重要Tor暗网站点的验证码快速识别和数据采集
2022-08-10王轶骏
龙 军 王轶骏 薛 质
(上海交通大学电子信息与电气工程学院 上海 200240)
0 引 言
洋葱路由(The onion route,Tor)通过采用不定数量节点、不定路由建立通信链路,并且在通信过程对通信数据进行层层加密,使得每一个洋葱节点只知道自己的前一个节点和后一个节点,从而保证数据通信过程的隐蔽、匿名和防溯源等特性[1]。由于Tor暗网的这些特性,里面充斥着许多违法犯罪行为。例如,2019年1月13日,暗网中文论坛Deepmix上一名ID为Itaiwanses的卖家在出售近1.3 GB的中国航空客户信息数据[2],其中包含了用户的各种敏感信息。文献[3]指出,2018年是数据泄露的灰色之年,而暗网(主要是Tor暗网)成为了贩卖泄露数据的主要渠道。
于浩佳等[4]提出了一种通过Scrapy框架接入Polipo服务器,再结合tor浏览器进入到Tor暗网中的方法,对Tor暗网网页进行爬取。汤艳君等[5]利用Selenium工具及相关代理进入到Tor暗网,对Tor暗网网页进行爬取。但是以上方法爬取的站点都是简单的网页,没有验证码机制,不需要绕过人机交互,而目前的重要Tor暗网站点基本都采用了验证码机制。因此,上述方法都不适合对现有的重要Tor暗网站点进行自动化爬取。
研究表明,目前大型的Tor暗网站点都采用了验证码机制进行人机交互来抵抗分布式拒绝服务(DDoS)攻击和防止爬虫,特别是交易市场和黑色论坛[6]。针对目前重要Tor暗网站点的特性,本文通过对神经网络进行研究和实验来实现对相关验证码进行快速有效的识别,并且将其应用到Tor暗网站点的数据采集系统中去,实现自动化绕过验证码检验机制后爬取和存储站点的数据信息,从而能够有力地支撑暗网数据提炼、分析和挖掘的后续工作,对于监控暗网空间资源、获取威胁情报信息、感知网络安全态势具有重大意义。
对于一个特定的Tor暗网站点,验证码识别工作包括样本收集、样本标记和神经网络的设计与训练等工作,最后得到一个有效的模型。但是鉴于Tor暗网站点的变化是不定的,它的验证码样式和存在状态是随时可能发生变化,所以每一个Tor暗网站点的验证码识别工作花费的时间不能太长。针对于Tor暗网站点的这个特性,本文的最主要研究内容为设计实现一个能够使用少量验证码样本来训练的神经网络模型,并且该模型训练完成后能够快速有效地对验证码进行识别。设计实现Tor暗网站点的数据采集系统来实时、准确地采集相应站点的数据信息是另一项研究内容。最后将验证码快速识别模型应用到Tor暗网站点的数据采集系统,实现一套自动化的Tor暗网站点数据采集系统。
