基于决策树和混合神经网络的大数据攻击增量检测研究
2022-08-10谭继安
谭 继 安
(东莞职业技术学院 广东 东莞 523808)
0 引 言
随着5G时代的到来,信息网络已深入国民经济的各个环节,物联网技术的发展也将人、物及商业进行了互联。随着物联网技术在医疗、智能家居、智能穿戴等领域的普及,物联网每日采集海量的数据,传统的网络安全机制则难以负担海量的数据分析[1]。近年来深度学习技术在网络安全领域取得了卓越的成果,但大数据的攻击检测问题是一种典型的不平衡数据分类问题,传统的深度学习技术在此类场景下容易发生过拟合[2]。另外,大数据每天流入大量的新数据,而深度神经网络模型的训练效率较低,许多模型需要一天以上的训练时间[3],难以满足大数据实时攻击检测的需求。
近期许多研究者通过深度学习技术检测网络的攻击,文献[4]提出深度学习模型下多分类器的入侵检测方法,该方法利用深度信念网络提取低维的特征数据,在任意两类特征数据之间构建一个梯度提升树分类器,基于NSL-KDD数据集的仿真实验表明其实现了较好的性能。而NSL-KDD数据集的数据量依然较小,且仅包含DoS、Probe、R2L和U2R等攻击类型。与之相似,文献[5-7]等深度学习技术也在部分公开的小规模数据集上进行了验证实验,但难以判断其对于大数据的效果。
UNSW-NB15数据集[8]是近期一个测试入侵检测的数据集,该数据集包含了100 GB以上的真实网络流量数据。文献[9]将自编码器和前馈神经网络结合,用于UNSW-NB15数据集的入侵检测研究,该研究实现了较高的检测准确率,但是网络的训练时间较长。文献[10]将多层前馈神经网络在UNSW-NB15数据集上进行了实验验证,该网络出现了明显的过拟合现象,且计算效率较低。
综上所述,传统的深度学习技术在特征提取过程中容易出现过拟合的情况,并且计算时间较长。为了解决该问题,本文提出了新的深度神经网络模型,利用卷积神经网络提取流量数据的特征,利用长短期记忆网络(LSTM)学习特征之间的依赖关系,避免CNN发生梯度消失问题。对LSTM的连接设计了Dropout设计,一方面减少了特征关系学习过程的过拟合情况,另一方面也提高了网络的计算效率。为了支持大数据动态演化的特点,本文设计了基于决策树的增量学习模型,能够动态地对新流入的数据进行学习和预测。
1 混合深度神经网络设计
1.1 长短期记忆网络结构
LSTM[11]是一种循环神经网络结构,网络包含一个记忆单元和输入门、输出门和遗忘门三个控制门。输入门的数学式为:
it=σ(Wixt+Uiht-1)
(1)
遗忘门的数学式为:
ft=σ(Wfxt+Ufht-1)
(2)
输出门的数学式为:
ot=σ(Woxt+Uoht-1)
(3)
式中:σ为激活函数;W和U为权重矩阵;xt是在时间步t的输入向量。
在时间步t的记忆单元状态ct为:
(4)
(5)
式中:“×”表示矩阵按元素相乘。
在时间步t的隐层状态ht为:
ht=ot×tanh(ct)
(6)
LSTM通过记忆单元维护输入特征之间的依赖关系,输入门向记忆单元输入一个新元素,遗忘门控制删除记忆单元内的元素,输出门基于记忆单元的内容计算网络的输出。正切函数和Sigmoid函数是两个常用的激活函数。
1.2 权重正则化LSTM结构
设计了权重正则化的LSTM结构(Weight Regularization-LSTM,WRLSTM),提高网络的计算效率,并且防止过拟合。WRLSTM对LSTM的连接进行Dropout正则化处理,并未采用传统方案对输出单元进行Dropout处理,通过该方式可增加激活和输出向量的稀疏性。WRLSTM在训练阶段对LSTM的隐层权重进行随机Dropout处理,防止发生过拟合的情况。LSTM的输出可以总结如下:
yt=σ(Wxt+(M×U)ht-1)
(7)
式中:M是网络连接的二值矩阵掩码形式。在训练阶段通过修改M中的元素来更新每次迭代的网络连接Dropout状态。
1.3 CNN网络模型
CNN每个神经元的输出是一个关于输入、权重和偏置的函数,每一层权重的更新计算式为:
(8)
式中:wi为神经元i的权重;α和r分别为正则参数和学习率;n为训练样本总量;m为动量;t为迭代次数;C为成本函数。
每一层偏置的更新计算式为:
(9)
式中:bi为神经元i的偏置;α为正则参数;n为训练样本总量;m为动量;t为迭代次数;C为成本函数。
CNN卷积运算的计算式为:
(10)
式中:xi为输入向量;N为xi的元素数量;h为卷积层的filter;yi为输出向量;n为yi的元素数量。
CNN的池化层可降低卷积层的维度,从而减少计算成本且防止过拟合,本文采用最大池化机制。
1.4 CNN和WRLSTM的混合网络结构
为了同时利用深度CNN的特征学习能力及WRLSTM的记忆能力,将两个网络融合成一个高效的入侵检测模型。图1所示为混合深度神经网络(Hybrid Deep Neural Networks,HDNN)的结构。

