基于卷积神经网络的多特征融合和图像分类
2022-08-22李陈军张伯健
李陈军,褚 凯,张伯健
(广西师范大学计算机科学与信息工程学院,广西 桂林 541004)
1 引言
随着计算机科学与互联网技术的高速发展,全世界每时每刻都在产生大量数据,例如:文本、音频、图片、视频等。大数据含有大量信息,但是这些信息人工难以辨别和整理,因此如何对信息进行分类与识别一直备受广大研究者关注和研究。各种信息中图像信息是一种极重要的信息载体,上世纪研究者针对图像中纹理信息提出很多优秀的图像算法,为计算机视觉和模式识别领域奠定了坚实的基础。21世纪,随着卷积神经网络(Convolutional Neural Network,CNN)在图像分类领域取得了很大的突破,计算机视觉进入一个全新的时代。
卷积神经网络通过多层非线性变换模拟人大脑的学习能力,利用大量有标记的数据进行训练,在计算机视觉领域取得了显著的成绩。但是卷积神经网络对于计算性能有着严格要求,它只关注图像区别性最高的部分[1],忽略了图像中其它细节特征。通过互补特征融合的方法能有效改善特征忽略问题。目前,基于语义特征的融合方法主要分为:异构特征融合,多神经网络特征融合以及神经网络多层特征融合。
异构特征融合:基于传统特征和深层语义特征的融合方法。Wang等人[2]提出了一种基于多方向梯度HOG特征和深度学习特征进行迭代融合的面部表情识别方法。Li等人[3]提取图像的传统特征(LBP,SIFT和Color)和深度置信网络的语义特征,并使用玻尔兹曼机挖掘传统特征与深层特征的关联。异构特征融合证明了传统特征可以有效改善语义特征空间的多样性。
多神经网络特征融合:基于不同卷积网络特征的融合方法。Liu等人[4]通过监督学习的方法训练不同神经网络中层特征,使用后期融合策略处理分类器的预测,有效提高图像分类性能。Zhang等人[5]构建CFR-DenseNet和ILFR-DenseNet双重网络,并使用端对端进行训练,融合两种不同网络的特征。T. Akilan等人[6]使用三个完成预训练的卷积网络作为特征提取器,使用单个隐藏层将高级特征转化到低维空间,融合各个特征的丰富信息。与先进方法相比,多特征融合方法在图像分类准确性上有着足够的竞争力。
