声纹鉴定中嗓音音质的声学界标初探
——基于随机森林和决策树模型的研究
2022-08-12耿浦洋施少培卞新伟卢启萌曾锦华
耿浦洋,施少培,郭 弘,卞新伟,卢启萌,曾锦华
(司法鉴定科学研究院 上海市司法鉴定专业技术服务平台 司法部司法鉴定重点实验室,上海 200063)
嗓音音质是语音中最显著、最易感知的特征之一,通常指嗓音的质量,由声带振动/松紧、声门闭合以及呼吸和发声的协调等因素共同决定。 从听觉感知的角度出发,常见的嗓音音质可以归类为正常嗓音、气嗓音、嘎裂嗓音和假嗓音等。 在以往研究中发现,嗓音音质与说话人的性别、体型、病理、语言/文化背景以及情感等信息都存在较高的相关性。 因此,有学者提出嗓音音质是话者语音产出的重要特征,能够反映说话人的个体特点,并且具有一定的稳定性。
目前,在声纹鉴定工作中,嗓音音质是极具参考价值的特征之一,无论是在听觉检验还是在频谱分析中, 对语音同一性判断都起着非常重要的作用。 然而,在对证据语音和样本语音的嗓音音质进行比对分析时发现,目前的鉴定实践中存在一个亟待解决的问题,即对嗓音音质的类别判断尚缺乏客观的数据支撑。 例如,听感上判断为嘎裂的嗓音,在频谱上没有理想的声学参数加以佐证。 KEATING 等研究发现,基频抖动(jitter)、振幅抖动(shimmer)、谐噪比(Harmonic to Noise Ratio, HNR)、谐波差值(如H1-A1)等声学参数和嗓音音质存在一定的相关性。例如,嘎裂嗓音比气嗓音的第一第二谐波差值(H1-H2)更低。但是,气嗓和嘎裂两类音质在声学参数上的分界点究竟在哪里? 什么样的声学参数才能够被判断为某类音质? 关于这些问题尚缺乏实证研究。 因此,本研究旨在探索不同嗓音音质之间的分界点,为嗓音音质的类别判断提供数据支撑,利用相关结果为声纹鉴定中证据语音和样本语音在嗓音类别的同一性判断上提供客观依据和量化指标。
1 声学界标
为了解决嗓音音质在声学参数上的类别划分问题,本研究引入一种新型分析方法——声学界标分析。 声学界标(acoustic landmark)是基于STEVENS提出的“语音量子理论”(Quantal Nature of Speech, QNS)的一种分析方法。QNS 认为,发音器官运动和声学参数之间存在一种非线性关系,即量子关系(图1)。