基于多关键字的Top-k布尔可搜索加密方案
2022-08-12郭斯栩周福才张鑫月
郭斯栩 何 申 粟 栗 张 星 周福才 张鑫月
1(中国移动通信有限公司研究院安全技术研究所 北京 100053)2(东北大学软件学院 沈阳 110819)
现阶段,越来越多的用户和企业选择将自己的数据存储及业务计算外包到云服务器中,并由其代为存储和计算,以节省数据存储开销和系统维护开支.为了保证云端数据的机密性,人们首先考虑到对数据进行加密.然而,加密之后的数据,也丧失了数据原有的特性.经过大量的研究之后,可搜索加密(searchable encrypion)[1-5]技术应运而生.可搜索加密是指对于诸如文件、数据表等信息,在加密之后通过使用关键词的手段对密文进行搜索.最早的可搜索加密[1]这一概念是由Goldreich和Ostrovsky提出的.传统的可搜索加密方案包含客户端与服务器2个实体以及2个阶段:数据初始化阶段和搜索阶段.在数据初始化阶段,客户端对每一个关键字生成倒排索引,同时对索引加密生成加密索引,并将加密后的文件集合与加密索引上传至服务器;在搜索阶段,当用户发起搜索请求时,客户端向服务器发送待搜索关键字的搜索令牌.该令牌利用密码学知识将关键字封装,且无法泄露任何关键信息.当服务器获得令牌后,利用数学运算等方式将加密索引解开,返回符合搜索条件的文件.现如今,可搜索加密的重要性从其广泛的应用领域中显而易见,其中许多工作正在进行中.文献[6]中提出可搜索加密正在探索物联网设备和智能电表;文献[7]中提出可搜索加密技术被应用于云环境中的电子医疗保健系统中;文献[8]中讨论:当与区块链技术结合使用时,可搜索加密也会对安全交易产生深远的影响.随着同态加密的出现,在基因组分析中也正在探索使用可搜索加密来安全地分析和搜索人类DNA序列[9].
同时,为了保证从大数据中高效安全地提取重要信息,满足用户需求,我们考虑针对一些特殊的关键字对每一个文件进行排名,top-k排名搜索[10-15](top-kranking search)技术应运而生.Fagin[10]首先提出了top-k排名搜索这一概念,目的是解决针对大数据的文件检索.由于很多场景对文件等数据的排名有特定的要求,top-k排名搜索一经提出便备受关注,在搜索引擎、电子商务、移动App等诸多领域得到了广泛的研究与应用.用户通过对关键字不同属性的权值设定来反映其自身偏好,而云服务器则根据用户提供的权值信息作为排名依据进行计算,并返回符合用户需求的前top-k个数据.top-k排名搜索能够帮助用户从大量数据中精确找到自己所关心的信息,因此研究top-k排名搜索具有非常实际和广泛的应用价值.
然而,当前的top-k排名算法大多针对明文数据,这无法确保在云服务器上保证数据的安全性,因此top-k排名与可搜索加密机制的结合也势在必行.但现存的可搜索加密方案大多不支持top-k排名搜索;在构建可搜索加密方案时,通常需要考虑隐私性、效率与查询有效性[16]这3个因素,尽管这些因素同等重要,但大多数现有方案无法在它们之间保持平衡;同样地,现阶段的可搜索加密方案大多只支持对单关键字的搜索,无法对多关键字进行高效的布尔搜索.因此,这些方案缺乏可用性,无法部署到真正的云服务器上.
针对上述所提到的问题,本文提出一种基于多关键字的top-k布尔可搜索加密方案(top-kboolean searchable encryption scheme based on multiple keywords, TBSE).其能够满足用户的日常需求,在对多关键字进行安全高效的布尔搜索的同时,对文件进行高效的top-k排序.TBSE首先利用数学中集合论的知识,对多关键字进行高效的布尔搜索;然后构建正向文件索引,利用安全协处理器对搜索后的文件进行top-k排名.另外,现存的可搜索加密方案所使用的倒排索引大多不支持动态更新,在增加或删除关键字时,倒排索引需要重新构建.这不仅仅降低了关键字更新的效率,每次重构索引也会泄露更多文件信息.TBSE利用Goldwasser-Micalli与2DNF这2种加密算法构建关键字索引,能够对索引进行动态的更新,同时利用搜索令牌的巧妙构造,大大提高了搜索效率与top-k排名效率.通过安全性分析,证明该方案满足自适应安全.
本文的优势在于,从功能性的角度考虑,相比于传统可搜索加密方案,TBSE方案能够在支持布尔搜索的同时,对搜索后的文件进行top-k排名;相比于文献[17]中的方案,该方案支持对多关键字进行布尔搜索;相比于文献[17-19]中的方案,本方案支持对索引的动态更新.从性能的角度考虑,首先考虑到对关键字的搜索效率,由于TBSE方案独特的索引构造,其搜索效率与索引长度无关,只与关键字个数成线性关系,因此相比于文献[18-19]中的方案,本方案提升了布尔搜索的效率.关于索引存储效率,文献[18]中方案的索引存储空间与关键字个数成线性关系,文献[19]中方案在此基础上做出了改进,其索引存储空间与关键字个数成亚线性关系,而本方案由于索引结构为向量形式,其索引存储空间只与向量长度有关,而与关键字个数无关.因此,本方案的索引存储效率为一个常数级,当关键字个数较多时,其索引存储效率将会大大提升.
1 相关知识
1.1 Goldwasser-Micalli公钥加密方案
Goldwasser-Micalli(GM)公钥加密方案是第1个在标准密码假设下可证明安全的概率公钥加密方案,由Gen,Enc,Dec三个算法组成.
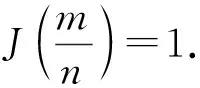

3)Dec.解密算法.对于密文ci∈C,利用私钥sk,对密文中的每一个比特ci解密,得到明文xi:
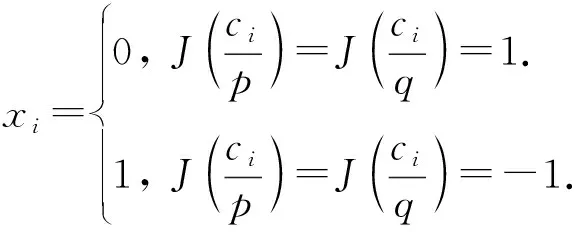
(1)
由于GM加密是使用概率算法执行的,所以给定的明文在每次加密时可能产生非常不同的密文,这具有显著的优点.
