多预测融合的脑电情绪识别迁移方法
2022-08-19梁圣金
梁圣金
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
情绪对人们的言行举止有着重要的影响。情绪的刺激和响应理论认为,主体对客观事物和环境的评价水平是情绪唤醒和产生的关键所在[1]。已有研究表明,情绪与一些精神疾病密切相关,如受到情绪调节影响的抑郁症[2]。所以,对情绪的研究,将有助于人们对自身情绪状态及其影响拥有更深入的认知。
近年来,一种能够从人类的大脑活动中检测情绪状态的情感脑机接口[3]技术得到了越来越多的关注。脑电具有非侵入性和时间分辨率高等优点,常用于记录大脑活动。相比于面部表情、声音及身体姿态等,脑电信号不易受到个体的刻意控制,为情绪识别提供了客观可靠的基础。但是,脑电信号的非平稳特性[4]使得不同个体间(跨被试)或不同时段下(跨会话)的脑电数据不满足机器学习中独立同分布的要求,不利于已有情绪识别模型的推广应用。最近,迁移学习技术为该问题提供了一些解决方案,如其中的领域自适应[5-7]方法尝试从原始领域(源域)和应用领域(目标域)中挖掘领域不变的成分。
但是,在一些实际应用场景中,模型可能无法预先获取待测试被试的任何数据。而且,对目标被试建立的情绪识别模型也会随着时间的推移而过时。对此,少部分研究者尝试求助于领域泛化[8]方法。例如,MA 等人[9]和ZHAO 等人[10]为所有源域被试提取共享特征,并为每个源域被试独立地提取特定特征,其中提取共享特征的组件有利于改善对目标被试的预测效果。相比于领域自适应方法,领域泛化方法因其在模型的训练阶段无需访问目标域而有利于情感脑机接口的推广应用,值得进一步的开发。
为了探讨领域泛化在脑电情绪识别中的可行性,本文提出一个名为领域对抗多预测融合的迁移方法,利用特征提取器和领域分类器之间的对抗训练来从各个源域中提取领域不变的特征。此外,分别为每个源域延伸出一个独立的标签预测器,以充分利用不同源域的情绪判别信息进行融合预测。最后,在情绪脑电数据集上验证了所提方法的性能。
1 方 法
1.1 问题定义
当测试领域(目标域)完全未知时,只能尽可能地从训练领域(源域)中学习具有较好泛化能力的模型。在基于脑电信号的情绪识别中,当预先训练的模型服务于大众时,它可能会遇到为模型提供过训练数据的人(跨会话场景),但更多时候都会面临着未知的测试者(跨被试场景)。这些真实的场景对模型的成功应用提出了较高的要求。本文尝试探索领域泛化在脑电情绪识别中的可行性,以减少对目标域数据的需求。

1.2 领域对抗多预测融合
1.2.1 网络框架
为了应对在训练模型过程中无法访问目标域的情况,本文提出了一个领域对抗多预测融合(Domain-Adversarial Multi-Prediction Fusion,DAMPF)网络,结构如图1 所示。其中,虚线箭头表示对目标域进行预测时的行为。DAMPF 网络主要由一个特征提取器、一个领域分类器以及K个标签预测器组成。