在I 区和Ⅲ区,发音器官运动不会引起相应声学参数的剧烈变化,即为稳定段;在Ⅱ区,发音器官运动会引起声学参数的剧烈变化,即为不稳定段。 从区别特征的角度来看,Ⅱ区是从I 区没有形成特征(即[-F])到Ⅲ区形成稳定特征(即[+F])的关键区域。 该区域存在一个声学界标,反映声学特征在发音参数不同赋值下的有无情况。 针对声学界标的研究,不仅有助于增进对语音产出过程中发音-声学的非线性关系的理解,还具有广泛的应用价值,如利用声学界标进行病理语音的识别、二语偏误教学等。

图1 发音-声学量子关系图
围绕声学界标的概念,已有部分学者开展了相关研究。 例如:PERKELL 等对英语的元音(即/a/、/i/、/u/)声学界标进行分析;KOZLOFF 等对西班牙语中拍音(tapped /ɾ/)和颤音(thrilled /r/)的声学界标进行探索。 还有学者利用声学界标的研究方法对特殊语音进行相关分析,如发音障碍患者的语音、抑郁语音等。与其他语言的研究相比,对汉语的研究尚处于探索阶段,只有曾晨刚对汉语普通话的塞擦音进行过声学界标研究。本研究参考曾晨刚、VEILEUX 等研究的范式,基于随机森林和决策树模型,对嗓音音质的声学界标进行探索。
2 实验方法
2.1 发音被试对象
本研究共招募12 名汉语普通话发音人(6 名女性,6 名男性),被试对象均来自中国北方地区(北京、河北和东北部),且普通话标准。 招募的男性被试对象平均年龄32.2 岁(标准差为6.4),平均身高177.2 cm(标准差为1.6),平均体重77.2 kg(标准差为6.8);女性被试对象平均年龄32.0 岁(标准差为6.3),平均身高163.7 cm(标准差为2.0),平均体重55.17 kg(标准差为5.5)。 所有被试对象均为右利手,无言语或听觉损伤历史。
2.2 语料采集
由于汉语研究发现,普通话常用嘎裂音质来表现曲折调(即三声,T3)的低点,因此本研究选取声调为三声的单音节词为实验材料,以获取更自然的嘎裂音质。 本研究选取9 个单音词为实验材料,如表1 所示。 为了保证语料的可控性, 声母统一选取较稳定的/m/,以排除声母影响。同时,选取单韵母(即/a/、/i/、/u/)和复韵母(即/ao/、/iao/、/an/、/in/、/ang/、/eng/),以达到覆盖不同韵母类别的目的。 实验在安静录音棚内进行,使用专业录音机(SONY PCM-D50)进行录音,采样率48.0kHz,量化精度16bit。录音开始前,被试对象首先熟悉录音材料并试读。 然后,分别用正常嗓音、嘎裂嗓音、气嗓音、假嗓音这4 种状态朗读录音材料,每个单音节词读3 遍,间隔1s。 每种嗓音朗读间隔2min,以达到声带状态复原的目的。