神经网络多层特征融合:基于单个网络多个不同特征的融合方法。Song[7]等人引入残差学习建立了深层卷积网络,利用深度特征融合网络将卷积网络不同层的特征进行加权融合。Feng等人[8]提出MSLN-CNN,在局部和非局部约束下增强图像,并将不同层次的特征进行融合,在训练样本有限的情况下性能表现得极为出色。Guo等人[9]提出了一种多分类器网络(MCN)使用同一CNN的不同层的语义特征通过自适应的方法进行融合,在多个数据集上验证了该融合方法的有效性。神经网络多层特征融合提取网络的多层语义特征,将抽象程度较低的特征当成深层特征的互补特征,相互融合可以有效改善分类结果的准确性和可靠性。
本文综合了异构特征融合和多卷积网络特征融合的优点,提出了一种自适应加权融合算法,能有效,简洁地将多个语义特征和传统特征进行融合,极大的提高了分类的准确性。本文所做的贡献如下:
1)根据图像颜色和边缘信息设计出一种手工特征,可以强化特征空间的多样性,与语义特征形成有效互补;
2)针对不同卷积神经网络多种语义特征和多种学习方法进行研究和对比,发现不同网络的语义特征之间的互补性优于同种网络不同层的特征,将异构特征和多神经网络特征进行融合,进一步强化特征空间的多样性;
3)提出了一种新的融合算法,对不同卷积神经网络多种语义特征和传统手工特征进行融合,相对于端对端的训练和融合算法,有着更好的分类性能,并且极大的降低了算法所需的时间成本。
2 方向梯度和颜色体积直方图与自适应加权融合算法
图像分类方法包括为三个步骤:
1)图像预处理(包括图像去噪,光照归一化等等);
2)图像特征提取(包括训练图像以及测试图像);
3)利用分类对提取的特征进行学习。
本文根据不同网络特征之间的差异与互补性,利用权值对多特征进行动态融合(参见图1)。
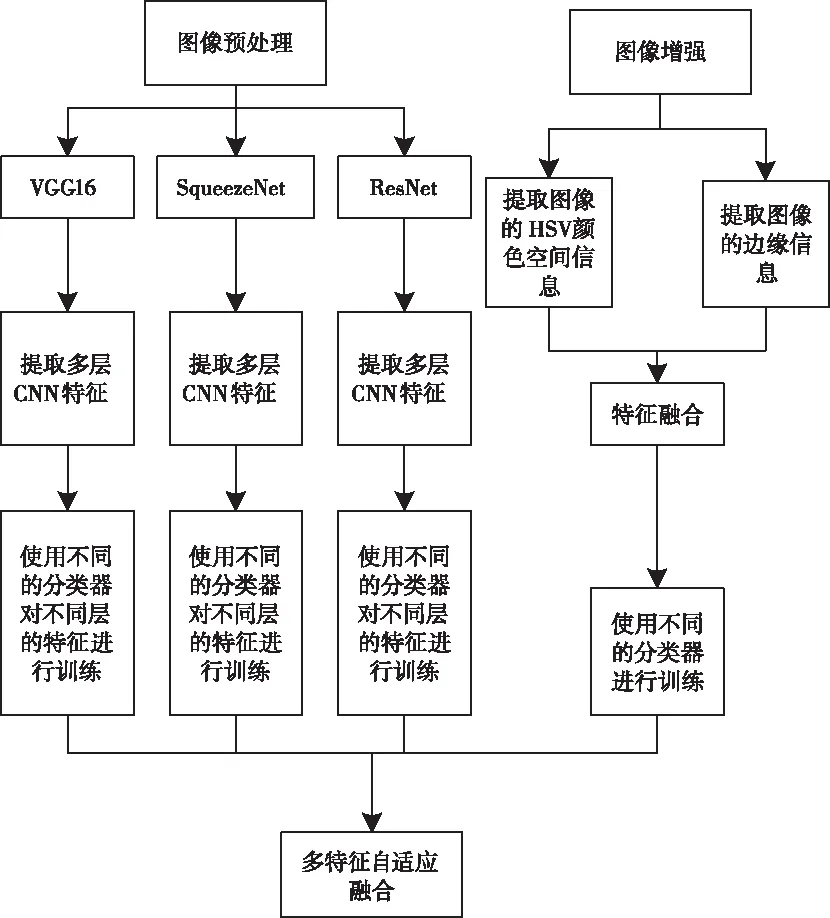
图1 多特征融合的图像分类算法流程图
2.1 方向梯度和颜色体积直方图(HOGCV)
HSV颜色空间与人眼的视觉感知接近,对于颜色之间的差异十分敏感。HSV颜色空间度量颜色信息的参数分别是:色调(H),饱和度(S),明度(V)。将色调,饱和度和明度分别量化为6,4.3份,颜色体积特征的维数为6×4×3=72。本文参考了Hua[10]提出的颜色体积特征,增加了颜色空间特征标记矩阵,提高了颜色之间区分度。并对颜色空间体积特征的累加计算进行了优化与改良,提高了分类性能,同时使其对于语义特征有着更强的互补性。
