基于动态环境建模与智能感知的实训方法研究
2022-08-17闫琳
闫琳
(西安航空职业技术学院,陕西西安 710089)
随着人工智能、虚拟现实(VR)等技术的发展,高职教育也迎来了信息化、智能化转型的机遇。使用计算机技术对教学场景进行动态建模,再基于各种感知技术对场景进行信息采集,便可实现智能化的人机交互。最终,基于智能设备完成对于学生的职业技能培训,实现“人工智能+职业教育”的结合[1-5]。
在上述背景下,文中以空乘专业的职业培训为切入点,针对职业技能教育场景下的动态建模、智能感知方法进行了研究。在动态建模方面,引入了基于视频图像的环境建模方法。并结合实际的教学环境,对光照进行了自然均衡,提升设备对于环境信息的采集能力[6-8];在智能感知方面,文中使用胶囊结构代替传统的神经元结构,提升算法在复杂场景下的感知能力[9-12]。
1 理论基础
随着智能设备的普及,对于复杂动态环境的场景建模与人体行为感知,将在各个行业发挥越来越重要的作用。在进行动态环境建模时,需要根据文中的应用场景,解决动态环境光照复杂多变、人体动作识别困难两个问题。
1.1 光照补偿结构图的光照自然均衡算法
由于在动态环境采集时,光照难以规律地变化,从而导致采集设备无法准确获取环境信息。为了解决该问题,文中引入了一种光照自然均衡算法。其基本流程如图1 所示。
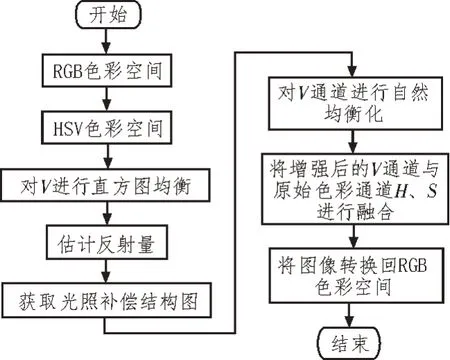
图1 算法流程
在进行直方图均衡时,传统的方法能够改进图像的亮度与对比度,但由于过度追求亮度的均匀分布,经常会造成图像炫光。为此,文中对均衡方法进行了改进[13-16]。对于通道V的(x,y)点,记其亮度为v(x,y)。首先,对直方图进行归一化,在此引入归一化函数:
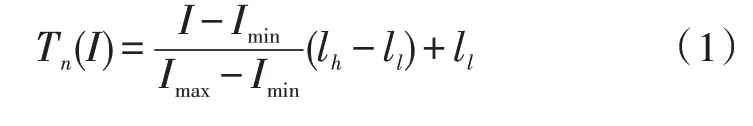
将直方图转化到对数坐标系:
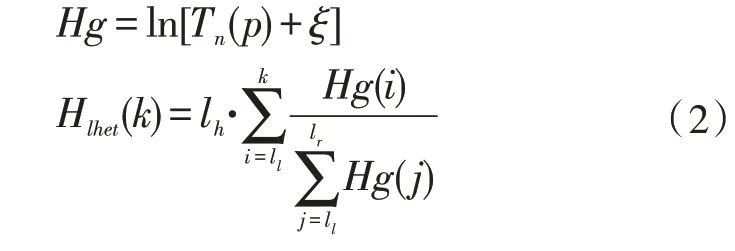
其中,Hlhet为文中的均衡变换关系。定义光照补偿结构图ics(x,y):
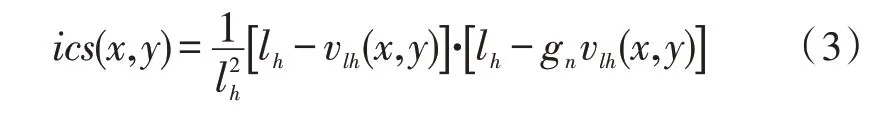
