基于轻量化神经网络的空中目标检测算法
2022-08-22杨玉敏廖育荣林存宝倪淑燕
杨玉敏,廖育荣,林存宝,倪淑燕
(航天工程大学,北京 101400)
1 引言
视频卫星在应急事件监控、战场态势感知等军民领域都具有广泛的应用价值,尤其适用于运动目标监视。空中目标检测是视频卫星执行空中目标捕获跟踪任务的必备前提,相比常规图像,卫星视频图像具有背景复杂、光照强度、云层遮挡等干扰因素,且为多视角拍摄,多样性强[1]。而传统的目标检测主要针对手工设计特征,无法适用于多样化的视频图像检测,鲁棒性差。
随着深度学习在计算机视觉领域取得突破性成果,目前很多研究者开始将深度学习应用到遥感影像目标检测领域,并提出很多针对遥感目标检测的网络。戴伟聪等人[2]基于YOLO v3框架,提出了一种改进的遥感图像飞机目标检测算法;余东行等人[3]提出了一种基于级联卷积神经网络的遥感影像飞机目标检测算法;顾恭等人[4]基于YOLO v3网络,提出了一种Vehicle-YOLO的实时车辆检测分类模型。虽然基于深度学习的遥感目标检测算法在检测精度和检测速度上,相比于传统算法都有较大的提升,但是其网络模型体积和计算量普遍都较大,而星载系统本身功耗低,其携带的计算单元的内存、计算能力有限,使得深度学习算法难以在资源受限的星载平台上应用。
针对上述问题,本文改进了YOLO v3[5]的特征提取网络,提出了轻量化的空中目标检测网络。采用MobileNet v3[6]的高效卷积模块Bneck对骨干网络进行了轻量化处理,并通过实验不断对通道超参数更新,在最大化压缩通道数的同时提升了检测速度,并在边界框回归损失函中引入IoU(交并比)提高了精度。
2 基于YOLO v3的轻量化网络改进
YOLO v3是一个经典的端到端目标检测框架,其由骨干网络(backbone)和检测头(head)两部分组成。本文主要基于轻量化网络MobileNet v3对YOLO v3骨干网络部分进行轻量化改进,在保持检测精度的同时,提升网络的实时性。
2.1 轻量化骨干网络的高效卷积模块
网络结构的轻量化设计有一个共同的特点,其网络结构都是由基本构建模块堆叠而成。而基本构建模块是采用不同的卷积方式进行互补组合,充分发挥不同卷积方式的优点,使网络计算量和参数量减少,且不损失网络性能。如图1所示MobileNet v3的高效卷积模块Bneck,其内部模块引入了的深度可分离卷积[7]和线性瓶颈的倒残差结构[8]。同时,采用了squeeze and excitation结构的轻量级注意力机制,对特征通道间的相关性进行建模,将图像的重点特征进行强化计

图1 MobileNet v3 block[6]
算来提升整体网络结构的准确率。Bneck模块在计算量、空间消耗和检测精度方面取得了很好的平衡。
2.2 轻量化骨干网络设计
轻量化骨干网络结构如图2立方体块堆叠部分所示,该网络结构主要采用高效卷积块Bneck堆叠成“金字塔”型网络结构的方式。相比于DarkNet53有53个卷积层,改进的骨干网络只有2个卷积层和17个Bneck模块。而且从Bneck模块中可以看出Bneck模块的卷积操作主要由Pointwise(逐点卷积)和Depthwise-Pointwise(深度可分离卷积)两个主要步骤构成。深度可分离卷积采用Depthwise和Pointwise两个步骤实现卷积,其参数仅约为普通卷积参数量的1/9,乘法计算量仅约为1/c+1/9,其中c为输入通道数。除此之外,轻量级注意力机制通过最大池化操作提取关键点特征,再通过全连接层的学习得到不同通道的权重,在只增加很少网络开销的基础上增加网络对关键特征的学习能力。基于这种高效Bneck卷积模块搭建的网络将大大精简整个模型的体积,极大减少计算量。

