改进Faster R-CNN 网络的航拍小目标检测研究
2022-08-17刘晋川黎向锋刘安旭左敦稳赵康
刘晋川,黎向锋,刘安旭,左敦稳,赵康
(南京航空航天大学机电学院,江苏南京 210016)
随着航空航天技术的飞速发展,无人机技术及其航拍图像在军事和民用等领域应用也越来越广,如搜索救援、地形勘探、交通疏导以及智能停车等[1-4]。由于无人机拍摄高度高、视野广,导致航拍图像中的目标存在尺度变化大、尺寸较小以及背景复杂等问题。而传统的特征提取方法如SIFT 和HOG 算法需要人工设计特征[5-6],只能在特定的场景下才能取得较好的效果,适应性和泛化能力差,不适合航拍图像的检测。
近年来,基于深度学习的目标检测算法取得了重大进展,其准确性和实时性不断提升。基于深度学习的目标检测算法大致分为两类:一类是以Faster RCNN[7]以及Cascade R-CNN[8]等算法为基础的两阶段检测算法,另一类是以YOLO[9]、RetinaNet[10]等算法为代表的一阶段检测算法。两阶段算法首先选择候选区域,然后将候选区域进行位置回归和类别分类,这种方法检测精度较高,但检测速度较慢。而一阶段算法则去掉了候选区域的选择步骤,直接对图像进行分类和回归,检测速度较快,但检测精度略低。基于深度学习的目标检测方法在检测精度和检测速度上相较传统方法有了很大提升,但无论是一阶段还是两阶段检测算法,在面对小目标较多且各类目标间尺度变化较大的图像时,仍然存在召回率低、误检率高的问题。为此,国内外学者进行了大量研究:Zhang等人为恢复小目标尺寸,在网络中添加了反卷积层,改善了航拍图像中小目标的检测精度,但该方法过于聚焦小目标,对不同尺寸的目标检测鲁棒性较差[11];Kisantal 等人提出一种对图像中的小目标进行复制和重复采样的方法,通过丰富小目标的训练样本来提高检测精度,然而这种数据增强的方法对于没有实例分割的数据集较为繁琐[12];刘英杰等人提出基于级联区域建议网络的航拍目标检测算法,通过设置多阈值级联机构优化对小目标的检测,提高了航拍图像中小目标的检测精度,但该类网络的高计算成本限制了检测的速度[13]。
