基于元数据映射关系的结构化数据血缘分析方法
2022-08-15唐雪飞樊治强
唐雪飞,樊治强
(电子科技大学 信息与软件工程学院,四川 成都 610054)
0 引 言
科学计算、数据仓库以及工作流管理等应用领域,都需要记录数据的来源信息。来源信息除了原始数据以外,还包括数据的变换过程。例如,分子生物学领域的公共数据库多达1 000 个,其中只有较少的数据库存储的是原始的实验记录,大部分数据库都是由其他数据库经过数据清洗、格式转换以及数学运算等操作派生而来。在面对这类庞大复杂的数据时,如果无法知晓数据的来源和转换过程,甚至无法判断某些数据是原始数据还是转换后的数据,那么这些数据将失去价值,因此,数据的来源信息的重要性不亚于数据本身。
数据血缘分析,又称数据溯源(Data Provenance)和数据世系(Data Lineage),借助于数据血缘分析技术,可以追踪数据的来源,评价数据的质量和可靠性,复现数据的产生与转换过程,当发现数据质量问题时,能够高效地定位至错误产生的位置从而分析出错误的原因等。数据血缘分析技术的研究,无论对于科研领域还是商业生产领域,都具有重要的意义。
结构化数据也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,一般通过关系型数据库进行存储和管理。目前对于关系型数据库中的数据血缘分析的研究,其中大多数都依赖于特定数据库和相关查询语言。本文提出一种基于标注的方法,通过构造并存储关系表和字段的元数据映射关系,记录关系表及其字段的血缘关系,从而给出针对特定表和字段的血缘分析算法描述。
1 关键概念
1.1 元数据
元数据被定义为“描述、解释、定位或以其他方式使信息资源更容易检索、使用或管理的结构化信息”。针对分散于不同物理位置和不同业务系统中的数据库业务表,可以使用元数据表metadata_table 对这些表的元数据信息进行统一记录、管理和维护;对于数据库表的列(字段),则使用另一张元数据表metadata_field 进行管理。每一张业务表在metadata_table 中都有其唯一标识tid,每一个业务表中的字段在metadata_field 中也有其唯一标识fid。
数据血缘信息也可以被认为是一种元数据,用来记录数据产品的原始数据及其演变和转换过程。关系型数据库中的血缘分析可分为基于标注和基于非标注两种方法,基于标注的方法需要更多的存储空间来记录数据血缘信息,但是其查询比较简单;基于非标注的方法不需要存储数据演变和转换过程的全部标注信息,只需要使用少量的元数据信息,但这种方法需要存在已验证的逆查询机制或逆过程推导函数时才有效。本文采用一种基于标注的方法,即通过构造、存储并分析元数据的映射关系,实现数据血缘分析。
1.2 映射关系
定义映射关系:a⁃>b。其表示表b 的数据是基于表a 的数据生成的,称a 是b 的来源表,b 是a 的目标表。
对于映射关系*:ta⁃>tb。其中表ta 有4 个字段分别为af1,af2,af3,af4;表tb 有4 个字段分别为bf1,bf2,bf3,bf4。其中bf1 来源于af1,bf2 来源于af2 和af3,bf3 和bf4 来源于af4。图1 为映射关系*的图形表示。
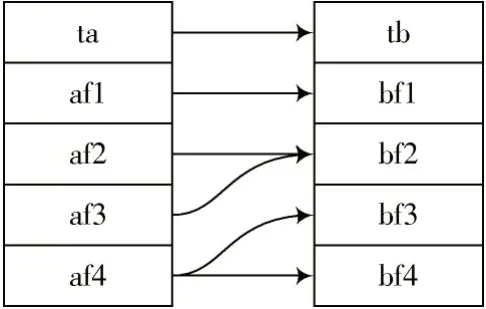
图1 映射关系M*的示例
因此,映射关系可以用有向图的形式展现,其中数据库表用深色矩形块表示,表的字段用白色矩形块表示,块之间的有向连接线(弧)表示数据流向。以上示例也说明:目标表的某个字段可能来源于来源表的多个字段,来源表的某个字段也可能传播至目标表的多个字段。
本文使用一个关系表来存储,表示表与表之间的映射关系,表名为mapping_relation,该表的主要字段如表1所示。

表1 表mapping_relation 的主要字段
在 表 mapping_relation 中,字 段 source_tid 和target_tid 的含义分别为来源表和目标表在元数据表metadata_table 中的唯一标识。创建映射关系M 的记录即在表mapping_relation 中创建一个元组,该元组通过source_tid 和target_tid 两个字段的值分别确定唯一的来源表和目标表,因此,该元组也称作一个元数据映射关系,在下文中简称为映射关系。字段field_relations 的值用以下JSON 格式存储:

