基于卷积神经网络模型的堆芯有效增殖因数预测方法研究
2022-08-11张海明张昊春
张海明,张昊春
(哈尔滨工业大学 核科学与技术研究所, 哈尔滨 150001)
反应堆堆芯参数的计算对核能系统的设计开发和安全验证有重要作用。在反应堆物理计算中,常采用数值方法对中子扩散方程进行近似求解,主要是用一组确定的数学物理方程,建立起描述实际问题的数学模型,并采用数值离散方法求出这些方程的近似解[1]。随着反应堆工程技术的发展,对反应堆物理计算的要求不断提高,传统的中子扩散方程求解方法存在计算时间长及所需存储空间较大等问题[2]。因此,对如何快速、准确求解扩散方程方面的相关研究十分必要。
目前,许多传统机器学习模型已应用于核领域。深度学习作为人工智能的一个高级领域,近年来已广泛应用于堆芯换料参数的快速预测[3]、核素含量预测[4]和堆芯功率预测[5]等问题。但以往的研究普遍基于传统的全连接神经网络,存在学习参数多,组件编码的大小和形式显著影响神经网络的训练及预测精度,组件类型较多时编码形式将变得异常复杂等问题。同时,全连接神经网络还存在参数冗余和忽略位置信息等缺陷[6]。卷积神经网络(convolution neural network, CNN)作为一种可处理类网格结构数据的模型[7],有效地解决了全连接神经网络的缺点,广泛应用于图像识别、文档分析和语言检测等领域[8-9]。
本文提出基于CNN的深度学习模型进行预测有效增殖因数的方法。通过核反应堆堆芯数值模拟程序,计算不同组件截面参数对应的有效增殖因数,将这些数据作为原始数据用于建立深度学习模型。将1/4堆芯组件截面参数按照组件装载位置整合到一个信息矩阵中,将得到的原始数据进行归一化后采用CNN模型进行训练,最后得到替代数值计算方法的深度学习模型,用于预测具体堆型的堆芯有效增殖因数。
1 参数预测方法及原理
1.1 数据来源
在反应堆堆芯物理计算中采用 “中子数守恒”或“中子数平衡”原理[1],以双群扩散理论为例,各参数满足方程
(1)
其中:D1、D2分别为快群和热群的扩散系数, cm;φ1、φ2分别为快群和热群的中子注量率, cm-2·s-1; ∑R1、 ∑R2分别为快群和热群的消失截面, cm-1;χ1和χ2为快群和热群裂变能谱;k为有效增殖因数,S为源项; ∑S,1→2为快群到热群的散射截面, cm-1。
本文研究对象是一个简化的2群压水反应堆(pressurized water reactor, PWR)问题,堆芯共有177盒燃料组件,组件的几何尺寸为20 cm×20 cm,堆芯呈1/4对称分布。图1为堆芯结构示意图。其中,堆芯布置了3种不同富集度的燃料组件,所有组件均采用等效均匀化的参数,通过有限差分方法编制Python堆芯数值模拟程序计算堆芯参数。