与一阶段算法相比,Faster R-CNN 算法使用了RPN 网络,解决了训练过程中类别不均衡的问题。故该文基于Faster R-CNN 网络,改进特征提取网络并与特征金字塔网络[14](Feature Pyramid Networks,FPN)结合,同时改进锚框设置,提出了适合航拍图像检测的多尺度目标检测网络MS-R-CNN(Multi-Scale R-CNN)。
1 数据集及评价指标
1.1 数据集介绍
DIOR 数据集[15]是西北工业大学于2019 年提出的,该数据集包含23 463 张图片,图片尺寸均为800×800 像素,共有192 472 个对象实例,覆盖20 个类别目标。该数据集中有车辆、船舶等小目标,也有高尔夫球场、公路收费站等尺寸较大的目标,具有较大的尺寸变化,并且具有较高的类内多样性和类间相似性。
1.2 评价指标
文中采用查准率(Precision)、召回率(Recall)、平均精度(Average Precision,AP)和平均精度均值(Mean Average Precision,mAP)作为模型性能的评价指标。AP 值为以查准率为横坐标、召回率为纵坐标绘制的曲线所围的面积。查准率与召回率定义如式(1)和式(2)所示:
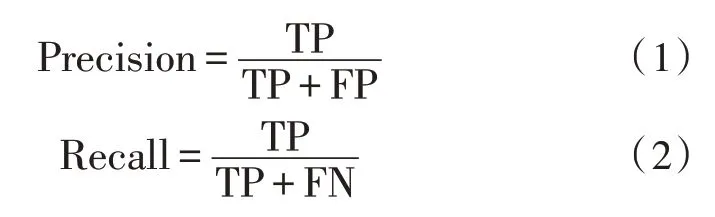
式中,TP(True Positive)表示分类器认为是正样本且确实是正样本的例子,FP(False Positive)表示分类器认为是正样本但实际上不是正样本的例子,FN(False Negative)表示分类器认为是负样本但实际上不是负样本的例子。
目标检测任务中最重要的一个指标是平均精度均值,在多分类任务中,将所有类别的AP 求均值就可以得到mAP。
2 Faster R-CNN算法改进研究
Faster R-CNN 自提出到现在,一直采用最经典的两阶段检测算法,其网络框架如图1 所示。该算法共分为四个阶段:1)VGG 网络提取待检测图片特征;2)特征图进入RPN 网络后输出候选框矩阵及其得分;3)ROI Pooling 层将RPN 的输出和特征图进行处理,融合后生成大小一致的特征图;4)全连接层将3)中得到的特征图进行类别分类和位置回归,得到检测框的位置信息及得分。
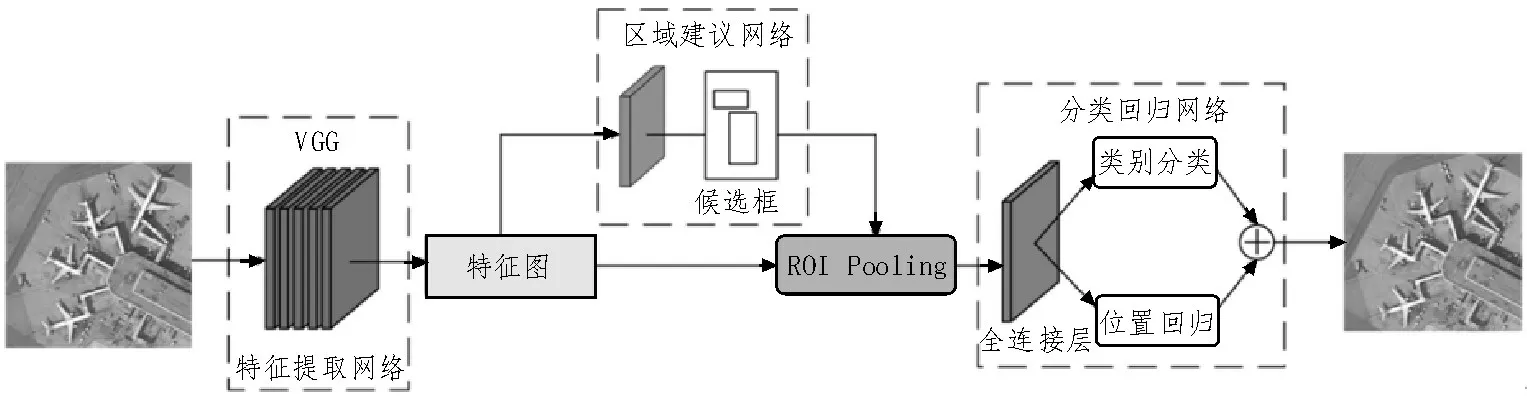
图1 Faster R-CNN网络框架
2.1 引入Res2Net的特征提取网络
