基于YOLOv3的车辆行人目标检测算法改进方法研究
2022-08-10王景中王宝成
梁 策 王景中 王宝成
(北方工业大学信息学院 北京100144)
0 引 言
行人与车辆识别是智能交通的核心技术,此技术通过对行人、车辆目标进行检测识别,以对路况进行实时计算,对信号灯时间长短进行规划。在远程调度指挥、拥堵情况报警等方面具有重要应用价值[1]。而对行人与车辆识进行识别是目标检测技术一种具有研究意义的应用。
由于深度学习具有强大的学习与泛化能力,基于深度学习的目标检测方法日益发展与成熟。目前基于深度学习的目标检测方法有两类,一类是基于候选区域检测的方法,例如R-CNN[2-3]、Fast R-CNN[4]、Faster R-CNN[5];另一类是基于回归检测的方法,如YOLO[6-7]、YOLO 9000[8]、SSD[9]、YOLOv3[10-11]。YOLOv3算法使用了特征金字塔[12](Feature Pyramid Networks,FPN)策略,其特征提取主干网络Darknet-53采用残差网络结构,在提高网络深度、增强特征复用的同时,避免梯度消失、网络退化的情况。
然而,以上方法在面对交通图像中出现的目标尺度多、目标尺度过小、遮挡情况严重等情况时存在一些不足。传统方法的泛化能力不足,并且实时性较差;基于候选区域的目标检测方法拥有更高的准确度,但是检测速率较慢,并不适合对于检测实时性需求较高的应用场景;回归的目标检测方法具有更快的检测速率,例如YOLOv3算法,更适合行人车辆检测的性能需求。对于YOLOv3的FPN多尺度优化工作例如PANet[13],它通过自底向上的路径增强,利用准确的低层定位信号增强整个特征层次,从而缩短了低层与顶层特征之间的信息路径。基于PANet改进的ZigZagNet[14]通过预测层之间的双向交互完成了一种双向的多尺度上下文信息增强。而针对YOLOv3中NMS算法出现的误删候选框问题也出现了各种解决方案,例如:郭进祥等[15]通过线性衰减置信得分的方式,对非极大值抑制算法NMS进行优化。Jiang等[16]通过在NMS阶段引入定位得分作为排序指标而不是采用传统的分类得分,解决分类置信度和定位置信度不匹配的问题。Hosang等[17]通过一个新的网络架构来执行NMS算法,基于CNN来实现NMS网络架构。
本文针对交通监控图像存在的目标尺度多样、目标图像小和目标被遮挡等问题,对YOLOv3的网络结构与NMS算法进行改良:① 针对多尺度目标及小目标,向YOLOv3网络中加入新的预测层以获取更多尺度的特征图,并进行特征融合,使特征图具有高层语义信息的同时,还具有底层的位置信息,从而增强算法对多尺度目标、小目标的预测能力;② 针对被遮挡目标,使用以高斯分布的连续函数作为权重的衰减置信得分的NMS算法,降低被遮挡目标框被误删的风险,从而提高算法对被遮挡目标的识别能力。
1 YOLOv3算法
YOLOv3算法的前身是YOLOv1、YOLOv2算法。YOLO系列算法的主要流程是先通过卷积神经网络提取图像的特征图,再将特征图输入到预测网络层进行预测,最后输出预测结果。YOLOv3的网络结构如图1所示。

图1 YOLOv3网络结构