其中,gn是当前环境下的光感知单元模型:
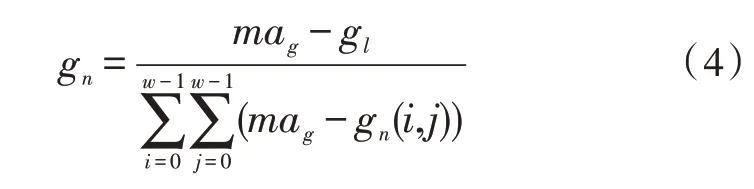
在进行光补偿时,需考虑宏观的图像因素。当图像整体较亮,但亮度差异较大时,需要对亮度小的部分提供更大的光补偿权重。为使该方法能够感知亮度分布的集中度,文中定义了图像的全局补偿感知指数:

接着,根据物体的光照反射基本原理,能够获得直方图均衡图像vlh的反射分量vlh(x,y)。随后对vlh(x,y)进行对数变换,然后进行归一化,可以计算得到反射量的估计gv(x,y):
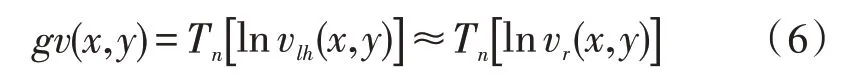
最后,利用反射量的估计值得到vlh补偿后的结果:
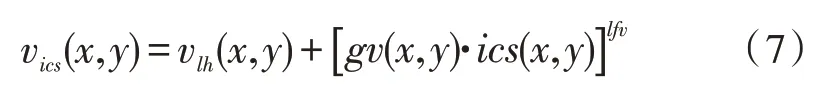
1.2 胶囊网络
为了对动态环境感知后的人体进行智能识别,还需引入人体行为识别算法。由于动态环境下,人体的行为不断变化,因此相较于静态图像的行为识别,动态环境下则需要对行为进行分解再整合。文中引入了融合注意力机制的胶囊网络,在该网络中使用胶囊作为信息处理的基本单元,其基本结构如图2所示。
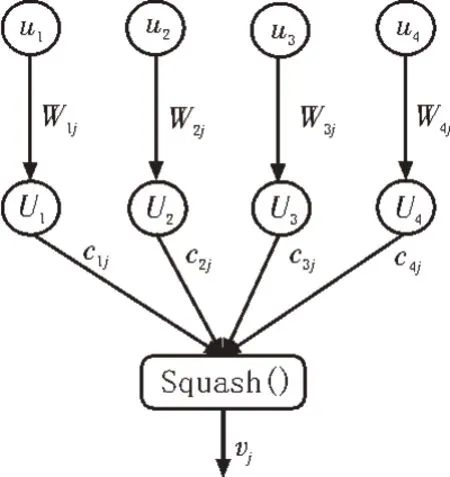
图2 胶囊基本结构
相较于神经网络中的神经元,胶囊的激活条件是多个人体姿势之间的比较差值。在图2 中,ui是图像低层次特征,Ui是低层次对应的高层次特征,Wij为对应的传输权重,预测向量加权后,得到加权和sj=∑icij·Uj|i。其中,Uj|i=Wij·ui,加权和经Squash 函数压缩后,得到胶囊的输出vj:
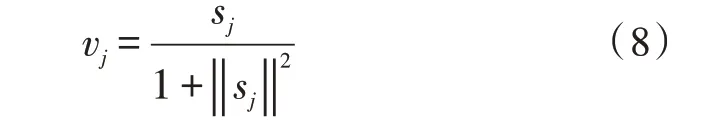
在胶囊网络中,对于层数L的胶囊c,需要获取其姿势矩阵Mc和激活值ac:
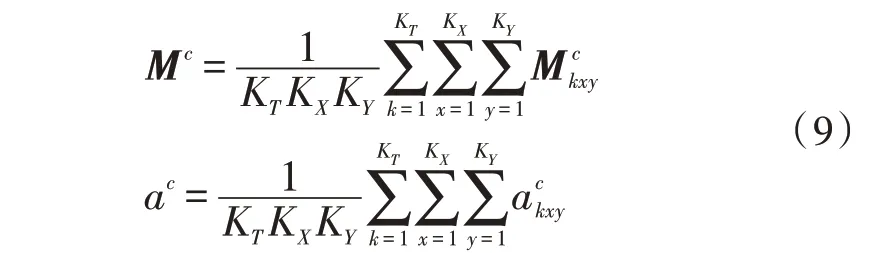
由于在L、L+1 层间,每个感受野(k,i,j)内均会产生CL×CL+1个投票,因此在决策时,需要使用最大期望(EM)路由算法。首先,对分配概率Rij进行初始化分配随后,在路由迭代的过程中,对高斯模型与高层胶囊的激活值进行更新:
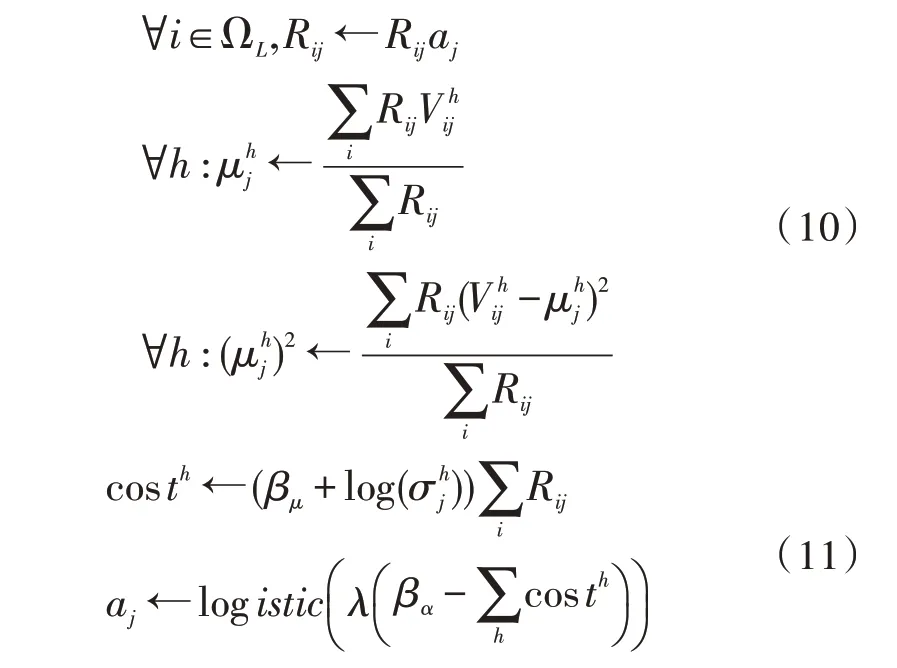
最终,能够获得模型的参数pj的更新方法:

相较于传统的神经网络的神经元,依靠胶囊组建的非线性网络更注重学习动作组合本身的内在机制,而不是单纯的进行数据集的模仿。为了保证胶囊对于视频动作的捕捉能力,文中还引入了“挤压-激励”机制:
“挤压”后,所有类型的动作均在维度方面有所收缩,实现了信息聚集,能够捕获胶囊在类型层上的依赖性:
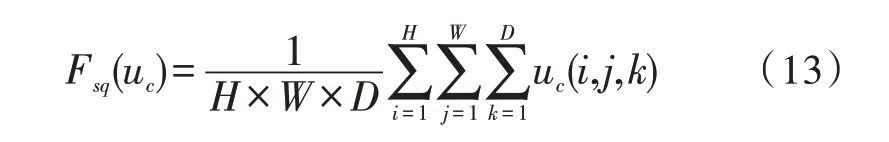
随后输入激励,整合上下文信息有:
最终,引入尺度变换将“激励”后的结果与原始的特征层进行修正:

其中,uc∈RH×W×D。
2 方法实现
2.1 实验设计
在算法验证阶段,该文使用公开数据集J-HMDB与UCF-Sports 进行模型的训练和测试,验证算法在智能感知时的有效性。视频环境的动态感知需要消耗大量的运算资源,为了保证顺利完成算法的训练和测试,文中在进行实验时,使用了目前最强的消费级GPU。该显卡基于NVIDIA 的安培架构,使用8 nm工艺,运行速率能够达到19.5 Gbps。仿真环境的其他硬件参数,如表3 所示。
表3 仿真环境的硬件参数
2.2 仿真结果
在测试算法前,需要先利用数据集进行模型的训练。在进行场景的智能感知时,会由于类别、定位的判别错误产生类别损失与定位损失。因此文中在设计损失函数时,引入Sigmoid 函数的交叉熵来计算损失。首先,对于空间位置(k,i,j),能够得到后验概率:根据后验概率,能够得到损失函数:
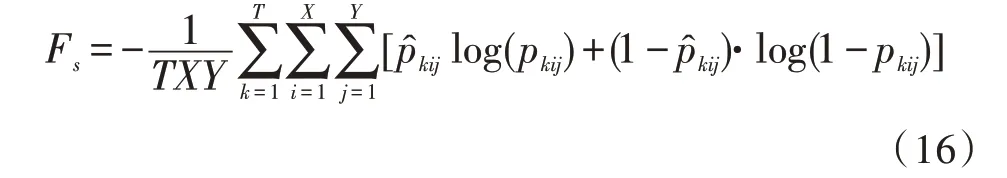
在确定损失后,J-HMDB、UCF-Sports 每个数据集中60%的数据分别作为训练数据进行模型的训练,获得两个不同的模型;随后,将剩余40%的数据作为测试数据分别输入到对应的模型中。在测试时,文中将f-Map 和v-Map 的IoU 阈值分别设置为0.5 与0.2。最终的测试结果,如表4 所示。

表4 该文算法的仿真结果