对Faster R-CNN 算法的特征提取网络进行替换和改进,将其中的VGG 特征提取网络替换为Res2Net[16]网络。相比VGG 网络,Res2Net 可以提 取到更深层的语义信息,有效地改善了网络梯度消失和梯度爆炸的问题,整体提高了远距离小目标这种对分辨率要求较高的信息的特征提取和表达能力。
Res2Net 网络是通过改进ResNet[17]网络中的残差块得到的。残差块结构如图2(a)所示,输入特征矩阵以两个分支进入残差块,直线分支经过多个卷积层产生输出特征矩阵后与shortcut 分支传过来的特征矩阵相加,之后再使用激活函数,由这种若干个残差块堆叠构建而成的网络叫做残差网络。深度较大的特征提取网络能提取到更加丰富的特征,而残差网络保证了在网络深度加深的同时不会产生梯度消失和梯度爆炸的问题。
通常的特征提取网络如ResNet 等都使用分层的方式表示多尺度特征,在每层网络上运用多尺度,而Res2Net 在一个残差块中构建了分层的、多通道的残差连接,以更细粒度级别来表示多尺度特征。如图2(b)是Res2Net中的残差块示意图,该残差块先获得1×1卷积后的特征图,对其通道数顺序均分为s块,图中s=4,每一小块Xi都会进行一个3×3 的卷积,用Ki表示,卷积结果用Yi表示,Xi与Ki-1的输出相加并送入Ki,这样就可以得到s个输出。最后将s个结果进行拼接融合,然后进行1×1 的卷积,这种先拆分后融合的思路可以得到多尺度的特征,更好地进行特征融合。
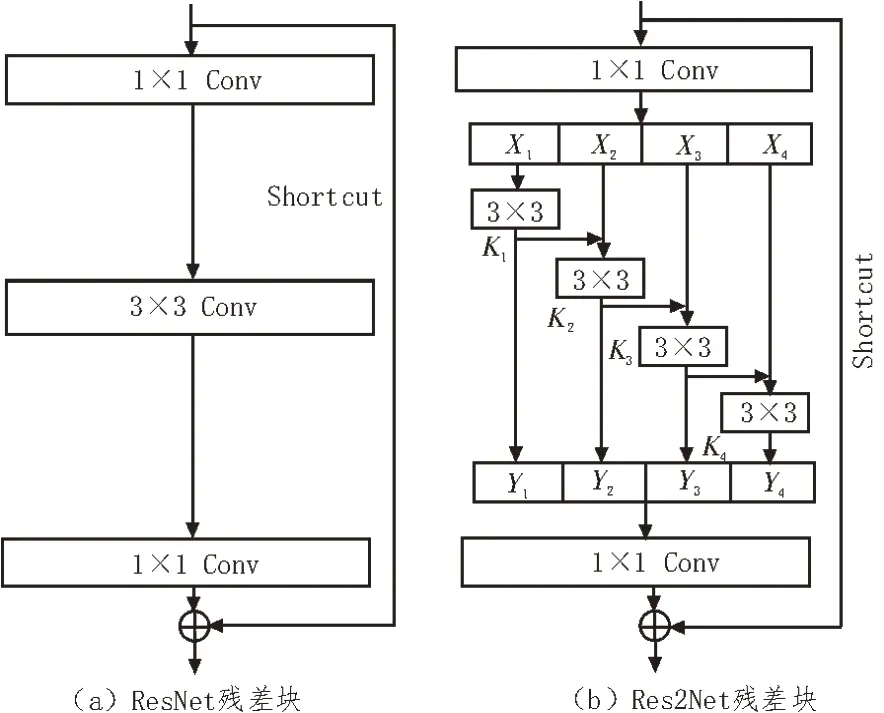
图2 ResNet和Res2Net残差块对比
图3 是Res2Net 的网络结构图。图中Res2Net bottleneck 代表一个图2(b)所示的Res2Net 残差块,选取Conv2_x、Conv3_x、Conv4_x、Conv5_x卷积后提取的特征图作为多尺度特征图,送入后续的检测网络。
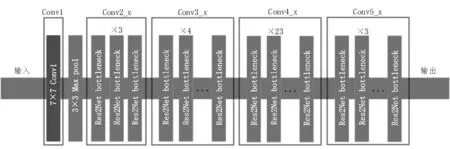
图3 Res2Net网络示意图
2.2 Res2Net网络中部分标准卷积的替换