1 神经网络模型
实际调查表明,基本所有的重要Tor暗网站点所采取的验证码机制是由数字或者英文字母或者两者混合组成的文本验证码。程舟航[7]提出了一种端到端的文本验证码识别方法,结合CNN、RNN和Attention机制设计实现一个神经网络模型,通过使用大量标记好的样本进行训练得到了一个识别准确率可观的验证码识别模型。文献[8]提出了一种基于生成式对抗网络(GAN)的验证码识别模型,通过使用一定量的样本训练一个能够生成与样本非常相似的验证码的GAN模型,然后通过GAN模型自动生成大量样本来训练一个CNN网络,再用一定量的原始验证码进一步训练来修正这个CNN网络,最后能够得到一个识别准确率可观的验证码识别模型。但是上述第一种研究方法需要大量的样本和一定的机器资源,第二种方法需要一定量的样本、足够的机器资源及多次的实验,因此都需要花费大量的时间,不适合Tor暗网站点数据采集中的验证码识别工作。
结合文献阅读和相关实验,本文提出了一种结合CNN网络、门控循环单元(GRU)网络及ctc(Connectionist Temporal Classification)loss的神经网络模型,实验结果表明该模型能够在使用少量验证码样本进行训练的情况下达到可观的识别准确率。该网络模型的结构如图1所示。
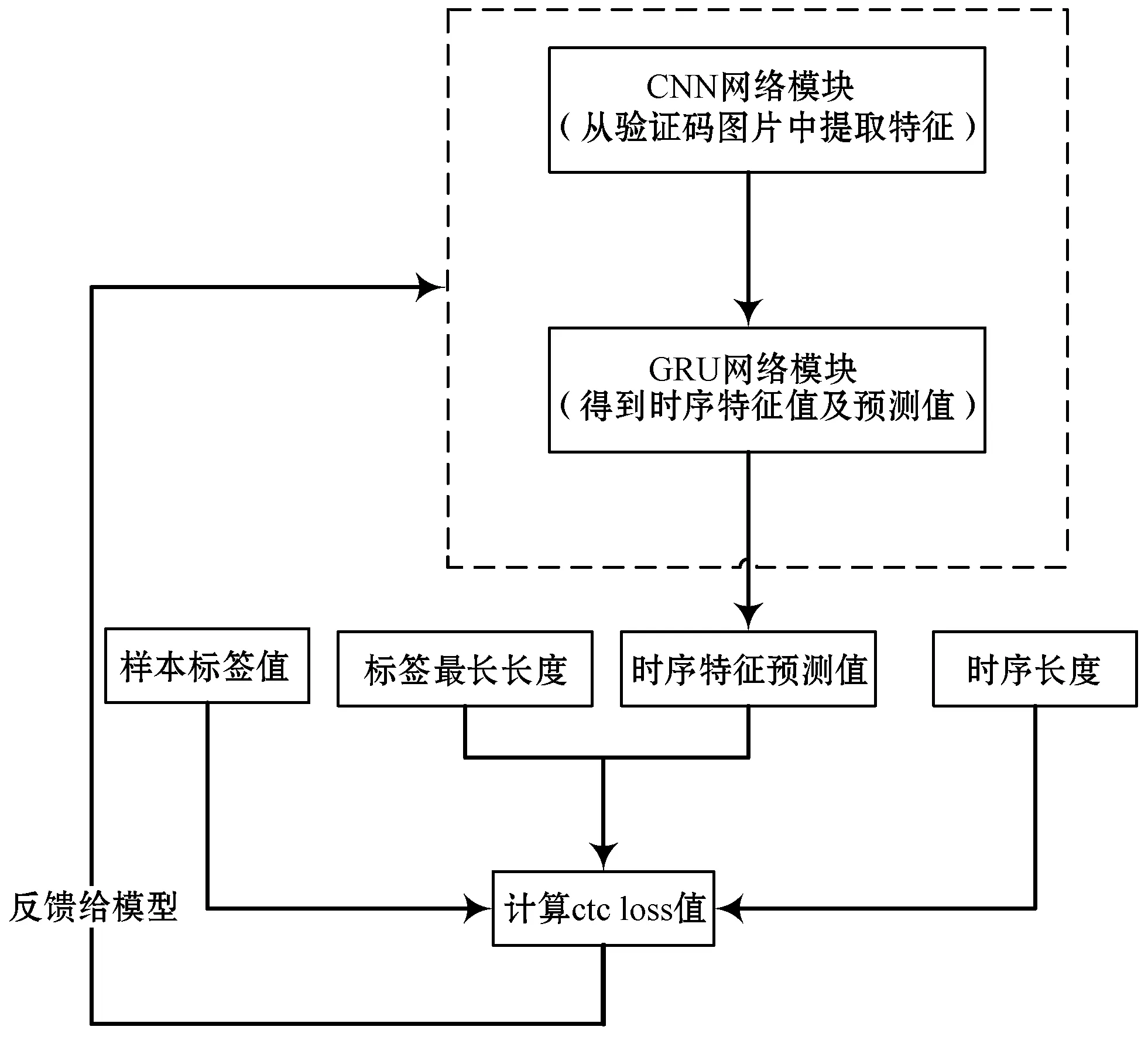
图1 网络模型整体结构图
1.1 CNN网络模块
在整个神经网络模型中,CNN网络模块的作用是从验证码图片中提取特征,将每一幅验证码图片转化为相应维度的特征值。
本文在设计CNN网络模块时借鉴了VGG[9]分类模型,整个CNN网络模块由五层子模块串联而成,每一层子模块包含了两层卷积层和一层池化层,卷积层中包括了卷积操作、批量正则化操作,并且使用了ReLU函数作为激活函数;池化层的参数需要根据验证码图片的宽度来设计,要使得经过CNN网络模块提取的特征再经过GRU网络模块后得到的时序特征长度不能太长。每层子模块的网络结构如图2所示。
1.2 GRU网络模块
GRU网络模块首先将CNN网络模块提取的特征转化为时序特征,再对得到的时序特征进行预测,计算出一个时序特征预测值,这个值的长度要大于样本标签值的最长长度。
