毛笔书写视频中运笔骨架动态提取方法
2022-08-17申子宜王佳玉
夏 曦,申子宜,王佳玉,覃 璐,施 霖
(昆明理工大学 信息工程与自动化学院, 云南 昆明 650500)
汉字骨架提取的研究大多都是基于粗细均匀的硬笔字或印刷字体。目前对于书法字的骨架提取并没有通用的算法。常见的传统骨架提取方法按照其处理方式可分为距离变换和轮廓点删除两大类[1]。周正扬等[2]提出了一种基于局部关联度的手写汉字骨架提取算法,在原有基础上对骨架点做归类处理,改进复杂区域的骨架点连接策略,对传统骨架在复杂区域产生的畸变有良好的修正效果。常庆贺等[3]在Zhang等[4]细化算法的基础上,使用消除模板和保留模板,不仅能保证汉字骨架的连通,还去除了骨架毛刺。赵春江等[5]提出了一种基于正方形的中轴变换算法,通过统计判断图像中每个像素点个数,并对其进行中轴变换查找骨架点,生成最终的骨架,该算法具有一定的鲁棒性。张若文等[6]提出一种基于距离变换的对图像局部区域采取最大值搜索的骨架提取方法,该方法适用于二维、三维图像的骨架提取。吕岳等[7]提出了一种基于并行操作处理的图像细化算法,通过设定好的细化模板来提取图像骨架,提取的骨架具有良好的连通性。CUI Xue-sen等[8]提出了一种通过统计边界压力大小的图像骨架提取方法,先标定图像边界范围、再统计每个像素点的受力大小等步骤来判断该点是否可以作为图像骨架提取的标准点。蔡兴泉等[9]针对图像骨架的毛刺、骨架信息冗余等问题提出了基于漫水填充的骨架提取方法,该方法获得到的骨架图像毛刺明显减少。距离变换类的方法中以基于中轴变换[10-11]的算法最为常见,其中最大圆盘算法最为著名。这类方法对图像边缘的细微变化不具有鲁棒性。轮廓点删除算法根据像素点处理顺序的不同又可分为串行细化、并行细化和综合型细化[12],这类算法能最大限度得到图像连通的拓扑结构,但提取出的骨架极易畸变失真,笔画交叉处连通性差。
书法字的骨架提取研究都是在传统算法的基础上做一些局部优化,提取的骨架依然或多或少存在形变、分叉、不连通等问题。同时,目前多数研究都是基于静态的书法字图像进行骨架提取。本文则是提出了一种基于书写过程中墨迹增量的书法字骨架动态提取算法。
1 毛笔书写视频
1.1 毛笔墨迹分离的拍摄方式
搭建平台采集书写视频,并基于视频完成对书法骨架的提取。毛笔运笔书写视频中包含着完整的书写过程。若以最常见的从上方拍摄方式,无论垂直还是带有一定倾角,在这个过程中毛笔与墨迹始终紧密相连。这种方式会同时采集到毛笔的运动轨迹和墨迹的形态进程,两者难以分离,如图1(a)所示,而且墨迹会被手挡住摄像视线,如图1(b)所示。

(a) 倾斜视角 (b) 垂直视角图1 拍摄毛笔书写图像
即使能够解决上述问题,也依然有更复杂的问题。即将毛笔和墨迹分离后,由于书写过程中毛笔有提起运动的过程,毛笔笔尖的运动轨迹也分为书写轨迹和非书写轨迹,还需要将这二者分离。
图2为《九成宫醴泉铭》中“九”字书写时的运笔轨迹,其中笔划中虚线为书写轨迹,笔划外虚线为非书写轨迹。如需通过算法将这两者分离,实现起来有一定难度,可能还需要一定的人工干预,不利于批量处理。

图2 “九”字运笔轨迹
针对上述问题,本文尝试了一种新的拍摄方式,即从下方拍摄进行视频采集。这种方式能准确地获取书写时纸张上墨迹的变化,通过墨迹变化去还原行进轨迹。
1.2 书法视频的矫正
由于光照不均匀、摄像头拍摄存在畸变等因素影响,采集到的毛笔字书写视频还存在一些诸如边缘噪声、墨迹模糊等问题。这些问题会对后续骨架提取的结果产生不同程度的影响,因而在此之前,还需要对书写视频进行预处理,以便后续算法能更好地实现。
预处理部分包括畸变矫正、倾斜矫正、灰度化、二值化、图像去噪,具体流程如图3所示。

图3 视频预处理流程图
1.2.1 相机标定和图像去畸变
相机标定法原理是用如图4所示的棋盘格来表示视界坐标系。具体操作是将棋盘格标定板打印出来,用摄像机拍摄。拍摄得到标定板的照片后,再通过角点检测算法检测各个角点的坐标(u,v)。然后将标定板打印,以不同位置和角度置于平台摄像头上方,采集标定板图像。最后使用OpenCV中自带的角点检测相关函数cv2.findChessboardCorners (),使用其检测角点的坐标并使其可视化。