航拍图像由于拍摄高度以及拍摄视角不同,同一物体在图像中出现时的角度、大小等差异较大,而标准卷积限于固定的几何结构,并不能很好地对其进行模拟,故提出在Res2Net 网络中使用变形卷积[18](Deformable Convolution Networks,DCN)替换图3 中Conv3_x、Conv4_x 和Conv5_x 中的标准卷积,以提高网络对目标变换的建模能力。
变形卷积在标准卷积的常规采样位置添加了偏移量,使采样的网格变形,如图4 所示。标准卷积的计算方式如下:
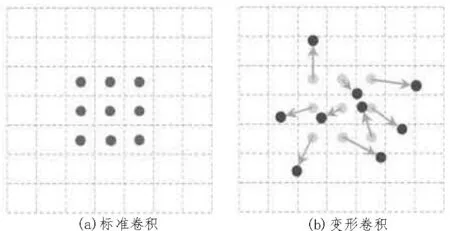
图4 标准卷积和变形卷积采样图示
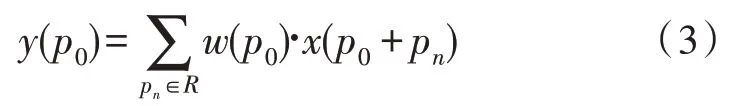
其中,pn是对采样网格(卷积核)R中所有位置的枚举,p0为输出特征图上对应pn的位置。变形卷积在标准卷积的基础上增加了一个偏移量,同样位置的p0变为:
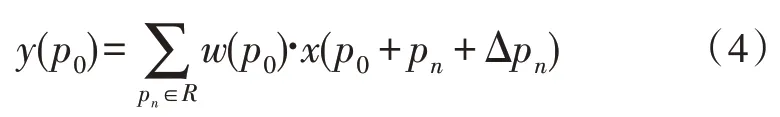
即在每个采样网格上添加了一个偏移量Δpn。图5 为3×3 变形卷积的流程,首先通过一个额外的卷积层学习偏移量,然后将得到的偏移量作用到常规卷积之中,得到不规则位置的采样。
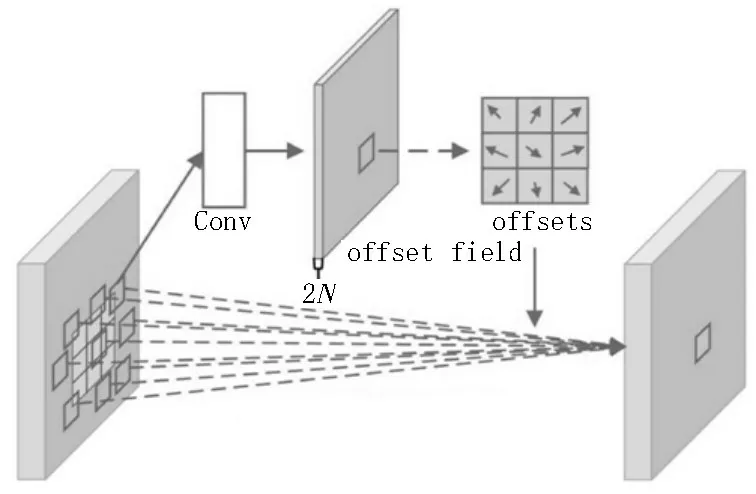
图5 3×3变形卷积
2.3 融合FPN的特征提取网络
图6为DIOR 数据集中某航拍图像在网络Conv3_4 和Conv5_3 阶段的特征热力图,图中颜色不同表示特征图提取到的信息重要程度不同,颜色偏向框线区域表示网络对其更加关注,偏向非框线则相反。从图中可以看出,浅层(Conv3_4)特征图更加注重飞机等小目标信息,由此可知,浅层信息更加适合小目标的检测,而深层特征图由于具有更大的感受野,所以对大目标的检测更加敏感。如果直接采用深层特征进行检测,容易忽略图像中的小目标。为了增强对小目标的检测性能,MS-R-CNN 引入了特征金字塔网络FPN,FPN 通过自顶向下的路径和横向连接,将高分辨率、语义弱的特征和低分辨率、语义强的特征结合起来,可以对小目标进行更有效的检测。

图6 Res2Net网络不同层次的热力特征图
如图7(a)所示,特征金字塔网络FPN 从深层到浅层融合特征。首先深层特征图通过步长为2 的卷积操作使特征图尺寸扩大一倍,同时将特征提取网络中对应大小的特征图使用1×1 的卷积层进行降维,然后将两者对应元素相加得到融合后的特征图,最后进入后续网络进行预测。融入FPN 的MS-RCNN 算法结构如图8 所示,图中c2-c5 为Res2Net 网络生成的特征图,p2-p7 为FPN 网络产生的特征图。