本文设计的GRU网络模块由置换层、时序平滑层、两层GRU层及Dense层组成,其中置换层可以改变特征维度的顺序,本文的GRU网络模块中通过置换层将第一维的特征与第二维的特征交换顺序;时序平滑层将特征转化为时序特征;GRU层是一种特殊的RNN层,在原本的RNN层的基础上引入重置门和更新门,从而能够有效避免训练过程中参数消失和参数爆炸的情况;Dense层对经过GRU层得到的特征进行分类计算出一个长度为时序特征长度的预测值,这个长度大于样本标签值的最长长度。GRU网络模块的结构如图3所示。

图3 GRU网络模块结构图
1.3 损失函数ctc loss
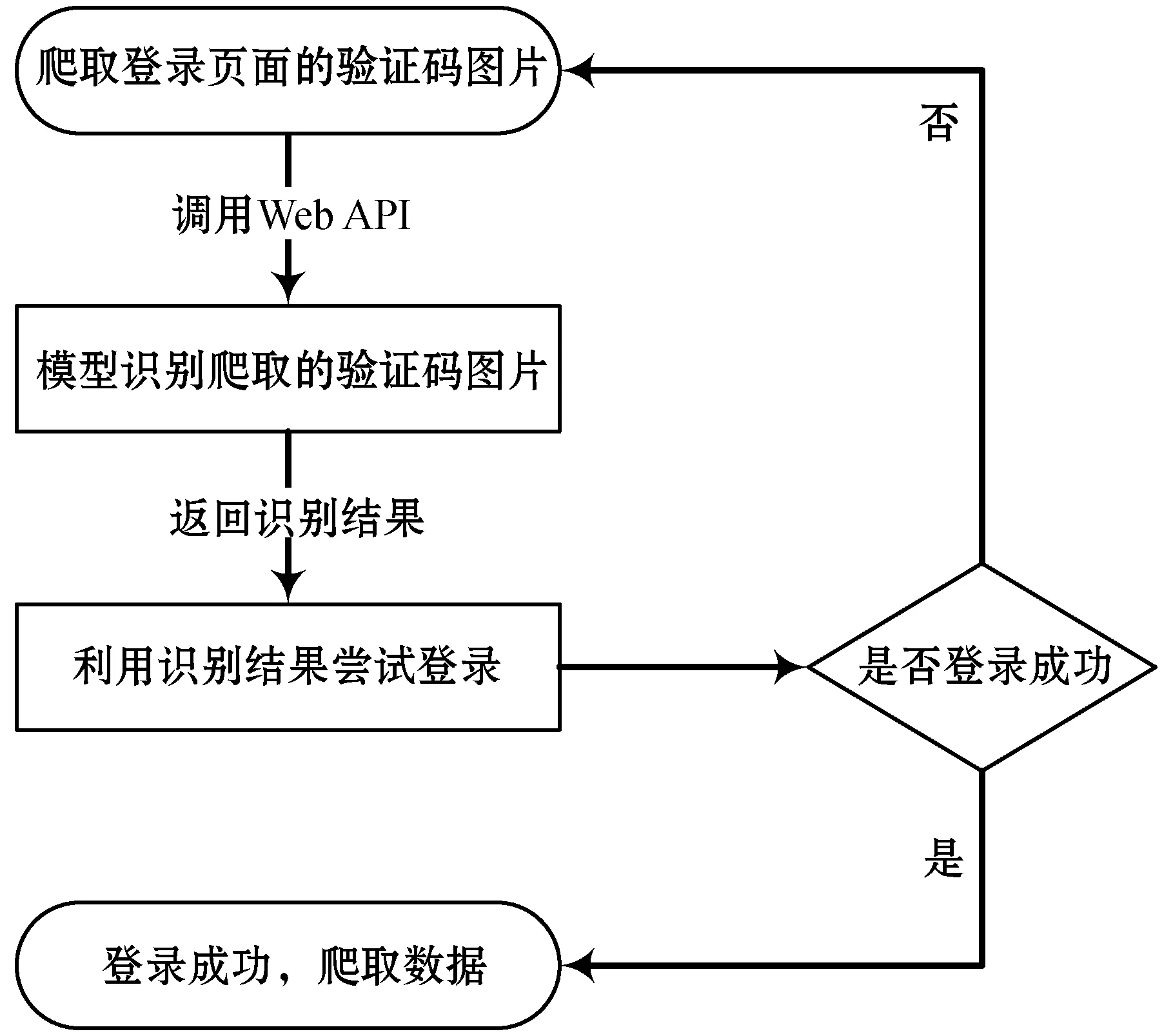
假设样本标签的取值空间为Z={z1,z2,…,zn},样本标签的最大长度为m。经过上述的CNN网络模块和GRU网络模块(Dense层之前),一幅验证码图片就变成了X=[x1,x2,…,xT]的时序特征,其中T表示时序长度,xi(0 ctc loss在原来的样本标签取值空间中加入了空符号,即变为Z={z1,z2,…,zn,_},其中_表示空符号。因为ctc loss的输入值长度大于输出值,所以会有多个输入值映射到一个输出值,映射的规则为连续的重复符号只保留一个,空符号去掉,这里称每一个映射为一条路径。对于t时刻,预测值为at(at∈Z)的概率为P(at|||xt),所以时序特征的预测值为A=[a1,a2,…,aT]的概率,如式(1)所示。 (1) 令Ay表示所有能够映射到样本标签值的时序特征预测值的集合,则预测后映射能够得到正确的样本标签Y的概率值如式(2)所示。 (2) 训练过程中ctc loss的损失函数则为式(2)所示的概率值的负对数。但是随着时序长度T的增加,能够映射到样本标签值的路径个数呈指数增长,ctc loss在计算过程中没有使用穷举法计算所有路径,而是借鉴了隐马尔可夫模型(HMM)中的前向后向动态规划算法[11],动态地计算式(2)中的值。假设样本标签值为AUUW,计算时首先在这个标签的前后及两两字符之间插入空字符变为_A_U_U_W_,令rt(s)表示t时刻预测的符号为扩展序列(_A_U_U_W_)的第s个符号,且到t时刻为止预测路径是正确路径的前缀的概率,则可以动态地计算rt(s)。如图4所示,通过前向概率动态计算rt(s)分为三种情况(通过后向概率计算类似)。 图4 ctc loss动态计算图 第一种情况,第s个符号为空白符号,如图4中的情况1所示,此时t=3,s=3,则t=2时只能是图4中圆圈1所标记的两种可能,所以r3(3)=(r2(3)+r2(2))×P_(3),其中P_(3)表示t=3时预测为空白符号的概率。 