电子信息系统中多维度数据协同过滤方法
2022-08-17阮大治徐东黄海艇
阮大治,徐东,黄海艇
(工业互联网创新中心(上海)有限公司,上海 200232)
数据过滤是指将信息参量传递给固定用户,并后续处理的完整执行流程。相较于一般的数据库系统,配置信息过滤行为的操作系统同时具备结构化与半结构化的处理能力,可在准确接收文本信息的同时,直接执行数据存储的职能,从而大大节省信息参量传输耗时。从宏观角度分析,数据过滤是将混合信息中滤除无效信息,作为数据文件纠正的末尾处理环节,可在检查信息一致性的同时,实现整理缺失值与无效值参量[1-2]。一般来说,过滤后的信息参量可直接进入数据仓库,以供信息系统主机的直接调取与利用。
在电子信息系统中,随数据传输时间的延长,一部分信息参量出现乱序排布的情况,从而使区域环境中数据维度条件呈现极度混乱的表现形式。传统云共享型数据过滤方法可借助基本矩阵分解模型,确定不同维度信息参量,在电子信息系统中所属的阶层等级,再通过XML 框架,实现集中处理与分离无效值参量。然而,该方法在单位时间内处理的电子信息数据量有限,并不能完全满足系统主机信息参量的定向提取需求。为解决此问题,提出一种新的电子信息系统中多维度数据协同过滤方法,通过构建Hadoop 分布框架的方式,定义关键的多维度数据集合,按照过滤偏好设置过滤标准,筛查处理隐向量,并以此为基础,计算并得到准确的协同梯度值结果,实现多维度数据协同过滤。
1 多维度数据分析
为实现电子信息系统中多维度数据分析,需要在Hadoop 分布框架的支持下,建立多维度数据集合,并且通过提取特征信息参量的方式,得到最终处理结果。
1.1 Hadoop分布框架
在电子信息系统中,Hadoop 平台拥有极强的分布式处理能力,可同时开启多个数据信息副本,并借助MapReduece 节点占据系统环境中空余的数据参量节点,从而完全独立处理多维度数据信息,元数据直接存储于系统数据库。在边缘Service 节点的作用下,Public、Private、Hybrid 三类次级节点可分别连接Hadoop 平台主机元件,并可按照电子信息参量的实际传输需求,存储多维度数据于不同的应用结构体系[3-4]。完整的Hadoop 平台由Saas、Paas、Lass 三类结构共同组成。其中,Saas 结构负责电信号的处理与传输需求,Paas 结构可分布判别多维度电子信息,Lass 结构则可借助电子信息开发软件,实现调取与利用数据参量多维度传输条件。
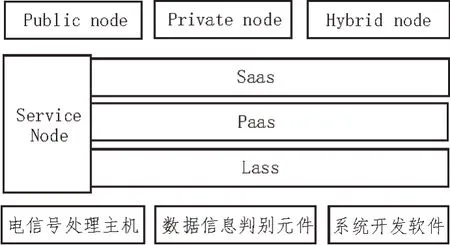
图1 Hadoop分布框架结构图
1.2 多维度数据集合