1.2 2DNF同态加密方案
2DNF加密方案[20]满足同态机制,其具有加法同态性质,这与Paillier[21]加密方案相似.具体地说,2DNF加密方案由Gen,Enc,Dec三个算法组成.
1)Gen.密钥生成算法.给定一个安全参数l.首先选择2个l-bit的奇素数q1,q2,计算N=q1×q2∈.生成N阶双线性群G,令g,u为G的2个生成元,然后计算h=uq2为G的q1阶子群的随机生成元.最后输出私钥sk=q1和公钥pk=(N,G,GT,g,h).
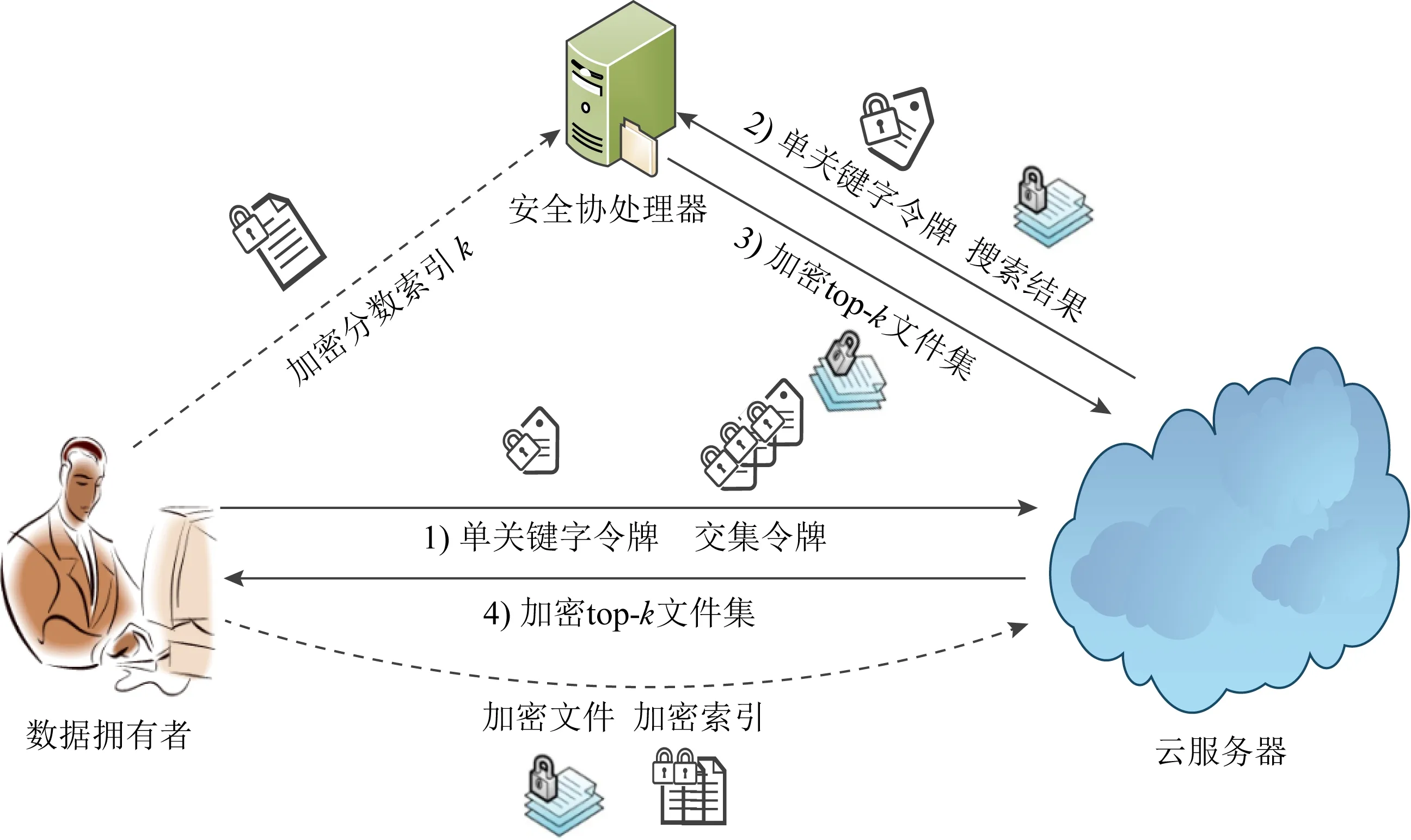
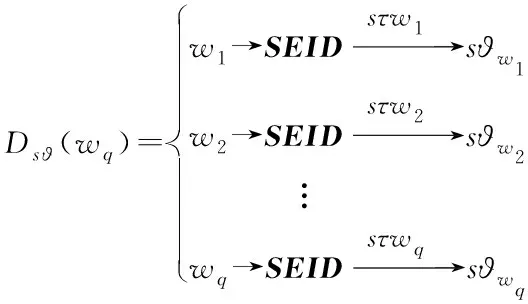
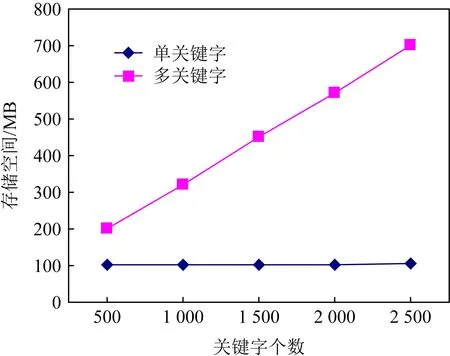
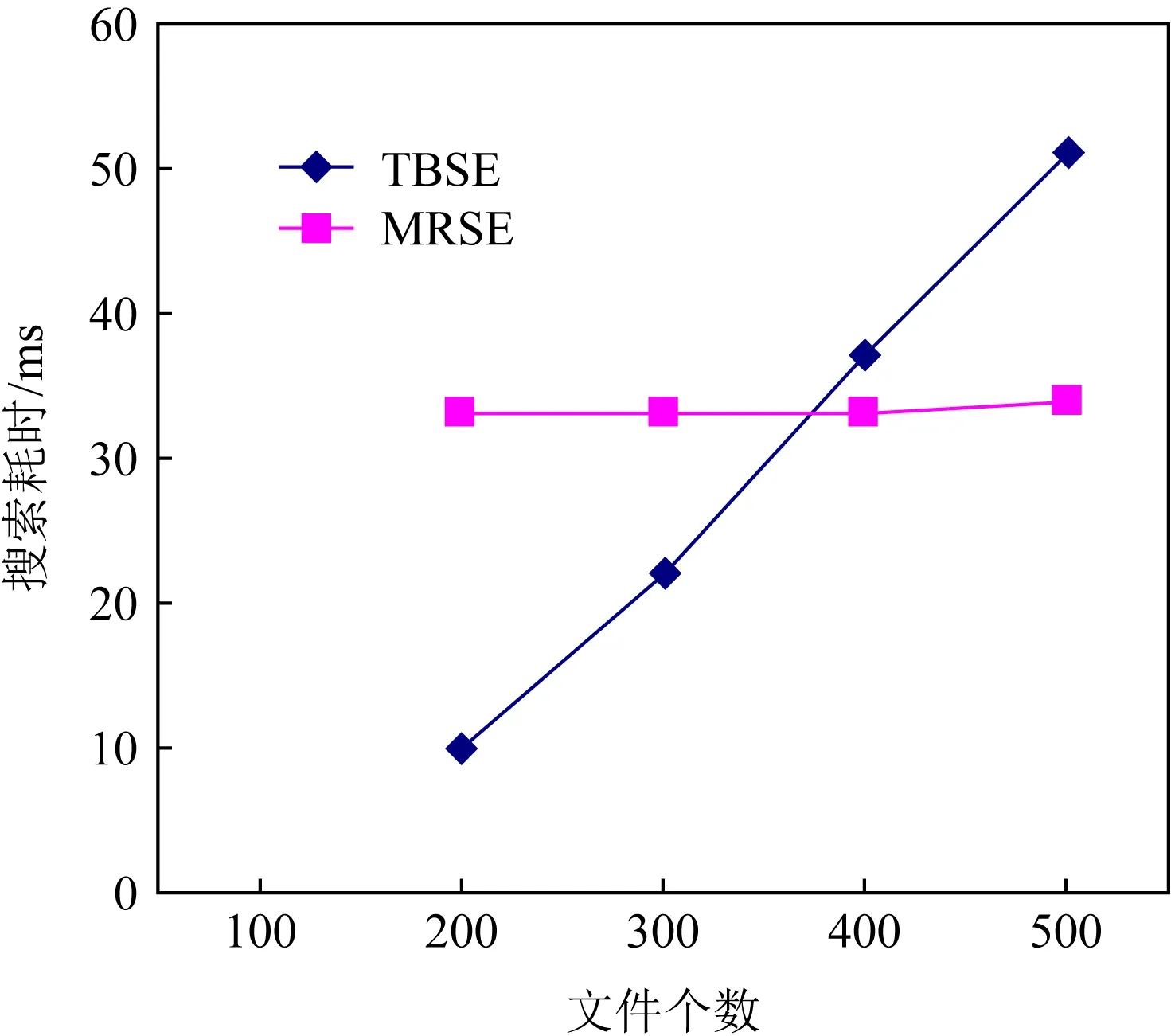
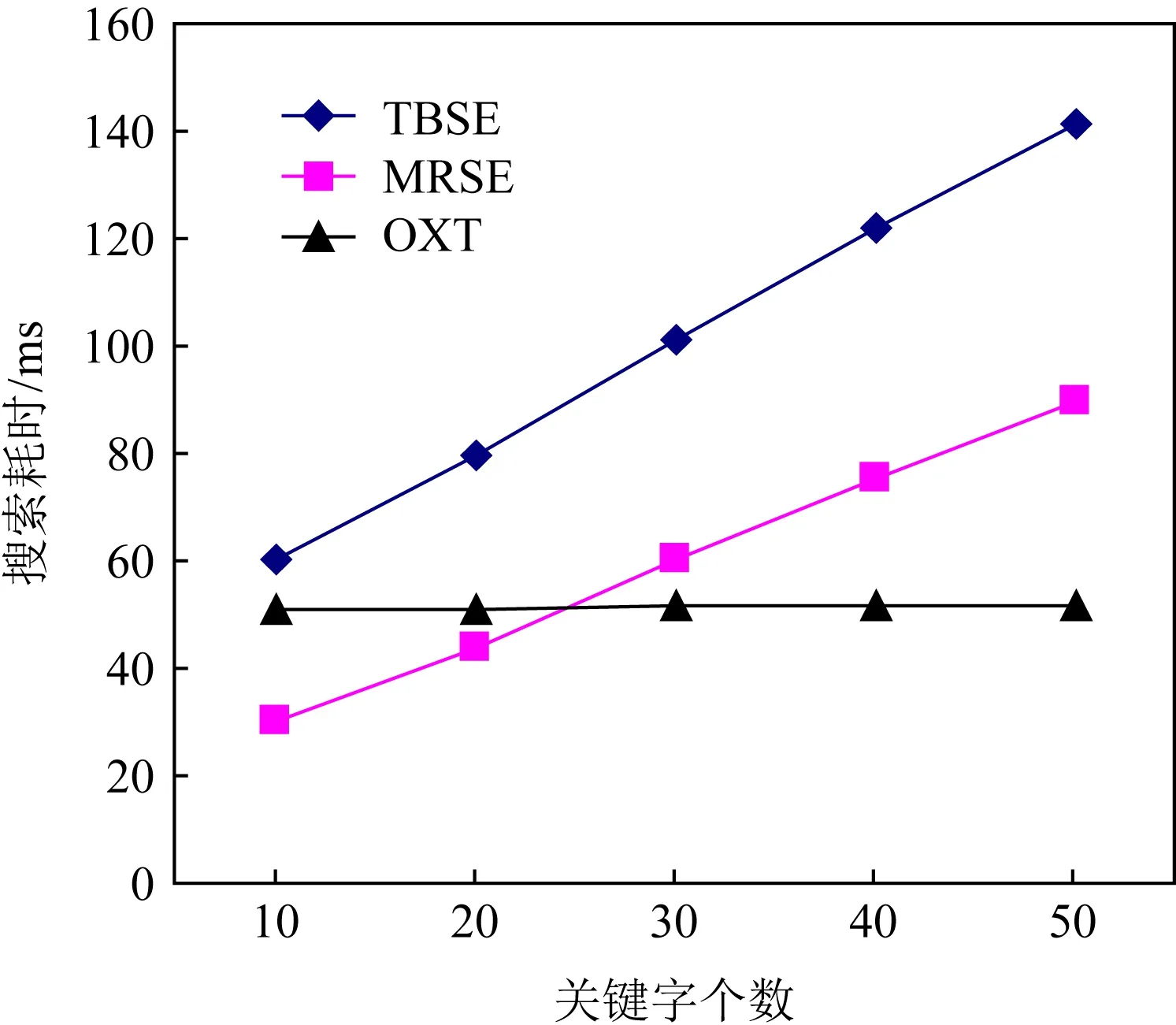
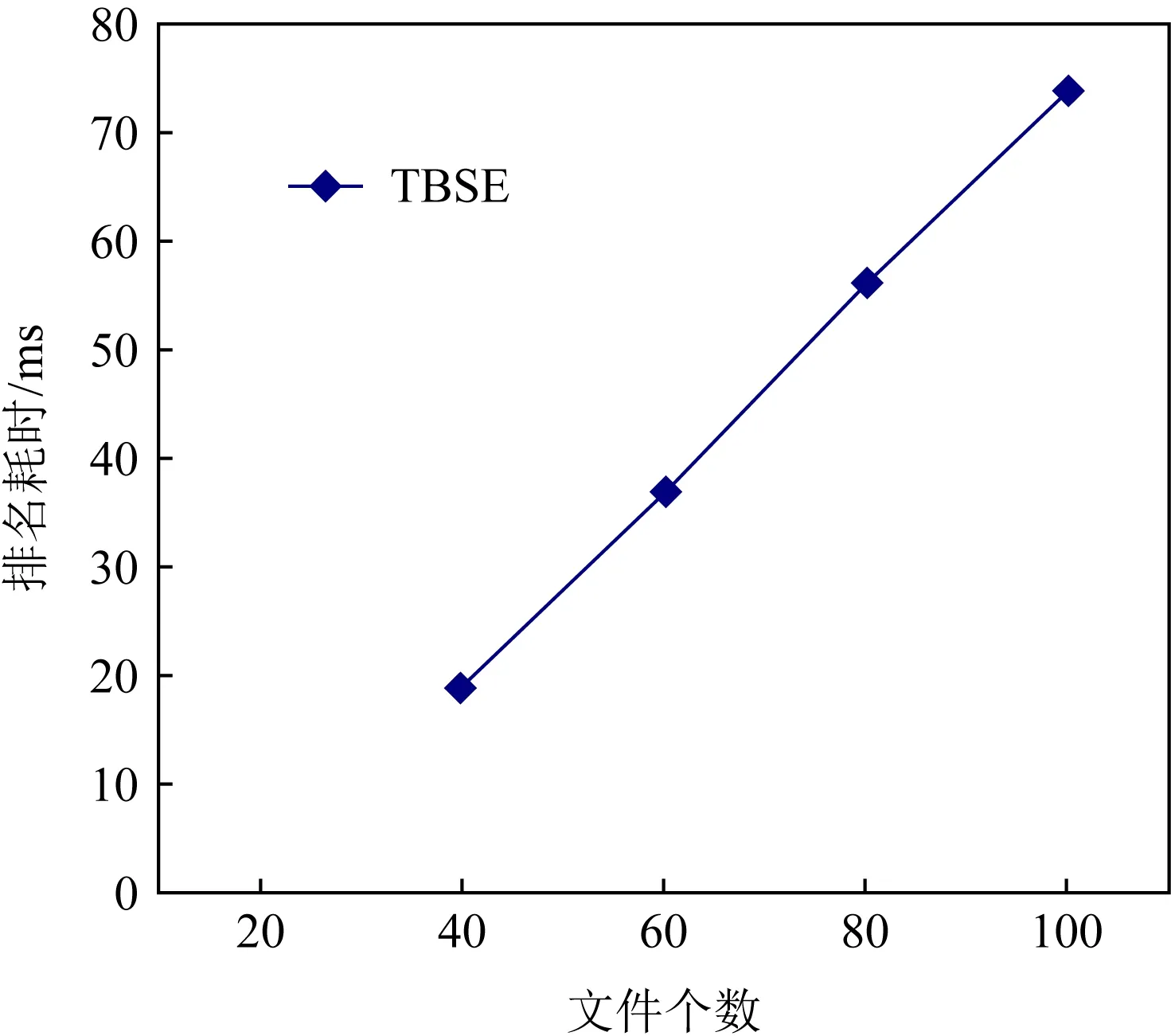
2)Enc.加密算法.假设消息空间由集合{0,1,…,T}中的整数组成且T 2DNF加密方案有加法同态的特性,即:给定密文E(a1),E(a2),那么a1+a2的密文可以被计算.同时,方案中的解密时间是消息空间m大小的多项式时间,因此,2DNF密码方案显然可以有效地适用于短消息. TF-IDF[22]是一种信息检索的常用技术,主要用于对文件中常用关键字进行加权.在信息检索领域常用 TF-IDF作为统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度,因此用这项技术进行top-k排名搜索来说再合适不过了.在该技术中,不仅仅只关注字词出现的频率,因为例如“的”、“the”这些词汇在文章中经常出现,但意义却并不大.因此,TF-IDF 技术的字词的重要性不仅仅随着它在文件中出现的次数成正比增加,同时会随着它在语料库中出现的频率成反比下降. 在进行布尔搜索的过程中,首先要对生成的逻辑检索式进行析取操作,得到一个标准的关键字连接式δ1∨δ2∨…∨δ,其中,对于任意一个δi来说,δi=ωi,1∧ωi,2∧…∧ωi,q,对于集合的交集来说,只需要将二者包含的相同内容找到即可,对于集合的并集来说,需要找到集合的交集,并用二者的和减掉交集,这样做,无疑浪费了大量的时间用在求和与减法操作上. 在集合论知识体系中,有一种将并集操作转化为交集操作的内容,例如,有3个集合DB(ω1),DB(ω2),DB(ω3),关系如图1所示: Fig. 1 Collection relationship diagram图1 集合关系示意图 对于3个集合的并集操作来说,推导过程[19]: DB(ω1)∪DB(ω2)∪DB(ω3)= (2) 至此,就完成了用交集操作替换并集操作的推导过程. 本节将描述TBSE方案的模型、形式化定义以及存在的安全威胁. TBSE方案包括3个实体,分别是数据拥有者、云服务器和安全协处理器(secure coprocessor, SCP)如图2所示: Fig. 2 The architecture of TBSE scheme图2 TBSE方案的体系架构 对于图2所示的方案模型而言,TBSE方案首先执行图2中虚线所表示的离线传输阶段.数据拥有者将加密文件及加密关键字索引传送至云服务器,并将加密分数索引及top-k排名中的k值传送至SCP.接下来方案执行在线传输阶段,包括4个步骤: 1) 数据拥有者将搜索令牌传送至云服务器,发出搜索请求; 2) 云服务器执行搜索后,将搜索后的结果与搜索令牌传送至SCP; 3) SCP对搜索结果执行top-k排名后,将前k个加密文件传送至云服务器; 4) 云服务器将排名后的前k个加密文件传送至数据拥有者,整个TBSE方案执行完毕. 