field_relations 用来记录来源表和目标表的字段映射关系,对于其中任意一组由花括号包裹的“属性⁃值”对集合,属性“source_fid”的值为来源表的某个字段在元数据表metadata_field 中的唯一标识,属性“target_fid”的值为目标表的某个字段在元数据表metadata_field 中的唯一标识。
对于具体应用而言,创建映射关系可分为自动生成和手动设置两种方式。映射关系的自动生成主要基于SQL 脚本的解析来完成:在SQL 编译阶段,对SQL 脚本进行语法、词法分析,得到抽象语法树(Abstract Syntax Tree,AST);然后遍历抽象语法树的叶子节点及叶子节点中可能出现的子树,通过分析得到映射关系。由于不同的关系型数据库的SQL 语法不统一,且对于某些特定类型的SQL,如存储过程,其存在变量定义、游标操作和控制结构等不在抽象语法树的SQL 操作范围内,基于SQL 脚本解析的生成方式有可能会失败,而手动设置映射关系则允许人为地创建和修改映射关系数据,弥补自动方式的不足之处,并提供对错误映射关系的修正途径。
2 算法描述
数据质量问题按粒度大小可分为表级、字段级和元组级,血缘分析的执行粒度也应以此划分。由于映射关系是基于表和字段的,本节将阐述针对特定表和字段的血缘分析算法。
2.1 表级血缘分析
设待分析的产生数据质量问题的表为t,表级血缘分析的主要思路是:分析第1 节所述映射关系表mapping_relation 中的映射关系数据,得到最终目标表为t的所有映射关系的集合;然后以有向图的方式展示t数据的来源(上游表)和流转过程,以便数据分析人员快速定位和找到数据问题的原因。用算法1 描述表级血缘分析的具体步骤。
算法1:表级血缘分析
输入:t在元数据表metadata_catalog 中的唯一标识tid;
输出:产生t的映射关系集合resultSet。
resultSet=null,tidQueue=null;
tidQueue.add(tid);
while(tidQueue.isNotEmpty())do
{
targetTid= tidQueue.remove();
relations=getRelationsByTargetTid(targetTid);
{
resultSet.add(relations[]);
tidQueue.add(relations[].targetTid);
} //end for
} //end while
算法1 的核心是广度优先搜索(Breadth First Search,BFS)。首先初始化一个队列tidQueue,用来存放未访问过的上游表的id。 每次从tidQueue 弹出targetTid,使 用getRelationsByTargetTid 函 数 查 找 以targetTid 对应的表为目标表的映射关系集合relations。然后遍历relations,将relations 的每个元素(一个上游映射关系)放入结果集resultSet 中,再将该映射关系的targetTid 加入tidQueue 中,直到while 循环结束。
3.1.4 蓖麻PIP5K蛋白跨膜结构域的预测与分析 膜蛋白这种特殊的环境决定了跨膜区必须由强疏水的氨基酸组成,同时磷脂双层的厚度又决定了膜蛋白的跨膜区一般大约由20个强疏水性的氨基酸组成[17]。跨膜结构域的预测和分析,有利于正确认识和理解蛋白质的结构、功能、分类及在细胞中的功能部位。用CBS的TMHMM2.0对蓖麻PIP5K蛋白氨基酸序列的跨膜结构域进行预测,结果如图1-A所示。结果表明,7个PIP5Ks基因家族对应的PIP5K蛋白跨膜结构域均小于1,即均不存在跨膜结构域,所有氨基酸均位于细胞膜表面。
图2 为关于某张表tf 的表级血缘分析的结果示例,其中tf的上游表包括ta,tb,tc,td,te 五张表。

图2 表级血缘分析结果
2.2 字段级血缘分析
第1 节中建立字段间映射关系的目的是实现字段级别细粒度的数据血缘分析。数据质量检测工具可依据规则将数据质量问题定位到表的字段及元组(数据行)上。字段级血缘分析的意义在于:当能确定一张表的数据质量问题发生在哪些字段上时,找出对问题字段有影响的上游表和上游字段,以更快速、精确地定位分析问题产生的位置和原因。算法2 展示了字段级血缘分析的具体步骤。