图1 领域对抗多预测融合(DAMPF)网络框架
特征提取器用Gf表示,参数为θf。其作用是把各个领域的输入数据映射到一个公共的特征空间中,以供后续使用。
领域分类器用Gd(参数为θd)表示,用于判断输入样本来自哪个领域。对于K个输入源域,Gd是一个K类分类器。它和特征提取器之间通过一个特殊的梯度反转层[11]进行连接。梯度反转层在前向传播过程中不起作用,而在反向传播过程中先将领域分类器传给它的梯度乘以-1 再传给前面的特征提取器。在梯度反转层的作用下,特征提取器和领域分类器在基于标准反向传播的训练过程中往相反的方向进行优化。具体而言,领域分类器尽量区分输入样本的原始领域,而特征提取器尽量混淆输入样本的原始领域以提取领域不变的特征。

1.2.2 模型优化
在本文考虑的问题中,各个给定的源域的数据均已标注。这些带标签的源数据可以用来训练各个标签预测器,其中第k个标签预测器的损失可以计算为:


式中:λ为权衡标签预测损失和领域分类损失的超参数。训练模型时,在梯度反转层的帮助下,优化过程可利用标准的梯度下降来完成。因此,通过最小化总的损失就可以同时学习所有组件的参数。
1.2.3 模型预测
在预测阶段,对所有标签预测器的预测输出进行融合,来判断对应目标样本的情绪类别。所采用的融合策略为求多个预测的平均值,相当于给予各个标签预测器相同的权重。具体地,对于来自目标域的样本xi,第k个标签预测器的输出为:

2 实验设置
2.1 数据集
为了对所提的DAMPF 网络进行评估,本文在常用的情绪脑电数据集SEED[13]上执行迁移实验。SEED 数据集包含15 名被试在观看情感电影片段时所采集的脑电数据,包含积极、中性及消极三种情绪类别。每名被试在不同的日期共参与了三次数据采集实验,其中每次实验被称为一个会话。在每个会话中,每名被试共观看了15 个情感电影片段,每个电影片段持续约4 min。每种情绪所对应的电影片段数量是一致的,这意味着每种情绪的样本数量基本一致。由于脑电采集实验中所使用的设备有62 个通道,而每个通道的数据又划分为5 个频段,所以每个样本的维度为62×5=310。预处理后的脑电数据被分割成许多个长度为1 s 的无重叠时间序列,并从中提取微分熵特征。最终从每个会话得到3 394 个样本。
2.2 迁移场景
本文考虑跨被试和跨会话这两种迁移场景下的脑电情绪识别。
在跨被试场景中,每个方法都需要执行15 次实验。每次实验都从15 名被试中选择一名被试作为目标域,而其余14 名被试作为源域,使得每名被试都有机会成为目标域。实验中每名被试仅包含其一个会话的脑电数据。对15 次实验的目标域准确率求平均值和标准差。
在跨会话场景中,对于每名被试,都将其第一个会话和第二个会话作为源域,而剩余的第三个会话作为目标域,使得每名被试独立地进行实验。对于每个方法,对所有15 名被试的目标域准确率取平均值和标准差。
2.3 对比方法及实现细节