在TBSE方案中,安全协处理器被认为是一个代理的小型服务器,它驻留在云服务器提供的隔离执行环境中,被认为是可信的.数据拥有者首先将文件加密,并上传到服务器.云服务器被认为是诚实且好奇(curious but honest)的.下面对3个实体在本方案中的功能进行详细介绍: 1) 数据拥有者.负责生成整个搜索方法中要使用到的密钥及利用对称加密算法生成加密文件,即负责初始化的部分;他要对自己的文件集合生成对应的关键字集合,并根据二者生成倒排索引;他要对已经生成的倒排索引进行处理,加密后上传至云服务器,即要负责关键字索引生成;由于要实现布尔搜索,该索引包括单关键字索引及交集索引2部分;为了实现top-k排名,他需要为每一个文件生成正向的分数索引;同时对于每一个待搜索的关键字,数据拥有者需要为其生成关键字所对应的令牌,并将其传送给数据拥有者;同时,当搜索结果返回时,他需要对数据进行解密,并得到搜索到的文件. 2) 云服务器.主要接收数据拥有者传送的加密索引;接受可信赖用户的搜索请求及相应的搜索令牌,并进行搜索操作;同时它还接受数据拥有者发出的搜索请求,并接收安全协处理器排名好的top-k个文件集. 3) 安全协处理器.主要负责接收加密的分数索引,同时接收云服务器传递的加密的字符串,对关键字进行搜索及 top-k排名,并返回相应文档标签至云服务器. TBSE方案共包含7个算法,分别是密钥生成算法、关键字索引生成算法、加密分数索引生成算法、令牌生成算法、搜索算法、top-k算法以及索引更新算法,TBSE方案所示: (KeyGen,IndexGen,ScoreIndexGen, 每个算法的具体描述为: 1) 密钥生成算法KSY,KDN,KGM←KeyGen(λ)为概率性算法,运行于数据拥有者.输入安全参数λ,输出对称加密密钥KSY,2DNF加密密钥KDN=(pkDN,skDN)以及GM加密密钥KGM=(pkGM,skGM). 2) 关键字索引生成算法EID←IndexGen(pkDN,pkGM,V,W,R)为概率性算法,运行于数据拥有者.输入密钥pkDN,pkGM,随机正交向量集V,关键字集合W以及随机数集合R,输出关键字加密索引EID. 3) 加密分数索引生成算法EIDScore←ScoreIndexGen(pkDN,D,V,W,R)为概率性算法,运行于数据拥有者.输入密钥pkDN,随机正交向量集V,文档集合D,关键字集合W以及随机数集合R,输出加密分数索引EIDScore,用于对搜索后的文件进行top-k排名. 4) 令牌生成算法τwq←TrapdoorGen(KDN,W,V)为确定性算法,运行于数据拥有者.输入密钥pkDN,随机正交向量集V以及关键字集合W,输出关键字的搜索令牌τwq. 5) 搜索算法ϑwq←Search(EID,τwq)为确定性算法,运行于云服务器.输入加密的安全索引EID,搜索令牌τwq,输出每一个搜索关键字所对应的加密字符串ϑwq. 6) top-k算法Dk←Top_k(ϑwq,skGM,k,EIDScore,τwq)为确定性算法,运行于SCP.输入加密字符串ϑwq,密钥skGM,搜索令牌τwq,加密分数索引EIDScore与可选数字k,输出top-k个文档集合Dk. 7) 索引更新算法EID′←IndexUpdate(EID,w′)为概率性算法,运行于数据拥有者.输入为加密索引EID与待更新的关键字w′,输出为新的加密索引EID′. 根据文献[17,22],本文方案考虑2种模型安全威胁,即已知明文模型和已知背景模型.