表1 实验录音材料
本研究共录制1 296 个单音节词,并进一步邀请2 名具有丰富听辨经验的汉语母语者对语料进行感知筛选。 对于每个单音节词,选取三遍朗读中嗓音音质感知效果最佳的那一遍,用于接下来的声学界标研究。
2.3 参数提取
首先,使用Montreal Forced Aligner 软件对语料在字和音位两个层面进行自动标注,并由一名具有丰富标注经验的人员手动对标注精度进行校正。其次,基于标注语音,使用Praat 软件提取声学参数。 前人认为, 嗓音音质通常和基频抖动(jitter)、HNR、第一第二谐波差值(H1-H2)等参数具有较高相关性。 同时,为了更全面地考察声学参数和嗓音类别的关系,研究还选取了基频(听觉对应音高)、音强和时长3 个常见参数。 最后,本研究共提取18个声学参数:基频均值、标准差、最大值/最小值及范围,音强均值、标准差、最大值/最小值及范围,时长(即整字、元音段、辅音段),基频抖动、振幅抖动(shimmer)、HNR 和谐波相关参数(即H1-H2、H1-A1、H1-A2、H1-A3)。 其中,基频的提取使用Praat自带的短期自相关算法,对每个计算错误(倍频或半频)的音高点都进行手动修正。 对提取的基频值(单位为Hz)进行半音(st)转换[st= 12×log(f/f)],参考频率(f)为100 Hz。 对于谐波相关参数,提取方法是将每个单音节词的元音段平均分为5 段,再分别对5 段语音信号的谐波参数进行提取。
2.4 分析思路
本研究的分析思路如下:先基于18 个声学参数,建立随机森林模型对4 种嗓音音质进行判别分析,并按照声学参数对嗓音判别的影响大小进行排序;再选取影响较大的声学参数,使用决策树模型对4 种嗓音音质的声学界标进行分析。
3 实验结果
3.1 基于随机森林的判别结果
随机森林是一种基于决策树的并行集成学习算法,其原理是利用bootstrap 重抽样方法对原始样本进行抽样,然后对所有抽样建立决策树模型,最后根据投票得出最终的预测结果。 随机森林模型的构建流程如图2 所示。