图1 混合深度神经网络的结构
HDNN由两个卷积层、一个最大池化层、一个WRLSTM及一个全连接层构成,两个卷积层的激活函数均为ReLU,其计算式为:
σ(x)=max(0,x)
(11)
式中:x为神经元的输入。
最大池化层的输出传入WRLSTM层,WRLSTM学习所提取特征之间的依赖关系,随机失活部分的权重。最终WRLSTM的输出传入全连接层,全连接层通过Softmax激活函数将流量数据分类。Softmax激活函数计算了每个流量类别的概率分布,其计算式为:
(12)
式中:n为流量的类别数量;x为输入数据。
2 HDNN的增量学习模型
2.1 HDNN-tree的网络结构
图2所示为HDNN-tree的结构示意图,每个节点为一个HDNN。根节点将流量数据分类为正常或异常,然后再传入到下一层的节点,对数据类型进行深入的识别,最终在叶节点输出流量数据的类型。HDNN-tree的每个叶节点与一个唯一类别相关联。

图2 HDNN-tree的结构
2.2 增量学习算法

(13)
似然矩阵的计算式为:
(14)
然后将LK×M排序产生一个列表S,S的数据结构具有三点性质。性质1:S共有M个对象,每个对象和一个新类相关联。性质2:每个对象S[i]具有3个属性值:(1)S[i].label:新类的标签;(2)S[i].value:Softmax输出值的Top-3;(3)S[i].nodes:Top-3值对应的3个输出节点。性质3:列表S按S[i].value值降序排列。
列表S的排序处理保证了相似性最高的新类优先加入HDNN-tree,通过Softmax计算样本和类标签之间的似然,能够更好地识别新样本和已有类标签之间的相似度。然后对S的第1个元素S[1](相似性最高的新类)进行以下三个判断和操作:
假设v2是新类,v1和v3为已有类。
第1个判断:如果v1-v2>α,那么新类和子节点n1关联性较强,将新类加入n1中。
第2个判断:如果新类和多个子节点具有高相似度,那么将几个相似的节点组成一个新的子节点。数学模型为:如果v1-v2<α且v2-v3>β,那么将n2和n1合并,并将新类也将入n1中。
第3个判断:如果新类和所有子节点相似度均较低,那么网络为新类增加一个新的子节点。数学模型为:如果v1-v2<α且v2-v3<β,那么为新类创建一个新子节点。
算法1是增量学习算法的伪代码。图3所示为增量学习的一个实例,假设α=β=0.3,Chi4、Chi5和Chi6是三个新加入的节点。Chi4的v1-v2=0.95-0.26=0.69>0.3,因此Chi4加入Chi1;Chi5的v1-v2=0.2<α,且v2-v3=0.01<β,因此Chi5建立新节点;Chi6的v1-v2=0.93-0.18<α,因此Chi6加入Chi2。
算法1增量学习算法。
输入:似然矩阵L,每个分支的最大子节点数量maxchi,根节点Rnode,新节点node。