本方案认为数据拥有者和SCP是完全可信的实体,而云服务器是“诚实且好奇的”,它会“诚实地”根据算法的指定协议存储数据拥有者全部的数据文档,但对存储的数据“感到好奇”,即云服务器想通过推断或分析加密数据和搜索令牌来获取数据拥有者的数据信息. 2) 已知背景模型.在已知背景模型中,云服务器能够获取比已知密文模型更多的数据信息,比如关键字索引之间、搜索令牌之间相关的信息或者数据集之间的统计信息等.因此,云服务器具有更强的攻击能力.云服务器可以根据已知的令牌信息,并借助一些统计信息来推断,分析上传的加密索引,搜索令牌和搜索结果等来确定搜索中的某些关键词的明文信息. 本节主要介绍TBSE方案的详细设计.TBSE方案需要解决3个问题:1)能够高效地实现对多关键字的布尔搜索;2)能够对搜索后的文件进行有效的top-k排序;3)能够对构建的关键字安全索引进行动态更新.根据第2节形式化定义,下面对TBSE方案的7个算法分别进行详细描述. 密钥生成算法KSY,KDN,KGM←KeyGen(λ)在数据拥有者端实现.TBSE方案在加密文件时利用传统对称加密方式(如AES)的方式加密文件,输入安全参数λ,生成文件加密密钥KSY.本方案在构造加密索引与搜索令牌的过程依赖于GM加密与2DNF加密,输入安全参数λ,生成2个加密方案的公私钥KDN=(skDN,pkDN),KGM=(skGM,pkGM).根据相关知识,pkDN=(N,G,GT,g,h),skDN=q1;pkGM=(n,m),skGM=p. 关键字索引生成算法EID←IndexGen(pkDN,pkGM,V,W,R)实现于数据拥有者端.为了实现布尔搜索,利用预备知识中集合论的相关知识,本方案所构建的关键字加密索引包含2个部分:对单关键字的加密索引SEID与关键字之间交集的加密索引inEID. 3.2.1 单关键字加密索引生成 首先,数据拥有者为每一个关键字wi∈W生成一个长度为|D|的二进制索引串biwi,即当文件dj∈D中包含关键字wi,biwi的第j位记为1,否则记为0.每一条biwi被存放在一个字典的数据结构中,记为biD(wi),大小为|W|,biD(wi)构造如图3所示: Fig. 3 Construction of binary dictionary图3 二进制字典构造结构 对字典中的每一个元素,使用GM加密生成Gi=EncGM(pkGM,bID(wi)).定义V是一个互相正交的向量集,vi∈V为每一个关键字所对应的随机向量,r∈R为一个随机数,vr∈V为一个随机向量.对每一个关键字wi使用2DNF加密生成Di=EncDN(pkDN,wi).利用上述步骤,生成关键字集W所对应的单关键字加密索引向量SEID,其构造: (3) 3.2.2 关键字交集加密索引生成 根据集合论相关知识,数据拥有者首先为每一个关键字wi∈W与其后面的关键字wj∈W做交集,生成(|W||D|)个交集倒排索引inIDi.与单关键字加密索引生成类似,根据每一个关键字的交集倒排索引生成长度为|D|的二进制索引串inbIDi,并将其依次存放于一个字典中.将每一个字典放入一个Multi-map结构MMb(wi)中.对MMb(wi)的每一个元素,采用与生成单关键字加密索引类似的方法生成加密索引.使用GM加密生成inGi∩inGj=EncGM(pkGM,inbIDi).对进行交集操作的关键字之间做“⊕”异或操作,使用2DNF加密生成inDi∩inDj=EncDN(pkDN,wi⊕wj).其余操作与生成单关键字加密索引类似.数据拥有者将每一个关键字对应的交集加密索引向量放入字典inD(wi)中,其构造: (4) 综上所述,关键字交集索引inEID生成完毕. 