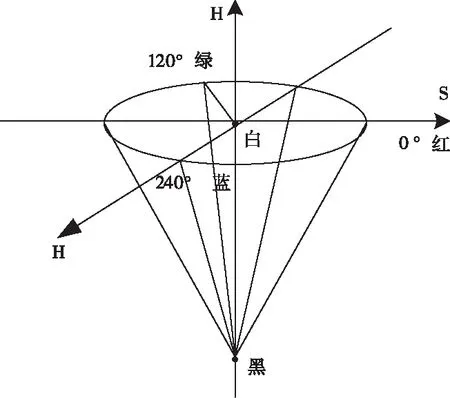
图2 HSV颜色空间
将RGB图像转化到HSV颜色空间,计算图像颜色空间体积特征矩阵cv
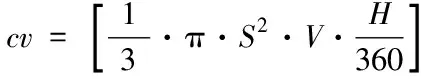
(1)
根据图像H,S,V的分量大小,计算图片不同空间位置像素点的颜色空间特征标记矩阵K
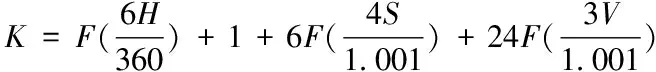
(2)
式(2)中F函数是向下求整。设一张图像中有多个3×3像素块,每个像素块的中心像素的坐标为(x0,y0),其它八个像素坐标分别命名为(xi,yi),其中i∈[1,8],计算9个像素点颜色空间体积的平均值,将其作为中心的颜色空间特征h(x0,y0)。最终将颜色空间特征标记矩阵中标记k相等的颜色空间体积特征累加并统计,即为当前图像的颜色体积直方图特征
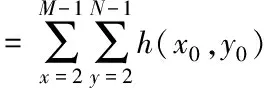

(3)
方向梯度直方图[11](Histogram of Oriented Gradient,HOG),是目前计算机视觉和模式识别领域一种常用的图像边缘特征。HOG通过计算和统计图像局部梯度方向直方图来构成特征,与其它的特征描述方法相比,HOG特征是在局部方格单元上形成的,所以它对图像几何和光学上形变都有着良好的不变性,这两者的形变只会出现在更大的空间邻域上。
HOG特征的提取过程如下:将彩色图像转化为灰度图像,并利用Gamma校正法减少光照对于图像信息的影响
I(x,y)=[I(x,y)]Gamma
(4)
计算图像A的水平梯度Gx和竖直梯度Gy,根据Gx和Gy大小确定为图像中每一个像素的梯度幅度值G以及梯度方向θ

(5)
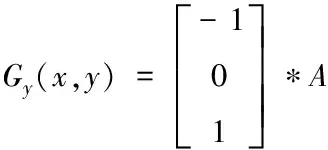
(6)

(7)
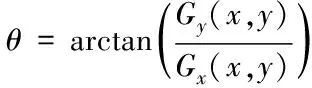
(8)
图像分割成多个4×4单元,[0°,360°]划分为9个bins,将单元中的梯度方向在同一bins的梯度幅度值累加,形成9×1的HOG特征向量。4个单元组合为更大范围的正方形区间。在区间上为了进一步减少光照和阴影的影响,将不同的单元的特征向量进行归一化。统计图片中所有区间的HOG特征,将其合成为最终的特征向量。