1.S←createS(L,node,maxchi);
//创建S列表
2.whileS!=NULL do {
3.[classlabel,value,node]←S[1];
//提取S[1]属性
/*第1个判断*/
4.if (value[1]-value[2]>α) {
5.Rnode=inserttonode(Rnode,classlabel,node[1]);
//将新类加入node[1]
/*第2个判断*/
6.} else if (value[2]-value[3]>β){
7.mergenode(Rnode,node[1],node[2]);
/*第3个判断*/
8.} else {
9.Rnode←addnewnode(Rnode,classlabel);
10.}
/*重新创建S*/
11.S←createS(L,node,maxchi);
10.}
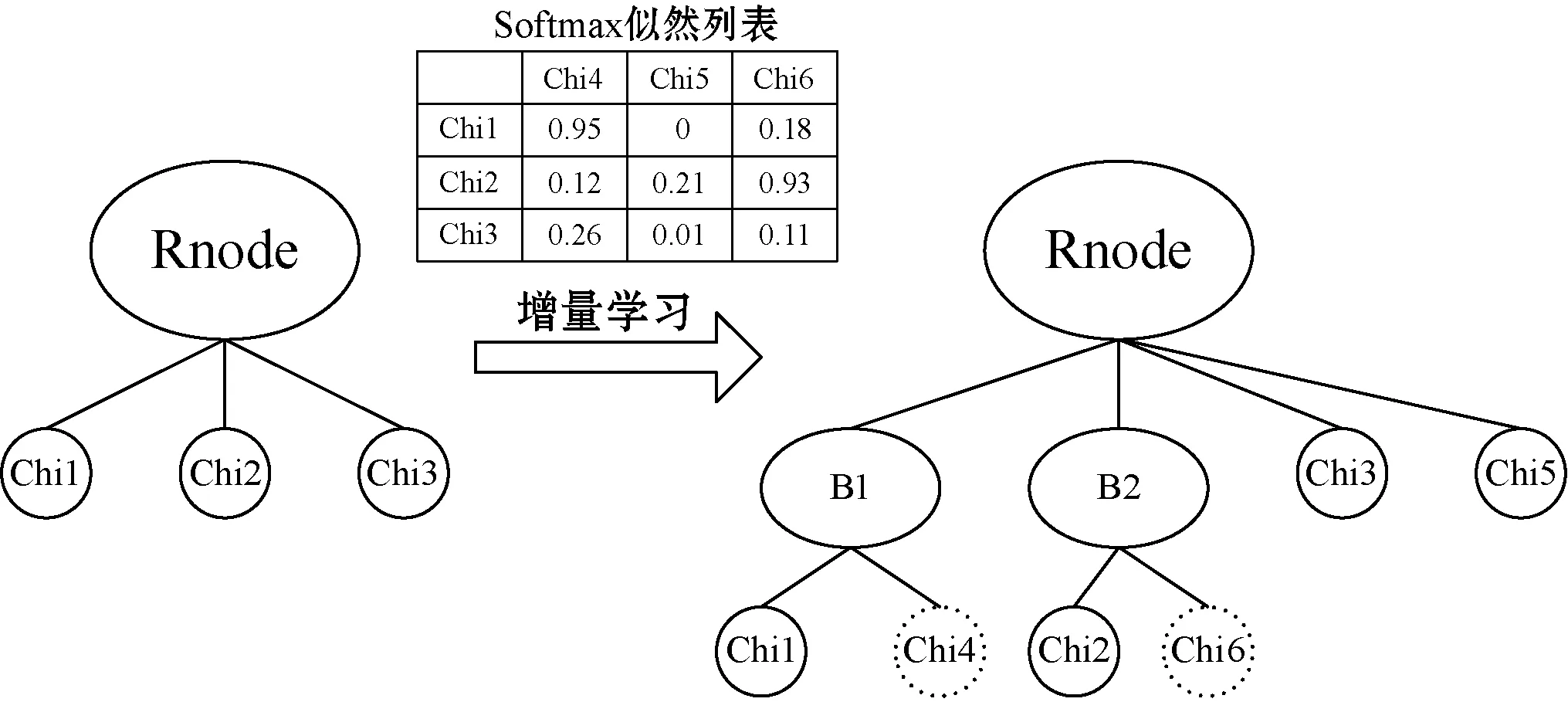
图3 增量学习的实例
在创建HDNN-tree的过程中,如果根节点的分类数量达到了最大子节点数量,那么增加HDNN-tree的深度,每个深度所支持的最大子节点数量和tree的最大深度由用户根据实际应用场景所设定,在本文系统中,根节点最大子节点数量为2(正常用户类和异常用户类),其他层的最大子节点数量为15,树的最大深度为2。
当系统为新类分配了一个节点位置时,通过梯度下降法训练受影响的节点,该机制避免了重新训练全部的网络,并且这部分的训练处理可以离线完成,并不影响树中其他HDNN的工作。在初始化阶段,首先利用可用的数据训练根节点,在之后的增量学习过程中,仅在根节点将输入数据分配到特定分支的时候,该分支才被激活,因此不仅提高了流量检测的精度,同时也保持了较低的处理时间。如果某个节点发生分类错误,那么该分支会为该类分配一个新节点,因此并不会影响已有节点中神经网络的训练。
3 仿真实验与结果
3.1 实验数据集
UNSW-NB15数据集是Moustafa研究小组收集的一个大规模IDS实验数据集,该数据集包含了100 GB以上的真实网络流量数据。该研究小组使用自动攻击生成工具Perfect Storm[12]对几个目标服务器进行真实的攻击。数据集共包含2 540 044个标记样本,共有九种攻击类型,分别为:漏洞攻击、DoS攻击、后门攻击、分析攻击、渗透攻击、通用攻击、侦察攻击、Shellcode注入攻击、蠕虫病毒。
将UNSW-NB15数据集中空记录删除,最终筛选出2 273 332个样本,按照7 ∶3的比例将数据集分为训练集和测试集。表1所示为实验数据集的统计信息,表中显示网络流量的数据为不平衡分类,正常流量远多于攻击流量,因此传统的机器学习分类器极易发生过拟合的情况,本文设计了HDNN结构来缓解过拟合,并且提高计算效率。

