决。
国内相关专家给出了一些较好的研究成果,例如时梦丽等人[3]通过Ostu分割方法分割手势区域,同时对手势特征进行提取,获取手掌不同区域的形态特征,结合已经提取到的特征进行手势识别。王勇等人[4]通过二维傅里叶变换提取信号对应的频谱,对手势对应的距离和速度进行估算,通过多重信号分类计算角度,将手势动作进行特征提取,同时将得到的特征进行融合,最终实现手势识别。由于上述已有方法未能对手势深度图像进行去噪处理,导致识别耗时增加,识别结果不准确。为了有效解决上述问题,提出一种基于全链条AI技术的手势深度交互识别方法,经实验测试证明,所提方法能够有效降低识别耗时,获取更高的识别率。
2 手势深度交互识别方法
2.1 手势深度图像去噪
统计学习属于机器学习领域中的一个重要理论,其中的支持向量机(Support Vector Machine,SVM)属于其分支[5,6],被应用于医疗以及交通等多个研究领域中。最优超平面是SVM的核心,同时也是SVM进行分类的主要工具。设定有N个训练样本的数据集,要想确保分类准确性最高,则对应的最优超平面需要满足式(1)中的条件,即
yk|ωTφ(xk)+b|-1=0,k=1,2,…,N
(1)
式中,xk代表第k个输入的数据;yk代表第k个输入数据所属类别;φ代表非线性函数;ωT代表权重值;b代表任意常数。
为了能够充分利用最优超平面的特性进行数据分类,需要在式(1)中加入非负松弛因子ζk,则式(1)能够转换为以下形式
yk|ωTφ(xk)+b|-1+ζk=0,k=1,2,…,N
(2)
结合式(2)对应的约束条件,采用结构最小风险原则,将界限进行最小化优化处理,详细的计算式如下
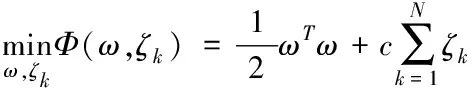
(3)
式中,Φ(ω,ζk)代表最小界限;c代表任意常数;ω代表权重的取值范围。
非下采样轮廓变换是在已有轮廓变换的基础上经过一系列改进获取的,为了更好保留手势深度图像的特征,需要针对变换中的图像进行下采样操作,最终获取非下采样轮廓变换。非下采样是一种典型的滤波器,具有多尺度不变的特性。在进行轮廓变换的过程中,需要借助滤波器实现下采样,同时以此为依据建立一个和树型结构相近的滤波器组。
结合以上分析,根据构建的滤波器组,得到如式(4)所示的采样插值矩阵Sk
Sk=diag(2l-1,2),0≤K≤2l-1-1
(4)
式中,l代表树型结构的级数;K代表手势深度图像的二维频率。
SVM的核心是通过二次规划方法进行分类,以下将SVM的损失函数转换为最小二乘线性系统,同时借助全新的损失函数优化传统方法,最终达到简化SVM的目的,全面增强分类效果。
设定拉格朗日函数L(ω,b,e,a)为
L(ω,b,e,a)=Φ(ω,b,e)-

(5)
式中,ak代表拉格朗日因子;Φ(ω,b,e)代表核函数。
式(5)可以采用以下矩阵形式进行分解
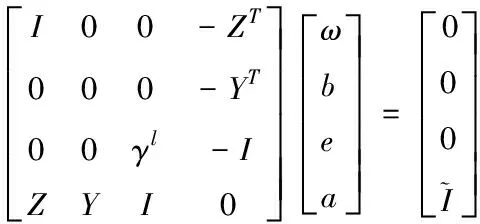
(6)
式中,ZT和YT代表线性方程对应的函数取值;γl代表手势深度图像的高频区域;I代表手势交互图像的总数。
由于非下采样轮廓具有很好的轮廓保持特性,结合相关的轮廓变换理论可知,噪声大部分集中在图像的高频区域内。其中,含有噪声的图像可以表示为以下的形式
y=x+v
(7)
式中,v代表噪声信号。通过非下采样轮廓变换对手势深度图像进行分解,最终获取对应的轮廓变换系数。
根据噪声的分布特征,采用空间规则确定SVM的训练特征向量,根据式(8)将各个高频子带系数进行初始化处理,形成一个二元表