图4 标定板照片的角点检测图像
由于视界坐标系已经被固定在棋盘格上,则棋盘格上任意一点(Xw,Yw,Zw)中Zw=0,由于标定板上格子的尺寸大小已知,则可以计算每一个角点(u,v)在视界坐标系下的坐标(Xw,Yw,Zw),从而计算出相机的畸变参数,并以此参数来矫正图像。OpenCV中有去畸变函数cv2.undistort()可供直接调用。为了效果更加明显,本文在平台上放置了一个矩形物体进行拍摄,得到图像后在此基础上添加网格,并对此图像进行去畸变处理,效果如图5所示。

图5 图像去畸变效果
1.2.2 倾斜矫正
在图5中可以明显观察到,由于相机拍摄时角度和旋转的问题,原本矩形的物体,在图像上出现了失真,呈现的并非为一个矩形。需要通过透视变换对其进行矫正,将图片由三维数据降维。以倾斜矫正过的“国”字图像为例,结果如图6所示。

图6 “国”字倾斜矫正效果
2 字形骨架提取算法
常见的汉字骨架提取方法都是建立在一张静止的书法图像上,通过相关算法对其细化实现骨架的提取。而本文是建立在一段书法创作的动态视频,通过提取视频中书法墨迹增量信息来实现对书法字的骨架提取。提取的汉字图像骨架信息满足以下条件:
(1)骨架是单像素点;
(2)骨架贯穿于书法字笔画的中间;
(3)骨架基本保持了原本汉字图像的拓扑结构;
(4)骨架在汉字笔画分叉处、边界处没有伪支。
2.1 墨迹增量提取
计算机视觉领域,检测物体运动的方法主要有3种:帧间差分法、光流法和背景减法。相机拍摄的视频是有时间序列的,如果相机视野内没有物体在运动,则相邻帧的图像几乎不发生改变,但如果存在运动物体,则相邻两帧之间会产生显著变化。帧差法就是利用视频的这一特性,对时间上连续的两到三帧图像进行差分运算,将不同帧的同一像素点位的灰度值相减,判断灰度差。当超过一定阈值时,即可确定物体处于运动状态,从而实现运动目标的检测功能。帧差法的流程如图7所示。