加密分数索引生成算法EIDScore←ScoreIndex-Gen(pkDN,D,V,W,R)实现于数据拥有者端.分数索引为正向索引,即每一个文件dj对应一串索引,这与关键字索引不同.数据拥有者首先计算关键字wi在文件中的“词频”(TF)与“逆向文本频率”(IDF)对dj构建分数索引,以方便之后对文件进行top-k排序,记关键字wi在文件dj中的个数为c.计算文件的TF-IDF值后,存放在字典sD(dj)中.其算法为 (5) (6) 令牌生成算法τwq←TrapdoorGen(KDN,W,V)实现于数据拥有者端,以便于实现搜索与top-k排序操作.TBSE方案为实现布尔搜索,每一个关键字wq对应的令牌τwq=(sτwq,inτwq)包含2个部分:单关键字令牌sτwq与关键字之间交集令牌inτwq. 3.4.1 单关键字令牌生成 (7) 3.4.2 关键字交集令牌生成 (8) 将每一个inτbiwq∩biwi整合在一起,生成wq所对应的交集搜索令牌inτwq.对于最后一个关键字wq,无需与其他关键字做交集,只需要得到其单关键字搜索令牌sτwq即可.将2部分令牌合并得到τwq,其结构: τw1=(sτw1,inτbiw1∩biw2,…,inτbiw1∩biwq), (9) 当wq∈W时,云服务器得到的参数sϑwq即为wq所对应的GM加密的二进制索引串Gwq.将搜索到的每一个sϑwq放入字典Ds ϑ(wq)中,其结构如图4所示: Fig. 4 Construction of single keyword search result图4 单关键字搜索结果构造结构 云服务器取出inτwq对inEID进行搜索,分别从字典inD(wi)中取出每个关键字对应的索引向量,其方法同对SEID的搜索方法类似,得到的参数inϑwq∩inϑwi为对wq与其后面关键字wi所对应的GM加密的二进制索引串inGq∩inGi.将搜索到的每一个参数inϑwq∩inϑwi放入MultimapMMinϑ(wq)中.其结构如图5所示: Fig. 5 Construction of multi-keywords search result图5 关键字交集搜索结果构造结构 对于最后一个关键字wq,只需要取出其单关键字令牌sτwq对SEID进行搜索,得到sϑwq=Gwq.将sϑwq放入字典Ds ϑ(wq)中,搜索过程执行完毕. top-k算法Dk←Top_k(ϑwq,skGM,k,EIDScore,sτwq)实现于安全协处理器(SCP)端,用于对文档进行排序并返回top-k个文件集Dk.云服务器在搜索算法执行完毕后,发送ϑwq至SCP.SCP首先用skGM分别对sϑwq与inτwq解密,得到每一个关键字wq的二进制索引串biwq,以及wq与其后面的每一个关键字wi的交集二进制索引串inbiwq∩inbiwi.对于执行布尔搜索的全部关键字W′,首先对执行“并”操作的全部关键字andW进行操作: (10) 得到andbi.这里的“∑”表示逐比特相加.将andbi与执行“交”操作全部关键字inW的inbiwq∩inbiwi进行操作: (11) 得到对执行布尔搜索得到的全部文件集的二进制索引串biD′,进而得到搜索到的全部文件集D′. SCP利用分数索引实现top-k排序操作,使用单关键字搜索令牌sτwq对EIDScore解密.得到存储dj的排名分数字典sD(dj).SCP根据数据拥有者提供的可选数字k对sD(dj)中的所有文件的分数进行排序,返回前k个文档集Dk至云服务器,整个top-k算法执行完毕. 索引更新算法EID′←IndexUpdate(EID,w′)实现于数据拥有者端.TBSE方案实现了对关键字集合W更新的同时,对关键字加密索引EID进行动态更新,大大提升了关键字索引更新的效率.