图2 改进YOLO v3网络结构
3 损失函数优化
在目标检测网络中,损失函数是对网络误检惩罚的根据,在很大程度上影响着模型收敛的效果,因此设计合适的损失函数以获得更好的检测性能也是网络优化性能的重要方向。YOLO v3的损失函数由三部分组成:定位损失(Localization loss)、分类损失(Classification loss)、置信度损失(Confidence loss),本文主要对网络的定位损失部分进行优化。
3.1 定位损失函数分析
YOLO v3在定位损失中采用了L2范数损失函数,其忽略了ground-truth和预测框之间的交并比IoU。而在目标检测中IoU是比较预测框与ground-truth(真实框)框之间常用的度量标准,是评价网络检测性能的重要指标。IoU函数如公式
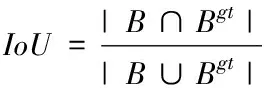
(1)
其中,B是目标预测框;Bgt是ground-truth框,IoU是ground-truth和预测框之间的交并比。
由图3可以看出,采用L2范数作为边框回归损失函数与优化IoU值没有较强的关联,当目标预测框与ground-truth框L2范数均相等时两者的IoU值却不相同。图中右上角在圆心的框为ground-truth框,右上角在圆上的框为预测框,可以看出预测框与ground-truth框的L2范数均相等,但(c)的IoU明显最高,所以采用L2范数作为边框回归损失函数并不能较好地优化网络。
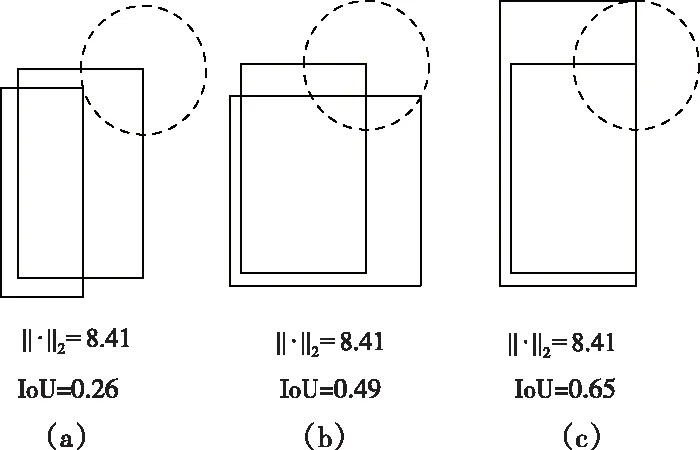
图3 L2范数相同IoU不同
3.2 定位损失函数优化
针对YOLO v3在定位损失中存在的不足,将IoU加入到边界框回归损失函数中。但将IoU直接作为边界框损失函数存在一些缺陷。如图4所示,右边框为ground-truth框,左边框为预测框。当预测框与ground-truth不重合时,IoU的值为0,导致网络无法进一步优化。为了在边界框回归损失函数中加入IoU,将LossIoU作为边界框回归损失函数,直观的反应预测框与ground-truth之间的偏差。LossIoU函数如公式:

图4 ground-truth框与预测框之间关系
其中,LossIoU的取值范围(0,1]。当IoU=0时,LossIoU的值一直为1,无法反应预测框和ground-truth之间的距离关系,如图5中的(b)和(c)两种情况。
为了体现不相交两个边框之间的距离关系,文献[9]提出了GIoU Loss函数。GIoU加入了预测框与ground-truth框的最小外接矩阵面积,克服了LIoU的不足。GIoU函数与LossGIoU函数如公式:

(3)
LossGIoU=1-GIoU
(4)
其中,C是最小外接矩阵面积,B是目标预测框;Bgt是ground-truth框。
4 实验结果与分析
4.1 实验数据集
实验使用的数据集是武汉大学团队标注的RSOD-Dataset以及长光卫星科技集团拍摄的遥感图像。RSOD-Dataset只使用其中的446张包含飞机目标的图像,共4993个目标。通过图像增强的方式,包括对图像进行加噪、调整亮度、旋转等操作,将数据集扩充至1338张图像。随机选取936张作为训练集、267张作为验证集、135张作为测试集。RSOD-Dataset图像尺寸为1044×916,而本文重点针对3840×2160遥感图像进行目标检测。因此,为提升网络检测性能的泛化能力,在进行网络训练时采用随机多尺度训练,并在测试集中加入了100张3840×2160长光卫星技术有限公司提供的高分辨遥感图像。图5展示了数据集的示例图。