第二种情况,第s个符号等于第s-2个符号,如图4中的情况2所示,此时t=5,s=6,则t=4时只能是图4中圆圈2所标记的两种可能,所以r5(6)=(r4(6)+r4(5))×PU(5),其中PU(5)表示t=5时刻预测为符号U的概率。 第三种情况为其他情况,即不属于上述两种情况,如图4中情况3所示,此时t=4,s=4,则t=3时只有图4中圆圈3标记的三种可能,所以可得r4(4)=(r3(4)+r3(3)+r3(2))×PU(4),其中PU(4)表示t=4时刻预测为符号U的概率。 所以可以利用动态规划算法计算rt(s),其中seq表示扩展后的序列(示例为_A_U_U_W_),seq(s)表示seq序列中的第s个字符。 (1) 初始条件r1(1)=P_(1),r1(2)=Pseq(2)(1),r1(s)=0,其中s>2。 (2) seq(s)为空字符或者seq(s)=seq(s-2),如式(3)所示。 rt(s)=(rt-1(s)+rt-1(s-1))×Pseq(s)(t) (3) (3) 其他情况如式(4)所示。 rt(s)=(rt-1(s)+rt-1(s-1)+rt-1(s-2))× Pseq(s)(t) (4) 则式(2)中的P(Y|||X)=rT(L),其中L表示seq的长度。 对于上述的神经网络模型,本文在实际过程中对18个重要Tor暗网站点进行测试,其中大部分为售卖违法商品的Tor暗网交易市场,还有几个Tor暗网黑色论坛。所测试的Tor暗网站点有部分目前已经被关掉了,这也说明了自动化的Tor暗网数据采集工作中快速识别验证码的重要性。 本文设计的所有验证码识别模型在训练过程中所使用的机器配置为Intel Core i5 2.3 GHz四核,8 GB内存,macOS Mojave系统。 测试过程中,对所有测试了的Tor暗网站点收集的样本量均为1 000到4 000之间,所收集的验证码样本数量与该Tor暗网站点的验证码复杂性有关。在模型训练之前,把对每一个Tor暗网站点收集的验证码样本分成三部分,一部分作为训练集,一部分作为训练过程的验证集,一部分作为测试训练完成后的模型的试验集来计算该模型的识别准确率。 所有进行测试的Tor暗网站点的模型测试结果及相关测试信息如表1所示。 表1 Tor暗网站点的模型测试结果 如表1所示,本文所设计的神经网络模型在少量验证码样本的训练下能够获得较高的识别准确率,全部站点都在60%以上,大部分站点在80%以上,甚至有的达到了90%以上。实际上,在Tor暗网的数据采集过程中,数据采集插件是可以进行多次的验证码识别和登录尝试,而其中只要成功一次即可。