索引更新算法包括对单关键字加密索引SEID与关键字交集加密索引inEID的更新. (12) 本节首先对TBSE方案进行安全性分析及性能分析,再从性能和功能2个角度与之前已有方案进行对比,最后对搜索效率及索引存储效率进行效率测试. 1) 已知密文模型中的安全性 在已知密文模型中,攻击者可以通过已知的密文建立线性方程,来计算加密索引和搜索令牌的真实值.考虑到加密索引,云服务器对于加密索引EID中的2部分SEID与inEID均为已知的,但对其中每一个关键字对应的子索引的值未知.使用随机向量vi∈V,随机数r∈R与GM,2DNF这2种加密算法分别对SEID与inEID加密,从而构成一个线性方程组: (13) 其中,考虑到vi,vr,r均为随机的,则方程式左侧有(|W||D|)个未知数,方程式右侧有|D|个未知数.根据式(13)所示,此方程组包含|W|个方程式.根据行列式的性质可知,当未知数的数量大于行列式的数量时,此方程组无解,则根据方程组无法得到通过GM以及2DNF加密后的数据,也就无法获得加密索引的真实值.同理,通过搜索令牌也得不到有关关键字数据和加密后数据的真实值,本方案对索引及令牌采用的加密机制能够保证数据的隐私性. 2) 已知背景模型中的安全性 根据文献[17]中的证明可知,在已知背景模型中,云服务器能够通过分析词频分布图,寻求加密索引与搜索令牌之间的内在联系来挖掘泄露文档的隐私,进而推断关键字信息.本方案在索引构建的过程中,对于单关键字索引SEID,将对每一个加密后的子索引向量相加,使其成为单个向量的形式,并引入随机数与随机向量,确保了加密后的单关键字索引与关键字所对应的倒排索引是毫无关联的.同样地,对于关键字交集索引inEID中的每一个向量,其每一条索引都采用2种加密方式,并将加密的数据相乘,同样引入了随机数与随机向量,因此无法得到多条关键字交集索引之间的关联.同理,攻击者也无法通过分析搜索令牌之间的关系得到搜索结果.同时,由于2DNF与GM加密中均引入了随机数,也就是说,即使多次重复一样的搜索,云服务器收到的索引和令牌也是不一样的,这有效地抵抗了统计分析攻击,防止了搜索模式泄露.因此,本文方案在已知背景模型中是安全的. 本节对TBSE方案与之前的相关可搜索加密方案进行对比,并对方案功能及性能2方面进行分析. TBSE方案同其他方案的对比数据如表1所示,其中M表示MRSE方案[17]与OXT方案[19]生成的倒排索引的最长索引的长度.#DB(w)表示MRSE,OXT,IBE方案[18]生成的倒排索引的长度,strg表示索引的存储空间.其中,从方案实现功能的角度,相比于IBE,TBSE方案支持对多关键字的布尔搜索.与MRSE方案和OXT方案相比,TBSE方案可以对搜索后得到的文件进行top-k排序.相比于MRSE,OXT,IBE,TBSE方案支持对关键字索引的动态更新. Table 1 Function and Performance Comparison Between TBSE and Other Schemes表1 TBSE同各方案的功能对比及性能对比 从方案性能的角度,首先分析方案的时间复杂度.假定待搜索的关键字集合为W={w1,w2,…,wq}.首先取出每一个关键字的单关键字搜索令牌与单关键字索引做乘法及幂运算,其搜索效率为O(|W|).接下来依次取出关键字w1,w2,…,wq-1的交集搜索令牌inτwq并与交集索引inEID做乘法及幂运算,其搜索效率为O(|W|2).则TBSE搜索算法的时间效率为O(|W|2).相比于同样支持布尔搜索的MRSE与OXT,TBSE提高了搜索算法的效率.其搜索算法时间复杂度低于IBE,主要是因为该算法只支持对单关键字的搜索. 