图7 帧差法流程图
下面给出算法描述:
(1)采集视频序列中第n-1帧、第n帧图像,将两者像素点的灰度值作差,取其绝对值,得到差分后的图像;
(2)设定阈值T,逐个对像素点进行二值化,确定运动目标和背景点;
(3)对图像进行形态学滤波、连通性分析等操作来衰减噪声信息。
将帧间差分法的思想运用到毛笔字书写视频上。从书写平面底部拍摄视频,通过强透光和纸面及摄像视角固定,使非书写区域变化的影响降低到可以忽略的程度,从而使得运动目标只剩下笔墨。通过去噪、二值化等数字图像处理技术,得到黑白二色的毛笔字书写墨迹变化视频。基于视频对任意两帧的图像做一个交运算,就能得到这两帧间隔内的墨迹变化量。
固定两帧之间的帧数,每间隔固定的帧数抽取出一帧图像保存,从而得到一系列包含时间序列的墨迹图。然后通过相邻的图像不断进行交运算,得到单位时间内墨迹增量图。取各个单位时间内墨迹增量的中点即为骨架点,连点成线得到骨架。动态骨架提取算法流程如图8所示。
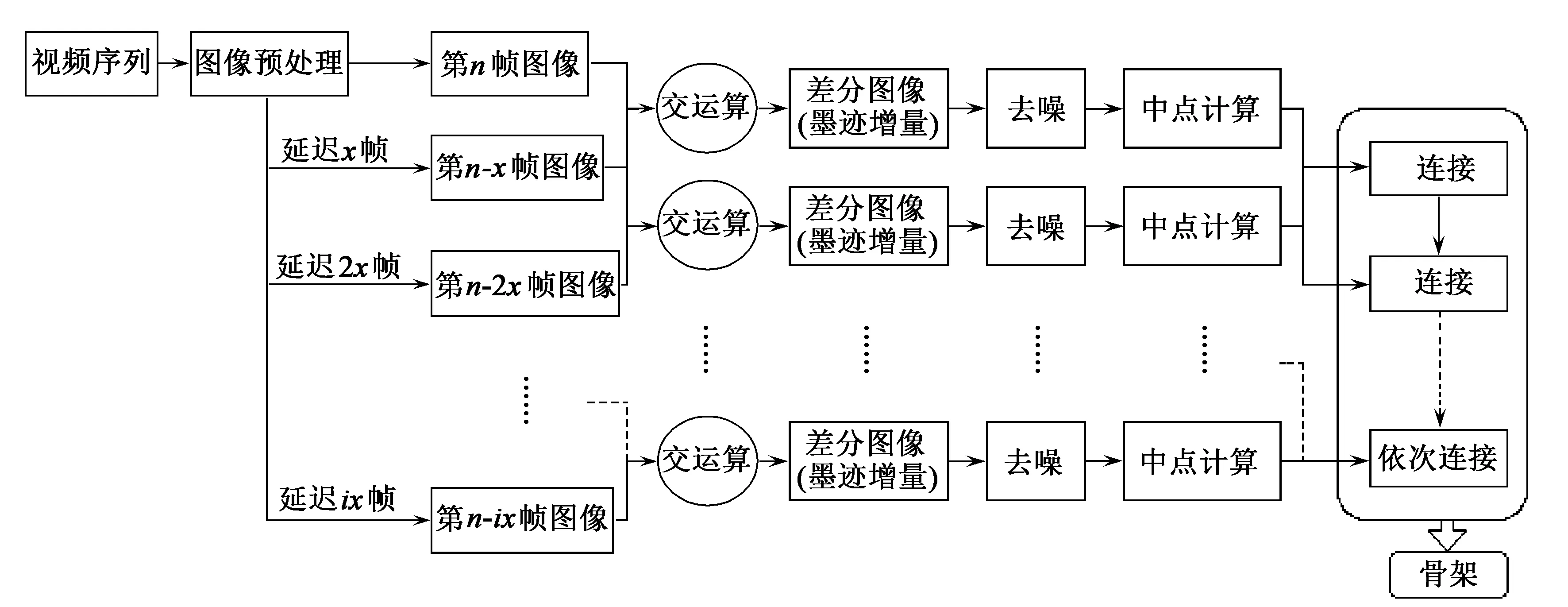
图8 动态骨架提取算法流程
墨迹状态是一组基于视频的书法字书写过程的帧序列图像。以提取“国”字骨架为例,首先要获取一组完整的“国”字墨迹笔画书写序列图像,由于图像数量太多,在此列出其中的15张图像,展示了“国”字第二笔“横折”的墨迹状态的动态变化,如图9所示。



图9 “国”字横折笔画墨迹状态变化
通过观察发现“国”字墨迹序列图像中相邻两帧之间有着微小的变化,将该组序列中相邻的两帧墨迹图像进行相减运算,获取到的结果即是墨迹增量信息。图10中图像46—60表示“国”字第二笔画墨迹增量渐进的变化过程。

图10 “横折”笔画墨迹增量
墨迹增量图像序列的提取步骤如下:
(1) 遍历“国”字墨迹序列中的每一帧图像并建立一新的缓存空间,用以存储后续的墨迹增量图像;
(2) 相邻两帧图像之间进行相减计算,用后一帧图像减去前一帧图像获取两张图像之间的差异,计算公式为:dsti(x,y)=fi+1(x,y)-fi(x,y)(i=1,2,…,n),其中dsti(x,y)是墨迹增量图像序列,fi+1(x,y)表示当前帧的图像序列,fi(x,y)表示当前帧的下一帧图像序列;
(3) 对“国”字的墨迹增量图像序列进行平滑处理,结果记为dsti′(x,y);
(4) 将dsti′(x,y)复制到第一步建立好的缓存空间中去,完成对“国”字墨迹增量图像序列的提取。
观察现阶段提取出的墨迹增量,发现在笔画边缘会有一些抖动被误识别为墨迹增量,用一次开运算将其取出。
2.2 中点计算与骨架连接
获取毛笔运笔书写视频中墨迹增量的变化后,提取墨迹增量图像的中心并计算中心坐标。墨迹增量是不规则、不均匀的形状。为了最终提取到的骨架线能够贯穿书法笔画的中心,墨迹增量中心点的提取至关重要。
中点这一概念看似简单,但也有不同的取法,如外接圆中心、外接矩形中心、凸壳中心、像素点重心等。选取不同的中心作为骨架点,得到的骨架也不同。
观察提取的墨迹增量,图像大多呈现不规则的月牙形,若选取外接圆或外接矩形可能会出现中点不在墨迹增量上的情况,同时,若墨迹增量外有噪点,则会导致图像的凸包检测不准。综上,本文决定采用像素点重心。
像素点重心的计算方式很简单,遍历所有像素点,将目标物的像素点标记,然后将其行列号分别依次求和后取平均值即可得到像素点重心。目标P内任意像素点Pi的坐标为(xi,yi),重心坐标的数学表达式为
提取墨迹增量像素点重心,将这些数据全部转换成对应的像素点值一一映射到已建立好的模板图像上,具体的实现步骤如下:
(1)以“国”字为例,提取墨迹增量像素点重心数据,墨迹增量像素点重心的横坐标记为xc,纵坐标记为yc;
(2)横纵坐标的最小值和最大值记为(xcmin,ycmin)、(xcmax,ycmax);
(3)根据(xcmin,ycmin)、(xcmax,ycmax)大小,建立一张宽度、高度适当的模板图像;
(4)分别以坐标(xc,yc)的形式映射到模板图像中。根据提取的墨迹增量序列图像的个数,批量提取其像素点,计算像素点重心坐标。
“国”字“横折”笔画骨架提取效果如图11所示。对“国”字墨迹增量计算中点并将其依次相连,设定阈值,将不同笔画的骨架点断开,得到骨架,为了更加清晰的呈现出骨架提取结果,进行图像叠加,如图12所示。