因此本文也针对每个重要Tor暗网站点,分别统计了在三次尝试以内至少能够成功一次的概率,结果表明绝大部分站点都在98%以上,而若干验证码样式比较复杂的Tor暗网站点也均在90%以上。因此,测试结果表明,将本文所提出的神经网络模型应用在重要Tor暗网站点的数据采集工作中,就能够进行自动的数据采集,而不是像以前需要人为干预。由于目前业界尚没有和本文类似的研究工作公开发表,基本上都还只是针对无验证码机制的简单Tor暗网页面进行的数据采集,因此本文没有也无须进行相关的功能和性能比较。这同时也表明本文在暗网空间资源监测领域获得了突破性的进展,具有较重大的意义。 该神经网络模型通过CNN网络模块和GRU网络模型得到一个比样本标签值更长的时序特征预测值,该预测值中能够包含空白符号,这相当于在特征层面对原有的验证码进行了切割,从而对每一个切割的部分进行识别,再通过ctc loss计算整体预测值的损失函数反馈给模型进行训练,这是该神经网络模型在少量验证码样本的训练下就能够得到一个识别准确率较高的识别模型的重要原因。 Tor暗网数据采集系统主要由三部分组成,分别是Tor内核传输模块、数据采集模块和数据存储模块,其中数据采集模块是整个系统的核心模块,结合使用了本文实现的神经网络模型来进行自动登录采集数据,整个系统的结构如图5所示。 图5 Tor暗网数据采集系统结构图 Tor内核传输模块使用Tor官方提供的tor软件,该软件可以提供一个能够进入到Tor暗网空间的socks代理。但是本文设计的数据采集插件对于socks代理的支持不稳定,因此本文使用了polipo服务器将socks代理转化为https代理,更稳定地支持数据采集插件的使用。本文参考文献[12]中Tor暗网空间资源探测的工作中的Tor提速手段,修改tor软件配置文件中的节点为平均节点速度高的国家的节点,提高数据采集模块的采集速度。 数据采集模块将数据采集插件与本文实现的验证码快速识别模型结合起来,从而解决数据采集插件遇到验证码无法自动识别后进行登录的技术难题,实现自动化的数据采集。 3.2.1数据采集插件 数据采集插件使用Scrapy爬虫框架设计实现,实现采集插件中最关键的两点是抵御相应Tor暗网站点的反爬措施及数据的去重增量爬取。本文通过控制数据爬取的速率与频率来抵御相应Tor暗网网站的反爬措施,并且设计为被反爬措施检测到进行人机交互挑战后数据采集插件从之前停止的地方继续重新爬取。对于去重增量爬取,数据量大的Tor暗网站点采用Bloomfilter去重,数据量较小的Tor暗网站点则直接在数据库中查询进行去重。 