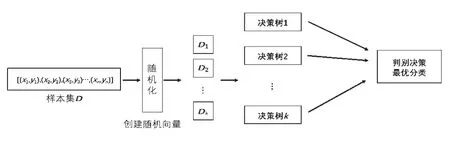
图2 随机森林模型构建流程
使用R 语言的rondomForest 包,以18 个声学参数为因子,嗓音音质为因变量,建立随机森林模型。 按7:3 的比例将数据分为训练集和测试集。模型内,决策树的数量(n)设为默认值500。 同时,为最小化OOB(out-of-bag)预测错误率,使用rondomForest 包中的“tunTF”功能,将m参数优化为8,训练集的OOB 预测错误率为9.03%。
针对测试集的嗓音音质的总体判别准确率为90.76%。 4 种嗓音音质判别结果的混淆矩阵如表2所示。 正常嗓音和气嗓音的判别准确率均为100%;假嗓音的判别准确率为93.33%,有6.67%的假嗓音被判别为正常嗓音;嘎裂嗓音的判别准确率最低(即88.46%),约8%的嘎裂嗓音被判别为正常嗓音、4%被判别为假嗓音。

表2 随机森林判决结果的混淆矩阵(测试集) (%)
最后,以平均损耗准确率为标准,对18 个声学参数对嗓音判别的贡献度进行排序。 如图3 所示,对判别准确率影响较大的参数(图中阴影标示柱状图)包括:基频参数(即F0_max、F0_min、F0_mean、F0_sd)、整字时长(duration)、HNR、基 频 抖 动(jitter)、振幅抖动(shimmer)、第一谐波和第三振幅差值(H1-A3)。 此外,音强参数(即Intensity_sd、Intensity_mean)对于嗓音判别也具有一定的贡献。
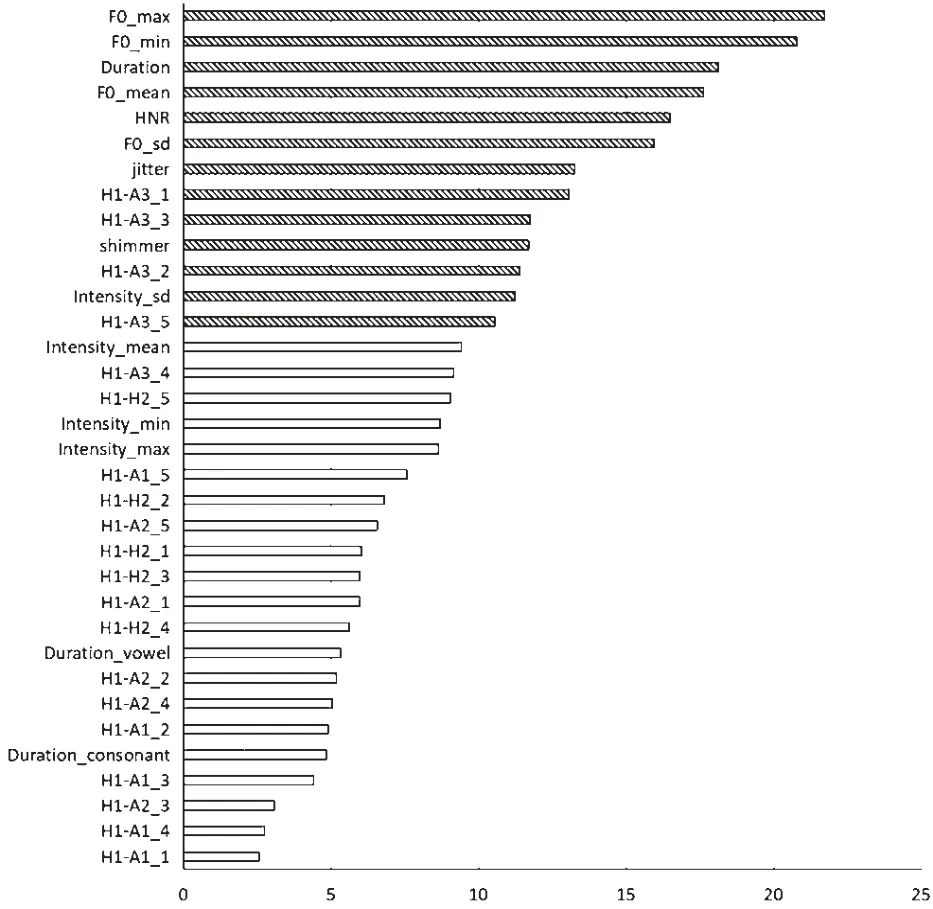
图3 声学参数对嗓音判别的贡献度
3.2 决策树模型结果
决策树模型是一种非参数监督学习模型,是研究数据分类规则的常见方法。 该模型的基本原理是通过一系列if-then 决策规则的集合,将特征空间划分成有限个不相交的子区域,对于落在相同子区域的样本,决策树模型给出相同的预测值。使用SPSS 25.0 软件建立决策树模型。 基于本文3.1 章节随机森林的结果,选取音高参数、整字时长、HNR、基频抖动、振幅抖动、第一谐波和第三振幅差值作为因子,将4 种嗓音类别作为因变量输入模型。 按7:3的比例设置训练集和测试集。
