软件定义物联网中基于深度强化学习的路由优化算法
2022-08-12王健朱晓娟
王健,朱晓娟
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
0 引 言
近年来,物联网(Internet of Things, IoT)被广泛应用于环境监测、工业控制和国防军事等领域,并逐渐成为全球科技战略发展的焦点之一。随着物联网的快速发展,高速、海量数据通信向服务质量保障机制提出了挑战。于是,有学者提出了软件定义网络(software def ined network, SDN),用以优化通信网络。SDN是将控制平面和数据平面分离的框架,以便动态管理和控制大量网络设备、拓扑、路由、QoS和数据包处理策略。SDN控制器通过在控制器内运行不同的模块来执行各种任务,从而提供面向应用程序的服务。
强化学习作为可以优化网络决策的一种方案也被应用到物联网环境中。在一定的环境状态中,智能体与环境交互,根据动作来获得奖励,并根据奖励情况确定下一步的动作,循环往复,不断提高自己的决策能力。Lillicrap等人提出的深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG)基于Actor-Critic框架解决连续状态空间下的问题。DDPG使用深度Q网络逼近Q表,使用策略网络直接产生确定的动作,解决了DQN面对连续动作时无法处理的问题。
文献[3-6]提出了基于SDN特性的路由解决方案,如可编程性、全局视图、网络传输和控制的解耦,以及逻辑集中控制。但是这些解决方案没有使用强化学习的算法,在网络状态变化时容易导致拥塞。
Muhammad Adil等人提出一种高效的混合路由方案(DCBSRP),利用自组织按需距离矢量(AODV)路由协议和低能耗自适应集群层次结构(LEACH)协议,在规定的时间间隔内动态形成簇头节点。选择能量高的节点充当簇头节点,平衡节点之间的负载。仿真结果表明,该方案不仅提高了网络的寿命,而且在吞吐量、丢包率和能效方面都优于其他方案。
文献[8-10]基于传统强化学习的思想解决路由优化问题。CHANGHE Y U等人使用深度强化学习(deep reinforcement learning, DRL)中的DDPG对路由进行优化。仿真实验表明,该算法实现了对网络全局的智能控制和管理,具有良好的收敛性。针对DDPG训练过程会消耗较多网络资源这一情况,周浩等人提出了“线下训练、线上运行”的方法,但他们在设计该方法时并没有将复杂的网络环境考虑在内。
将SDN路由优化看成一个决策问题,运用强化学习来优化路由。将当前的网络环境视为强化学习中的初始状态,通过改变网络参数,将当前网络状态下的网络信息作为输入,奖励值采用延迟、吞吐量等指标,最后通过训练得到路由模型。当网络中有新流到达时,智能体可以快速计算出性能最优的路由路径。