(8)
式中,τ代表高频子带系数。
在组建二元表时,需要选取对应的高频子带系数,同时引入中位法对噪声标准差σ进行估计,如式(9)所示

(9)
当完成二元表的建立后,通过空间规则可以判定轮廓采样系数属于孤立噪声还是空间特征。
另外,采用SVM进行分类的过程中[7,8],还需要选择合理的阈值,同时还需要对每一个子带中的噪声信号进行分布估计,将其称为标准偏差σy,具体的计算式如下

(10)
为了获取最优阈值,需要借助平方差r(T)来缩小误差,具体的计算式为
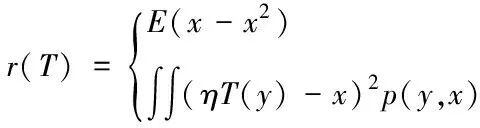
(11)
式中,E(x)代表误差的取值范围;ηT(y)代表软阈值函数。
通过上述方法对含有噪声的手势深度图像进行去噪处理,同时对子带系数进行非下采样轮廓变换,最终实现图像去噪。
2.2 基于全链条AI技术的手势深度交互识别
当手势深度图像经过去噪处理后,采用肤色特征完成手势分割[9,10],由于肤色在颜色空间中十分集中,包含一定的统计特性。YCbCr空间是一种十分常见的颜色空间,主要来源于YUV空间。当完成肤色检测后,需要将彩色图像转换为YCbCr空间图像,YCbCr空间图像中的亮度和色相两者是分离的,所以需要将图像中的亮度相关信息剔除,然后进行处理,有效避免光照变化产生的干扰。
在RGB色彩空间中,由三个不同的分量共同组成亮度Y,具体的表达形式如下
Y=kr×R+kg×G+kb×B
(12)
式中,Y代表亮度;kr、kg和kb代表加权因子;R、G和B代表色彩空间。
在Kinect摄像机的芯片集中加入了一种全新的肤色检测算法,主要借助亮度补偿对手势进行肤色检测C(Y),具体的计算式如下
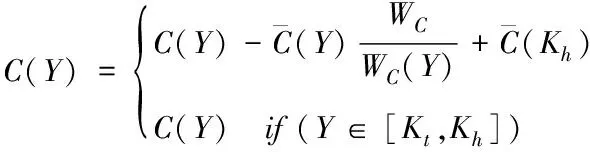
(13)

其中,肤色对应的椭圆模型能够表示为以下的形式
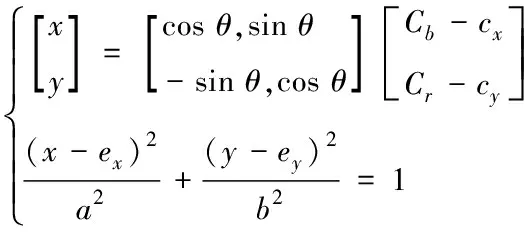
(14)
式中,cx和cy代表手势深度图像的弧度;Cb和Cr代表手势深度图像的肤色像素值;ex和ey代表任意常数。
传统混合高斯模型法在YCbCr空间进行使用时,会完全忽略图像亮度信息对识别结果的影响。为了有效克服上述问题,本文借助训练样本和协方差矩阵共同实现手势特征提取。
首先建立两个协方差矩阵