如表3 所示,根据决策树模型判别结果的混淆矩阵,训练集总体判别准确率为78.0%,气嗓音的判别准确率最高(即94.2%),嘎裂音和假嗓音的判别准确率在75%左右, 正常嗓音的判别准确率相对较低(即65.7%)。模型经过学习对测试集进行判别时,准确率与学习前基本保持一致,只有正常嗓音的准确率下降了7.1 个百分点。
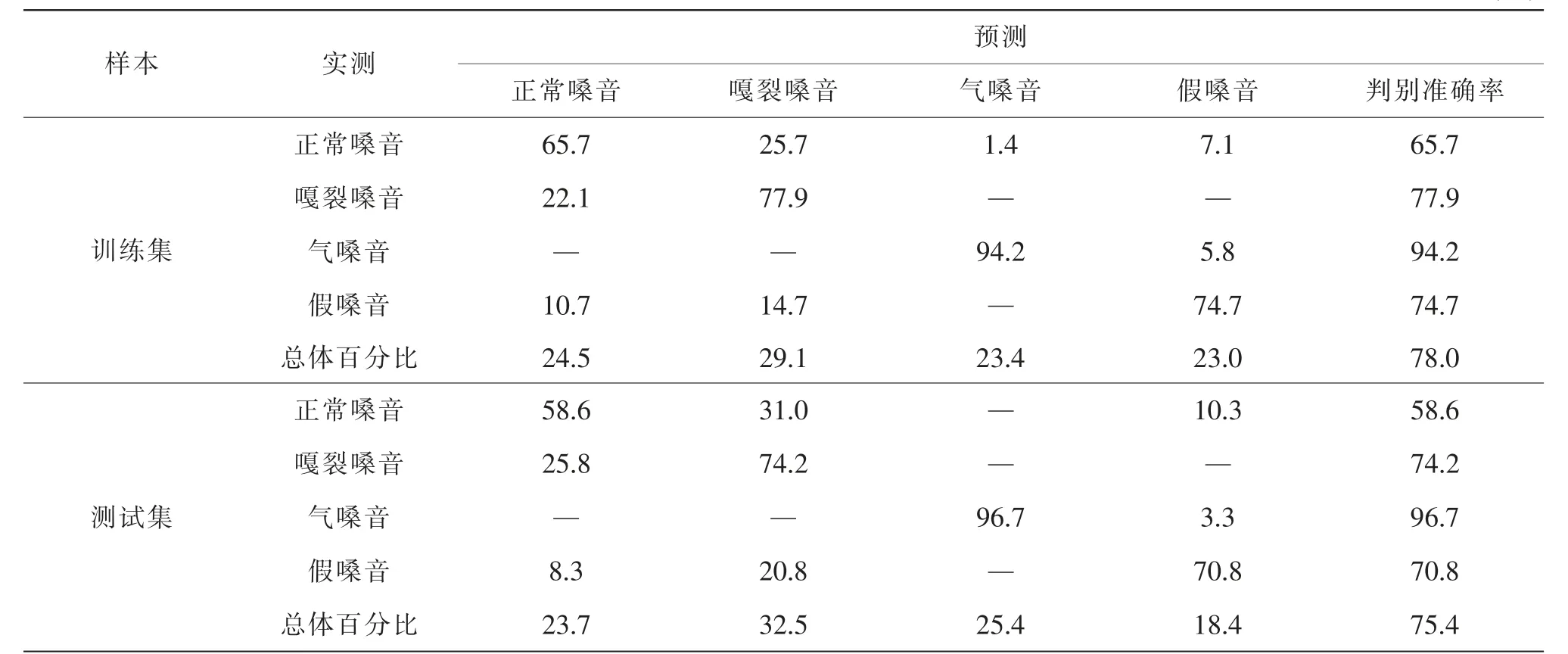
表3 决策树模型判别结果的混淆矩阵 (%)
决策树经过学习生成的嗓音音质聚类流程如图4 所示。 根据流程图可以看出,不同嗓音音质的分类规则包括三个决策点:
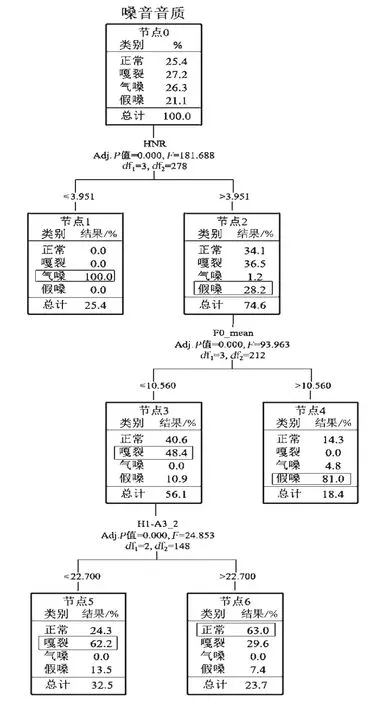
图4 嗓音音质的决策树分类流程
(1)HNR:HNR 反映语音信号中谐波和噪音的比例, 该值越低表示信号中的噪音成分越多。 以3.951 为阈值,决策树模型将气嗓音和其他3 种嗓音区分开来,小于等于该数值的语音被判别为气嗓音。 这一分类规则也符合通常对气嗓音HNR 数值的预期。
(2)基频均值:以10.560 为阈值,模型进一步将假嗓音和正常嗓音、嘎裂嗓音进行了区分,当基频均值大于10.560 时,语音信号被判别为假嗓音。 这一分类规则同样符合对假嗓音基频均值的预期。
(3)第一谐波和第三振幅差值(H1-A3):本研究对谐波参数进行提取时,将每个元音均分为5段,然后分别提取每段的谐波参数。 在决策树模型中,以第二段的H1-A3 为第三个决策点,22.7 为阈值,对正常嗓音和嘎裂嗓音进一步区分。
再将决策树模型对4 种嗓音音质的分类规则加以归纳,结果如表4 所示。
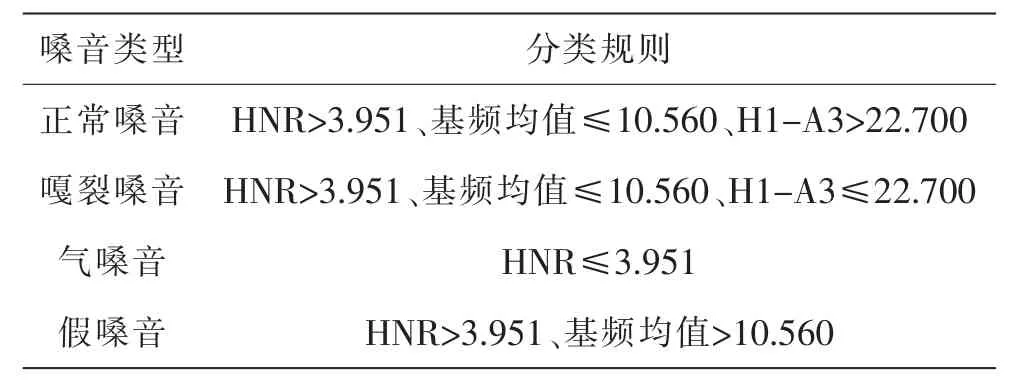
表4 嗓音音质的决策树模型分类规则
4 结论
本研究基于随机森林和决策树模型,对4 种嗓音音质的声学界标进行了探索。 随机森林结果显示:嗓音音质的判别准确率为90.76%,基频、整字时长、HNR 和第一谐波和第三振幅差值(H1-A3)等参数对于嗓音判别的贡献度较大。 基于随机森林的结果,以对嗓音判别贡献度较大的声学参数为因子建立决策树模型,结果发现:嗓音音质的判别准确率在75%以上,决策树共有三个决策点,分别为SNR、基频均值和H1-A3。