多维度数据集合是一个独立存在的电子信息参量表达定义体系,可在已知Hadoop 分布框架布局形式的基础上,确定与待过滤信息匹配的协同处理作用强度,从而使电子信息参量具备更强的聚合性价值,便于系统主机后续的过滤与处理信息参量。一个多维度数据集合至少具备一个完整的协同处置强度指标值,且随着数据传输量的增加,电子信息系统所具备的过滤处理能力也在逐渐增强,直至所有信息参量都能被匹配至少一个协同处理系数值[5-6]。设u0代表电子信息系统中多维度数据参量的基本过滤系数,Rmin代表最小的电子信息特征值,Rmax代表最大的电子信息特征值,Ri代表第i个电子信息特征值,联立上述物理量,可将多维度数据集合表示为:
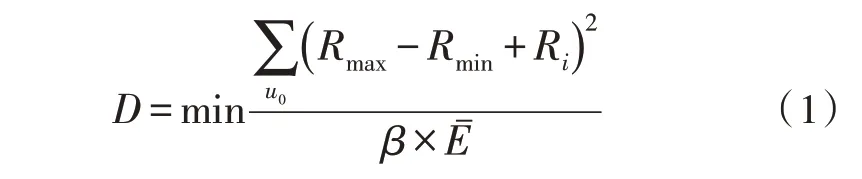
其中,β代表电信号传输特征值,代表多维度电子数据的单位传输均值量。
1.3 特征信息参量提取
为实现协同过滤多维度数据参量,需要在电子信息系统环境中,利用已知的系数值条件,提取特征信息参量集,并从中选取具有实用性价值的参量文件,以供数据库主机的直接调取与应用。特征信息参量是指一类具有极强传输能力的电信号数据指标,可在多维度数据集合中确定电子信息参量的实际传输位置,并通过整合关联数据文件的方式,实现筛查与整合多维度电子信息数据[7-8]。设P1、P2代表两个不同的电子信息数据文件编码条件,λ代表多维度电子信息数据的提取权重值,联立公式(1),可将特征信息参量提取结果表示为:
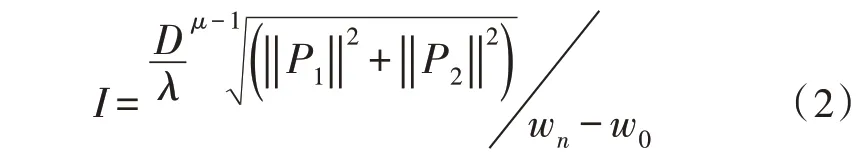
式中,μ代表电子信息的维度系数值,w0代表电子信息参量的起始传输位置,wn代表电子信息参量的终止传输位置,n代表单位时间内的电子信息传输与调取次数。
2 多维度数据协同过滤方法
2.1 过滤偏好数据
过滤偏好是指电子信息系统在执行多维度数据协同过滤时,遵循的信息参量处置标准。一般来说,随电子信息累积量的增大,系统处理遵循的过滤偏好标准也会变化,但这种物理变化作用表现形式细微,并不能直接描述多维度数据集合的存在形式,但由于二者之间存在限制影响作用,可认为数据集合中与信息参量匹配的维度数值量越大,电子信息系统所具备的过滤处理能力就越强[9-10]。在不考虑其他干扰条件的情况下,电子信息系统中过滤偏好设置结果只受数据集维度参量值、信息过滤处理强度两项物理指标的直接影响。数据集维度参量值可表示为q′,一般情况下,该项物理量的数值水平越高,电子信息系统所具备的数据过滤处理能力也就越强。信息过滤处理强度可表示为χ,在电子信息系统中,该项物理指标能够反映多维度数据参量所具备的协同传输能力,但由于信息数据传输量具有不确定性,该项物理指标的实际数值水平不易过大。在上述物理量的支持下,联立公式(2),可将电子信息系统的过滤偏好设置标准定义为:
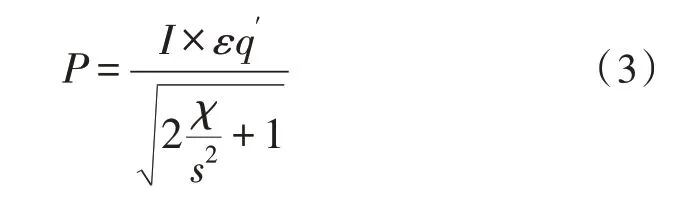
其中,ε代表电子信息系统中数据参量供应系数项,s代表电子信息数据的协同传输量均值。
2.2 隐向量筛查
隐向量是指电子信息系统中,因维度属性过于复杂而被忽略的数据参量,由于过滤偏好设置情况的不同,待筛查的隐向量数值水平存在差异性。在电子信息系统环境中,大多数隐向量筛查行为都可满足定值检索条件,特别是在已知过滤偏好设置结果的情况下,可认为待筛查的隐向量数值水平越高,多维度数据集合中的已存储数据信息量也就越大[11-12]。在多维度指标保持为定值参量时,协同过滤指令的作用范围越广泛,隐向量筛查行为的处理程度越深。因此,为获得理想的多维度数据协同过滤结果,需要限定隐向量筛查行为的作用价值,并且通过计算电子信息传输量数值的方法,确定隐向量指标的实际数值水平[13-14]。设γ代表电子信息数据的隐藏系数,f代表多维度数据的协同过滤量,l˙代表电子信息数据的过滤特征值,联立公式(3),可将电子信息系统的隐向量筛查结果表示为:
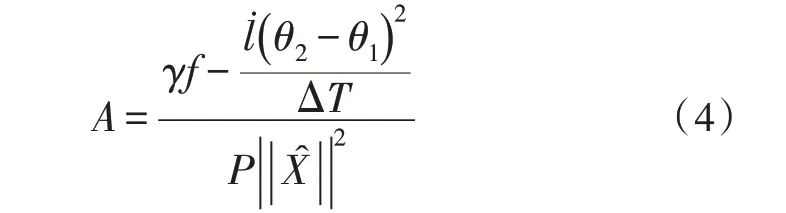
式中,θ1、θ2代表两个不同的电子信息数据维度编码条件,ΔT代表单位过滤时长,代表既定的数据信息协同传输量。
2.3 协同梯度值计算
协同梯度是指多维度数据在电子信息系统中能到达的最大传输深度值,对于数据信息过滤行为而言,协同梯度值越大,电子信息系统具备的数据参量承载能力越强。在不考虑其他干扰条件情况下,协同梯度值计算结果受到电子信息系统承载能力、数据流传输覆盖面积两项物理指标的直接影响[15-16]。数据流传输覆盖面积由下限参量v0、上限参量vn两部分共同组成,上述两项参数指标间设置的物理距离越长,多维度数据在电子信息系统中能到达的传输距离越远。设ξ代表与电子信息系统匹配的数据承载系数值,联立公式(4),可将协同梯度值计算结果表示为:
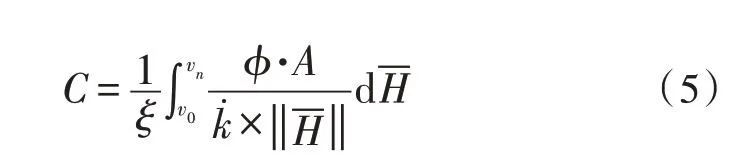
其中,φ代表既定的隐向量数据排查系数,代表多维度数据参量的协同传输系数值,代表电子信息参量的平均过滤数值。
至此,完成各项物理系数值的计算与处理,在不考虑其他外界干扰条件的情况下,实现多维度数据协同过滤方法的应用。
3 实验分析
为验证电子信息系统中多维度数据协同过滤方法的实际应用能力,设计对比实验。在电信号输出主机中同时输入多维度数据协同过滤方法、云共享型过滤方法两种执行流程,其中前者作为实验组、后者作为对照组。控制跳频器装置,使信号量显示器中物理示数值快速趋于稳定,当其示数量不再发生变化时,将所获数据平均分成两份,其中一部分作为实验组电子信息数据参量,另一部分作为对照组电子信息数据参量。