对比实验将所提方法与基线方法、领域自适应方法及领域泛化方法进行比较。
本文将k最近邻(k-Nearest Neighbors,KNN)方法作为基线方法。它没有采用迁移学习技术,直接将从源域训练得到的模型应用于目标域。KNN的参数k设置为5。
领域自适应方法包括迁移成分分析(Transfer Component Analysis,TCA)[14-15]和联合分布自适应(Joint Distribution Adaptation,JDA)[16]方法。TCA通过对齐源域和目标域的边缘分布来促进知识迁移,而JDA 又进一步地对齐跨领域的条件分布。对于TCA 和JDA,降维后的维度为30,正则化参数为1,训练模型的源域样本数量为5 000(由于内存有限,仅使用所有源域样本的子集)。JDA 的迭代次数为10。
领域泛化的对比方法为领域对抗神经网络的领域泛化变体(Domain Generalization in Domain-Adversarial Neural Network,DG-DANN)[9]。 它 利用一个特征提取器、一个标签预测器及一个领域分类器来从源域的数据中提取领域不变成分。对于DG-DANN,特征提取器有3 层,分别有512,256,128 个节点。标签预测器有3 层,节点数量分别有64,32 和3 个。领域分类器有3 层,分别有256,256 和K个节点,其中K为源域的数量。
对于本文所提出的DAMPF 网络,特征提取器、领域分类器及每个标签预测器的层数和节点数都与DG-DANN 的一样。此外,与仅有一个标签预测器的DG-DANN 不同,DAMPF 网络为每个源域都设置了一个标签预测器。
对于DG-DANN 和DAMPF 网络,权衡参数λ的设置遵循文献[11]:λ=2/(1+e-ηp)-1,其中η=10,p为模型训练进度,使得λ从0 逐渐变化到1。
3 实验结果及分析
3.1 跨被试实验
各个方法在SEED 数据集上进行跨被试实验的结果如图2 和表1 所示。
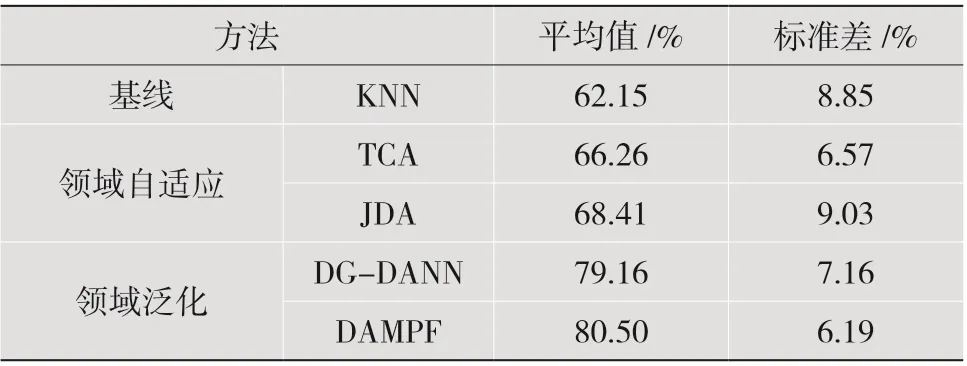
表1 各个方法的跨被试实验的平均结果
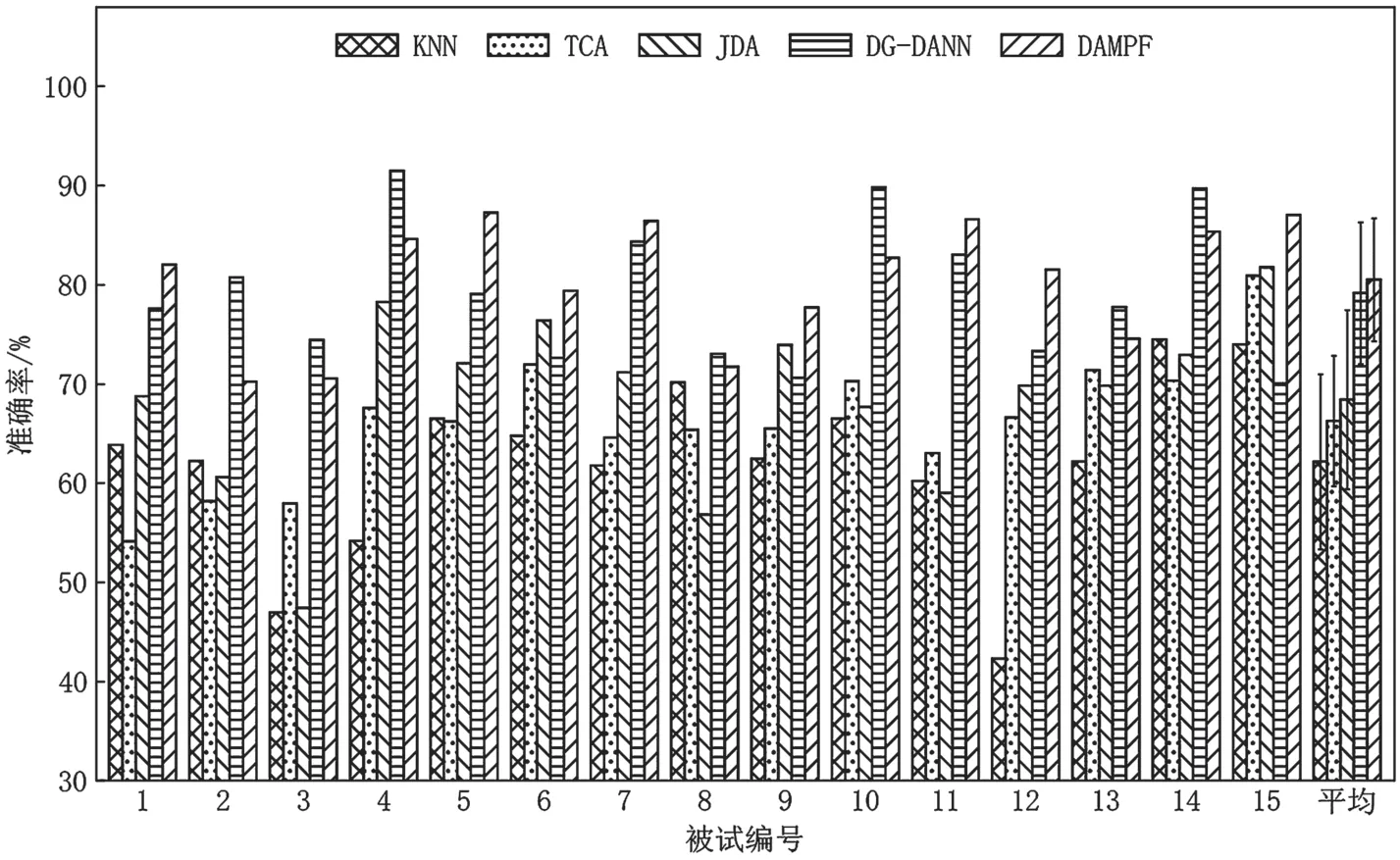
图2 每名被试作为目标域时所对应的跨被试实验结果
基线方法KNN 取得了62.15%的平均准确率和8.85%的标准差。KNN 没有使用任何迁移学习技术,因此将它作为最基础的对比方法。
传统的领域自适应方法TCA 和JDA 分别取得了66.26%(6.57%)和68.41%(9.03%)的平均结果,在平均准确率上与KNN 相比分别提升了4.11%和6.26%。由此可见,对齐源域和目标域的边缘分布和条件分布,可以减小领域之间的差异;使用迁移学习技术,可以改善跨被试的脑电情绪识别效果。
基于神经网络的方法(DG-DANN 和DAMPF)均比基于传统机器学习的方法(KNN、TCA 及JDA)有较大的性能提升,平均准确率都提升了10%以上。可见与神经网络相结合的迁移方法能够提取可迁移性更高的特征,使得源域和目标域的差异变得更小,从而更有利于对目标域数据的预测。