(15)
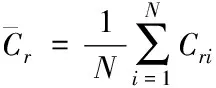
(16)
式中,Cbi和Cri代表手势深度图像的特征向量。
高斯混合模型利用M个高斯分布元素计算出各个像素点向量为肤色像素的概率,则第j个高斯分布能够表示为
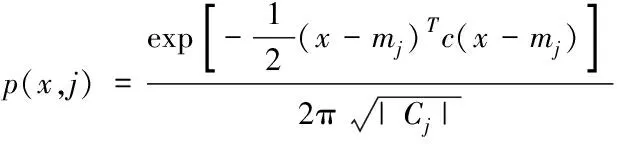
(17)
式中,mj代表手势轮廓点到指尖的最大距离;Cj代表协方差矩阵。
像素属于肤色像素的概率p(x,skin)能够表示为
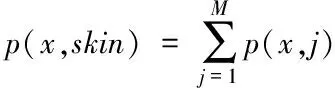
(18)
将Kinect摄像机放置在相同的场景内进行拍摄,由于光照图像不同,所以可以得到彩色图像和深度图像,分别采用不同的方法对两幅图像进行分割处理。其中,深度图像还需要进行去噪处理,将图像中存在的噪声点剔除。
当进行手势交互时,人的身体一直位于摄像头的正前方,所以将深度图像输入直方图内进行统计分析后发现,人的身体和背景在深度直方图中会形成两个比较大的峰值。结合以上分析,以下详细给出自适应深度直方图阈值算法的具体操作步骤:
1)在直方图中获取两个含有像素数量最多的深度值,同时将较小的深度值设定为身体峰值的深度值。
2)对直方图进行二次遍历,同时设定最大和最小间隔阈值。
3)对手势深度图像的检测记录进行查询,同时根据设定的深度阈值对图像进行全局阈值处理,最终获取对应的手势区域信息。
在上述分析的基础上,肤色检测是由于输入到系统内的彩色图像具有较高的精度,所以得到的检测结果准确性较高;而将经过分割的手势区域输入到系统内,获取的检测结果准确性偏低。为了获取更加准确的信息,通过区域生长法将两者获取的手势深度边缘信息进行配准[11,12],进而得到手势边缘信息,最终实现手势特征提取。
当手势深度图像完成深度和肤色分割后,即可通过全链条AI技术将分割结果进行边缘配准,同时将错误的像素信息删除。其中,错误像素的删除工作是借助区域生长法实现的,它是一种比较经典的算法,主要作用就是提取图像中的相似区域。如果提前给定一个种子像素点和对应的相似性像素,则需要将前者设定为中心点,而通过后者判定图像的边缘和领域像素两者是否属于同一类别,假设是,则继续生长;反之,则结束生长,直至全部像素点无法被包含为止。其中,边缘配准的具体操作流程如图1所示。

图1 手势深度图像的边缘配准操作流程图
对手势深度图像和彩色图像中的边缘信息进行检测,将检测结果作为依据,采用全链条AI技术得到不同边缘存在的错误像素信息,将其全部剔除;进而获取彩色图像中精准的手势轮廓,提取手势特征,最终实现识别。
3 仿真研究
为了验证所提基于全链条AI技术的手势深度交互识别方法的有效性,随机邀请20名志愿者作为测试对象,在测试过程中需要通过Kinect设备采集图像,将手掌放置于身体的最前端,图2为手势示例图像。