分析索引的存储效率.对于MRSE方案,其关键字索引的存储效率随关键字个数呈线性提升.OXT方案对MRSE方案进行了改进,主要表现在存储交集索引时,其存储效率与关键字数量呈亚线性提升.TBSE方案进一步提升了索引存储效率,由于其单关键字索引SEID为一个向量元素,其存储效率为O(strg(#SEID)).交集索引inEID为存储(|W|-1)个向量元素的字典,其存储效率为O(strg(|W-1|#inEID)).因此,TBSE的单关键字索引存储效率只与向量的长度有关,因此单关键字存储效率不会随着关键字个数的增加而增加,同时在存储交集索引时也会减少存储空间.当|W|很大时,这大大提高了索引的存储效率,其效率优于MRSE方案和OXT方案.对于IBE方案,由于其不支持布尔搜索,在这里不参与对索引存储效率的比较. 通过实验的形式分别对方案中的索引存储大小,搜索效率及top-k排名效率进行测试,本文设计了一个C/S架构的TBSE方案原型系统,在Win10操作系统下通过Java语言实现. 首先对索引存储空间效率进行测试.实验结果如图6所示,横坐标为关键字个数,纵坐标为内存大小.可以发现,索引内存大小随着关键字个数的增加不会有非常明显的变化,这是因为我们利用向量的加法,将索引存储到一个向量中. Fig. 6 Index storage efficiency图6 索引存储效率 对关键字的搜索效率进行测试.首先对单关键字的搜索效率进行测试并与MRSE方案对比,如图7所示,其中横坐标为待搜索文件集的个数,纵坐标为搜索时间.通过实验我们可以清晰地得出结论,该方案在对单关键字进行搜索时,其时间复杂度不会随着文件集个数的增加而增加,永远保持一个常数,即O(|W|)的时间复杂度.当文件集个数越来越多时,TBSE在对单关键字的搜索效率的提升显著. Fig. 7 Single keyword search efficiency图7 单关键字搜索效率 对多关键字的布尔搜索效率测试,如图8所示.假定布尔搜索全部为求“交”操作,横坐标为待搜索的关键字个数,纵坐标为搜索耗时.通过实验结果我们可以得出结论,在对多关键字进行布尔搜索时,其搜索算法的时间复杂度为O(|W|2).相比于同样支持布尔搜索的OXT方案,本文方案提高了搜索算法的效率.而相比于MRSE方案,由于其不支持布尔搜索,只考虑对多关键字搜索时,其搜索效率为常数,不随搜索关键字个数增加而改变,因此只有当搜索关键字很少时,本方案相比MRSE方案在多关键字搜索上有优势. Fig. 8 Multi-keywords boolean search efficiency图8 多关键字布尔搜索效率 最后,对方案的top-k排名效率进行测试,如图9所示.尽管MRSE方案支持top-k,由于其搜索阶段包含top-k排名,因此不与其作比较. Fig. 9 top-k rank efficiency图9 top-k排名效率 针对先有的可搜索加密方案大多不支持对多关键字进行布尔搜索这一问题,本文提出了一种基于多关键字的top-k布尔可搜索加密方法,简称TBSE.该方案在传统的可搜索加密方案的基础上,通过GM加密算法及2DNF加密算法,生成了具有高搜索效率、高存储率的加密安全索引.在此基础上,利用集合论的相关性质,分别构建了单关键字加密索引及交集加密索引,从而实现了对多关键字的布尔搜索;利用TF-IDF技术构建正向分数索引,借助第三方实体SCP实现了对搜索后文件的top-k排名;同时,该方法能够对多关键字进行动态更新,提升了更新效率.之后通过安全性分析,证明了该算法能够对抗2种不同的安全威胁.最后对该方法进行了功能分析及性能分析,通过与其他可搜索加密方案进行对比,证明了TBSE方案的优越性.