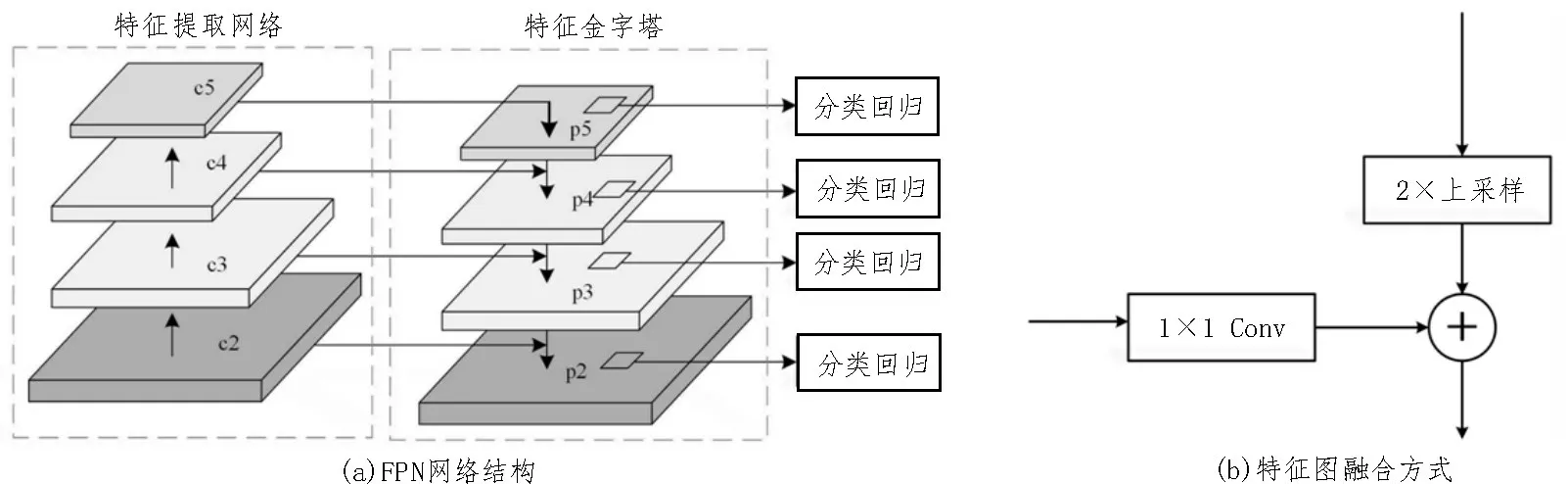
图7 融合FPN的主干网络
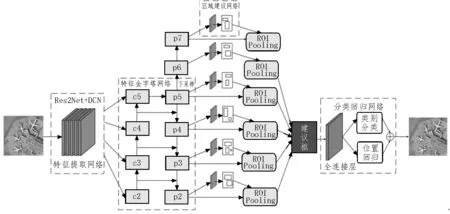
图8 改进后网络结构图
2.4 针对小目标的锚框改进
Faster R-CNN 定义了锚框(anchor)检测物体,anchor 本质就是在特征图的每个像素点上设置一组具有不同大小和比例的矩形框模板,随后用这组矩形框检测框内是否包含物体。结合DIOR 数据集的特性来设置anchor 的数量及尺寸。
Faster R-CNN 网络中的锚框是基于VOC 数据集设置的,共有3 种尺寸大小,分别为128×128 像素,256×256 像素和512×512 像素,每种尺寸都对应3 种不同的宽高比(1∶1、1∶2 和2∶1),故特征图中的每一个点都会生成9 个锚框。但DIOR 数据集中超过一半的目标是像素小于32×32 的小目标,所以对于该数据集,其锚框设计不太合理。
为了设计符合数据集的锚框大小及比例,对该数据集中的目标实例进行统计分析。图9 展示了数据集中192 472 个对象实例的尺寸分布,从图中可以看出,数据集中目标大小尺寸分布极不均匀,且多数目标为中小目标,虽然部分目标长宽比跨度较大,但绝大多数集中在0.5~2.0 之间。故在MS-R-CNN 算法中,设置anchor的尺寸分别为16×16像素,32×32像素,64×64 像素,128×128 像素,256×256 像素和512×512 像素,宽高比分别为1∶1、1∶2 和2∶1,这样的设置基本能覆盖各个尺寸的目标。由于每个尺寸的特征图只能对应一种尺度的锚框,故在原FPN 的基础上,通过对p6 特征图进行最大池化操作生成p7,如图8 所示,p2-p7 分别对应上述6 种锚框尺寸。
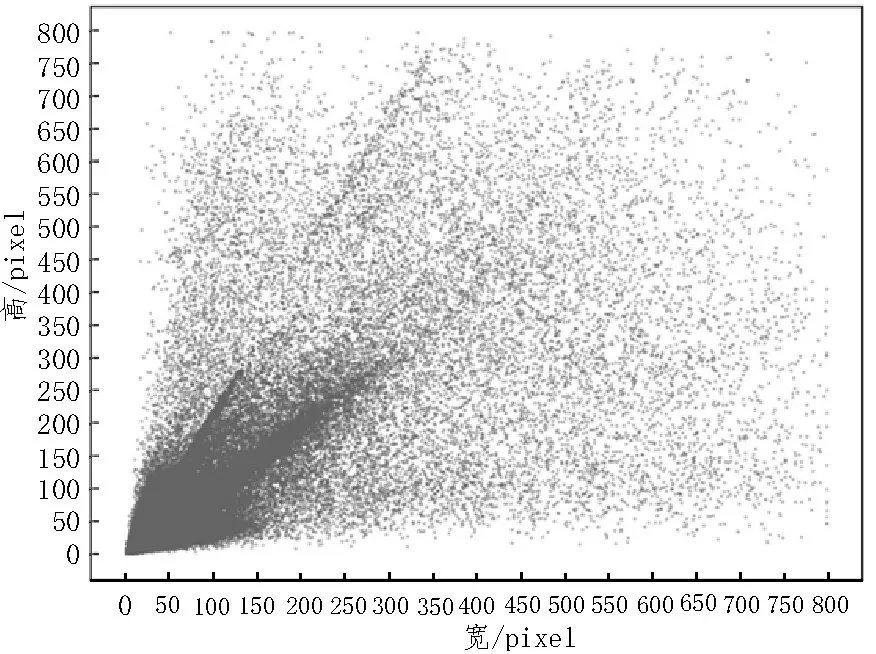
图9 尺寸分布
3 实验与分析
3.1 模型训练
采用SGD(Stochastic Gradient Descent)算法对模型进行求解,共学习12 轮,在第8 轮和第11 轮调整学习率,降为原来的0.1,目的是为了保证模型可以稳定收敛,避免发生梯度爆炸。其他参数设置如表1所示。