本文在SDN架构下,针对无线传感器网络环境流量信息复杂,容易致使路径发生拥塞的问题,采用RDIS算法使计算出的源节点与目标节点之间的路由路径在全局下性能接近最优,从而实现提高网络性能的目的。根据SDN控制器提供的全局路由视图,RDIS通过DRL代理与环境交互学习路由策略,该算法可以根据动作和获得的奖励找到性能接近最优的路由路径。
1 深度强化学习
1.1 DDPG算法
DDPG可以基于确定性策略梯度算法(Deterministic Policy Gradient, DPG)完成具有连续状态空间和动作空间的任务。在每一轮的训练过程中,DDPG将获得的状态转换信息(sras)作为经验存储在一个经验回放池中。DDPG使用深度神经网络去逼近策略函数,直接输出一个确定的动作。DDPG由一个actor模块和一个critic模块组成,每个模块拥有两个网络,分别是actor模块中的策略网络((s|θ))和目标策略网络(′(s|θ))以及critic模块中的网络((,)|θ)和目标网络(′(,)|θ)。在神经网络训练的过程中,DDPG在经验回放池中对样本进行随机抽样训练,所抽取的样本用来更新每个模块中的神经网络参数,最后得到网络模型。
DDPG的参数更新过程主要分为两个阶段。actor模块根据输入的状态输出动作,critic模块将actor模块输出的动作和当前状态输入,最终输出值。两个模块进行参数的更新。式(1)表示策略更新的方法:

在critic模块中,通过TD-error对神经网络参数进行反向更新,如式(2)所示:
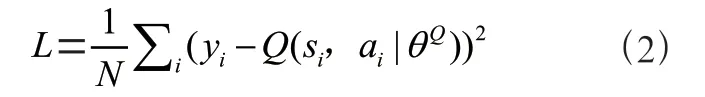
y是目标网络针对网络环境状态所采取的下一步动作的值。该值的动作来源于actor模块中的目标网络。目标网络根据在线网络传送过来的参数信息′和下一步状态所采取的动作a进行更新。y的具体更新过程如式(3)所示:
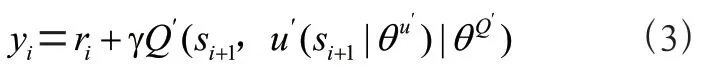
在网络中,将值进行参数化,可以针对现有状态做出准确的评估,选取最合适的动作持续运行。
在DDPG中,智能体从经验池中对样本“随机采样”,由于不同数据的重要性不同,这种方法容易导致学习效率低。本文基于优先经验回放,根据经验重要性,希望价值越高的经验被采样到的概率越大,从而提高学习效率。通过概率方式抽取经验,每个经验的优先值表达式如式(4)所示:

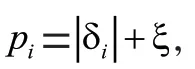
但是这种采样方法引入了偏差,因为它改变了数据的分布,进而改变了期望值。因此,通过加上重要性采样来修改权重,如式(5)所示:
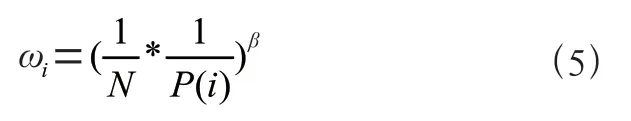
其中,表示抽样的批次大小,表示一个介于0和1之间的参数。在采样时,使用重要性采样参数来调整权重,根据样本优先级对样本采样。