1.2 卷积神经网络
CNN一般指带有卷积运算的深度神经网络[10]。常用的卷积运算有1维、2维和3维等形式。图2为本文所采用的CNN结构,包括输入层、卷积层、池化层、全连接层及输出层。一个完整的CNN一般会采取多个卷积层与池化层交替设置,即一个卷积层连接一个池化层,池化层后再连接一个卷积层,依此类推。
卷积层由多个特征面(feature map)组成,每个特征面由多个神经元组成,每个神经元通过卷积核与上一层特征面的局部区域相连。卷积核是一个权值矩阵[11-12]。CNN的卷积层通过卷积操作提取输入的不同特征,池化层紧跟在卷积层之后,同样由多个特征面组成,每一个特征面与上一层的一个特征面唯一对应,不会改变特征面的个数。
池化层起到二次提取输入值特征的作用,它的每个神经元对局部接受域进行池化操作[13]。经多个卷积层和池化层后,连接全连接层。全连接层由1个或多个隐藏层组成,隐藏层中的每个神经元与前一层的所有神经元进行全连接。全连接层可整合卷积层或池化层中具有类别区分性的局部信息。为提升CNN性能,全连接层每个神经元的激励函数一般采用ReLU函数。最后一层全连接层的输出值被传递给一个输出层[14]。
CNN具有局部连接、权值共享、池化操作及多层结构的特点[15],能通过多层非线性变换,从数据中自动学习其特征,从而代替手工设计的特征,且深层的结构使它具有很强的表达能力和学习能力。
1.3 数据处理
在堆芯物理参数计算中,组件截面参数包括热群及快群的平均裂变中子数、散射系数、移出截面、裂变截面、反照率、快群到热群的转移截面及裂变能谱7个参数。
本文选取这7个特征参数作为CNN输入物理量,有效增殖因数作为输出物理量。通过Python堆芯数值模拟程序随机生成2 000个独立的方案,获得数据集K={S1,S2,…,S2 000}。以其中1个方案Sn为例,CNN模型所用的数据预处理过程,如图3所示。由图3可见,为保留堆芯组件位置信息,按照1/4堆芯横截面的形状将组件截面参数放入8×8的矩阵方格内,每个方格为3×4的矩阵,填入每个组件的12个参数,无数据的空白处均设置为0,最终将Sn整合为一个24×32的特征矩阵,作为CNN模型的一组输入值,特征矩阵对应的有效增殖因数作为该组数据的输出值。按照4∶1的比例将2 000组数据划分为训练集和测试集。其中,训练集用于神经网络的训练,测试集用于模型泛化能力的评估。
原始数据集中存在量纲因素的影响,为加速神经网络训练及优化模型拟合,需对所有数据做归一化处理[16]。数据归一化处理只对数据的数值进行变换,数据的输入格式保持不变,原始数据归一化后的取值公式为