图11 “横折”笔画骨架提取效果

图12 “国”字动态骨架 提取效果
2.3 实验效果与分析
本文总共进行了两部分实验,分别为多个字体的书法骨架提取和书法字的各算法细化结果比较实验。现分别描述如下。
实验1 多个字体的书法骨架提取。
上述以“国”字为例展示了整个骨架动态提取算法的各阶段效果,仅以一个字为例展示效果,偶然性较大,但要对数量庞大的所有汉字做骨架提取,考虑到书写视频的算法原理对工作量的限制,因此参考了计算机字库,一款商业级别的中文字体包含7000字左右,开始一般会以以下几个字作为起点,确定整套字体的风格特征,分别是:
(1)永:永字八法是书法中传承的概念,八法指的是“永”字的八个笔画,分别是:侧、勒、弩、趯、策、掠、啄、磔,包含了汉字中可能出现的大部分笔画,通过这一个字就能反应整个书体的特征和气质。
(2)国、今:方形的“国”和菱形的“今”在中文字体设计中,作为字面范围的两个极端,也能在一定程度上反应书体的特性。
(3)我:笔画较多且细长,将字符的空间切割成若干不等份,可以推敲字体的内部空间划分。
(4)然:包含了各式各样的点。
(5)风:包含了汉字中较难处理的笔画。
(6)意、酬:分别代表横竖笔画特别多的情况。
(7)鹰:极为复杂,包含了汉字中上下、左右、包围各种嵌套结构。
重新用平台进行视频采集,再用动态提取算法进行骨架提取,结果如图13、14、15所示。

图13 楷书骨架提取结果图

图14 行书骨架提取结果图

图15 隶书骨架提取结果图
实验2 书法字体的各算法细化结果比较。
以“国”字为例进行实验,该字纵横及交叉笔划具有一定的代表性。将本文方法与Z-S算法[4]和最大圆盘算法进行对比,并将提取的骨架叠加到原始字符图像上,结果如图16所示。

(a) Z-S算法 (b) 最大圆盘算法 (c) 本文算法图16 “国”字的几种骨架提取算法结果比较
可以看出本文算法去除了毛刺、分叉等缺陷,取得了更好的效果,优于Z-S算法和最大圆盘算法。为了更好地评价本文算法,以骨架节点数和冗余边数为衡量细化算法优劣的指标,很多细化算法都会产生非单像素宽的线和毛刺,多种细化算法得到的骨架节点数、冗余边数和提取骨架时间可以用来表征算法性能。仍以实验中的国字为例,所得结果见表1。

表1 算法对比指标评价表
由表1可知:本文算法的骨架节点数、冗余变数和提取时间均低于传统算法,说明基于墨迹增量的动态骨架提取方法能够有效解决传统骨架提取算法对书法字边缘噪声的鲁棒性极差、骨架畸变等问题。提取出的骨架不仅能够保证单个笔画连通性,而且保证了书法字的间架结构,同时在不同笔画的连接区域也不会出现骨架的粘连,后续还可以用于笔画分离。
3 结语
本文通过搭建一个效果良好的毛笔字书写视频采集平台,采用下方拍摄的方式能较为准确地获取墨迹信息视频,以避免毛笔与墨迹分离问题。然后提出了一种新型的基于墨迹增量的书法字骨架动态提取方法,利用帧差法的思想,提取视频图像的墨迹增量,然后计算图像中心坐标,最后连接中心点坐标即可完成书法字骨架的提取。通过与传统的骨架提取算法对比,以骨架节点数、冗余边数和提取时间为评价指标,结果表明本文方法的骨架节点数、冗余边数和提取时间均低于传统方法,且具有不会出现分叉、断裂的优势,形变情况也很少,提取的骨架更能接近“书法骨架”的概念。