YOLOv3较其前身做出了一些改进:引入了残差网络(ResNet)[18]、特征金字塔等思想。借助残差网络深化网络以避免梯度消失的能力,构建出Dartnet-53网络作为特征提取的骨干网络,该骨干网络由5个残差块组成,每个残差块由多个残差单元组成。如图2所示,残差单元由两个DBL单元组成,每个DBL单元由卷积层、批归一化(batch normalization)[19]层和激活函数(Leaky ReLU)层组成;YOLOv3利用特征金字塔的思想,将第3、4、5个残差块生成的不同尺度的特征图进行融合,形成3个新的特征图,三种特征图的尺寸分别为(52×52)、(26×26)、(13×13),这种融合后的特征图在具有高层特征图的详尽语义信息的同时,还拥有底层特征图的详尽位置信息,分别用于预测小、中、大三种尺度的目标。

图2 DBL单元与残差单元结构图
检测网络使用特征提取骨干网络生成的三个不同特征图进行预测,以13×13的特征图为例,将图像分为相等的13×13的网格,每个网格只负责预测中心在落在其中的目标,每个网格生成b个预测框,每个预测框对应C+5个值(维度),C为检测类别数,5代表预测框的5个数值,分别为中心点横坐标x、纵坐标y、高度h、宽度w及预测框是否包含检测物体P(Oobject),再通过式(1)计算预测框的置信得分Sconfi。
Sconfi=P(C|||Oobject)×P(Oobject)×I(truth,pred)
(1)
式中:P(C|||Oobject)为网络预测目标为i类的置信得分;I(truth,pred)为预测框与目标框的交并比,如果预测框包含预测目标,则P(Oobject)=1,否则P(Oobject)=0。
最后使用非极大值抑制NMS算法对预测框进行筛选,将置信得分Sconfi最高的预测框作为候选框。NMS算法公式如下:
(2)
式中:i为类别编号;M为置信得分较大的候选框;bi为待处理的预测框;I(M,bi)为M与bi的交并比;Nt为抑制阈值。
在YOLOv3中,特征提取网络Darknet-53使用后3个残差层生成的特征图对原图像进行检测,此设计能够检测一定范围尺度的目标,但对于检测交通监控图像这种多尺度目标、小目标过多的图像还存在一定局限性;而NMS这种非连续性、抑制程度较大的预测框筛选方式,极大可能会误删被遮挡物体的预测框,影响对被遮挡目标的检测效果。
2 本文方法
2.1 高分辨率、预测尺度详细的特征提取网络
对于多尺度的目标检测,需要多种分辨率的特征图,低分辨率的特征图适用于对大目标的识别,高分辨率的特征图更适用于小目标的识别。对于特征图,底层的特征图语义信息较少,目标位置准确;高层的特征图语义信息较为丰富,目标位置比较粗略。顶层特征图在不断卷积的过程中,可能会忽略了很多小物体的信息,而特征金字塔可以将不同层次的特征进行尺度变化后,再进行信息融合,从而能够提取到较为底层的信息。本文对YOLOv3的网络结构进行改进,并结合多尺度预测、特征融合技术,提出一种高分辨率、预测尺度详细、对小目标识别效果好的网络。
为使网络获得更多种分辨率的特征图,提高对多尺度目标的检测率,本文将YOLOv3原网络中DarkNet-53的第2个残差块输出的下采样特征图作为一个新的尺度,将第3个残差块输出的下采样特征图进行2倍上采样,与新的特征图进行融合,从而增加了一个新的预测层。
对于YOLOv3网络,各个尺度的预测层输出预测结果之前,都需要经过6个DBL单元和1个卷积层。为了增强特征的复用以及避免梯度消失,本文将6个DBL单元变为2个DBL单元和4个残差单元,如图3所示。

图3 改进6×DBL层
改进的YOLOv3网络结构如图4所示,使用第2个残差块输出的下采样特征图,生成新的预测层。并将该特征图与第3个残差块输出的特征图进行融合,以增加新的预测层,将残差网络生成的特征图处理网络结构由6个DBL层调整为2个DBL单元和4个残差单元组成的残差块。