(2)
其中:x为原值;xmax为特征最大值;xmin为特征最小值。
1.4 建立模型
在整个CNN模型建立过程中,为避免在特征学习过程中出现梯度消失及神经元饱和的状况,将所有激活函数均设置为ReLU函数。原始数据经卷积及池化操作后得到多个信息矩阵,然后把每个特征矩阵进行扁平化处理,将得到的1维数据输入到全连接层。全连接层含有3个隐含层,为使计算机充分利用资源,全连接层3个隐含层神经元的个数分别为228,228,100,输出层含有一个神经元,用于实际值的回归。
CNN网络模型采用信号前向传递和偏差反向传播的方式进行训练,反向传播中采用的损失函数为均方偏差,可表示为
(3)
其中:ypi和yri分别为第i个样本的模型预测值和实验测定值;N为样本个数。通过不断调整每一层的权值和偏置值使σMSE值达到最小。采用Adam算法[17]对模型进行优化更新。Adam算法是一种自适应学习速率的算法,通过计算梯度的1阶矩和2阶矩估计来控制模型更新的方向和学习速率。
2 模型训练及结果分析
2.1 模型训练
将归一化处理的数据导入CNN模型中,可得到CNN模型的训练曲线,如图4所示。由图4可见,学习曲线在最初下降十分迅速,之后随着训练次数的不断增加,学习曲线逐渐趋于平稳,在200次训练后,模型达到最佳状态。
在CNN模型中,卷积层层数、训练批次B及学习率ε均能影响模型预测性能。本文分2种情况讨论这些因素对模型预测性能的影响。
(1) 在使用相同数据进行建模的情况下,分别采用3种不同卷积层数的CNN模型进行训练,训练曲线如图5所示。由图5可见,3种层数的模型在预测速度方面无明显差异,但3层卷积层的CNN模型比其他2种模型学习曲线更平滑,因此,本文选用具有3层卷积层的CNN模型对样本进行训练学习。
(2) 在确定卷积层数的情况下,不同ε与B的CNN预测模型的σMSE与平均绝对偏差σMAE,如表1所列。σMSE和σMAE是衡量模型的预测精度的参数,σMSE与σMAE越小,说明预测模型的性能越好,反之则越差。由表1可知,在CNN预测模型中,训练批次B=32,学习率ε=10-3时,预测模型的σMSE为2.48×10-4,σMAE为1.25×10-2,模型的预测效果最好。

表1 不同ε与B的CNN预测模型的参数Tab.1 CNN prediction model parameters with different ε and B
根据以上对于CNN模型卷积层数、B大小及ε的分析,最终得到一套最优的CNN模型结构参数,如表2所列。采用Tensorflow2.0框架和Python编程语言建立CNN预测模型,并进行CNN预测模型的训练。