HOGCV=[λ*HOG,(1-λ)*CV]
(9)
通过主成分分析方法(Principal Component Analysis,PCA)将HOG特征维度降低至128,与颜色体积直方图特征分别进行归一化,根据式(9)融合得到一种新的特征描述符,命名为方向梯度和颜色体积直方图(Histogram of Oriented Gradient and Color Volume,HOGCV),式(9)中的参数λ推荐使用0.95。HOGCV特征拥有几何不变性和旋转不变性,与卷积神经网络提取的语义特征形成有效互补。
2.2 自适应加权融合算法
在计算机视觉分类领域,高性能特征贡献较大,对于特征融合赋予优势性能特征更高的权重可以有效地融合多种特征,提高特征空间的多样性。与此同时,考虑到传统特征性能在异构特征融合中的缺陷,自适应加权融合算法通过性能指标在特征融合中有效地动态地控制多特征融合权重,强化语义特征在多特征融合中的主导地位。
自适应加权融合算法是利用后期融合的策略对分类器的预测进行融合。首先,将提取的多种特征分别输入不同分类器训练,统计每一种组合分类结果,将参与融合的分类准确率进行归一化
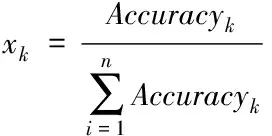
(10)
其中Accuracyk表示参与融合的第k种特征的top1分类准确率。高斯分布是一种钟形曲线,符合特征融合中权重的变化趋势。利用高斯分布和不同特征的分类结果控制特征融合的权值,并通过高斯分布均值来调整高斯曲线,动态的调整权重变化的快慢,以及确定不同特征的融合权重
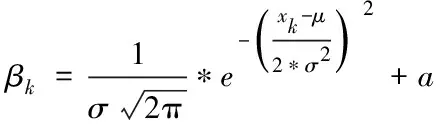
(11)
由于传统特征和语义特征有着较大的性能差距,将不同分类器精确度累加在调整后的权重上,削弱传统特征对于融合特征的影响,强化语义特征在融合特征中影响性。

(12)
μ=|1-2.5*σ|
(13)
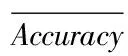
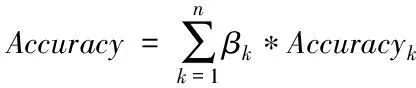
(14)
自适应加权融合算法通过高斯分布均值调整权重曲线,使其能够根据融合特征的性能动态地调整不同特征的融合权重。此方法在保证语义特征的优势下将传统特征与语义特征融合,强化特征空间的多样性,且能有效的将多网络的语义特征进行融合。