表1 实验数据集划分情况

续表1
为了兼容本文的神经网络模型,将流量的特征由名词转化成独立的编号数值,然后对数值进行归一化处理,归一化的计算式为:
(15)
式中:fi,j表示数据矩阵在(i,j)位置的值。
3.2 性能评价指标
通过以下4个广泛应用的性能指标评价HDNN-tree的性能。
准确率A的计算式为:
(16)
式中:TP表示将正类预测为正类的数量;TN表示将负类预测为负类的数量;FP表示将负类预测为正类的数量;FN表示将正类预测为负类的数量。
精度P的计算式为:
(17)
召回率R的计算式为:
(18)
F1-score的计算式为:
(19)
3.3 实验方法
因为本文针对大数据攻击检测问题提出了新的深度神经网络结构HDNN,所以通过第1组实验评价HDNN的性能,然后设计了第2组实验评价增量学习方法HDNN-tree的有效性。
3.4 HDNN的性能实验
1) HDNN的参数设置。HDNN的参数包括filter数量、epoch数量、学习率、WRLSTM隐层单元数量、dropout率p,批大小和最大池化长度。首先通过试错法训练HDNN,最终的网络参数确定如下:epoch数量为40,学习率为0.004,输出层大小为30,LSTM的dropout率p为0.2。第1个和第2个卷积层的filter数量分别为32和64,核大小为3,最大池化长度为2。
2) HDNN的性能结果。首先测试了本文模型对于异常流量的检测能力,图4(a)所示为模型所检测正常流量和异常流量的ROC曲线,正常流量的ROC区域为0.92,异常流量的ROC区域为0.91,可以看出本文模型对于大规模数据依然实现了较高的检测效果。图4(b)所示为模型所检测正常流量和异常流量精度、召回率和F1-score的性能,对正常流量、异常流量的检测精度均高于0.95,对正常流量的召回率较高,但对异常流量的召回率略低。总体而言,本文模型对于大数据集实现了较高的异常流量检测性能。