图4 改进YOLOv3网络结构图
改进后YOLOv3算法具有更多的预测尺度及更高的分辨率。更多的预测尺度意味着算法能够识别更多尺寸的目标;对多个特征进行融合可以提升算法对小目标的识别能力;优化残差结构会让网络层次更深预测能力更强。三种对网络结构的优化都提升了YOLOv3算法对交通监控图像中的行人车辆检测能力。
2.2 高斯衰减NMS算法
如图5所示,在车道中的行驶的A、B两辆汽车,A车的预测框的置信得分为0.85,B车的预测框置信得分为0.7,A车预测框与B车预测框的交并比(IOU)大于0.5。因此,在使用改进前的NMS算法时,由于A、B车预测框的IOU大于YOLOv3算法的默认阈值(0.5),因此算法会保留预测框置信得分最高的A车,会将B车的预测框置信得分置为0,导致无法对B车进行识别。造成上述情况的重要原因在于被覆盖目标的预测框与置信度得分最高的预测框交并比过大而超过阈值,被算法认定为是对同一目标的检测框,由于其置信得分不是最高,因此被算法淘汰,将置信得分直接置为0。

图5 目标遮挡情况
为此,对于与置信得分最高的预测框交并比超过阈值的预测框,采用不直接将该预测框的置信得分至于0,而是采用更平滑的处理方式,利用高斯函数对预测框置信得分进行处理,与置信得分最高的预测框交并比越大,则预测框的置信得分下降越多。式(3)为优化后的NMS算法表示:
(3)
式中:σ为高斯函数处理后的置信得分;i为类别编号;M为置信得分较大的预测框;bi为被比较的目标预测框;iou(M,bi)为M与预测框bi的交并比;D为处理后的预测框集合。优化后的NMS算法伪代码如算法1所示。
算法1改进NMS算法
输入:B={b1,b2,…,bn},S={s1,s2,…,sn},Nt,其中:B为候选预测框集合;S为所有候选框的置信得分集合;Nt为NMS算法置信得分筛选阈值。
输出:筛选后候选框的得分集合S;筛选后的候选框集合D。
1.begin
2.D←{}
3.whileB≠emptydo
4.m←argaxS
//获取置信得分最高的候选框行号
5.M←bm
//提取出置信得分最高的候选框
6.D←D∪MB←B-M
7.forbiinBdo
//对其他预测框高斯衰减函数处理
9.end
10.end
11.fordiinDdo
//删除D中置信分数小于阈值的预测框
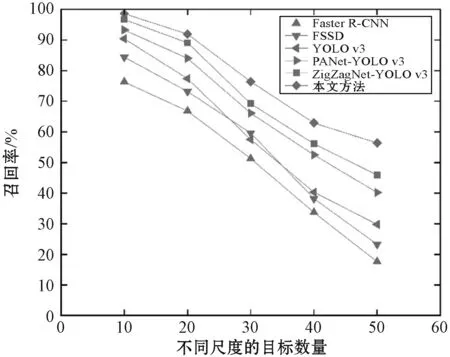
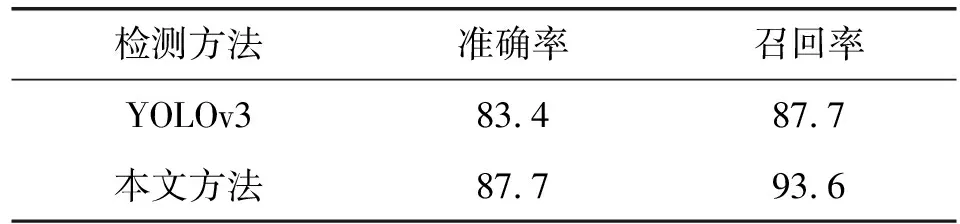
12.ifsi 13.D←D-diS←S-si 14.end 15.end 16.returnD,S //获取结果 17.end 算法流程如下: ① 将所有候选预测框集合D、候选框对应置信得分集合S、置信得分阈值Nt作为算法输入; ② 选取置信得分最大的预测框,将其存入集合D中,并从集合B中删除; ③ 计算置信得分最大的预测框与其他预测框的IOU值; ④ 使用式(3)对置信分数其他预测框进行高斯衰减处理,重新计算其置信分数; ⑤ 对剩余的预测框重复步骤②-步骤④,直到B所有预测框都被存入D中; ⑥ 删除D中置信度分数小于阈值的预测框,显示置信分数大于阈值的预测框,即该预测框为目标的最终检测结果。 传统的NMS算法是一种简单的阈值比较法,改进后的NMS算法通过对其衰减规则的改进,采用高斯衰减得分的方式对重叠复选框进行筛选,尽量避免将被遮挡目标的预测框误删,从而提高算法对遮挡目标的召回能力。 