图5 数据集
4.2 评价标准
实验中使用平均准确率(mAP)和召回率(R)作为目标检测结果的评价指标。召回率表示被正确检测出来的目标个数(NTP)与测试集中所有目标的个数(包括正确检测NTP和漏检NFN)的比值,可以表示为
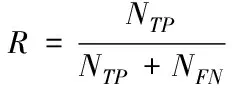
(4)
式中NTP为被正确检测出的个数,NFN为目标被漏检的个数,NTP和NFN相加就是数据集中目标总数。
数据集中某个类别C在一张图像上的检测准确率PC等于在该图像上正确检测出的类别C的个数NTP-C与该图片上检测出的类别C的总数(包括正确识别NTP-C和误识别NFP-C)的比值
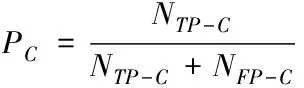
(5)
类别C在所有包含该类别的图片中的单类平均准确率APC等于数据集中包含该类别的每张图片的PC求和后与数据集中含有类别C的图片总数N:
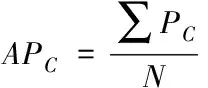
(6)
实际对于每一种类别,平均准确率是准确率随召回率变化(PR)曲线的积分,如图6所示为改进网络检测飞机目标的PR曲线,其平均检测精度是其PR曲线的积分,即曲线与坐标轴的面积。从图中可以看出网络检测召回率和检测准确率分别在85%和95%以上。

图6 PR曲线
对于包含m个类别的数据集,其平均准确率mAP等于各个单类平均准确率求和后除以类别数m
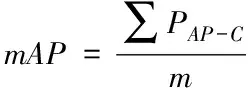
(7)
由于本实验中类别数m=1,因此实际中PmAP=PAP。
4.3 网络模型的训练与测试实验
实验采用的软硬件平台配置如下。
CPU:Intel(R)Core(TM)i9-7900X@3.30GHz;GPU:NVIDIA Titan XP;系统环境:ubuntu16.04、CUDA(Compute Unified Device Architecture)10.0、cuDNN(CUDA Deep Neural Network library)7.4;深度学习框架:Tensorflow。
网络训练时输入尺度采用的是多尺度输入训练,初始学习率为0.001,批(batch size)设置为8,epoch设置为100(每迭代5步输出一次损失值)和200(每迭代10步输出一次损失值)两种情况对网络进行训练。如图7所示为损失函数衰减变化情况。从图7(a)和图7(b)可以看出网络损失函数在随着网络的迭代周期不断下降,验证了GIoU损失函数在改进YOLOv3中的有效性,且网络的迭代次数越多,损失函数越小。

图7 损失函数
见表1,YOLO v3和改进网络的性能。通过对比可以发现:使用GIoU损失函数的算法性能可以产生很好的检测效果,在改进的网络检测精度上提升了2.1%。同时,改进的网络相比于YOLO v3参数量压缩了3.2倍,检测速度(帧数/秒)相比于YOLO v3提升了2倍。

表1 性能对比
网络测试效果如图8、9所示,图8为输入尺寸1044×916遥感图像检测结果,图9为输入尺寸3840×2160遥感图像检测结果。可以看出算法无论是在检测精度、检测速度以及泛化能力都达到了较好的效果。

图8 图像大小为1044×916

图9 图像大小为3840×2160
5 结束语
本文提出了一种轻量化的卷积神经网络结构,用于视频卫星对空中目标实时检测。该网络基于YOLO v3进行了轻量化的改进,利用MobileNet v3中的高效卷积模块Bnec搭建“金字塔”型的精简骨干网络。Bneck模块中引入的注意力机制,在一定程度上解决了高像素小目标漏检、错检以及重复检测等问题。同时,在边界框回归损失函数中引入了GIoU损失函数,增强了目标定位精度。改进的轻量化网络在检测精度上达到了88.7%,并获得了43.7FPS的检测速度。在后续的工作中,将进一步研究高像素小目标的轻量化检测算法,并且利用改进型的算法和星载平台结合,实现卫星在轨实时检测。