3 实验结果及分析
本文为了验证提出的多特征融合和图像分类方法的有效性,使用了不同网络的多层特征和多种分类方法进行学习,根据性能标准对融合的特征和方法进行筛选。
实验的硬件环境:CPU Inter Core i7-7700,GPU NVIDIA GeForce GT 730,软件环境为MATLAB R2018b。
3.1 数据集以评价准则
本文在Cifar-10,STL-10,Cifar-100和Caltech-101数据集上对基于卷积神经网络的多特征融合和图像分类算法进行了实验验证。
Cifar-10数据集:一个接近普适物体的彩色图像数据集。该数据集一共包含10个类别,每张图片的尺寸为32×32。每个类别有6000个图像,此数据集中一共有50000张训练图片和10000张测试图片。
STL-10数据集:该数据集一共有10个类别,每个类有拥有的测试样本数都大于训练样本。每张图片的尺寸为96×96。此数据集中一共有5000张训练图片和8000张测试图片。
Cifar-100数据集:该数据集包含100个类别,每个类别拥有500张训练图像和100张测试图像,每张图片的尺寸为32×32,一共有50000张训练图片和10000张测试图片。
GHIM-10K数据集:该数据集一共有10000张图像,包含20个类,每个类别拥有500张图片,每张图片的大小为 300 ×400或400×300。本文在使用时将每个类别前350张图片作为训练数据,后150图片作为测试数据。

图3 Cifar-10数据集训练样本展示

图4 STL-10数据集训练样本展示

图5 Cifar-100数据集训练样本展示

图6 GHIM-10K数据集训练样本展示
本文采用的准确率作为评价指标,计算公式如下

(15)
3.2 卷积神经网络以及分类方法
本文为了减少算法的时间成本,使用三种规模小的卷积网络提取深层语义特征,并利用预训练模型提取所需特征,进一步加快了分类速度。经实验验证可改用拥有更深层数的卷积网络或者使用迁移学习,可进一步提高分类精度,但需要更大的时间成本。
本文主要使用以下三种卷积神经网络:
VGG-16[12]。VGG-16是一个杰出的视觉模型,网络结构较为整洁,它通过多个小卷积核模拟实现更大的卷积核,极大地极少了模型中的参数。本文提取了该网络的全连接层fc6,fc7,卷积层conv5_3和池化层pool5的激活特征。
ResNet[13]:ResNet被用来解决随着网络深度的增加,系统性能达到饱和,然后迅速退化的问题。本文中,考虑了加快计算速度的浅层网络ResNet-18作为模型来提取相应特征。本文提取了该网络的全连接层fc1000,卷积层res5a_branch2b,res5b_branch2b和池化层pool5的激活特征。
SqueezeNet[14]:轻量级网络,最大程度提高运算速度。SqueezeNet模型核心是Fire模块,通过减少参数使得单步计算速度增加。本文提取了该网络的fire9-relu-expand3×3,卷积层conv10和池化层pool10的激活特征。
本文中使用以下方法训练分类器:
支持向量机[15](Support Vector Machine,SVM),SVM是一种处理模式识别领域分类问题的监督算法,通过寻找样本的最大边距超平面,使得特征空间中距离超平面最近的不同类别的点间隔达到最大,SVM相对于其它的分类方法有着更好地稳定性以及健壮性。
K最邻近算法[16](K-Nearest Neighbor,KNN),KNN算法的实现原理为将已知的样本作为参照,计算与未知样本的距离,选取其中距离最近的K个样本,根据投票法则确定未知样本的类别。
决策树[17](Decision Tree DT)是一种自上而下,对样本空间进行树形分类的方法,其原理是由上而下计算信息增益比,根据结点的信息增益比对训练数据进行分割,并建立子结点,然后对子结点递归调用此方法,直到每个子集都分配到结点上,就得到了一个决策树。决策树的方法通常有三个步骤特征选择,决策树的生成和决策树的剪枝。
线性判别分析[18](Linear Discrimination Analysis,LDA)。其原理是将所有的样本投影到一维空间,投影后使两类之间的间隔尽可能的大,而类别之间的差距尽可能得小。
3.3 实验结果以及分析
Cifar-10,STL-10及GHIM-10K数据集上,VGG和ResNet全连接层提取的特征优于其它层的特征,SqueezeNet中conv10层特征更优秀,VGG-16网络相对于其它两个深层卷积网络分类效果更优,在未训练的情况下,达到83%的精确度。四种学习方法中SVM和LDA在三个数据集中总体表现超过另外两种方法,详情参考图7、图8和图10。