1.3 逆向文本频率TF-IDF
1.4 布尔搜索与集合论
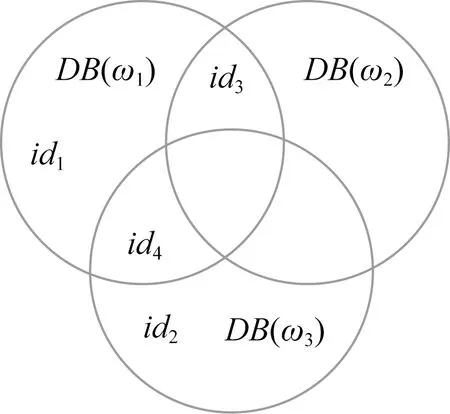
(id1,id2,id3,id4)↔(id1)+(id3)+(id2,id4)=
DB(ω1)-(DB(ω1)∩DB(ω2))-(DB(ω1)∩
DB(ω3))+DB(ω2)-(DB(ω2)∩
DB(ω3))+DB(ω3)=(id1,id3,id4)-
(id3)-(id4)+(id3)-∅+(id2,id4).2 TBSE方案
2.1 方案模型
2.2 形式化定义
TrapdoorGen,Search,Top_k,IndexUpdate).2.3 安全威胁

3 TBSE方案详细设计
3.1 密钥生成算法
3.2 关键字索引生成算法
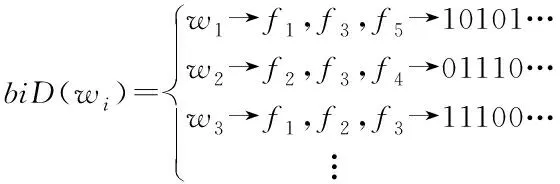
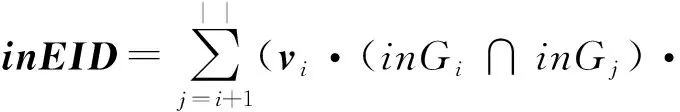
3.3 加密分数索引生成算法
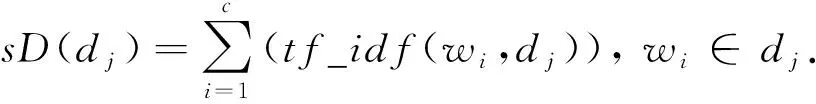
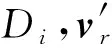

3.4 令牌生成算法
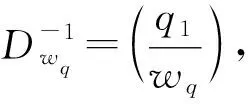
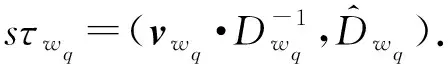
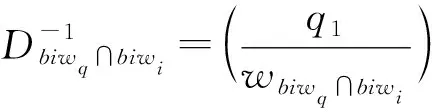
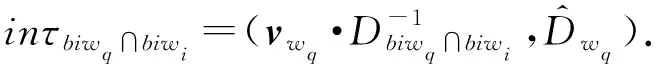
τw2=(sτw2,inτbiw2∩biw3,…,inτbiw2∩biwq),
⋮
τwq-1=(sτwq-1,inτbiwq-1∩biwq),
τwq=sτwq.3.5 搜索算法
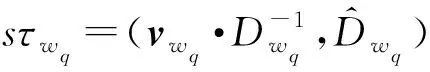
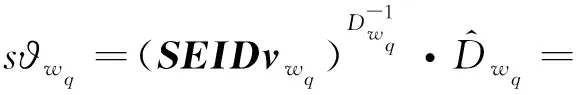

3.6 top-k算法
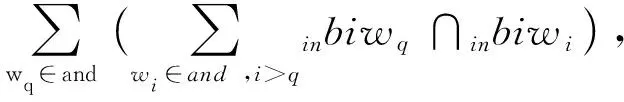
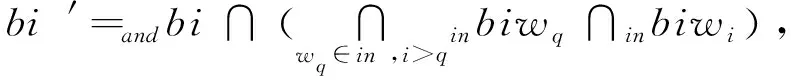
3.7 索引更新算法
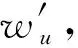
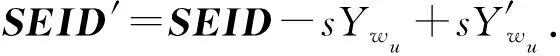
4 安全性与性能分析
4.1 安全性分析
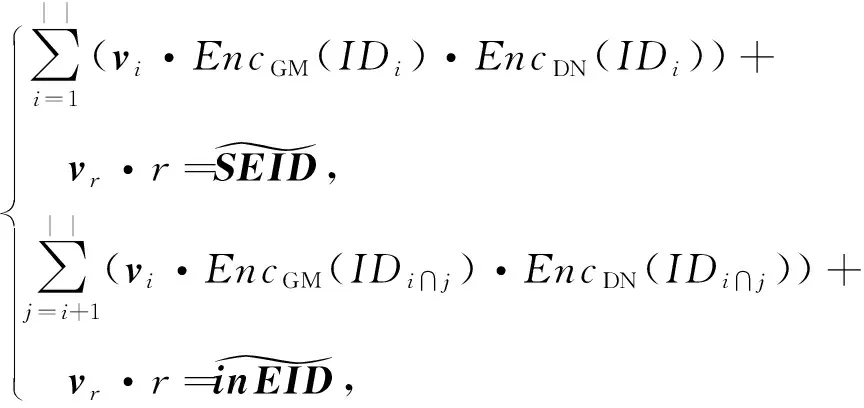
4.2 性能分析与方案对比

4.3 效率测试
5 总 结