表1 参数设置
3.2 实验结果分析
采用mAP 作为评价指标,为验证设计模型的先进性和有效性,将标准Faster R-CNN网络(VGG-16)、经典Faster R-CNN(ResNet-101+FPN)网络以及该文算法MS-R-CNN 进行了对比实验。消融对比结果如表2 所示。表中anchor 表示改进anchor 设置并在FPN 网络上添加p7 层特征图。
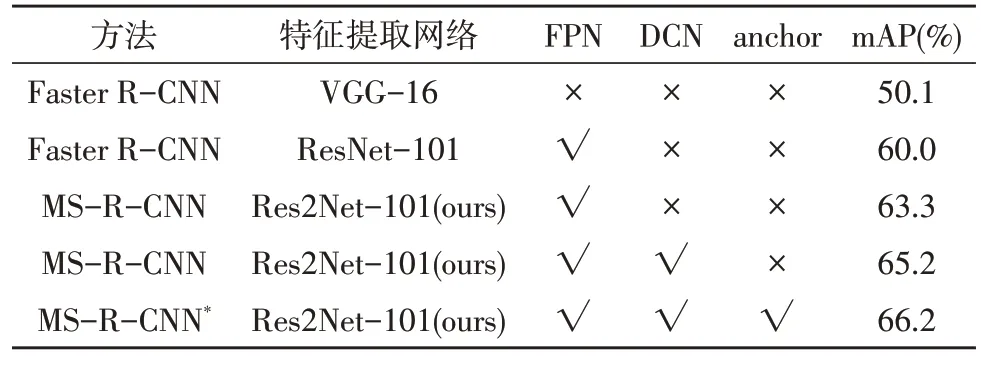
表2 各类算法在DIOR数据集上的mAP对比
通过实验对比可以看出,MS-R-CNN 网络对提高检测效果非常有效,较标准Faster R-CNN 网络准确率提高了16.1%,较经典的Faster R-CNN 算法提高了6.2%。其中Res2Net-101 特征提取网络、DCN方法以及对anchor 的改进分别贡献了3.3%、1.9%和1.0%的检测精度。
图10 所示为经典Faster R-CNN 算法与MS-RCNN 算法检测效果的局部放大图。从对比图可知,经典Faster R-CNN 算法会对图像中小目标船只造成漏检以及误检的情况,而该文的MS-R-CNN 算法可以对图像中的船只进行正确的检测和识别。

图10 不同算法检测结果示例
4 结论
为了提高航拍图像的检测精度,文中基于Faster R-CNN 网络提出一种多尺度航拍目标检测算法MS-R-CNN。MS-R-CNN 选用Res2Net 网络作为特征提取网络,同时用变形卷积替换该网络Conv3_x、Conv4_x 和Conv5_x 中的标准卷积,提高了网络对目标深层信息的提取能力以及对目标变换的建模能力,将Res2Net产生的多尺度特征图通过FPN 网络自上而下融合起来,有效改善了深层特征图中小目标位置信息不足的问题。针对数据集中目标的大小设置合适比例和尺寸的anchor,使其能有效地对各个尺度的目标进行检测。实验显示,该文提出的MSR-CNN 算法在DIOR 数据集上较Faster R-CNN 算法mAP 提高了16.1%,较经典的Faster R-CNN 算法mAP 提高了6.2%,明显降低了小目标的漏检率和误检率,取得了良好的检测效果,验证了该文方法的有效性。