本文就YOLOv3的网络结构和NMS算法进行改进。改进后的NMS算法不再是简单的阈值比较法,而是通过一种高斯权重的置信得分衰减方法,有效避免对被遮挡目标的预测框的误删,从而提升对遮挡目标的检测能力;将DBL层替换为残差块,强化网络等级,增强对特征的复用,并有效避免梯度消失的情况出现。 实验使用操作系统为Ubuntu14.04,处理器为Intel Core i7 8700K,搭载NVIDIA 1070 GPU,内存容量为32 GB的计算机,神经网络基于深度学习框架Tensorflow运行。 实验使用UA-DETRAC[20]车辆数据集与PASCAL VOC[21]数据集。其中UA-DETRAC车辆检测数据集包含121万个带标签的车辆边界框,图像分辨率为960×540,数据集包含了白天、夜晚与各种天气条件的视频帧。从UA-DETRAC数据集中筛选出8 000幅含有遮挡情况的图像,从PASCAL VOC数据集中提取了2 000幅分辨率较高、目标较小且出现遮挡情况的行人、车辆图像。两个数据集共计10 000幅图片,将其中8 000幅图片作为训练数据集,剩余2 000幅作为测试数据集。 将YOLOv3与本文改进后的YOLOv3网络中NMS算法的阈值设定为默认值0.5,将两种网络的网络动量设置为0.9。初始学习率设置为0.001,学习率衰减系数为0.005,并将学习率在迭代20 000次时降为0.000 1,在迭代25 000次时降为0.000 01,让损失函数继续收敛。 图6为改进YOLOv3网络的损失值收敛曲线。由图可见,经过25 000次迭代后,Loss值降至0.2左右,由此得出,改进后YOLOv3网络在30 000次迭代后的训练效果较为理想。 图6 Loss函数曲线 本文主要针对YOLOv3算法的改进点在于增强其对多尺度目标以及被遮挡目标的识别能力,因此为了验证改进效果,使用PASCAL VOC数据集中目标大小尺度不一、目标小且遮挡情况较多的行人车辆图像进行对比实验。 1) 针对多尺度目标检测。测试集中包含537幅车辆行人目标大小不一的图像,使用Faster R-CNN[5]、FSSD[22]、YOLOv3[10-11]、具有PANet[13]结构的YOLOv3(PANet-YOLOv3)、具有ZigZagNet[14]结构的YOLOv3(ZigZagNet-YOLOv3)与改进后检测方法进行对比实验。 如图7所示,使用不同检测方法对多尺度行人车辆图像进行检测。当不同尺度目标数量为10时,Faster R-CNN、FSSD、YOLOv3、PANet-YOLOv3、ZigZagNet-YOLOv3改进方法的召回率均超过75%。当不同尺度目标数量为30时,Faster R-CNN为51.3%,YOLOv3为59.6%,FSSD为57.5%,PANet-YOLOv3为66.1%,ZigZagNet-YOLOv3为69.2%,改进方法为76.4%。随着图像中不同尺度的目标数量逐渐增加,召回率逐渐降低,当不同尺度目标数量为50时,Faster R-CNN的召回率为17.6%, FSSD为23.3%,YOLOv3为29.8%,PANet-YOLOv3为40.2%,ZigZagNet-YOLOv3为45.9%,本文方法为56.4%,明显高于其他方法。由此可知,通过增加YOLOv3网络预测层的方式,提高了其对多尺度目标的预测能力。 图7 本文方法与其他方法在多尺度目标检测的召回率对比 2) 针对小目标检测。