图2 手势示例图像
考虑到Kinect本身的物理限制,将测试范围设定为60~200m,在不同测试距离进行测试,具体的测试结果如表1所示。
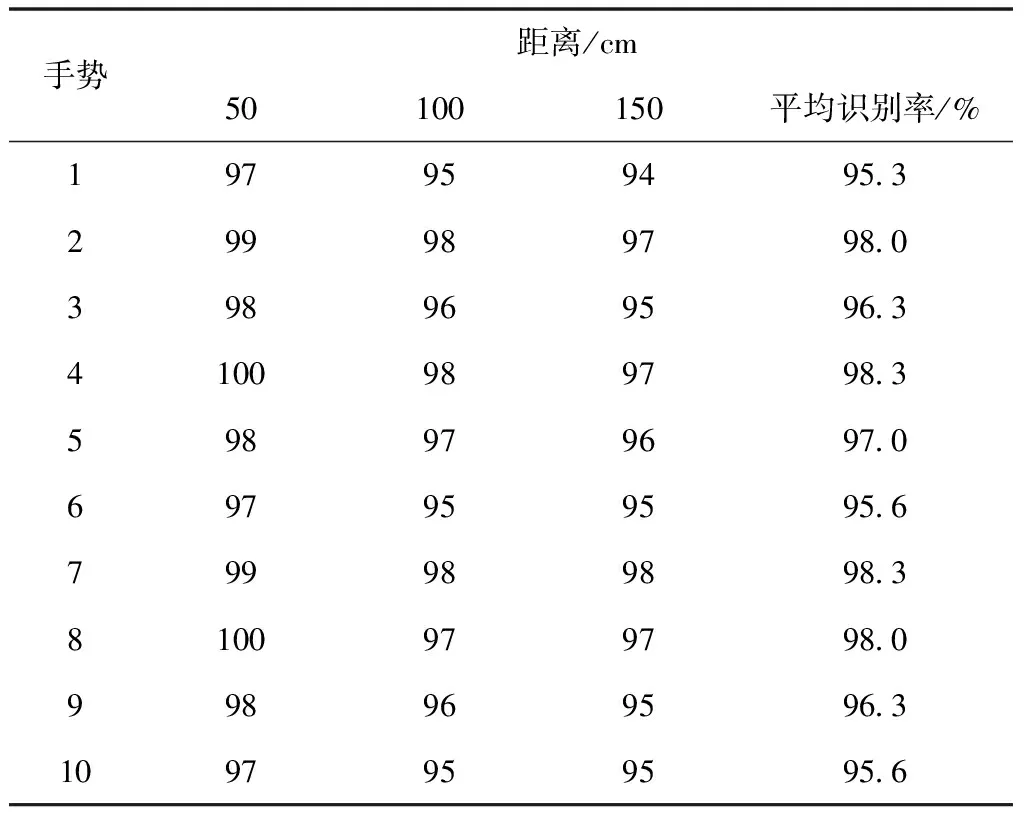
表1 不同距离下手势深度交互结果
从表1中能够看出,所提方法具有较高的识别率,且平均值均在95%以上,能够达到预期的识别效果。
为了验证所提方法在不同光照条件下的鲁棒性能,在20名测试对象随机选取一名进行测试,测试结果如图3所示。

图3 不同光照条件下的手势识别结果
分析图3可知,即使在不同光照条件下所提方法依旧能够精准识别不同手势,充分证实所提方法的优越性。
将所提方法和文献[3]、文献[4]方法的识别率进行对比,选取五个手势作为测试对象,具体实验结果如图4所示。
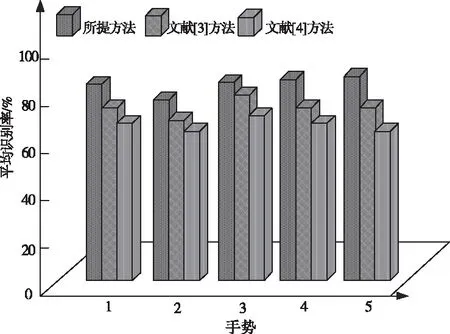
图4 不同方法的识别结果测试分析
由图4中可知,所提方法的平均识别率明显高于另外两种方法,主要因为在进行手势深度交互识别前期,对手势深度图像进行去噪处理,有效滤除图像中的噪声点,确保识别结果更加准确。
为了进一步验证所提方法的实用性,以下实验测试对比不同方法的识别耗时,具体实验结果如图5所示。

图5 不同方法的识别耗时对比结果
分析图5中的实验数据可知,所提方法的识别耗时明显低于另外两种方法,充分证明了所提方法的实用性。
4 结束语
针对传统方法存在的不足,设计并提出一种基于全链条AI技术的手势深度交互识别方法。与已有方法相比,所提方法具有较快的识别速度和较高的识别率。由于受到环境以及人为等多方面因素的限制,所提方法仍有进步的空间,后续将对其展开更深层次的研究。