文献[13]指出,Bloomfilter是一种使用很长的比特串记录目标是否出现过的技术,其中比特位为1表示记录为出现过,0表示记录为未出现。最初的比特串全为0,判断过程中使用多个Hash函数将目标内容映射为多个数字用来表示在比特串中的索引,如果这些索引处全为1则表示该目标出现过,否则目标未出现过则处理目标并且将这些索引处全置为1。因此,使用Bloomfilter技术在爬取时进行去重能够极大地减少内存的使用,节省资源。 3.2.2验证码识别模型应用 在数据采集模块中,本文通过使用Python的Flask框架将所有训练好的验证码识别模型整合成一个Web系统,为每一个Tor暗网站点提供一个特定的Web API来自动识别验证码并且返回结果。爬取过程中识别相应验证码然后进行自动登录的流程如图6所示。 图6 Tor暗网站点自动登录流程图 当数据采集插件遇到登录页面时,首先将登录页面的验证码图片爬取下来,通过相应的Web API调用相应模型识别该验证码图片并且将识别结果返回给数据采集插件,插件利用识别结果尝试登录,再根据登录后的页面判断是否登录成功,如果登录成功则进一步爬取数据,登录失败则重新爬取登录页面的验证码。重复进行上述的工作直至登录成功。在实际数据采集工作中,结果表明所有采集的重要Tor暗网站点基本尝试三次以内的登录流程后就能够登录成功。另外,测试结果表明登录过程调用Web API识别验证码每次所消耗的时间都在5秒以内。 本文使用MongoDB作为数据存储的数据库,MongoDB数据库存储数据时不会固定于一种数据格式,因此能够使得数据爬取过程中更具有伸缩性。另外,本文通过搭建一个MongoDB集群而不是使用单一的MongoDB节点进行数据存储,MongoDB集群由多个MongoDB节点组成,其中一个为主节点,剩余的节点全为从节点,存储过程中先将数据存储在主节点然后备份到各个从节点,当主节点出现不可预估的故障时,MongoDB集群剩余的从节点会通过选举方式选出一个节点替代原先的主节点继续数据存储工作,能够提高数据存储模块的鲁棒性。 Tor暗网数据采集系统使用机器的配置为Intel Xeon Bronze 1.7 GHz 12核,64 GB内存,4 TB硬盘,Centos7系统,带宽100 MB。 到目前为止,该系统已经运行长达近一年,实际结果证明该系统能够自动、准确、快速地采集重要Tor暗网站点的数据信息。爬取的Tor暗网重要站点分为Tor暗网交易市场和Tor暗网黑色论坛,系统采集的交易市场实际数据如表2所示,采集的黑色论坛的实际数据如表3所示。 