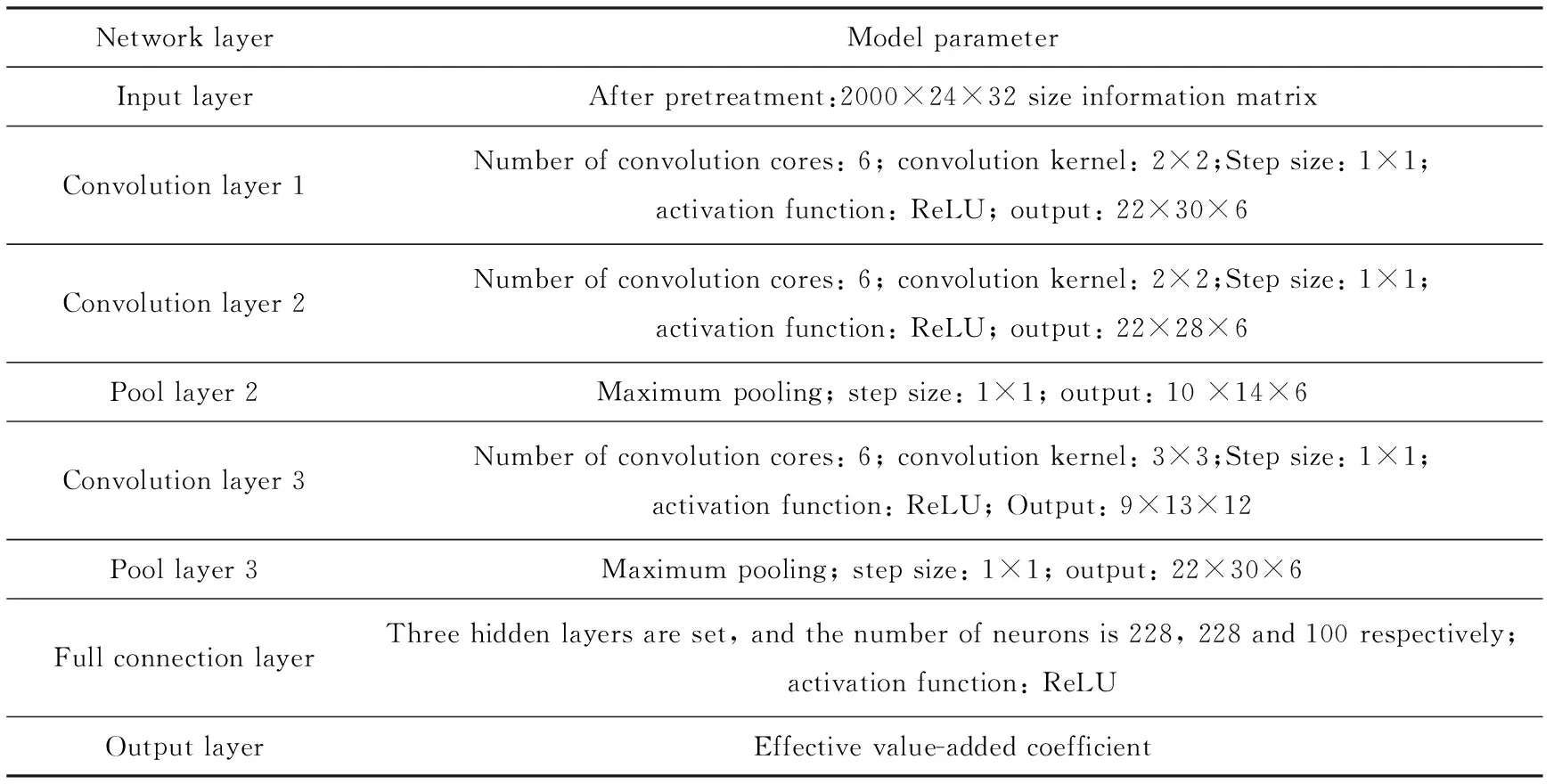
表2 模型结构参数Tab.2 Model structure parameters
2.2 结果分析
本文将2 000个有效数据样本按照4∶1的比例划分为训练集和测试集,按具有相似的统计特性的规则,将数据随机划分为训练集和测试集。训练集中的1 600个样本数据用于建立CNN预测模型,交叉验证也包含在其中;测试集中400个样本数据用于检验模型的预测性能。为验证CNN预测模型的预测性能,采用反向传播神经网络(back propagation neural network, BPNN )模型对数据集进行了训练与测试。BPNN与CNN预测模型分别将这些样本数据进行了5次重复训练与测试并取平均值。
BPNN与CNN预测模型预测精度对比,如表3所列。由表3可知,CNN模型的σMSE和σMAE明显小于BPNN模型,这表明CNN预测模型在预测本文建立的数据样本时的性能要明显优于BPNN模型。
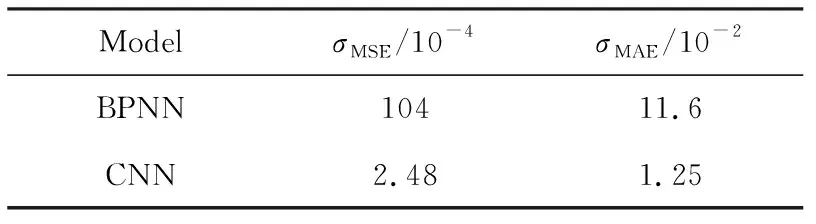
表3 BPNN与CNN预测模型预测精度对比Tab.3 Comparison of prediction accuracy betweenBPNN and CNN prediction models
图6为CNN预测模型的训练曲线。由图6可见,在训练次数小于50时,测试集数据的σMSE稍高于训练集数据的σMSE,随着训练次数的增加测试集与训练集的σMSE趋于稳定并重合。这表明,模型不存在过拟合及欠拟合情况,模型对数据的拟合程度较好。
图7为CNN预测模型对测试集样本有效增殖因数进行预测时,预测值与真实值相对偏差统计分布。
由图7可见,在CNN预测模型的预测结果中,几乎所有样本预测值的相对偏差都小于1%;90%样本预测值的相对偏差小于0.6%;50%样本预测值的相对偏差小于0.2%;测试集样本预测值的平均相对偏差为0.251%。因此,CNN预测模型对堆芯参数的预测具有较高的预测精度,预测可靠性较好。
3 结论
本文针对简化的2群PWR问题,建立了组件截面数据库,开发了基于CNN的预测模型。在经过训练的CNN预测模型中,输入燃料组件截面参数可快速预测有效增殖因数。通过BPNN与CNN预测模型预测结果的对比发现,CNN预测模型性能要明显优于BPNN模型。CNN预测模型预测结果平均相对偏差为0.251%,表明CNN预测模型预测精度高,可靠性好。本文在2维双群扩散方程求解的应用方面证实了CNN预测模型的可行性,可为传统堆芯物理分析问题提供新的求解理念。
