融合词嵌入和通道注意力机制的网络安全态势预测
2022-08-19史飞洪李敏芳
史飞洪,李敏芳
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
随着网络技术的快速发展,网络安全问题变得日益严重。结合深度学习技术对网络安全态势进行感知并以此解决网络安全问题,具有广阔的应用前景。一般来说,网络安全态势感知具有态势要素提取、态势理解以及态势预测三个核心要素[1],具体如图1 所示。

图1 态势感知三级模型
现在,大多网络安全问题都是由Web 攻击引起的,如SQL 注入、Web 后门以及代码执行等。而Web 攻击数据基于超文本传输协议(Hyper Text Transfer Protocol,HTTP)请求,是文本数据的一个类型。在基于深度学习的文本分析研究上,最初,由于循环神经网络(Rerrent Neural Network,RNN)能够记忆序列信息的上下文语义信息,所以其应用范围为文本数据[2]。但是,RNN 存在梯度消失和梯度爆炸的问题[3]。为解决这一问题,此后出现了长短期记忆网络(Long Short-Term Memory,LSTM)[4]和引入了门控循环单元(Gated Recurrent Unit,GRU)的RNN 神经网络[5]。两者都是通过引入门的机制来解决RNN 的梯度消失和梯度爆炸问题,只不过GRU 在保证性能的同时,比LSTM 具有更少的门。但两者都是RNN 的变种,因此也存在无法并行训练、训练效率低等问题。随着训练复杂度的增加以及训练数据规模的日益增大,这一弊端越来越明显。基于此。KIM[6]将卷积神经网络(Convolutional Neural Network,CNN)应用到文本分类任务。针对CNN 并不能很好地捕获特征图的重要信息问题,引入了SEnet[7]中的SE(Squeeze-and-Excitation)模块注意力机制,获取特征的重要程度。
综上所述,GRU 虽然能够获取文本的上下文语义信息,但是存在无法并行训练、效率低以及不能有效注意到单词的重要程度的问题。而SEnet 虽然能解决上述问题,但是同样不能充分提取单词自身的语义信息。针对上述问题,本文提出了E-SECNN 模型。首先利用Embedding 层获取单词自身的语义信息,其次利用CNN 解决无法并行训练、效率低的问题,最后利用SE 模块给予CNN 提取到的特征图不同的权重,来注意到不同单词的重要程度。为验证E-SE-CNN 的模型的有效性,本文在基于告警日志构建的Web 攻击数据集的基础上,设计了5组实验来进行对比。
1 E-SE-CNN 模型构建
E-SE-CNN 模型包含输入模块、Embedding 模块、SE-CNN 模块以及输出模块,具体如图2 所示。

图2 E-SE-CE 模型结构图
1.1 输入模块
经过处理的告警日志数据集的输入序列长度为300,所以输入模块的输入词向量序列长度为300,记为X300=w1,w2,w3,…,w300,用于输入Embedding 模块中。
1.2 Embedding 模块
Embedding 模块输入为X300,即长度为300 的token序列,输出为token 序列的分布式表示矩阵X300,224。具体来说,这一模块主要是用来对输入的词向量序列进行分布式表示,使其能够包含充足的语义信息。输入模块的词向量序列输入到Embedding 模块最终获得的词向量序列的分布式表示如式(1)所示:

式中:X300为经过词向量化之后的长度为300 的token 序列,每条数据包含300 个单词;X300,224为经过Embedding操作之后,这300 个单词的分布式表示矩阵。
1.3 SE-CNN 模块
SE-CNN 模块的输入为token 序列的分布式表示矩阵X300,224,输出则为带有权重的特征图。具体由图2 可知,SE-CNN 模块分别由两个CNN block和SE block 交叉连接组成,每个CNN block 由若干个卷积层、池化层及批归一化层组成,每个SE block则由通道注意力机制和残差机制组成。SE-CNN 模块主要是对输入token 序列分布式表示矩阵进行特征图提取、变换以及为不同通道的特征图赋予不同权重,以期注意到更加重要的单词。其中,CNN 部分主要负责特征图的提取、变换;SE 部分主要负责对CNN提取、变换后的特征图通道赋予不同的权重。SE 部分的结构如图3 所示,它主要通过残差连接的方式对每个通道赋予权重。假设输入特征图尺寸为C×H×W(其中C是特征图的通道数,H为特征图的高度,W为特征图的宽度),这一特征图先经过通道注意力机制获取每个通道的权重值Cw,再通过残差连接的方式进行对原来特征图的通道赋予权重Cw,获取到赋予通道权重的特征图。

图3 SE block 结构图
SE block 的具体机制如下。
首先,对卷积层CL 层输出的特征图通过GAL层进行全局平均池化,以完成对特征图在空间维度的压缩,只保留通道维度,特征图的尺寸由原来的C×H×W变为C×1×1:

其次,通过全连接层FL1,经过ReLU 激活进行非线性变换后,将通道维度压缩,以减少参数量和计算量,具体为:

1.4 输出模块
输出模块的输入为SE-CNN 模块的输出(SE block2 的输出SLout),输出为每个标签的概率。由图2 可知,输出模块由Flatten 层、Sigmoid 层以及分类结果三部分组成。其中,Flatten 层主要做展平操作,对SE-CNN 模块输出的特征图展平成一维;Sigmoid 层对展平后的特征向量进行归一化(由于任务是多标签分类,因此选取的是Sigmoid 函数);分类结果则输出满足阈值的标签,完成对Web 攻击数据的多标签分类。
2 数据集
2.1 数据集描述
由于本文是某运营商的一个大数据分析与挖掘项目的一个模块,因此本研究的数据集为该运营商网络安全设备产生的Web 攻击日志数据。数据集包含了从2021 年5 月—2021 年11 月共6 个月的告警日志数据,共计约2 400 万条数据,脱敏后的数据集共有12 个属性。数据集的具体详情如表1 所示。
实际上,Web 攻击日志数据是网络安全设备通过对每条请求数据进行专家系统的规则匹配而生成的。结合表1 可以得知,除了dip,dport,sip,sport,request_head,time 这6 个属性,其余的属性都是基于网络安全设备的专家系统生成的。因此,本文以专家系统生成的可信度较高且经过网络安全管理人员检查过的Web 攻击日志数据为指导,学习原始数据中的规律,并训练出网络安全态势预测模型。

表1 数据集详情
2.2 数据预处理
通常情况下,大规模的数据集存在很多失真的数据。除此之外,原始数据集本身的数据形式并不符合模型的输入格式。因此,必须对获取到的数据进行初步的筛选,也就是预处理。在本文中,数据预处理主要包含数据清洗、特征选择及特征重构三部分。数据清洗主要负责清洗掉置信度较低且未经过网络安全管理人员检查的Web 攻击日志数据,清洗之后,数据集由原来的2 400 万条缩小到约900万条;特征选择主要选择合适的属性作为本文模型的输入和标签,这里选择了request_head 这一属性作为模型的输入,attack_mode_name_cn(攻击列表)属性作为数据集的标签;特征重构主要负责重构模型的输入和标签数据,这里对文本类型的request_head(请求头)数据,根据专家意见制定了若干个正则规则用来切分数据,从而构建字典完成request_head 的词向量化(长度为300 的token 序列),同样对文本类型的attack_mode_name_cn(攻击列表)数据进行了标签化(由于其总共有56 类,因此标签为长度为56 的向量)。经过上述三步预处理操作后的数据如表2 所示。

表2 预处理后的数据
3 实验与分析
3.1 实验环境
本文的实验环境为:Ubuntu 操作系统,CPU为9 核Intel(R) Xeon(R) Silver 4210R CPU@2.40 GHz,内存为256 GB,显卡为RTX 3090,显存为24 GB,编程语言为Python 3.7,深度学习框架为Tensorflow 和Keras。
3.2 评估指标
本文采取F1score 作为评估指标。若该指标较高,表示模型在高占比的标签上具有良好的表现。除此之外,也保留了Recall和Precision作为评估指标。同样,为了客观地评价模型的性能,本文分别计算了BCE Loss(Binary Cross Entropy Loss)和Hamming Loss。这5 个评估指标的计算式分别如下。
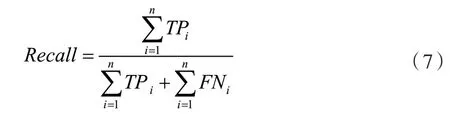

式中:n表示类别个数,在本研究中是56;m表示样本数,yj为样本j的标签,y^j为样本j的预测结果;yij表示样本j在第i类上的标签,y^ij表示样本j在第i类上的预测结果。
3.3 Embedding 层对Web 攻击分类结果的影响
为了评估Embedding 层对token 序列进行分布式表示是否对语义信息的表示有益,本文设计了两个网络模型做了一组对比实验。这两个模型分别为MLP 和E-MLP。MLP 是一个简单的多层感知机,输入的是token 序列。E-MLP 是经过Embedding 层之后MLP 网络输入的分布式表示的token 序列特征图。图4 给出了在Web 攻击数据集上,训练过程中验证集上hamming loss 变化曲线。由图4 可知,E-MLP 能够更快地收敛,且损失值远远低于MLP的损失值。图4 中的曲线比较平滑、看不出波动的原因是,E-MLP 和MLP 的损失值差距过大,而波动相对于这个差距是很小的一个数字,所以会看起来很平滑,实际上是存在波动的。

图4 MLP 和E-MLP 验证集汉明损失变化图
表3 的结果展示了引入了Embedding 层后的E-MLP 网络在测试集上的5 种评估指标均远远高于未引入Embedding 层的MLP 网络,并且在推理速度上相等。实验表明,Embedding 层对token 语义信息的提取具有非常积极的意义。