1.2 路由算法RDIS
本文所提出的路由算法RDIS(Routing optimization algorithm based on deep reinforcement learning in software def ined Internet of things, RDIS),是在SDN下将DDPG应用到路由问题中实现的。相较于传统的WSN,RDIS具有可编程性、灵活性和集中式管理等优点。本文的模型以SDNWISE架构为基础,如图1所示。
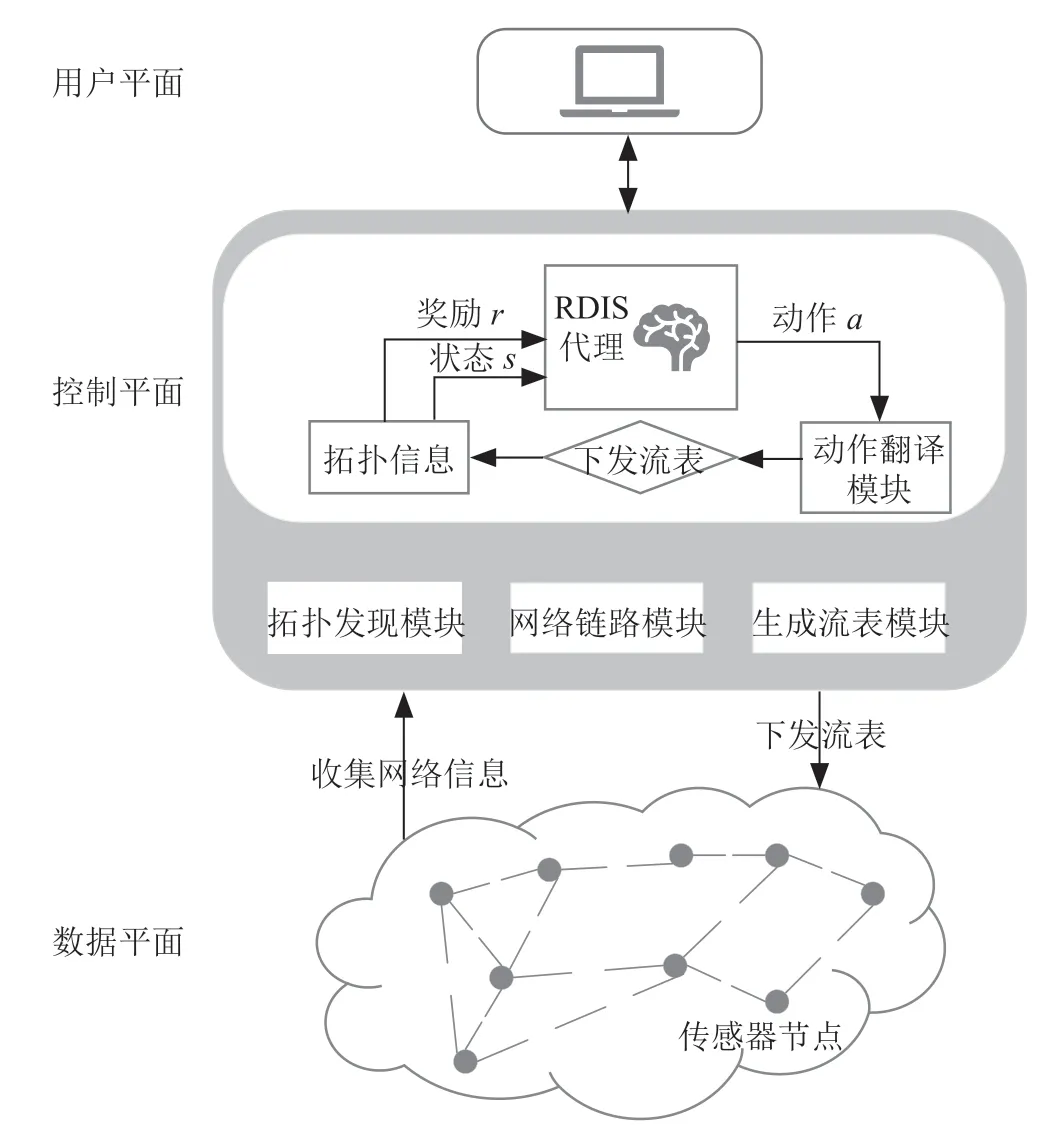
图1 DDPG路由模型
最底下为数据平面, 由传感器节点等硬件设备组成。数据平面的主要功能是在传感器节点之间执行数据的转发。
控制平面拥有一个逻辑集中的控制器,确保用户平面和数据平面之间的通信。控制平面内包含四个模块,分别为网络链路模块、拓扑发现模块、生成流表模块和智能模块。
网络链路模块的作用是发现和维护整个网络拓扑的链路信息。网络链路模块将每个传感器节点的相关信息上传到控制器,存储到控制器中为接下来的模块做准备。在SDN-WISE架构下,使用report数据包获取所需的链路信息,包括延迟、吞吐量等信息。拓扑发现模块使用从网络链路模块获取的节点信息生成和维持网络拓扑。生成流表模块根据智能模块计算好的路径,将流表下发到数据平面,规划路由路径。
智能模块学习网络的行为,并利用RDIS代理计算路径。它与控制平面交互,检索链路状态信息并下发计算好的流表。该模块还包含拓扑信息收集模块、RDIS代理和动作翻译模块。拓扑信息收集模块用于存放从控制平面收集的网络状态信息。动作翻译模块将RDIS代理中的动作翻译成一组适当的sensor-openflow消息,从而更新流表。
用户平面是SDN的最高级别层,在该平面中实现了面向应用程序服务的概念。网络状态信息(例如路由信息)通过数据平面收集并被各种网络应用程序使用。
在RDIS中,将PER与DDPG相结合,以提高价值高的经验被成功采样的概率。PER处理过程为:
算法1:PER采样过程。
(1)初始化经验回放池。
(2)根据权重θ和θ初始化critic网络((,)|θ)和actor网络((s|θ))。
(3)根据权重θ←θ和θ ′←θ初始化目标critic网络(′(,)|θ)和目标actor网络(′(s|θ)。
(4)初始化状态(),设置批次大小。
(5)将(s,r,a,s)存储至经验回放池,设置最大优先级。
(6)For j=1 to T do:
(7)根据优先级进行样本转换:(s,r,a,s)。
(8)计算相应的重要性采样权重W和TD误差δ。
(9)根据|δ|的值更新样本优先级。
(10)End for。
为了将DDPG应用到路由问题中,对算法的奖励函数、动作空间和状态空间进行设计。下面介绍RDIS算法的奖励函数、状态空间和动作空间:
(1)奖励函数。奖励是智能体做出动作后获得的反馈,它可以是正面的,也可以是负面的。奖励在RDIS中非常重要,因为下一个动作将根据奖励的值来确定。奖励函数的定义如式(6)所示,它与吞吐量成正比,与链路延迟成反比。值和∈[0,1]是可调的参数,可根据需要自动调整权重。
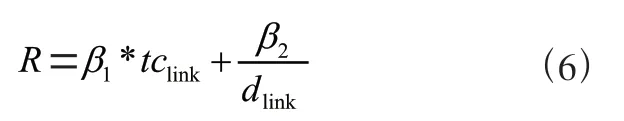
为了防止在学习过程中存在某一个状态指标比其他指标影响更大的情况,对方程(6)使用Min-Max技术进行归一化处理。它可以将参数范围缩放到任意值区间。式(7)表示奖励函数的归一化结果,其中和分别为吞吐量和链路延迟的归一化值。

每个归一化值(和)均由方程(8)得到。在这个方程中,′表示需要归一化的值,表示归一化中使用的值集。
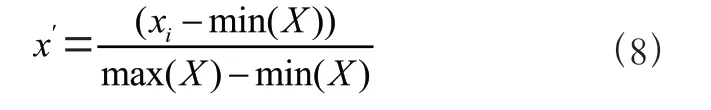
(2)状态空间。控制器拥有网络拓扑的全局视图,通过控制器可以获得所需的状态空间信息。状态空间中的每个状态为在选择下一跳节点后收集到的节点和链路状态信息。对于传感器节点v,∈{1,2,3,…,},控制平面从数据平面收集带宽、时延、丢包率loss和吞吐量等信息。总体来说,状态空间可以表示为:

其中,∈{1,2,3,…,},s表示所有状态中的任意一个状态,在每一个状态中,收集链路中的信息。
(3)动作空间。动作空间表示对所有状态采取动作的合集。可由以下公式表示:

a代表在节点采取的动作,并且a={
a|j∈{1,2,3,…,},≠}。a表示节点和节点之间的连接关系。若a=0,表示两个节点之间不连通,a∈(0,1]表示从节点选择下一跳节点为节点的权重。
使用上述状态空间、动作空间和奖励函数进行路由优化并使奖励最大化。以下是RDIS的训练过程:
算法2:RDIS训练过程
输入:网络状态数据包括边总数、顶点数、奖励函数、学习率等
输出:路由路径。
(1)初始化控制器。
(2)控制器发现邻居节点,收集传感器节点信息。
(3)建立网络拓扑图。
(4)For episode = 1 to M do。
(5) For t = 1 to T do。
(6) 根据重要性采样从经验回放池中采集样本(s,r,a,s)。
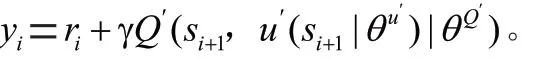
(8) 最小化损失更新critic网络:
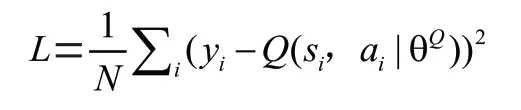
(9) 通过采样更新actor策略:
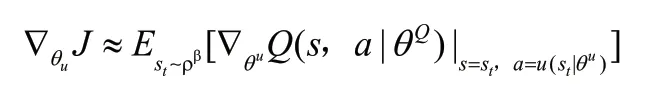
(10) 目标网络更新:

(11) End for
(12)End for
2 实验与性能评估
在实验中,使用Pytorch作为后端实现RDIS算法,Python版本为3.8。在接下来的内容中,对RDIS的性能进行了评估。实验结果分为两个部分:(1)展示了RDIS在不同学习率情况下的收敛速度。(2)将提出的算法与RLSDWSN和DCBSRP算法进行了性能对比。