表2 暗网交易市场数据采集结果表 续表2 表3 Tor暗网黑色论坛数据采集结果表 本文的研究重点放在Tor暗网交易市场的数据采集上,因此表2中的市场数据比表3的论坛数据要大。此外,表2市场中的商品数量这一数据比这些市场上实时发布的数据量要大,这是因为Tor暗网交易市场中的商品存在更新和下架,系统采集的数据长期积累使得该数据量大于市场实时发布的数据量。系统实际运行的结果充分证明本文所设计的Tor暗网数据采集系统能够自动、准确、快速地采集Tor暗网重要站点的数据信息。 随着数字货币的出现和快速发展,暗网上的各种违法行为愈来愈多,Tor暗网上违法泄露数据交易事件也逐年增多。为了及时采集Tor暗网站点的数据信息,从而进一步监控暗网空间资源,本文提出了数据采集模块通过Tor内核传输模块进入到Tor暗网空间实时采集数据信息的方法。但是随着Tor暗网站点的发展,特别是为了抵御DDoS攻击和防止爬虫,重要Tor暗网站点都使用了验证码机制来进行人机交互。学者们目前普遍使用CNN、RNN网络来对验证码进行端到端的识别,但是这种方法需要大量标记好的验证码样本来训练模型,这对于Tor暗网站点地数据采集工作是不合适的。Tor暗网的变化是频繁和不定的,需要能够快速简便地得到一个Tor暗网站点的验证码识别模型,同时需要的训练样本要尽可能少。因此本文设计实现了一个神经网络模型,通过CNN网络模块提取验证码图片的特征,再通过GRU网络模块将提取到的特征转化为时序特征并且得到一个时序特征预测值,网络模型使用ctc loss对时序特征预测值和样本标签值进行比较计算得到损失函数反馈给模型,不断训练得到一个有效的验证码识别模型。这个神经网络模型在使用少量验证码样本训练的情况下能够达到一个可观的验证码识别准确率,这是因为通过利用GRU网络得到时序特征,并且在训练过程中使用ctc loss进行计算,相当于在特征层面对验证码进行了切割,每一个时刻的特征像相当于切割的一部分,从而相当于对每个单字符进行识别,而单字符的识别所需要的样本是少量的。最后将该神经网络模型应用到Tor暗网站点的数据采集系统中,结果表明该系统能够自动、准确、快速地采集Tor暗网站点的数据信息,对于监控暗网空间资源、获取威胁情报信息、感知网络安全态势具有重大意义。
2 测 试
2.1 测试结果

2.2 结果分析
3 Tor暗网数据采集系统
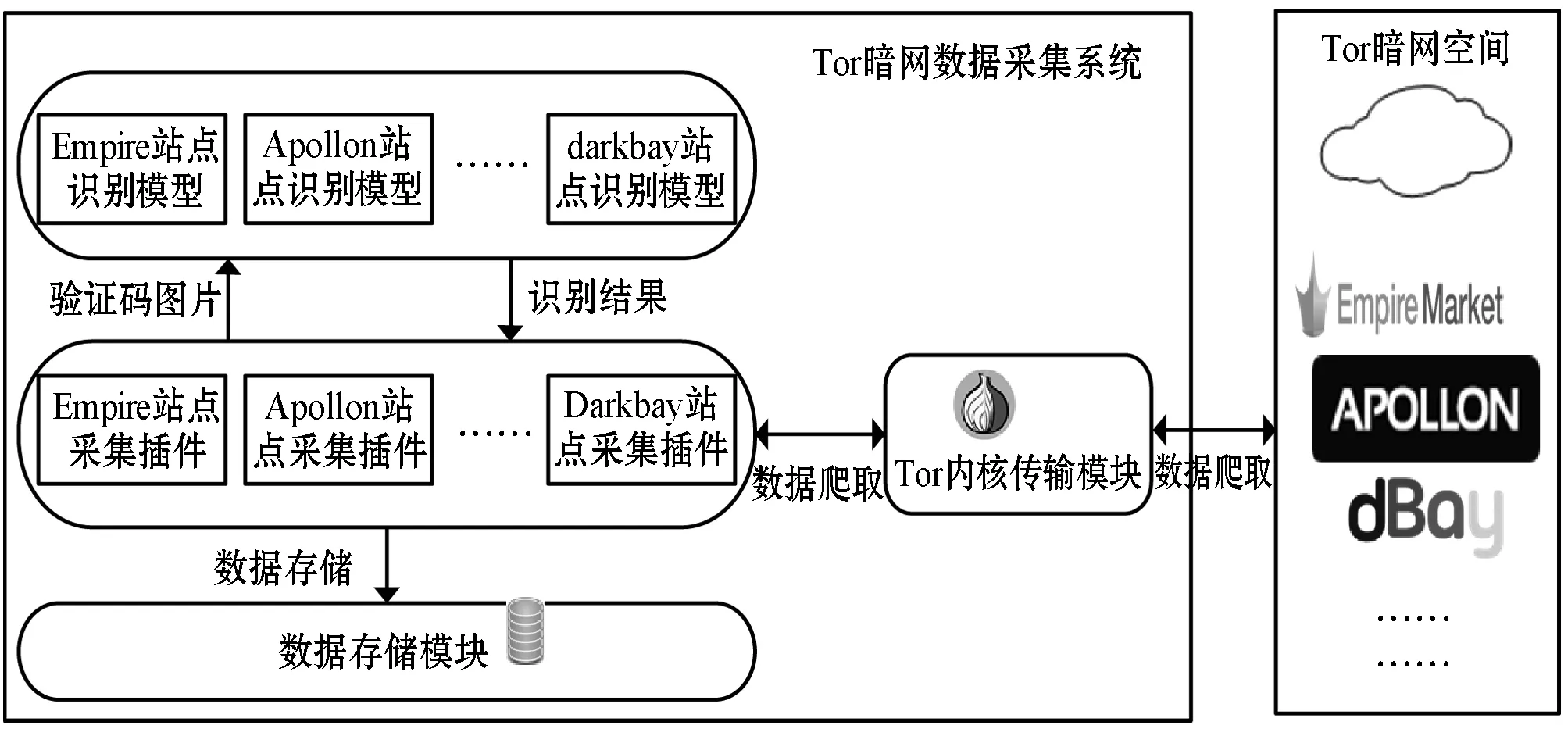
3.1 Tor内核传输模块
3.2 数据采集模块
3.3 数据存储模块
3.4 系统运行结果与分析



4 结 语