为了评估文中算法结果的公正性,该文采用同样的仿真环境,使用经典的卷积神经网络算法LeNet进行了对比测试。其测试的结果,如表5 所示。

表5 LeNet的仿真结果
从表4 能够看出,该文算法在J-HMDB 数据集上f-Map、v-Map 两个指标均大于UCF-Sports 数据集上的指标。因此,文中在J-HMDB 数据集上的感知效果优于UCF-Sports。从表5能够看出,LeNet在J-HMDB上的感知效果同样优于UCF-Sports。分析两个数据集的结构,在J-HMDB 的数据集内部的视频中,所要感知的目标大多集中在视频中央,而UCF-Sports 较分散。由于在损失函数中,会引入定位误差,因此较分散的动态环境不利用智能感知算法进行处理。
对比表4 与表5 的仿真结果能够看出,该文引入的智能感知算法在进行动态环境的感知时,f-Map、v-Map 两个指标均优于LeNet。以J-HMDB 数据集为例,文中算法在f-Map、v-Map 上分别提升5.56%与4.98%。LeNet 是视频识别、智能感知领域的经典算法,因此可以证明文中的算法达到了能够广泛使用的性能要求。但结合UCF-Sports 数据集的仿真结果,文中算法在该数据集上的提升小于J-HMDB。这说明该文算法在处理分散动态环境的能力上仍有一定的优化空间。
此外,为了评估“挤压-激励”机制引入的降维比的参数对算法性能的影响,文中对不同降维比下的算法性能进行了评估,结果如表6 所示。可以看出,当降维比增加时,参数增加量会降低,f-Map与v-Map会提升。当降维比取16 时,模型参数与参数增加量取得了较好的平衡。
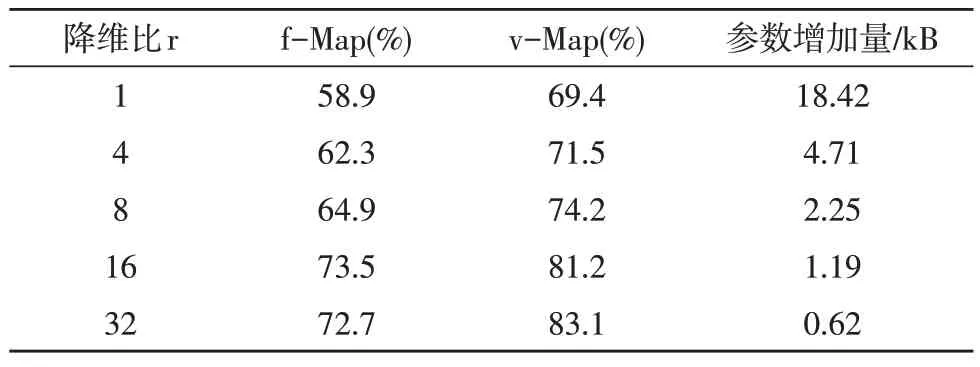
表6 不同降维比下的仿真结果
3 结束语
文中对于高等院校职业技能训练智能化过程所需要的动态建模与智能感知方法进行了研究。在动态建模方面,引入了光照补偿结构图的光照自然均衡算法,提升视频设备对于环境信息的采集能力;在智能感知方面,使用胶囊组建了非线性网络,实现了复杂环境下的目标定位与动作识别。文中方法能够达到业界的性能要求,并有所提升,可以进行推广应用。