表3 Embedding 层对Web 攻击分类结果的影响
3.4 CNN 相对于GRU 对Web 攻击分类结果的影响
为了评估CNN 相对于GRU 在训练速度上是否有提升以及表现性能的变化,本文设计了两个网络模型做了一组对比实验。这两个网络模型分别为E-GRU和E-CNN。E-GRU是通过Embedding层之后,GRU 网络输入的分布式表示的token 序列特征图,E-CNN 是经过Embedding 层之后,CNN 网络输入的分布式表示的token 序列特征图。图5 给出了在Web 攻击数据集上训练过程中验证集上hamming loss变化曲线。由图5可知,E-CNN能够更快地收敛,且损失值低于E-GRU 的损失值。

图5 E-GRU 和E-CNN 验证集汉明损失变化图
表4 的结果展示了E-GRU 和E-CNN 两个网络在测试集上的表现。在5 种评估指标上,E-CNN在其中4 种上略微高于E-GRU,说明CNN 神经网络对语义特征具有较强的提取表征能力。值得注意的是,E-CNN 在测试集上的速度相较于E-GRU 提升约21%。实验表明,相较于GRU,CNN 对于训练推理速度有显著提升,且性能有略微提升。

表4 CNN 相对于GRU 对Web 攻击分类结果的影响
3.5 通道注意力机制对Web 攻击分类结果的影响
为了评估通道注意力机制对Web 攻击分类结果的影响,本文设计了两个网络模型做了一组对比实验。这两个网络模型分别为E-CNN和E-SE-CNN。E-CNN 不具有通道注意力机制,E-SE-CNN 带有通道注意力机制。图6 给出了在Web 攻击数据集上的训练过程中验证集上hamming loss 变化曲线。由图6 可知,E-SE-CNN 能够更快地收敛,且损失值低于E-CNN。

图6 通道注意力机制-验证集上汉明损失变化图
表5 的结果展示了在引入了通道注意力机制后的E-SE-CNN 网络在测试集上的5 种评估指标均高于未引入通道注意力机制的E-CNN 网络。由于引入了通道注意力机制,增加了计算量,因此在推理训练速度上有一定程度的增加。实验结果表明,通道注意力机制对重要语义信息的提取具有一定的积极的意义。

表5 通道注意力机制对Web 攻击分类结果的影响
3.6 所有模型的表现
为了进一步对比所有模型在Web 攻击数据集上的表现,且为了消除MLP 损失值过大对量纲的影响,详细观察Hamming Loss 变化,去除MLP 的损失变化后,整体损失变化曲线如图7 所示。

图7 所有模型在验证集汉明损失变化图
由图7 可知,在所有模型中,E-SE-CNN 具有最快的收敛速度和最低的损失值。其次是E-CNN。这表明在收敛速度上,CNN 具有较大的优势,并且性能表现也较好。
表6 的结果展示了所有模型在Web 攻击数据集上5 种评价指标的表现。其中,引入了Embedding 层、CNN 及通道注意力机制的E-SECNN 具有最佳的表现,相较于E-GRU,性能有较高的提升,同时训练推理速度并没有增加。实验结果表明,Embedding 层对于语义信息的表征具有极大的积极意义,CNN 对于训练推理速度的提升具有较大的影响,通道注意力机制对于重要语义信息的提取具有一定的积极意义。

表6 所有模型在Web 攻击数据集上的表现
4 结 语
针对GRU 神经网络不能很好地注意到关键词且训练速度较慢的问题,本文提出了一种融合词嵌入和通道注意力机制的网络安全态势预测模型E-SE-CNN。该模型首先利用Embedding 层进行词嵌入获取token 序列的分布式语义表示矩阵,利用该矩阵构建token 序列的二维特征图,其次基于此引入2D 卷积对特征图进行语义提取和尺寸变换,最后引入通道注意力机制(SE)实现对重要语义信息的关注。E-SE-CNN 的优势在于,在保证了训练推理速度的同时,充分提取了token 序列的语义信息,较好地关注了重要的语义信息,进而提升了模型的性能。实验结果表明,该模型在5 种评价指标上都具有较好的表现,其中F1score 达到了0.998 621,充分表明了该模型的有效性和可行性。
本文在设计卷积神经网络时,仅仅考虑了单支卷积神经网络,并没有充分利用CNN 结构灵活的特性,设计多支交叉融合的CNN,进一步提升模型的性能,加快模型的训练推理速度。由于时间原因,模型的验证工作仅在自建的Web 攻击数据集上进行。在未来的研究工作中,将结合现有的优秀的CNN 网络结构,设计参数量更少、训练推理速度更快、性能更好的多支交叉融合的CNN 模型,进一步提升模型的表现。同时,为了进一步验证模型的表现,将会对模型在公共数据集上进行验证。