与KEATING 等研究结果一致,HNR、谐波差值等参数确实和嗓音音质存在较高的相关性。 与H1-H2、H1-A1、H1-A2 相比,H1-A3 对于嗓音音质的区分度更好。此外,尽管在随机森林模型中,基频抖动(jitter)和振幅抖动(shimmer)都具有较高的贡献度。但在决策树模型中,基频抖动和振幅抖动并未作为嗓音类别的决策点。 TEIXEIRA 和FERNANDES 认为,基频抖动和振幅抖动对于病理和健康嗓音的区分效果可能更佳。
研究发现,(1)决策树模型以HNR、基频均值和H1-A3 为决策点。首先,根据气嗓音信号中噪音成分更多的特点,HNR 将气嗓音和其他3 种嗓音区分开来。 其次,根据假嗓音基频均值更高的特点,将假嗓音和正常嗓音、嘎裂嗓音进一步区分。 最后,根据H1-A3 的差异区分正常嗓音和嘎裂嗓音。 三个决策点作为嗓音音质的声学界标,不仅能够实现较高的嗓音判别准确率,同时也能够较好地反映出不同嗓音类别的特点。值得注意的是,决策树模型对正常嗓音的识别率相对较低(如表3 所示,分别为65.7%和58.6%),并且正常嗓音和嘎裂嗓音的区分性也相对较差(如图4 所示,存在25%左右的混淆)。 可能的原因是,H1-A3 对于正常嗓音和嘎裂嗓音的区分效果并不十分理想。 未来可以针对正常嗓音和嘎裂嗓音的区分进行专门考察,尝试增加其他声学参数(如共振峰、带宽),寻找能够更好区分正常嗓音和嘎裂嗓音的声学界标。 (2)4 种常见嗓音音质之间存在显著的声学界标。 这一结果对于声纹鉴定中的嗓音音质判断具有重要的理论意义和应用价值,不仅能够为听觉检验中的主观判断提供客观数据支撑,还能够丰富声谱检验的测量指标。此外,本研究对于推动声纹鉴定的科学化、客观化,司法鉴定的规范化以及提升证据可信度等方面也具有积极的作用。
但本研究仍存在以下几点不足值得改进:(1)本研究采集了1 296 个单音节词,并进行了感知筛选,以期对更具代表性和普遍性的嗓音语料加以研究。在数据量上略显不足,未来可以继续扩大男性、女性被试对象的数量,对嗓音音质的声学界标进行更为广泛、深入的大数据研究,以进一步推广本研究结论。 (2)本研究以单音节词为考察对象,未来还可以对连续语流进行考察,以进一步验证本文结论。 (3)尽管通过声学参数可以实现较高的嗓音判别准确率,但是嗓音音质的声学界标在声纹鉴定实践中的应用效果尚不得而知,需要后续开展基于真实案件的应用研究加以确认。