从测试数据集中选择1 233幅包含共2 618个小目标的图片,对改进前YOLOv3算法与本文方法进行准确率与召回率统计。由于在人车识别中,小目标虽然有一定机会被识别,但过小的车辆目标可能会被识别为行人目标,因此本阶段实验以准确率与召回率作为评价标准。 从表1中结果可知,本文方法相比改进前的YOLOv3算法,在小目标识别方面的准确率提升了4.3百分点,召回率提升了5.9百分点。实验证明通过新增特征融合预测层的方法,能够提升YOLOv3对小目标的检测能力。 表1 YOLOv3与本文方法小目标检测对比(%) 3) 针对遮挡情况的检测。测试数据集中包含677幅存在遮挡情况的图片,将其按照横纵遮挡比例进行分组,对遮挡方向、遮挡比例的不同情况对改进前的YOLOv3算法与本文方法进行检测比较。 从表2中结果可以看出,在水平遮挡、遮挡比例低于20%的条件下,两种算法的准确率数值基本接近;遮挡比例处于20%~40%时,本文方法比YOLOv3的准确率数值高23百分点左右;遮挡比例高于40%时,相比与改进前YOLOv3算法仍然具备更高的准确率数值。在垂直遮挡,遮挡比例低于20%的条件下,相比YOLOv3的准确率数值高11百分点左右;在遮挡比例处于20%~40%时,本文方法的准确率值已经高于YOLOv3 28百分点左右;遮挡比例高于40%时,仍然相比于YOLOv3有更好的识别准确度。 表2 目标遮挡情况下本文方法与YOLOv3检测效果对比(%) 图8为本文方法与YOLOv3对于目标遮挡情况下的检测效果对比图。图8(a)、(b)为车辆遮挡比例为20%的情况,两种算法均能检测到目标车辆;图(c)、(d)为车辆遮挡比例80%的情况,YOLOv3算法无法检测被遮挡目标,但本文方法能够识别被遮挡目标;图(f)、(e)为行人遮挡比例为20%的情况,两种算法均能识别出被遮挡目标;图(g)、(h)为行人遮挡比例为40%的情况,改进后方法可识别被遮挡的行人目标。结果证明对NMS算法置信得分高斯加权衰减的改进取得了理想效果。 (a) (b) 4) 算法整体性能。实验使用全部测试集对本文方法与各类检测方法进行性能对比,从表3可知,改进后算法的准确率达到了86.1%,召回率达到了91.9%。相比于ACF的准确率提升了40.7百分点,召回率提升了40.7百分点;相比于R-CNN的准确率提升了35.3百分点,召回率提升33.9百分点;相比于Faster R-CNN准确率提升了27.3百分点,召回率提升22.6百分点相比于YOLOv3算法,准确率提升8.4百分点,召回率提升了10.4百分点。由上述阶段的实验结果可知,通过改进NMS算法与增加新的特征融合预测层,本文方法能够对YOLOv3的识别能力进行提升。 表3 各种检测方法的准确率与召回率对比(%) 本文将YOLOv3算法应用于行人车辆检测识别领域,实现了对交通监控图像中行人、车辆的实时准确检测。针对多尺度目标、目标过小及目标遮挡的问题,本文提出了对网络结构与NMS算法的优化思路。本文使用PASCAL VOC和UA-DETRAC数据集进行训练与测试。实验结果证明:本文方法能够改善YOLOv3算法对多尺度、小目标、被遮挡目标的检测能力,将行人车辆识别的检测准确率从77.7%提升至86.1%,召回率从81.5%提高到91.9%。但是本文向YOLOv3算法加入了更多的预测层及更复杂的高斯权重计算,因此对检测速率的优化是后续的研究方向。3 实验与结果分析
3.1 实验条件与数据集
3.2 模型训练

3.3 实验结果分析



4 结 语