本文所提出的领域泛化方法DAMPF 取得了80.50%的平均准确率和6.19%的标准差。在平均准确率上,利用神经网络构建的DAMPF 方法相比传统的领域自适应方法TCA 和JDA 有了较大的提升,分别提升了14.24%和12.09%;DAMPF 方法比仅有一个标签预测器的领域泛化方法DG-DANN提升了1.34%,在所有方法中取得了最好的效果,说明利用多个标签预测器的预测进行融合的迁移方法可以提升模型的泛化能力。此外,DAMPF 方法取得了最低的标准差,说明它的稳定性较高。由于DAMPF 不需要目标域的任何数据参与模型训练,所以这些实验结果表明它在跨被试场景中应用时具有较好的性能。
3.2 跨会话实验
各个方法在SEED 数据集上的跨会话实验结果如图3 和表2 所示。图3 比较了各个方法在每名被试中进行跨会话实验的准确率,表2 给出了各个方法在所有跨会话实验中的平均准确率和标准差。下面对跨会话实验结果进行分析。
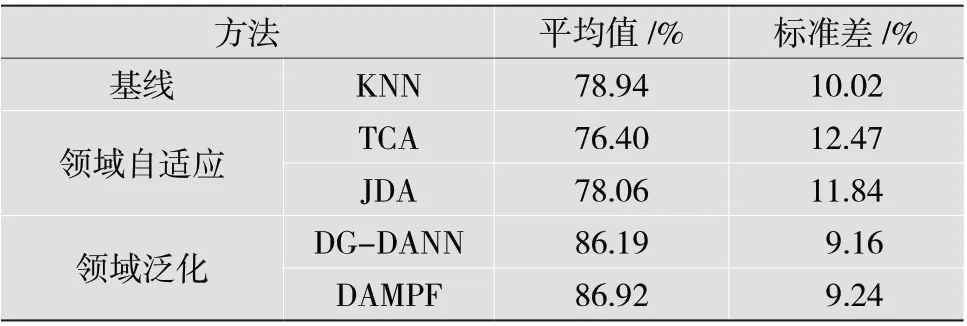
表2 各个方法的跨会话实验的平均结果

图3 每名被试所对应的跨会话实验结果
在跨会话实验中,所有方法的平均准确率都比跨被试实验有了很大的提升,其中基于传统机器学习的方法(KNN、TCA 及JDA)的提升幅度尤为明显。这些观察说明,同一被试内部不同会话的脑电数据虽然存在领域差异,但其差异比不同被试之间的要小很多。
可以发现,TCA 和JDA 的结果略逊于KNN。这可能是因为TCA 和JDA 只使用了源域的部分数据来训练模型,而KNN 则使用了全部的源域数据。
从实验结果中同样也发现了基于神经网络的方法(DG-DANN 和DAMPF)比基于传统机器学习的方法(KNN、TCA 和JDA)取得了更好的效果。这说明在跨会话场景下,神经网络有利于提高所学习特征的判别性,使得情绪识别模型的准确率更高。
本文所提出的领域泛化方法DAMPF 的平均准确率较传统领域自适应方法有了较大的提升,也优于领域泛化方法DG-DANN,并且在所有对比方法中取得了最好的预测效果。这些结果表明,DAMPF 充分利用了源域中各个会话的数据分布来学习较为通用的模型,并通过利用不同标签预测器的输出进行多预测融合提供了较好的性能。
4 结 语
本文提出了一个领域泛化的迁移方法,即领域对抗多预测融合。该方法利用特征提取器将所有源域映射到一个公共的特征空间,并利用领域分类器和梯度反转层增强特征的领域不变性;目标域数据的预测由所有标签预测器的预测的平均融合来决定。为了评估所提方法的性能,本文分别执行了跨被试和跨会话两种场景的迁移实验。实验结果表明,所提方法的性能优于其他对比方法,证明了所提方法在脑电情绪识别的迁移问题中的有效性,也表明领域泛化方法可以在无需利用目标域数据来训练模型的前提下维持较好的情绪识别准确率。