图2 电子信息系统中的数据信息收发
QBI 指标在单位时间内数值变化量水平能够描述电子信息数据的实际传输能力,一般情况下,QBI指标数值越大,电子信息数据的传输能力也就越强,反之则越弱。实验时间共计60 min,每15 min 为一个实验组别,每组实验数据分别在三个时间点采集数据,时间间隔为5 min,即每组数据获得三个数据值。通过表1 记录了实验组、对照组QBI 指标数值的具体变化情况。
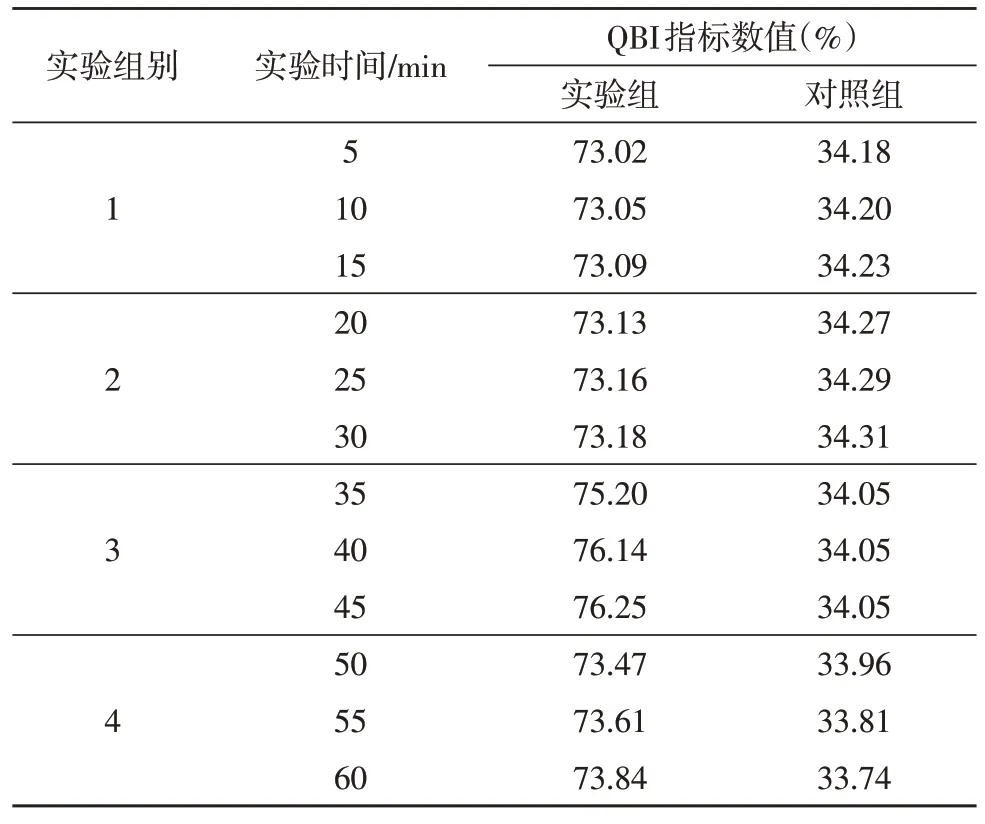
表1 QBI指标对比
分析表1 可知,实验组QBI 指标在前两个单位时长内,一直保持小幅上升的数值变化趋势,而从第三个单位时长开始,这种数值上升状态开始不断扩大,且一直延续至实验结束;对照组QBI 指标在前两个单位时长内,也一直保持小幅上升的数值变化趋势,而从第三个单位时长开始,这种数值上升趋势得到有效抑制,开始呈现连续稳定的数值变化状态,从第四个单位时长开始,则开始连续下降的变化形式。在整个实验过程中,实验组最大值73.84%与对照组最大值34.31%相比,上升了39.53%。
BBS 系数反映电子信息系统对于数据参量的按需提取能力,BBS 系数值越大,电子信息系统所具备的数据参量按需提取能力越强,由于不同时间段的BBS 系数变化趋势不同,为了便于详细分析,将实验数据分为两个时间段,呈现更多更详细的数据。实验数值对比情况如图3 所示:
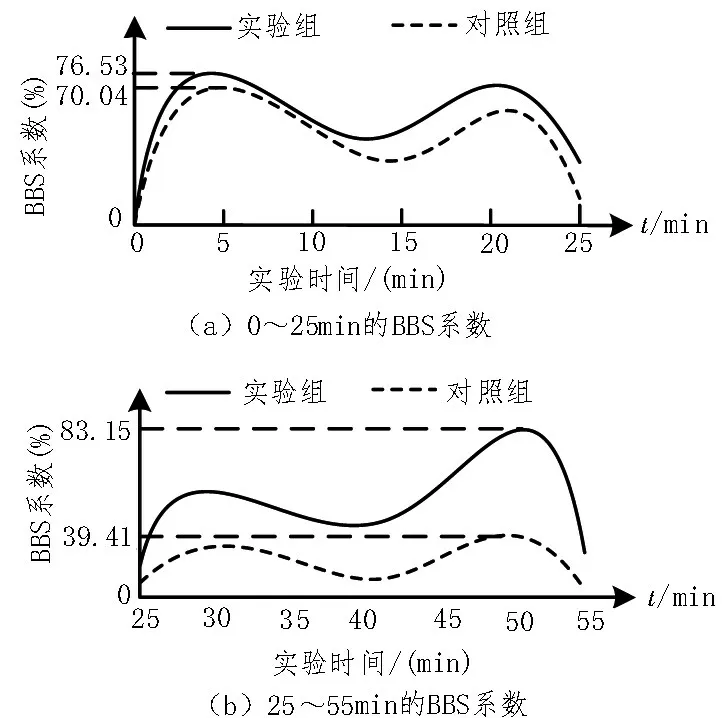
图3 BBS系数对比图
分析图3 可知,实验组BBS 系数在前25 min 的实验时间内,保持先上升、再下降、然后重复的变化趋势;在30~55 min 的实验时间内,BBS 系数则保持先上升、再下降的趋势。整个实验过程中最大数值达到了83.15%。对照组BBS 系数在整个实验过程中始终与实验组保持相同的变化趋势,但其均值水平却远低于实验组,其最大数值只能达到70.04%,与实验组最大值相比,下降了13.11%。
4 结束语
与云共享型过滤方法相比,多维度数据协同过滤方法解决了数据维度混乱问题,这是因为该方法应用了Hadoop 分布框架,定向提取特征信息参量,并且通过设置过滤偏好的方式,得到最终的协同梯度值计算结果,最终有效过滤相关电子信息参量。从实用性角度分析,QBI 指标数值与BBS 指标数值的增大,可在维持数据参量按需提取能力的同时,增强系统主机在单位时间内的数据上传能力,具备较强的实际应用可行性。