(a) ROC曲线
然后分析了本文模型对于异常流量的细粒度识别能力,图5(a)所示为模型所检测的不同异常流量类别的ROC曲线,后门攻击、蠕虫病毒和分析攻击的ROC区域分别为0.54、0.56和0.57,这三种攻击类型的特征显著性较低,隐蔽性较强,因此对于这三种攻击的识别效果不足。本文系统对于漏洞攻击、渗透攻击、通用攻击、侦察攻击及Shellcode注入攻击均实现了较好的识别效果,ROC区域均超过了0.8。图5(b)、(c)、(d)分别为模型所检测的不同异常流量类别的精度、召回率及F1-score的性能。和ROC曲线的结果相似,后门攻击、蠕虫病毒和分析攻击的识别效果较差,另外对于DoS攻击的识别精度也较低。但本文系统对于漏洞攻击、渗透攻击、通用攻击、侦察攻击及Shellcode注入攻击均实现了较好的识别效果,精度、召回率及F1-score均超过了0.6。

(a) ROC曲线
3) 对比实验分析。选择了5个近年来性能较好的大数据异常流量检测算法与本文模型对比,分别为基础CNN[13]、GoogLeNetInceptionCNN[14]、LSTM[15]、GRU[16]、AL模型[17]。因为本文模型是CNN和LSTM的混合网络,所以通过基础CNN和LSTM可以判断本文模型是否有效。GoogLeNetInceptionCNN和GRU是两个不同类型的深度学习模型。AL是一种自学习的非神经网络模型,该模型的优势是计算速度较快。
因为上述5个对比方法中主要提供了对于UNSW-NB15数据集的准确率结果,所以在此也主要比较了6个检测算法的准确率指标,如图6所示。可以看出GoogLeNetInceptionCNN和GRU均实现了较高的检测准确率,且5种深度神经网络模型的准确率均高于90%,仅AL模型的准确率略低于90%,由此可见深度神经网络对于大规模不平衡数据的检测性能较好。此外,本文模型的检测准确率高于基础CNN和LSTM,本文模型通过对神经网络连接的dropout处理,缓解了深度神经网络的过拟合,从而提高了对不平衡数据的分析效果。

图6 异常检测算法的准确率指标
本文的实验环境为PC机:Intel i7- 9700 6核心处理器,16 GB内存,操作系统为64位 Windows 10。本文模型通过对神经网络连接的dropout处理,缓解了深度神经网络对大规模不平衡数据的过拟合问题,也提高了模型的计算效率。图7所示是6个检测算法对每个流量样本的平均分类时间,GoogLeNetInceptionCNN采用GoogLeNet模型实现了多级CNN的深度网络结构,因此计算效率较低。AL模型则是一种基于核函数的自动学习模型,该模型的计算效率较高,平均处理时间达到了0.003 ms左右,而本文模型的处理时间略低于AL模型,实现了最快的检测速度。

图7 每个样本的平均处理时间
3.5 增量学习的性能实验
实验数据集的2 273 332个样本筛选出一半数据作为初始化数据集,并且初始化数据集中仅包含一部分漏洞攻击、DoS攻击和后门攻击的数据,其他均为正常数据。剩余的一半样本随机分成6个大小相等的子数据集,将子数据集依次输入HDNN-tree进行识别,统计每个子数据集的识别准确率。图8所示是增量学习的HDNN-tree演化示意图。

图8 增量学习的HDNN-tree演化示意图
图9所示为每次输入子数据集的平均识别准确率结果,可以看出50%数据集的识别准确率约为78%,随着增量加入新的子数据集,模型的识别准确率得以提升,最终达到约95%。增量学习的模型性能始终低于静态训练的模型。主要原因在于增量学习过程中仅受到影响的分支被重新训练,未受影响的分支保持固定,所以影响了整体模型的识别性能,但是实现了增量学习的目标。

图9 增量学习的平均识别准确率
4 结 语
为了提高大数据攻击检测的准确率和效率,通过卷积神经网络提取数据的特征,然后基于长短期记忆网络学习所提取特征之间的依赖关系,防止出现梯度消失问题。针对LSTM的连接设计了dropout设计,一方面减少特征关系学习过程的过拟合情况,另一方面也提高了网络的计算效率。最终,设计了基于决策树的神经网络增量学习算法,能够识别出数据的细粒度类标签。实验结果表明,混合神经网络有效地缓解了过拟合问题,并提高了模型的计算效率,同时也验证了增量学习的有效性。增量学习的神经网络模型准确率随着数据集的增加而提升,最终达到约95%,并且本文模型处理每个样本的时间约为0.002 3 ms,有利于大数据的实时攻击检测。