2.1 实验设置
为了测试提出的RDIS算法,选择一个含有30个节点的网络。从源节点到目标节点之间有多条路径可供选择。实验参数的设置如表1所示。

表1 仿真参数表
图2展示了不同学习率情况下RDIS算法的收敛速度。从图中可以看出学习速率对收敛性能有影响,而当学习速率为0.1时,RDIS的收敛速度最快。因此,在接下来的训练中,将学习率设置为0.1。

图2 不同学习率下算法收敛速度
2.2 性能评估
为了评估RDIS的性能,选择分组延迟和吞吐量作为网络度量标准。在相同条件下,将RDIS算法与文献[10]中的RL-SDWSN算法和文献[7]中的DCBSRP算法进行性能对比。
RL-SDWSN算法使用学习算法,考虑到能源效率和网络服务质量,根据获得的奖励情况确定下一步的行动,从而提高WSN的网络性能。DCBSRP算法选择不同的节点充当簇头节点,使用能量高的节点执行收集和转发任务,从而提高无线传感器节点的寿命和性能。每个算法在同一实验环境下分别运行了300轮。
从图3中可以看出,随着训练次数的增加,RDIS的分组延迟持续减小。在RDIS训练到69轮、RL-SDWSN训练到95轮后,二者的分组延迟都变化缓慢且趋于稳定,RDIS的延迟更低。这是因为RDIS可以根据流量大小动态地选择转发路径,并通过与环境的交互,找到近乎最优的策略,不断提高路由决策的水平。DCBSRP由于一开始就确定了路由路径,在后续流量增大的情况下,容易导致链路拥塞,分组延迟稍高于其他两种算法。
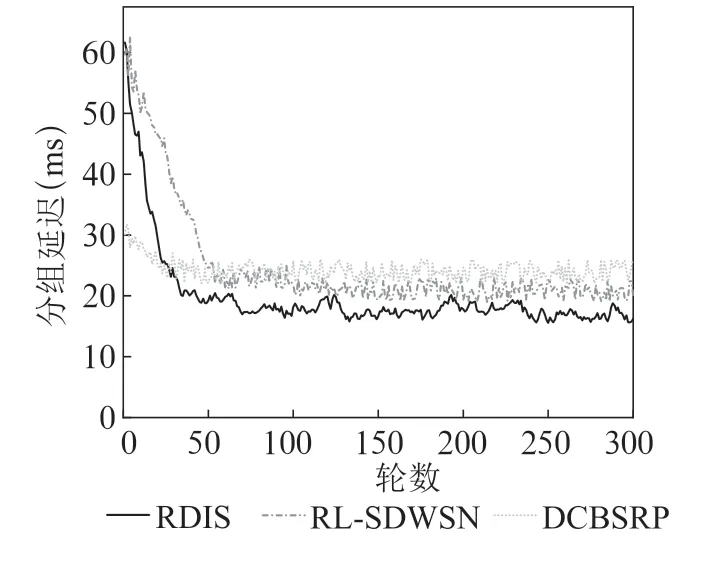
图3 分组延迟对比
图4展示了同一环境下三种算法的吞吐量对比,吞吐量定义为控制器接收到的数据包总数。
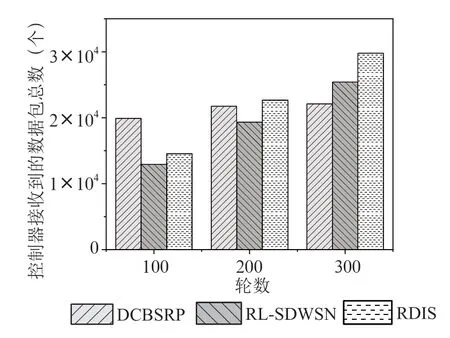
图4 吞吐量对比
从图4中可以看出,一开始与DCBSRP相比,RDIS和RLSDWSN没有明显的优势。这是因为流量较小时,网络不会出现拥塞,DCBSRP计算的路径对路由数据流非常有效。但是DCBSRP在高流量负载下会严重导致低效的带宽分配。在流量逐渐变大的过程中,RDIS可获得最大的网络吞吐量,具有明显的优势。RDIS的吞吐量高于RL-SDWSN下的吞吐量,性能更好。
3 结 论
本文提出了一种无线传感器网络中基于DDPG的智能路由算法,以便在应用服务质量要求提高的情况下,通过优化路由路径使整体网络性能接近最优。具体来说,RDIS从控制器中获得网络流量信息,根据网络需求和环境条件,提出了具有分组延迟和吞吐量的效用函数,通过不断的迭代来优化网络性能,通过与网络环境互动,根据自己的经验做出更好的控制决策,实现最佳网络效用。RDIS通过提高吞吐量和降低分组延迟,实现了更好的网络性能。