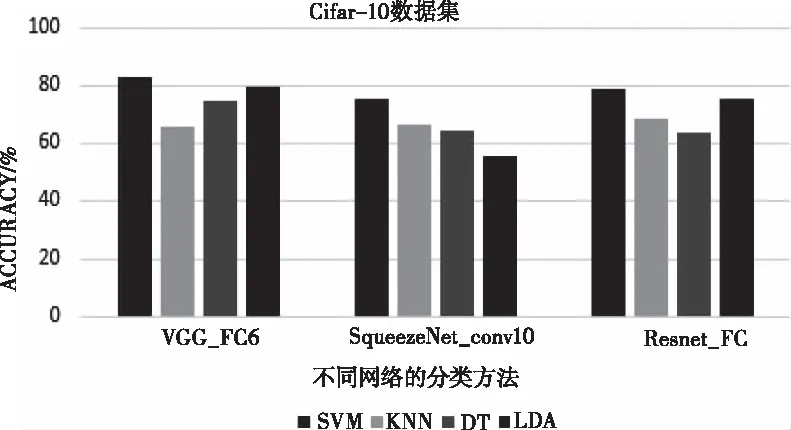
图7 Cifar-10数据集上单个网络最优层精确度
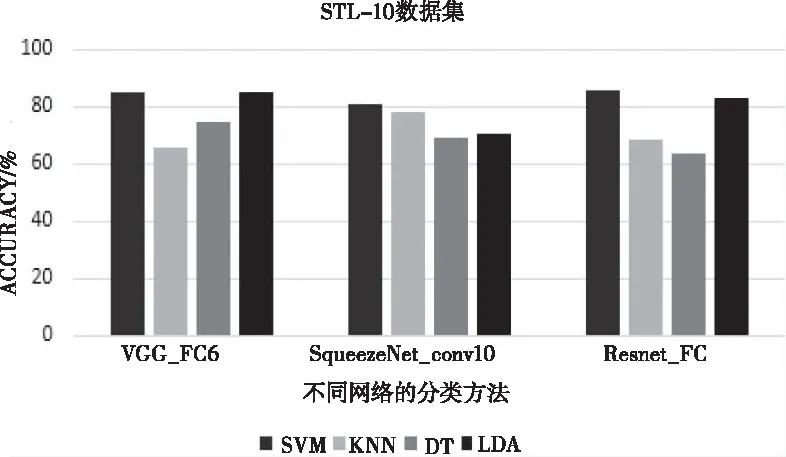
图8 STL-10数据集上单个网络最优层精确度
Cifar-100中,VGG的pool层的特征有着优秀的分类性能,且SVM和DT方法在Cifar-100数据集上分类效果显著,详情参考图9。从四个数据集的单层特征实验结果分析,VGG网络和SVM方法有着更好的稳健性,单层特征对比其它特征性能最优。
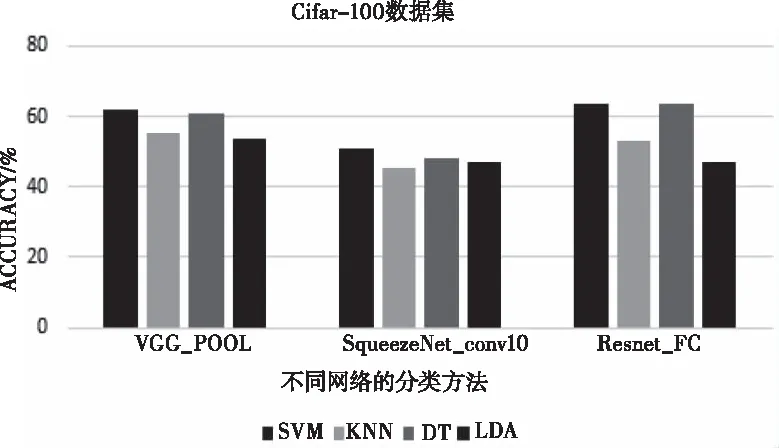
图9 Cifar-100数据集上单个网络最优层精确度
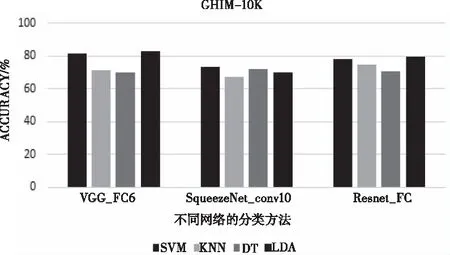
图10 GHIM-10K数据集上单个网络最优层精确度
针对卷积神经网络单层特征的实验结果,利用卷积神经网络特征对自适应加权融合算法进行验证。多个数据集上两层卷积特征融合结果,表1至表5。表中R为ResNet-18,V为VGG-16,S为SqueezeNet,ResNet-18网络中fc1000层简化为fc,p代指pool层,c代指onvc。Accuracy单层特征的分类结果,Accuracy2代指双特征融合的精确度。
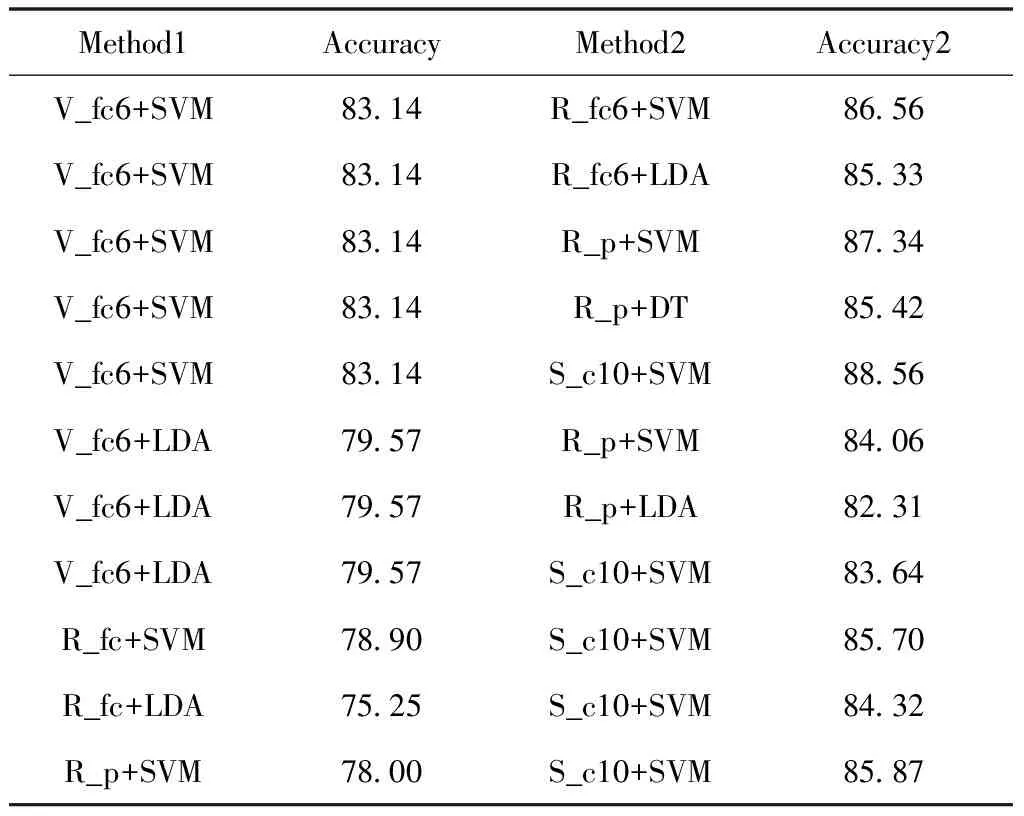
表1 Cifar-10数据集上两种特征融合的精确度(%)

表2 STL-10数据集上两种特征融合的精确度(%)
双特征融合实验结果表明:同种网络中语义特征融合的精确度低于不同网络的语义特征融合的精确度,证明不同网络特征之间互补性优于同种网络。Cifar-10,STL-10,Cifar-100和GHIM-10K数据集上双特征融合准确率相对于单层语义特征提高了5%~8%,参照表1-表4。

表3 Cifar-100数据集上两种特征融合的精确度(%)
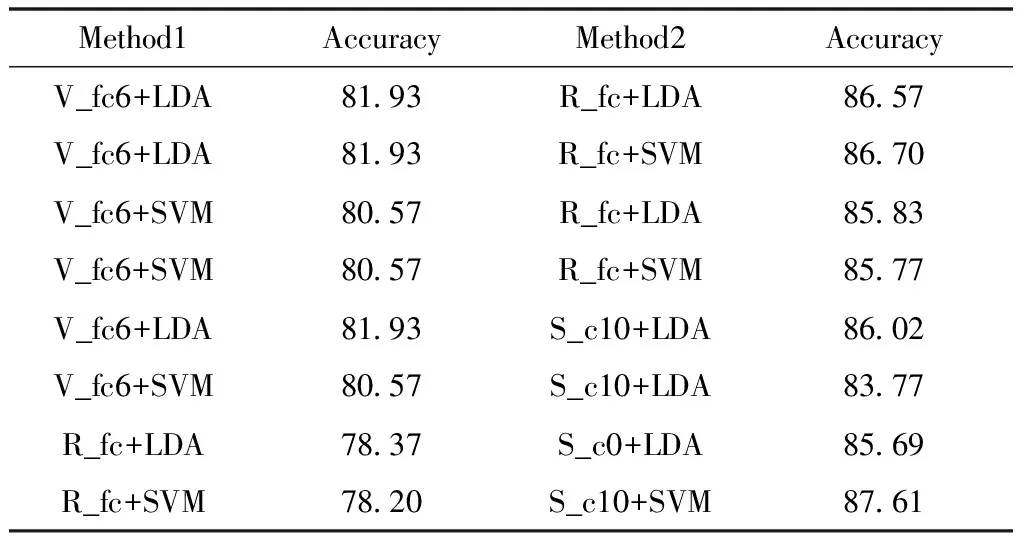
表4 Cifar-10,STL-10,Cifar-100数据集上多方法精确度对比(%)