算法2:字段级血缘分析
输入:t在元数据表metadata_catalog 中的唯一标识tid,f在元数据表metadata_field 中的唯一标识fid;
输出:对f有贡献的映射关系集合resultSet,f的上游字段在元数据表metadata_field 中的唯一标识的集合fidSet。
resultSet=null;fidSet=null;
traceField(tid,fid);
//以下为traceField 函数定义
void traceField(targetTid,targetFids){
relations=getRelationsByTargetTid(targetTid);
for=1 to relations.length do
{
fieldRelations=relations[].fieldRelations;
recursionFlag=false;
tempFids=null;
for=1 to fieldRelations.length do
{
i(ftargetFids.cotains(fieldRelations[].targetFid))then
{
recursionFlag=true;
fidSet.add(fieldRelations[].sourceFid);
tempFids.add(fieldRelations[].sourceFid);
}
} //end for
i(frecursionFlag)then
{ relationResult.add(relations[]);
traceField(relations[].sourceTid,tempFids);
} } //end for }
算法2 结合了深度优先搜索(Depth First Search,DFS)的思想,递归调用traceField 函数完成字段级血缘分析。traceField 函数的第1 个参数targetTid 的含义是待分析的目标表的唯一标识,第2 个参数targetFids 的含义是待分析的目标字段的唯一标识集合。在函数体内,首先调用getRelationsByTargetTid 函数查找以targetTid对应的表为目标表的映射关系集合relations。对于relations 的每个元素relations[],遍历其包含的字段映射关系fieldRelations,判断本次调用traceField 函数的参数targetFids 是否包含fieldRelations 中的targetFid,如果包含则代表当前遍历的映射关系relations[]中的来源表是t的 上 游 表,并 用tempFids 记 录fieldRelations 中 与targetFids 对应的所有sourceFid,和relations[].sourceTid一起作为下一次调用traceField 函数的参数。
图3 为表tf 的字段ff2 的字段级血缘分析的结果示例,其中用实线表示的表tb,td 为字段ff2 的上游表,tb 的字段bf2,bf3 以及td 的字段df2 为ff2 的上游字段;ta,tc,te 虽然是tf 的上游表,但没有对输入字段ff2 产生贡献,所以用虚线表示,表示它们并没有被纳入最终输出。即字段级血缘分析算法根据字段映射关系对表级血缘分析的结果进行了约简,只分析得到对输入字段有贡献的上游表及上游字段。

图3 字段级血缘分析结果
3 结 语
本文提出的基于元数据映射关系的结构化数据血缘分析方法,其价值在于:当发现数据质量问题时,可以通过分析关系表和字段的元数据映射关系追根溯源,快速地定位到问题数据的来源和加工过程,减少数据问题排查分析的时间和难度。本文所述的“血缘分析”一词基于现有文献的名词定义,侧重于指分析数据的来源,然而对于数据的综合治理而言,除了获取数据的来源信息以外,对于影响分析,即衡量数据在血缘关系网络中的影响力、分析上游数据对下游数据的影响也有重要的研究价值和实践意义。后续将重点研究数据血缘图中的数据影响分析方法,并完善本文数据血缘分析方法的不足之处。