经过实验验证不同网络的特征在超过三种后或者同网络多特征通过此融合方法性能提高十分有限。在多CNN特征融合的基础上,进一步利用HOGCV特征强化特征空间多样性,参考表5,HOGCV特征对多特征融合的结果有1.5%左右的提高,说明了HOGCV特征能有效强化高级语义特征的多样性,与高级语义特征有着良好的互补性。Cifar-10,STL-10,Cifar-100和GHIM-10K数据集上经过三个不同CNN特征以及HOGCV特征融合,最终分类精度分别达到了93.39%,93.13%,74.58%和90.34%,相比于单个特征的最优结果对比准确率有着7%到12%提高,对比双特征融合的结果有着5%左右的提高,证明了自适应加权融合算法的有效性。
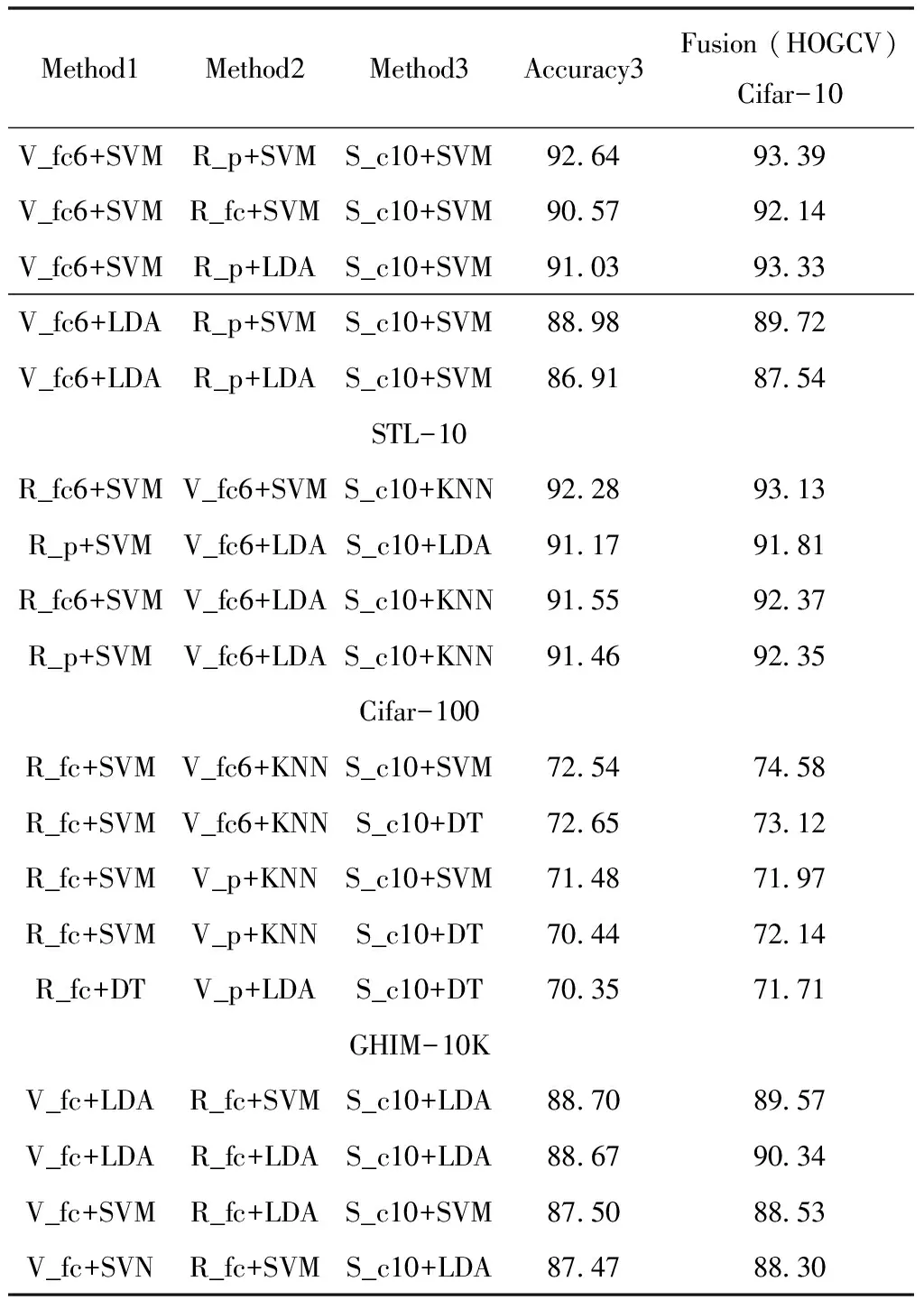
表5 Cifar-10,STL-10,Cifar-100以及Caltech-101数据集上多种特征融合的精确(%)
本文利用预训练模型提取语义特征,通过性能自适应调整融合权重,利用HOGCV特征加强融合特征的多样性,进一步强化了分类性能,在多种数据集上的实验结果表明本文提出的算法具有普适性。与多种先进方法的研究结果进行了对比,文中的方法拥有更显著的性能,并且由于使用的模型都是轻量级且无需进一步训练,效率较高,对于图像分类领域现实应用有着极大的意义,参考表6。
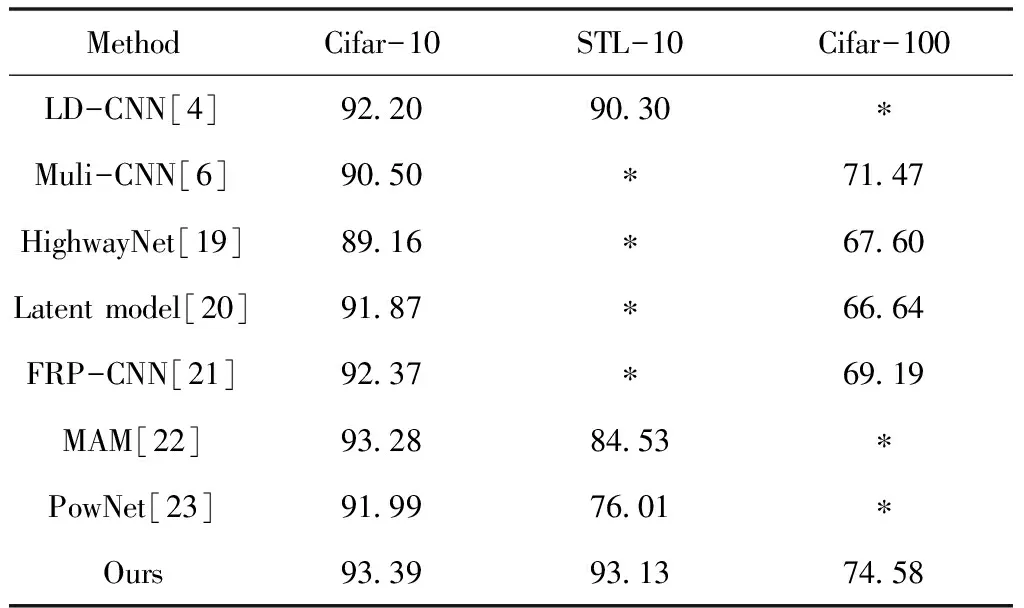
表6 Cifar-10,STL-10,Cifar-100数据集上多方法精确度对比(%)
4 总结和展望
卷积神经网络的快速发展极大推动了计算机视觉领域的进步,对传统手工特征带来了新的机遇和挑战,本文提出了一种基于图像颜色和边缘的手工特征:方向梯度和颜色体积直方图(HOGCV),用于提高了语义特征空间的多样性,还提出利用准确率动态控制多种语义特征和传统特征的自适应加权融合算法,并使用预训练的网络模型提取语义特征,在保证分类结果的同时,极大地加快了算法的计算速度。实验结果证明了不同网络语义特征的互补性更优,验证了 SVM对多种卷积神经网络的健壮性,HOGCV特征对于语义特征强化作用和自适应加权融合算法的有效性。本文通过复杂的融合算法得到了更好地性能,而且在细粒度图像分类上不出色,今后研究目标是优化融合算法和结构,强化其在细粒度图像分类中表现。
